Комментарии 18
На PGDay 15 ребята демонстрировали OKmeter довольно интересная вещь для мониторинга PostgreSQL, за 25$ в месяц с сервера.
Для анализа можно еще взять pgBadger, но тут нужно смотреть на объем логов. На том же PGDay упоминали, что 200 Gb логов в несколько потоков переваривает за 6 часов.
Можно еще pgCluu, он работает через разные view и расширения PostgreSQL, а не через лог.
Для анализа можно еще взять pgBadger, но тут нужно смотреть на объем логов. На том же PGDay упоминали, что 200 Gb логов в несколько потоков переваривает за 6 часов.
Можно еще pgCluu, он работает через разные view и расширения PostgreSQL, а не через лог.
От одного из участников PGDays слышал, что видеозаписи конференции выложат, особенно интересно про системную часть — барьеры, noatime и тп, очень жду, а за ссылку на pgCluu спасибо, сейчас все эти метрики руками собираем из системы или из системных табличек =(
Про системную часть можете глянуть презентацию www.slideshare.net/alexeylesovsky/linux-tuning-for-postgresql-at-secon-2015
Там тезисно, но общие направления куда копать вполне понятны.
Там тезисно, но общие направления куда копать вполне понятны.
Видео конфы наконец-то появилось pgday.ru/ru/news/52. В итоге заюзали OKmeter, графики и язык для форматирования графиков у них шикарные
Еще можно взять pg_stat_statements — тоже без файловых логов (расширение) и просто взять информацию через SQL.
Спасибо за перевод книги.
В зависимости от версии PostgreSQL запрос может обрезаться..
По логам мы получаем отдельное время выполнения каждого запроса, по pg_stat_statements только среднее. PostgreSQL еще не все запросы хорошо нормирует, и люди пытаются при помощи регекспов это подправить.
В зависимости от версии PostgreSQL запрос может обрезаться..
По логам мы получаем отдельное время выполнения каждого запроса, по pg_stat_statements только среднее. PostgreSQL еще не все запросы хорошо нормирует, и люди пытаются при помощи регекспов это подправить.
OKmeter хорош да, постгресовый плагин там очень годный за счет агрегации данных с pg_stat_statements — очень хорошо видно запросы которые вдруг начинают выпирать (cpu/disk usage, row returned).
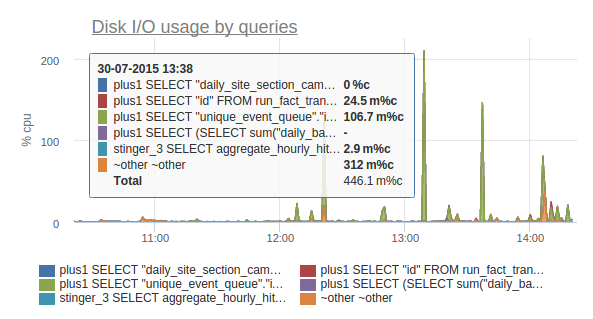
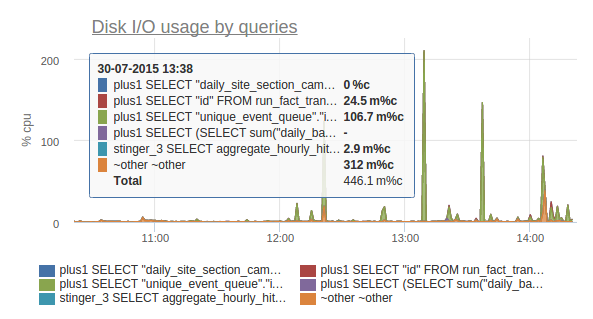
НЛО прилетело и опубликовало эту надпись здесь
Способы диагностики PostgreSQL в pdf вы найдете perf, SystemTrap, gdb.
Если кому-то интересно то же самое для MySQL:
1) Добавление столбца в существующую таблицу:
существует утилита от Percona под названием pt-online-schema-change, которая позволяет в неблокирующем режиме альтерить таблицы — www.percona.com/doc/percona-toolkit/2.1/pt-online-schema-change.html
работает путем создания новой пустой таблицы с новой схемой и обновления её с помощью триггеров, создает значительно большую нагрузку на базу, чем при обычном альтере
2) мониторинг запросов к базе
«show full processlist» или «select * form information_schema.PROCESSLIST», если нужна какая-то особенная информация
3) slow_log точно также есть в MySQL из коробки — dev.mysql.com/doc/refman/5.0/en/slow-query-log.html
4) Узнать какие запросы в данный момент делает процесс на продакшене
точно также — в strace будут видны запросы, которые исполняются на сервере
5) Обработка дубликатов
ALTER IGNORE для удаления дубликатов из таблицы при создании уникального индекса
INSERT IGNORE / INSERT ON DUPLICATE KEY UPDATE / REPLACE для вставки с игнорированием вставки в случае дубля / обновлением строки / заменой строки целиком соответственно
1) Добавление столбца в существующую таблицу:
существует утилита от Percona под названием pt-online-schema-change, которая позволяет в неблокирующем режиме альтерить таблицы — www.percona.com/doc/percona-toolkit/2.1/pt-online-schema-change.html
работает путем создания новой пустой таблицы с новой схемой и обновления её с помощью триггеров, создает значительно большую нагрузку на базу, чем при обычном альтере
2) мониторинг запросов к базе
«show full processlist» или «select * form information_schema.PROCESSLIST», если нужна какая-то особенная информация
3) slow_log точно также есть в MySQL из коробки — dev.mysql.com/doc/refman/5.0/en/slow-query-log.html
4) Узнать какие запросы в данный момент делает процесс на продакшене
точно также — в strace будут видны запросы, которые исполняются на сервере
5) Обработка дубликатов
ALTER IGNORE для удаления дубликатов из таблицы при создании уникального индекса
INSERT IGNORE / INSERT ON DUPLICATE KEY UPDATE / REPLACE для вставки с игнорированием вставки в случае дубля / обновлением строки / заменой строки целиком соответственно
Задача: сделать составной уникальный индекс, одно из полей может быть null
Проблема: уникальный индекс не сравнивает null поля
Решение: разбить индекс на 2 разных индекса.
Так же можно сделать индекс по выражению:
evgenykokovikhin=# create unique index test_unique_idx on test(a, coalesce(b, ''));
CREATE INDEX
evgenykokovikhin=# insert into test (a,b) values ('foo', null);
INSERT 0 1
evgenykokovikhin=# insert into test (a,b) values ('foo', null);
ERROR: duplicate key value violates unique constraint "test_unique_idx"
DETAIL: Key (a, (COALESCE(b, ''::character varying)))=(foo, ) already exists.
Мониторинг текущих запросов к базе
Хочу отметить сущестование параметра track_activity_query_size, который увеличивает размер, отводимый под хранение выполняющегося запроса
NULL и уникальные индексы
Также, если количество столбцов превышает максимально допустимое для индекса (по умолчанию, 32), уникальный индекс можно построить по хешу результата их конкатенации:
Обработка дубликатов
Если необходимо избавится от уже существующих дубликатов, может помочь такой запрос (id — PK, field_one, field_two — столбцы, по которым необходимо построить уникальный индекс):
Хочу отметить сущестование параметра track_activity_query_size, который увеличивает размер, отводимый под хранение выполняющегося запроса
выдержка из документации
Specifies the number of bytes reserved to track the currently executing command for each active session, for the pg_stat_activity.query field. The default value is 1024. This parameter can only be set at server start.
NULL и уникальные индексы
Также, если количество столбцов превышает максимально допустимое для индекса (по умолчанию, 32), уникальный индекс можно построить по хешу результата их конкатенации:
CREATE UNIQUE INDEX idx_name_unique ON foobar USING btree ( md5 ( field_one::text || field_two::text ) );Обработка дубликатов
Если необходимо избавится от уже существующих дубликатов, может помочь такой запрос (id — PK, field_one, field_two — столбцы, по которым необходимо построить уникальный индекс):
DELETE FROM foobar
WHERE id IN
(
SELECT unnest ( ( array_agg ( id ) ) [2:9999999] )
FROM foobar
GROUP BY field_one, field_two
HAVING count ( * ) > 1
);важно помнить что приём с конкатенацией полей в строку работает только до момента пока вам не встретится null :)
В приведенном выше комментарии указан один из вариантов работы с NULL-значениям.
Случайно нашел эту статью поисковиком.
Насчет решения с gdb:
Можно просто сделать pg_cancel_backend, а потом посмотреть в логах что за STATE мы убили (будет сразу после сообщения о том, что произошел cancel).
Насчет решения с gdb:
Можно просто сделать pg_cancel_backend, а потом посмотреть в логах что за STATE мы убили (будет сразу после сообщения о том, что произошел cancel).
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
PostgreSQL: Приемы на продакшене