В этой статье мы рассмотрим один из вариантов реализации системы частиц на OpenGL ES 2.0. Подробно поговорим об ограничениях, опишем принципы и разберем небольшой пример.

В общем случае, от OpenGL ES 2.0 мы будем требовать два дополнительных свойства (cпецификация не требует их наличия):
Информация по процессорам:
Есть проблема с NVIDIA Tegra 2/3/4, на этой серии работает ряд популярных устройств таких, как Nexus 7, HTC One X, ASUS Transformer.
Рассматривая системы частиц, генерируемые на CPU, в разрезе увеличения количества обрабатываемых данных (количества частиц), основной проблемой производительности становится копирование (выгрузка) данных из оперативной памяти в память видеоутсройства на каждом кадре. Поэтому, наша основная задача — избежать этого копирования, перенеся вычисления в неоперативный режим на графический процессор.
Суть метода заключается в том, чтобы использовать в качестве буфера данных для хранения, характеризующих частицу, величин (координаты, ускорения и т.д.) — текстуры и обрабатывать их средствами вершинных и фрагментных шейдеров. Также, как мы храним и загружаем нормали, говоря о Normal mapping. Размер буфера, в нашем случае, пропорционален количеству обрабатываемых частиц. Каждый тексель хранит отдельную величину (величины, если их несколько) для отдельной частицы. Соответственно, количество обрабатываемых величин находиться в обратной зависимости от количества частиц. Например, для того, чтобы обработать позиции и ускорения для 1048576 частиц, нам понадобиться две текстуры 1024x1024 (елси нет необходимости в сохранение соотношения сторон)
Здесь есть дополнительные ограничения, которые нам необходимо учесть. Чтобы иметь возможность записать какую-либо информацию, формат пиксельных данных текстуры должен поддерживаться реализацией как color-renderable format. Это означает, что мы можем использовать текстуру в качестве цветового буфера в рамках закадровой отрисовки. Спецификация описывает только три таких формата: GL_RGBA4, GL_RGB5_A1, GL_RGB565. Принимая во внимание предметную область, нам требуется как минимум 32 бита на пиксель, чтобы обрабатывать такие величины, как координаты или ускорения (для двухмерного случая). Поэтому, упомянутых выше форматов нам недостаточно.
Для обеспечения необходимого минимума, мы рассмотрим два дополнительных типа текстур: GL_RGBA8 и GL_RGBA16F. Такие текстуры часто называют LDR(SDR) и HDR-текстурами соответственно.
По данным GPUINFO на 2013 — 2015 год поддержка расширений следующая:
Вообще говоря, для наших целей больше подходят HDR-текстуры. Во-первых, они позволяют нам обрабатывать больше информации без ущерба производительности, например, манипулировать частицами в трехмерном пространстве, не увеличивая количества буферов. Во-вторых, отпадает необходимость в промежуточных механизмах распаковки и запаковки данных при чтении и записи соответственно. Но, в силу слабой поддержки HDR-текстур, мы остановим свой выбор на LDR.
Итак, возвращаясь к сути, общая схема того что мы будем делать, выглядит так:
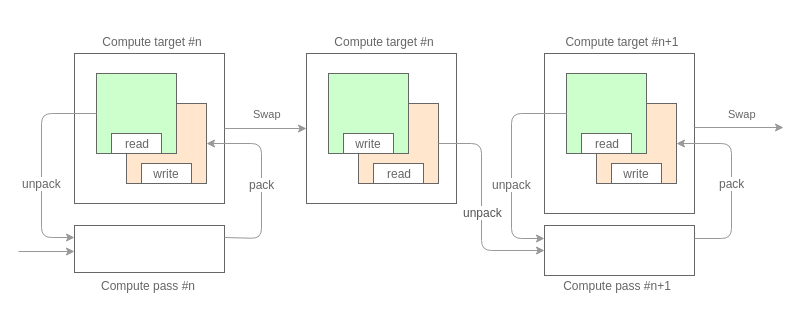
Первое что нам необходимо, это разбить вычисления на проходы. Разбиение зависит от количества и типа характеризующих величин, которые мы собираемся орабатывать. Исходя из того, что в качестве буфера данных у нас выступает текстура и с учетом, описанных выше, ограничений на формат пиксельных данных, каждый проход может обрабатывать не больше 32 бит информации по каждой частицы. Например, на первом проходе мы расчитали ускорения (32 бита, по 16 бит на компоненту), на втором обновили позиции (32 бита, по 16 бит на компоненту).
Каждый проход обрабатывает данные в режиме двойной буферизации. Тем самым обеспечивается доступ к состоянию системы предыдущего кадра.
Ядро прохода, это обычный texture mapping на два треугольника, где в качестве текстурных карт выступают наши буферы данных. Общий вид шейдеров следующий:
Реализация функций распаковки/запаковки зависит от величин, которые мы обрабатываем. На данном этапе мы опираемся на требование, описанное в начале, о высокой точности вычислений.
Например, для двухмерных координат (компоненты [x, y] по 16 бит) функции могут выглядить так:
После этапа вычислений следует этап отрисовки. Для доступа к частицам на этом этапе нам необходим, для перебора, некоторый внешний индекс. В качестве такого индекса будет выступать вершинный буфер (Vertex Buffer Object) с текстурными координатами буфера данных. Индекс создается и инициализируется (выгружается в память видеоустройства) один раз и в процессе не меняется.
На этом шаге, вступает в силу требование о доступе к текстурным картам. Вершинный шейдер похож на фрагментный с этапа вычислений:
В качестве небольшого примера, мы попробуем сгенерировать динамическую систему из 1048576 частиц, известную как Strange Attractor.

Обработка кадра состоит из нескольких этапов:
На этапе вычислений у нас будет всего один независимый проход, отвечающий за позиционирование частиц. В его основе лежит простая формула:
Такая система еще называется Peter de Jong Attractors. С течением времени, мы будем менять только коэфициенты.
На этапе рендеринга сцены, мы отрисуем наши частицы обычными спрайтами.
В заключение, на этапе постобработки, мы наложим несколько эффектов
Gradient mapping. Добавляет цветовое содержание на основе яркости исходного изображения.
Bloom. Добавляет небольшое свечение.
Репозиторий проекта на GitHub.
На данный момент доступны:
На этом примере, мы видим что этап вычислений, этап отрисовки сцены и постобработка состоят из нескольких зависимых между собой проходов.
В следующей части мы постараемся рассмотреть реализацию многопроходного рендеринга с учетом требований, накладываемых каждым этапом.
Буду рад комментариям и предложениям (можно по почте yegorov.alex@gmail.com)
Спасибо!

Ограничения
В общем случае, от OpenGL ES 2.0 мы будем требовать два дополнительных свойства (cпецификация не требует их наличия):
- Vertex Texture Fetch. Позволяет нам получить доступ к текстурным картам через текстурные юниты из вершинного шейдера. Запросить максимальное количество, поддерживаемых графическим процессором, юнитов можно с помощью функции glGetIntegerv с именем параметра GL_MAX_VERTEX_TEXTURE_IMAGE_UNITS. В таблице ниже, представлены данные по популярным, на сегодняшний день, процессорам.
- Fragment high floating-point precision. Позволяет нам производить вычисления с высокой точностью во фрагментном шейдере. Запросить точность и диапазон значений можно с помощью функции glGetShaderPrecisionFormat с именами параметров GL_FRAGMENT_SHADER и GL_HIGH_FLOAT для типа шейдера и типа данных соответственно. Для всех, перечисленных в таблице, процессоров точность состовляет 23 бита с диапазоном значение от -2^127 до 2^127, за исключением Snapdragon Andreno 2xx, для этой серии диапазон значение от -2^62 до 2^62.
Информация по процессорам:
| Процессор | Vertex TIU | Точность | Диапазон |
|---|---|---|---|
| Snapdragon Adreno 2xx | 4 | 23 | [-2^62, 2^62] |
| Snapdragon Adreno 3xx | 16 | 23 | [-2^127, 2^127] |
| Snapdragon Adreno 4xx | 16 | 23 | [-2^127, 2^127] |
| Snapdragon Adreno 5xx | 16 | 23 | [-2^127, 2^127] |
| Intel HD Graphics | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T6xx | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T7xx | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T8xx | 16 | 23 | [-2^127, 2^127] |
| NVIDIA Tegra 2/3/4 | 0 | 0 | 0 |
| NVIDIA Tegra K1/X1 | 32 | 23 | [-2^127, 2^127] |
| PowerVR SGX (Series5) | 8 | 23 | [-2^127, 2^127] |
| PowerVR SGX (Series5XT) | 8 | 23 | [-2^127, 2^127] |
| PowerVR Rogue (Series6) | 16 | 23 | [-2^127, 2^127] |
| PowerVR Rogue (Series6XT) | 16 | 23 | [-2^127, 2^127] |
| VideoCore IV | 8 | 23 | [-2^127, 2^127] |
| Vivante GC1000 | 4 | 23 | [-2^127, 2^127] |
| Vivante GC4000 | 16 | 23 | [-2^127, 2^127] |
Есть проблема с NVIDIA Tegra 2/3/4, на этой серии работает ряд популярных устройств таких, как Nexus 7, HTC One X, ASUS Transformer.
Система частиц
Рассматривая системы частиц, генерируемые на CPU, в разрезе увеличения количества обрабатываемых данных (количества частиц), основной проблемой производительности становится копирование (выгрузка) данных из оперативной памяти в память видеоутсройства на каждом кадре. Поэтому, наша основная задача — избежать этого копирования, перенеся вычисления в неоперативный режим на графический процессор.
Напомним, что в OpenGL ES 2.0 нет встроенных механизмов таких, как Transform Feedback (доступного в OpenGL ES 3.0) или Compute Shader (доступного в OpenGL ES 3.1), позволяющих производить вычисления на GPU.
Суть метода заключается в том, чтобы использовать в качестве буфера данных для хранения, характеризующих частицу, величин (координаты, ускорения и т.д.) — текстуры и обрабатывать их средствами вершинных и фрагментных шейдеров. Также, как мы храним и загружаем нормали, говоря о Normal mapping. Размер буфера, в нашем случае, пропорционален количеству обрабатываемых частиц. Каждый тексель хранит отдельную величину (величины, если их несколько) для отдельной частицы. Соответственно, количество обрабатываемых величин находиться в обратной зависимости от количества частиц. Например, для того, чтобы обработать позиции и ускорения для 1048576 частиц, нам понадобиться две текстуры 1024x1024 (елси нет необходимости в сохранение соотношения сторон)
Здесь есть дополнительные ограничения, которые нам необходимо учесть. Чтобы иметь возможность записать какую-либо информацию, формат пиксельных данных текстуры должен поддерживаться реализацией как color-renderable format. Это означает, что мы можем использовать текстуру в качестве цветового буфера в рамках закадровой отрисовки. Спецификация описывает только три таких формата: GL_RGBA4, GL_RGB5_A1, GL_RGB565. Принимая во внимание предметную область, нам требуется как минимум 32 бита на пиксель, чтобы обрабатывать такие величины, как координаты или ускорения (для двухмерного случая). Поэтому, упомянутых выше форматов нам недостаточно.
Для обеспечения необходимого минимума, мы рассмотрим два дополнительных типа текстур: GL_RGBA8 и GL_RGBA16F. Такие текстуры часто называют LDR(SDR) и HDR-текстурами соответственно.
- GL_RGBA8 поддерживается спецификацией, мы можем загружать и читать текстуры с таким форматом. Для записи нам необходимо потребовать расширение OES_rgb8_rgba8.
- GL_RGBA16F не поддерживается спецификацией, для того чтобы загружать и читать текстуры c таким форматом нам необходимо расширение GL_OES_texture_half_float. Более того, чтобы получить приемлемый по качеству результат, нам необходима поддержка линейных фильтров минификации и магнификации таких текстур. За это отвечает расширение GL_OES_texture_half_float_linear. Для записи нам необходимо расширение GL_EXT_color_buffer_half_float.
По данным GPUINFO на 2013 — 2015 год поддержка расширений следующая:
| Расширение | Устройства (%) |
|---|---|
| OES_rgb8_rgba8 | 98.69% |
| GL_OES_texture_half_float | 61.5% |
| GL_OES_texture_half_float_linear | 43.86% |
| GL_EXT_color_buffer_half_float | 32.78% |
Вообще говоря, для наших целей больше подходят HDR-текстуры. Во-первых, они позволяют нам обрабатывать больше информации без ущерба производительности, например, манипулировать частицами в трехмерном пространстве, не увеличивая количества буферов. Во-вторых, отпадает необходимость в промежуточных механизмах распаковки и запаковки данных при чтении и записи соответственно. Но, в силу слабой поддержки HDR-текстур, мы остановим свой выбор на LDR.
Итак, возвращаясь к сути, общая схема того что мы будем делать, выглядит так:
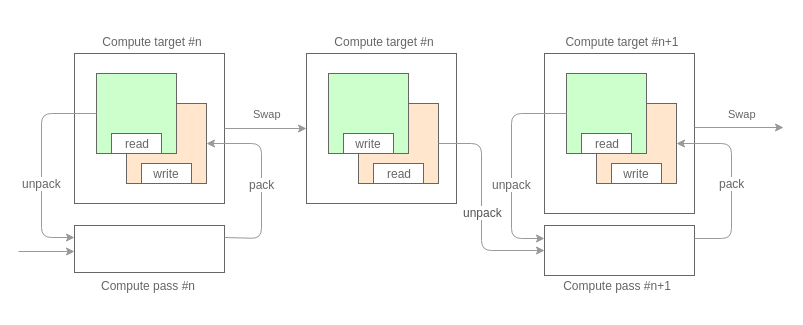
Первое что нам необходимо, это разбить вычисления на проходы. Разбиение зависит от количества и типа характеризующих величин, которые мы собираемся орабатывать. Исходя из того, что в качестве буфера данных у нас выступает текстура и с учетом, описанных выше, ограничений на формат пиксельных данных, каждый проход может обрабатывать не больше 32 бит информации по каждой частицы. Например, на первом проходе мы расчитали ускорения (32 бита, по 16 бит на компоненту), на втором обновили позиции (32 бита, по 16 бит на компоненту).
Каждый проход обрабатывает данные в режиме двойной буферизации. Тем самым обеспечивается доступ к состоянию системы предыдущего кадра.
Ядро прохода, это обычный texture mapping на два треугольника, где в качестве текстурных карт выступают наши буферы данных. Общий вид шейдеров следующий:
// Вершинный шейдер
attribute vec2 a_vertex_xy;
attribute vec2 a_vertex_uv;
varying vec2 v_uv;
void main()
{
gl_Position = vec4(a_vertex_xy, 0.0, 1.0);
v_uv = a_vertex_uv;
}// Фрагментный шейдер
precision highp float;
varying vec2 v_uv;
// состояние предыдущего кадра
// (если необходимо)
uniform sampler2D u_prev_state;
// данные из предшествующих проходов
// (если необходимо)
uniform sampler2D u_pass_0;
...
uniform sampler2D u_pass_n;
// функции распаковки
<type> unpack(vec4 raw);
<type_0> unpack_0(vec4 raw);
...
<type_n> unpack_1(vec4 raw)
// функция запаковки
vec4 pack(<type> data);
void main()
{
// распаковываем необходимые для расчетов данные
// для частицы с индексом v_uv
<type> data = unpack(texture2D(u_prev_state, v_uv));
<type_0> data_pass_0 = unpack_0(texture2D(u_pass_0, v_uv));
...
<type_n> data_pass_n = unpack_n(texture2D(u_pass_n, v_uv));
// получаем результат
<type> result = ...
// упаковываем и сохраняем результат
gl_FragColor = pack(result);
}Реализация функций распаковки/запаковки зависит от величин, которые мы обрабатываем. На данном этапе мы опираемся на требование, описанное в начале, о высокой точности вычислений.
Например, для двухмерных координат (компоненты [x, y] по 16 бит) функции могут выглядить так:
vec4 pack(vec2 value)
{
vec2 shift = vec2(255.0, 1.0);
vec2 mask = vec2(0.0, 1.0 / 255.0);
vec4 result = fract(value.xxyy * shift.xyxy);
return result - result.xxzz * mask.xyxy;
}
vec2 unpack(vec4 value)
{
vec2 shift = vec2(1.0 / 255.0, 1.0);
return vec2(dot(value.xy, shift), dot(value.zw, shift));
}Отрисовка
После этапа вычислений следует этап отрисовки. Для доступа к частицам на этом этапе нам необходим, для перебора, некоторый внешний индекс. В качестве такого индекса будет выступать вершинный буфер (Vertex Buffer Object) с текстурными координатами буфера данных. Индекс создается и инициализируется (выгружается в память видеоустройства) один раз и в процессе не меняется.
На этом шаге, вступает в силу требование о доступе к текстурным картам. Вершинный шейдер похож на фрагментный с этапа вычислений:
// Вершинный шейдер
// индекс данных
attribute vec2 a_data_uv;
// буфер данных, хранящий позиции
uniform sampler2D u_positions;
// дополнительные данные (если необходимо)
uniform sampler2D u_data_0;
...
uniform sampler2D u_data_n;
// функция распаковки позиций
vec2 unpack(vec4 data);
// функции распаковки дополнительных данных
<type_0> unpack_0(vec4 data);
...
<type_n> unpack_n(vec4 data);
void main()
{
// распаковываем и обрабатываем позиции частиц
vec2 position = unpack(texture2D(u_positions, a_data_uv));
gl_Position = vec4(position * 2.0 - 1.0, 0.0, 1.0);
// распаковываем и обрабатываем дополнительные данные
<type_0> data_0 = unpack(texture2D(u_data_0, a_data_uv));
...
<type_n> data_n = unpack(texture2D(u_data_n, a_data_uv));
}Пример
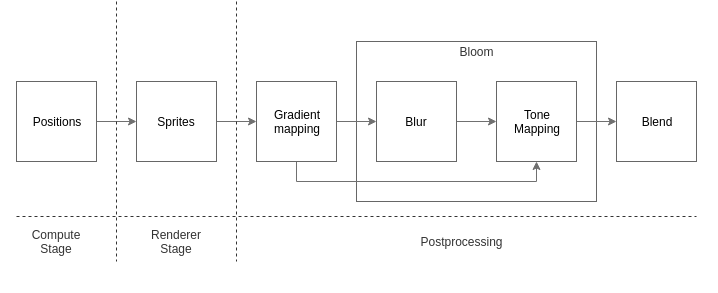
В качестве небольшого примера, мы попробуем сгенерировать динамическую систему из 1048576 частиц, известную как Strange Attractor.
Обработка кадра состоит из нескольких этапов:

Compute Stage
На этапе вычислений у нас будет всего один независимый проход, отвечающий за позиционирование частиц. В его основе лежит простая формула:
Xn+1 = sin(a * Yn) - cos(b * Xn)
Yn+1 = sin(c * Xn) - cos(d * Yn)Такая система еще называется Peter de Jong Attractors. С течением времени, мы будем менять только коэфициенты.
// Вершинный шейдер
attribute vec2 a_vertex_xy;
varying vec2 v_uv;
void main()
{
gl_Position = vec4(a_vertex_xy, 0.0, 1.0);
v_uv = a_vertex_xy * 0.5 + 0.5;
}// Фрагментный шейдер
precision highp float;
varying vec2 v_uv;
uniform lowp float u_attractor_a;
uniform lowp float u_attractor_b;
uniform lowp float u_attractor_c;
uniform lowp float u_attractor_d;
vec4 pack(vec2 value)
{
vec2 shift = vec2(255.0, 1.0);
vec2 mask = vec2(0.0, 1.0 / 255.0);
vec4 result = fract(value.xxyy * shift.xyxy);
return result - result.xxzz * mask.xyxy;
}
void main()
{
vec2 pos = v_uv * 4.0 - 2.0;
for(int i = 0; i < 3; ++i)
{
pos = vec2(sin(u_attractor_a * pos.y) - cos(u_attractor_b * pos.x),
sin(u_attractor_c * pos.x) - cos(u_attractor_d * pos.y));
}
pos = clamp(pos, vec2(-2.0), vec2(2.0));
gl_FragColor = pack(pos * 0.25 + 0.5);
}Renderer Stage
На этапе рендеринга сцены, мы отрисуем наши частицы обычными спрайтами.
// Вершинный шейдер
// индекс
attribute vec2 a_positions_uv;
// позиции (буфер, полученный на этапе вычислений)
uniform sampler2D u_positions;
varying vec4 v_color;
vec2 unpack(vec4 value)
{
vec2 shift = vec2(0.00392156863, 1.0);
return vec2(dot(value.xy, shift), dot(value.zw, shift));
}
void main()
{
vec2 position = unpack(texture2D(u_positions, a_positions_uv));
gl_Position = vec4(position * 2.0 - 1.0, 0.0, 1.0);
v_color = vec4(0.8);
}// Фрагментый шейдер
precision lowp float;
varying vec4 v_color;
void main()
{
gl_FragColor = v_color;
}Результат

Postprocessing
В заключение, на этапе постобработки, мы наложим несколько эффектов
Gradient mapping. Добавляет цветовое содержание на основе яркости исходного изображения.
Результат

Bloom. Добавляет небольшое свечение.
Результат

Код
Репозиторий проекта на GitHub.
На данный момент доступны:
- Oснавная база кода (C++11/C++14) вместе с шейдерами;
- Примеры и демо-версии приложений;
- Liquid. Симуляция жидкости;
- Light Scattered. Адаптация эффекта рассеяного света;
- Strange Attractors. Пример, описанный в статье;
- Wind Field. Реализация Navier-Stokes с большим количеством частиц (2^20);
- Flame Simulation. Симуляция пламени.
- Клиент под Android.
Продолжение
На этом примере, мы видим что этап вычислений, этап отрисовки сцены и постобработка состоят из нескольких зависимых между собой проходов.
В следующей части мы постараемся рассмотреть реализацию многопроходного рендеринга с учетом требований, накладываемых каждым этапом.
Буду рад комментариям и предложениям (можно по почте yegorov.alex@gmail.com)
Спасибо!







