Комментарии 27
Дайте, пожалуйста, пример готовой СМСки.
К сожалению, примера готовой СКСки нет, так как само мобильное приложение писал не я, а только предоставил библиотеку для упаковки трека в массив массивов байтов (так как трек мог быть больше 84 точек и нужно было делать несколько жирных СМСок).
Схема работы была следующей: Сырые данные -> Преобразование в массив байтов (бинарный формат из статьи) -> Base64 -> Использование SMS API в Android.
Для других платформ предоставил описание формата (заголовок, тело, первая точка трека, последующие точки трека, правила заполнения флагов).
Схема работы была следующей: Сырые данные -> Преобразование в массив байтов (бинарный формат из статьи) -> Base64 -> Использование SMS API в Android.
Для других платформ предоставил описание формата (заголовок, тело, первая точка трека, последующие точки трека, правила заполнения флагов).
Добавил сводную информацию по бинарному формату + пример сообщения.
Да, я тоже ожидал увидеть СМС в статике. А раз прмера нет, то это не хорошая статья...
А зачем пользователю без интернета GPS-трек? или у вас приложение с загружаемыми картами?
Даже в отсутствии загружаемых карт можно писать трек. Ведь карты нужны только для показа пользователю на экране телефона.
В простом варианте можно использовать оффлайновый «сриншот» кусочка карты, где мы знаем, например, координаты левой верхней и правой нижней точки прямоугольника. Если, конечно, речь не про северный полюс.
В простом варианте можно использовать оффлайновый «сриншот» кусочка карты, где мы знаем, например, координаты левой верхней и правой нижней точки прямоугольника. Если, конечно, речь не про северный полюс.
абсолютные координаты и время фиксировались только для первой точки, а все последующие точки хранили в себе смещение относительно предыдущей и по координатам, и по времени.
Скажите честно, сами до идеи дошли или подсмотрели в MPEG-сжатии? :)
Сам дошёл, причём вполне естественным образом: статья, конечно, больше поток сознания из воспоминаний трёхлетней давности, но логику постепенного создания формата привёл без искажений. Поскольку я увидел очевидные предположения (пункты 1-3) по сжатию метки времени — оставалось смасштабировать время с 50 лет до максимальной теоретической продолжительности одного трека (что заведомо было меньше недели, а в своём большинстве ограничивалось одним-двумя днями). С координатами было чуть сложнее — можно было только предполагать, как далеко может пользователь сместиться от первой точки, поэтому в первой версии протокола могли отказаться от этой оптимизации.
К сожалению, я не знаю, как устроено сжатие в MPEG. Возможно, что перед тем, как начинать оптимизировать, нужно было изучить матчасть.
К сожалению, я не знаю, как устроено сжатие в MPEG. Возможно, что перед тем, как начинать оптимизировать, нужно было изучить матчасть.
К сожалению, я не знаю, как устроено сжатие в MPEG
Почти как у вас. Берется ключевой кадр, а информация о следующих кадрах записывается разностная (т.е. изменения относительно ключевого). Если в общих словах — то вот и вся премудрость.
Первая мысль, которая мне пришла в голову по прочтении: «надо туда CABAC прикрутить».
Почитал про контекстно-адаптивное сжатие — а не слишком ли малый объём данных для применения таких методов?
Извините, я не поставил смайлик хотя это была большей частью шутка (и меньшей частью моя профессиональная деформация).
Если серьёзно, то в случае, если передаётся разница между точками трека, вполне можно поэсплуатировать большую вероятность небольшой разницы и использовать универсальный код, что-то вроде экспоненциального кода Голомба.
Если серьёзно, то в случае, если передаётся разница между точками трека, вполне можно поэсплуатировать большую вероятность небольшой разницы и использовать универсальный код, что-то вроде экспоненциального кода Голомба.
как минимум до MPEG был ADPCM , а до него — возможно что-то еще.
8 байт — что-то многовато для инкрементального кодирования. Байта на время и трех-четырёх на координаты (зигзаг-кодированием) должно хватить.
Как в один байт сохранить сдвиг на 1 час для указанной точности? С координатами сложно, т.к. за те же 2 часа можно долететь из Екатеринбурга в Санкт-Петербург, поэтому нужно понимать область применимости.
Впрочем, пока писал статью — увидел ещё несколько возможных вариантов допущений и оптимизаций, но уж как было — так и рассказал.
Впрочем, пока писал статью — увидел ещё несколько возможных вариантов допущений и оптимизаций, но уж как было — так и рассказал.
НЛО прилетело и опубликовало эту надпись здесь
Будет интересно посмотреть на код по работе с побитовыми операциями.
Примеры декодирования данных:
Тут можно отметить две вещи:
1. Нужно не забывать правильно очищать входные байты, которые «шарятся» между полями сообщения (пример с первым байтом при декодировании поля dateTime).
2. Используется Big Endian порядок байтов (замечание актуально только для платформ/языков, где используется другой порядок), так как от «расшаренных» байтов под флаги откусываются старшие биты старших байтов.
public static final DateTime ERA_DATE = DateTime.parse("2014-01-01T00:00:000Z");
public static final int SEC_SCALE = 4;
public static final int SEC_TO_MILLIS = 1000;
public DateTime decodeDateTime(byte first, byte second, byte third, byte fouth) {
long time = (first & 0x1FL)<<24 | (second & 0xFFL)<<16 | (third & 0xFFL)<<8 | (fouth & 0xFFL);
return ERA_DATE.plus(time * SEC_SCALE * SEC_TO_MILLIS);
}
public DateTime decodeOffset(DateTime date, byte first, byte second) {
long offset = (first & 0xFFL)<<8 | (second & 0xFFL);
offset *= SEC_SCALE;//в секундах
offset *= SEC_TO_MILLIS;//в миллисекундах
return date.plus(offset);
}
Тут можно отметить две вещи:
1. Нужно не забывать правильно очищать входные байты, которые «шарятся» между полями сообщения (пример с первым байтом при декодировании поля dateTime).
2. Используется Big Endian порядок байтов (замечание актуально только для платформ/языков, где используется другой порядок), так как от «расшаренных» байтов под флаги откусываются старшие биты старших байтов.
Всегда люблю статьи где что то не очень сложное оптимизируют))
Немного покритикую(не воспринимайте сильно близко).
Возможно я что то неправильно или не до конца понял.
1. base64 кодирует и при этом выходная строка увеличивается в объёме.
2. Время можно брать по тому когда сообщения придет, а всё остальное по сдвигам от первой точки(как бы в обратном порядке)
3.160 символов для 7-битной кодировки т. е. по факту у вас 160*7=1120 бит(140 байт). Как я понял используются только цифры и то не все + точка + разделитель(можно и не использовать) а буквы и другии символы не использующийся т.е это позволяет использовать собственную кодировку для данного формата которая будет вмешать больше данных.
Немного покритикую(не воспринимайте сильно близко).
Возможно я что то неправильно или не до конца понял.
1. base64 кодирует и при этом выходная строка увеличивается в объёме.
2. Время можно брать по тому когда сообщения придет, а всё остальное по сдвигам от первой точки(как бы в обратном порядке)
3.160 символов для 7-битной кодировки т. е. по факту у вас 160*7=1120 бит(140 байт). Как я понял используются только цифры и то не все + точка + разделитель(можно и не использовать) а буквы и другии символы не использующийся т.е это позволяет использовать собственную кодировку для данного формата которая будет вмешать больше данных.
Если перефразировать 1 и 3 — можно попробовать заморочиться за собственное кодирование на основе 7-битных символов. Полезная нагрузка для текущего решения — 120 байт, а максимально возможная — 140 байт, то есть возможен прирост до 16.5%. Оптимизация же самих данных давала от 30% на каждом шаге (переход от наивной реализации вообще в разы увеличил объём переданных полезных данных). Так что такое решение бы стало следующим шагом.
Закладываться на время получения сообщения нельзя, так как имеют место действия, временные интервалы между которыми могут быть неопределённой длины: момент формирования трека, момент упаковки в бинарный формат, момент создания сообщения, момент отправки с телефона, момент получения сообщения оператором и так далее.
Одини из поинтов статьи заключался в том, что в 2014 году (да и уже завтра — в 2017 году) в эпоху 4G, без пяти минут 5G, домашнего интернета до 300 МБит могут возникать ситуации, когда нельзя бездумно разбрасываться данными. Если бы я не вмешался в разработку алгоритма (Base64 был зафиксирован), то на полном серьёзе собирались использовать формат, который позволял бы передать только четыре точки в одинарной СМСке, когда весь трек состоит из десятков (в некоторых случаях — из сотен) точек. К сожалению, мы пережили то время, когда программирование было искусством.
Закладываться на время получения сообщения нельзя, так как имеют место действия, временные интервалы между которыми могут быть неопределённой длины: момент формирования трека, момент упаковки в бинарный формат, момент создания сообщения, момент отправки с телефона, момент получения сообщения оператором и так далее.
Одини из поинтов статьи заключался в том, что в 2014 году (да и уже завтра — в 2017 году) в эпоху 4G, без пяти минут 5G, домашнего интернета до 300 МБит могут возникать ситуации, когда нельзя бездумно разбрасываться данными. Если бы я не вмешался в разработку алгоритма (Base64 был зафиксирован), то на полном серьёзе собирались использовать формат, который позволял бы передать только четыре точки в одинарной СМСке, когда весь трек состоит из десятков (в некоторых случаях — из сотен) точек. К сожалению, мы пережили то время, когда программирование было искусством.
У гугла есть polylineutility — алгоритм позволяет хранить координаты в строковом виде с отличным сжатием, например 10 точек уложились в 45 байт. 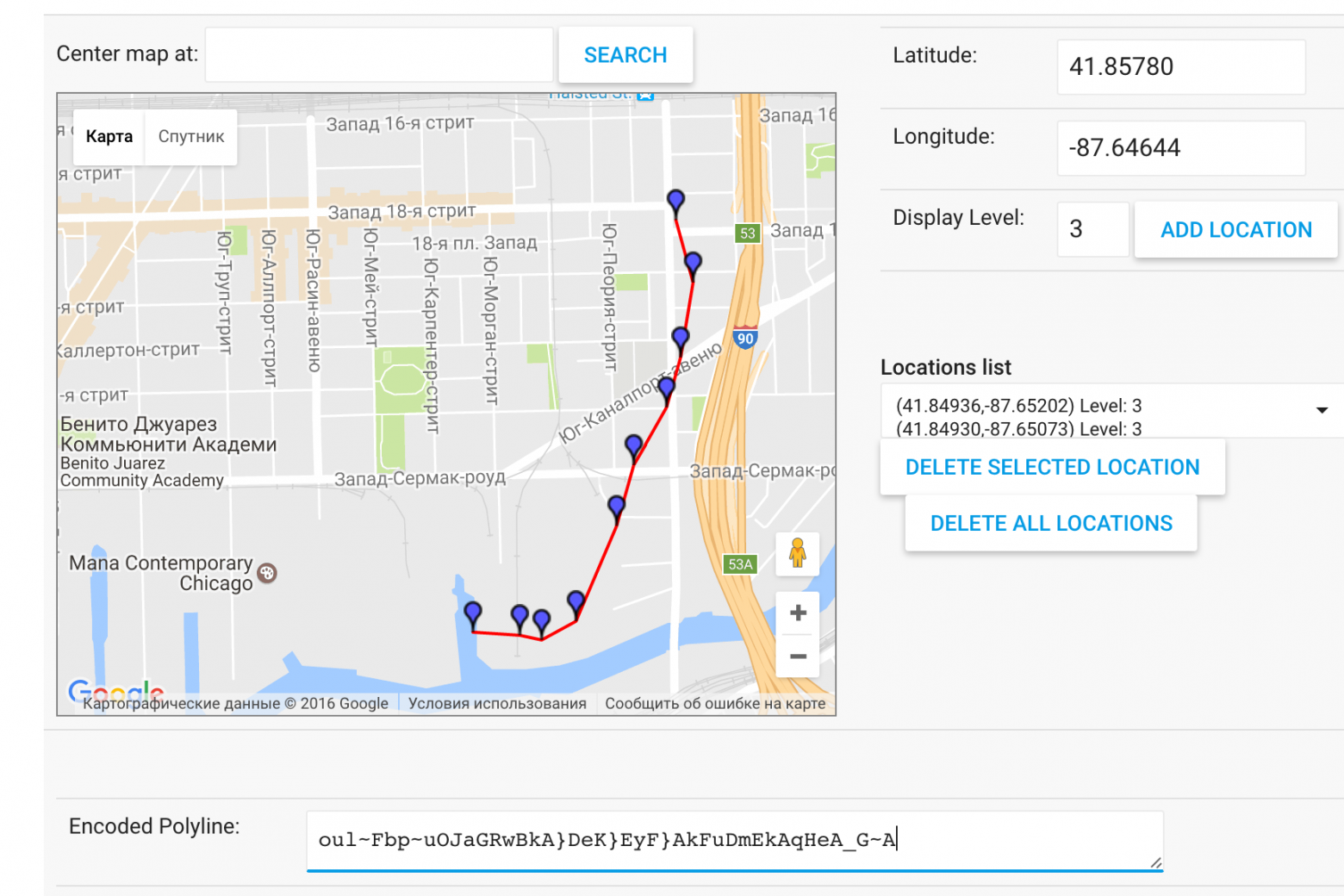

30 гугловых точек против 84
В моём случае для кодирования 10 точек (без учёта меток времени и флагов) потребуется 443 бита против 360 бит (на 18.7% эффективнее); с другой стороны, если считать, что все точки в пределах одной улицы (как в вашем примере), то можно добиться и лучшего результата. В любом случае, стоит ознакомиться с алгоритмом, спасибо!
Для нас важным результатом было:
1. В трети случаев точки помещались в одну маленькую СМСку.
2. В подавляющем большинстве весь трек укладывался бы в одну жирную СМС (за редким исключением, когда трек мог состоять из ~ 100-200 точек).
3. Заголовок, тело и каждая точка трека занимали целое число байт.
4. Кодирование (не сжатие) давало предсказуемый результат по длине (цель не столько в упаковке как можно большего числа точек, сколько в упаковке заранее известного достаточного количества точек).
Для нас важным результатом было:
1. В трети случаев точки помещались в одну маленькую СМСку.
2. В подавляющем большинстве весь трек укладывался бы в одну жирную СМС (за редким исключением, когда трек мог состоять из ~ 100-200 точек).
3. Заголовок, тело и каждая точка трека занимали целое число байт.
4. Кодирование (не сжатие) давало предсказуемый результат по длине (цель не столько в упаковке как можно большего числа точек, сколько в упаковке заранее известного достаточного количества точек).
Посмотрите протокол APRS. Все давно придумано.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Передача GPS-трека по SMS