Комментарии 12
А можете в двух словах объяснить, что из себя представляет FlexFabric сугубо практически? Мы не используем, а гуглится только какой-то маркетинг. В чем там этот Flex?
Практически, пара модулей «HP VC FlexFabric 10/24» может заменить пару LAN модулей (а иногда и две пары) и пару SAN модулей в блейд-корзине, и позволяет гибко управлять подачей LAN и SAN-адаптеров и VLAN-ов в блейд-сервера. По данной технологии много интересного написано в блоге HP — habrahabr.ru/company/hp
Был опыт внедрения и эксплуатации, похожей инфраструктуры виртуализации, на базе Cisco Nexus 5k /UCS 5800 /6248UP. В свое время, не стали обновлять существующие корзины HP C7000 до 10Gb, решили переехать на новые крзины Cisco UCS. Довольно таки, гибкое решение. Автор, поделитесь опытом эксплуатации NFS в среде виртуализации, интересно узнать ваше мнение?
а почему NFS, а не FCoE? у вас вроде все компоненты поддерживают FCoE…
Это решение было принято СХДшниками. Насколько я знаю NFS проще FCoE в выявлении проблем.
Легче управляется, проще бэкапится, гранулярность бэкапа-восстановления выше (на уровне отдельного виртуального диска, а не датастора целиком), в ряде случаев может быть выше производительность, из-за отсутствия ограничений «одна очередь SCSI-команд на данный датастор со всеми его VMDK целиком».
Когда у вас есть связка на подобии той которая описана в статье, а именно FlexFabric, Nexus 5k, NetApp FAS у нас есть выбор какой протокол запускать по конвергентным линкам FCoE/iSCSI/NFS для VMware. В нашем случае можно по одним и тем же линкам запустить все эти протоколы сразу. Важно отметить что для СХД NetApp все перечисленные протоколы работают практически одинаково быстро. Стоит также отметить что протокол NFS в продуктах VMWare появился именно с подачи NetApp.
С точки зрения работы с VMware NFS протокол более удобен в плане резервного копирования/восстановления, клонирования, тонкого провиженинга (Thing Provitioning) и Дедубликации в связке с СХД NetApp.
Когда хранилище отдаёт блочное устройство на котором потом живёт файловая система, а поверх неё лежат виртуалки, то СХД не знает о том что там и где на самом деле лежит. Когда же cистема хранения (не гипервизор) делает снепшоты или клоны с блочного устройства она не может отделить одни виртуальные машины от других, по-этому в снепшоте/клоне будут находиться все виртуальные машины. Если откатываться на ранее сделанный снепшот, то все данные будет откачены назад.
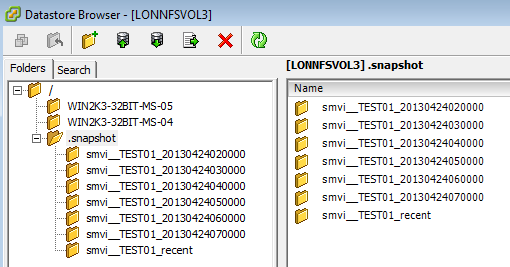
По-этому удобнее когда СХД управляет файловой системой и соответственно знает о том что где лежит. Когда мы делаем снепшот с файловой шары NFS, то как и в случае блочного устройства откатить мы можем только всю шару целиком, но при этом можем поштучно выборочно клонировать виртуалки средствами хранилища, не нагружая гипервизор. После снятия снепшота все виртуалки зафиксированные в снепшоте будут видны из специальной папки .snapshot в корне NFS датастора, и любая виртуальная машина может быть от туда восстановлена или скопирована просто операцией копирования.
Зачем вообще исспользовать снепшоты/клоны хранилища?
На практике использовать снепшоты/клоны NetApp очень выгодно, так как они, в отличае VMWare снепшотов, совсем никак не влияют на производительность всей системы. Напомню, что VMware не рекомендует исспользовать свои снепшоты на высоконагруженных вируальных машинах, потому что снепшоты VMWare влияют на производительность виртуальной машины потому-что работают по технологии CoW, чем больше снепшотов, тем хуже работает виртуальная машина.
ThingProvitioning / Дедубликация на хранилище
ThingProvitioning который исспользуется на СХД NetApp FAS тоже не влияет на производительность.
Когда вы исспользуете эти технологии на стороне хранилища, то высвобожденное пространство в случае NFS возращается «внутрь» файловой шары и может исспользоваться живущими на ней виртуалками, в случае блочного хранения высвобожденное какбы во вне луна (можно создать ещё один лун), а не внутрь.
Блочные протоколы FC/FCoE/iSCSI удобно исспользовать для загрузки серверов. Важным преимуществом блочных протоколов перед NFS является наличие встроенного механизма мультипасинга и балансировки нагрузки. Так как у NFS нет мультипасинга, его роль должен выполнять коммутатор и технологии на подобии vPC и LACP. Также протоколы FC/FCoE устроены таким образом, что они не теряют свои фреймы, это кстати часто является причиной более низких задержек чем у Ethernet. К счастью Nexus 5k поддерживает DCB (lossless Ethernet), vPC, LACP что позволяет полностью компенсировать все эти недостатки NFS.
С точки зрения работы с VMware NFS протокол более удобен в плане резервного копирования/восстановления, клонирования, тонкого провиженинга (Thing Provitioning) и Дедубликации в связке с СХД NetApp.
Когда хранилище отдаёт блочное устройство на котором потом живёт файловая система, а поверх неё лежат виртуалки, то СХД не знает о том что там и где на самом деле лежит. Когда же cистема хранения (не гипервизор) делает снепшоты или клоны с блочного устройства она не может отделить одни виртуальные машины от других, по-этому в снепшоте/клоне будут находиться все виртуальные машины. Если откатываться на ранее сделанный снепшот, то все данные будет откачены назад.
По-этому удобнее когда СХД управляет файловой системой и соответственно знает о том что где лежит. Когда мы делаем снепшот с файловой шары NFS, то как и в случае блочного устройства откатить мы можем только всю шару целиком, но при этом можем поштучно выборочно клонировать виртуалки средствами хранилища, не нагружая гипервизор. После снятия снепшота все виртуалки зафиксированные в снепшоте будут видны из специальной папки .snapshot в корне NFS датастора, и любая виртуальная машина может быть от туда восстановлена или скопирована просто операцией копирования.

Зачем вообще исспользовать снепшоты/клоны хранилища?
На практике использовать снепшоты/клоны NetApp очень выгодно, так как они, в отличае VMWare снепшотов, совсем никак не влияют на производительность всей системы. Напомню, что VMware не рекомендует исспользовать свои снепшоты на высоконагруженных вируальных машинах, потому что снепшоты VMWare влияют на производительность виртуальной машины потому-что работают по технологии CoW, чем больше снепшотов, тем хуже работает виртуальная машина.
ThingProvitioning / Дедубликация на хранилище
ThingProvitioning который исспользуется на СХД NetApp FAS тоже не влияет на производительность.
Когда вы исспользуете эти технологии на стороне хранилища, то высвобожденное пространство в случае NFS возращается «внутрь» файловой шары и может исспользоваться живущими на ней виртуалками, в случае блочного хранения высвобожденное какбы во вне луна (можно создать ещё один лун), а не внутрь.
Блочные протоколы FC/FCoE/iSCSI удобно исспользовать для загрузки серверов. Важным преимуществом блочных протоколов перед NFS является наличие встроенного механизма мультипасинга и балансировки нагрузки. Так как у NFS нет мультипасинга, его роль должен выполнять коммутатор и технологии на подобии vPC и LACP. Также протоколы FC/FCoE устроены таким образом, что они не теряют свои фреймы, это кстати часто является причиной более низких задержек чем у Ethernet. К счастью Nexus 5k поддерживает DCB (lossless Ethernet), vPC, LACP что позволяет полностью компенсировать все эти недостатки NFS.
спасибо! тот случай когда комментарий ценнее статьи )
едниственный нюанс — imho, LACP или vPC никак не помогут NFS-у. Данные в LACP/vPC распределяются по линкам в лушчем случае в зависимости от хэша (src-ip+port / dst-ip+port) и соответвенно поток данных от хоста к хранилке всегда будет идти одним путем. Ну разве кто-то опубликует хранилку с двумя адресами и это будут два разных стора для машин.
едниственный нюанс — imho, LACP или vPC никак не помогут NFS-у. Данные в LACP/vPC распределяются по линкам в лушчем случае в зависимости от хэша (src-ip+port / dst-ip+port) и соответвенно поток данных от хоста к хранилке всегда будет идти одним путем. Ну разве кто-то опубликует хранилку с двумя адресами и это будут два разных стора для машин.
Полностью с вами согласен.
Общее правило для LACP гласит, что количество хостов должно быть равное или больше чем линков по которым необходимо балансировать нагрузку, и чем больше хостов тем более вероятно что они более равномерно утилизируют пропускную способность всех агрегированных линков.
Но можно и не надеяться на вероятность, а высчитать подходящие IP адреса, чтобы утилизировать все линки.
Но к счастью обычно число хостов в ЦОД на намного больше числа линков. По этому для большинства ЦОД ов это совсем не проблема.
Кроме того если речь про 10Гб линки, как в нашем случае, то нужно еще постараться чтобы загрузить хотя-бы один 10Гб линк.
Посему возвращаюсь к своему первоначальному утверждению, что разницы В ПРАВИЛЬНО НАСТРОЕННОЙ ИНФРАСТРУКТУРЕ между блочным протоколами и nfs быть не должно.
Общее правило для LACP гласит, что количество хостов должно быть равное или больше чем линков по которым необходимо балансировать нагрузку, и чем больше хостов тем более вероятно что они более равномерно утилизируют пропускную способность всех агрегированных линков.
Но можно и не надеяться на вероятность, а высчитать подходящие IP адреса, чтобы утилизировать все линки.
Но к счастью обычно число хостов в ЦОД на намного больше числа линков. По этому для большинства ЦОД ов это совсем не проблема.
Кроме того если речь про 10Гб линки, как в нашем случае, то нужно еще постараться чтобы загрузить хотя-бы один 10Гб линк.
Посему возвращаюсь к своему первоначальному утверждению, что разницы В ПРАВИЛЬНО НАСТРОЕННОЙ ИНФРАСТРУКТУРЕ между блочным протоколами и nfs быть не должно.
Высчитать правильные IP (если хостов действительно мало) можно так.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Нюансы связки ESXi, FlexFabric, 10 Gbit и NFS