Комментарии 429
Когда статья подготовлена нормально, таких комментариев не появляется. Не зря классики говорили «Кто ясно мыслит, тот ясно излагает.»
Вопрос, почему мы такие злые все-таки остается актуальным.
Было ещё хуже?
«При все моем уважении к тому, что для автора русский — это не родной язык, он поторопился, выкладывая данную статью без вычитки. К сожалению, я не смог прочитать даже первые пару абзацев. Думаю, вычитка и исправление помогло бы раскрыть суть статьи полнее для многих читателей.»
Смысл тот же, а отношение лучше.
Речь шла не обо мне. Это был тонкий намек на то что возможно и у Вас ушло бы сопоставимо времени на это. Но вы предпочли возмущаться тем что человек для которого русский не является родным осмелился публиковаться, не выучив язык на уровне натива. Россияне ведь все как один владеют языками лучше носителей, да что там — носители свой язык учат по постам россиян на форумах. Оттого и требования у нас высокие, не злые мы, совсем нет. А еще мы воспитанные.
Я бы с удовольствием помог автору, если бы он, зная, что у него возможны проблемы с изложением на русском обратился ко мне с просьбой глянуть черновик перед публикацией. И я, в принципе, не против делать это в будущем.
Мне хотелось бы видеть здесь более качественные публикации (хотя бы в плане изложения) — к сожалению, в последнее время таковых все меньше. Чтобы не возникало отторжения при чтении — даже если материал интересный, то качество изложения может весьма сильно подпортить впечатление, а в некоторых случаях и исказить его понимание, не говоря уже о желании читать.
Раз уж писать статью, то писать ее для людей — понимая кто ее будет читать и хоть немножко уважать читателя. Не надо говорить мне, что я преувеличиваю — читать то, что было предложено было реально тяжело.
Такова моя позиция, пространные рассуждения про злость или не злость совершенно не к месту — разве что только высказывание своего мнения карается у нас минусами в карму — это весьма по-доброму, при всем при том, что вроде бы на личности не переходил и просто высказал мнение с которым имеются и солидарные.
В конце концов, объективно — для ресурса статья была подготовлена ненадлежащим образом и, обращаясь к автору/авторам — уделяйте чуть больше внимания к подготовке материала, чтобы всем было хорошо, на крайний случай попросите кого-нибудь.
С наступившим.
И что же помешало сделать это в прошлом?
Однако, вас я не пойму — вы чего-то от меня хотите или ждете? Вроде как, уже все прояснено, я дал развернутый ответ и обозначил свою позицию, а вы продолжаете за что-то цепляться.
Так я уже даже похвалил вас без всякого сарказма — быть может вам самому стоит вспомнить про ту ссылку, которую вы приводили?
видимо по причине того, что автор опубликовал «как было» и не обратился.
Не думал комментировать, но как это "обратится"? К кому? Есть песочница, там можно писать в черновики, а потом публиковать и ждать модератора и приглашения (ну или неприглашения). Я просто не понимаю где в этом процессе можно попросить помощь и от кого?
Потом, когда статью одобрили к публикацию, вот gearbox сразу написал на ЛС, что и где не так. А я исправил. Кстати, я даже не знал что есть ЛС.
Кстати, я даже не знал что есть ЛС.
Кстати, дайте ответ в ЛС. Пожалуйста!
Думаю, что вы уже прочитали ветку и понимаете о чем идет речь.
Раньше модераторы просматривали статьи и сами корректировали их при необходимости, а в некоторых случаях и не допускали к публикации, если в большем количестве присутствовали ошибки (даже несмотря на интересный материал).
Но с тех времен, к сожалению, многое изменилось, в частности, сейчас ответственность за качество статей почти полностью лежит на руках самих авторов.
Зная, что у вас возможны проблемы с написанием статьи на русском, к кому обратиться — вопрос не технический (с учетом отсутствия такого механизма на хабре, насколько я знаю), а эстетический, чтобы быть уверенным в своей публикации и что она будет понятна читающим.
Думаю, в просьбе пробежаться по статье и поправить ошибки перед публикацией нашлось бы немало тех, кто был бы не против, и это могли бы быть люди не обязательно с этого сайта. Если готовится публикация на широкую публику, а не у себя в блоге, то почему бы не сделать ее доступнее и на нормальном уровне? Ведь все от этого будут только в плюсе.
Здесь есть даже правила для публикаций, с которыми было бы крайне желательно ознакомиться перед самой публикацией: https://habrahabr.ru/info/help/posts/
Там, как раз, и изложены принципы и пожелания о которых идет речь, и ваша публикация была бы только лучше, если бы вы, зная, что возможны ошибки в таком большом объеме уделили бы им внимание. Ничего личного — то, что я писал направлено не только к вам, но к авторам в целом и к носителям языка тем более. Ребят, просто хочется видеть приемлемый уровень, а не ломать мозг при чтении.
Но с другой стороны, плюсов никаких. С точки зрения производительности, разницы особо думаю не будет — 99% у тебя займёт шаблонизатор и база данных, или 95%.
Беда в другом. Никому не нужен хороший и оптимизированный софт. Стоит взглянуть на любой продукт крупных компаний — это становится ясно. Важна скорость и стоимость разработки. Ассемблер при всей любви к нему не может похвастаться хорошими показателями в этих категориях. Увы, так устроено наше общество.
Никому не нужен хороший и оптимизированный софт.
Дело в том, что 95% на С и 5% критичного кода на асме покажет результаты не хуже практически на любой задаче. Чистый асм не нужен
Не всегда. Под "5% критичного кода на асме" я подразумеваю "используя при необходимости асм в 5% критичного кода"
Я его сам пишу, собственно.
Но это безусловно не во всех случаях так.
P.S. Заранее извиняюсь, но приводить примеры мне лень. В основном это simd-ы и/или упихивание алгоритма в доступные регистры общего назначения.
ffmpeg вроде как классический пример, там прилично асма, и не думаю что просто так
Чистый асм не нужен
А здесь, кстати, и нет чистого асм-а. Большая часть кода (и по объёму — автор это упоминает, и по ресурсу процессора, я уверен) — отжирает SQLite, который написан на C.
Перед fcgi еще работает apache, плюс движек базы данных, так что разница в производительности на порядок, вряд ли.
А Веб-сервер на ассемблере на Хабре уже писали, да
Ждем еще до кучи реализацию БД на асме )
А сервер уже есть: RWASA.
Весь flatassembler.net работает на нем.
Там у меня сайт тоже на ассемблере: https://fresh.flatassembler.net
Правда, там MiniMagAsm работает.
https://benchmarksgame.alioth.debian.org/u64q/program.php?test=fannkuchredux&lang=go&id=1
https://benchmarksgame.alioth.debian.org/u64q/program.php?test=fannkuchredux&lang=java&id=1
https://benchmarksgame.alioth.debian.org/u64q/program.php?test=fannkuchredux&lang=csharpcore&id=4
— лютая синтетика
— transliterated from Mike Pall's Lua program — то есть с LUA перевели на javascript и php (что характерно, для java код писали ручками)
— var вместо let или const
— for вместо forEach, map и прочего
Нормальный тест, чо.
Тестов там много для разных языков. Не для всех выведены ссылки, но минимальная смекалка приводит к сравнению PHP против Java. Тесты могут быть не идеальны, и не стоит делать поспешных выводов. Если есть идеи, как переписать тест, чтобы он стал эффективнее и переиграл другие языки, можно прислать свой вариант.
Сайт не претендует на истину в последней инстанции, но позволяет неплохо прикинуть потенциал производительности по CPU и RAM для популярных языков на вполне практических, пусть и не повседневных задачах. А так никто не спорит, что без конкретного приложения, по которому неоднократно прошлись профайлером, абстрактные споры смысла не имеют.
Если что, в V8 let и const сейчас медленней, чем var: https://youtu.be/BstzvS2xd5U?t=1166
А forEach медленней for: https://twitter.com/jsunderhood/status/585372287077081089
Это обычно сочетание множества факторов, но конкретно Java и JVM там ближе к концу списка. Вот неэффективные фреймворки, да ещё и неправильно и неуместно применённые, ORM с избыточными выборками и N+1 problem, неэффективные модели данных, просто индусский код — это да. Сам пишу на ней, родимой, уже пять лет, и всё это знаю не понаслышке. Ещё на Java пишут как правильно большие и сложные системы, так что если оно тормозит, возможно, на другом языке оно тормозило бы ещё сильнее (хоть и не факт, т.к. см. выше).
Движки форумов тоже разные по степени навороченности бывают. Если честно сравнивать, то затраты на SQL будут одинаковые. А дальше идет разница: время ответа HTTP-сервера (не более 0.02 мс везде), шаблонизатор (тут большую часть времени отожрёт Markdown, так что тоже будет примерно одинаково), оверхэд на ORM/QueryBuilder (в данном случае он небольшой, т.к. запросы тривиальные), вспомагательные мидлвары.
Другими словами, я бы не ожидал ускорения за счёт применения ассемблера более, чем на 20-30% при честном сравнении на данном классе задач.
Можно легко проверить на PyStone
Это чистой воды ответ «да зелен виноград».
Лучше писать код, который будет работать быстро всегда.
В плане веб серверов есть общие тесты производительности, и там тоже показатели скорости разнятся на порядок
Лучше писать код, который будет работать быстро всегда.
Смысл, если это — не бутылочное горлышко?
Это чистой воды ответ «да зелен виноград».
Нет, это чистой воды ответ «экономить на спичках — глупо».
Во-вторых, лучше писать код как можно быстрее и качественнее, так чтобы он укладывался в нужные рамки производительности. Сама по себе абстрактная производительность никому не нужна.
А «код, который будет работать быстро всегда» это какой-нибудь ассемблер с диким количеством ручных оптимизация под конкретное железо. Да он будет работать быстрее всего в том числе Си, делают так? Крайне редко. Тут все упирается в стоимость разработки и сэкономленное железо, если железо дешевле работу программиста — смысла в быстром коде нет никакого.
В-третьих, если производительность кода на производительность системы не влияет — нужен ли быстрый код?
Это не верно. Она нужна очень много кому, а точнее — всем, кто является конечным пользователем этого кода (в случае бекэнда — владельцу сайта). Другой вопрос, что платить за эту абстрактную производительность никто не готов. Но «экономически не целесообразна» и «не нужна» — всё же разные вещи.
Другой вопрос, что платить за эту абстрактную производительность никто не готов. Но «экономически не целесообразна» и «не нужна» — всё же разные вещи.
Иногда не нужна. При типичном бекэнде веб приложения количество одновременных соединений с серверу ограничено, сервер имеет ограниченную скорость записи/чтения на диск, то есть работа с базой данных, записью файлов не может быть быстрее скорости работы с жестким диском, а канал связи с инетом тоже не безлимитный. Производительность кода на ресурсы сервера для веб бека может не влият практически никак, так как сервер 100% времени будет заниматься записью/чтением с диска, а процы будут загружены на 10-20%. Либо он упрется в трафик или количество открытых соединений. Смысл супер оптимизировать код, если процы и так не работают в полную силу и лимит достигнут совсем в другом?
2. Нет понятия «абстрактная производительность». Какую платформу выберешь, такую производительность будешь иметь _всегда_
Дело не в оптимизации, точнее далеко не только в ней. Просто на языках, скажем так, пост-ЯВУ, невинно-выглядящая операция может тянуть сумасшедшие накладки, о которых средний программист, которому нужно «быстрее и качественнее» может не задумываться или даже игнорировать. Когда все пишется руками, контроль выше, как впрочем и цена.
3.Так не бывает в реальности. В одном месте — может и не влияет, а в другом…
Просто на языках, скажем так, пост-ЯВУ, невинно-выглядящая операция может тянуть сумасшедшие накладки, о которых средний программист, которому нужно «быстрее и качественнее» может не задумываться или даже игнорировать. Когда все пишется руками, контроль выше, как впрочем и цена.
Да, это правда. И что отсюда следует?
«на ЯВУ легче написать плохой код, чем на ассемблере» — да, и это правда.
«на ассемблере легче написать хороший код, чем на ЯВУ» — нет, и это неправда.
«на ассемблере легче написать хороший код, чем плохой» — нет, и это неправда.
Интерпретатор проигрывает маш.коду в 100 раз. Это на 9900%
Какая у Вас интересная версия математики… в 100 раз быстрее == на 99% быстрее.
Только причём тут это вообще? Я же написал "на данном классе задач", т.е. рендеринг простеньких HTML-страниц на основании данных, полученных из реляционной СУБД.
Каким боком тут Dhrystone, актуальность которого осталась где-то в 80-х? Или при взгляде на великолепные результаты ассемблера в синтетическом бенчмарке у вас автомагически SQL быстрее работать начинает?
Это тест вычислений с плавающей точкой. Весьма актуален в настоящее время, потому что данные операции подешевели и все больше заменяют целочисленные.
Тест устарел, но он легко доступен и легко перепроверяется. Можно взять другие тесты.
Не выдумывайте! Считать не умеете Вы… Нельзя что-то ускорить на 200%. Максимум можно ускорить на 100% и это уже будет в бесконечность раз быстрее. А на 200% можно только замедлить.
Можно взять другие тесты.
Можно, только зачем, если в среднестатическом случае (для вышеописанного класса задач) 70% времени всё равно придётся на запросы к БД. Даже если весь остальной код будет выполняться за пару наносекунд, Вы всё равно получите лишь 30% ускорения. Учитывайте матчасть, а не только синтетику.
И давайте представим, что БД тоже написал «эффективный программист», на PHP…
Стало лучше. Но, справедливости ради, первоначально речь шла о потенциале ускорения от переписывания на асме. Фиг знает, причём тут потенциал замедления от обратного переписывания и к чему вдруг Вы начали его считать..
И давайте представим, что БД тоже написал «эффективный программист», на PHP…
Вы понимаете смысл оптимизации узких мест? Хранилище данных очень часто оказывается узким местом, именно поэтому в оптимизацию СУБД вложено столько человеко-лет. И несмотря на это когда нужна действительно высокая пропускная способность всё равно приходится отходить от реляционной модели.
Проблема в том, что ассемблер не поможет написать отзывчивый высоконагруженный веб-сервис… вроде и потенциал есть, но по факту граблей больше. И даже отличные знания асма, на уровне автора статьи, не застрахуют Вас от performance-ляпов, как у автора получилось со страницей тредов по тегу (20-30 мс там, где должно быть 7-8 мс). При использовании ЯВУ такие performance-ляпы встречаются реже, т.к. можно сконцентрироваться на оптимизации узких мест, не распыляясь на оптимизацию каждой функции.
Но я бы разделил ЯВУ на три класса
— быстрые компилируемые языки, как примеры c++, d, rust, go, даже фортран, паскаль и ада
— байт-машинные с динамической компиляцией jvm, pvm, net
— скриптовые php, js итп
С каждой ступенькой повышается уровень абстракции и понижается производительность.
К сожалению, есть тенденция писать быстро и лениво. А вместо оптимизации, замены фреймворка/языка, заниматься массовой демагогией и пропагандой типа «скорость языка неважна, все равно задержки в другом месте», «это сложно и дорого», «дешевле не стараться, а купить новый сервер»
И в итоге, используется, например Yii, который в 30 раз медленнее топов
С делением ЯВУ на классы я согласен, хотя там можно ещё интерпретаторы с JIT в отдельный класс выделить. А вот с тенденцией не согласен. Наоборот, тенденция писать на скриптовых языках слабеет с каждым годом. Народ активно смотрит в сторону Go, Elixir, Crystal, Nim, Clojure, etc.
Другое дело, что необязательно бросать все существующие наработки на PHP, Ruby, Python и JS. Во многих случаях достаточно выделить узкие места в отдельные сервисы на более быстрых языках, а ненагруженную часть проекта оставить, как есть.
P.S. Мне лично тоже нравится писать быстрый код, но опыт работы показывает, что в первую очередь бизнесу быстро нужен код, а не быстрый код.
А лучшие алгоритмы получаются сложными, и их плохо писать на ассемблере.
Нет с этим я не согласен. Сложными они получаются, когда пишут их на ЯВУ. Потому что лучшие алгоритмы, такие, которые ближе к CPU. Нативнее что ли. А таких намного легче писать на ассемблере. На ассемблере они и читаются лучше.
Правда, надо язык знать хоть немного. Но это для каждого языка в силе.
1. Используете базу данных, которая физически не может вытянуть большое количество пользователей и данных,
2. Каждый раз заново парсите markdown, вместо хранения скомпилированного варианта,
3. Имеете непонятные баги перфоманса, когда страница сильно тормозит,
4. Не кешируете html страницы в памяти или диске для ускорения работы,
У меня был сайт с миллионом просмотров в день на старом медленном PHP и хостинге подобном вашему и он не падал, только потому что там большинство запросов кэшировалось и php просто большинству пользователей отдавал готовый html, а запросы на изменения писались сначала в файл, а потом сразу скидывались из файла в таблицу.
Вы же выигрываете копейки на скорости кода проигрываете тысячи на алгоритмах и архитектуре.
- Каждый раз заново парсите markdown, вместо хранения скомпилированного варианта,
А сколько времени вы думаете отнимет чтобы сделать эту функцию? Моя оценка — около двух часов. Ничего сложного там нет. Понадобится, сделаю.
А кстати, этим можно протестировать насколько плохо поддерживается ассемблерный код.
Нужен доброволец, который хоть немного знает ассемблер и синтаксис FASM. Даем ему задание, чтобы сделал кеширование компилированного markdown-а и посмотрим сколько времени ему отнимет.
Конечно эму будет нужны намного больше 2-х часов, хотя и потому что понадобиться почитать исходники и ориентироваться в проекте с нуля. Но я считаю, что получится все очень быстро.
Сделать миграцию, добавить заполнение поля при сохранении модели, заменить название поля при выводе — 10 минут. А может и меньше.
Конечно эму будет нужны намного больше 2-х часов, хотя и потому что понадобиться почитать исходники и ориентироваться в проекте с нуля.
Во-во. На ЯВУ сложность вхождения в проект гораздо ниже.
Во-во. На ЯВУ сложность вхождения в проект гораздо ниже.
Совсем не факт. Это зависит от того насколько программист знает тот язык и фреймворк.
Любой проект зависит от знания языка. Речь не идет об уровне знаний, подразумевается, что знание языка достаточное.
Добавить поле на сайт — это типичная задача за 10-20 баксов на фрилансе. Думаете, там люди незнакомый проект неделями изучают? Да нет, просто берут и делают за пару часов. А у вас пара часов нужна даже на хорошо знакомый проект.
— байт-машинные с динамической компиляцией jvm, pvm, net
— скриптовые php, js итп
Странное деление, потому что PHP и JS перед выполнением точно так же компилируются в байт-код, как и JVM и .NET.
Скриптовые языки, которые не компилируются перед выполнением — это, например, bash и awk.
Только чтобы действительно был заметен эффект JIT, а не как раньше в Питоне — вроде и JIT, а толку 0
Но это трейдофф за счет памяти, да и динамическая типизация мешает оптимизатору.
Так что обычные компилируемые языки со строгой типизацией будут всегда иметь некоторую фору.
Есть примеры, когда код на Java обгоняет аналогичный код на Си, потому что JIT-компилятор заменяет «заглушками» редко используемые ветви условий внутри часто выполняемых процедур, и в результате тело процедуры сокращается по размеру и помещается в кэш целиком.
То же самое и с динамической типизацией: если в некой переменной 99% времени хранится целое число и 1% времени — более сложный объект, то JIT-оптимизатор может сгенерировать эффективный код для работы с целым числом, который при получении объекта бросит исключение, которое виртуальная машина обработает в «медленном режиме». AOT-компилятор, напротив, вынужден при каждом обращении к такой переменной сгенерировать код для обработки всех возможных случаев; так что размер кода сильно разбухнет.
Собственно, я и сказал «за счет памяти», а не скорости.
Про влияние кэша очень сомневаюсь, что его можно оценить.
Кроме того и современные кэши огромные, и код JITа кусок себе отъест — он же тоже исполняется в этот или близкий момент.
Теоретически да, но вот используются ли такие хинты современными JIT на самом деле?Естественно.
Кроме того и современные кэши огромные, и код JITа кусок себе отъест — он же тоже исполняется в этот или близкий момент.Практически всё время выполнения программы приходится на скомпилированный код; иначе бы смысла в JIT-компиляции не было.
Т.е. JIT-движок вытесняется из кэша сразу после очередного этапа компиляции, и уступает кэш скомпилированному коду.
Ускорить на 200% = ускорить в 3 раза = увеличить скорость в 3 раза. Есть такая величина. Скорость.
Правильный вариант Вашего комментария звучит так:
"Ускорить на 66.(6)% = ускорить в 3 раза = увеличить скорость в 3 раза. Есть такая величина. Скорость."
P.S. Любая величина изначально принимается за 100% при расчётах. Допустим, после оптимизации стало в 3 раза быстрее, т.е. (100/3)% от начального значения, значит мы ускорили на (100 — 100/3)%.
Любая величина изначально принимается за 100% при расчётах. Допустим, после оптимизации стало в 3 раза быстрее, т.е. (100/3)% от начального значения, значит мы ускорили на (100 — 100/3)%.А вы не путаете скорость вычислений и время вычислений?
Ничего я не путаю, увеличение скорости вычислений в 3 раза — это и есть сокращение времени вычислений на 67%… И то и то упрощенно называется ускорением.
А если хотите морфологией заняться, то не забывайте, что ускорение — это производная от скорости по времени, удачи в трактовке ;-)
увеличение скорости вычислений в 3 раза — это и есть сокращение времени вычислений на 67%и увеличение операций в единицу времени (скорости вычислений) на 200%
И что? Мы измеряем время в рамках бенчмарков, ips — это производная (вычисляемая, а не измеряемая) характеристика. Ускорить алгоритм == сократить время его выполнения. Это общепринятая трактовка.
Другими словами, ускорение на 67% == ips вырос на 200%.
Поймите простую вещь, "рост ips" и "ускорение" — это не синонимы ни разу.
Нельзя что-то ускорить на 200%. Максимум можно ускорить на 100% и это уже будет в бесконечность раз быстрее. А на 200% можно только замедлить.
"автомобиль ускорился на 200%" = "автомобиль увеличил скорость в 3 раза".
"автомобиль замедлился на 200%" = ???
P.S. Изначально производительность была N исполнений в секунду. После оптимизации стала 3N исполнений в секунду. Была 100%. Стала 300%. Изменилась на 200%.
Я понял Вашу отсылку к физическому понятию "скорость", но, к сожалению, как физик, вынужден отметить, что Ваши формулировки безграмотны с точки зрения физики и знак "=" там не уместен, т.к. у слова "ускорение" совершенно иной физический смысл, и ни в процентах, ни в разах оно в физике не измеряется.
«x стало в три раза больше» означает «x*3», почему Вы делите-то? О_о
Было 100 ms, стало в 3 раза быстрее, т.е. стало 33 мс. Так понятнее?
Слово "ускорился" в контексте быстродействия синоним слова "подешевел".
Функция ускорилась в 2 раза == Функция подешевела в 2 раза == Стала занимать в 2 раза меньше времени.
Функция ускорилась на 50% == Функция подешевела на 50% == Стала занимать на 50% меньше времени.
Аллюзии к слову "скорость" тут совсем не в тему. У меня странное ощущение, от того, что мне приходится разжевывать такую базовую тему на Хабре… Причём эффекта ноль, никто даже не пытается задуматься над неверным пониманием этого аспекта.
Функция ускорилась в 2 раза == скорость выполнения функции стала больше в 2 раза == функция стала быстрее на 100% == функция стала занимать на 50% меньше времени. Вы пытаетесь подменять понятия, и говоря о быстродействии но подразумевать скорость. Это такая же ошибка, как говорить что частота измеряется в секундах, хотя задав период в секундах мы однозначно определяем частоту.
Ну, ё-моё, опять 25… Забудьте Вы уже про скорость… Абстрагируйтесь от неё, если морфологическое сходство слов вас так сильно запутывает. Тем более, что такого термина как "скорость выполнения" в принципе нет в бенчмарках.
Бенчмарки меряют время ожидания (latency в секундах) и считают пропускную способность (throughput в ips или в rps).
При этом изменения latency обычно считают в процентах, а изменения throughput — в разах.
Ускорилось на 50% = latency уменьшилось на 50% = throughput вырос в 2 раза = ускорилось в 2 раза.
Вы же пытаетесь ввести какую-то свою терминологию, и не понятно откуда Вы её вообще взяли… Мне прям даже интересно на базе чего Вы так упорствуете… Дайте хоть ссылку на какую-нибудь benchmark-утилиту, которая вашей методологии подсчётов придерживается.
Забудьте Вы уже про скорость…А как тогда производительность процессора измерять: в секундах или гигафлоппс?
На базе знания русского языка и математики. Их, знаете, в младшей школе изучают. Вам пора бы уже их изучить, а то как-то плохо выглядит их полное незнание у взрослого (я надеюсь) человека.
Это тест вычислений с плавающей точкой. Весьма актуален в настоящее время, потому что данные операции подешевели и все больше заменяют целочисленные.
Вы его с чем-то путаете, потому что это как раз тест целочисленных вычислений.
The Dhrystone benchmark contains no floating point operations, thus the name is a pun on the then-popular Whetstone benchmark for floating point operations.
Весьма актуален в настоящее время, говорите?
Это где интересно? Разве что в играх. В бизнес-логике в основном строки и целочисленные айдишники.
И не про обработку html / json / xml / sql — ею, я надеюсь, занимается бэкенд — а про бизнес-логику.
А что есть html? Строки. Что есть json и xml? Строки. Что есть sql запросы? Cтроки.
Это всё форматы представлений и запросов. Бизнес-логика обычно оперирует числами и идентификаторами (по сути не важно в какой форме).
В бизнес-логике в основном строки и целочисленные айдишники.
Это что же за бизнес-логика такая? Обычно бизнес-логика считает количества, цены и стоимости.
Вот так, с помощью нехитрых приспособлений буханку белого (или черного) хлеба ассемблер можно превратить в троллейбус язык веб-программирования… Но зачем?
Писать веб-сайты на ассемблере полезно и приятно
Жесть
Для базы данных была выбрана SQLite.
Жестокая жесть
Ну, вот и все. Если кому понравилось, используйте на здоровье.
Спасибо, как нибудь в другой раз. В другой жизни.
Писать веб-сайты на ассемблере полезно и приятноЖесть
Не очень понятно — человек взял написал и говорит, что это полезно и приятно.
А у вас как-то не аргументировано.
Для базы данных была выбрана SQLite.
Жестокая жесть
А что с SQlite не так? Или коллега привык на каждый чих развертывать MSSQL?
Насколько понимаю, SQlite поддерживает одного писателя, а когда имеем несколько писателей, то получаем SQLITE_BUSY, который приходится обрабатывать вручную.
Кто то должен обслуживать wal(очищать, перемещать данные из wal в базу и т.д.), этим будет заниматься ваш обработчик, который вроде как должен быстро отдавать ответ на запрос.
Я привык, что у меня развернут постгрес и я просто добавлю новую базу в кластер.
К чем смысл страдать с асмом ради первоманса и экономии памяти а, в итоге, подключить тормозок sqlite'a.
А вообще у автора много свободного времени и запасная жизнь. Я бы столько времени не тратил непонятно на что. Взял бы готовый движок форума, развернул его за 15 минут и забыл. Каждая секунда моей жизни для меня важнее сэкономленных мегагерцев и мегабайт.
А вообще у автора много свободного времени и запасная жизнь. Я бы столько времени не тратил непонятно на что.
Зачем идти в пеший поход на неделю, если можно до конечного пункта доехать на поезде за два часа?
Зачем рисовать картину красками, если можно щёлкнуть айфоном и распечатать?
Вот и тут как-то так.
Для неопытного фронтендчика — весь современный фроеюнтенд кажется ненормальным)
А для опытного — все что другим кажется ненормальным, покажется отличной идеей.
https://ru.m.wikipedia.org/wiki/WebAssembly
[sarcasm] Хостинг-провайдеры кусают локти и ждут обрушения рынка. [/sarcasm]
Ничего. Левша вон блоху подковал, и тоже не взлетело — бывает.
Free text search — FTS
Full Text Search же :-)
С другой — проблема производительности все же есть, не зря акамаи и подобные востребованы. Сам веб — неэффективная технология со стороны клиента, потому все мучаются со стороны сервера.
В ту же копилку — любой SQL также не особо эффективен по отношению к конкретной задаче. Но до определенного предела (SQL кстати, забывают что погрешим), весьма удобен.
А что потом? Ищем оптимальные, или используем подставные планы исполнения, пытаемся как то обмануть абстрактные машины типа sql, jvm и прочие байт код интерпретаторы.
Это тлен, во имя «быстро написать и сдать».
Дальше скупые платят уже нам вдвойне, «за оптимизацию»
Просто бизнес
Хотя пожалуй больше всё-таки забавно.
Я С/С++ программист в свободное время изучаю (пока только изучаю) современные веб-фреймворки, и это туши свет! Мало того что php/python/ruby etc. сами по себе интерпретируемые языки, так разработчики еще и внутрь умудряются напихать каких-то бешеных абстракций! ORM — «птичий» язык доступа к БД, зачем когда есть SQL? Шаблонизаторы — еще один птичий язык. Я когда смотрю на это и понимаю какое количество пустопорожнего кода там выполняется, сколько раз происходят бессмысленные переаллокации памяти и перекачивание данных между буферами прежде чем они попадут в HTTP поток…
А если еще вспомнить как работает веб сервер — активизируется заново для каждого обращения, выполняет каждый раз 99% одних и тех же действий и только 1% отличающихся для каждого запроса… это тоже непаханное поле для оптимизации, и какое нибудь кэширование байт-кода php только слегка затрагивает эту тему.
Конечно писать именно на Ассемблере… может быть просто just for fun, но на Си — вполне разумное решение.
php/python/ruby etc. сами по себе интерпретируемые языки
неправда. Они компилируются в байткод, который потом исполняется виртуальной машиной.
умудряются напихать каких-то бешеных абстракций
которые нужны, чтобы код от разных вендоров работал "искаропки" и имел одинаковые интерфейсы.
ORM — «птичий» язык доступа к БД, зачем когда есть SQL
затем, чтобы вы могли выбрать данные из одной СУБД (например MySQL), "сджойнить" их с данными из другой (например MongoDB, мне это приходилось делать), закешировать на некоторое время, и всё это без кучи бойлерплейт кода каждый раз. Для любителей SQL есть Query Builder'ы, которые генерят запросы для разных диалектов SQL.
Шаблонизаторы — еще один птичий язык
а что вы предлагаете взамен? Только PHP, насколько я знаю, позволяет инлайнить код прямо в HTML, остальным языкам (React не рассматриваем) нужны шаблонизаторы. Хорошо, что есть широкоиспользуемые языки для шаблонов (Mustache, Jade/Pug и т.д.), которые позволяют не учить 100500 разных синтаксисов, а везде делать одинаково (имел несчастье работать с angular1 на фронте и php на бэкенде, один шаблонизатор немного сгладил боль).
переаллокации памяти и перекачивание данных между буферами
оверхед неизбежен, но это плата за скорость разработки.
как работает веб сервер — активизируется заново для каждого обращения
это не так. Какой-нибудь apache ещё может порождать по процессу на запрос, но, к счастью, к нему прибегают всё реже. nginx, например, имеет пул процессов, которые обрабатывают запросы пользователей. Здесь можно мне возразить, что процесс всё же порождается, но только это не веб-сервер, а какой-нибудь PHP-интерпретатор. Да, это так, но только если вы не используете fastCGI. В остальных языках чаще используется какой-нибудь встроенный в веб-фреймворк (Node.JS, Ruby Unicorn и т.д.) HTTP сервер (хотя мне тоже такое решение не особо нравится).
на Си — вполне разумное решение
нет. Это очень опасное занятие. Даже матёрые программисты допускают глупые ошибки, которые могут очень дорого обойтись. Все эти "интерпретируемые языки" зачастую неплохо отлажены и не имеют таких багов, по крайней мере, их сложнее эксплуатировать. Если хотите убер-скорость, но чтобы было безопасно, взгляните на Rust, с его zero-cost abstractions, и какой-нибудь веб-фреймворк для него или на Go и его решения.
P.S. Сам я веб-разработчик и сейчас, как раз, изучаю Rust, но всё равно не стал бы на нём писать веб.
Только PHP, насколько я знаю, позволяет инлайнить код прямо в HTML, остальным языкам (React не рассматриваем) нужны шаблонизаторы.
Java тоже может, либо в серлетах генерить HTML просто как текст, либо инлайнить код прямо в HTML это JSP технология. Но в большинстве случаев оно не несет особого смысла, так как по сравнению с любым запросом в БД шаблонизатор практически не требует времени и ресурсов.
Если язык разработки будет статически и строго типизированным и компилируемым
Отличная идея! Только причём тут low-level? В ассемблере типизации вообще нет, в Си она слабая… А под Ваш критерий лучше подходит Haskell, или Idris, или на крайний случай Crystal.
$object = new $class; неплохо так вынесет мозг рядовому C++ программисту. Но, как заметил, такие штуки нечасто используются.
Все эти абстракции и птичие языки нужны для делегирования работы между разными специалистами, экономии вменении разработки, упрощения поддержки и тестирования.
В один прекрасный момент ресурсы у любого железа кончаются и поднимается вопрос о распределении нагрузок. Так уж получается, что основное время ваша система, пусть даже на С будет тупо ждать ответ. С этого ракурса — написав web систему на C вы не особо выиграете. Если же взять во внимание время, которое вы потратите на разработку — это будет на много дороже.
UPD: хотя судя по всему именно с базой. Статистику по запросам интересно было бы посмотреть. Изучать какие запросы в коробке как-то трудновато, учитывая незнание asm
Это из за рендеринга markdown. Каждый пост обрабатывается отдельно. А markdown вообще транслируется весьма сложно — там два прохода по тексту и сложные правила. BBcode было бы на порядок быстрее.
Можно конечно. Только для прототипа это было не нужно. Производительность пока хватит с избытком. А если понадобится сделать можно очень быстро.
К чему это я? Можно было бы сделать реально что-то очень быстрое, чтобы показать реальные преимущества, а не только теоретические.
Ну я так скажу, у нас коммерческая црм, написанная на php (+phalcon) работает не сильно хуже, когда речь идет о большом кол-ве постов. Понятное дело не 2мс, но 20, по памяти выходит близко к вашему (2-4мб, если замерять средствами php).
Между 2 и 20мс разница в 10 раз. А кстати, на каком сервере работает этот php+phalcon? Параметры моего хостинга даны в статье.
Уаы, но мои сайты на Go быстрее работают. Просто у вас уперлось в бд.
Сделайте хранение данных в памяти и раз в минуту сохраняйте дамп на диск.
Апач думаю даёт мало оверхеда, поэтому можно оставить.
А теперь давайте спросим сколько времени потребовалось сделать такой форум на Assembler, и сколько времени потребуется на эту же задачу «порочным» «PHP, ну или на один из модерных языках Питон, Руби, Node.js и т.д.» программистам.
А теперь давайте спросим сколько времени потребовалось сделать такой форум на Assembler, и сколько времени потребуется на эту же задачу «порочным» «PHP, ну или на один из модерных языках Питон, Руби, Node.js и т.д.» программистам.
Я написал сколько времени потребовалось мне. Но ничего не могу сказать насчет Питон и Руби. Если вы можете, то скажите и сравним.
Но мне кажется, что на ЯВУ, очень грязно и с багами, написать будет быстрее, а вот вылизать все и выдать работающий продукт уже будет вполне сравнимо.
Вылизать все и выдать работающий продукт, то есть работающий на любой базе данных, с сотнями и тысячами unit, интеграционных, e2e и перфоманс тестов, который можно продавать за реальные деньги — может быть будет сравнимо по времени с вашей разработкой, только это совсем другой класс продуктов чем ваш форум. Уж поверьте, ваш форум находится тоже в категории «грязно и с багами», просто потому что его оттестировать по-настоящему долго и дорого.
А без веб Фреймуърков?
Потому что, если считать AsmBB веб фреймуърком, то теперь я тоже за два дня могу чего нибудь подобное написать — например блог или cms.
А что-то более серьезное?)
Не вопрос. :D
Ну оцените для начала, сколько займет реализация HTTPS? :)
А она уже реализована. Давал выше ссылку на RWASA, но опять дам, не жалко: https://2ton.com.au/rwasa/
Замечательный сервер 100% на ассемблере с TLS и FastCGI.
Вообще SSL тут просто в качестве примера — сколько времени займет реализация скажем прокотола SPDY или HTTP 2.0, на асме?
Таких тонких мест в web достаточно много — например, были попытки вызвать DDOS путем передачи сервису заголовков, вызывающих множественные коллизии в hash map, где обычно хранят заголовки сервера на Java. Вы же храните http заголовки? Насколько вам легко поменять тип контейнера?
И так в общем на каждом углу будет — либо все будет в виде библиотек, а тогда зачем ассемблер?
Вот скажем не очень быстрый язык groovy, для JVM. Насколько я помню, на достойном железе, за счет некоторых несложных оптимизаций, безо всякой магии, на нем получали результат порядка полумиллиона http запросов в секунду. Сколько у вас один запрос, 1мс? Так вы значит в 500 раз отстаете, или я что-то неправильно считаю?
Не, ну это же не вы написали.
На ЯВУ пишется быстро и легко именно потому что многое уже написали не мы. То что требовалось доказать.
Насколько я помню, на достойном железе...
Не знаю. Всегда запускал только на очень недостойном железе. Если у вас, есть "достойное", попробуйте запустите и скажите.
Это не http а немного другое — но тем не менее, это получение сообщения из сети, складирование его в базу, некоторая маршрутизация, отдача клиенту снова по сети. Т.е. тут есть все основные компоненты, типичные и для http тоже, кроме разве что шаблонизаторов.
В итоге — меньше 1 мс на сообщение. Память сэкономили? В большинстве практически интересных случаев дополнительная память стоит просто такие копейки, которые с зарплатой программиста несравнимы.
И потом — вы в курсе, что сегодня html страница бывает порядка мегабайта, и зачастую делает много чего интересного на сервере? Т.е. сожрать всю вашу экономию памяти — это просто подключить скажем svg процессор какой-нибудь, или imagemagic, или еще какую-то фигню для генерации контента?
Ну и ради чего стоило так стараться? Разве что из спортивного интереса.
я тоже за два дня могу чего нибудь подобное написать — например блог или cms.
Хорошо, а за сколько вы напишите простой сайт онлайн банкинга с транзакциями и необходимой надежностью?
За сколько напишите интеграцию по Rest и Soup с другими сервисами, прикрутите к вашему форуму Ajax, работу с json и xml?
Загрузку и выгрузку в Excel/Word?
Все это грязно и с багами тоже делается на Java за 2 дня (все вместе). А у вас за сколько? Особенно без хаков с чужими библиотеками.
А без веб Фреймуърков?
А это бессмысленно предложение, серлеты, JSP, orm это официальная часть Java технологии, её вам предоставит любой веб.сервер на Java, это равносильно сказать, за сколько вы сделаете свой сайт без вебсервера.Так или иначе, веб фреймворк, хотя бы на уровне серлета (то есть генератора HTML из текста, на Java будет).
А у вас за сколько? Особенно без хаков с чужими библиотеками.
Странно почему на Java можно использовать чужие библиотеки, а на ассемблере, видите ли, нельзя ???
Хорошо, уточню: без хаков с чужими библиотеками, написанными на высокоуровневых языках. На Java можно обойтись библиотеками, созданными только на Java, а на ассемблере?
В целом, как забивание микроскопом гвоздей разработка забавная, но на любом языке (хоть Java) можно сделать лучше, быстрее и даже производительнее.
Производительнее в том плане что используя многопоточность, нормальные базы данных, кэширование получиться отклик страницы намного быстрее чем вы сможете достичь на ассемблере Так как скорость кода вовсе не означает скорости ответа.
Хорошо, уточню: без хаков с чужими библиотеками, написанными на высокоуровневых языках. На Java можно обойтись библиотеками, созданными только на Java, а на ассемблере?А что, есть JVM, написанная на Java, которой можно пользоваться?
В целом, как забивание микроскопом гвоздей разработка забавная, но на любом языке (хоть Java) можно сделать лучше, быстрее и даже производительнее.Ваша Java на таком хостинге, да и на очень многих подобных, даже не запустится
Производительнее в том плане что используя многопоточность, нормальные базы данных, кэширование получиться отклик страницы намного быстрее чем вы сможете достичь на ассемблере Так как скорость кода вовсе не означает скорости ответа.Надо сравнивать технологии с одинаковым стеком
Ваша Java на таком хостинге, да и на очень многих подобных, даже не запустится
Запустится, Java 8 требует 128 МБ памяти и 126 МБ на диске.
Надо сравнивать технологии с одинаковым стеком
Есть заявление, что на ассемблер все делается легко и просто. И мол зачем вообще нужны высокоуровневые языки. А получается что все делается относительно легко, только если подключать библиотеки из других языков, а никто и никогда не будет делать полноценный стэк подобных технологий на ассемблере (ибо их придется выкинуть при каждой смене архитектуры железа).
Ну да, Java обгонит по производительности Си если подключить библиотеку на ассемблере и делать всю критическую по производительности работу в ней. Только так нечестно сравнивать производительность и нечестно сравнивать скорость разработки ассемблере, если 99% функционала на самом деле будут выполняться на высокоуровневом языке.
Запустится, Java 8 требует 128 МБ памяти и 126 МБ на диске.Я имел в виду аналогичный сайтик на Яве, а не просто JVM.
Проблема скорее в прожорливости фреймворка, чем в JVM.
Проблема скорее в прожорливости фреймворка, чем в JVM.
Значит надо не использовать такие фреймворки. Tomcat или Jetty (это веб серверы для Java) требуют около 12Mb памяти и диска, примерно столько же сколько Апач, при этом дают возможность использовать сервлеты и всякие jsp. Для данной задачи этого с головой хватит.
Но почему то дефолтная установка Tomcat 8 прописана с Xms256Mb.
Я уже молчу про размер виртуальной памяти для Java фреймворка — VSZ в 2.5Гб — то что она намерена сожрать (по необходимости).
Но почему то дефолтная установка Tomcat 8 прописана с Xms256Mb.
Дефолтная установка и минимальная установка это совсем разные вещи. Дефолтная установка не предполагает экономию памяти и вообще предназначена для больших EE приложений, то есть она прописана с огромным запасом (там принцип — память дешевле процессора, поэтому лучше сожрать больше памяти, но работать чуть быстрее).
К тому же я говорил про Tomcat 6/7, они едят чуть меньше памяти чем 8. По дефолту Java приложение съест столько памяти сколько ей «хочется», но можно заставить работать её с и меньшим кол-вом памяти. Тем более если там не будет ничего серьезного вроде транзакций, а простейшие сервлеты, вида сгенерировать html из строк и простых jdbc запросов к базе.
Запустить минимальное серверное приложение, заставить его «прогреться» запросами и показать вывод RSS и VSZ для Java-tomcat процесса
А то, что ты писал про базовое потребление, я на стековерфлоу тоже видел.
Толку от тебя 0.
Задача элементарная, но все эти «сделай бенчмарк», дай отчет об «использовании памяти» в Инете всегда заканчивается одним и тем же: это неправильный отчет/ты исправил цифры в блокноте/ты померил не то и не там/ты запустил на Linux, а надо было на Windows, не на 32 битном процессоре, а на 64битном, не в включенном Compressed Oops, а с выключенном/твоя конфигурация слишком минимальна. И вообще твой Hello World слишком простой, давай сразу форум как у автора напиши.
Не хочу заниматься сомнительной игрой «Докажи, что не верблюд» и тратить время на установку и настройку Tomcat 6/7 в минимальной конфигурации. Плюс если делать исследование по уму, то любой элементарный бенчмарк требует учитывать много моментов и проверять его работу на разном железе/операционках. Если мне нужно будет засунуть tomcat или Jetty в хостинг с минимальными характеристиками, тогда проведу полноценное исследование и напишу статью, но на это придется потратить пару дней, если делать все по уму.
Если у вас есть реальный интерес, а не просто холивары разводить — подскажу на сайте tomcat'а море работающих примеров, скачиваете tomcat, примеры и тестируйте сами.
На bash в конце концов.
Интересная идея.
Насчет применения в коммерческих целях не уверен, но как проект для демонстрации возможностей и эксперимента очень крут.
Всем привет. Извините насчет плохого Русского языка. Некоторые товарищи отредактировали и прислали исправления. Постараюсь все исправить как можно быстрее.
Вот, кажется все отредактировано хотя бы грамматически. Наверное некоторые предложения все-таки звучат не по русски, но я здесь ничего не могу сделать — Русский я учил в школе, примерно 35 лет назад. Читаю много, понимаю все, но падежи для меня очень сильное колдунство :D (их в Болгарском языке нет).
Большое спасибо: gearbox и Protonicus! Ребята, вы мне помогли очень сильно!
А меня заинтересовали параметры хостинга. Такого ада я ещё не видел, чтобы было ограничение на потребление процессорного времени, да ещё посуточно + ограничение на процессы, но при этом можно запускать свой бинарный код, т.е. не PHP/MySQL-only. Как я понял, хостится ваше приложение на https://www.superhosting.bg (судя по IP), но похожего плана у них не видно. Просто интересно, сколько такое может стоить.
По теме: если кого-нибудь интересует веб-разработка на сравнительно низкоуровневых языках, могу посоветовать взглянуть на Wt — приятный виджетоориентированный фреймворк на C++, fullstack. На хабре немного было про него, но довольно старое всё. Я переписал один небольшой проект «для своих» с Java на Wt, сэкономил кучу памяти, т.к. на VDS её всего 1 Гб. Сейчас ест примерно 10 Мб, не течёт.
Понятно, что какие-то личные проекты можно писать на чём угодно, в том числе и на ассемблере, но в современном мире ценится не потребление памяти или скорость работы, а поддерживаемость продукта, т.к. человеческое время ценится на порядки дороже машинного. Этим можно быть недовольным, но остаётся лишь смириться.
Я на Wt делал CloudBerry Backup for NAS. На мой взгляд Wt оправдан в двух случаях:
- вы мало что знаете про html, js, css;
- нужно цепляться к C++ коду.
Я в основном пишу веб-приложения, т.е. не сайты, а именно аналог десктопа, но в вебе. Там чем меньше знаешь и используешь вышеперечисленное, тем лучше. Можно сосредоточиться на бизнес-логике, когда сервер и клиент суть почти одно целое. Разумеется, далеко не у всех так.
Wt вряд ли подойдёт для крупномасштабных приложений, в частности, потому что почти любое действие на клиенте вызывает запрос к серверу. Отзывчивость приложения напрямую зависит от пинга до сервера. Но для embedded это то, что доктор прописал. Компактно, быстро, а если располагается в локалке, то пинг можно считать близким к нулю. Но в целом, фреймворк любопытный и стоит того, чтобы его хотя б потыкать.
Я в основном пишу веб-приложения, т.е. не сайты, а именно аналог десктопа, но в вебе.
Именно этим я занимался в CloudBerry Lab. Делал веб интерфейс к десктопному продукту.
Там чем меньше знаешь и используешь вышеперечисленное, тем лучше.
Не получается. Приходит начальство, приносит крутой дизайн интерфейса на картинке и ставит задачу сделать. В таких ситуациях прибегал к помощи front end разработчиков, которые верстали html/css страницу, которую потом шаблонизировал через WTemplate.
Ну, зависит от конторы. У нас нет фронтэндщиков, дизайнеров, верстальщиков, пишем программы вдвоём. Главный критерий — чтобы выполняло поставленную задачу (преимущественно учёт всех сортов, иногда задачи типа хелпдеска или системы оповещения населения). Дизайна из бутстрапа более чем хватает. Конечно, если делать на продажу и вообще на экспорт, всё сложнее, и с таким мне пока сталкиваться не доводилось.
Именно этим я занимался в CloudBerry Lab. Делал веб интерфейс к десктопному продукту.
Забавно. Когда мы выбирали изначальное имя для одного своего веб-клиента для десктопного приложения, тоже назвали его Cloudberry, независимо от вашего проекта. Потом поменяли, чтобы не было путаницы. А название какое-то… витающее в воздухе, видимо.
А меня заинтересовали параметры хостинга.
Это план "СуперСтарт". Официально 6.75лв в месяц (3.4€). Я плачу несколько меньше (2.5€) потому что покупая когда есть "акция".
Спасибо. Но это действительно неоправданные ограничения какие-то (если было бы 5€ в год, тогда ещё можно понять), за эти деньги можно взять полноценную VDS без лимитов на процессы и время. Я сам покупаю у LeaseWeb, там 4.95€. У OVH можно взять за 2.99€, да, чуть дороже, но зато свой сервер для чего угодно. Я к тому, что ассемблер для сайта был выбран всё же не только потому, что это было интересно, но и для того, чтобы вписаться в отведённые ресурсы. Сейчас можно примерно за те же деньги получить сервер с намного более хорошими характеристиками и ни в чём себе не отказывать.
Я не знаю, что там за vps SuperStart - на сайте не увидел, увидел такое название только в
Так, у меня не VPS, а именно SuperStart shared hosting.
Я могу себе его позволит. Компания отечественная. Поддержка на Болгарском.
Так-то если поискать всякие «секретные» тарифы у хостингов то можно найти за 10-15$ в год впску, правда памяти там будет 512 и вроде 5ГБ диска.
Проект впечатляет, хотя скорее тем, что целиком на асме, а не скоростью работы.
Непонятно почему выбран SQLite, а не PostreSQL или MySQL. Очевидно же, что SQLite — далеко не самая быстрая СУБД.
Кроме того заметил, что поиск тредов по тегу сильно проседает: ~ 20 мс против ~ 7 мс на показ списка всех тредов. Проверьте индексы в таблице пересечения (ThreadTags), думаю, добавление индекса по Tag улучшит ситуацию.
PostgreSQL и MySQL иногда трудно использовать на виртуальном хостинге. А так, все файлы находятся в одном месте.
И не так медленна SQLite как принято считать. Когда все настроено правильно (WAL, работает очень шустро.
Производительность на демо сервере сравнивать не очень удобно. Там у провайдера есть какое-то распределение ресурсов и иногда все начинает работать 2..3 раза медленнее. Конечно, вполне возможно, что некоторые индексы надо добавить и/или исправить.
PostgreSQL и MySQL иногда трудно использовать на виртуальном хостинге.
Это наверно большая редкость… Хоть я уже лет 7 вирутальным хостингом не пользуюсь, но не помню, чтобы с этим хоть раз были проблемы… Неужели за предыдущие 7 лет ситуация с виртуальным хостингом так ухудшилась?
Производительность на демо сервере сравнивать не очень удобно. Там у провайдера есть какое-то распределение ресурсов и иногда все начинает работать 2..3 раза медленнее.
Не, дело не в этом. Да, иногда по тегу и больше 100 мс ответ занимает, но чаще всего попадает в диапазон 20-30 мс и тут явно есть performance-bug.
P.S. Ещё на порядок сортировки тредов обратите внимание: 
Найти хостинг без mysql это надо постараться.
Сочтут идиотом
Поскольку дальше есть этап компиляции Java байт кода в машинный — то еще терпимо. Но есть и интерпретаторы байт кода (другого, не JVM), которые медленные как все прочие интерпретаторы.
А если мы считаем таракана птицей, то что?
Сочтут идиотом
Нет, это корректное допущение. У нас гипотетически может быть «железный» процессор, работающий с байт-кодом. Если у вас есть виртуальная машина, скажем, bochs или что-то аналогичное, работающее с x86 кодом, который является продуктом компилтора gcc, вы же не будете говорить, что мы имеем дело не с компиляцией, поскольку код исполняется виртуальной машиной.
Но есть и интерпретаторы байт кода (другого, не JVM), которые медленные как все прочие интерпретаторы.
И что? Машинный код многих процессоров тоже интерпретируется.
Но речь идет о конкретной платформе, на которой JVM не родной код, так что не надо заниматься софистикой.
Железный Java-процессор кстати, уже был, еще и не один
AFAIK bochs интерпретирует чужой машинный код, потому очень медленный.
Замечательно. Значит то, что некий машинный код — интерпретируется, не делает транслятор в этот код не-компилятором?
Железный Java-процессор кстати, уже был, еще и не оди
Тем более это не дает оснований говорить о не-компиляции.
Но речь идет о конкретной платформе, на которой JVM не родной код, так что не надо заниматься софистикой.
Не додумывайте условий про «заданную платформу». Компилируемость не определяется «конкретной платформой», иначе у нас не было бы кросс-компиляторов.
А чем хуже разрабатывать в компилируемых языках, например в тех же ASP.Net или Java?И нет платформ, ну кроме музея, где байт код JVM был бы родным для процессора.
Потому есть различие — нативный код — не нативный код. Есть ли промежуточная прослойка, транслирующая некий код в нативный или ее нет.
И есть итоговая разница в производительности/ресурсах, требуемых для нее.
Мне надоело.
Про кросс-компиляторы — в учебник.
Про экселсиор я забыл, но там ценник…
И где там .NET?
По С# не специалист, но вроде технология NET Native, описана в MSDN
Про экселсиор я забыл, но там ценник…
Это уже совсем другой вопрос. Технологии есть, а бесплатно или нет — не принципиально. Тот же Delphi никогда не был полностью бесллатен (не в курсе что сейчас с оплатой .Net студии, когда с ней работал она тоже стоило прилично для нашей фирмы).
Так что пробовать можно бесплатно, разрабатывать — ну чуть-чуть придется работодателю заплатить, но тут уже речь идет о нескольких процентах с ЗП разработчика.
Потому есть различие — нативный код — не нативный код.
Такое различие есть, но оно мало отношения имеет к компиляции.
И нет платформ, ну кроме музея, где байт код JVM был бы родным для процессора.
Байт код — родной для виртуальной машины JVM. Ваши требования «нативности» — волюнтаризм, к градации «компиляция-не компиляция» не имеют отношения.
Потому есть различие — нативный код — не нативный код. Есть ли промежуточная прослойка, транслирующая некий код в нативный или ее нет.
И есть итоговая разница в производительности/ресурсах, требуемых для нее.
Упор на производительность — это демагогия, см. пример с компиляцией и Bochs. Компилируемый язык или нет — не зависит от того, нативный ли код на выходе. Если вы, условно, транслируете программу на платформе Win32 / x86 под Linux/Itanium, то вы выполняете компиляцию, хоть тресни. Кросс-компиляцию, но тем не менее.
Мне надоело.
Про кросс-компиляторы — в учебник.
Для начала разберитесь в определениях, которые отличаются от ваших хотелок, потом вернемся к разговору.
Тогда интерпретируемых языков нет — поскольку любой текст программы является родным кодом для её интерпретатора.
Тут надо разделить эмулятор машины и интерпретатор языка. Что bochs, что JVM — эмуляторы машин, кмк.
2)железные JVM
Java, исполняемая на железном JVM — компилируемая. Удачи в поиске такого сервера. В остальных случаях — нифига.
двоичный код x86 запущенный в эмуляторе — да, интерпретируемый. Ну мало ли что он бинарно совпадает с точно таким же компилированным кодом на реальной x86 машине.
А, и ещё. Хотя я не признаю java компилируемой (кроме случая железной JVM, да), интерпретируемой (во всяком случае в привычном понимании) — я её пожалуй тоже поостерегусь называть. Благодаря JIT она является чем-то средним.
В моём понимании, исполняемый в интерпретаторе код в данном случае интерпретируемый, а если тот же код собрали компилятором — то уже вполне компилированный. Логично же, нет?
По-моему, нет. Точнее, здесь играет свою роль неоднозначность слова в русском языке. Интерпретируемый как тип, и как страдательный залог.
двоичный код x86 запущенный в эмуляторе — да, интерпретируемый. Ну мало ли что он бинарно совпадает с точно таким же компилированным кодом на реальной x86 машине
Он интерпретируется, но он скомпилирован.
Не вижу противоречия. Скажем бейсик — исходно был интерпретируемым языком, что не мешает существованию компиляторов. В моём понимании, исполняемый в интерпретаторе код в данном случае интерпретируемый
Поясню еще.
У нас на работе используется свой внутренний скриптовый язык в одном из продуктов. Так вот, в языке есть конструкция вида [] которая перед интерпретацией строки подставляет/вычисляет значение something и замещает квадратные скобки им.
Например:
set %b := 1
loop
set %a := arr[%b]
set %b := %b + 1
while…
что эквивалентно:
%a := arr1
…
%a := arr2
и так далее по ходу исполнения.
Вот это — интерпретируемый язык, потому что данную конструкцию невозможно скомпилировать — строка кода изменяется во время выполнения программы, эту конструкцию можно только интерпретировать. Данный язык — интерпретируемый потому что он в принципе некомпилируем.
И прекратить заниматься демагогией.
У нас гипотетически может быть «железный» процессор, работающий с байт-кодом.
Не гипотетически, а вполне реально у нас может быть процессор, выполняющий байт-код Java «в железе» — например:
- Sun microJava701 (1998)
- Sun MAJC 5200 (1999)
- aJile aJ-100 (2000)
- Imsys Cjip (2000)
- ARM Jazelle (2001)
Но с тех пор технологии JIT-компиляции развились настолько, что аппаратные реализации JVM утратили практическую ценность.
Вот допустим есть проект на C#, я в VS нажимаю «Build» — получаю на выходе EXE файл, который могу запустить. Это не компиляция?
Допустим есть проект на ASP.Net, я в VS нажимаю «Publish» — получаю на сервере DLL файл. Это не компиляция?
Давайте проверим — в случае php я на выходе получаю PHP файл, который могу запустить. Это теперь тоже компилируемый язык? А почему нет? Три буковки не те? А вот в проекте под линукс я получаю на выходе файл без EXE и без DLL — значит он уже интерпретиреумый, да? Ну нет же расширения.
На самом деле, правильно выше написал MacIn — это терминологический спор. Я не считаю, что превращение код для виртуальной машины — это компиляция. Именно потому, что машина виртуальная. Если бы речь шла о некоем реальном процессоре, выполняющем байткот — тогда да, я бы согласился, что это таки компиляция. Поясню на примере, почему я так считаю — если мы запускаем виндовый запускаемый файл под линуксом через wine — он не становится нативным приложением, ведь так? Хотя и выполняется под линуксом. Значит разница в том, что в этом случае имеет место виртуальная среда исполнения. Так и в случае с java и .net — это можно назвать «виртуальной компиляцией». Напомню, что виртуальный — значит «Возможный; условный, кажущийся». Кажется, что это компиляция. Но на самом деле нет.
Так и в случае с java и .net — это можно назвать «виртуальной компиляцией». Напомню, что виртуальный — значит «Возможный; условный, кажущийся». Кажется, что это компиляция. Но на самом деле нет.
Выше уже несколько раз сказано, что есть компиляторы в машинный код с этих языков. Есть и вполне реальные существующие процессоры (и их можно купить и использовать) для байткода Java. Java это только спецификация, а JVM может быть на любых принципах…
если мы запускаем виндовый запускаемый файл под линуксом через wine — он не становится нативным приложением, ведь так?
Не так. Приложение исполняется полностью нативно, на том же процессоре, на котором запущена система. Эмуляция ограничена подменой вызовов.
Кстати, сама ОС может быть виртуализирована. Вы же не говорите, что от этого все приложения в ней стали не нативными? А они могут все исполняться в режиме эмуляции, на виртуальной машине эмулирующей требуемый процессор.
Более того, тот же .Net в нормальных случаях не предполагает исполнения в режиме эмуляции, весь код исполняется нативно.
Мы можем, конечно, привязаться именно к содержимому исполняемого файла. Но можно взять тот же C, откомпилировать и сразу запустить, не создавая никаких файлов вообще. Что в таком случае?
Компилировать — проводить трансляцию машинной программы с предметно-ориентированного языка на машинно-ориентированный язык.
Compile — составлять, собирать.
Вот например если мы интерпретатор бейсика назовём «виртуальная машина бейсик», ну и заодно превратим все команды — в последовательность байт, а не ascii-представление (а на zx-spectrum кстати так и было, там для каждой команды был один байт), бейсик станет компилируемым языком? Ну а что, машина есть — интерпретатор. машинно-ориентированный язык есть. Ну подумаешь команды вычитываются и превращаются в реально-исполняемый код по одной, мелочи какие.
бейсик станет компилируемым языком
Он компилируемый и так и так, без приведенных допущений.
… написание сайтов на ассемблере очень полезно, а с подходящими инструментами — легко и приятно ..
А так получается что статья — «я написал форум на ассемблере — вот он»
Легко и приятно — это высокоуровневый код в котором есть конструкции типа
Бесполезное сравнение. Это, на минутку, разные парадигмы. В одном случае мы имеем императивное, в другом — ООП. Сейчас придет какой-нибудь функциональщик и скажет свое «фи» на ваше ООП.
$user->setNewPassword('123456')->save();
Это субъективно — спору о конвейере Vs проверке кодов ошибок с последовательным исполнением — множество машинных тиков в обед. Мне, например, наоборот, некомфортна такая запись.
А что лёгкого и понятного в коде типа вот такого? Да ничего.
Да всё.
Как может быть понятен код, в котором даже нельзя наименовать переменную так как мне надо (точнее можно, но в том случае если это именно своя переменная а не системный регистр)?
Да элементарно: область видимости сокращается, парой строк выше можно увидеть, что именно задается в esi или какой там регистр использовался. Ну, будет у вас вместо
if(abc* ==…
mov esi, abc
…
cmp [esi],…
И парадигма тут ни при чём. Вот смотрите — как бы там не было, но в моём коде чётко понятно что в $user — очевидно хранятся данные пользователя. И это одна строка кода, урывок из контекста.
Ну так и что-то вроде
mov esi, user
mov eax, [esi+_user.name]
не бог весть какая сложность.
Теперь берём отрывок асма.
bswap eax
откуда мне знать что мы храним в eax в данный момент?
Из знания конвенции вызова. Результат работы функции там хранится. Обмен, очевидно, производится из-за разницы endianess.
А почему сравниваем это? Что такое esi и edx? Сравните какое-нибудь
Потому что, очевидно, мы сравниваем полученный нами ЦРЦ с находящимся в буфере. esi — наверняка указатель на буфер, edx — текущий «бегунок», указатель на ЦРЦ в самом буфере. Я не уверен, что это так — cам код не смотрел. Но исходя из отрывка оно так.
И ооп тут ни при чём — изменить user.type (ооп, объект) на user[«type»] (массив, более функциональный подход) — менее понятно не станет.
Нет, простите, при чем. Давайте тогда смоделируем обсуждаемый отрывок:
bool DoComething(char* buf) {
uint CRC;
char* offset;
…
…
CRC = DataCRC32(buf, offset);
SwapHL(&CRC); — тут я просто не знаю, как это в Си делается
if (uint*(buf + offset) == CRC) {
…
…
и будем сравнивать одинаковые парадигмы. Уже разница не так ощутима. А если использовать в FASM макросы if then else, разница станет еще менее заметной.
Пфф, да понятно что парой строк выше можно смотреть, можно вообще весь код перечитать чтобы понять что в одной строке происходит. Да только вот явное — лучше чем неявное
Не потребуется. Здесь за счет короткого scope'а это будет в пределах взора. Плюс, человек, который «в теме», знает, какие регистры для чего обычно применяются (тот же esi), и у него не возникнет вопросов подобных вашим, а-ля «а что же в eax после вызова GetCRC32 посредством stdcall?»
это позволительно только специфическому языку, но никак не «полезному и удобному»
А Ассемблер — как раз специфический язык. И сам по себе ни фига не удобный, если сравнивать с ЯВУ.
С таким же успехом можно прям в опкодах программировать. Ну а что? Если потом взять таблицу кодов — можно будет легко понимать где что. Удобно и полезно. Почему бы не писать на машинных кодах? Зачем вообще ассемблер, эта ненужная прослойка? Машинные коды — не бог весть какая сложность.
Нет, в случае именно x86 разница как раз колоссальна, вы просто, видимо, не знаете о чем говорите. Даже если мы отложим в сторону то, что мы говорим о макроассемблере, который по функционалу в чем-то близок к Си, пусть ограниченному подмножеству, то основное преимущество использования мнемокода по сравнению с машинным — это расчет адресов.
Понимаете, использовать опкоды вместо ассемблера для написания веб-сайтов — это такая же затея как и использовать ассемблер вместо той же java или php.
Не совсем верная аналогия. Но о неразумности использования ассемблера я автору неоднократно говорил в предыдуших его темах. Еще раз, на всякий случай: не боритесь против ветряных мельниц, я не говорю, что писать сайты на асм вместо php или Java норма, напротив. Парой сообщений выше я уже написал вам, но вы проигнорировали:
Вы пытаетесь доказать, что писать на асме подобные приложения сложно по сравнению с ЯВУ. Это бесполезная борьба с ветряными мельницами. Говоря об удобстве, имеется в виду, что «все не так плохо, как казалось», не более. ИМХО.
А преимущество использования ЯВУ против ассемблера — кроссплатформенность, более удобные абстракции, большая встроенная библиотека, и многое другое.
Разумеется! С этим никто не спорит как бы.
Но вы утверждаете что на ассемблере писать — одно удовольствие.
Не-а. Автор статьи утверждает, что писать на современном макроассемблере fasm — намного приятнее и проще, чем «встарь». По крайней мере, я именно об этом веду разговор.
Так всё-таки — а почему ж тогда сразу не на опкодах? Если расчитывать адреса вручную — так можно вообще дико оптимизированный код писать. Прям каждый такт выжать. А то сейчас привыкли ленивые программисты медленный код писать, ассемблер всё за них делает…
Нет, я же говорю вам: использование современного fasm — это уже ближе к C, чем к традиционному ассемблеру. Такие вот проекты — это показывают. А опкоды и адреса вручную — это шаг в противоположную сторону.
Если расчитывать адреса вручную — так можно вообще дико оптимизированный код писать. Прям каждый такт выжать. А то сейчас привыкли ленивые программисты медленный код писать, ассемблер всё за них делает…
Я понимаю иронию, но она должна опираться на правильных фактов. Нет такие оптимизации, которые нельзя написать в ассемблере. И это отличает ассемблер от ЯВУ.
Ну или дайте пример.
А да и кроссплатформенность это не священная корова. По крайней мере не для всех.
А вот glibc (GNU C library) нельзя скомпоновать статически.
С чего бы это вдруг?
$ dpkg -L libc6-dev-i386 | grep '\.a'
/usr/lib32/libanl.a
/usr/lib32/libBrokenLocale.a
/usr/lib32/libc.a
/usr/lib32/libc_nonshared.a
/usr/lib32/libcrypt.a
/usr/lib32/libdl.a
/usr/lib32/libg.a
/usr/lib32/libieee.a
/usr/lib32/libm.a
/usr/lib32/libmcheck.a
/usr/lib32/libnsl.a
/usr/lib32/libresolv.a
/usr/lib32/librt.a
/usr/lib32/libutil.a
/usr/lib32/libpthread_nonshared.a
/usr/lib32/libpthread.a
Ждём веб-сайт, написанный на VHDL!
Захотел написать пост на форум — взял и допаял.
То есть, если я захочу поправить внешний вид сайта
Внешний вид поправляется через CSS. Этот HTML отражает семантики сообщения.
А почему его убирать? Этот код форматирует сообщение ошибки. Например это: https://board.asm32.info/!message/Habrahabr
Потому что свой шаблонизатор — нужно писать
Я не совсем понимаю о чем вы. Наверное терминология подводит. Давайте уточнить? Это шаблоны: https://asm32.info/fossil/repo/asmbb/dir?ci=930d7bcfcd750ee0&name=www/templates
А пока никак. Все работает, не падает.
Сегодня есть около 5000 уникальных посетителей.
Сервер запускает около 4 копия движка. Иногда 3, иногда несколько больше.
Зарегистрировались 18 человек. Написали несколько десятков тестовых постов.
Попробовали XSS, не получилось.
Попробовали переполнение буфера — не получилось. Буферы не переполнились, но нашелся баг — когда название темы очень длинное, скрипт третирует его как имя файла и возвращает "Forbidden". Скоро исправлю.
Буферы не переполнились, но нашелся баг — когда название темы очень длинное, скрипт третирует его как имя файла и возвращает "Forbidden". Скоро исправлю.
Нет не исправлю. Это баг Apache :(. Баг репорт написали в 2008-го года, но баг живой и шевелится. Наверное, потому что на C пишется намного быстрее чем на ассемблере. :D
На lighttpd все работает.
Ну и, в нике дыра XSS)
А вот за это спасибо. :) Сейчас заделаю. И XSS тоже.
Ник должен показываться как и раньше, но код не должен исправляться. К тому же, по логике, логиниться я должен также как и раньше <script>alert...., а не & lt;script& gt;alert(1);& lt;/script& gt; (без пробелов)
А вообще, единственно верным решением этой проблемы было бы на хрен выпилить всех подобных юзеров и поставить ограничение по типу и количеству символов. Ибо не хрен)
Что-то вы накосячили с исправлением XSS'а)
Я ничего еще не исправлял. Работаю над кодом. А это так, на время, только отредактировал в БД.
А вообще, единственно верным решением этой проблемы было бы на хрен выпилить всех подобных юзеров и поставить ограничение по типу и количеству символов. Ибо не хрен)
Наверное так и сделаю в конце концов. :) А этого юзера придется стирать.
Исправил. Теперь должно быть ОК. И XSS и ошибка 500.
Правда, тот юзер пришлось удалить.
Спасибо, еще раз. :)
Вне обсуждения практичности, автор крут!
Так как ассемблер линковался с библиотеками, то для следующего сайта, наверное, стоит взять ассемблер от от Го. Тогда даже некоторой переносимости можно будет добиться, например.
Ассемблер (х86) я знал не плохо и веб сервер тоже пытался писать. Но потом я понял, что есть 64битные системы и sse наборы инструкций, которые лучше справляются с некоторыми задачами, но изучать сотни новых инструкций мне не хотелось. Поэтому асм был заброшен навсегда (никогда не говори никогда). Когда я вернусь в низкоуровневый мир, я буду «программировать» под плис! Вот уж где низкоуровневость себя действительно оправдывает, а отсутствие кросс-платформенности не так критично.
Не все так плохо. Мои тесты показывают, что если программисты пишут не оптимизированный, достаточно сложный код (чтобы оптимизировать было не очевидно), то программы на ассемблере всегда получаются быстрее. И быстрее намного. А не оптимизированный код — это 99.9% всего кода в мире.
Дело в том, что программисты ленивые и всегда пишут так как им легче. Вот, на ассемблере, легче (почти) всегда пишется так как проще, а это (почти) всегда быстрее. Потому что проще, на ассемблере означает и проще для процессора.
А "проще" на ЯВУ, совсем не означает "проще для процессора". Поэтому, чтобы стало быстрее на ЯВУ, нужно прилагать нешуточные усилия, а код получается далеко не читаемым.
Такая простая процедура, а тема как разрослась!
Так тоже бывает, но только когда код нужен совсем наибыстрейший. :D
Когда пишутся глубокие оптимизации, то скорость оптимизированного кода на ассемблере и на C будет приблизительно одинакова. Ну пусть ассемблер будет на 10..20% быстрее. (Но читаемость кода на ассемблере все таки будет лучше).
Но дело в том, что 99% программ в мире, наоборот — совершенно не оптимизированные. Вот там, разница в производительности будет в десятки раз.
Я делал такие эксперименты дважды или трижды и всегда было так. Конечно, программисты должны быть одинаковой квалификации, а программы достаточно большими, чтобы нельзя было заняться сразу глубокими оптимизациями.
Ждем от вас в десятки раз более быстрого браузера.
Когда хороший браузер писался в одиночку??? Как соберутся энтузиасты, так сразу и возьмусь.
А пока пишу хорошее IDE и GUI библиотека для FASM.
Веб программирование на ассемблере, просто хобби и повод написания провокационных статей. ;)
Да, сложно предположить, что кто-то возьмется так работать в коммерческой разработке. Но для научных целей — вполне годится.
Видел также статью одного умника на английском языке. Он писал о том, как глупо в наше время писать сайты на чем-то интерпретируемом, а не на C. К сожалению, ссылку не сохранил. Как минимум, после Вашего эксперимента, есть смысл ее перечитать. Там схожие мысли были. Как минимум, они заслуживают внимания.
Было бы интересно (откровенно говоря только в этом и интерес) провести полное нагрузочное тестирование этого решения.
Тут есть проблемка… Автор хорошо разбирается в ассемблере, но плохо в веб-программировании… Поэтому сайт получился не особо быстрый с точки зрения пользователя. Для примера запустил простенький тест на LoadImpact. VU load time получился в районе 2.3 секунды (даже всего при 3 посетителях), это уже медленно.
Так что устраивать серьёзное нагрузочное тестирование смысла нет. Веб-сервер скорее всего не настроен должным образом и просто захлебнется под нагрузкой даже не дойдя до кода автора.
Для сравнения у Хабра VU load time в районе 1.7 секунды (быстрее 2 секунд — это хороший результат).
на таком фреймворке можно было бы писать вебсервера для микроконтроллеров, например веб оболочку для умного дома.
все равно когда нибудь наверное придем к тому что на контроллере обычной лампочки можно будем устанавливать формуы/блоги/магазины.
не рассматриваю проект для себя как нужную платформу для какого то дела, но это хорошая стартовая точка для дальнейшего развития, чего и желаю автору от всей души.
все равно когда нибудь наверное придем к тому что на контроллере обычной лампочки можно будем устанавливать формуы/блоги/магазины.
На этаж выше меня сидят IoT-разработчики, которые действительно пишут веб-приложения, встроенные в лампочки.
Уверяю вас, они пишут на C и C++, потому что им переносимость между разными контроллерами важнее потенциальной экономии килобайта памяти.
Если серьёзно, вы играете на поле, где ваш подход имеет немного смысла — достать 100 кусков текста с бд, отформатировать и отослать клиенту. Это работа базы даных, шаблонизатора, веб-сервера, и немного прослойки вроде вашего кода. Я на rake напишу такой код в обход фреймворков и он заработает на очень плохом хостинге, хотя и проиграет пару мс вашему варианту.
Но. Если вы бекенд, допустим, Призмы, если вы считаете в реальном времени кластеризацию данных от клиента, если вы строите маршрут алгоритмом, который не зависит или слабо зависит от БД, если вам надо посчитать уникальный набор чисел, которые идентифицируют человека на фото относительно пред-рассчитанного базиса, и вообще найти человека на фото — вы сможете обойти конкурентов всерьёз. Не знаю, насколько вы обойдёте tensorflow который на c + python, но это имеет на порядок больше смысла, чем собирать тексты с бд в единый кусок HTML.
чистых независимых вычислениях на нагружённом сервере
У нас был подобный проект, когда не было ни бд, ни шаблонов, просто очень быстрый код, который должен давать очень быстрый ответ на множество запросов «клиентов» из веба. В общем, несмотря на то что код был на Java, мы в первую очередь уткнулись в максимально возможное кол-во одновременных соединений по TCP к серверу, а переходит на UDP было слишком сложно. Скорость кода тут оказалось делом десятым, от перехода к C или ассемблеру мы ничего бы не выиграли.
Да, если требовалось много сложных вычислений, то С++ или С нам бы помогли, но это не имеет отношения в вебу, достаточно переписать только критичную часть.
Если написать в сообществе программистов, что вы собрались писать форум на ассемблере, чтобы он работал на дешевом хостинге, есть довольной большой шанс, что вам придёт несколько небольших пожертвований. Но с поточными расценками на хостинг даже небольших пожертвований хватит, чтобы этот хостинг держал пару десятков тысяч уникальных посетителей в день год или больше.
Дело не в форуме. Мне форум не нужен как таковой. То что я инсталлировал, просто демо, чтобы можно было потрогать руками.
И если дело в одном форуме то конечно заплати и спи спокойно. Но дело здесь в принципе. Если сделать бакенд вдвое легче (а AsmBB более чем вдвое легче эквивалента на PHP) то при прочих равных вы сможете обслуживать за те же деньги вдвое больше посетителей. Ну или сэкономить половину бюджета. А половина, иногда может быть много миллионов. Не так ли?
Я на rake напишу такой код в обход фреймворков и он заработает на очень плохом хостинге, хотя и проиграет пару мс вашему варианту.
Я в комментариях уже наверное 100500 раз прочитал, как на языке X и Y все это пишется за 2 часа и будет конечно и быстрее и память будет жрать меньше и поддерживаться лучше.
И языки были и Java и PHP и C. Вот теперь rake (никогда не слышал, может это и не язык).
Только ведь, не пишут, только болтают.
Потому что реальный проект просто так не пишется. Тем более за 2 часа или 2 дня. Там многое чего нужно придумывать.
А вот вы возмите и напишите. Сделайте хранилище кода, а мы посмотрим как быстро у вас получится. Поставьте где нибудь демо.
А мы посетим, зарегистрируемся. Понагрузим хабра-эффектом. Поищем XSS уязвимостей. Осмотрим на каком хостинге это установлено. И вывод сам сделается.
Но ведь не напишете.
Но дело здесь в принципе. Если сделать бакенд вдвое легче (а AsmBB более чем вдвое легче эквивалента на PHP) то при прочих равных вы сможете обслуживать за те же деньги вдвое больше посетителей. Ну или сэкономить половину бюджета. А половина, иногда может быть много миллионов. Не так ли?
Мне кажется, это ошибочное предположение, что основная часть бюджета тратится на вычислительные ресурсы. Основные затраты — это разработка и сопровождение.
Конечно, если проект написан раз и навсегда, и больше в нем на 100% нет никаких синтаксических и логических ошибок, то да — бюджет будет тратиться только на ресурсы сервера. Но я в природе таких проектов еще не встречал :)
Поэтому переписав все на асме получится практически та же стоимость сервера, хорошо если выигрыш будет 25-30%.
Все это так, но не совсем.
Ваши все вычисления предполагают, что разработчики будут работать в одинаковом темпе, во все время жизни проекта. Работает сервер, тысячи посетители посещают сайт, читают, пишут, общаются, а в то же время 5 девелоперы, каждый день, 8 часов подряд, пишут новый код, фиксят баги и т.д. И так в продолжении 10..20 лет.
Но ведь так не бывает. Разработка всегда движется по экспоненте — в начале все работают много, потом работа уменьшается и приоритеты смещаются — примерно исправляются ошибки.
Во вторых, вы пишете насчет разработки очень специализированного софта, который будет работать на одном сервере и нигде больше. Но так тоже далеко не всегда. Если взять например SMF — там тоже разработчики работают все время (и опять интенсивность работ совсем не всегда одинакова), но их программа установлена на десятки тысячи серверов и суммарные расходы на хостинг просто сумасшедшие.
почему же никто не использует это в промышленных масштабах? Да потому что в наше время кроссплатформенность и человеческий ресурс сильно важнее железа. Железо всегда можно докупить.
У сервера есть несколько узких мест:
1. Максимальное количество открытых соединений,
2. Скорость записи на диск (базы данных, файлы),
3. Скорость обмены с другими серверами (удаленный базы данных, микросервисы),
4. Память (читай кэши),
5. Канал трафика,
6. Процессор,
Так вот использование низкоуровневого языка влияет только на процессор, на память он виляет слабо, исходный код это меньшая часть памяти, большая часть съедают структуры данных и кэши (кэши вебсерверов, кэши баз данных, объекты бизнес логики и т.п.). А современное железо достаточно производительно, и в типовом бекеэнде веб приложений процессор редко бывает узким местом. Ускорять код, когда процессор и так никогда не бывает загружен даже на 50%, можно, но это мало чем поможет если пользователи уперлись в трафик или скорость записи на диск. Отсюда огромную экономию низкоуровеневые языки в вебе дают редко (и обычно проще переписать только кричиный код на таком языке).
Ассемблер то быстрый, а сайт получился медленный:
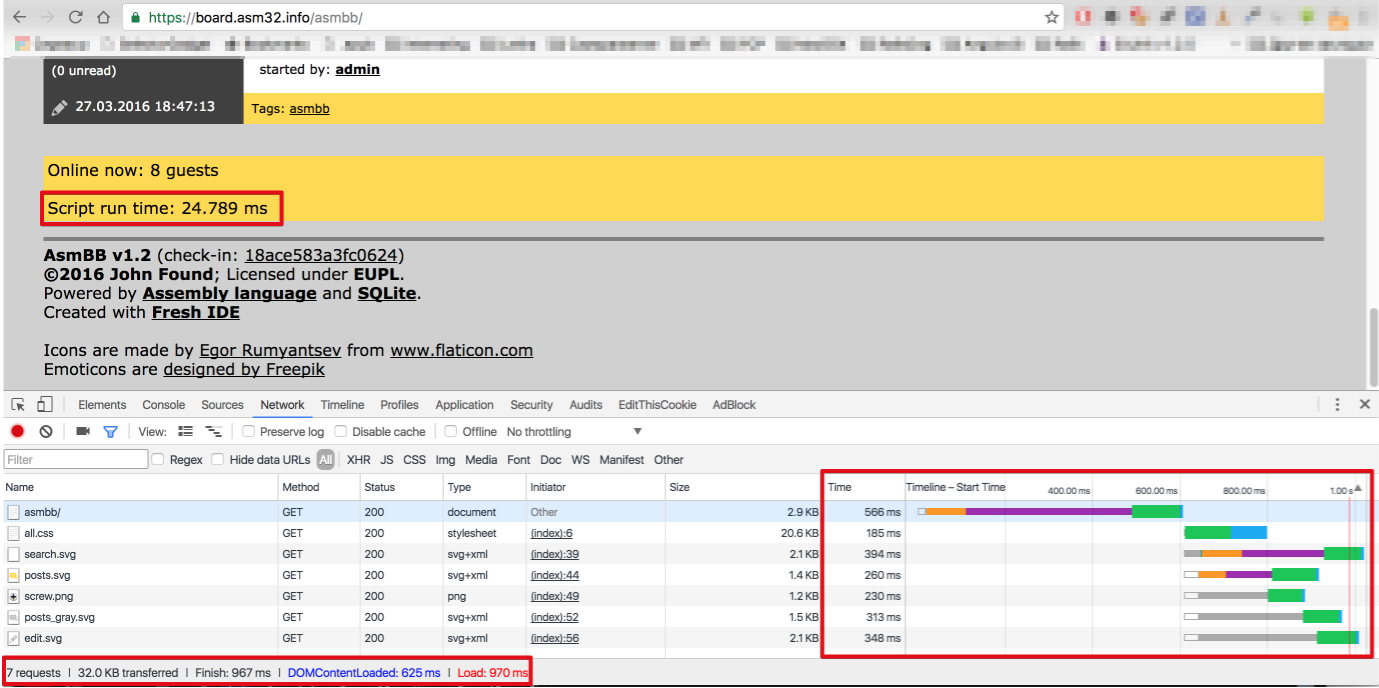
При оптимизации сайтов главная метрика — load time, а не время генерации на сервере. Да и временем генерации ответа за миллисекунды сложно удивить, было бы меньше 1 ms — было бы круто. А текущие результаты (6 — 30 ms) можно и на ЯВУ воспроизвести. Т.е. в теории выигрыш от применения ассемблера должен быть, но на данном примере его не видно.
0.97с это долго? А сравниваете с чем?
Это не так чтобы очень долго, но и не быстро. Считается, что меньше 2 секунд — это приемлемый результат для среднестатистического сайта.
Но, учитывая достаточно простой дизайн (малое кол-во картинок и CSS) и практически пустую БД, можно было ожидать хотя бы в районе 0.5 секунды.
Обратите внимание, что у Вас плохие показатели по Initial connection и по TTFB. Не факт, что Вы можете на них повлиять, т.к. они зависят от настроек сервера. Но дело в том, что они добавляют сотни миллисекунд оверхеда, на фоне которых экономия пары миллисекунд за счёт применения ассемблера совсем потерялась.
А вот вы возмите и напишите. Сделайте хранилище кода, а мы посмотрим как быстро у вас получится. Поставьте где нибудь демо.
А я вот взял и написал.
https://github.com/michael-vostrikov/asm-bb
http://michae9j.bget.ru/test/asm-bb/
Логин: admin
Пароль: 123456
В сумме ушло часов 10-12. Не знаю насчет хабраэффекта, тариф минимальный, посмотрим сколько выдержит. Функционал скопирован не полностью, но для proof of concept хватит. Нет загрузки файлов, закрепления тредов, редактирования/удаления комментов и тредов, профиля пользователя, и прочих полезных мелочей. На них оценка от одного до нескольких дней, в зависимости от требований. Для комментов используется не markdown, а HTML с обработкой через HTMLPurifier. Да, специально для вас, коммит с добавлением поля для скомпилированного HTML.
Я в комментариях уже наверное 100500 раз прочитал, как на языке X и Y все это пишется за 2 часа. Только ведь, не пишут, только болтают. Потому что реальный проект просто так не пишется. Тем более за 2 часа или 2 дня.
Ну, кстати, load time у Вас получился 0.35 секунды (против 0.97 у демо asmbb), даже несмотря на то, что оставили без объединения 3 CSS и 3 JS-файла. Так что отзывчивость сайта оказалась почти в 3 раза лучше, просто за счёт более хорошего хостинга.
А скорость разработки пока так:
3 дня и 27 коммитов, а версия, согласитесь что сырая. (Кстати, вы начали писать 3-его Января?!)
У меня, для v1.0 понадобилось 54 коммитов.
Так что если привести эту работу к v1.0 по моему брой коммитов будет очень близко к те 54.
О! Уважаю! Теперь давайте приводить в вид, которого можно было сравнивать:
- Script runtime добавьте. Как иначе сравнивать будем.
- markdown, компилировать сложно и медленно. Так что форматирование через HTML, несколько не то. Нет готовых библиотек что ли?
- Добавьте счетчик "read count" на каждом посте — это важно, потому что делает запись в базе данных на каждом посте.
- Индикация непрочитанных тем — это тоже совсем не тривиальная проблема, которой я решал нескольких дней.
Функционал скопирован не полностью, но для proof of concept хватит.
Насчет оценки быстродействия может и хватит — но, конечно если добавите измеритель (см. 1)
Но насчет сравнения времени разработки не хватит, потому что у вас нет:
- Редакция и удаление темы.
- Редакция потребительского профиля. Аватары.
- Поддержка сессии. Например я не могу разлогинится.
- Администраторская панель. У меня их 2 — общие настройки и SQLite конзоль.
- Права доступа. Сейчас, администратор никак не отличается от потребителей.
А чтобы сделать все это нужно время. И так эти 12 часов превратятся в намного больше.
2. Markdown для форматирования постов выбрали вы, мне было удобнее взять HTML. Форматирование постов есть? Есть.
3. См. п.1, цель не в быстродействии.
4. Не, спасибо. Еще один день неохота на это тратить. Лучше опишите проблемы, которые у вас возникли.
1. Если посмотрите в коммиты, там был код для редактирования и удаления. Я его убрал, потому что неохота было делать интерфейс.
2. Да, это самая долгая часть из оставшегося.
3. Если есть логин, значит есть и сессия. Возможно, у вас скрипты отключены. Кстати, вы в курсе, что не рекомендуется делать logout по GET-запросу?
4. Админка есть, только там ничего нет: http://michae9j.bget.ru/test/asm-bb/admin/. Отладочная панель есть в debug-режиме, сейчас включен production-режим.
5. Это не так долго, есть готовый компонент для управления доступом на основе ролей. Тут смысл не в том, что он готовый, а вы писали сами, а том, что подключить новый компонент в проект на ЯВУ гораздо проще.
А чтобы сделать все это нужно время. И так эти 12 часов превратятся в намного больше.
По текущему функционалу можно оценить время остальных доработок по пунктам 2,4,5. Оценку я уже дал — несколько дней, максимум пусть будет неделя. Но как я уже сказал, больше время на это тратить не хочется.
Этим проектом я хотел показать преимущества от разработки на ЯВУ. Время на разработку уходит в несколько раз меньше (счет идет на дни, а не на месяцы), решение получается более переносимое (можно подключить любую БД), сложность и время внесения изменений гораздо ниже (пример с добавлением поля), решение будет гораздо понятнее для новых разработчиков.
Из преимуществ ассемблера только призрачная скорость выполнения кода.
- Смысл был в том, чтобы показать скорость разработки аналогичного проекта на языке высокого уровня. Я не ставил себе цель сравнивать миллисекунды.
Я тоже провел эксперимент. Мне очень трудно считать сколько времени отнимет та или другая задача. Поэтому, решил реализовать кеширование HTTP (как советовали), но измерить точное время работы.
Эта задача очень подходит под эксперимент, потому что код которого надо было менять писался весной и больше никогда не менялся (ну может быть были некоторые багфиксы). Так что задача получается очень реалистична. Надо менять код, которой писался давным давно, надо сориентироваться и потом поменять его.
Получилось ровно 78 минут.
Можно было и быстрее, но мне не хотелось удалять старую БД, поэтому пришлось писать и код который рендировал все старые посты на сервере.
А, да. Весь код, который менялся за те 78 минут здесь: HTTPCache
В то же время, на задаче кластеризации данных от датчиков, которые поступают непрерывным потоком, руби берет 30 секунд на порцию. На python и tensorflow/или аналог должно отработать в разы быстрее. Вы бы з хорошим знанием ассемблера код под конкретную задачу разогнали бы до нескольких секунд. А это задача, которая начальный по цене хостинг грузит 100% почти треть времени (причём это ограниченная по объёме выборка данных). Я вижу, как решения, которые работают быстрее, могут принести реальную пользу. Но зачем, кроме фана, нужен ассемблер в задаче, где нет никаких вычислений, я все же не понимаю.
Но зачем, кроме фана, нужен ассемблер в задаче, где нет никаких вычислений, я все же не понимаю.
А разве фан, это плохо?
Я пишу на ассемблере много чего. Часть моего кода (например программы управления промышленного оборудования) закрытая. Можно посмотреть некоторые картинки здесь.
A вообще, больше всего нравится писать десктоп приложения. Но написание AsmBB было мне очень полезно. Я научил что это FastCGI, SMTP, XSS и много всего из мира WWW/HTTP. Разве это плохо?
Используя рекламную площадь комментария, попрошу совета. Как проще всего зайти в ассемблер на уровне «оптимизация некоторых функций» программисту, который кроме программирования на си микроконтроллера, работал только с высокоуровневыми языками?
Как проще всего зайти в ассембер на уровне «оптимизация некоторых функций» программисту, который кроме программирования на си микроконтроллера, работал только с высокоуровневыми языками?
"Зайти" на уровне "оптимизация" не получится. Оптимизация, это высший пилотаж. Поэтому лучше просто начать писать на ассемблере неоптимальный код. Скачайте FASM или Fresh IDE, почитайте примеры которые в архиве. Напишите небольшие программы, которые вам нужны.
Общайтесь на форуме FASM. Спрашивайте на stackoverflow. Постепенно все образуется.
Не стоит делать то, что многие рекомендуют — читать выход компилятора на C. Люди пишут на ассемблере совершенно по другому.
А вот gcc…
Дело не в то как компилятор компилирует, а в то что компилирует он код, который написан на ЯВУ. Вся логика у этого кода не ассемблерная, а именно логика ЯВУ. Человек, который писал этот код, скорее всего написал эго так как легче и лучше именно C или на Паскаль.
Когда человек пишет на ассемблер, он пишет так как легче и лучше писать именно на ассемблере.
Собственно, и Асм и С и Паскаль императивные языки и, за исключением ньюансов по использованию регистров, логика одинаковая (я только не знаю, что курили создатели gcc=).
Для более совершенных ЯВУ, уже нет такого подобия.
Хотя я и видел примеры, что на ассемблере можно весьма наплевательски нарушать все правила структурного программирования Дейкстры, но эти программы потом весьма тяжело читаются и сопровождаются.
Я не говорю о компиляторах — они делают свою работу прекрасно.
Я говорю о логике ЯВУ. Давайте дам пример. Пусть требуется сделать поиск строки в массиве строк. На каждом ЯВУ, это проще всего сделать через цикл, ну или (если массив сортирован) через бинарный поиск. Потому что в ЯВУ есть сравнение строк. Там можно написать:
if MyString = Arr[i] then return iКонечно это будет не так быстро, но коротко, ясно и естественно. А все знают что “Premature optimization is the root of all evil”. Поэтому так и оставят.
А вот, на ассемблере, этот подход уже не так удобен. Потому что там сравнение строк нет. Придется сравнивать побайтно. Появятся вложенные циклы. Не хватит регистров. Читаемость кода ухудшится.
Программист, который раньше писал на ЯВУ так и напишет. Потому что по другому он не мыслит. Он знает что это самое простое решение, а то что получается плохо, это из за дурацкого ассемблера.
А на ассемблере, намного проще сделать поиск через хеш таблицу. Потому что там все циклы одиночные, короткие и ясные. Код получится намного проще и понятнее. Даже совершенно наивная реализация хеш функции сделает поиск намного быстрее. И заметьте — никакие ранние оптимизации — пишем так как проще, а не думаем о скорости. Она получается сама.
Этот пример не высосан из пальца. Именно так получилось однажды, когда организовали битвы "assembly vs c++" на одном болгарском форуме. Надо было сделать парсер markdown (кстати, парсер в AsmBB результат именно этой битвы). Так первая версия на ассемблере была в 80 раз быстрее чем на C++, только из за этого.
А на ассемблере, намного проще сделать поиск через хеш таблицу. Потому что там все циклы одиночные, короткие и ясные. Код получится намного проще и понятнее. Даже совершенно наивная реализация хеш функции сделает поиск намного быстрее.
Но и на ассемблере нужно подобрать такую хеш функцию чтобы работала быстро, если сравнивать по хешу.
Хеш вычисляется только однажды, а сравнение делается с каждой строке в массиве. Посмотрите ниже — я дал пример.
Я не отрицаю преимущество использования хэш функции в частном случае:
Сравнение по хэшу имеет смысл когда много сравнений в неизменяемом множестве строк,
Я лишь возражаю против вот этого обобщения:
то он понимает, что сравнивать побуквенно — это лишняя трата ресурсов
Потому что в общем случае сравнивать побуквенно эффективнее чем считать и сравнивать хэши.
Сравнение по хэшу имеет смысл когда много сравнений в неизменяемом множестве строк,
А почему в "неизменяемом"? Вполне может быть и изменяемом.
Потому что в общем случае сравнивать побуквенно эффективнее чем считать и сравнивать хэши.
Нет не так. Побуквенное сравнение будет эффективнее только в некоторых частных случаях. Например когда массив очень небольшой. Но когда массив небольшой и почти сортивован, даже сортировка пузырком может быть быстрее quick сорта.
Но дело в том, что каждой небольшой массив всегда вырастает после две версии программы. ;)
Кстати, мне кажется, что вы не совсем понимаете как работает хеш-таблица. Там нет поиска в массиве и нет циклов, кроме однократного вычисления хеша.
Кстати, мне кажется, что вы не совсем понимаете как работает хеш-таблица. Там нет поиска в массиве и нет циклов, кроме однократного вычисления хеша.
А что происходит в случае коллизий?
Но дело в том, что каждой небольшой массив всегда вырастает после две версии программы. ;)
Заменить линейный поиск на поиск в хэш-таблице — дело 5 минут (если код хорошо спроектирован).
Но часто выясняется более веселое. Нужно сравнивать строки не как попало, а по умному.
Во-первых, строки бывают в юникоде. Простое сравнение уже не всегда работает. Хеш-функция должна это учесть.
Во-вторых, сравнивать нужно без учета регистра. Иногда. Опять же простым сравнением не получается. Хеш-функция должна это учесть и это.
Для дополнительного веселья выясняется, что один из поддерживаемых языков имеет странные правила. И сравнивать строки нужно с учетом этих правил. Хеш-функция разрастается в монстра.
И тут уже все сильно зависит от доступного инструментария. Многие ЯВУ содержат встроенные средства для работы со всем этим. Хотя тот же C++ нет, но можно что-то найти.
А что происходит в случае коллизий?
Колизии происходят очень нечасто и поэтому не влияют на производительности алгоритма. А если случаются часто, то надо исправлять баги.
Даже не буду комментировать насчет 5 минут. Вы ещо операционку состряпаете за 5 минут на JS. :P
Но часто выясняется более веселое. Нужно сравнивать строки не как попало, а по умному.
Конечно, когда пишется программа, применяются разные алгоритмы.
Но не понятно, почему этот очевидный факт должен доказывать чего нибудь насчет вполне конкретного примера??? Или сравнивая побайтно легче сделать сравнение UTF-8 с combining characters (например (U+0061)+(U+0301) == (U+00E1))? Не думаю.
А очевидный факт должен показать, что из примера "поиск строки в массиве строк" совсем не следует оправданность применения хэш-таблиц.
Ситуации могут быть разные.
Если нам требуется выполнить одноразовый поиск в массиве, то очень запросто может оказаться, что проход по массиву со сравнением будет куда быстрее, чем создание хэш-таблицы (или хэш-множества) из-за высокой трудоемкости первоначального создания хэш-таблицы.
Есть ситуации, когда хэш-таблицы эффективнее. И их использование следует из логики выполнения, не из удобства для реализации. Если разработчик не увидел этого, это говорит о разработчике, не о языке.
С учетом этого становится очевидно что использование хэша выгодно когда КАЖДАЯ строка используется в сравнении несколько раз (или в нескольких сравнениях) Если надо один раз сравнить строку по множеству — смысла считать хэш нет. Ну и, как выше отметили — коллизии. Чем меньшую вероятность коллизии дает хэш функция, тем она, как правило, более ресурсоемкая. Проблемы с кодировками или регистром решаются нормализацией строки, их я пропускаю.
Да, и мы еще не рассматривали суффиксное дерево, которое на многих случаях пододвинет и брутальное сравнение и хэши. К чему это я. Просто не надо вот ТАК обобщать:
то он понимает, что сравнивать побуквенно — это лишняя трата ресурсов
Это не Вам, это автору этих слов. Без агрессии, просто объясняю свою позицию.
С учетом этого становится очевидно что использование хэша выгодно когда КАЖДАЯ строка используется в сравнении несколько раз (или в нескольких сравнениях) Если надо один раз сравнить строку по множеству — смысла считать хэш нет.
Мне все-таки кажется, что вы не понимаете как работает хеш-таблица. Мне кажется, что вы думаете что там в массиве кроме строки сохраняется и хеш этой строки и когда нужно сравнить строку по множеству мы циклим по массиву, только сравниваем не строка с строкой, а хеш с хешем.
Поиск строки в хеш таблицу состоится от:
- Вычисление хеша строки которую будем сравнивать — пусть будет h
- Смотрим в hash_table[h] — если там 0 то строки нет в массиве. Если там указатель <>0 — то строка есть в массиве.
Это все, даже если в таблице есть миллиардов строк. Поиск будет занимать только одну проверку в массиве. Сложность О(1).
Я сознательно опустил проверки на коллизии, но они не уменьшают скорость, потому что случаются нечасто. Разрешение коллизии просто немножко удлиняет код. Этот код в большинстве случаев не выполняется.
>Вычисление хеша строки которую будем сравнивать — пусть будет h
Строку выбираем? Что бы вычислить хэш. Выбираем. Всю? Всю.
Сравниваем побайтово. Один раз. Строку Выбираем? Выбираем. Всю? Нет. Сатистически — 1/2 от средней длины строк. Так как сравниваем две строки — то в среднем выборка равна средней длине строки. При разовом сравнении — побайтовое сравнение выгоднее.
Дальше. Эффективность хэш таблиц проявляется при МНОГОКРАТНОМ сравнении строк (сортировки, выборки). Но тут конкурент — суффиксное дерево. На котором не надо строить на каждой строке хэш, а надо строить дерево, которое, при достаточно плотном распределении строк может памяти занимать меньше чем исходный набор строк. И при таком сравнении:
Смотрим в hash_table[h] — если там 0 то строки нет в массиве. Если там указатель <>0 — то строка есть в массиве.
по любому получаем засаду — либо у нас маленький хэш (32 разряда — это ОЧЕНЬ маленький хэш для строк) с большой вероятностью коллизий, либо у нас нормальный хэш, но тогда проблемы с распределением памяти (и виртуальная память тут не спасет — даже одна строка будет вызывать необходимость выделить физическую страницу в памяти). И тогда нам нужно либо иметь более умный алгоритм (учитывающий в том числе и коллизии) либо вообще не хэши. То есть для принятия решения (какой алгоритм применять) надо учитывать среднюю длину строки, плотность распределения, объем памяти. Собственно то, что делают движки баз данных, применяя оптимизации на основании собранной статистики на прогретых базах.
Поймите, я уже третье сообщение пытаюсь донести — я не против хэшей. И не за. Есть задачи на которых они работают хорошо, есть где не очень. Я вообще не про хэши начал диалог. Я попытался отметить тот факт что простое сравнение не всегда сливает хэшам и прочим алгоритмам. Есть большое множество задач, где простое сравнение работает лучше остальных. И глупо говорить что использовать его — пустая трата ресурсов. Глупо том смысле, что это неоправданное обобщение.
А приведите код для поиска через хеш-таблицу? Как-то не очень верится, что он намного проще "=" или "rep cmpsb". И на ЯВУ тоже можно хеш посчитать, если ставить цель именно оптимизировать выполнение.
"rep cmpsb"
Так сравнивать строки обычно нельзя. Потому что длина неизвестна.
А приведите код для поиска через хеш-таблицу? Как-то не очень верится, что он намного проще "=" или "rep cmpsb"
Напишу. Только проще <> короче. Код там будет несколько больше, но его будет проще писать и читать. И конечно будет намного быстрее.
И на ЯВУ тоже можно хеш посчитать, если ставить цель именно оптимизировать выполнение.
Конечно можно. Но там это будет "оптимизация" — то что делается когда иначе никак нельзя. А на ассемблере, это будет проще написать, не думая о производительности.
Так сравнивать строки обычно нельзя. Потому что длина неизвестна.
Ну так и хеш неизвестен. Вместо вычисления хеша можно вычислять длину строки (это тоже вариант хеш-функции). Или вообще вычислять заранее и хранить вместе со строкой. Вы мыслите в алгоритмах ассемблера, а это уже ближе к ООП.
И начинать можно со сравнения длин строк. И сравнивать с конца. Так что неизвестно, какой код будет быстрее работать. Поэтому преждевременная оптимизация — зло.
Код там будет несколько больше, но его будет проще писать и читать.
Чем это проще чтения знака "="?
Но там это будет "оптимизация" — то что делается когда иначе никак нельзя.
Правильно. Потому что преждевременная оптимизация — зло.
Ну вот один простой пример. Жаль что нет подсветки синтаксиса. Здесь даю только процедуры которые делают работу.
Весь тестовой проект можно скачать здесь. Компилируется в Fresh IDE для Windows, Linux или KolibriOS.
uglobal
hash_table rd 65536
endg
; returns 16 bit hash in EAX!
proc HashFNV1b, .pString
begin
push esi
mov esi, [.pString]
mov eax, $811C9DC5
.hashloop:
cmp byte [esi], 0
je .exit
xor al, byte [esi]
inc esi
imul eax, $01000193
jmp .hashloop
.exit:
; folding to 16 bit.
mov esi, eax
shr esi, 16
xor eax, esi
movzx eax, ax
pop esi
return
endp
; Returns:
;
; CF=0 - the string has been added to the list.
; CF=1 - the string is already in the list or the list is full.
proc AddUniqueToList, .pString
begin
pushad
stdcall HashFNV1b, [.pString]
mov edx, eax ; in order
.put_loop:
mov esi, [.pString]
mov edi, [hash_table+4*eax]
test edi, edi
jnz .compare
; Empty slot has been found
mov [hash_table+4*eax], esi
clc
popad
return
; Collision?
.compare:
cmpsb
jne .yes_collision
cmp byte [esi-1], 0
jne .compare
; the string is already in the list.
stc
popad
return
.yes_collision: ; closed hashing
inc ax
cmp eax, edx
jne .put_loop
; the table is full.
stc
popad
return
endp
Побайтовое сравнение строк тоже есть, а вы говорили, что есть только простые циклы. Есть хитрый хак с переполнением, это понятности не добавляет. Для оптимизации есть более эффективные методы (которые на ЯВУ проще применять). Ну и в целом кода гораздо больше, и я бы не сказал, что он проще для понимания, совершенно обычный код.
Кроме того johnfound подменил изначальную задачу "поиск строки в массиве строк" на "добавление строки в уникальное множество строк". Т.е. сразу взял случай, когда проверка наличия строки в множестве будет выполняться часто. Однако, для таких случаев практически в любом ЯВУ есть класс/структура типа HashSet, которая работает с произвольными объектами, проверяя уникальность добавляемого объекта неожиданно при помощи метода GetHashCode.
Кроме того johnfound подменил изначальную задачу "поиск строки в массиве строк" на "добавление строки в уникальное множество строк"
Это не подмена, потому что это одна и та же задача. Код будет тот же самый только будет на инструкции меньше:
; mov [hash_table+4*eax], esi
Кроме того, почему я дал тот пример? — потому что хотел показать, что на ассемблере и на ЯВУ программисты думают по разному. Потому что то что пишется просто на ЯВУ, на ассемблере пишется сложно, а то что на ЯВУ написать сложно, наоборот, на ассемблере пишется просто.
Поэтому я считаю, что учится программировать на ассемблере, читая выход компилятора на ЯВУ нельзя.
Это не подмена, потому что это одна и та же задача. Код будет тот же самый только будет на инструкции меньше
Да, только это медленнее побайтового сравнения будет, если нужно всего один раз за время выполнения программы эту проверку вызывать.
А если надо много проверок, то, как я выше написал, это и на ЯВУ будет HashSet, который под капотом сделает то же самое, что Ваш код, только с большим количеством проверок.
потому что хотел показать, что на ассемблере и на ЯВУ программисты думают по разному
Скорее они думают на разных уровнях абстракции, и это вполне очевидно.
Поэтому я считаю, что учится программировать на ассемблере, читая выход компилятора на ЯВУ нельзя.
С этим я согласен, т.к. у компилятора нет задачи сделать код читабельным.
Использование веб программы на ассемблере может сэкономить на хостинге и позволит использовать дешевый виртуальный хостинг там, где другие используют выделенные серверы и другие дорогие решения.
Через сколько времени экономия на хостинге окупит увеличенную оплату работы программистов?
Через сколько времени экономия на хостинге окупит увеличенную оплату работы программистов?
Это конечно смотря какой сайт и какие программисты. Можно и сразу.
Например, если вам нужен форум чтобы несколько тысяч человек общались:
- Качаете AsmBB.
- Устанавливаете за 5 минут.
- ???????
- Профит!
Где ж тут профит?.. AsmBB пока на уровне прототипа и нет никаких гарантий, что Вам не надоест его разрабатывать и он дотянет до production-ready состояния в ближайшие пару лет.
Несколько тысяч пользователей для форума — это мелочи, можно взять любой движок с активным комьюнити, поддержкой и расширениями.
На самом деле профит от любого быстрого развертывания. Только вот AsmBB потребует VDS, потому профит может оказаться меньшим на начальном этапе
Или не потребует в базовой функциональности?
Только вот AsmBB потребует VDS,
Никакого VDS не надо. У меня работает на shared hosting.
У меня работает на shared hosting.
Далеко не на любом хостинге вам дадут запускать исполняемые файлы. Во многих хостингах все ограничивается php, MySQL и ещё чем-нибудь вроде питона. А там где дадут, скорее всего не будет такого жесткого ограничения по ресурсам.
А вы это пробовали?
Я не встречал такой хостинг, который не позволял бы бинарные файлы. Если PHP или Perl работают, то и бинарные CGI и FastCGI скрипты должны работать.
Я конечно не специалист в Apache, но по моему там просто нет возможность ограничит исполнения таких файлов.
Если PHP или Perl работают, то и бинарные CGI и FastCGI скрипты должны работать.
Я конечно не специалист в Apache, но по моему там просто нет возможность ограничит исполнения таких файлов.
Ну кто вам помещает просто не пустить пользователя в папку куда он сможет положить бинарные CGI и FastCGI? Будет у него папка куда он сможет залить php скрипты (да ещё и с кучей ограничений, вроде safe мода) и все. Ни модули php переставить, ни бинарники запустить, ни .httaccess свой использовать. Естественно, ни ssh, ни прав на смену прав у пользователя не будет, чисто ftp и веб.консоль.
Я не встречал такой хостинг, который не позволял бы бинарные файлы.
Я встречал хостинги, которые вообще ничего кроме html не позволяли. Ничего народ пользовался… правда это было давно. А так как только хостеры не извращались в своих тарифах.
Просто попробуйте.
Я встречал хостинги, которые вообще ничего кроме html не позволяли.
Это да, возможно. Но раз позволены некоторые исполняемые файлы — например PHP, то позволены все выполняемые файлы. Некоторые из них можно запретить, просто не устанавливая интерпретатор — например Perl. Но бинарные файлы не нуждаются в интерпретатором. Они работают всегда.
Но бинарные файлы не нуждаются в интерпретатором. Они работают всегда.
Эээ, а как же chmod +x имя_файла? Как нечто залитое по ftp вдруг в Linux станет исполняемым без прав доступа? И как вы его запустите из веба, если там позволены только расширения php и html? Настроить FastCGI свои права доступа для каждого пользователя можно.
Права вполне можно менять и через FTP. Я собственно так и делаю. А если PHP доступны, то их права тоже надо менять на +x
PHP работает через FastCGI. Если PHP работает, то в модуль Апачи fcgi работает. Остается только написать в .htaccess:
FcgidWrapper "/YOUR_PATH/engine" virtual
SetHandler fcgid-scriptИ все будет работать.
PHP может и через mod_php быть настроен. Раньше на большинстве shared-хотингов был именно он.
Ну, вообще то, может быть. Как я сказал, я не специалист в Апачи.
Просто я никогда не видел такой хостинг, чтобы нельзя было запустить бинарные CGI или FastCGI скрипты, если хоть какие CGI скрипты разрешены, например Perl или PHP. Кстати, то же самое в силе и насчет bash CGI скрипты. Например fossil работает именно через bash скрипт.
Ну не совсем на уровне прототипа. Там все вполне хорошо работает. А мне даже и если надоест его разрабатывать, то хоть баги исправить не откажусь никогда. А если люди начнут использовать, то найдутся и такие, которые будут писать расширения и развивать проект дальше. Это и есть сущность свободного ПО.
Несколько тысяч пользователей для форума — это мелочи, можно взять любой движок с активным комьюнити, поддержкой и расширениями.
Я имел ввиду общаться одновременно в онлайне. Это совсем не мелочь. И да, можно взять любого движка, только на хостинг придется платить намного больше. Что я и имел ввиду.
Я имел ввиду общаться одновременно в онлайне. Это совсем не мелочь. И да, можно взять любого движка, только на хостинг придется платить намного больше. Что я и имел ввиду.
Хотите расскажу как добиться того скорости в десяток раз большей, а затрат ресурсов в десяток раз меньшей чем ваш прототип, причем на любом ЯП?
На любом языке пишем скрипт, который всю информацию форума будет хранить в виде сгенеренных html файлов или json файлов для ajax (или и того и другого вместе), при каждом добавлении новой информации, он будет просто блокировать нужный файл html/создавать новый, дописывать в страницу пост и возвращать результат. А в базу все изменения будут скидываться с определенной периодичностью (минута, час, день) и к базе он будет обращаться только при восстановлении системы или для поиска по форуму.
Скорость чтения будет равна скорости отдачи любого html'а (а это самый частый запрос), скорость записи будет ограничена записью в файл с блокировкой. Ресурсов будет тратиться мизер, база данных вообще не будет грузиться.
P.S. Насколько знаю подобные движки уже существуют (например, на PHP).
P.P.S. Кое-какие функции будут недоступны или придется исхитрится, чтобы их реализовать, но скорость будет… быстрой.
Эта техника была достаточно популярна ещё лет 5 назад… С современным фронтендом всё ещё проще для бекэнда. Теперь весь HTML принято кешировать в шаблонах любимого JS-фреймфорка, а от сервера только JSON спрашивать… Который в свою очередь легко кешируется в memcached, хотя в большинстве случаев даже его честная генерация занимает в разы меньше времени, чем пинг до сервера )
На любом языке пишем скрипт, который всю информацию форума будет хранить в виде сгенеренных html файлов или json файлов для ajax (или и того и другого вместе), при каждом добавлении новой информации, он будет просто блокировать нужный файл html/создавать новый, дописывать в страницу пост и возвращать результат. А в базу все изменения будут скидываться с определенной периодичностью (минута, час, день) и к базе он будет обращаться только при восстановлении системы или для поиска по форуму.
ixbt вспомнился, он примерно так и работал. Рендер в статику — и в путь.
Ну не совсем на уровне прототипа. Там все вполне хорошо работает.
Ну на уровне прототипа работает… А если прикинуть сколько человеколет понадобится, чтобы до уровня какого-нибудь Discourse допилить, то становится грустно.
Поймите, что ваш проект привлекателен только тем, что он на ассемблере. Если бы кто-то опубликовал анонс аналога (по функционалу) на PHP/Ruby/Python, то его закидали бы помидорами в стиле "что это за кусок г...?" Потому что все, когда начинали изучать веб-программирование, писали собственный форум, или CMS, или соц.сеть, или ещё что-то подобное, но и то более навороченное по фичам.
Я имел ввиду общаться одновременно в онлайне. Это совсем не мелочь.
Согласен, это уже не мелочь. Но, как я выше писал, для пользователей AsmBB работает медленно даже без нагрузки. Если к вам пару сотен одновременных посетителей нагнать, то у вас тупо веб-сервер ляжет, до asmbb даже запросы доходить не будут.
Это я ещё молчу, что придётся как в прошлом веке страницу каждый раз обновлять, чтобы о новых сообщениях узнать. Что для активных переписок выглядит жестоким анахронизмом.
но и то более навороченное по фичам.
А какие именно фичи вы имеете ввиду?
Если по форумам, которые раньше в качестве обучалок писали, то там хотя бы были дерево категорий (а не только теги), личные сообщения между пользователями, система рейтинга и т.д. По современным фичам — смотрите современные форумы.
для пользователей AsmBB работает медленно даже без нагрузки
Да, если эти пользователи из Канады. Но это не проблем AsmBB, а конкретного веб провайдера.
Скорее проблема в вашем хостинге… Сегодня он, кстати, получше работает. Мораль тут в том, что нагруженный проект на shared-хостинге всё равно не получится запустить просто по определению shared-хостинга… Все ресурсы разделяемы, в том числе и канал… Попробуйте тысячу ботов на ваш форум запустить, которые ежесекундно будут к нему обращаться (читать, писать, редактировать) и посмотрите через сколько дней вас попросят на VDS переехать или хотя бы на VPS без оверсейла. А заодно узнаете какая часть запросов не дойдёт до AsmBB и какое будет время ответа от сервера при средненькой базе (в районе 10 Gb)… Хотя это я загнул, база не успеет до средних размеров вырасти, т.к. дисковая квота закончится ещё на миниразмере БД )
Я имею ввиду случай, когда продукт разрабатывается самостоятельно, а не берётся готовый.
Для ассемблера это не важно, но SQLite мне тоже нужна 32 битная, а ей нужна стандартная библиотека C.
Дык все тормоза то останутся с СУБД.
Логично от неё отказаться.
Писать веб-сайты на ассемблере полезно и приятно