Комментарии 54
Решение(ли) какой именно проблемы описано(ли) в этой статье?
Уже смешались люди, кони, Мечи, секиры, топоры
Какую задачу вы пытаетесь решить (или уже решили)?
НЛО прилетело и опубликовало эту надпись здесь
Люблю я хабровчан за их неравнодушие! Этим-то и ценно общение — обменом информацией или эмоциями, на худой конец. В общем, никто не уйдет обиженным.
Для себя я решил задачу экстрагирования в статье небольшого размера сути подхода по отделению обрабатываемых данных от обработчиков, что, на мой взгляд, является одним из краеугольных камней при распределенной разработке (слабосвязанными командами разработчиков) гетерогенных программных систем (типичный пример — web-приложение), интегрированных с внешними сервисами посредством SOAP/REST и адаптируемых конечным пользователем под изменяющиеся условия применения.
Да, это довольно узкоспециализированное направление, достаточно сильно отличающееся, например, от «программирования игр под андроид», но, к сожалению, на habr'е нет отдельной категории для подобных направлений, поэтому я и запостился в общий хаб «Программирование». Прошу прощения у всех, кого отвлек этим своим постом от забот насущных.
Для себя я решил задачу экстрагирования в статье небольшого размера сути подхода по отделению обрабатываемых данных от обработчиков, что, на мой взгляд, является одним из краеугольных камней при распределенной разработке (слабосвязанными командами разработчиков) гетерогенных программных систем (типичный пример — web-приложение), интегрированных с внешними сервисами посредством SOAP/REST и адаптируемых конечным пользователем под изменяющиеся условия применения.
Да, это довольно узкоспециализированное направление, достаточно сильно отличающееся, например, от «программирования игр под андроид», но, к сожалению, на habr'е нет отдельной категории для подобных направлений, поэтому я и запостился в общий хаб «Программирование». Прошу прощения у всех, кого отвлек этим своим постом от забот насущных.
1. Не думаю что уместно сравнивать применение аксессоров с «железной» архитектурой Эйкена.
2. Применение аксессоров далеко не бесспорно. Судя по вашей дате рождения из профиля, вы (как и я) начинали с процедурного программирования и до сих пор подсознательно «тоскуете» по тем временам. Универсального контейнера данных не существует как и «серебряной пули» т.к. за любую универсальность приходится платить. Например в вашей терминологии:
2. Применение аксессоров далеко не бесспорно. Судя по вашей дате рождения из профиля, вы (как и я) начинали с процедурного программирования и до сих пор подсознательно «тоскуете» по тем временам. Универсального контейнера данных не существует как и «серебряной пули» т.к. за любую универсальность приходится платить. Например в вашей терминологии:
Самое главное, что универсальный контейнер каждой «вселенной» может разбирать и генерировать транскод (JSON/XML/YAML/...), адаптируя к своей среде выполнения не только те данные, которые заложил в него разработчик самого приложения («A»), но и дополнительные данные, которые прицепили к «посылке» разработчики сервиса («C») или клиента («B»).Вас не напрягает, что сервис («C») или клиент («B») могут не только добавлять свои данные, но и изменять данные приложения («A»), причем так, что приложение («A») даже не будет догадываться, что его данные кто-то поменял?
1. Я сравнивал с архитектурой Эйкена не акцессоры, а именно сам подход, когда данные отделяются от обработчиков.
2. Любая DBMS является довольно-таки универсальным контейнером данных.
3. Я использую подход с акцессорами только лишь из-за привычки ожидать подсказки от IDE после набора префикса get/set. Мне так удобнее. Чтобы не путать с другими методами при использовании автодополнения. Но если мы работаем с контейнером данных, то там не должно быть других методов, кроме акцессоров, так что можно обойтись и самими свойствами.
4. В моем примере A, B и C — это представители различных уровней приложения, разных «вселенных». Это как запросить данные из программы на JavaScript у сервиса, написанного на Java. Java-сервис может изменять запрос сколько угодно — он работает с копией, созданной на основании транскода (XML в случае с SOAP).
5. Менять входные данные — не очень хорошая практика, даже если ты создаешь весь код сам, а уж если ты работаешь в команде, то надо много раз подумать, чтобы решится на это.
6. Если все-таки приходится сталкиваться с тем, что моя или чья-то еще функция/метод изменяет входные данные, то — да, меня это напрягает.
2. Любая DBMS является довольно-таки универсальным контейнером данных.
3. Я использую подход с акцессорами только лишь из-за привычки ожидать подсказки от IDE после набора префикса get/set. Мне так удобнее. Чтобы не путать с другими методами при использовании автодополнения. Но если мы работаем с контейнером данных, то там не должно быть других методов, кроме акцессоров, так что можно обойтись и самими свойствами.
4. В моем примере A, B и C — это представители различных уровней приложения, разных «вселенных». Это как запросить данные из программы на JavaScript у сервиса, написанного на Java. Java-сервис может изменять запрос сколько угодно — он работает с копией, созданной на основании транскода (XML в случае с SOAP).
5. Менять входные данные — не очень хорошая практика, даже если ты создаешь весь код сам, а уж если ты работаешь в команде, то надо много раз подумать, чтобы решится на это.
6. Если все-таки приходится сталкиваться с тем, что моя или чья-то еще функция/метод изменяет входные данные, то — да, меня это напрягает.
Это не узкоспециализированное направление. Вы описали массив в PHP. Ваш DataObject практически ничем от него не отличается.
Массив в PHP это и есть контейнер для переноса любых данных, мы его имели и до результата.
Почему бы просто не объявить нормальный класс с нормальными свойствами, унаследованный от ArrayObject? Потому что вам удобнее по-другому? Хороший аргумент, что сказать.
То есть, вы предлагает в каждый контейнер, который надо сериализовать в JSON, копировать одну и ту же функцию сериализации, вместо того чтобы держать ее отдельно и передавать объект как параметр?
Выходные данные одних функций всегда можно передать в другие функции. На то они и данные. Другое дело, что функция может ожидать на вход данные определенного формата, и произвольный DataObject ей не нужен.
Что имеем в результате? Контейнер для переноса любых данных.
Массив в PHP это и есть контейнер для переноса любых данных, мы его имели и до результата.
Можно все то же самое делать через аннотацию @property
Почему бы просто не объявить нормальный класс с нормальными свойствами, унаследованный от ArrayObject? Потому что вам удобнее по-другому? Хороший аргумент, что сказать.
Скрытый текст
class GetForDependentCalc extends DataObject
{
public $baseCalcData;
public $dependentCalcData;
}
$a = new GetForDependentCalc();
$a->test = 'test';
var_dump($a);
/*
object(GetForDependentCalc)[1]
public 'baseCalcData' => null
public 'dependentCalcData' => null
public 'test' => string 'test' (length=4)
*/
class DataObject extends ArrayObject
{
public function __construct($input = [], $flags = ArrayObject::STD_PROP_LIST, $iterator_class = 'ArrayIterator')
{
parent::__construct($input, $flags, $iterator_class);
}
}
Более того, можно «научить» универсальный контейнер автоматически преобразовывать хранимые в нем данные в формат, например, JSON
То есть, вы предлагает в каждый контейнер, который надо сериализовать в JSON, копировать одну и ту же функцию сериализации, вместо того чтобы держать ее отдельно и передавать объект как параметр?
можно получить весьма интересные последствия в виде цепочек функций-процессоров, где выходные данные одних функций являются входными данными для других
Выходные данные одних функций всегда можно передать в другие функции. На то они и данные. Другое дело, что функция может ожидать на вход данные определенного формата, и произвольный DataObject ей не нужен.
1. Суть подхода вы уловили — в качестве контейнера можно использовать и массив, и ArrayObject. Самое главное, чтобы функционал, который реализован в контейнере, не зависел от типа данных, которые в нем содержатся. Как в том же ArrayObject.
2. Можно при сериализации использовать и внешнюю функцию — это не принципиально. Принципиально, что сериализуются любые данные — и те, которые уложил в контейнер разработчик основного функционала, и те, которые в этот же контейнер уложил разработчики плагинов для основного функционала.
3. Один входной объект для функции и один выходной — это принципиальный вопрос для конвейеризации. Если вы посмотрите на web-сервисы, то увидите, что именно так и есть — на вход подается одна структура данных (request), на выходе получается другая, но тоже одна (response). В request'е объединены воедино все данные, необходимые для выполнения операции сервисом (как и в запросе) — сервис сам может выбрать из запроса нужные ему данные (а плагин к сервису может выбрать из этого же запроса нужные ему).
2. Можно при сериализации использовать и внешнюю функцию — это не принципиально. Принципиально, что сериализуются любые данные — и те, которые уложил в контейнер разработчик основного функционала, и те, которые в этот же контейнер уложил разработчики плагинов для основного функционала.
3. Один входной объект для функции и один выходной — это принципиальный вопрос для конвейеризации. Если вы посмотрите на web-сервисы, то увидите, что именно так и есть — на вход подается одна структура данных (request), на выходе получается другая, но тоже одна (response). В request'е объединены воедино все данные, необходимые для выполнения операции сервисом (как и в запросе) — сервис сам может выбрать из запроса нужные ему данные (а плагин к сервису может выбрать из этого же запроса нужные ему).
Для себя я решил задачу экстрагирования в статье небольшого размера
Ну то есть вся задача статьи — это написать статью?
сути подхода по отделению обрабатываемых данных от обработчиков,
Извините, что? Разделение данных и логики? А вы про функциональное программирование вообще не слышали никогда?
при распределенной разработке (слабосвязанными командами разработчиков) гетерогенных программных систем (типичный пример — web-приложение), интегрированных с внешними сервисами посредством SOAP/REST
Паттерн Data Transfer Object — не? Buzzword SOA — не?
Но самое главное — «универсальный контейнер данных» тут совсем ни при чем. Во всех описанных выше случаях используется вполне конкретный объект, предпочтительно — типизированный (если это позволяет язык и платформа), потому что иначе количество геморроя неописуемо.
1. Да. Причем попытаться уложиться в несколько экранов.
2. Слышал.
3. Если DTO не зависит от типа переносимых данных — да, это он и есть.
4. Buzzword SOA — не понимаю, о чем это.
5. Самое главное в этой концепции: мухи (код обработчиков) отдельно, а котлеты (обрабатываемые данные) — отдельно. А если «мухи» и/или «котлеты» будут в виде типизируемых объектов — так оно даже и лучше.
2. Слышал.
3. Если DTO не зависит от типа переносимых данных — да, это он и есть.
4. Buzzword SOA — не понимаю, о чем это.
5. Самое главное в этой концепции: мухи (код обработчиков) отдельно, а котлеты (обрабатываемые данные) — отдельно. А если «мухи» и/или «котлеты» будут в виде типизируемых объектов — так оно даже и лучше.
Когда вы говорите «мухи», «котлеты», у меня создается ощущение что вы не слышали про MVC.
По поводу вашего DataObject. Я подобное создавал в первый год изучения прогркммирования и очень бытсро отказался от этого решения. Основная проблема это отсутствие типизации и жесткой структуры объектов и с автодополнением в те годы были проблемы.
По поводу вашего DataObject. Я подобное создавал в первый год изучения прогркммирования и очень бытсро отказался от этого решения. Основная проблема это отсутствие типизации и жесткой структуры объектов и с автодополнением в те годы были проблемы.
Если отталкиваться от аббревиатуры MVC, то M — это «чистые данные», а V & C — это типизация, наследование и все прочее. В «коде» (VC) можно и нужно использовать все, что позволяет уменьшить сложность и увеличить управляемость, а в данных (M) — только данные (аналог POJO). Потому что именно это уменьшает сложность и увеличивает управляемость. Код в данных — это как SQL-процедуры в БД.
Так я и думал. Модель это не только данные, но еще и бизнес логика. Бизнес логика должна находится как можно ближе к данным. Именно по этому (еще из-за производительности) некоторые размещают бизнес логику в тригерах и процедурах БД, рядом с хранимыми данными. И именно по этому класс модели должен быть типизирован и хранить данные и бизнес логику одной конкретной сущности. Смотрите тот же ActiveRecord.
Если же нужен контейнер для временного хранения данных, то, как и говорили michael_vostrikov и lair, достаточно обычного массива
Если же нужен контейнер для временного хранения данных, то, как и говорили michael_vostrikov и lair, достаточно обычного массива
По поводу использования обработчиков (SQL-процедур/функций и триггеров) рядом с данными есть различные мнения. Нет универсального решения — «каждому решению присуще сожаление» (с) Применяемый способ решения зависит от условий задачи. Обычный массив можно использовать в качестве «универсального контейнера», а можно для тех же целей его доработать (как это было сделано в той же Magento) и использовать его более эффективно. Сравните:
Во втором случае адрес элемента в массиве данных напоминает привычные пути (файловые, XPath, JSONPath), что позволяет использовать уже существующие методы работы с подобной информацией. При помощи аннотаций его можно слегка «дотипизировть», оставляя тем не менее дополняемым на уровне исполнения.
Вы правы в том, что все данные одной не очень большой базы можно воткнуть в обычный ассоциативный массив. И да, это будет универсальный контейнер. А если его использовать без добавления инструкций по обработке, то это и будет универсальный контейнер данных. Вот только не будет отражена структура «известных данных», что изрядно усложнит разработку. Хотя можно сделать «типизатор» данных, который для любого произвольного массива будет извлекать данные нужной структуры. Это тоже путь.
$transId = $data['Sales'][3]['Payments'][0]['Transactions'][0]['Id'];
$transId = $data['/Sales/3/Payments/0/Transactions/0/Id'];
Во втором случае адрес элемента в массиве данных напоминает привычные пути (файловые, XPath, JSONPath), что позволяет использовать уже существующие методы работы с подобной информацией. При помощи аннотаций его можно слегка «дотипизировть», оставляя тем не менее дополняемым на уровне исполнения.
Вы правы в том, что все данные одной не очень большой базы можно воткнуть в обычный ассоциативный массив. И да, это будет универсальный контейнер. А если его использовать без добавления инструкций по обработке, то это и будет универсальный контейнер данных. Вот только не будет отражена структура «известных данных», что изрядно усложнит разработку. Хотя можно сделать «типизатор» данных, который для любого произвольного массива будет извлекать данные нужной структуры. Это тоже путь.
Вот только не будет отражена структура «известных данных», что изрядно усложнит разработку.
Поэтому нужно использовать классы которые будут описывать конкретную структуру «известных данных», а не ваш DataObject и массив.
Пример по вашем же данным
$transId = $data->getSales()[3]->getPayments()[0]->getTransactions()[0]->getId();
И при правильном описании аннотации будет работать автодополнение на протчжении всей цепочки вызовов
Ну вот! Так это то, о чем я и писал!!! Делая класс на базе DataObject вы делаете его:
а) типизируемым;
б) дополняемым;
Меня в Magento весьма сильно напрягало, что в таких структурах никогда точно не знаешь, что лежит, и сильно радовало, что в них всегда можно положить все, что угодно. Проблема в том, что в некоторых случаях множественное наследование не работает. Например, когда два-три расширения переопределяют один и тот же класс основного функционала. Разработчик каждого плагина не знает о существовании других плагинов, да и не должен. А я, как интегратор, должен сам решать в каком порядке мне выстроить иерархию наследования в конечном приложении. И иногда это бывает довольно забавной задачей, если учесть, что порой приходится совмещать в одном приложении по 15-20 сторонних плагинов.
В подобной ситуации вот такой DataObject + «гарвардский» подход (отделение данных от инструкций, функциональное программирование, если кому удобнее) может дать весьма ощутимые бонусы в виде конвейеризации обработчиков некоей «структуры данных».
а) типизируемым;
б) дополняемым;
Меня в Magento весьма сильно напрягало, что в таких структурах никогда точно не знаешь, что лежит, и сильно радовало, что в них всегда можно положить все, что угодно. Проблема в том, что в некоторых случаях множественное наследование не работает. Например, когда два-три расширения переопределяют один и тот же класс основного функционала. Разработчик каждого плагина не знает о существовании других плагинов, да и не должен. А я, как интегратор, должен сам решать в каком порядке мне выстроить иерархию наследования в конечном приложении. И иногда это бывает довольно забавной задачей, если учесть, что порой приходится совмещать в одном приложении по 15-20 сторонних плагинов.
В подобной ситуации вот такой DataObject + «гарвардский» подход (отделение данных от инструкций, функциональное программирование, если кому удобнее) может дать весьма ощутимые бонусы в виде конвейеризации обработчиков некоей «структуры данных».
Ну вот! Так это то, о чем я и писал!!! Делая класс на базе DataObject вы делаете его:
а) типизируемым;
б) дополняемым;
Для этого создается обычный класс. DataObject здесь не нужен. Он не решает никаких проблем, а только создает их
Проблема в том, что в некоторых случаях множественное наследование не работает. Например, когда два-три расширения переопределяют один и тот же класс основного функционала.
Множественное наследование и не должно работать. В вашем случае нужно использовать Адаптор. Использование DataObject в описанном вами случае больше похоже на костыль
Смотрите, в базовой имплементации есть объект Customer, есть два плагина, разработчики которых не знают друг о друге, но знают, что есть базовая имплементация Customer'а. Каждый из разработчиков добавляет по одному атрибуту к базовой сущности Customer:
и создает свои собственные расширения базового объекта CustomerRef & CustomerEmail:
допустим, есть внешний класс для выполнения операций с БД (разделение инструкций и данных, детали его реализации на данный момент не важны). В этом случае в базовой имплементации подгружается объект со всеми своими атрибутами и используется в таком виде в базовом workflow. В местах, где включаются обработчики плагинов (допустим, по событию), они преобразовывают базовые данные в понятный для себя вид и работают со «знакомыми» атрибутами, игноря атрибуты незнакомые. В конце базового workflow происходит сохранение объекта в БД:
По сути дела производный от DataObject класс в некотором роде и является для среды выполнения адаптером к данным, хранимым в ассоциативном массиве. Все то же самое, при желании, можно изобразить и просто на ассоциативном массиве, только без autocomplete'а в IDE и без возможности поиска Find Usages.
CREATE TABLE Customer (
Id int NOT NULL AUTO_INCREMENT COMMENT 'this is attribute from base implementation',
Ref varchar(255) DEFAULT NULL COMMENT 'this attribute is added by plugin 1',
Email varchar(50) DEFAULT NULL COMMENT 'this attribute is added by plugin 2',
PRIMARY KEY (Id)
)
и создает свои собственные расширения базового объекта CustomerRef & CustomerEmail:
/**
* This is base object.
*
* @method int getId()
* @method void setId(int $data)
*/
class Customer extends DataObject {
}
/**
* This is extended customer (plugin 1).
*
* @method string getRef()
* @method void setRef(string $data)
*/
class CustomerRef extends Customer {
}
/**
* This is extended customer (plugin 2).
*
* @method string getEmail()
* @method void setEmail(string $data)
*/
class CustomerEmail extends Customer {
}
допустим, есть внешний класс для выполнения операций с БД (разделение инструкций и данных, детали его реализации на данный момент не важны). В этом случае в базовой имплементации подгружается объект со всеми своими атрибутами и используется в таком виде в базовом workflow. В местах, где включаются обработчики плагинов (допустим, по событию), они преобразовывают базовые данные в понятный для себя вид и работают со «знакомыми» атрибутами, игноря атрибуты незнакомые. В конце базового workflow происходит сохранение объекта в БД:
// data loader (base impl.)
$base = $repo->load('Customer', 21);
// plugin1 code on event 1
$cust1 = new CustomerRef($base);
$id1 = $cust1->getId();
$ref = $cust1->getRef();
// plugin2 code on event 2
$cust2 = new CustomerEmail($base);
$id2 = $cust2->getId();
$cust2->setEmail('any@email.com');
// data saver (base impl.)
$repo->save('Customer', $cust2);
По сути дела производный от DataObject класс в некотором роде и является для среды выполнения адаптером к данным, хранимым в ассоциативном массиве. Все то же самое, при желании, можно изобразить и просто на ассоциативном массиве, только без autocomplete'а в IDE и без возможности поиска Find Usages.
Вот. С этого и стоило начинать. Это уже нормальное описание проблемы. Его и нужно было приводить в статье. Тогда и вопросов было бы меньше.
Пример решения с использованием декораторов и включенным strict mode:
исполняемый код полностью копирует ваш:
С использованием DataObject нельзя контролировать тип хранящихся в нем данных и список самих данных. Например что будет при выполнении следующего кода? Вы будете в методе save() проверять список доступных полей на запись или будете писать данные как есть в БД и получать fatal error из-за отсутствия соответствующей колонки в таблице?
Пример решения с использованием декораторов и включенным strict mode:
Структура классов
под рукой нет php7 чтобы проверить, но должно работать
declare(strict_types=1);
interface CustomerInterface
{
public function getId(): int;
public function setId(int $id);
}
interface CustomerPluginInterface extends CustomerInterface
{
public function getCustomer();
}
// This is base object.
class Customer implements CustomerInterface
{
private $id;
private $ref;
private $email;
public function getId(): int
{
return $this->id;
}
public function setId(int $id)
{
$this->id = $id;
return $this;
}
public function getRef(): string
{
return $this->ref;
}
public function setRef(string $ref)
{
$this->ref = $ref;
return $this;
}
public function getEmail(): string
{
return $this->email;
}
public function setEmail(string $email)
{
$this->email = $email;
return $this;
}
}
// This is extended customer (plugin 1).
class CustomerRef implements CustomerPluginInterface
{
private $customer;
public function __construct(Customer $customer)
{
$this->customer = $customer;
}
public function getId(): int
{
return $this->customer->getId();
}
public function setId(int $id)
{
$this->customer->setId($id);
return $this;
}
public function getRef(): string
{
return $this->customer->getRef();
}
public function setRef(string $ref)
{
$this->customer->setRef($ref);
return $this;
}
public function getCustomer()
{
return $this->customer;
}
}
// This is extended customer (plugin 2).
class CustomerEmail implements CustomerPluginInterface
{
private $customer;
public function __construct(Customer $customer)
{
$this->customer = $customer;
}
public function getId(): int
{
return $this->customer->getId();
}
public function setId(int $id)
{
$this->customer->setId($id);
return $this;
}
public function getEmail(): string
{
return $this->customer->getEmail();
}
public function setEmail(string $email)
{
$this->customer->setEmail($email);
return $this;
}
public function getCustomer()
{
return $this->customer;
}
}
под рукой нет php7 чтобы проверить, но должно работать
исполняемый код полностью копирует ваш:
$base = $repo->load('Customer', 21);
// plugin1 code on event 1
$cust1 = new CustomerRef($base);
$id1 = $cust1->getId();
$ref = $cust1->getRef();
// plugin2 code on event 2
$cust2 = new CustomerEmail($base);
$id2 = $cust2->getId();
$cust2->setEmail('any@email.com');
// data saver (base impl.)
$repo->save('Customer', $cust2->getCustomer()); // <-- различие только здесь
// но можно и так, ибо изменив $cust2 мы изменили $base
//$repo->save('Customer', $base);
С использованием DataObject нельзя контролировать тип хранящихся в нем данных и список самих данных. Например что будет при выполнении следующего кода? Вы будете в методе save() проверять список доступных полей на запись или будете писать данные как есть в БД и получать fatal error из-за отсутствия соответствующей колонки в таблице?
$base = $repo->load('Customer', 21);
$base->setId('foo');
$base->setFieldNotSetInDb('bar');
$repo->save('Customer', $base);
Спасибо за пример.
Вот в этом месте лишние атрибуты. Разработчик базового функционала заложил только $id. Атрибут $ref заложил разработчик плагина 1, атрибут $email — разработчик плагина 2. Разработчики друг с другом не знакомы. Поэтому базовый класс выглядит по идее как-то так:
После чего у интегратора и начинается свистопляска с различными переопределениями. Акцентирую еще раз — весь фокус в том, что разработчики плагинов ничего не знают друг про друга, каждый из них знает только структуру базового объекта и свои собственные дополнения.
По поводу сохранения. В Magento при обращении к БД считывается структура таблиц со всеми атрибутами и при сохранении фильтруются «лишние» из $data. Это дело кэшируется, поэтому иногда получается весьма забавно, когда поля в таблице есть, а сохранить в них ничего нельзя. Но все лечится путем удаления кэша.
Вот в этом месте лишние атрибуты. Разработчик базового функционала заложил только $id. Атрибут $ref заложил разработчик плагина 1, атрибут $email — разработчик плагина 2. Разработчики друг с другом не знакомы. Поэтому базовый класс выглядит по идее как-то так:
class Customer implements CustomerInterface
{
private $id;
public function getId(): int
{
return $this->id;
}
public function setId(int $id)
{
$this->id = $id;
return $this;
}
}
После чего у интегратора и начинается свистопляска с различными переопределениями. Акцентирую еще раз — весь фокус в том, что разработчики плагинов ничего не знают друг про друга, каждый из них знает только структуру базового объекта и свои собственные дополнения.
По поводу сохранения. В Magento при обращении к БД считывается структура таблиц со всеми атрибутами и при сохранении фильтруются «лишние» из $data. Это дело кэшируется, поэтому иногда получается весьма забавно, когда поля в таблице есть, а сохранить в них ничего нельзя. Но все лечится путем удаления кэша.
Разработчик базового функционала заложил только $id. Атрибут $ref заложил разработчик плагина 1, атрибут $email — разработчик плагина 2. Разработчики друг с другом не знакомы.
Я не могу вам предложить конкретное решение вашей проблемы потому что не знаю особенностей архитектуры вашего приложение и не знаю на что вы можете влиять. Судя по тому что вы предлагаете в статье, вы можете влиять на код всех 3-х компонентов: «базовый функционал», «плагина 1» и «плагина 2».
Самое простое решение, если вы не можете влиять на код плагинов, это добавить в базовый функционал атрибут $ref из плагина 1 и атрибут $email из плагина 2. Базовый класс будет описывать реальную сущность из БД, а сущности из плагинов будут ориентироваться на свой интерфейсом как и раньше, а дополнительные атрибуты из другого плагина будут просто игнорировать.
Я рассматривал ситуацию, когда я — разработчик базового функционала. Мне нужно предложить разработчикам плагинов такую модель взаимодействия, которая бы позволила им независимо ни от меня, ни друг от друга дополнять базовый функционал всем, чем им заблагорассудится. Если отталкиваться от нашего примера, то я ввожу в приложение сущность Клиент и обеспечиваю какие-то базовые функции (например, аутентификацию по логину и паролю), а разработчики плагинов уже сами добавляют свое (разработчик плагина 1 добавляет реферальную программу и новый атрибут ref к сущности Клиент, разработчик плагина 2 — аутентификацию по email'у и новый атрибут email). Я, как разработчик базового функционала ничего не знаю какие плагины разрабатываются сейчас или будут разрабатываться в будущем. Разработчики плагинов также не знакомы друг с другом и не имеют представления, какие еще плагины будут стоять рядом с их собственными. Но, разумеется, все разработчики имеют представление о базовом функционале и базовых структурах данных (сущностях/атрибутах). В какой комбинации весь этот зоопарк будет собран на стороне клиента — зависит от клиента, его постоянно меняющихся запросов и выхода новых плагинов. Количество сущностей (таблиц в БД) и набору их атрибутов (колонки таблиц) изменяется с установкой каждого нового плагина. Единая команда разработчиков есть только у базисного функционала, остальные разработчики могут строить свои плагины либо на основании базисного функционала, либо на основании других плагинов (по большому счету независимы друг от друга). Вот в такой среде и функционирует DataObject.
НЛО прилетело и опубликовало эту надпись здесь
Обмен данными как объектами самое правильное. Ещё более правильное, если функционал будет в одном формате. Этот формат JSON, а выбирать нужный контент, нужно запросами.
SRSLY? А ничего, что «формат JSON» — это не обмен объектами? И строить к JSON (а не к дереву) запрос — непозволительно медленно?
Я согласен, что объектное (структурированное) представление данных — весьма удобно. Более того, я настаиваю, что это правильно (у меня был опыт работы с базами документов Lotus Domino, с тех пор я поклонник RDBMS). Но данные — это данные.
Они могут лежать в БД, представлены в виде JSON/XML/binary/encoded Base64, могут обрабатываться программой в виде ассоциативного массива, множества POJO-объектов, «однойбольшойдлиннойстроки» и т.п. Приложения постоянно трансформируют данные из одного формата в другой, начиная от UI'я и заканчивая БД и в обратную сторону. JSON/XML/YAML/… — это форматы передачи данных между различными (а иногда и разнородными) системами. У каждого из них своя «заточка», своя ниша. По-большому счету, исходный код — это тоже данные. Как правило, текстовые. Я встречался с решениями, когда код хранился в БД, извлекался и выполнялся по мере необходимости (то ли Liferay, то ли Odoo/OpenERP). BPML — это XML-данные или инструкции по обработке (код) в формате XML?
Иногда, особенно когда разработчики плохо представляют себе моделируемую предметную область или просто не в состоянии представить себе ее полностью (а чем сложнее система, тем выше вероятность возникновения такой ситуации), жесткая типизация объектов-данных может дать больше минусов, чем плюсов (особенно, если система нуждается в постоянной подстройке под постоянно изменяющиеся требования). И вот тут уже нужна универсализация.
Я с вами согласен, что идеальный плагин должен стать частью системы, но что делать с плагинами неидеальными? Которые core-разработчики не берут в свой код, а у этих плагинов, между прочим, весьма обширный круг пользователей? И сколько «идеальных плагинов» выдержит core и его разработчики, пока не начнут задаваться вопросом «а не сильно ль мы раздулись?»
По поводу выборки контента из JSON'а — я более чем уверен, что в вашем случае обработка идет не прямо по тестовым данным regexp'ом, а по их преобразованному (проиндексированному) аналогу (тому же ассоциативному массиву).
Они могут лежать в БД, представлены в виде JSON/XML/binary/encoded Base64, могут обрабатываться программой в виде ассоциативного массива, множества POJO-объектов, «однойбольшойдлиннойстроки» и т.п. Приложения постоянно трансформируют данные из одного формата в другой, начиная от UI'я и заканчивая БД и в обратную сторону. JSON/XML/YAML/… — это форматы передачи данных между различными (а иногда и разнородными) системами. У каждого из них своя «заточка», своя ниша. По-большому счету, исходный код — это тоже данные. Как правило, текстовые. Я встречался с решениями, когда код хранился в БД, извлекался и выполнялся по мере необходимости (то ли Liferay, то ли Odoo/OpenERP). BPML — это XML-данные или инструкции по обработке (код) в формате XML?
Иногда, особенно когда разработчики плохо представляют себе моделируемую предметную область или просто не в состоянии представить себе ее полностью (а чем сложнее система, тем выше вероятность возникновения такой ситуации), жесткая типизация объектов-данных может дать больше минусов, чем плюсов (особенно, если система нуждается в постоянной подстройке под постоянно изменяющиеся требования). И вот тут уже нужна универсализация.
Я с вами согласен, что идеальный плагин должен стать частью системы, но что делать с плагинами неидеальными? Которые core-разработчики не берут в свой код, а у этих плагинов, между прочим, весьма обширный круг пользователей? И сколько «идеальных плагинов» выдержит core и его разработчики, пока не начнут задаваться вопросом «а не сильно ль мы раздулись?»
По поводу выборки контента из JSON'а — я более чем уверен, что в вашем случае обработка идет не прямо по тестовым данным regexp'ом, а по их преобразованному (проиндексированному) аналогу (тому же ассоциативному массиву).
Из вас всю информацию приходится прям клещами вытягивать.
Получается так. Есть базовый, не изменяемый функционал. И создаются новые плагины которые расширяют базовый функционал не затрагивая базовый класс. Базовый класс изменять условно нельзя.
В таком случае нужно сразу сказать что дополнительные поля из плагинов не должны быть обязательными для заполнения, иначе они могут поломать базовый функционал.
Я вижу 2 пути решения проблемы. Вариант с хранением в БД JSON я не рассматриваю потому что это… извращение. В таком случает лучше сразу хранить все данные в документоориентированных СУБД.
1. Создание отдельной таблицы с дополнительными полями необходимыми для плагина и сделать связь с базовой таблицей OneToOne.
Преимущества:
Ни базовый класс, ни базовая таблица никак не затрагиваются. Новая сущность существует параллельно с базовой. Доступ осуществляется так:
Недостатки:
Нет возможности получить сущность плагина из базовой сущности. Так как мы не можем изменять базовый класс, следующий вариант работать не будет:
Нужно создавать еще одну таблицу и делать JOIN для выбора дополнительных данных
2. Расширить функционал базового класса через extends и новые поля из класса CustomerRef должны просто игнорироваться движком.
Преимущества:
Просто в реализации. Код будет выглядеть так:
Недостатки:
Опять же нельзя получить поля плагина из базового класса.
Усложняется разработка движка который будет отвечать за загрузку/сохранение данных. При неправильной реализации могут потеряться значения дополнительных полей CustomerRef при сохранении объекта как Customer.
Итог
Оба варианты рабочие, но не применимы для тех случаев когда нужно получить дополнительные поля из оригинального объекта. Это не страшно в тех случаях если плагины используются только для создания новой функциональности и фатально для тех случаев когда нужно переопределить базовую функциональность.
Ваше решение с DataObject позволяет получить дополнительные поля из базового класса, хотя автодополнение в IDE работать не будет.
PS: надо отметь что отсутствие возможности получить поля плагина из базового класса не всегда является минусом. В некоторых случаях это позволяет избежать ошибок.
Получается так. Есть базовый, не изменяемый функционал. И создаются новые плагины которые расширяют базовый функционал не затрагивая базовый класс. Базовый класс изменять условно нельзя.
В таком случае нужно сразу сказать что дополнительные поля из плагинов не должны быть обязательными для заполнения, иначе они могут поломать базовый функционал.
Я вижу 2 пути решения проблемы. Вариант с хранением в БД JSON я не рассматриваю потому что это… извращение. В таком случает лучше сразу хранить все данные в документоориентированных СУБД.
1. Создание отдельной таблицы с дополнительными полями необходимыми для плагина и сделать связь с базовой таблицей OneToOne.
Преимущества:
Ни базовый класс, ни базовая таблица никак не затрагиваются. Новая сущность существует параллельно с базовой. Доступ осуществляется так:
$customer_ref->getCustomer()->getId();
$customer_ref->getRef();
Недостатки:
Нет возможности получить сущность плагина из базовой сущности. Так как мы не можем изменять базовый класс, следующий вариант работать не будет:
$customer->getCustomerRef()->getRef();
Нужно создавать еще одну таблицу и делать JOIN для выбора дополнительных данных
2. Расширить функционал базового класса через extends и новые поля из класса CustomerRef должны просто игнорироваться движком.
Преимущества:
Просто в реализации. Код будет выглядеть так:
$customer->getId();
// $customer->getRef(); // no work
$customer_ref->getId();
$customer_ref->getRef();
Недостатки:
Опять же нельзя получить поля плагина из базового класса.
Усложняется разработка движка который будет отвечать за загрузку/сохранение данных. При неправильной реализации могут потеряться значения дополнительных полей CustomerRef при сохранении объекта как Customer.
Итог
Оба варианты рабочие, но не применимы для тех случаев когда нужно получить дополнительные поля из оригинального объекта. Это не страшно в тех случаях если плагины используются только для создания новой функциональности и фатально для тех случаев когда нужно переопределить базовую функциональность.
Ваше решение с DataObject позволяет получить дополнительные поля из базового класса, хотя автодополнение в IDE работать не будет.
PS: надо отметь что отсутствие возможности получить поля плагина из базового класса не всегда является минусом. В некоторых случаях это позволяет избежать ошибок.
Из вас всю информацию приходится прям клещами вытягивать.
Ну я же не знаю, чего не знаете вы :) С моей колокольни все это вполне укладывается в следствие из «слабосвязанные команды разработчиков»
В целом достаточно верно.
В таком случае нужно сразу сказать что дополнительные поля из плагинов не должны быть обязательными для заполнения, иначе они могут поломать базовый функционал.
Не совсем так, возможен вариант, когда плагин добавляет обязательные поля в БД, а также на web-форму добавления/редактировния соотв. сущности (в UI).
Создание отдельной таблицы с дополнительными полями необходимыми для плагина и сделать связь с базовой таблицей OneToOne.
Отличная идея! Без преувеличения (просто в Magento это сделано слегка не так). Я бы даже смотрел в сторону создания отдельной таблицы для каждой колонки (атрибута сущности; так сказать, максимальное приближение к «6-й нормальной форме»), но количество неизведанного геморроя заставляет останавливаться на 3NF (вернее, не отрываться от нее достаточно далеко).
Нет возможности получить сущность плагина из базовой сущности.
Именно так. Поэтому и производные от DataObject, структурирующие «просто данные» под текущие условия использования.
Нужно создавать еще одну таблицу и делать JOIN для выбора дополнительных данных
Это да, есть такая беда. Можно для облегчения жизни задействовать views (а в postgres'е даже и materialized views), но без автоматизации сборки/разборки объектов по-атрибутно это будет условно-досрочное облегчение. А уж как БД админы будут благодарны девелоперам…
Кстати, если во втором варианте положить, что все объекты данных наследуют от DataObject (CustomerRef extends Customer extends DataObject), то это и будет то, о чем я и пытался сказать:
$customer->getId();
$customer->getRef(); // works, but autocomplete doesn't
$customer_ref->getId();
$customer_ref->getRef();
Другое дело, что обращение к ref-атрибуту в контексте базовой сущности не имеет смысла — этот атрибут вводится только в ref-плагине. Но если базовый функционал загрузил все доступные атрибуты сущности «Клиент» и передал их в ref-плагин, то в ref-плагине достаточно создать новый ref-объект на основании данных базового и autocomplete заработает (т.к. это уже будет другой объект с теми же данными, можно сказать — другая проекция данных на типизированный объект). В PHP можно даже просто проаннотировать тип переменной/аргумента, без реального изменения его типа, и autocomplete будет работать. Создание нового объекта на основании данных базового — это для строго типизированных языков.
надо отметь что отсутствие возможности получить поля плагина из базового класса не всегда является минусом. В некоторых случаях это позволяет избежать ошибок.
Я бы даже сказал, что так должно быть всегда, когда это делается не из контекста самого плагина (или других плагинов, на нем базирующихся).
Ну я же не знаю, чего не знаете вы :)
Я, как и другие пользователи хабра, не знаем ничего. Абсолютно ничего о вашем проекте и о проблемах с которыми вы сталкиваетесь.
Подведем итоги:
1. Вам нужно было в статья привести пример проблемы который вы озвучили в комментариях, тогда бы ваша статья была бы понятней и не вызвала бы такую бурю негативных эмоций. Ваше решение, в отрыве от решаемой им проблемы, выглядит бессмысленно и бесполезно.
2. Кроме вашего DataObject есть и другие методы решения описанной проблемы, но в целом оно вполне имеет право на жизнь.
Спасибо за интересную дискуссию. На этой замечательной ноте предлагаю закруглится.
Почему же «слегка не так»?Создание отдельной таблицы с дополнительными полями необходимыми для плагина и сделать связь с базовой таблицей OneToOne.Отличная идея! Без преувеличения (просто в Magento это сделано слегка не так).
В основном только так все нормальные разработчики плагинов для Magento и поступают!
Для того чтобы заполнить (при загрузке объекта) дополнительные (добавленные в плагине) атрибуты из такой отдельной таблицы (созданной плагином) в коде плагина отслеживается событие модели объекта: *_load_after, а для того чтобы сохранить их в тоже же таблице событие: *_save_before
а для того чтобы сохранить их в той же таблице событие: *_save_after
Потому что в базовой реализации для работы с сущностями и их атрибутами была заложена EAV-модель.
Посмотрите таблицы:

на примере того же Клиента:
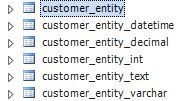
Посмотрите таблицы:

на примере того же Клиента:

Да. Причем попытаться уложиться в несколько экранов.
То есть вы считаете, что статья — самоценна?
Слышал
Тогда чем суть вашего подхода отличается от функциональной парадигмы?
Если DTO не зависит от типа переносимых данных — да, это он и есть.
DTO бывает разный. DTO, как паттерн, не заивисит от типа переносимых данных.
SOA — не понимаю, о чем это.
Вы не знаете, что такое service-oriented architecture?
мухи (код обработчиков) отдельно, а котлеты (обрабатываемые данные) — отдельно.
Повторюсь еще раз: зачем для этого универсальный «контейнер данных»?
А если «мухи» и/или «котлеты» будут в виде типизируемых объектов — так оно даже и лучше.
… а тогда никакого универсального контейнера тоже не будет.
1. Да. Теперь мои мысли приобрели форму ссылки. Это удобно.
2. В некотором смысле этот подход является следствием функциональной парадигмы.
3. В таком случае «DTO — как паттерн» можно использовать в качестве универсального контейнера данных;
4. Знаю.
5. Чтобы не смешивать данные и обрабатывающий их код — как в DTO.
6. Если типизируемый объект позволит добавлять к себе любую структуру данных и выдавать ее — то он и будет являться универсальным контейнером. Именно это и позволяют делать объекты, наследующие от DataObject.
2. В некотором смысле этот подход является следствием функциональной парадигмы.
3. В таком случае «DTO — как паттерн» можно использовать в качестве универсального контейнера данных;
4. Знаю.
5. Чтобы не смешивать данные и обрабатывающий их код — как в DTO.
6. Если типизируемый объект позволит добавлять к себе любую структуру данных и выдавать ее — то он и будет являться универсальным контейнером. Именно это и позволяют делать объекты, наследующие от DataObject.
Да. Теперь мои мысли приобрели форму ссылки. Это удобно.
Когда программист использует — или придумывает — какой-то подход, он делает это, чтобы решить конкретную задачу (или группу задач). Какую задачу решали вы?
В некотором смысле этот подход является следствием функциональной парадигмы.
Чем он от нее отличается?
В таком случае «DTO — как паттерн» можно использовать в качестве универсального контейнера данных;
Нет, нельзя. DTO — это конкретный паттерн, используемый в конкретных случаях.
Знаю
Тогда чем предлагаемое вами решение «для гетерогенного приложения» отличается от SOA?
Чтобы не смешивать данные и обрабатывающий их код — как в DTO.
Универсальный контейнер данных для этого не нужен. Достаточно любого способа обработки структурированных данных (которых, заметим, в любом приличном функциональном языке есть из коробки).
Если типизируемый объект позволит добавлять к себе любую структуру данных и выдавать ее — то он и будет являться универсальным контейнером.
В этот момент он перестал быть типизируемым — потому что «любая структура данных» противоречит типизации (статической, понятное дело).
Повторюсь еще раз: чем предлагаемый вами подход «по отделению обрабатываемых данных от обработчиков» отличается от обычного функционального программирования?
1. Я решал задачу уменьшения сложности при производстве ПО.
2. Функциональная парадигма делает акцент на вычислениях, я же делаю ацент на данных. В обоих случаях рассматривается один и тот же посыл — «отделение данных от инструкций», который был предложен еще 70-80 лет назад Говардом Эйкеном.
3. В таком случае DTO нельзя использовать как «универсальный контейнер данных».
4. Не отличается, но дополняет — вводит расширяемость на уровне данных в «чётко определённые интерфейсы» SOA.
5. «Универсальный контейнер данных» — это более узкий термин, чем «любой способ обработки структурированных данных». «Контейнер» подразумевает краткосрочное хранение при передаче, «универсальный» подразумевает независимость от содержимого, «данные» подразумевают данные. Это все равно спросить «Зачем вводить понятие 'функционального программирования', когда уже есть всем понятный термин 'программирование'».
6. В таком случае, типизируемый объект не может являться универсальным контейнером данных.
7. См. п.2
2. Функциональная парадигма делает акцент на вычислениях, я же делаю ацент на данных. В обоих случаях рассматривается один и тот же посыл — «отделение данных от инструкций», который был предложен еще 70-80 лет назад Говардом Эйкеном.
3. В таком случае DTO нельзя использовать как «универсальный контейнер данных».
4. Не отличается, но дополняет — вводит расширяемость на уровне данных в «чётко определённые интерфейсы» SOA.
5. «Универсальный контейнер данных» — это более узкий термин, чем «любой способ обработки структурированных данных». «Контейнер» подразумевает краткосрочное хранение при передаче, «универсальный» подразумевает независимость от содержимого, «данные» подразумевают данные. Это все равно спросить «Зачем вводить понятие 'функционального программирования', когда уже есть всем понятный термин 'программирование'».
6. В таком случае, типизируемый объект не может являться универсальным контейнером данных.
7. См. п.2
Я решал задачу уменьшения сложности при производстве ПО.
Каким образом ваше решение уменьшает сложность?
Функциональная парадигма делает акцент на вычислениях, я же делаю ацент на данных.
На основании чего вы делаете такое утверждение о функциональной парадигме? В чем конкретно выражается ваш «акцент на данных»?
В таком случае DTO нельзя использовать как «универсальный контейнер данных».
Но при этом DTO полностью удовлетворяет задаче «по отделению обрабатываемых данных от обработчиков, что, на мой взгляд, является одним из краеугольных камней при распределенной разработке (слабосвязанными командами разработчиков) гетерогенных программных систем (типичный пример — web-приложение), интегрированных с внешними сервисами посредством SOAP/REST и адаптируемых конечным пользователем под изменяющиеся условия применения.»
Не отличается, но дополняет — вводит расширяемость на уровне данных в «чётко определённые интерфейсы» SOA.
А почему вы думаете, что в SOA (а) четко определенные интерфейсы и (б) нет расширяемости на уровне данных? Вы знаете, как расшифровывается XML?
«Универсальный контейнер данных» — это более узкий термин, чем «любой способ обработки структурированных данных». [...] Это все равно спросить «Зачем вводить понятие 'функционального программирования', когда уже есть всем понятный термин 'программирование'».
Вы не поняли. Речь не о вводе термина, а о том, что для решения задачи достаточно любого способа структурирования данных. Какие преимущества появляются именно от вашего «универсального контейнера»?
В таком случае, типизируемый объект не может являться универсальным контейнером данных.
Именно. Но при этом полностью удовлетворяет описанной задачи.
1. А разве это не очевидно?
вместо
Даже визуально видно, что сложность уменьшилась минимум в 2 раза.
2. На основании названия.
3. Если DTO полностью удовлетворяет условиям, значит его можно использовать в качестве «универсального контейнера данных».
4. Если есть расширяемость на уровне данных, то значит в SOA уже используется концепция «универсального контейнера данных». Да, я знаю, как расшифровывается XML.
5. Нет, это вы не поняли. Если вы используете любой способ структурирования данных для формирования «посылки» с произвольным содержимым, то вы таким образом создаете «универсальный контейнер данных». Даже если сами об это не подозреваете. А я просто обращаю ваше внимание на этот аспект «обработки структурированных данных». Вы могли всю жизнь программировать в определенном стиле, не подозревая об этом, а потом я пришел и сообщил, что для вашего стиля характерны определенные черты, и дал ему название «функциональное программирование».
6. Если он полностью удовлетворяет, то является.
/**
* @method array getBaseCalcData()
* @method void setBaseCalcData(array $data)
*/
вместо
private $_baseCalcData;
public function getBaseCalcData() {
return $this->_baseCalcData;
}
public function setBaseCalcData(array $data) {
$this->_baseCalcData = $data;
}
Даже визуально видно, что сложность уменьшилась минимум в 2 раза.
2. На основании названия.
3. Если DTO полностью удовлетворяет условиям, значит его можно использовать в качестве «универсального контейнера данных».
4. Если есть расширяемость на уровне данных, то значит в SOA уже используется концепция «универсального контейнера данных». Да, я знаю, как расшифровывается XML.
5. Нет, это вы не поняли. Если вы используете любой способ структурирования данных для формирования «посылки» с произвольным содержимым, то вы таким образом создаете «универсальный контейнер данных». Даже если сами об это не подозреваете. А я просто обращаю ваше внимание на этот аспект «обработки структурированных данных». Вы могли всю жизнь программировать в определенном стиле, не подозревая об этом, а потом я пришел и сообщил, что для вашего стиля характерны определенные черты, и дал ему название «функциональное программирование».
6. Если он полностью удовлетворяет, то является.
А разве это не очевидно?
Нет, не очевидно. Сравните оба ваших варианта с:
object[] BaseCalcData {get; set;}
И, заметим, никакого универсального контейнера (
object там только потому, что я не знаю, какой именно у вас тип под массивом).На основании названия.
Название обманчиво. LISP, весь из себя насквозь функциональный, чуть более чем полностью состоит из структур данных.
Если DTO полностью удовлетворяет условиям, значит его можно использовать в качестве «универсального контейнера данных».
Нет. Напомню задачу: «отделение обрабатываемых данных от обработчиков, что [...] является одним из краеугольных камней при распределенной разработке [...] гетерогенных программных систем [...], интегрированных с внешними сервисами посредством SOAP/REST и адаптируемых конечным пользователем под изменяющиеся условия применения». В этой задаче прекрасно используется строго типизованный DTO.
Если есть расширяемость на уровне данных, то значит в SOA уже используется концепция «универсального контейнера данных».
В SOA может использоваться «универсальный контейнер». Намного чаще там используется практика «игнорирую то, чего не знаю».
Если вы используете любой способ структурирования данных для формирования «посылки» с произвольным содержимым, то вы таким образом создаете «универсальный контейнер данных».
Нет. Когда я сериализую число в бинарный поток, я формирую сообщение с произвольным содержимым, но я не создаю никакого универсального контейнера. Более того, даже когда я использую ассоциативный массив — я использую именно ассоциативный массив, и то, что вам хочется назвать его «универсальным контейнером», никак не отменяет того, что это просто ассоциативный массив.
1. Сравнил. Это точно не PHP.
2. Я имел в виду не LISP, я имел в виду именно «функциональное программирование».
3. «Строго типизированный» DTO не удовлетворяет условию «распределенной разработки» — там по определению не может быть строгой типизации.
4. Практика «игнорирую то, чего не знаю» весьма хорошо сочетается с «универсальным контейнером».
5. То, что это ассоциативный массив никак не отменяет того, что он может использоваться в качестве «универсального контейнера данных».
2. Я имел в виду не LISP, я имел в виду именно «функциональное программирование».
3. «Строго типизированный» DTO не удовлетворяет условию «распределенной разработки» — там по определению не может быть строгой типизации.
4. Практика «игнорирую то, чего не знаю» весьма хорошо сочетается с «универсальным контейнером».
5. То, что это ассоциативный массив никак не отменяет того, что он может использоваться в качестве «универсального контейнера данных».
Сравнил. Это точно не PHP.
А какая разница? Или ваш подход применим только и исключительно к PHP?
Я имел в виду не LISP, я имел в виду именно «функциональное программирование».
Покажите мне функциональный язык (из мейнстрима), в котором нет обширной поддержки структур данных.
«Строго типизированный» DTO не удовлетворяет условию «распределенной разработки» — там по определению не может быть строгой типизации.
Это почему это не может? Если все стороны договорились о четкой структуре сообщений, которыми они обмениваются, получается строгая типизация.
Практика «игнорирую то, чего не знаю» весьма хорошо сочетается с «универсальным контейнером».
Это, однако, не означает, что в SOA используется «универсальный контейнер».
То, что это ассоциативный массив никак не отменяет того, что он может использоваться в качестве «универсального контейнера данных».
Может, но какой от этого выигрыш?
1. Нет, подход не исключительно для PHP. Но я не могу сказать, какая разница, потому что я не понимаю, что вы написали. Раз уж вы задаете вопросы по статье, я полагаю, вы ее прочитали. Вопросов по PHP у вас не возникло — я делаю вывод, что этот язык вам знаком. А раз знаком, значит вы можете изложить свои мысли на нем. В конце концов, джентельмены во время дуэли оружие не меняют, а мы начали с PHP.
2. Я сделал вывод о том, что «функциональная парадигма делает акцент на вычислениях» на основании названия этой самой парадигмы, вы в свою очередь сказали, что «название обманчиво» и привели в качестве примера LISP. Я обратил ваше внимание на то, что мы говорим не про LISP, а именно про «функциональную парадигму» и в данном конкретном случае название вполне соответствует сути:
А теперь вы предлагаете мне показать функциональный язык (из мейнстрима), в котором нет обширной поддержки структур данных.. Похоже, вы просто потеряли нить обсуждения.
3. Потому что при распределенной разработке вполне возможен вариант, когда разработчики не могут договориться друг с другом просто в силу того, что они не знакомы друг с другом. Более того, я спорадически интегрирую такие решения друг с другом. Это Magento.
4. Но это и не означает обратного.
5. Если вы не видите выигрыша, то вам не и стоит этого делать. Если вдруг увидите выигрыш — тогда и применяйте.
2. Я сделал вывод о том, что «функциональная парадигма делает акцент на вычислениях» на основании названия этой самой парадигмы, вы в свою очередь сказали, что «название обманчиво» и привели в качестве примера LISP. Я обратил ваше внимание на то, что мы говорим не про LISP, а именно про «функциональную парадигму» и в данном конкретном случае название вполне соответствует сути:
Функциона́льное программи́рование — раздел дискретной математики и парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
А теперь вы предлагаете мне показать функциональный язык (из мейнстрима), в котором нет обширной поддержки структур данных.. Похоже, вы просто потеряли нить обсуждения.
3. Потому что при распределенной разработке вполне возможен вариант, когда разработчики не могут договориться друг с другом просто в силу того, что они не знакомы друг с другом. Более того, я спорадически интегрирую такие решения друг с другом. Это Magento.
4. Но это и не означает обратного.
5. Если вы не видите выигрыша, то вам не и стоит этого делать. Если вдруг увидите выигрыш — тогда и применяйте.
Но я не могу сказать, какая разница, потому что я не понимаю, что вы написали.
А написал я код, семантически эквивалентный вашему. Он декларирует свойство
BaseCalcData с типом «массив объектов».Вопросов по PHP у вас не возникло — я делаю вывод, что этот язык вам знаком. А раз знаком, значит вы можете изложить свои мысли на нем.
А на PHP такое невозможно.
Я обратил ваше внимание на то, что мы говорим не про LISP, а именно про «функциональную парадигму» и в данном конкретном случае название вполне соответствует сути:
Вы, похоже, не понимаете устройства функционального программирования. Здесь я могу только посоветовать вам почитать SICP, пересказывать его у меня нет никакой охоты.
Потому что при распределенной разработке вполне возможен вариант, когда разработчики не могут договориться друг с другом просто в силу того, что они не знакомы друг с другом.
Есть некоторая разница между «возможен вариант, что разработчики не могут договориться» и «в распределенной разработке по определению не может быть контракта».
Дополнение по пункту 3: первых 4 плагина как раз и занимаются поиском подобных конфликтов.
Так вы еще и о распределенной разработке в рамках одной системы, на самом деле? Тогда спешу вас расстроить: достаточно взять (и последовательно применять) строго типизированный язык — и вы получите строгую типизацию вне зависимости от степени «распределенности» разработки. Другое дело, что у вас в руках PHP…
Если вы не видите выигрыша, то вам не и стоит этого делать.
Угу. Более того, я смею утверждать, что выигрыша в общем случае и нет.
1. Ваш «семантически эквивалентный код» ни в коем разе не опровергает мой демонстрационный пример, что предложенный подход сокращает кол-во строк кода минимум в 2 раза для программ на PHP.
2. Если это невозможно сделать на PHP, то попробуйте изложить ваши мысли на Java/C/JavaScript/Python. У меня есть кое-какой опыт в этих языках и, надеюсь, я смогу понять, что вы хотите донести.
3.Т.е., вы утверждаете, что название «функциональная парадигма» не отражает сути?
4. Согласен, разница есть. Считайте, что я привел пример для случая, когда разработчик базового функционала ничего не знает о разработчиках плагинов, а разработчики плагинов знают только базовый функционал и не могут никаким образом повлиять ни на него, ни друг на друга.
5. Спешу вас расстроить а) PHP вполне позволяет строго использовать типизацию, б) вы все еще не поняли, что даже самая расстрогая типизация не дает возможности создавать изолированным командам разработчиков общее приложение, даже наоборот — мешает.
6. В самом общем случае вообще ничего нет — есть и такая теория.
2. Если это невозможно сделать на PHP, то попробуйте изложить ваши мысли на Java/C/JavaScript/Python. У меня есть кое-какой опыт в этих языках и, надеюсь, я смогу понять, что вы хотите донести.
3.Т.е., вы утверждаете, что название «функциональная парадигма» не отражает сути?
4. Согласен, разница есть. Считайте, что я привел пример для случая, когда разработчик базового функционала ничего не знает о разработчиках плагинов, а разработчики плагинов знают только базовый функционал и не могут никаким образом повлиять ни на него, ни друг на друга.
5. Спешу вас расстроить а) PHP вполне позволяет строго использовать типизацию, б) вы все еще не поняли, что даже самая расстрогая типизация не дает возможности создавать изолированным командам разработчиков общее приложение, даже наоборот — мешает.
6. В самом общем случае вообще ничего нет — есть и такая теория.
Ваш «семантически эквивалентный код» ни в коем разе не опровергает мой демонстрационный пример, что предложенный подход сокращает кол-во строк кода минимум в 2 раза для программ на PHP.
А для других языков не сокращает. Я потому и спрашиваю: ваш подход оправдан только для PHP?
Если это невозможно сделать на PHP, то попробуйте изложить ваши мысли на Java/C/JavaScript/Python.
Приведенный мной код — на C#. Этого достаточно, я думаю.
Т.е., вы утверждаете, что название «функциональная парадигма» не отражает сути?
Я утверждаю, что функциональная парадигма программирования всегда неразрывно связана со структурами данных.
Считайте, что я привел пример для случая, когда разработчик базового функционала ничего не знает о разработчиках плагинов, а разработчики плагинов знают только базовый функционал и не могут никаким образом повлиять ни на него, ни друг на друга.
То есть для других случаев гетерогенных приложений ваш подход не имеет смысла?
PHP вполне позволяет строго использовать типизацию
… на этапе выполнения. Есть разница.
вы все еще не поняли, что даже самая расстрогая типизация не дает возможности создавать изолированным командам разработчиков общее приложение, даже наоборот — мешает.
Каким образом она мешает?
(как помогает — понятно: определяем общие интерфейсы, в рамках которых могут существовать плагины, и можем быть уверенными, что контроль типов не позволит нам выйти за их рамки)
Дополнение по пункту 3: первых 4 плагина как раз и занимаются поиском подобных конфликтов. Которые возникают как раз вследствие того, что большинство разработчиков плагинов друг с другом элементарно не знакомы.
НЛО прилетело и опубликовало эту надпись здесь
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Универсальный контейнер данных