Сэмплирование данных значительно снижает нагрузку на вычислительные мощности. Но как можно судить о количестве дырок в сыре по одному куску? Что если из-за сэмплирования легко можно терять 20 тысяч и больше долларов в день?
Часто сэмплирование мешает проводить точный анализ потока данных, чему свидетельствует кейс под катом.

Сэмплирование — это способ формирования репрезентативной выборки так, чтобы можно было сделать выводы о генеральной совокупности.
Репрезентативность можно обеспечить, если выбирать элементы из генеральной совокупности случайным образом. Это означает, что у каждого посетителя сайта будет одинаковый шанс попасть в отчет. В большинстве случаев это не влияет на форму графика. Различие в значениях не будет заметно при переводе в процентное соотношение. Но сэмплирование может повлиять на статистически значимые различия.
Для того, чтобы сэмплированные данные могли адекватно передавать выводы обо всей совокупности, в выборке изначально не должно быть никаких аномалий: выбросов или провалов. Но никто от них не застрахован и почиканные данные могут быть искажены.
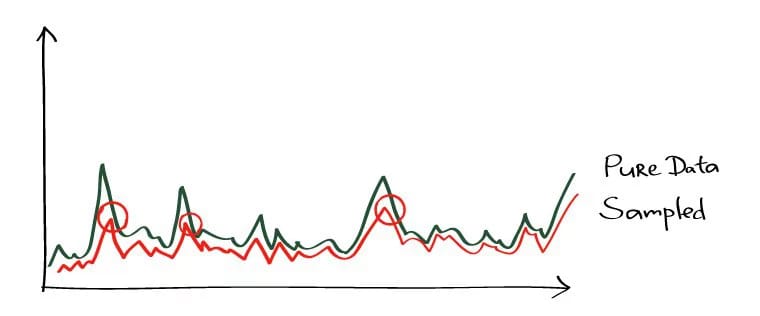
Более того, они даже могут быть скрыты маркетинговым эффектом, как описано тут.
Google и Яндекс применяют эту технику для снижения нагрузки на свои сервера. Отчет генерируется гораздо быстрее, но он может ввести маркетолога в заблуждение.
Компания Х получает в среднем 2 миллиона пользователей в сутки. В этом случае гугл уже применяет сэмплирование данных. Каждый день компания покупает 50 тысяч пользователей по 2$ каждый. Таким образом в день на рекламу уходит 100 000 у.е.
Среднее значение конверсии платного трафика в регистрации составило 25% по версии Google Analytics. При проверке на сервисе t.onthe.io, который не использует сэмплирование, средняя конверсия составила 20%.

Значит какие-то данные потерялись или исказились при сэмплировании. Компания Х из-за этого теряла 20 000$ в день.
Сэмплированные данные не всегда объективно отображают ситуацию. Есть несколько способов избежать сэмплирования.
При наличии премиум-аккаунта гугл выдает чистые данные до 1 миллиарда хитов в месяц. Но стоит аккаунт 150 000 $ в год, а есть и более дешевые способы.
Если для отчета используется большой временной отрезок (например отчет за год), то гугл скорее всего будет сэмплировать эти данные. Чтобы этого не допустить, можно разбить временной интервал на более мелкие части, например помесячно. А потом радостно слепить все месяцы вручную.
Можно увеличить точность выборки в настройках GA при формировании отчета. Погрешность представления данных уменьшится, но не сведется к нолю.
Настроить несколько представлений данных. Например, на сайте 10 основных разделов, тогда можно сделать 8 представлений данных, которые будут принимать информацию каждый со своего канала. В общем потоке на сайт заглядывают все те же 2 миллиона пользователей в месяц. Каждый из разделов получает по 200 000 посещений. Получается что в каждом разделе данные сэмплироваться не должны. Минус в том, что аналитику всего сайта снова придется склеивать вручную.
Также можно использовать инструмент Google Analytics Query Explorer или скрипты на языке R. Подробнее об этих методах здесь.
Многие сервисы для web аналитики не сэмплируют данные. К ним относятся t.onthe.io, stathat, Librato, Sumologic.
Часто сэмплирование мешает проводить точный анализ потока данных, чему свидетельствует кейс под катом.

Сэмплирование — это способ формирования репрезентативной выборки так, чтобы можно было сделать выводы о генеральной совокупности.
Репрезентативность можно обеспечить, если выбирать элементы из генеральной совокупности случайным образом. Это означает, что у каждого посетителя сайта будет одинаковый шанс попасть в отчет. В большинстве случаев это не влияет на форму графика. Различие в значениях не будет заметно при переводе в процентное соотношение. Но сэмплирование может повлиять на статистически значимые различия.
Для того, чтобы сэмплированные данные могли адекватно передавать выводы обо всей совокупности, в выборке изначально не должно быть никаких аномалий: выбросов или провалов. Но никто от них не застрахован и почиканные данные могут быть искажены.

Более того, они даже могут быть скрыты маркетинговым эффектом, как описано тут.
Зачем используется сэмплирование
Google и Яндекс применяют эту технику для снижения нагрузки на свои сервера. Отчет генерируется гораздо быстрее, но он может ввести маркетолога в заблуждение.
Кейс: как можно потерять деньги из-за сэмплирования
Компания Х получает в среднем 2 миллиона пользователей в сутки. В этом случае гугл уже применяет сэмплирование данных. Каждый день компания покупает 50 тысяч пользователей по 2$ каждый. Таким образом в день на рекламу уходит 100 000 у.е.
Среднее значение конверсии платного трафика в регистрации составило 25% по версии Google Analytics. При проверке на сервисе t.onthe.io, который не использует сэмплирование, средняя конверсия составила 20%.

Значит какие-то данные потерялись или исказились при сэмплировании. Компания Х из-за этого теряла 20 000$ в день.
Как избежать сэмплирования в GA
Сэмплированные данные не всегда объективно отображают ситуацию. Есть несколько способов избежать сэмплирования.
1. Премиум аккаунт в GA
При наличии премиум-аккаунта гугл выдает чистые данные до 1 миллиарда хитов в месяц. Но стоит аккаунт 150 000 $ в год, а есть и более дешевые способы.
2. Уменьшение временного интервала выборки
Если для отчета используется большой временной отрезок (например отчет за год), то гугл скорее всего будет сэмплировать эти данные. Чтобы этого не допустить, можно разбить временной интервал на более мелкие части, например помесячно. А потом радостно слепить все месяцы вручную.
3. Увеличить точность
Можно увеличить точность выборки в настройках GA при формировании отчета. Погрешность представления данных уменьшится, но не сведется к нолю.
4. Сегментация данных с помощью представлений
Настроить несколько представлений данных. Например, на сайте 10 основных разделов, тогда можно сделать 8 представлений данных, которые будут принимать информацию каждый со своего канала. В общем потоке на сайт заглядывают все те же 2 миллиона пользователей в месяц. Каждый из разделов получает по 200 000 посещений. Получается что в каждом разделе данные сэмплироваться не должны. Минус в том, что аналитику всего сайта снова придется склеивать вручную.
Также можно использовать инструмент Google Analytics Query Explorer или скрипты на языке R. Подробнее об этих методах здесь.
Сервисы, которые не сэмплируют данные
Многие сервисы для web аналитики не сэмплируют данные. К ним относятся t.onthe.io, stathat, Librato, Sumologic.
Конспект
- Выводы, основанные на сэмплированных данных могут привести к потере информации или денег.
- От сэмплирования в GA можно избавиться несколькими способами: уменьшением временного интервала, сегментацией данных, корректировкой точности.
- Сервисы, которые не сэмплируют данные: t.onthe.io, stathat, Librato, Sumologic.
