

Концепция программно-определяемых ЦОД появилась очень давно. Тем не менее, на практике мало что было реализовано и работало, разве что у IaaS-провайдеров. По факту чаще всего была обычная виртуализация. Теперь же можно шагнуть дальше на стеке VMware, а можно реализовать всё на Openstack — тут придётся думать головой и взвешивать много факторов.
За прошлый год мы увидели очень существенный технологический скачок в плане применения SDDC в обычной сисадминской практике. Теперь есть проверенные технологии и виртуализации сетей, и виртуализации систем хранения данных в виде нормальных инструментов. И от этого можно получить реальную пользу для бизнеса.
Зачем это нужно? Очень просто: начиная с автоматизации рутины, отвязывания зависимости от физического железа; точно знать потребление каждого ресурса; знать до копейки, и заканчивая тем куда и как идут деньги в IT-бюджете. Последние две причины лежат немного за пределами обычных админских целей, но очень полезны для CIO или сисадминов среднего и крупного бизнеса, рассчитывающих на полное взаимопонимание с коммерческим отделом. И премию, чего уж там.
Начнём с истории
В 60-х годах IBM пошла по правильному пути, решив, что мейнфреймы будут рулить. Появилась виртуализация как таковая. В 80-х появление стандарта IBM PC создало ситуацию, когда можно было купить десяток машин, а не вкладываться в инфраструктуру капитально. Уже в 1990 начался массовый переход от централизованной к децентрализованной архитектуре. Только в конце 90-х появилась более-менее успешная виртуализация на базе этой самой х86-архитектуры. В 2000-е началось серьёзное коммерческое внедрение виртуализации крупными компаниями. Через примерно пять лет стали появляться новые технологии VDI, виртуализации приложений и SDN. В 2010-м началась серьёзная поддержка SDN-подхода в оборудовании для дата-центров. Сейчас мы видим, что SDN и SDS – программно-определяемые сети, и хранилища – становятся необходимостью и вместе с виртуализацией вычислений складываются в концепцию SDDC – программно-определяемого дата-центра.
Сегодня главное — консолидация вычислительных ресурсов (когда всё железо рассматривается через платформу виртуализации как общая ёмкость для вычислений, хранения и передачи данных). Затем в приоритетах – катастрофоустойчивые решения от обычных резервных ЦОДов до «растянутых» ЦОДов. Наш опыт в этой истории такой: крупной рознице в большинстве случаев нужны резервные решения, госпредприятиям нужно хранить много данных, поэтому в приоритете виртуальные СХД под большие объемы, банкам нужно все что оптимизирует работу и позволяет учитывать затраты.
Сейчас нужно сказать, что на глобальном уровне начинается новый виток развития именно SDN. Некоторые зарубежные операторы начали смотреть на SDN и NFV как реальную замену текущим хардварным решениям, вырастили свои команды для SDDC внутри, но у наших же операторов эта история впереди.
Про SDS я уже писал в прошлом посте, немного концептуальных слов слов о SDN напишу тут. Думаю, немного позднее у нас будет более развернутая статья про эту часть.
Суть SDN подхода
Основная особенность стека – абстракция от железа, и, как следствие, абстракция всех политик обслуживания, возможностей и фич, уход от проблем совместимости и масштабирования. Горизонтальное масштабирование становится простым как никогда.
Ниже представлен знакомый всем проверенный временем подход к построению сети.

А на следующей картинке SDN-подход, по сути мы просто берем и выносим модуль управления или Data plane со всех сетевых устройств в одно место, естественно резервируя его. Тем самым превращая всю сетевую инфраструктуру в один «большой коммутатор» в качестве интерфейсных модулей которого могут выступать физические коммутаторы от различных вендоров, физические серверы с различными гипервизорами и виртуальными коммутаторами на них, и т.д.

Вот в общем-то и весь подход.
Дальше — зачем SDDC все-таки нужно. Возможно, все это с разных сторон озвучено, и вы это слышали, тогда считайте, что мы просто согласны и слышали это в том числе от наших заказчиков.
Автоматизация рутины
Все ее решают сейчас по-разному. Кто-то создает системы управления, кто-то пишет скрипты. Но я думаю любому админу хочется так, чтобы не нужно было по 100 раз в день создавать виртуалку, размечать луны, или устанавливать операционку если вдруг оно срочно понадобилось.
Предположим ИТ-отдел работает по заявкам от потребителей сервисов. Сегодня вам нужно создать один сервер, и это просто и быстро. Завтра — уже 20. При этом всем нужно прописать адреса, создать сети скоммутировать, маршрутизировать и так далее. А еще СХД выделить. Хорошо, что сейчас есть виртуалки, и часто вам нужно только прощелкать кнопочки. Но часто и это не всегда рационально. Мы, например, знаем это по своей лаборатории тестирования, в которой обычно порядка 300-500 виртуальных машин работают одновременно. А для потребителей медленная инициализация часто выглядит как простои и отказ сервиса, идут постоянные нарекания.
По словам VMware, автоматизация – это примерно 40% причин покупки их проприетарного стека для SDDC.
Управление ресурсами
Когда в любой момент вы можете построить отчет о том, что у вас работает, кто владелец, как интенсивно используется тот или иной ресурс и так далее. Это и инвентаризация оборудования и ПО, управление доступом к ресурсам. А представьте себе, сколько у вас может быть уже «мертвых» ВМ которые разбросаны по разным уголкам инфраструктуры? Как их отыскать и понять нужны ли они?
Вот допустим приходит к вам директор и спрашивает: «Зачем вы в этом году потратили 3 миллиона рублей на оборудование и софт?» Что вы делаете в такой ситуации? Как показать руководству, сколько ресурсов есть, кто их использует, по отделам или системам? А сколько вообще то свободно? Как ответить на вопросы вроде: «А сколько нам стоит по IT открыть новый филиал?», «А как сравнить аутсорс вот этого сервиса и его использование внутри?».
Каждый год ИТ-отдел согласует бюджет на развитие. Вы допустим, понимаете, что вот эта СХД за 1 миллион долларов очень нужна и без нее никак. Как показать это бизнесу? Нужно оперировать потреблением, а его нужно не просто считать, но и детализировать до конкретных отделов и сервисов.
Управление стоимостью
Это, наверное, самое главное и интересное для бизнес-пользователей, что может сейчас дать SDDC. Оно позволит руководству знать сколько и какие ресурсы используются на реализацию той или иной ИТ-функции. Будь то банальная почта, CRM, или ERP система… Кроме того можно облако интегрировать напрямую с этими системами, чтобы, например, стоимость СХД распределялась по мере ее использования между подразделениями. На что конкретно идут деньги, на ERP, или на CRM, в каких долях и так далее? А ещё такое понимание важно, когда нужно купить какую-то инфраструктурную штуку, и она совсем явно ни на кого не влияет.
Основная задача: превратить ИТ-инфраструктуру в бизнес-подразделение, которое предоставляет сервисы остальным подразделениям компании. Представьте, вы предоставляете ресурсы и вам за них платят «деньги», и в результате вы автоматически этот «доход» тратите на модернизацию и обеспечение работы ИТ, вызывая меньше вопросов у руководства. Поскольку в любой момент есть возможность показать – а кому собственно нужна эта ИТ и насколько. Именно такая модель наиболее понятна коммерческим отделам – фактически, они работают так со всеми подразделениями, оценивая их в модели генерации прибыли.
Оцените, насколько сложно сейчас узнать, сколько ресурсов (а значит и денег) было потрачено на тестирование и внедрение конкретной функции? Сколько будет стоить обслуживание каждой из бизнес-систем, с учетом всех используемых ресурсов?
Экосистема полноценного облака
Как, думаю, уже понятно, облако — это не только и не столько виртуализация вычислений (что как раз самое простое в IaaS), а ещё и программно-определяемая сеть и программно-определяемые хранилища. Про SDS можно прочитать вот здесь в большом ликбезе (https://habrahabr.ru/company/croc/blog/272795/). Если коротко, мы используем все типы хранения в сети включая серверы с дисками, «классические» централизованные СХД и другие типы библиотек, и объединяем всё это в одну виртуальную хранилку, которая умеет и правильно балансировать данные, и обеспечивать более правильное хранение «холодных» и «горячих» баз, и выжимать всё возможное из железа, вплоть до использования оперативной памяти серверов как кэша СХД. В этом суть, в этом стратегия: довольно скоро без таких решений, похоже, будут обходиться только ультрагомогенные дата-центры от одного вендора.
С SDN немного сложнее. Здесь вся сеть как таковая управляется программно. Любой узел может быть переопределён в любой момент.
Open source VS проприетарный подход
Есть 2 пути построения облака:
- Проприетарный. То есть предположим, что уже сделаны существенные вложения в платформу на VMware. И вы продолжаете развивать облако используя то, что предлагает или рекомендует вендор.
- Гибридный. Вы можете зафиксировать текущую инфраструктуру. И поверх нее создать облачное решение на базе Openstack. Чаще всего, такой путь начинается с того, что у вас уже есть хороший виртуализатор (как правило, это VMware или KVM), вокруг которого выстраивается стек открытого ПО. Как правило, крупные игроки идут к этому.
Все понимают, что VMware сейчас под своим зонтиком собрал огромное количество технологий и уверенно продолжает их разработку. Но и открытые решения не отстают, как показывает практика. Чего стоит только то, что и сам VMware выпустил и ведет разработку собственной версии Openstack, которая имеет набор функциональных возможностей по работе именно в среде VMware. Как раз как система управления облаком.
То есть второй путь фактически легализован.
При этом использование именно вмварной версии не требуется. Особенно если вы в дальнейшем планируете отказаться от VMware в целом, существенно сокращая затраты.
Тем не менее, далее пара-тройка фич, которые могут сыграть роль при выборе.
Проприетарные вендоры, на примере VMware
В VMware собрали под единым брендом продукты на базе которых можно собрать полноценный программно-определяемый ЦОД, то есть SDDC. Плюс вокруг VMware работает целая экосистема технологических партнеров, которые расширяют возможности ПО.
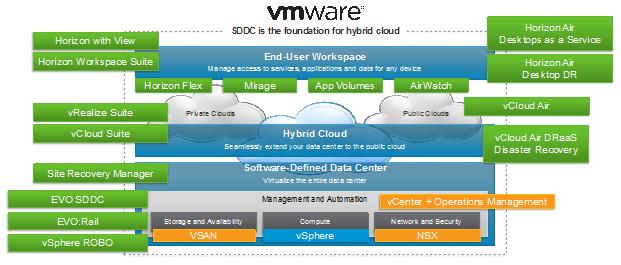
- Платформа виртуализации vSphere на сегодняшний день являющаяся фактически стандартом «де-факто» при построении виртуальных инфраструктур в Enterprise-сегменте, с релизом 6-й версии (чуть менее года назад) получила возможность перемещать виртуальные машины без остановки даже в рамках континента (round trip не должен превышать 100 мс).
- А для того, чтобы организовать единое сетевое пространство прекрасно подойдет продукт для виртуализации сети — VMware NSX. Который по сути сейчас при установке становится частью платформы практически незаметно для админа.
- Для хранения виртуальных машин здесь есть широкие возможности для выбора… У VMware «родные» решения — Virtual Volumes (https://www.vmware.com/products/vsphere/features/virtual-volumes) и Virtual SAN (https://www.vmware.com/products/virtual-san/)
- Про SDS обратите внимание ещё на продукты Atlantis, PernixData и DataCore.
- В качестве самой платформы управления облаком есть линейка vRealize. Это как раз все те продукты которые автоматизируют, дают портал самообслуживания и билинг ресурсов.
Openstack
Опенстек – это опенсурс. Все знают. Для частного облака это может быть крайне полезно. Как раз потому что врядли вы увидите 2 одинаковые реализации облака. Просто потому что организации все разные, свои процессы внутри и культура ИТ.
В итоге есть возможность кастомизации на очень высоком уровне. Важно понимать, что кастомизация достигается путем переписывания или дописывания программного кода, соответственно.
Составные части Openstack, как уверен вы помните, перечислены вот здесь (http://openstack.ru/about/components/). Правда не сильно отличается от VMware, если смотреть с высоты птичьего полета?

Компоненты идеологически все те же. Конечно уровень зрелости каждого из них может отличаться. Но сейчас уже даже телеком операторы говорят, мы будем использовать это. А все специфическое мы подцепим уже потом.
И если с первого взгляда вероятно покажется раз опенсурс, значит привычное корпоративно-энтерпразное вам прикрутить будет сложно. А вот и не так.
Есть и решения по SDN, например, OpenDaylight или OpenContrail, который, кстати, разрабатывается при поддержке Juniper, одного из основных игроков на рынке «традиционного» сетевого оборудования.
Есть SDS, например Datacore имеет возможность работы с Openstack, объединяя и транслируя все уже существующие системы хранения в понятном для Openstack виде.
Допустим, если вам нужен хороший балансировщик, вы можете смело брать F5. У него есть интергация с нейтроном. Есть еще интересный стартап Avi networks. Они делают и SDN, NFV, и балансировщики, так же для Openstack. Да и вообще сейчас хорошим тоном для энтерпрайз софта стала интеграция с Openstack.
Вероятно читатель на этом моменте может подумать, а вот ведь у нас опенсурс. Почему мы опять про платный софт. А это потому что лучше всего рассмативать Openstack как платформу именно облака, то объединяющее звено которое автоматизирует и связывает определенные функции, а не только предоставляет их само. Поскольку именно автоматизация – его основная задача.
Резюме
Есть старый программистский принцип: “работает — не трогай”. Возможно, именно он мешает ИТ-специалистам многих предприятий начать эксперименты с открытым кодом. Но сейчас скачки курса играют против ИТ-бюджетов компаний, при том, что в валюте стоимость программных продуктов западных разработчиков не становится выше. Так что даже задача по сохранению инфраструктуры на имеющемся уровне требует больших финансовых ресурсов, чем раньше. Проще говоря, наконец-то проприетарным быть стало настолько дорого, что это дошло даже до коммерческих отделов.
Поэтому именно сейчас в инфраструктурах наших заказчиков существенно растет доля решений с открытым исходным кодом. И так же думаю поэтому о гибридном пути развития облака задумаются многие.
Поэтому схема действий примерно следующая:
- Может ли компания получить преимущества от технологии SDDC и какие. Для этого нужно понять, например, насколько для вас необходимо персональное или гибридное облако. В лоб оценить не выйдет, причём парадокс в том, что ни ИТ-отдел, ни коммерческий этого внутри себя не сделают – нужно посотрудничать и понять, что для вас важно. Например, ускорение цикла разработки процентов на 30-40% было бы существенно для банка? Наверняка! А этого, в целом, можно добиться правильными тестовыми средами и снятием проблем с выделением ресурсов. Для промышленности с высокой долей ИТ в разработках это ещё важнее. Ускорение вывода инфраструктурных сервисов в работу – звучит круто, но, опять же, напрямую в деньгах оценить может быть сложно на уровне ИТ-отдела.
- Определиться с архитектурой. Если вы уже используете какой-то кусок проприетарного стека, это не повод строить всё на нём, но, отмечу, неоднократно упомянутый VMware, например, имеет кучу коммерческих «приблуд» сторонних производителей, которые превращают всю систему в «закрытый космос», но при этом дают возможность вообще всё делать из одной панели. За деньги. С другой стороны, если в вас есть сила разбираться с Openstack – готовьте напильники, но обойдётся это, возможно, сильно дешевле. Как правило, проприетарный путь – это вариант финансовой организации из-за гарантий вендоров, либо вариант компании, где высока текучка кадров в ИТ-отделе.
- Посчитайте в миниатюре. Увы, но внедрение компонентов SDDC очень сложно сделать «на коленке для проекта N», поскольку это затрагивает всю архитектуру.
- Посмотрите вот эти документы. Это зарубежный опыт, причём вполне успешный и хорошо применимый в российских условиях. Разброс внедрений – от университетов до крупных финансовых организаций, хорошо знакомое прикладное ПО и так далее.
В общем, смотрите:
- Университет — www.mirantis.com/blog/case-study-university-of-hawaii-openstack-private-cloud
- content.mirantis.com/rs/451-RBY-185/images/mirantis-banking-case-study.pdf — «растянутое» решение.
- Циско Вебекс как критичный приклад — content.mirantis.com/rs/451-RBY-185/images/Mirantis_CiscoWebex-case-study.pdf
- Конечно, изменение архитектуры – вопрос не из самых быстрых. Путь этот долгий, но результаты могут очень сильно превзойти ожидания. Инфраструктура такого типа экономит массу денег и ресурсов, но самое главное можно начать перестраивать части инфраструктуры (например, наименее критичные, но все равно требующие ресурсов) прямо сейчас. В этом случае — начинайте собирать данные с коллег, западных друзей и профессиональных форумов.
- Если вы уже готовы, и вам понадобится просчитать что-то «вчерновую» вилкой, я могу помочь на уровне советов и первого приближения – моя почта albelyaev@croc.ru. Кстати, ориентировочно в мае у нас состоится первое админское обучение по Datacore, правда, свободных мест уже нет. Но если кому интересно, пишите в личку или на почту, сообщу о семинаре, как только наберется группа, мы запланируем новый. А 14 апреля проведем расширенный семинар с онлайн-трансляцией на тему оптимизации инфраструктуры с помощью виртуализации сетей/систем хранения данных, VDI и пр. Анонс скоро появится тут.
