Coвсем недавно Google сделал доступной для всех свою библиотеку для машинного обучения, под названием TensorFlow. Для нас это оказалось интересно еще и тем, что в состав входят самые современные нейросетевые модели для обработки текста, в частности, обучения типа “последовательность-в-последовательность” (sequence-to-sequence learning). Поскольку у нас есть несколько проектов, связанных с этой технологией, то мы решили, что это отличная возможность перестать изобретать велосипед (наверное пора уже) и быстро улучшить результаты. Представив себе довольные лица клиентов, мы приступили к работе. И вот что из этого получилось…
Для начала нужно пояснить, что у нас имеется собственная нейросетевая библиотека. Конечно далеко не такая обширная и амбициозная, но предназначенная для решения определенных задач обработки текстов. В свое время я решил пойти путем написания собственного решения, вместо использования готового. По разным соображениям, в том числе кроссплатформенности, компактности, удобства интеграции в остальной код, эстетического нежелания иметь десятки зависимостей от вообще-то ненужных средств разных сторонних авторов. В итоге получилось некое средство, написанное на языке F#, удобное, занимающее порядка 2mb места, и делающее то, чего от него требовалось. С другой стороны довольно медлительное в плане скорости, не поддерживающие вычисления на GPU, урезанное в функционале, и оставляющее сомнение в своем соответствии современным реалиями.
Вопрос изобретать велосипед или использовать готовый он, в общем то, вечный. И червь сомнения все время грыз, что поддержание собственного средства вещь неоправданная, затратная по ресурсам и ограничивающая в возможностях. С периодическими обострениями приходили идеи перейти на использование, например Theano или Torch, как делают все нормальные люди. Но руки не доходили. А с выходом TensorFlow возникла еще одна дополнительная мотивация.
Вот в таком контексте я начал разбираться с этой системой.
Короткие замечания о процессе установки
TensorFlow установить пожалуй проще, чем ряд других современных нейросетвых библиотек. Если вам повезет, то дело может ограничится одной строчкой, введённой в строке терминала Linux. Да, Windows традиционно не поддерживается, но такая мелочь конечно не остановит настоящего разработчика.
Нам не повезло, на Ubuntu 11 TensorFlow устанавливаться отказалась. Но после апгрейда до 14.04 и некоторых танцев с бубном что-то все же заработало. По крайней мере, удалось выполнить фрагмент кода из раздела getting started. Поэтому, можно смело написать, что установка TensorFlow проста и не вызывает сложностей, особенно если у вас свежий дистрибутив, и версия python 2 не ниже 2.7.9. Для Linux это нормально, если сложный программный пакет не устанавливается сразу (ну может быть, не нормально, но это обычная ситуация, так часто бывает).
Проверка работы.
Здесь надо сказать следующее. Все нижеизложенное следует рассматривать как частный пример из личного опыта, сделанный в целях удовлетворения персонального любопытства в достаточно узкой области. Автор не претендует на то, что полученные выводы имеют глобальное значение, или вообще какое-то значение. Рассуждения о недостатках в результатах следует относить не к самой системе TensorFlow (которая в основном работает отлично и главное быстро), а к конкретным моделям и обучающим примерам.
Чат-бот
Вводные уроки про распознавание цифр из набора MNIST я оставил на будущее, и открыл сразу раздел, посвящённый sequence-to-sequence learning. Чтобы было понятно, о чем идет речь, опишу суть дела немного подробнее.
Задачей sequence-to-sequence learning в общем виде является генерация новой последовательностей символов на основании входной последовательности символов. В нашем частном случае символами являются слова. Наиболее известным приложением этой задачи является, вероятно, машинный перевод — когда на вход модели подаётся предложение на одном языке, а на выходе мы получаем перевод на другой язык. Как показано на рисунках из вводных уроков, есть два основных класса таких моделей. Первый использует вариант кодировщик-декодировщик. Исходная последовательность кодируется с помощью нейронной сети в представление фиксированной длины, а затем вторая нейронная сеть декодирует это представление в новую последовательность (рис. 1) [1]. Это похоже на то, как если бы человеку дали текст, попросили его запомнить, а затем отобрали и попросили написать перевод на другой язык. Второй класс использует модель селективного внимания, когда декодировщик может «подсматривать» в исходную последовательность при работе (рис.2) [2].
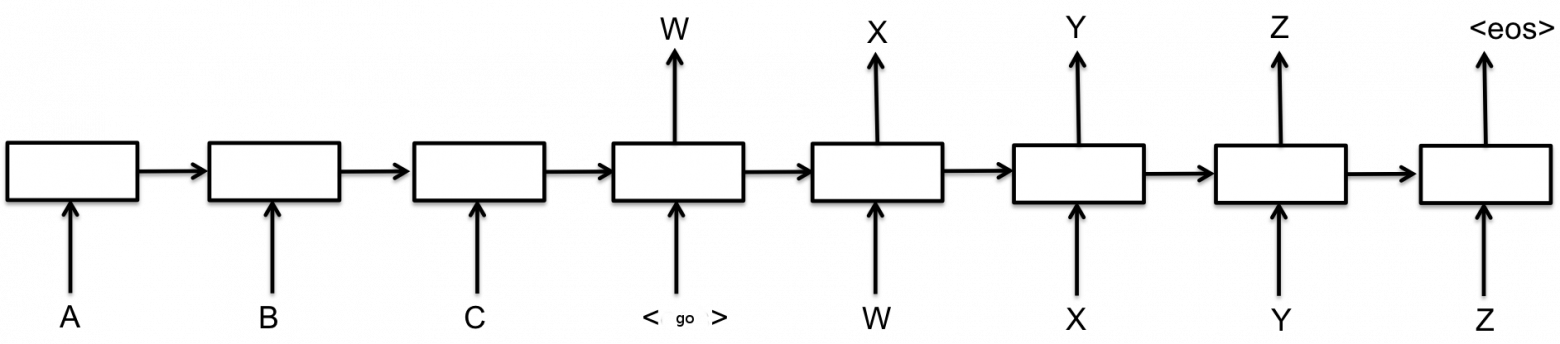
Рисунок 1. Базовая модель обучения нейронной модели последовательность-в-последовательность. Слева (до символа ) исходная последовательность, справа — генерируемая. Изображение с сайта tensorflow.org
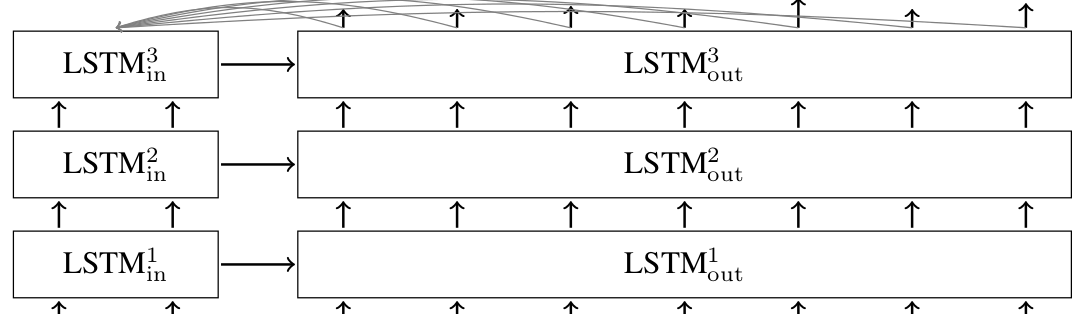
Рисунок 2. Базовая модель обучения нейронной модели последовательность-в-последовательность. Изображение с сайта tensorflow.org
Чат-бот является частным случаем задачи обучения последовательность-в-последовательность (вопрос на входе, ответ на выходе). Ранее мы писали про нашу реализацию чат-бота таким методом. Несколько позже появилась статья сотрудников Google [3] на ту же тему, но с использованием более продвинутой (как мы полагали) модели, аналогичной показанной на рис. 1.
Модель от Google использует LSTM ячейки, в то время как я, конструируя чат-бот применил обычную рекуррентную сеть, прикрутив только одну модификацию, для лучшей работы. Показанные в статье [3] диалоги выглядят впечатляющие и более интересными, чем удалось получить мне (Кроме того, идет речь о том, что обученный на диалогах службы поддержки пользователей, чат бот мог оказывать осмысленную помощь). Но чат-бот от Google обучен на много большей коллекции данных, чем мой старый образец.
Модифицировав стандартный пример из комплекта TensorFlow предназначенный для машинного перевода, я загрузил данные из коллекции диалогов, использованной для обучения моего чат-бота (там всего 3000 примеров, в отличии сотни тысяч на которых обучался чат-бот Google). в уроке от Google утверждается, что в примере реализована модель из [2], плюс выборочный softmax [4], то есть практически применены все самые современные результаты из этой области.
Мой чат-бот, как описано ранее, использует в качестве кодировщика сверточную сеть (один слой 16 фильтрами размером в 2 и 3 слова + слой максимального объединения), а декодировщик — простая рекуррентная сеть Элмана. Ни то, ни другое по данным других исследователей не показало себя хорошо задачах sequence-to-sequence learning. Поэтому к системе применена одна модификация, которую я придумал сам больше года назад для другой задачи (генерации отзывов). Вместо одной сверточной сети — кодировщика, используется две сверточных сети — одна для кодирования исходного текста, а другая — для кодирования нового, только что сгенерированного. Выходы последних слоев объединения соединяются в следующем слое попарно (т. е. один нейрон получает один вход от нейрона первой сети и один вход от нейрона второй). Идея была в том, что когда будет сгенерировано что-то, соответствующее входному сигналу, этот сигнал подавится за счет второй сети, и система продолжит генерацию оставшейся части текста. Насколько я знаю, такое решение нигде не описано, и точно не было описано на момент реализации. Работало оно как мне тогда казалось плохо (хотя чат бот получался лучше, чем с одним кодировщиком), и я забросил его когда увидел статью про механизм селективного внимания, так решил, что использованное там решение более «крутое» и нечего изобретать всякую ерунду.
Вот теперь результаты:
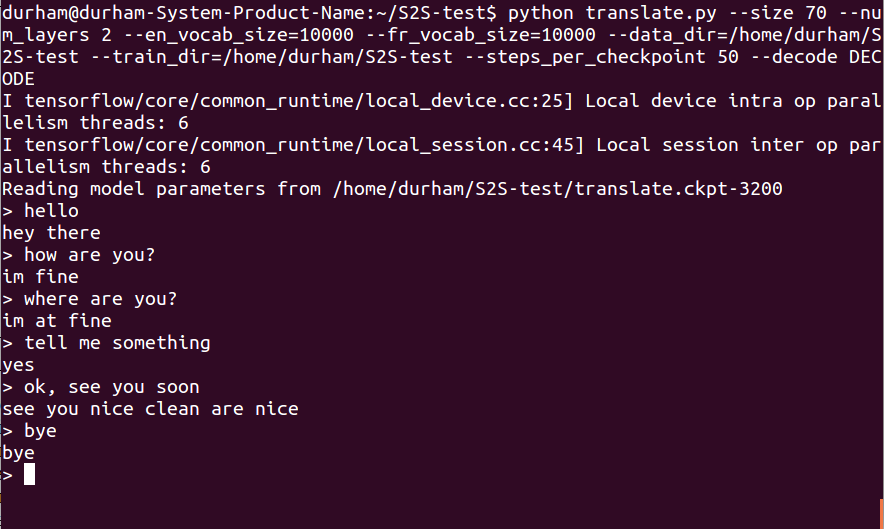
Рисунок 3. Диалог с чат-ботом, использующим модель seq2seq.embedding_attention_seq2seq из комплекта TensorFlow
Диалоги с чат-ботами, с примерным переводом:
Обе модели работают, но великого улучшения получить, увы, не удалось. Более того, диалог справа выглядит, на мой субъективный взгляд диалог справа выглядит даже интереснее и правильнее. Вероятнее всего, дело в объемах данных. Модель из рис. 1. обладает значительной репрезентативной силой, но ей надо много данных, чтобы начать выдавать осмысленные результаты (ситуация, которую мы обсуждали в предыдущей статье). Моя модель для чат-бота возможно не такая хорошая, но зато может выдавать осмысленные результаты в условиях дефицита данных. Что позволяет, например, создавать модели общения разных людей на ограниченных выборках диалогов. Например, если из моего набора в 3000 пар фраз взять фразы ответы только одного из собеседников, получается следующее:
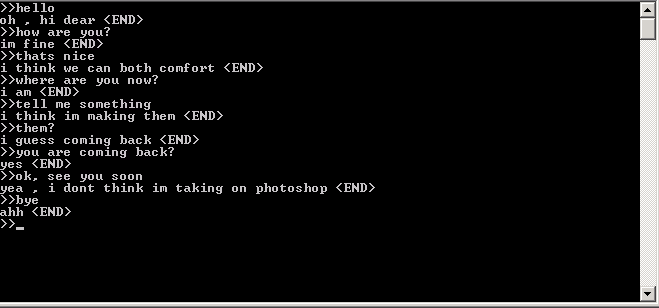
Рисунок 4.
У меня (опять таки субъективно) возникает ощущение более позитивного, и дружественно настроенного общения. А у вас? От модели из комплекта TensorFlow мне не удалось добиться лучшего диалога показано в таблице, хотя я проверил только пять разных конфигураций, возможно человек с большим опытом работы с ней может сделать лучше.
Реконструкция фраз из набора слов
Реконструкция фраз из набора слов — это синтетическое задание, которое я использую здесь вместо практической задачи, которую поставил перед нами один из заказчиков. Заказчик был против публикации самой как самой задачи, так и примеров со своими данными, поэтому для этой статьи я придумал другую задачу, похожую по форме.
В качестве фраз я использовал запросы пользователей к поисковым системам, потому что они являются хорошим источником коротких осмысленных фраз и кроме того они были под рукой в достаточном количестве. Суть задачи следующая. Допустим у нас есть запрос «Сделать диплом на заказ» и его испорченная версия «диплом сделать заказ». Надо из испорченной версии снова сделать осмысленный запрос, при этом сохранив смысл оригинала. То есть «сделать окна на заказ» будет считаться неверным результатом. Испорченные версии генерировались автоматически путем переставления слов, изменения рода, числа, падежа, и удаления всех слов длиной короче четырех букв. Всего таким образом было изготовлено 120 000 обучающих примеров, из которых 1000 была отложена для тестирования. Задача кажется проще, чем проблема машинного перевода, но одновременно имеет с ней кое что общее.
Для решения оригинальной задачи пришлось разработать специальную модель, базирующуюся на вышеописанной в разделе про чат-бот идее. Поскольку качество для нужд заказчика было недостаточным, то я добавил еще средство для работы с очень большими словарями, чем-то напоминающее по идее выборочный softmax. Про выборочный softmax я кстати узнал впервые четыре дня назад, из урока по TensorFlow. До этого я статью про него просмотрел, как оказалось, к счастью, ибо результаты… но о результатах чуть позже. Модель также снабжена средством для контроля степени «фантазии» нейросети и средством, не то, что учета морфологии, а скорее средством обхода проблемы учета морфологии, при котором каждая словоформа также представлена отдельным вектором, как и в системах без учета морфологии, но при этом не возникает связанных с этим проблем. Однако решение это лишено нормального механизма селективного внимания, имеет примитивный механизм представления исходной последовательности и не использует LSTM или GRU модули. Благодаря чему скорость его работы в моей реализации оказывается достаточно адекватной.
Итак результаты:
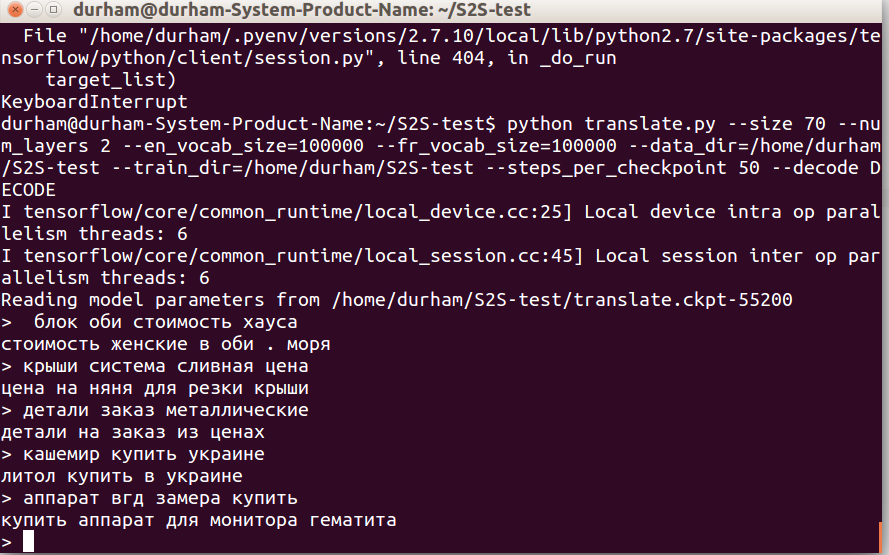
Рисунок 5.
Вот что сделала модель из комплекта TensorFlow. Генерируемые поисковые запросы имеют некоторое отношение к исходным ключевым словам, и, в целом, сделаны по правилам русского языка. А со смыслом беда. Одна «няня для резки крыши» чего стоит. С другой стороны, что меня восхищает в этих конструкциях, это понимание моделью принципов языка, и креативный подход. Например, «аппарат для монитора гематита» звучит правдоподобно и как-то даже по медицински, если не знать, что гематит это «железорудный минерал Fe2O3» и аппарата для монитора гематита не бывает. Но для целей практического применения такое не годится. Из 100 проверенных тестовых примеров, правильного не было ни одного.
Моя модель создала следующие варианты:

Рисунок 6.
Здесь original — испорченный вариант, generated — сгенерированный, human — исходный поисковый запрос. Из 100 проверенных примеров, правильных 72%. Улучшения от модели из комплекта TensorFlow никакого не получилось.
Скорость работы и широта функционала
По этим параметрам пакет от Google конечно превосходит мою библиотеку на порядок. У него есть и сверточные сети для анализа изображений со всеми современными методами, LSTM и GRU, автоматическое дифференцирование, и вообще возможность достаточно легко создавать всевозможные модели, а не только нейронные сети. Все сделано достаточно интуитивно понятно, и отлично документировано. Можно смело рекомендовать, особенно для начинающих заниматься машинным обучением, конечно если у вас есть Linux или MacOs (возможно, исходный код можно скомпилировать на Windows c помощью cygwin или mingw или еще как-нибудь, но официально это не поддерживается).
По скорости, я пока не делал точных замеров, но ощущение такое, что на CPU модели TensorFlow выполняются раза в два-три быстрее моих реализаций, при примерно одинаковом количестве параметров (можно было ожидать и большей разницы в производительности). И потребляют значительно меньше памяти. А уж GPU версия быстрее CPU реализации раз в десять (опять таки это общее впечатление, пока без точных замеров). Все это закономерно, ведь у Google много ресурсов и программистов занимается оптимизацией кода (на странице about TensorFlow в списке разработчиков 40 имен), а у меня возможности такой нет — работает и ладно.
С другой стороны моя библиотека занимает мало места, работает на Windows и под Linux при использовании mono. В определенных ситуациях это может быть плюсом.
Что касается результатов, конечно, их надо интерпретировать с большой осторожностью. Они относятся к определенным частным случаям, и кроме того это результаты конкретных моделей внутри целой библиотеки, функционал которой гораздо шире. Поэтому, если перенести мои модели на TensorFlow, то результаты должны быть такими же, а выполнятся все будет гораздо быстрее. В этом смысле знание правильной архитектуры нейросети важнее знания конкретного стека технологий.
Правда остаётся один философский вопрос. Если бы я имел изначально доступ к TensorFlow или работал с подобным готовым средством, удалось ли бы сделать те же модели и получить те же результаты? Помогает ли программирование системы с «нуля» понять глубже основы нейронных сетей или является лишней тратой времени? Являются ли ограничения в производительности стимулом для разработки новых моделей или досадной помехой?
Заключение
Выводы предлагаю каждому сделать самостоятельно. Очевидных ответов на свои вопросы из этих опытов я пока не получил, проблема изобретения/не изобретения велосипедов осталась, но информация кажется достаточно поучительной.
Список литературы
1. Sutskever, Ilya, Oriol Vinyals, and Quoc VV Le. «Sequence to sequence learning with neural networks.» Advances in neural information processing systems. 2014.
2. Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. «Neural machine translation by jointly learning to align and translate.» arXiv preprint arXiv:1409.0473 (2014).
3. Vinyals, Oriol, and Quoc Le. «A neural conversational model.» arXiv preprint arXiv:1506.05869 (2015).
4. Jean, Sébastien, et al. «On using very large target vocabulary for neural machine translation.» arXiv preprint arXiv:1412.2007 (2014).
PS
Все упомянутые в статье торговые марки являются собственностью их правообладателей.
Для начала нужно пояснить, что у нас имеется собственная нейросетевая библиотека. Конечно далеко не такая обширная и амбициозная, но предназначенная для решения определенных задач обработки текстов. В свое время я решил пойти путем написания собственного решения, вместо использования готового. По разным соображениям, в том числе кроссплатформенности, компактности, удобства интеграции в остальной код, эстетического нежелания иметь десятки зависимостей от вообще-то ненужных средств разных сторонних авторов. В итоге получилось некое средство, написанное на языке F#, удобное, занимающее порядка 2mb места, и делающее то, чего от него требовалось. С другой стороны довольно медлительное в плане скорости, не поддерживающие вычисления на GPU, урезанное в функционале, и оставляющее сомнение в своем соответствии современным реалиями.
Вопрос изобретать велосипед или использовать готовый он, в общем то, вечный. И червь сомнения все время грыз, что поддержание собственного средства вещь неоправданная, затратная по ресурсам и ограничивающая в возможностях. С периодическими обострениями приходили идеи перейти на использование, например Theano или Torch, как делают все нормальные люди. Но руки не доходили. А с выходом TensorFlow возникла еще одна дополнительная мотивация.
Вот в таком контексте я начал разбираться с этой системой.
Короткие замечания о процессе установки
TensorFlow установить пожалуй проще, чем ряд других современных нейросетвых библиотек. Если вам повезет, то дело может ограничится одной строчкой, введённой в строке терминала Linux. Да, Windows традиционно не поддерживается, но такая мелочь конечно не остановит настоящего разработчика.
Нам не повезло, на Ubuntu 11 TensorFlow устанавливаться отказалась. Но после апгрейда до 14.04 и некоторых танцев с бубном что-то все же заработало. По крайней мере, удалось выполнить фрагмент кода из раздела getting started. Поэтому, можно смело написать, что установка TensorFlow проста и не вызывает сложностей, особенно если у вас свежий дистрибутив, и версия python 2 не ниже 2.7.9. Для Linux это нормально, если сложный программный пакет не устанавливается сразу (ну может быть, не нормально, но это обычная ситуация, так часто бывает).
Проверка работы.
Здесь надо сказать следующее. Все нижеизложенное следует рассматривать как частный пример из личного опыта, сделанный в целях удовлетворения персонального любопытства в достаточно узкой области. Автор не претендует на то, что полученные выводы имеют глобальное значение, или вообще какое-то значение. Рассуждения о недостатках в результатах следует относить не к самой системе TensorFlow (которая в основном работает отлично и главное быстро), а к конкретным моделям и обучающим примерам.
Чат-бот
Вводные уроки про распознавание цифр из набора MNIST я оставил на будущее, и открыл сразу раздел, посвящённый sequence-to-sequence learning. Чтобы было понятно, о чем идет речь, опишу суть дела немного подробнее.
Задачей sequence-to-sequence learning в общем виде является генерация новой последовательностей символов на основании входной последовательности символов. В нашем частном случае символами являются слова. Наиболее известным приложением этой задачи является, вероятно, машинный перевод — когда на вход модели подаётся предложение на одном языке, а на выходе мы получаем перевод на другой язык. Как показано на рисунках из вводных уроков, есть два основных класса таких моделей. Первый использует вариант кодировщик-декодировщик. Исходная последовательность кодируется с помощью нейронной сети в представление фиксированной длины, а затем вторая нейронная сеть декодирует это представление в новую последовательность (рис. 1) [1]. Это похоже на то, как если бы человеку дали текст, попросили его запомнить, а затем отобрали и попросили написать перевод на другой язык. Второй класс использует модель селективного внимания, когда декодировщик может «подсматривать» в исходную последовательность при работе (рис.2) [2].

Рисунок 1. Базовая модель обучения нейронной модели последовательность-в-последовательность. Слева (до символа ) исходная последовательность, справа — генерируемая. Изображение с сайта tensorflow.org

Рисунок 2. Базовая модель обучения нейронной модели последовательность-в-последовательность. Изображение с сайта tensorflow.org
Чат-бот является частным случаем задачи обучения последовательность-в-последовательность (вопрос на входе, ответ на выходе). Ранее мы писали про нашу реализацию чат-бота таким методом. Несколько позже появилась статья сотрудников Google [3] на ту же тему, но с использованием более продвинутой (как мы полагали) модели, аналогичной показанной на рис. 1.
Модель от Google использует LSTM ячейки, в то время как я, конструируя чат-бот применил обычную рекуррентную сеть, прикрутив только одну модификацию, для лучшей работы. Показанные в статье [3] диалоги выглядят впечатляющие и более интересными, чем удалось получить мне (Кроме того, идет речь о том, что обученный на диалогах службы поддержки пользователей, чат бот мог оказывать осмысленную помощь). Но чат-бот от Google обучен на много большей коллекции данных, чем мой старый образец.
Модифицировав стандартный пример из комплекта TensorFlow предназначенный для машинного перевода, я загрузил данные из коллекции диалогов, использованной для обучения моего чат-бота (там всего 3000 примеров, в отличии сотни тысяч на которых обучался чат-бот Google). в уроке от Google утверждается, что в примере реализована модель из [2], плюс выборочный softmax [4], то есть практически применены все самые современные результаты из этой области.
Мой чат-бот, как описано ранее, использует в качестве кодировщика сверточную сеть (один слой 16 фильтрами размером в 2 и 3 слова + слой максимального объединения), а декодировщик — простая рекуррентная сеть Элмана. Ни то, ни другое по данным других исследователей не показало себя хорошо задачах sequence-to-sequence learning. Поэтому к системе применена одна модификация, которую я придумал сам больше года назад для другой задачи (генерации отзывов). Вместо одной сверточной сети — кодировщика, используется две сверточных сети — одна для кодирования исходного текста, а другая — для кодирования нового, только что сгенерированного. Выходы последних слоев объединения соединяются в следующем слое попарно (т. е. один нейрон получает один вход от нейрона первой сети и один вход от нейрона второй). Идея была в том, что когда будет сгенерировано что-то, соответствующее входному сигналу, этот сигнал подавится за счет второй сети, и система продолжит генерацию оставшейся части текста. Насколько я знаю, такое решение нигде не описано, и точно не было описано на момент реализации. Работало оно как мне тогда казалось плохо (хотя чат бот получался лучше, чем с одним кодировщиком), и я забросил его когда увидел статью про механизм селективного внимания, так решил, что использованное там решение более «крутое» и нечего изобретать всякую ерунду.
Вот теперь результаты:

Рисунок 3. Диалог с чат-ботом, использующим модель seq2seq.embedding_attention_seq2seq из комплекта TensorFlow
Диалоги с чат-ботами, с примерным переводом:
| Модель из комплекта TensorFlow | Моя модель |
| Ч:Hello (привет) К:hey there (привет) Ч:how are you? (как дела) К:i'm fine (отлично) Ч:where are you? (где ты находишься) K:i'm at fine (я нахожусь в отлично) Ч:Tell me something (скажи что-нибудь) К:yes (да) Ч:ok, see you soon (до скорой встречи) К:see you nice clean are nice (увижу тебя хорошо чисто это хорошо) Ч:bye (пока) К:bye (пока) |
Ч:Hello (привет) К:hi (привет) Ч:how are you? (как дела) К:i feel strange (чувствую себя странно) Ч:where are you? (где ты находишься) К:I'm at home now (я нахожусь дома) Ч:Tell me something (скажи что-нибудь) К: world (мир) Ч:ok, see you soon (до скорой встречи) K: I'm not sure… (не уверена) Ч: bye (пока) K: ok (окей) |
Обе модели работают, но великого улучшения получить, увы, не удалось. Более того, диалог справа выглядит, на мой субъективный взгляд диалог справа выглядит даже интереснее и правильнее. Вероятнее всего, дело в объемах данных. Модель из рис. 1. обладает значительной репрезентативной силой, но ей надо много данных, чтобы начать выдавать осмысленные результаты (ситуация, которую мы обсуждали в предыдущей статье). Моя модель для чат-бота возможно не такая хорошая, но зато может выдавать осмысленные результаты в условиях дефицита данных. Что позволяет, например, создавать модели общения разных людей на ограниченных выборках диалогов. Например, если из моего набора в 3000 пар фраз взять фразы ответы только одного из собеседников, получается следующее:

Рисунок 4.
У меня (опять таки субъективно) возникает ощущение более позитивного, и дружественно настроенного общения. А у вас? От модели из комплекта TensorFlow мне не удалось добиться лучшего диалога показано в таблице, хотя я проверил только пять разных конфигураций, возможно человек с большим опытом работы с ней может сделать лучше.
Реконструкция фраз из набора слов
Реконструкция фраз из набора слов — это синтетическое задание, которое я использую здесь вместо практической задачи, которую поставил перед нами один из заказчиков. Заказчик был против публикации самой как самой задачи, так и примеров со своими данными, поэтому для этой статьи я придумал другую задачу, похожую по форме.
В качестве фраз я использовал запросы пользователей к поисковым системам, потому что они являются хорошим источником коротких осмысленных фраз и кроме того они были под рукой в достаточном количестве. Суть задачи следующая. Допустим у нас есть запрос «Сделать диплом на заказ» и его испорченная версия «диплом сделать заказ». Надо из испорченной версии снова сделать осмысленный запрос, при этом сохранив смысл оригинала. То есть «сделать окна на заказ» будет считаться неверным результатом. Испорченные версии генерировались автоматически путем переставления слов, изменения рода, числа, падежа, и удаления всех слов длиной короче четырех букв. Всего таким образом было изготовлено 120 000 обучающих примеров, из которых 1000 была отложена для тестирования. Задача кажется проще, чем проблема машинного перевода, но одновременно имеет с ней кое что общее.
Для решения оригинальной задачи пришлось разработать специальную модель, базирующуюся на вышеописанной в разделе про чат-бот идее. Поскольку качество для нужд заказчика было недостаточным, то я добавил еще средство для работы с очень большими словарями, чем-то напоминающее по идее выборочный softmax. Про выборочный softmax я кстати узнал впервые четыре дня назад, из урока по TensorFlow. До этого я статью про него просмотрел, как оказалось, к счастью, ибо результаты… но о результатах чуть позже. Модель также снабжена средством для контроля степени «фантазии» нейросети и средством, не то, что учета морфологии, а скорее средством обхода проблемы учета морфологии, при котором каждая словоформа также представлена отдельным вектором, как и в системах без учета морфологии, но при этом не возникает связанных с этим проблем. Однако решение это лишено нормального механизма селективного внимания, имеет примитивный механизм представления исходной последовательности и не использует LSTM или GRU модули. Благодаря чему скорость его работы в моей реализации оказывается достаточно адекватной.
Итак результаты:

Рисунок 5.
Вот что сделала модель из комплекта TensorFlow. Генерируемые поисковые запросы имеют некоторое отношение к исходным ключевым словам, и, в целом, сделаны по правилам русского языка. А со смыслом беда. Одна «няня для резки крыши» чего стоит. С другой стороны, что меня восхищает в этих конструкциях, это понимание моделью принципов языка, и креативный подход. Например, «аппарат для монитора гематита» звучит правдоподобно и как-то даже по медицински, если не знать, что гематит это «железорудный минерал Fe2O3» и аппарата для монитора гематита не бывает. Но для целей практического применения такое не годится. Из 100 проверенных тестовых примеров, правильного не было ни одного.
Моя модель создала следующие варианты:

Рисунок 6.
Здесь original — испорченный вариант, generated — сгенерированный, human — исходный поисковый запрос. Из 100 проверенных примеров, правильных 72%. Улучшения от модели из комплекта TensorFlow никакого не получилось.
Скорость работы и широта функционала
По этим параметрам пакет от Google конечно превосходит мою библиотеку на порядок. У него есть и сверточные сети для анализа изображений со всеми современными методами, LSTM и GRU, автоматическое дифференцирование, и вообще возможность достаточно легко создавать всевозможные модели, а не только нейронные сети. Все сделано достаточно интуитивно понятно, и отлично документировано. Можно смело рекомендовать, особенно для начинающих заниматься машинным обучением, конечно если у вас есть Linux или MacOs (возможно, исходный код можно скомпилировать на Windows c помощью cygwin или mingw или еще как-нибудь, но официально это не поддерживается).
По скорости, я пока не делал точных замеров, но ощущение такое, что на CPU модели TensorFlow выполняются раза в два-три быстрее моих реализаций, при примерно одинаковом количестве параметров (можно было ожидать и большей разницы в производительности). И потребляют значительно меньше памяти. А уж GPU версия быстрее CPU реализации раз в десять (опять таки это общее впечатление, пока без точных замеров). Все это закономерно, ведь у Google много ресурсов и программистов занимается оптимизацией кода (на странице about TensorFlow в списке разработчиков 40 имен), а у меня возможности такой нет — работает и ладно.
С другой стороны моя библиотека занимает мало места, работает на Windows и под Linux при использовании mono. В определенных ситуациях это может быть плюсом.
Что касается результатов, конечно, их надо интерпретировать с большой осторожностью. Они относятся к определенным частным случаям, и кроме того это результаты конкретных моделей внутри целой библиотеки, функционал которой гораздо шире. Поэтому, если перенести мои модели на TensorFlow, то результаты должны быть такими же, а выполнятся все будет гораздо быстрее. В этом смысле знание правильной архитектуры нейросети важнее знания конкретного стека технологий.
Правда остаётся один философский вопрос. Если бы я имел изначально доступ к TensorFlow или работал с подобным готовым средством, удалось ли бы сделать те же модели и получить те же результаты? Помогает ли программирование системы с «нуля» понять глубже основы нейронных сетей или является лишней тратой времени? Являются ли ограничения в производительности стимулом для разработки новых моделей или досадной помехой?
Заключение
Выводы предлагаю каждому сделать самостоятельно. Очевидных ответов на свои вопросы из этих опытов я пока не получил, проблема изобретения/не изобретения велосипедов осталась, но информация кажется достаточно поучительной.
Список литературы
1. Sutskever, Ilya, Oriol Vinyals, and Quoc VV Le. «Sequence to sequence learning with neural networks.» Advances in neural information processing systems. 2014.
2. Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. «Neural machine translation by jointly learning to align and translate.» arXiv preprint arXiv:1409.0473 (2014).
3. Vinyals, Oriol, and Quoc Le. «A neural conversational model.» arXiv preprint arXiv:1506.05869 (2015).
4. Jean, Sébastien, et al. «On using very large target vocabulary for neural machine translation.» arXiv preprint arXiv:1412.2007 (2014).
PS
Все упомянутые в статье торговые марки являются собственностью их правообладателей.
