Задачей исследования является визуализация дуплицированности главных страниц доменов по пятисловным шинглам в рамках общей базы.


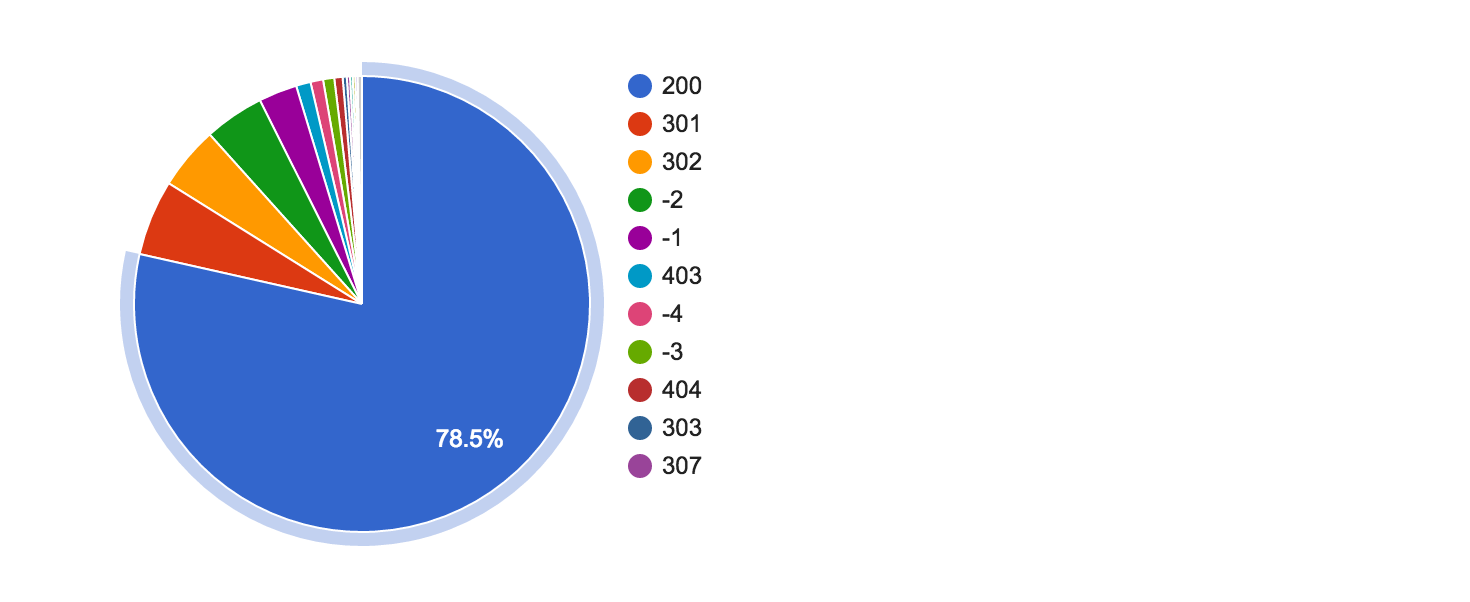


На ответивших контентом страницах найдено 588,086,318 шинглов.
Складываем каждый шингл с дополнительной информацией в датасет top1m_shingles:
shingle,domain,position,count_on_page
На выходе имеем таблицу shingle_w из 476,380,752 уникальных n-грамм с весами.
Дописываем вес шингла в рамках базы к исходному датасету:
Если получившийся датасет сгруппировать по документам (доменам) и сконкатить значения n-грамм и позиций, получим развесованную табличку для каждого домена.
Обогащаем on_page показателями, средними, рассчитываем UNIQ RATIO для каждого документа (как соотношение количества уникальных шинглов в рамках базы к не уникальным), выводим n-граммы, генерируем страничку:


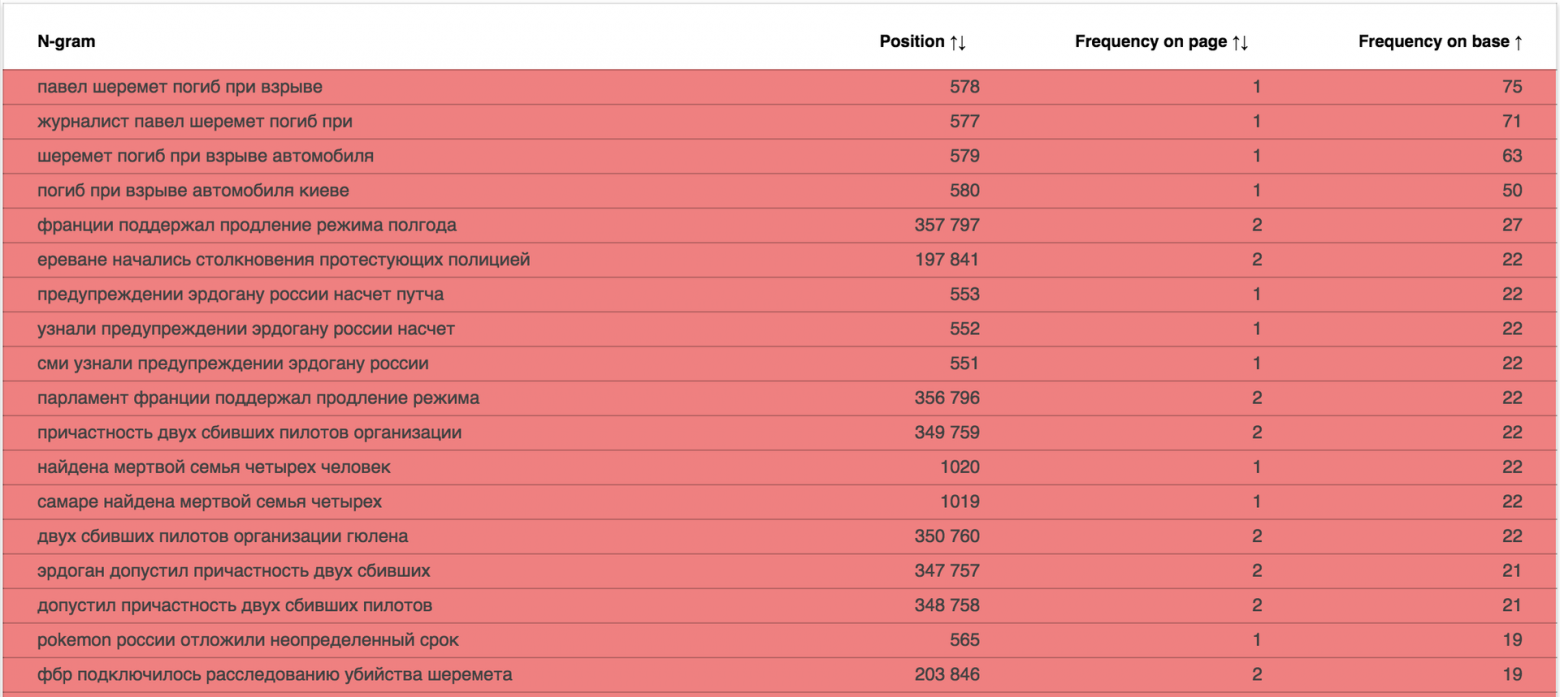
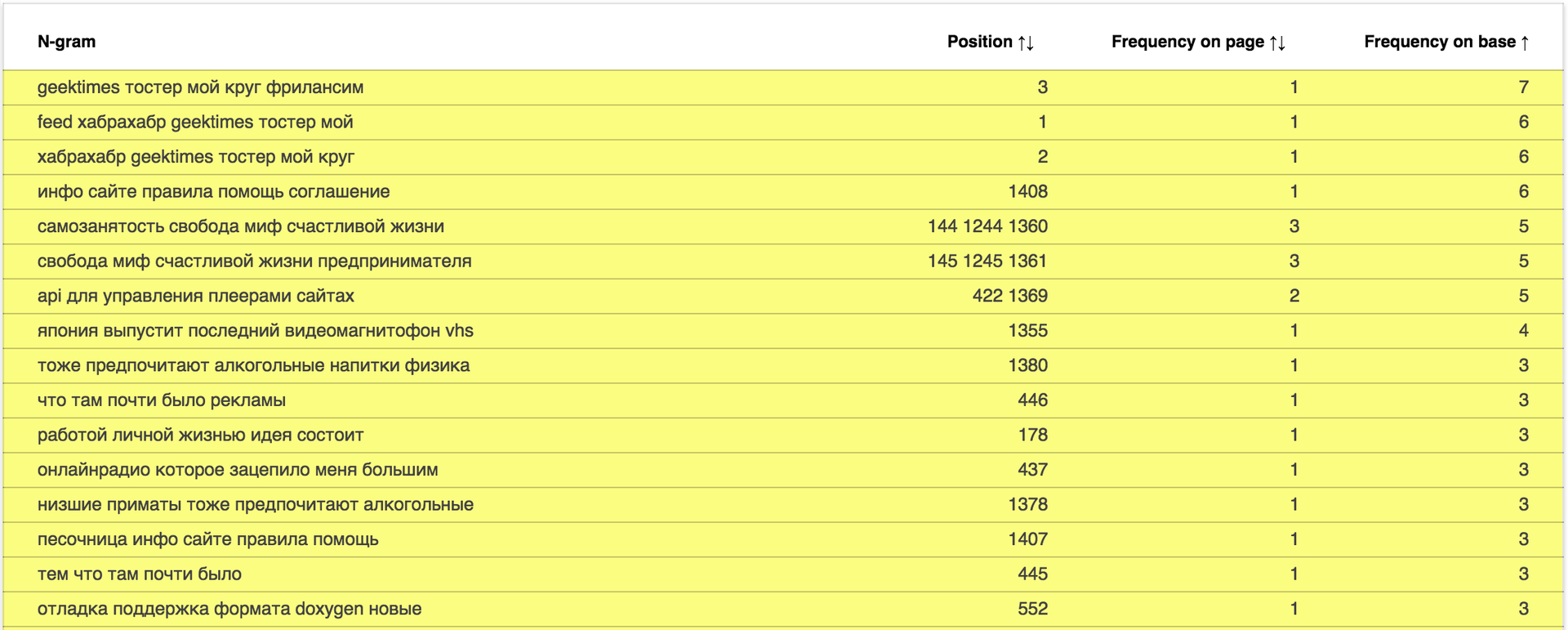
Отчёт доступен по адресу: data.statoperator.com/report/habrahabr.ru и содержит полную таблицу с текстами шиглов и их значениями. Шинглы изначально не отсортированы. Если хочется просмотреть их в том порядке, в котором они шли в документе — сортните таблицу по позиции. Или по частоте в базе, как на изображении:

Меняем домен в урле или вводим в форме поиска и смотрим отчёт по любому домену из списка Alexa top 1M.
Интересно взглянуть на новостные сайты: data.statoperator.com/report/lenta.ru
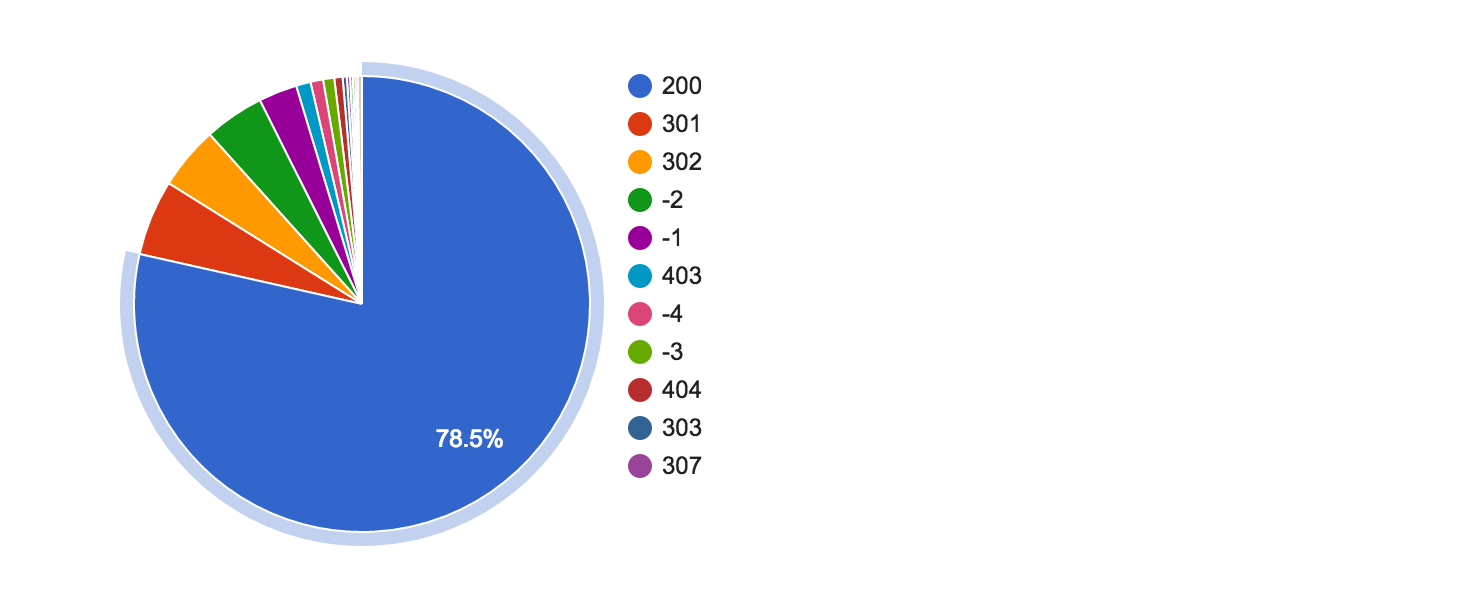
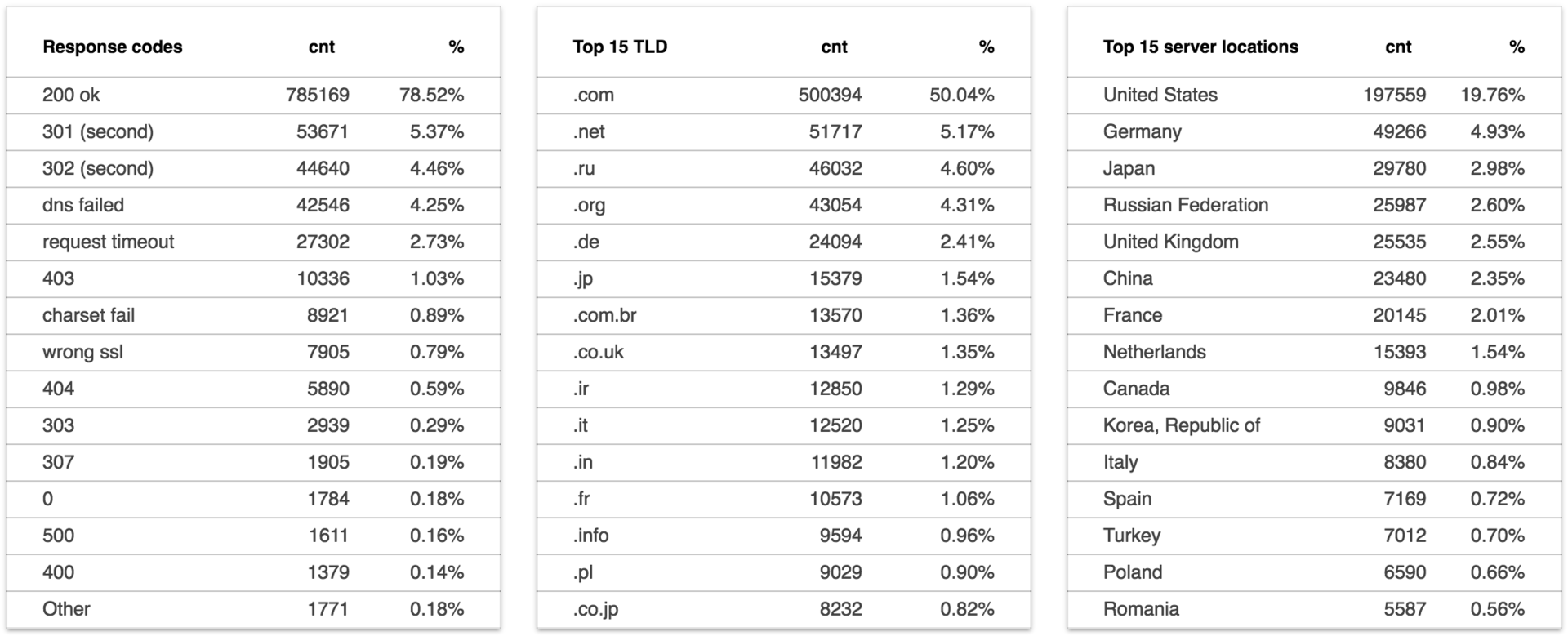
Сбор данных: 2016-07-21
Дата генерации отчёта: 2016-07-27

Запускаем краулер

Извлекаем текст, удаляем мусор, генерируем пятисловные шинглы

На ответивших контентом страницах найдено 588,086,318 шинглов.
Складываем каждый шингл с дополнительной информацией в датасет top1m_shingles:
shingle,domain,position,count_on_page
Рассчитываем n-граммы
SELECT
shingle,
COUNT(shingle) cnt
FROM
top1m_shingles
GROUP BY
shingle
На выходе имеем таблицу shingle_w из 476,380,752 уникальных n-грамм с весами.
Дописываем вес шингла в рамках базы к исходному датасету:
SELECT
shingle,
domain,
position,
count_on_page,
b.cnt count_on_base
FROM
top1m_shingles AS a
JOIN
shingles_w AS b
ON
a.shingle = b.shingle
Если получившийся датасет сгруппировать по документам (доменам) и сконкатить значения n-грамм и позиций, получим развесованную табличку для каждого домена.
Обогащаем on_page показателями, средними, рассчитываем UNIQ RATIO для каждого документа (как соотношение количества уникальных шинглов в рамках базы к не уникальным), выводим n-граммы, генерируем страничку:


Отчёт доступен по адресу: data.statoperator.com/report/habrahabr.ru и содержит полную таблицу с текстами шиглов и их значениями. Шинглы изначально не отсортированы. Если хочется просмотреть их в том порядке, в котором они шли в документе — сортните таблицу по позиции. Или по частоте в базе, как на изображении:
Меняем домен в урле или вводим в форме поиска и смотрим отчёт по любому домену из списка Alexa top 1M.
Интересно взглянуть на новостные сайты: data.statoperator.com/report/lenta.ru
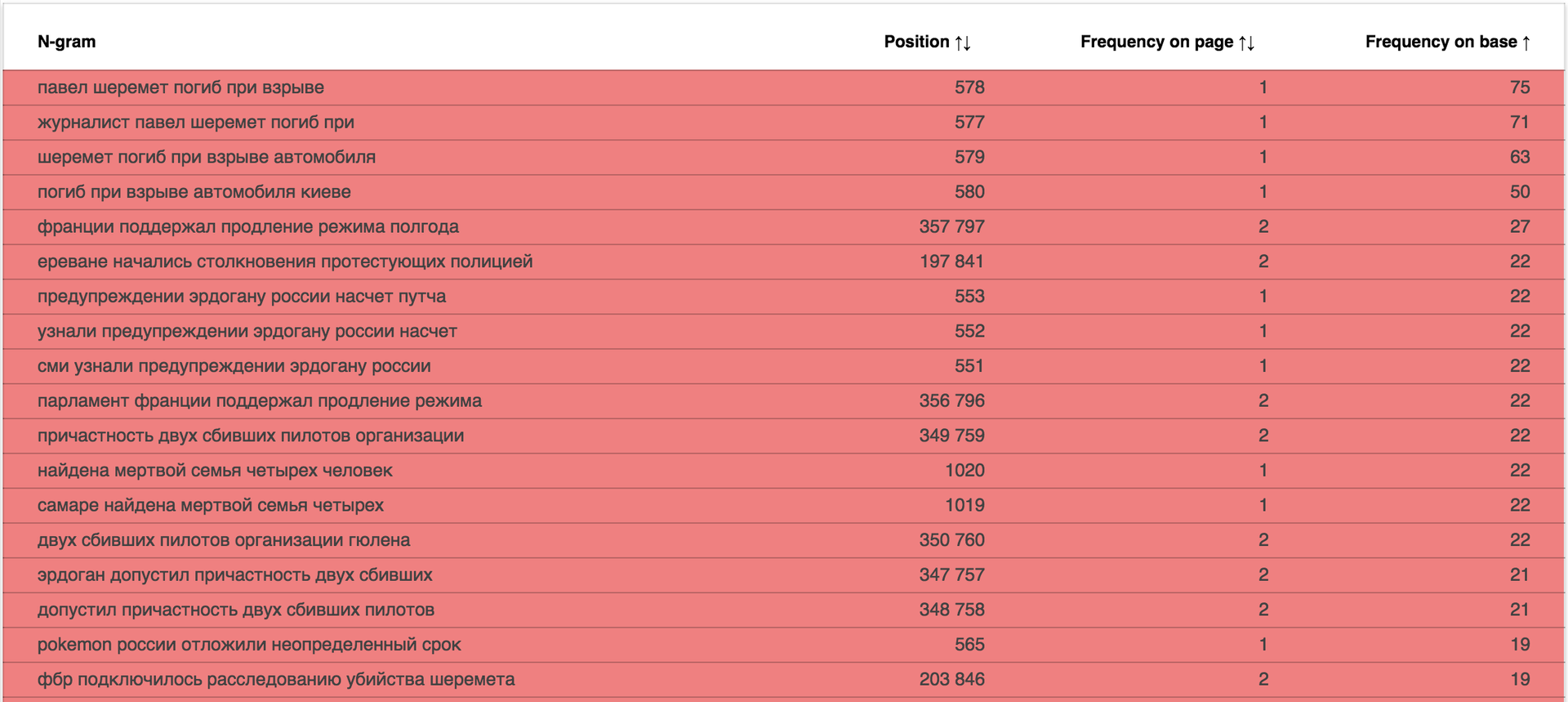
Средний показатель уникальности страниц: 82.2%
Сбор данных: 2016-07-21
Дата генерации отчёта: 2016-07-27







