Регулярные выражения в JavaScript понемногу догоняют PCRE.
Недавно упомянутая возможность lookbehind перешла на стадию флага --es_staging.
Разработчики V8 также начали добавлять в регулярные выражения свойства Юникода (см. общее описание и спецификацию этой характеристики символов).
В продвижении lookbehind и character properties, на мой взгляд, есть две разницы: первая возможность вводит совсем немного нового синтаксиса по сравнению со второй, зато вторая меньше изменяет поведение всего процесса (сравните количество затрагиваемых изменениями файлов в исходниках V8 по двум упомянутым ссылкам). По сути, свойства Юникода — всего лишь удобные сокращения, синонимы для разных групп codepoint-ов, поэтому от них можно ожидать минимум подвохов при интеграции в систему.
Конечно, обе возможности не советуют применять в продукции (кроме Google Chrome, они нигде в браузерах не реализованы, а Node.js только-только переходит на соответствующую им версию V8, в которой они всё равно пока под флагами).
Но для личных нужд (утилиты по обработке текста и т.д.), мне кажется, они вполне применимы. Возможно, коду разработчиков V8, даже экспериментальному, можно порой доверять с ничуть не большим риском, чем разнообразным библиотекам на npmjs или GitHub.
В Google Chrome, даже в стабильной на текущий момент v50, тестирование можно проводить под флагом:
В Node.js такая возможность появляется с v6.0 (уже есть первые RC):
В Google Chrome v50 и Node.js v6.0 текущая версия V8 ('5.0.71.32') содержит только первую порцию реализации — самый первый коммит от Feb 10, 2016. Но это уже огромный рывок вперёд, он позволяет работать с т.н. общими категориями символов (описание и спецификация). Наполнение категорий символами можно посмотреть здесь.
Пример скрипта для тестирования возможности.
В начале создаётся объект, ключами в котором служат названия категорий, а значениями — по три символа из данной категории. Если категория сборная (то есть просто объединяет в себе несколько других категорий), значением будет функция, объединяющая строки соответствующих категорий. То, что хоть как-то поддаётся внятному отображению, я вводил самими символами; то, что невидимо или сливается (управляющие символы, диакритики и т.д.), вводил при помощи escape-последовательностей.
Потом скрипт перебирает элементы объекта, создаёт из ключа (названия категории) регулярное выражение и тестирует с его помощью значение (строку с примерами). Результат выводится в консоль. Если категория не реализована, выводится сообщение об ошибке (в упомянутых версиях Google Chrome v50 и Node.js v6.0 не реализована всего одна, сборная, категория — \p{LC}, но её легко реализовать вручную при помощи объединения её членов в регулярном выражении; в более поздних версиях V8 это упущение уже исправлено). Если поиск безуспешен, выводится null (в скрипте такое происходит только с категорией \p{Cn}, потому что за ней в принципе не закреплён ни один символ и привести примеры для сопоставления невозможно).
Начало вывода скрипта в Node.js 6.0.0-rc.2 (V8 5.0.71.32 — начальная стадия реализации Unicode character properties):
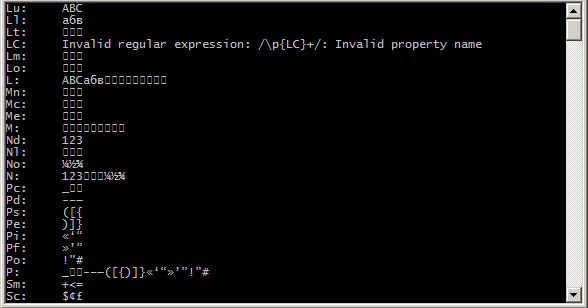
Начало вывода скрипта Google Chrome Canary 52.0.2710.0 (V8 5.2.26 — текущая стадия реализации, обратите внимание на разницу обработки \p{LC}):

Как мы можем видеть из списка реализованного, в Google Chrome Canary можно уже тестировать значительно больший набор возможностей: scripts, loose matching for property names, \p{} in character classes, binary and enumerated properties. Скоро эти элементы доберутся и до Node.
Приятного тестирования и успешного осторожного использования.
PS. Unicode property escapes in JavaScript regular expressions by Mathias Bynens — краткое описание будущей спецификации с примерами и полезными ссылками.
Недавно упомянутая возможность lookbehind перешла на стадию флага --es_staging.
Разработчики V8 также начали добавлять в регулярные выражения свойства Юникода (см. общее описание и спецификацию этой характеристики символов).
В продвижении lookbehind и character properties, на мой взгляд, есть две разницы: первая возможность вводит совсем немного нового синтаксиса по сравнению со второй, зато вторая меньше изменяет поведение всего процесса (сравните количество затрагиваемых изменениями файлов в исходниках V8 по двум упомянутым ссылкам). По сути, свойства Юникода — всего лишь удобные сокращения, синонимы для разных групп codepoint-ов, поэтому от них можно ожидать минимум подвохов при интеграции в систему.
Конечно, обе возможности не советуют применять в продукции (кроме Google Chrome, они нигде в браузерах не реализованы, а Node.js только-только переходит на соответствующую им версию V8, в которой они всё равно пока под флагами).
Но для личных нужд (утилиты по обработке текста и т.д.), мне кажется, они вполне применимы. Возможно, коду разработчиков V8, даже экспериментальному, можно порой доверять с ничуть не большим риском, чем разнообразным библиотекам на npmjs или GitHub.
В Google Chrome, даже в стабильной на текущий момент v50, тестирование можно проводить под флагом:
chrome.exe --js-flags="--harmony_regexp_property"В Node.js такая возможность появляется с v6.0 (уже есть первые RC):
node --harmony_regexp_property test.jsВ Google Chrome v50 и Node.js v6.0 текущая версия V8 ('5.0.71.32') содержит только первую порцию реализации — самый первый коммит от Feb 10, 2016. Но это уже огромный рывок вперёд, он позволяет работать с т.н. общими категориями символов (описание и спецификация). Наполнение категорий символами можно посмотреть здесь.
Пример скрипта для тестирования возможности.
В начале создаётся объект, ключами в котором служат названия категорий, а значениями — по три символа из данной категории. Если категория сборная (то есть просто объединяет в себе несколько других категорий), значением будет функция, объединяющая строки соответствующих категорий. То, что хоть как-то поддаётся внятному отображению, я вводил самими символами; то, что невидимо или сливается (управляющие символы, диакритики и т.д.), вводил при помощи escape-последовательностей.
Потом скрипт перебирает элементы объекта, создаёт из ключа (названия категории) регулярное выражение и тестирует с его помощью значение (строку с примерами). Результат выводится в консоль. Если категория не реализована, выводится сообщение об ошибке (в упомянутых версиях Google Chrome v50 и Node.js v6.0 не реализована всего одна, сборная, категория — \p{LC}, но её легко реализовать вручную при помощи объединения её членов в регулярном выражении; в более поздних версиях V8 это упущение уже исправлено). Если поиск безуспешен, выводится null (в скрипте такое происходит только с категорией \p{Cn}, потому что за ней в принципе не закреплён ни один символ и привести примеры для сопоставления невозможно).
Начало вывода скрипта в Node.js 6.0.0-rc.2 (V8 5.0.71.32 — начальная стадия реализации Unicode character properties):

Начало вывода скрипта Google Chrome Canary 52.0.2710.0 (V8 5.2.26 — текущая стадия реализации, обратите внимание на разницу обработки \p{LC}):

Как мы можем видеть из списка реализованного, в Google Chrome Canary можно уже тестировать значительно больший набор возможностей: scripts, loose matching for property names, \p{} in character classes, binary and enumerated properties. Скоро эти элементы доберутся и до Node.
Приятного тестирования и успешного осторожного использования.
PS. Unicode property escapes in JavaScript regular expressions by Mathias Bynens — краткое описание будущей спецификации с примерами и полезными ссылками.








