Самая ужасная страшилка для желающих разместить написанный компьютером контент на своих сайтах — санкции поисковых систем. Нас тоже в свое время пугали тем, что сайт с неуникальными и /или сгенерированными текстами, будет плохо индексироваться или что он вообще попадет под бан. При этом точных требований к текстам никто нам сказать не смог. Вообще тема уникального контента и его роли в продвижении сайтов больше похожа на оккультные знания. Каждый следующий «специалист» обещает на своей странице открыть страшную правду, но правда так и не открывается, а суть многих дискуссий на форумах сводиться к тому, что, скажем, Яндекс, распознает сгенерированный контент с помощью магии. Не такими словами, но смысл в этом.
Поскольку недавно к нам обратились заказчики с задачей создать описаний для товаров на сайте, мы решили подробнее изучить этот вопрос. Какие алгоритмы существуют для определения автоматически написанных текстов, какие свойства должен иметь текст чтобы не быть распознанным как веб-спам, и какие средства могут его генерировать?
В последние годы уникальный текст (и вообще текст) стал распространенным инструментом, который SEO-специалисты рекомендуют для продвижения сайтов в поисковых системах. Совсем в последние годы, владельцы сайтов поняли, что заказывать написание текстов людям достаточно накладно, ведь цены на авторские тексты во все времена находились в диапазоне $1-$3 за 1000 знаков. Понятно, что владельцу интернет-магазина даже со скромным ассортиментом в 3-4 тыс наименований надо заплатить за тексты от 300 000 рублей, причем трата это не разовая, поскольку ассортимент имеет тенденцию обновляться. Естественно, на страницах сайтов появились автоматически сгенерированные описания товаров.
Как на самом деле поисковая система распознает автоматически сгенерированный контент...
… этого мы конечно не знаем. Но, общий принцип метода тайны не составляет, и обратившись к первоисточникам можно сделать некоторые обоснованные выводы о границах возможного. Начнем с того, что на сайте научных публикаций Яндекса имеется статья с многообещающим названием «Поиск неестественных текстов» [1]. Там сказано примерно следующие “в неестественном тексте должно быть нарушено распределение пар [слов]… количество редких, нехарактерных для языка пар должно быть завышено по сравнению со стандартом, а количество частых пар – занижено”. Перед нами, таким образом, первая группа методов То есть, речь так или иначе идет о сравнении статистических параметров данного текста с параметрами «естественных» текстов. Помимо распределения пар, могут использоваться частоты n-грамм большего размера. В более современных работах [2] применяются также частоты n-грамм не самих слов, а частей речи, когда сначала каждому слову определяется часть речи (СУЩ-ПРИЛ-СУЩ-ГЛАГ), а потом подсчитывают частоты полученных n-грамм, и так далее.
Ясно, что самые примитивные описания, сгенерированные с помощью подстановки параметров товаров в шаблонный текст избегают этого фильтра по причине того, что исходный шаблон заготовлен человеком и, соответственно, имеет естественные характеристики. Это конечно, при условии, что в шаблоне приглажены соответствия родов и падежей, чтобы не получалось ничего вроде «Купить стиральная машина за 10399 рубля».
Генераторы на основе современных моделей языка, такие как нейросетевые модели языка, также весьма вероятно избегают этого фильтра, так как общее правило гласит «чтобы поймать текст сгенерированный некоторой моделью языка, надо использовать более совершенную модель языка». А более совершенная модель языка может быть в дефиците, и к тому же требовать огромных вычислительных затрат, так что ее использование для определения автоматических текстов в масштабах интернета просто будет нерациональным
Но генераторы на основе модели языка, примененные напрямую, генерируют тексты, лишенные смысла. Например, такие «Надежность водонагревателей «аристон» побеждает рейтинг бойлеров».
Поскольку владельцы интернет-магазинов как правило не хотят, чтобы водонагреватели побеждали рейтинги бойлеров, они предпочитают простые шаблонные тексты. Но и здесь есть некоторая потенциальная трудность.
Шаблонный текст не отличим от естественного до тех пор, пока он имеется в единственном экземпляре. Размноженные же, они становятся предметом второго класса методов определения машинных текстов. Суть метода в том, что все тексты, написанные на базе шаблона похожи друг на друга за исключением частей, куда вставляются параметры конкретного товара. Получается то, что называется в английской литературе ”near dublicates” — почти дубликаты. Поисковые системы умеют их определять [3], используя всем известный метод шинглов и его усовершенствованные варианты. Если же использовать дополнительно синонимайзер, то увеличится число маловероятных языковых конструкций и текст станет опознаваемым для первой группы алгоритмов [1]. Кроме того, существуют алгоритмы, специфически направленные против синонимайзеров — они убирают из текста все слова, для которых имеются синонимы в словаре, и сравнивают тексты по оставшимся словам [4].
Таким образом, алгоритмы распознавания машинно-генерируемых текстов являясь с одной стороны достаточно сложными, все же не содержат в себе никакой магии и сверхинтеллекта. При желании можно их воспроизвести для целей тестирования текстов, что затратно по времени, но в общем не сложно.
Философское отступление
Мы столкнулись с тем, что есть люди, считающие машинные тексты злом, засоряющим интернет и предназначенным для обмана пользователей. Но мы считаем, что это вряд ли правомочно относить к осмысленным текстам, описывающие конкретные товары по параметрам. Ведь эти тексты содержат фактически верную информацию о товаре. Размещая на странице такой текст мы обозначаем ее содержимое для поисковой системы, поэтому это не является обманом поисковых систем или покупателей.
Практика: Насколько хороши машинные тексты?
Принимая во внимание вышеизложенное, мы остановились на гибридном методе генерации текстов. В нем, сначала базовый каркас текста генерируется с помощью заданной вручную грамматики (подробнее в предыдущей статье), а затем сверху применяется нейросетевой анализатор, натренированный на определение мест, где можно вставить или удалить определенные классы слов без потери смысла. Необходимость создания порождающей грамматики вручную конечно удорожает стоимость решения, но все равно она остается на порядок меньшей, чем заказ текстов копирайтеру. Теперь собственно по качеству.
Читабельность:
«Смеситель для раковины Grohe Allure 19386000 из новой коллекции Allure, стоимостью всего 5800 рублей. Скрытый монтаж обеспечивает повышенное удобство эксплуатации и, конечно, установки. Cистема GROHE SilkMove позволяет обеспечить исключительно легкое движение рычага. Специальное покрытие, произведенное по технологии StarLight создает долговечность и сохраняет хороший вид изделия на протяжении долгих лет. Вертикальный монтаж с двумя монтажным отверстиями весьма удобен и не должен вызвать трудностей. Величина выноса излива здесь равна 220 мм. Больший размер выноса приводит к тому, что использовать изделие становится намного проще. Все изделие в общем имеет вес равный 1,955 кг. Минимальное давление для данной модели равняется 1 бар. В подключении к электричеству нет необходимости. Бесплатная доставка и надежное, проверенное годами, качество широко известного всем немецкого бренда — главные причины купить смеситель Grohe Allure 19386000».
Конечно, это не великое литературное произведение, но явных огрехов нет. Определить, что текст сгенерирован автоматически трудно, даже для человека.
Уникальность:
a) Глобальная уникальность. Суть глобальной уникальности в том, чтобы текст был уникален относительно всех других текстов, имеющихся в интернете на момент публикации.
Для проверки глобальной уникальности мы использовали известный сервис text.ru (для целей объективности, в этой статье мы приводим результаты анализа со сторонних сервисов, а не данные наших алгоритмов).
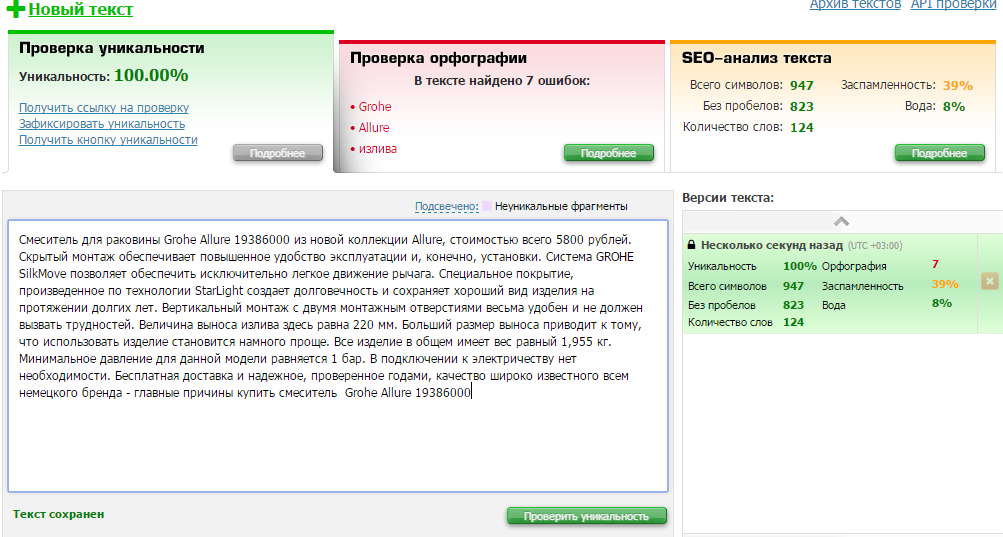
Как видно, с глобальной уникальностью нет никаких проблем. Сервис жалуется на орфографию, но при рассмотрении ошибки связаны с тем, употреблением слов ”Allure”, “StarLight” и других специфических терминов, которые сервис не знает. Примечание: это данные до размещения текстов на сайте заказчика. Сейчас, естественно, эти тексты можно обнаружить там.
б) Локальная уникальность. Как мы уже говорили, слишком похожие тексты могут быть сочтены поисковой системой дубликатами друг друга, что может выдать их искусственное происхождение. Для этого мы использовали сервис, размещенный на сайте backlinkmanager (другие реализации сравнения с помощью алгоритма шинглов дают похожие результаты)
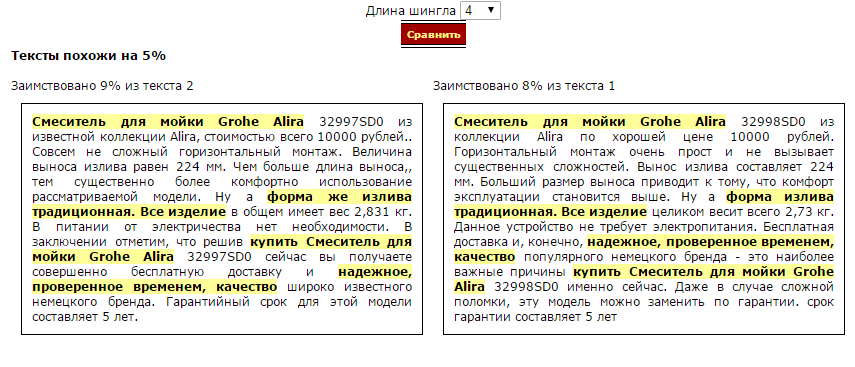
Два текста про очень похожие модели с совпадающими параметрами сходны всего на 5%, причем в значительной степени сходство обусловлено упоминанием названия товара «Смеситель для мойки Grohe Alira”. Будем считать это хорошим результатом, ведь есть не так много способов по разному описать один и тот же набор параметров товара.
Индексация поисковыми системами
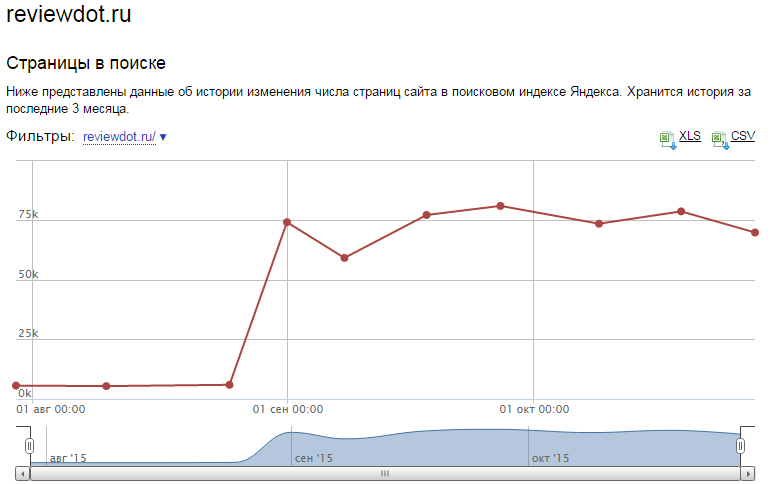
Индексация машинно-генерируемых текстов была проверена нами ранее на примере сайта reviewdot.ru. Страницы данного сайта не имеют уникального контента. Поэтому вначале этот сайт никак не хотел попадать в индекс Яндекса (из более чем ста тысяч страниц в индексе оказались около 1300 штук). Мы с этим упорно боролись, разместив сначала шаблонные тексты (число страниц в индексе выросло до 5000), потом использовав более сложные алгоритмы генерации, подобные рассмотренному выше. На сегодняшний день в индексе Яндекса около 70 000 страниц. Хотя что конкретно повлияло на ситуацию — наши усилия или изменения в алгоритмах Яндекса, нам неизвестно. Тем не менее, факт остается фактом — страницы, содержащие автоматически сгенерированные тексты успешно попадают в индекс поисковых систем. Несмотря на все опасения SEO специалистов,монстры не явились, что сожрать нас сайт не попал под санкции поисковых систем, хотя к тому имелись теоретические основания.
Причем в индексе не только страницы, но и конкретно автоматически сгенерированные тексты, в чем можно убедиться, введя фрагменты этих текстов в поисковую строку:
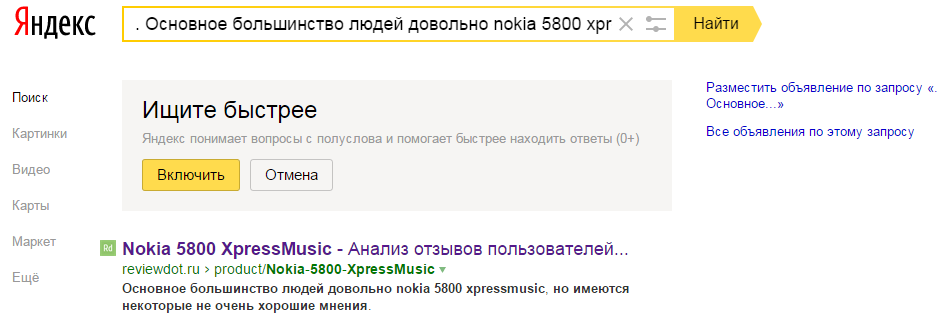
А значит, как минимум, машинно-генерируемый контент можно использовать для того, чтобы страница стала релевантной определенным запросам.
Конечно, надо заметить, что мы размещали не бессмысленные тексты, а тексты содержащие полезную пользователю информацию (reviewdot анализирует отзывы на товары, оставленные на разных сайтах и представляет пользователю краткую аннотацию об отмеченных плюсах и минусах).
Мы также провели сравнение времени нахождения пользователя на страницах с текстом.В результате этого обнаружилось, что тексты положительно сказались и на таком параметре, как время нахождения пользователя на странице. Видимо причина этого в том, что если человек видит на странице связный текст, содержащий нужные ему сведения, он начинает его читать, а чтение текста занимает некоторое время.
Заключительные замечания
На сегодняшний день тексты сданы заказчику и размещены на сайте (интернет-магазин сантехники g-online.ru), желающие могут ознакомится и с ними тоже. Пока что мы можем сделать выводы, что сгенерированные тексты могут быть сделаны достаточно сходными с «естественными», и при правильном подходе к делу они не влияют на сайт отрицательно. Сгенерированные тексты могут улучшить индексацию страниц сайта, и сделать страницы релевантными определенным запросам. Можно запрограммировать генератор на упоминание заданных ключевых слов или фраз в точно заданных процентных соотношениях от размера текста.
Литература
1. Е.А. Гречников, Г.Г. Гусев, А.А. Кустарев, А.М. Райгородский. Поиск неестественных текстов//Труды 11й Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» — RCDL’2009, Петрозаводск, Россия, 2009.
2. Aharoni, Roee, Moshe Koppel, and Yoav Goldberg. Automatic Detection of Machine Translated Text and Translation Quality Estimation//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 289–295, Baltimore, Maryland, USA, June 23-25 2014.
3. G. S. Manku, A. Jain, and A. Das Sarma. Detecting Near-duplicates for Web Crawling. In Proceedings of the 16th WWW Conference, May 2007
4. Zhang, Qing, David Y. Wang, and Geoffrey M. Voelker. «Dspin: Detecting automatically spun content on the web.» NDSS, 2014.
Поскольку недавно к нам обратились заказчики с задачей создать описаний для товаров на сайте, мы решили подробнее изучить этот вопрос. Какие алгоритмы существуют для определения автоматически написанных текстов, какие свойства должен иметь текст чтобы не быть распознанным как веб-спам, и какие средства могут его генерировать?
В последние годы уникальный текст (и вообще текст) стал распространенным инструментом, который SEO-специалисты рекомендуют для продвижения сайтов в поисковых системах. Совсем в последние годы, владельцы сайтов поняли, что заказывать написание текстов людям достаточно накладно, ведь цены на авторские тексты во все времена находились в диапазоне $1-$3 за 1000 знаков. Понятно, что владельцу интернет-магазина даже со скромным ассортиментом в 3-4 тыс наименований надо заплатить за тексты от 300 000 рублей, причем трата это не разовая, поскольку ассортимент имеет тенденцию обновляться. Естественно, на страницах сайтов появились автоматически сгенерированные описания товаров.
Как на самом деле поисковая система распознает автоматически сгенерированный контент...
… этого мы конечно не знаем. Но, общий принцип метода тайны не составляет, и обратившись к первоисточникам можно сделать некоторые обоснованные выводы о границах возможного. Начнем с того, что на сайте научных публикаций Яндекса имеется статья с многообещающим названием «Поиск неестественных текстов» [1]. Там сказано примерно следующие “в неестественном тексте должно быть нарушено распределение пар [слов]… количество редких, нехарактерных для языка пар должно быть завышено по сравнению со стандартом, а количество частых пар – занижено”. Перед нами, таким образом, первая группа методов То есть, речь так или иначе идет о сравнении статистических параметров данного текста с параметрами «естественных» текстов. Помимо распределения пар, могут использоваться частоты n-грамм большего размера. В более современных работах [2] применяются также частоты n-грамм не самих слов, а частей речи, когда сначала каждому слову определяется часть речи (СУЩ-ПРИЛ-СУЩ-ГЛАГ), а потом подсчитывают частоты полученных n-грамм, и так далее.
Ясно, что самые примитивные описания, сгенерированные с помощью подстановки параметров товаров в шаблонный текст избегают этого фильтра по причине того, что исходный шаблон заготовлен человеком и, соответственно, имеет естественные характеристики. Это конечно, при условии, что в шаблоне приглажены соответствия родов и падежей, чтобы не получалось ничего вроде «Купить стиральная машина за 10399 рубля».
Генераторы на основе современных моделей языка, такие как нейросетевые модели языка, также весьма вероятно избегают этого фильтра, так как общее правило гласит «чтобы поймать текст сгенерированный некоторой моделью языка, надо использовать более совершенную модель языка». А более совершенная модель языка может быть в дефиците, и к тому же требовать огромных вычислительных затрат, так что ее использование для определения автоматических текстов в масштабах интернета просто будет нерациональным
Но генераторы на основе модели языка, примененные напрямую, генерируют тексты, лишенные смысла. Например, такие «Надежность водонагревателей «аристон» побеждает рейтинг бойлеров».
Поскольку владельцы интернет-магазинов как правило не хотят, чтобы водонагреватели побеждали рейтинги бойлеров, они предпочитают простые шаблонные тексты. Но и здесь есть некоторая потенциальная трудность.
Шаблонный текст не отличим от естественного до тех пор, пока он имеется в единственном экземпляре. Размноженные же, они становятся предметом второго класса методов определения машинных текстов. Суть метода в том, что все тексты, написанные на базе шаблона похожи друг на друга за исключением частей, куда вставляются параметры конкретного товара. Получается то, что называется в английской литературе ”near dublicates” — почти дубликаты. Поисковые системы умеют их определять [3], используя всем известный метод шинглов и его усовершенствованные варианты. Если же использовать дополнительно синонимайзер, то увеличится число маловероятных языковых конструкций и текст станет опознаваемым для первой группы алгоритмов [1]. Кроме того, существуют алгоритмы, специфически направленные против синонимайзеров — они убирают из текста все слова, для которых имеются синонимы в словаре, и сравнивают тексты по оставшимся словам [4].
Таким образом, алгоритмы распознавания машинно-генерируемых текстов являясь с одной стороны достаточно сложными, все же не содержат в себе никакой магии и сверхинтеллекта. При желании можно их воспроизвести для целей тестирования текстов, что затратно по времени, но в общем не сложно.
Философское отступление
Мы столкнулись с тем, что есть люди, считающие машинные тексты злом, засоряющим интернет и предназначенным для обмана пользователей. Но мы считаем, что это вряд ли правомочно относить к осмысленным текстам, описывающие конкретные товары по параметрам. Ведь эти тексты содержат фактически верную информацию о товаре. Размещая на странице такой текст мы обозначаем ее содержимое для поисковой системы, поэтому это не является обманом поисковых систем или покупателей.
Практика: Насколько хороши машинные тексты?
Принимая во внимание вышеизложенное, мы остановились на гибридном методе генерации текстов. В нем, сначала базовый каркас текста генерируется с помощью заданной вручную грамматики (подробнее в предыдущей статье), а затем сверху применяется нейросетевой анализатор, натренированный на определение мест, где можно вставить или удалить определенные классы слов без потери смысла. Необходимость создания порождающей грамматики вручную конечно удорожает стоимость решения, но все равно она остается на порядок меньшей, чем заказ текстов копирайтеру. Теперь собственно по качеству.
Читабельность:
«Смеситель для раковины Grohe Allure 19386000 из новой коллекции Allure, стоимостью всего 5800 рублей. Скрытый монтаж обеспечивает повышенное удобство эксплуатации и, конечно, установки. Cистема GROHE SilkMove позволяет обеспечить исключительно легкое движение рычага. Специальное покрытие, произведенное по технологии StarLight создает долговечность и сохраняет хороший вид изделия на протяжении долгих лет. Вертикальный монтаж с двумя монтажным отверстиями весьма удобен и не должен вызвать трудностей. Величина выноса излива здесь равна 220 мм. Больший размер выноса приводит к тому, что использовать изделие становится намного проще. Все изделие в общем имеет вес равный 1,955 кг. Минимальное давление для данной модели равняется 1 бар. В подключении к электричеству нет необходимости. Бесплатная доставка и надежное, проверенное годами, качество широко известного всем немецкого бренда — главные причины купить смеситель Grohe Allure 19386000».
Конечно, это не великое литературное произведение, но явных огрехов нет. Определить, что текст сгенерирован автоматически трудно, даже для человека.
Уникальность:
a) Глобальная уникальность. Суть глобальной уникальности в том, чтобы текст был уникален относительно всех других текстов, имеющихся в интернете на момент публикации.
Для проверки глобальной уникальности мы использовали известный сервис text.ru (для целей объективности, в этой статье мы приводим результаты анализа со сторонних сервисов, а не данные наших алгоритмов).
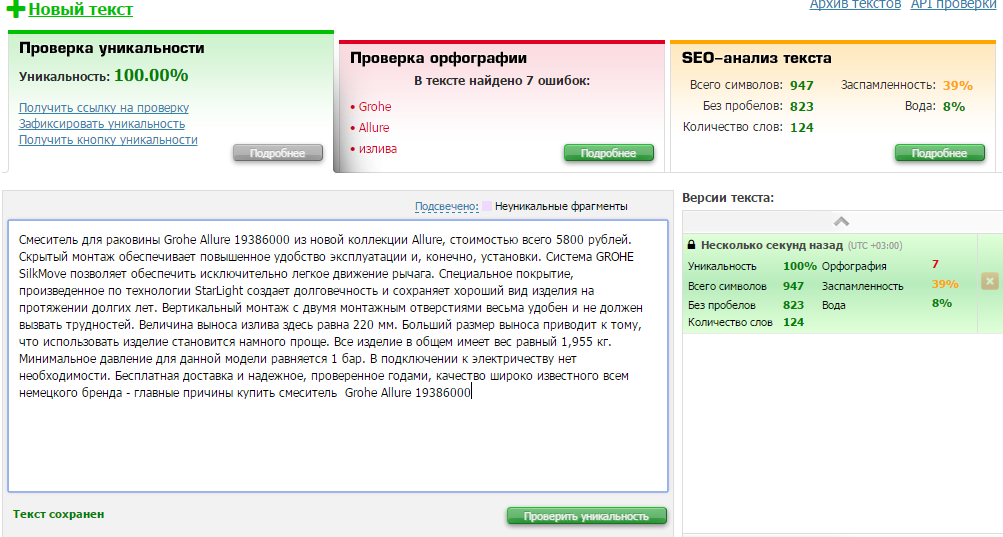
Как видно, с глобальной уникальностью нет никаких проблем. Сервис жалуется на орфографию, но при рассмотрении ошибки связаны с тем, употреблением слов ”Allure”, “StarLight” и других специфических терминов, которые сервис не знает. Примечание: это данные до размещения текстов на сайте заказчика. Сейчас, естественно, эти тексты можно обнаружить там.
б) Локальная уникальность. Как мы уже говорили, слишком похожие тексты могут быть сочтены поисковой системой дубликатами друг друга, что может выдать их искусственное происхождение. Для этого мы использовали сервис, размещенный на сайте backlinkmanager (другие реализации сравнения с помощью алгоритма шинглов дают похожие результаты)

Два текста про очень похожие модели с совпадающими параметрами сходны всего на 5%, причем в значительной степени сходство обусловлено упоминанием названия товара «Смеситель для мойки Grohe Alira”. Будем считать это хорошим результатом, ведь есть не так много способов по разному описать один и тот же набор параметров товара.
Индексация поисковыми системами
Индексация машинно-генерируемых текстов была проверена нами ранее на примере сайта reviewdot.ru. Страницы данного сайта не имеют уникального контента. Поэтому вначале этот сайт никак не хотел попадать в индекс Яндекса (из более чем ста тысяч страниц в индексе оказались около 1300 штук). Мы с этим упорно боролись, разместив сначала шаблонные тексты (число страниц в индексе выросло до 5000), потом использовав более сложные алгоритмы генерации, подобные рассмотренному выше. На сегодняшний день в индексе Яндекса около 70 000 страниц. Хотя что конкретно повлияло на ситуацию — наши усилия или изменения в алгоритмах Яндекса, нам неизвестно. Тем не менее, факт остается фактом — страницы, содержащие автоматически сгенерированные тексты успешно попадают в индекс поисковых систем. Несмотря на все опасения SEO специалистов,
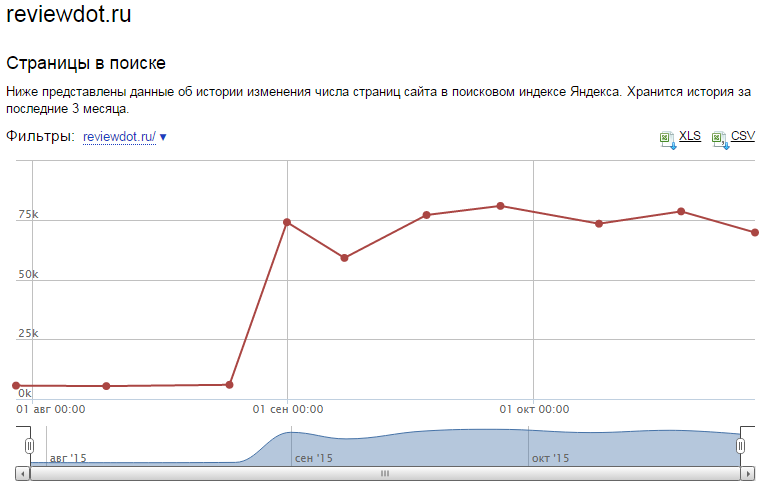
Причем в индексе не только страницы, но и конкретно автоматически сгенерированные тексты, в чем можно убедиться, введя фрагменты этих текстов в поисковую строку:
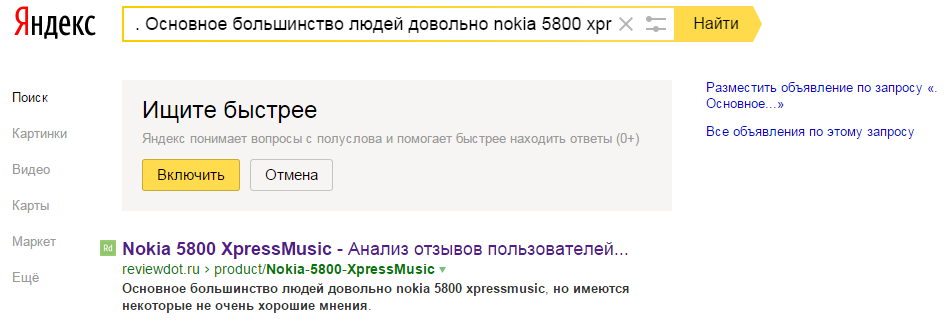
А значит, как минимум, машинно-генерируемый контент можно использовать для того, чтобы страница стала релевантной определенным запросам.
Конечно, надо заметить, что мы размещали не бессмысленные тексты, а тексты содержащие полезную пользователю информацию (reviewdot анализирует отзывы на товары, оставленные на разных сайтах и представляет пользователю краткую аннотацию об отмеченных плюсах и минусах).
Мы также провели сравнение времени нахождения пользователя на страницах с текстом.В результате этого обнаружилось, что тексты положительно сказались и на таком параметре, как время нахождения пользователя на странице. Видимо причина этого в том, что если человек видит на странице связный текст, содержащий нужные ему сведения, он начинает его читать, а чтение текста занимает некоторое время.
Заключительные замечания
На сегодняшний день тексты сданы заказчику и размещены на сайте (интернет-магазин сантехники g-online.ru), желающие могут ознакомится и с ними тоже. Пока что мы можем сделать выводы, что сгенерированные тексты могут быть сделаны достаточно сходными с «естественными», и при правильном подходе к делу они не влияют на сайт отрицательно. Сгенерированные тексты могут улучшить индексацию страниц сайта, и сделать страницы релевантными определенным запросам. Можно запрограммировать генератор на упоминание заданных ключевых слов или фраз в точно заданных процентных соотношениях от размера текста.
Литература
1. Е.А. Гречников, Г.Г. Гусев, А.А. Кустарев, А.М. Райгородский. Поиск неестественных текстов//Труды 11й Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» — RCDL’2009, Петрозаводск, Россия, 2009.
2. Aharoni, Roee, Moshe Koppel, and Yoav Goldberg. Automatic Detection of Machine Translated Text and Translation Quality Estimation//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 289–295, Baltimore, Maryland, USA, June 23-25 2014.
3. G. S. Manku, A. Jain, and A. Das Sarma. Detecting Near-duplicates for Web Crawling. In Proceedings of the 16th WWW Conference, May 2007
4. Zhang, Qing, David Y. Wang, and Geoffrey M. Voelker. «Dspin: Detecting automatically spun content on the web.» NDSS, 2014.
