В последнее время на Хабрахабр появилось много статей посвященных разработке для FPGA/ПЛИС. Это произошло как при непосредственном участии моих коллег, так и других пользователей. Видно, что такие статьи способствует популяризации этой сферы разработки и показывают, что уже есть существенный интерес к направлению разработки hardware в целом (образно называемого «железом»).
В этой статье я вступлю на практически «непаханое поле» разработки для ASIC и расскажу об одном интересном аспекте создания цифровых частей (IP-блоков) в микросхемах ASIC. Эта сфера разработки еще более узкая по сравнению с FPGA.
ASIC (application-specific integrated circuit, «интегральная схема специального назначения») — интегральная схема, специализированная для решения конкретной задачи.
Моя статья иллюстрирует часто используемый метод измерения power consumption (потребления энергии) для отдельного IP-блока внутри микросхемы еще до того, как его можно будет измерить в изготовленном чипе. Такая оценка позволяет уже на раннем этапе:
- сравнить разные варианты алгоритма цифровой обработки данных,
- выбрать оптимальный вариант реализации по критерию потребление/цифровые потери,
- довольно точно в числах оценить потребляемую мощность при работе в чипе, выпущенном по определенной технологии.
Этим методом с некоторыми допущениями можно довольно точно сравнить несколько реализаций алгоритма на HDL (языке описания цифровой схемы). В нашем случае это будет Verilog, который является наиболее популярным языком для разработки под ASIC.
Два допущения для ускорения процесса сравнения нескольких реализаций:
- Я не буду проводит полный синтез IP-блока для получения итоговой послойной реализации (она включает все паразитные емкости, которые также сказываются на потреблении), а ограничусь так называемой идеальной wire-load моделью синтезированного IP-блока. *Более точная оценка в абсолютных числа получается при синтезе в расширенном режиме topographical (с послойным синтезом), но при относительном сравнении этим можно пренебречь.
- Не получится оценить и учитывать потребление «клокового дерева» после wire-load синтеза. Для его оценки надо делать полную разводку в кристалле. В синхронных схемах оно может давать в цифрах существенное потребление относительно потребления всего блока при работе. Но при сравнении разной реализации блока с примерно одинаковой площадью триггеров можно считать потребление «клокового дерева» также примерно одинаковым.
Что нам нужно для измерения потребления:
- Библиотека компонентов (Standard Cell Library) под целевую технологию (130/90/65nm; предоставляется производителем под NDA)
- Программа для синтеза netlist из Verilog в базисе выбранной библиотеки компонентов
- Программа для оценки потребления
- Программа для симуляции и логирования рабочего режима нашего IP-блока (мы хотим получить точную оценку потребления в рабочем режиме, а не статистическую оценку потребления блока)
В частности, я использовал Synopsys DC (Design Compiler) для синтеза и расчета потребления, а Modelsim для симуляции работы и логирования количества переключений сигналов в схеме. Подобные данные и результаты можно получить и с использованием программ других фирм.
Чтобы получить потребление надо знать сколько раз и какие элементы переключались в синтезированной схеме IP-блока из 1 в 0 и из 0 в 1 (в цифровой схеме элементы могут находиться только в этих двух состояниях). Можно, конечно, не получать точные данные что и сколько раз переключилось, а посчитать их на основе статистических данных (этот сигнал будем считать переключается только 10% всего времени), но тогда и оценка потребления будет статистическая. А нам нужно получить точные оценки для нескольких реализация, чтобы сравнить. Поэтому будем симулировать работу IP-блока с помощью testbench и логировать все переключения элементов в тестируемом блоке.
Процесс оценки по этапам покажем с помощью примера
В качестве примера для оценки будем использовать исходный код цифрового блока обработки данных с выхода АЦП (Аналого-цифрового преобразователя). Его задача — сделать цифровую обработку сигнала (DSP/ЦОС) с целью реализовать Digital Down-shift Conversion (цифровое преобразование частоты вниз) для последующей обработки. С помощью этого примера я последовательно проиллюстрирую шаги, которые позволяют получить результат потребления для любого IP-блока написанного на Verilog/VHDL. * Некоторые имена в примере изменены из-за невозможности выложить как есть исходный код упомянутого цифрового блока.
Чтобы автоматизировать процесс тестирования разных реализаций IP-блока я написал скрипты, которые запускаются последовательно в 3 этапа:
- Синтез IP-блока под целевую технологию (в нашем случае будем синтезировать для TSMC 90nm, Library: typical )
- Запуск симуляция синтезированного описания (netlist)
- Расчет потребления по собранным данным переключений из симуляции.
А теперь сам процесс измерения по шагам и полученный результат с комментариями
Для каждого этапа можно выделить команды в свой скрипт, как сделано для автоматизации процесса у меня, или запускать их подряд по командам.
Скрипт run_srs для первого этапа (Design Compiler):
saif_map -start
read_verilog ~/srs/ddc_notch.v
read_verilog ~/srs/ddc_qnt3b.v
read_verilog ~/srs/ddc_intp.v
read_verilog ~/srs/ddc_qsr0.v
read_verilog ~/srs/ddc_qsr1.v
read_verilog ~/srs/ddc_lpf0.v
read_verilog ~/srs/ddc_qsr_lpf1.v
read_verilog ~/srs/ddc_reg.v
read_verilog ~/srs/ddc_top.v
current_design ddc_top
create_clock clk_ddc -period 20
set_clock_uncertainty 0.15 [all_clocks]
compile -gate_clock
change_names -rules verilog -hierarchy
write -format verilog -hierarchy -output ddc_top.v
write -format ddc -hierarchy -output ddc_top.ddc
report_area -hierarchy > ./log/area_ddc.rpt
exit
read_verilog ~/srs/ddc_notch.v
read_verilog ~/srs/ddc_qnt3b.v
read_verilog ~/srs/ddc_intp.v
read_verilog ~/srs/ddc_qsr0.v
read_verilog ~/srs/ddc_qsr1.v
read_verilog ~/srs/ddc_lpf0.v
read_verilog ~/srs/ddc_qsr_lpf1.v
read_verilog ~/srs/ddc_reg.v
read_verilog ~/srs/ddc_top.v
current_design ddc_top
create_clock clk_ddc -period 20
set_clock_uncertainty 0.15 [all_clocks]
compile -gate_clock
change_names -rules verilog -hierarchy
write -format verilog -hierarchy -output ddc_top.v
write -format ddc -hierarchy -output ddc_top.ddc
report_area -hierarchy > ./log/area_ddc.rpt
exit
Включаем логирования соответствия имен для расчета потребления
saif_map -start
Компилируем исходники
read_verilog ~/srs/ddc_notch.v
read_verilog ~/srs/ddc_qnt3b.v
read_verilog ~/srs/ddc_intp.v
read_verilog ~/srs/ddc_qsr0.v
read_verilog ~/srs/ddc_qsr1.v
read_verilog ~/srs/ddc_lpf0.v
read_verilog ~/srs/ddc_qsr_lpf1.v
read_verilog ~/srs/ddc_reg.v
read_verilog ~/srs/ddc_top.v
current_design ddc_top
Нам достаточно указать только настройки (constraints) для клока. Хотя для сложных блоков таких настроек надо указать достаточно много, чтобы результат после синтеза соответствовал ожиданиям.
create_clock clk_ddc -period 38.46
set_clock_uncertainty 0.15 [all_clocks]
Компилируем только с параметром gate_clock, что позволяет автоматически при синтезе вставить схему выключения клока (при не активности FF (флип-флопа/регистра) и соблюдении определенных правил описания регистров на Verilog). Это самый существенный метод снижения активного потребления схемы в ASIC)
compile -gate_clock
Записываем результаты синтеза для второго и третьего этапа
change_names -rules verilog -hierarchy
write -format verilog -hierarchy -output ddc_top.v
write -format ddc -hierarchy -output ddc_top.ddc
ddc_top.ddc — сохраняем результат синтеза, чтобы не компилировать заново на третьем этапе.
ddc_top.v — синтезированный Verilog netlist для симуляции
Скрипт vsim.do для второго этапа (симулирование и логирование переключений в Modelsim)
vlib work
vmap work work
vlog -work work ~/work/tsmc090.v
vlog -work work ~/work/ddc_top.v
vlog -work work ~/work/tb.v
vsim +notimingchecks -novopt work.tb +nowarn3017 +nowarn3722
run 90us
power add -r tb/ddc_top/*
run 200us
power report -all -bsaif saif.saif
exit
vmap work work
vlog -work work ~/work/tsmc090.v
vlog -work work ~/work/ddc_top.v
vlog -work work ~/work/tb.v
vsim +notimingchecks -novopt work.tb +nowarn3017 +nowarn3722
run 90us
power add -r tb/ddc_top/*
run 200us
power report -all -bsaif saif.saif
exit
Создаем библиотеку, в которой будем компилировать и симулировать
vlib work
vmap work work
Компилируем синтезированный на первом этапе netlist (ddc_top.v), библиотеку элементов TSMC 90nm для симуляции (tsmc090.v) и tеstbench (tb)
vlog -work work ~/work/tsmc090.v
vlog -work work ~/work/ddc_top.v
vlog -work work ~/work/tb.v
Код Verilog для testbench (tb.v)
`timescale 1ps/1ps
module tb;
reg clk_ddc;
reg rstz_ddc;
reg in_valid;
reg [2:0] in_i;
reg [2:0] in_q;
reg [2:0] i_temp;
reg [2:0] q_temp;
always @(posedge clk_ddc)
if (~rstz_ddc) i_temp <= 'd0;
else if (in_valid) i_temp <= $random % 8;
always @(posedge clk_ddc)
if (~rstz_ddc) q_temp <= 'd0;
else if (in_valid) q_temp <= $random % 8;
always @*
case (i_temp)
3'd0: in_i = 4'b001;
3'd1: in_i = 4'b001;
3'd2: in_i = 4'b010;
3'd3: in_i = 4'b011;
3'd4: in_i = 4'b100;
3'd5: in_i = 4'b101;
3'd6: in_i = 4'b110;
default:in_i= 4'b111;
endcase
always @*
case (q_temp)
3'd0: in_q = 4'b001;
3'd1: in_q = 4'b001;
3'd2: in_q = 4'b010;
3'd3: in_q = 4'b011;
3'd4: in_q = 4'b100;
3'd5: in_q = 4'b101;
3'd6: in_q = 4'b110;
default:in_q= 4'b111;
endcase
initial clk_ddc = 'd0;
always #19230 clk_ddc = ~clk_ddc; //26 Mhz
always @(posedge clk_ddc)
if (~rstz_ddc) in_valid <= 'd0;
else in_valid <= 'd1;
initial begin
rstz_ddc = 'd0;
#80000;
@(posedge clk_ddc);
rstz_ddc = 'd1;
@(posedge clk_ddc);
@(posedge clk_ddc);
#50000000; $display ($time);
#50000000; $display ($time);
#50000000; $display ($time);
#400000000;
end
ddc_top ddc_top (
.clk_ddc ( clk_ddc ),
.rstz_ddc ( rstz_ddc ),
// APB
.clk_apb ( 1'd0 ),
.reg_adr ( 10'd0 ),
.reg_we ( 1'd0 ),
.reg_wd ( 32'd0 ),
.reg_rd ( reg_rd ),
.ddc_qi ( {in_q,in_i} ),
.ddc_in_valid ( in_valid ),
.ddc_out_i ( ),
.ddc_out_q ( ),
.ddc_out_valid ( )
);
Отмечу, что на вход мы подаем изначально рандомно-сгенерированные входные данные, а не данные с модели имитирующие реальный входной сигнал. Для нашего случая измерения потребления цифровой схемы для сигнала, находящегося «под шумами», будет эквивалентно. По-сути, фактический сигнал на входе представляет «белый шум» (равномерное распределение случайного генератора). Хотя, если быть точным, он является не идеально «белым» из-за ограничения полосы сигнала и влияния аналоговых входных усилителей, но это в целом не сказывается на результат симуляции и измерения потребления.
Запускаем симуляцию без оптимизации для точного логирования и без проверки временных соотношений из библиотеки TSMC ( также скроем определенные Warning библиотеки).
vsim +notimingchecks -novopt work.tb +nowarn3017 +nowarn3722
Пропускаем начальную инициализацию для чистоты сравнения
run 90us
И начинаем логирование всех сигналов в нашем блоке
power add -r tb/ddc_top/*
Собираем данные 200мкс в рабочем режиме
run 200us
И записываем собранные данные в формате Switching Activity Interchange Format (SAIF) в файл для использования на третьем этапе.
power report -all -bsaif saif.saif
Пример части данных из файла saif
Показывает сколько раз определенный внутренний сигнал нетлиста переключался за время теста(INSTANCE dff_20_reg_6_ NET (flag (T0 0) (T1 200000000) (TX 0) (TC 0) (IG 0)) (n0 (T0 100534440) (T1 99465560) (TX 0) (TC 1324) (IG 0)) (clk (T0 150002000) (T1 49998000) (TX 0) (TC 5200) (IG 0)) (xRN (T0 0) (T1 200000000) (TX 0) (TC 0) (IG 0)) (xSN (T0 0) (T1 200000000) (TX 0) (TC 0) (IG 0))
Скрипт run для третьего этапа (измерение потребления блока на базе данных saif в Design Compiler)
read_ddc ./ddc_top.ddc
current_design ddc_top
read_saif -input ./saif.saif -instance tb/ddc_top
report_power -hierarchy -levels 1 -analysis_effort high > ./log/power_ddc.rpt
report_saif
current_design ddc_top
read_saif -input ./saif.saif -instance tb/ddc_top
report_power -hierarchy -levels 1 -analysis_effort high > ./log/power_ddc.rpt
report_saif
Прочитываем ранее сохраненную базу данных для синтезированного netlist и подключаем полученный ранее saif
read_ddc ./ddc_top.ddc
current_design ddc_top
read_saif -input ./saif.saif -instance tb/ddc_top
Запускаем измерение power consumption и записываем в файл
report_power -hierarchy -levels 1 -analysis_effort high > ./log/power_ddc.rpt
Проверяем, что все внутренние сигналы у нас были правильно сопоставлены и учитаны в анализе потребления. И при этом не было сигналов, для которых не получилось найти статистику переключений в файле saif (такое выходит для 50% сигналов, если симулировать исходный Verilog, а не синтезированный netlist под целевую библиотеку).
report_saif
Отчет этой команды для нашего примера
--------------------------------------------------------------------------------
User Default Propagated
Object type Annotated (%) Activity (%) Activity (%) Total
--------------------------------------------------------------------------------
Nets 2029(100.00%) 0(0.00%) 0(0.00%) 2029
Ports 655(100.00%) 0(0.00%) 0(0.00%) 655
Pins 7492(100.00%) 0(0.00%) 0(0.00%) 7492
--------------------------------------------------------------------------------
А теперь можно все 3 скрипта запустить последовательно одной командой и посмотреть что получилось для нашего примера
dc_shell source ./run_srs ; vsim do ./vsim.do ; dc_shell source ./run
Вот такой итоговый отчет
Library(s) Used: typical (File: ~/lib/lib90nm/typical.db)
Power-specific unit information :
Voltage Units = 1V
Capacitance Units = 1.000000pf
Time Units = 1ns
Dynamic Power Units = 1mW (derived from V,C,T units)
Leakage Power Units = 1pW
--------------------------------------------------------------------------------
Switch Int Leak Total
Hierarchy Power Power Power Power %
--------------------------------------------------------------------------------
ddc_top 6.60e-02 0.315 1.10e+08 0.491 100.0
r313 (ddc_top_DW01_inc_0) 0.000 0.000 1.40e+05 1.40e-04 0.0
ddc_reg (ddc_reg) 0.000 1.27e-03 3.78e+06 5.06e-03 1.0
ddc_intp (ddc_intp) 8.41e-03 3.34e-02 5.75e+06 4.76e-02 9.7
ddc_qnt3b (ddc_qnt3b) 2.59e-03 9.17e-03 2.20e+06 1.40e-02 2.8
ddc_qsr_lpf1(ddc_qsr_lpf1) 2.44e-02 0.110 1.54e+07 0.150 30.4
ddc_notch3 (ddc_notch_1) 1.75e-03 8.81e-03 1.05e+07 2.11e-02 4.3
ddc_notch2 (ddc_notch_2) 1.69e-03 8.81e-03 1.05e+07 2.10e-02 4.3
ddc_notch1 (ddc_notch_3) 1.69e-03 8.81e-03 1.05e+07 2.10e-02 4.3
ddc_notch0 (ddc_notch_0) 2.16e-03 9.98e-03 1.05e+07 2.27e-02 4.6
ddc_qsr1 (ddc_qsr1) 1.46e-03 2.98e-03 4.32e+05 4.86e-03 1.0
ddc_lpf0_q (ddc_lpf0_1) 9.79e-03 5.75e-02 3.80e+06 7.11e-02 14.5
ddc_lpf0_i (ddc_lpf0_0) 1.06e-02 6.05e-02 3.90e+06 7.50e-02 15.3
ddc_qsr0 (ddc_qsr0) 1.33e-03 2.68e-03 2.34e+05 4.24e-03 0.9
Суммарное потребление складывается из трех составляющих:
- Cell Leakage power — ток утечки. Статическая составляющая, которая зависит от технологии производства (90/65/28нм) и условий работы схемы (температура/напряжение). Рассчитанное значение пропорционально площади блока.
- Cell Internal power — ток, возникающий при изменении состояния входов/выходов компонента библиотеки (cell — пример: логическое «или» ORX2, триггер DFF). Динамическая составляющая.
- Net Switching power — ток, связанный с перезарядкой выходных емкостей компонента при переключении. Динамическая составляющая.
В нашем примере мы получили результат, что при клоке в 26МГц наш блок цифровой обработки потребляет 491 мкА в активном режиме для 90нм
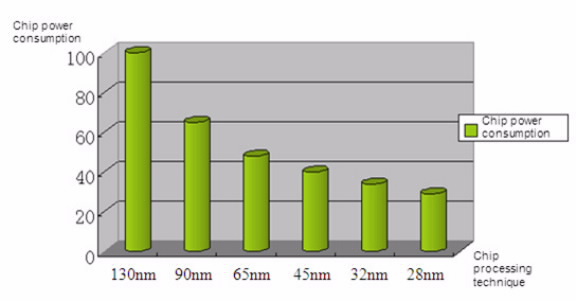
В следующей статье можно провести анализ потребления этого же IP-блока при реализации его в FPGA. Для этого у каждого производителя Altera/Xilinx/Microsemi есть специализированные программы в рамках их САПР (Систем автоматизированного проектирования). В частности, у Altera эта часть называется PowerPlay Power Analysis, которая позволяет сильно автоматизировать описанный выше процесс для своих FPGA. Только вот общеизвестно, что возможность «запрограммировать» в FPGA любой IP-блок имеет явную негативную составляющую в виде значительно большего потребления. Отличие в потреблении может достигать нескольких десятков раз, если сравнивать реализацию одного и того же IP-блока в ASIC 90nm и в современной FPGA, сделанной по технологии 28nm.







