ElasticSeach достаточно гибкая платформа, и полученные в него данные можно обрабатывать многими способами, даже за пределами стека ELK. Для этого предоставлено более десятка различных API. Но для многих задач будет достаточно и возможностей Kibana.
Одной из таких я хотел бы поделиться с сообществом. Для меня, как и любого безопасника, важно видеть и понимать коммуникацию своей инфраструктуры с внешним миром. Одной из самых интересных является коммуникация с луковой сетью (Tor).

Конечно же ELK стеком все не ограничивается, это лишь инструмент для хранения и обработки информации. Эффективность продукта на его базе определяется данными, которые нужно где-то взять. В моем случае это сырые Netflow данные, принятые напрямую из сетевого устройства, без предварительной обработки более умным коллектором. У этого подхода есть свои плюсы и минусы, но не об этом.
Для примера, на выходе получаем примерно следующую информацию:
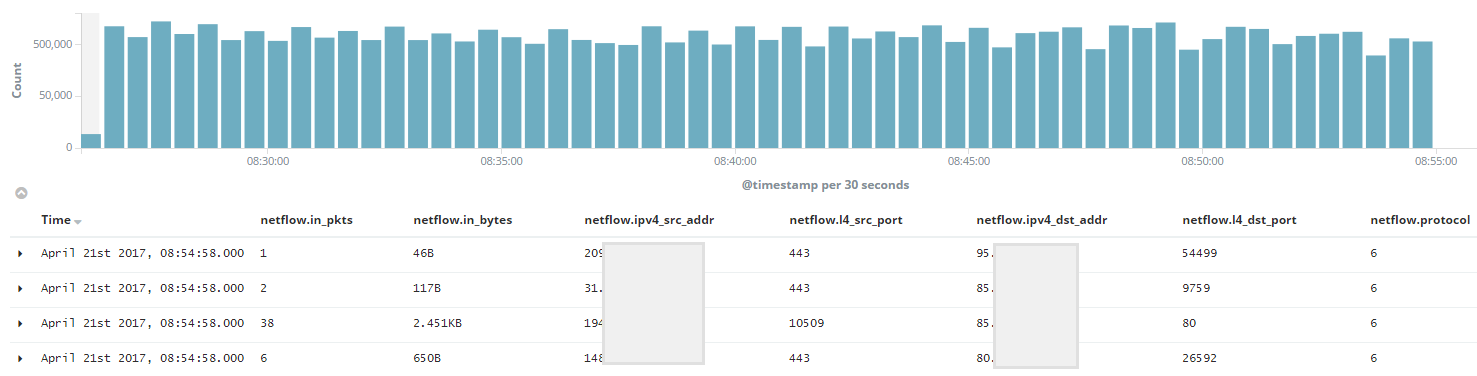
Хотелось бы отметить, что в данном примере отображены только самые интересные поля, бОльшая часть информации, полученной посредством Netflow, опущена. Один из главных плюсов, на мой взгляд, тот, что есть возможность оперировать данными о количестве трафика в потоке.
Уже на этом этапе хотелось бы оговориться, что в вопросе о коммуникации с Tor сетью есть один нюанс. К сожалению, у Вас и у меня есть возможность идентифицировать только трафик ИЗ сети Tor, но не В нее. Сообщество torprojects.org приводит только список Exit узлов, и мне повстречалось несколько топиков на тему того, что список Entry узлов не может быть однозначно идентифицирован.
В сети фигурируют списки, которые якобы описывают и входящие Tor ноды, но никакой достоверности у этой информации к сожалению нет. В свою очередь доверенный список Exit узлов доступен по этой ссылке: https://check.torproject.org/exit-addresses. В результате работаем только с трафиком ИЗ Tor.
Теперь о том, как использовать эту информацию внутри ELK. Что бы из всего потока данных отсеять именно трафик из Tor сети, можно создать фильтр, который будет построен по следующему сценарию:
По необходимости, после 'AND' добавляем уточнения фильтру. Для проверки работоспособности фильтра можно мануально создать конструкцию (Exit узлов с ' OR ' посередине) средствами bash и просто через clipboard проверить, верно ли функционирует поиск:
Список получается большым, по этому настройка ElasticSearch по умолчанию может ругнуться, что мы использует слишком много булеан операторов, по этому увеличиваем лимит в /etc/elastcisearch/elasticsearch.yml следующей настройкой и перезагружаем демон:
Сила ElasticSearch в том, что он быстро фильтрует запрашиваемую информацию, поэтому результат получаем довольно быстро. Сохраняем как Search в Kibana и пользуемся. По идее мы добились поставленной задачи — коммуникация из луковых сетей у вас перед глазами.
Скорее всего, в течение часа это считаные потоки, но каждый, из которых интересен:

Проблема в том, что список Exit узлов непостоянен, поэтому желательно обновлять его с какой-либо регулярностью. Мануальный метод не подходит. В теории можно подыскать корректную форму POST запроса на интерфейс Kibana, которая содержит в себе значение фильтра Search и его идентификатор. Таким образом, генерируя Веб запрос, обновлять список. Но есть вариант удобнее.
Kibana всю информацию о объектах хранит в этом же ElasticSearch кластере, в системном индексе '.kibana'. Там можно найти документ, который описывает ранее созданный Search запрос, содержащий список Exit узлов:
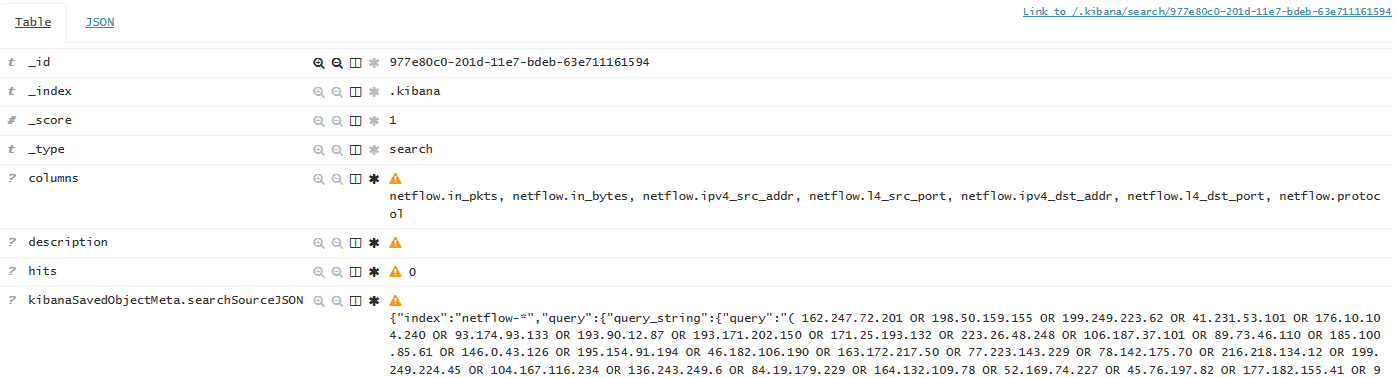
Значит, нужно всего лишь обновлять 'query' поле конкретно этого документа в соответствии с информацией check.torproject.org/exit-adresses. Для этого я накидал Python скрипт, актуальную версию которого можно найти тут. Для ознакомления, под спойлером предоставляю последнюю на данный момент версию:
Скрипт получает список Exit узлов и генерирует на его базе 'query' для Search объекта. Для обновления документа пришлось все же вызвать принадлежащий ОС 'curl', так как Python API при полностью идентичных запросах вызывал у ElasticSearch ошибку сериализации, которую так и не вышло решить. 'curl' в свою очередь использует файл query.json, путь к которому нужно указать в скрипте. Вообщем подправляем код в соответсвии с предписанием README, после чего закидываем скрипт в crontab сервера и получаем динамически обновляемый серч, который можно использовать дальше.
Первое что видно — это, конечно же, множественные сканы. Вас постоянно сканируют из Tor, ну в общем, как и отовсюду. Слушают и на четвертом уровне OSI, и веб-приложения, и все остальное. Поэтому я бы советовал анализировать сетевую информацию, которая собрана не перед файрволом, а после. Во-первых, отметается все, что не прошло внутрь, а во-вторых, будете видеть уже транслированные адреса внутренних узлов.
Второе — что является основным объемом данных, это совершенно валидные запросы к сервисам в вашей сети. Сегодня это нормально анонимизировать свое пользование сетью, по-этому коммуникация из Tor в первую очередь содержит коннекции на самые популярные ваши сервера. Возможно, конечно, у некоторых организаций (которые нужны пользователям больше, чем пользователи им) появиться желание рубить эту коммуникацию на корню. Такие случаи и вправду есть. Я же придерживаюсь мнения, что мы не праве ограничивать эту сферу развития интернет-сообщества, и надо научиться этот трафик понимать.
На обе предыдущие группы особое внимание обращать не надо, учимся распозновать их, и пропускать мимо. Однако, это не все. Корректный анализ может своевременно выявить интересные факты.
Проверяйте трафик на предмет C&C (command & control) уже подвластных злоумышленнику узлов в вашей сети, будь то машина в ботнете или целевая атака.
В принципе обе следующие коммуникации должны быть проанализирована на предмет C&C:
Оба сервиса до сих пор активно используются в дикой среде для туннелирования трафика, даже в случае нацеленных Advanced Persistent Threat атак. Одним из ярких примеров в последнее время будет, например, действие группировки Cobalt в случае с атакой на тайваньский First Bank (ссылка).
Так же советую обращать внимание нестандартные Веб запросы. Тут профильтровать будет посложнее, но я бы посоветовал все же пару зацепок.
Львиная доля все того же C&C в наши дни идет через Веб, так как в том или ином виде этот трафик разрешен в любой организации. По этому интересен в принципе любой TCP 80 и 443, который связан с НЕвеб сервером из вашей сети.
Дополнительно обращайте внимание на запросы, адресованные менее популярным Web серверам. И уж особенно, если есть те, которые построены на базе фреймворков с открытым кодом, особенно, если объем трафика превышает стандартный. Для еще большей прозрачности, можно подводить в тот же ElasticSearch на отдельный индекс логи таких серверов или WAF'а, и в параллельном окне визуализации смотреть, какие HTTP поля и значения содержат непосредственно сами запросы.
Что бы не быть голословным, попробую показать, каким образом можно оптимизировать подобный анализ данных в ELK стеке. Остановлюсь, например, на попытке быстро идентифицировать попытки ICMP или DNS туннелирования на основе собранных данных.
Любая информация воспринимается лучше в графическом виде, по этому попробуем создать визуализацию ICMP коммуникации превышающую норму по количеству трафика. Норму определяем по наблюдению активного трафика в сети, что бы обычные ICMP операции не всплывали, но вполне могли попасться попытки залить скрипт или передать вывод команды в ICMP пакетах. Я остановился на значениях больше 2KB на поток. Для получения этого трафика из предыдущего сёрча создаем новый, в конце добавляя следующий паттерн:
Далее выбираем Visualize > Pie Chart. Как источник данных выбирается только что дополненный Search.

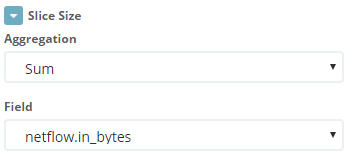
Как параметр для определения угла сектора указываем сумму параметра 'netflow.in_bytes'.
Указываем, что разделять пирог на секторы следует по IP адресу назначения.
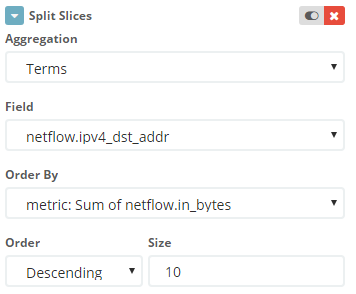
Так как в случае с Tor сетью адрес источника ничего не говорит (одна и та же коммуникация может вестись с несколькими адресами), коннекция идентифицируется по адресу в вашей сети. Но я для удобства идентификации потока создал и второй уровень пирога, где указывается адрес узла в сети Tor.
Хочу отметить один нюанс — под упомянутые параметры Search будет попадать и обычный ping, который велся продолжительное время и собрал количество пакетов в одну сторону 25+.
Можно провести еще одну оптимизацию — мануально в Kibana создать поле, которое будет отображать количество байт на пакет в одном определенном Netflow потоке. Для этого в разделе Scripted Fields создаем единицу, которая на языке painless выполняет следующую задачу:
Добавив это поле в Search, при просмотре информации можно сразу отсеять пакеты стандартного размера. К сожалению отфильтровать потоки по этому полю нельзя, Kibana об этом сообщает при создании поля:
Однако, в Dashboard можно сбоку от визуализации разместить непосредственно информацию из Search и сопоставлять данные.
Результат получается таким:
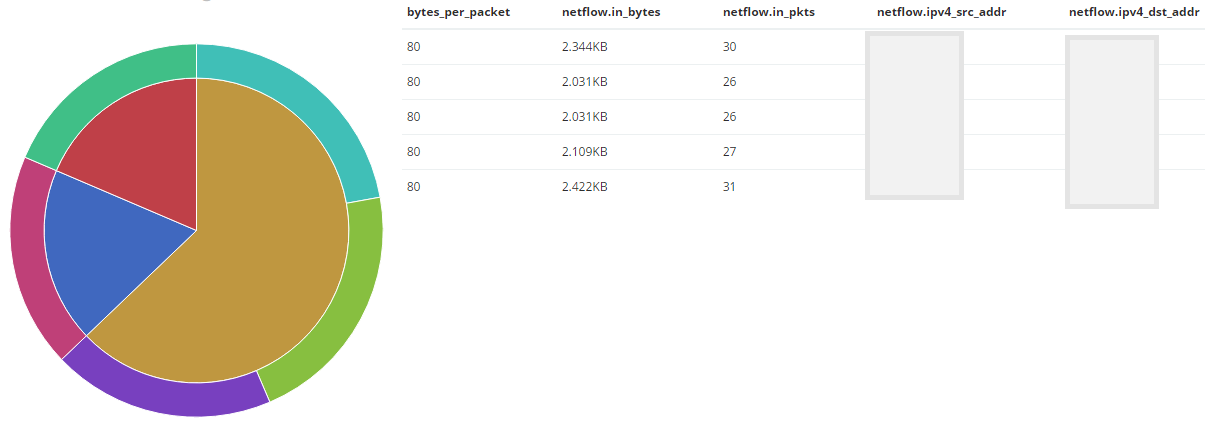
Чем шире сектор, тем больше данных получил IP адрес. Так же, в этом примере сразу видно, что все ICMP потоки имеют стандартный размер пакетов.
Аналогичный анализ подходит и для DNS коммуникации, где я остановился на потоках больше 1KB. Подправляем Search, дополненный следующим запросом и проводим те же манипуляции:
Скорее всего в предложенные мной примеры могут попадать специфичные узлы в вашей сети — мониторинг или DNS сервера, их конечно же фильтруем прочь. В итоге имеем наглядную картину, которая отображает девиации актуальных сервисов. Вообще, такой анализ этих сервисов нужно проводить не только трафику, который идет из Tor, по этому этот подход можно применить вообще всей информации, полученной ElasticSearch.
Конечно же, список возможного анализа этой информации не претендует на полноту. Это просто поверхностный пример, который желательно дальше развить. Пожалуйста, если читатель может описать методы анализа такой информации — поделитесь, мне и сообществу будет интересно.
Так же, скорее всего, любой из этих советов может быть разбит (в плане полезности) аргументами, которая мне не приходит на ум. В таком случае я очень хотел бы услышать эти доводы.
Конечно, всего этого вы не увидете, если потенциальный желающий анонимизировать своё поведение злоумышленник использует свзяку VPN — Tor — VPN или более мудреные махинации. Поэтому похожими методами лучше анализировать вообще весь трафик вашей инфраструктуры. Но и просмотр этой информации уже является очень интересным.
Спасибо за чтение! Надеюсь, было интересно/полезно.
P.S. Ответственно доработаю статью в соответствии с поправками читателя. Просьба заметки о качестве текста давать в личной почте, комментарии же оставить для обсуждения непосредственно темы статьи.
Одной из таких я хотел бы поделиться с сообществом. Для меня, как и любого безопасника, важно видеть и понимать коммуникацию своей инфраструктуры с внешним миром. Одной из самых интересных является коммуникация с луковой сетью (Tor).
Конечно же ELK стеком все не ограничивается, это лишь инструмент для хранения и обработки информации. Эффективность продукта на его базе определяется данными, которые нужно где-то взять. В моем случае это сырые Netflow данные, принятые напрямую из сетевого устройства, без предварительной обработки более умным коллектором. У этого подхода есть свои плюсы и минусы, но не об этом.
Для примера, на выходе получаем примерно следующую информацию:
Хотелось бы отметить, что в данном примере отображены только самые интересные поля, бОльшая часть информации, полученной посредством Netflow, опущена. Один из главных плюсов, на мой взгляд, тот, что есть возможность оперировать данными о количестве трафика в потоке.
Создаем фильтр
Уже на этом этапе хотелось бы оговориться, что в вопросе о коммуникации с Tor сетью есть один нюанс. К сожалению, у Вас и у меня есть возможность идентифицировать только трафик ИЗ сети Tor, но не В нее. Сообщество torprojects.org приводит только список Exit узлов, и мне повстречалось несколько топиков на тему того, что список Entry узлов не может быть однозначно идентифицирован.
В сети фигурируют списки, которые якобы описывают и входящие Tor ноды, но никакой достоверности у этой информации к сожалению нет. В свою очередь доверенный список Exit узлов доступен по этой ссылке: https://check.torproject.org/exit-addresses. В результате работаем только с трафиком ИЗ Tor.
Теперь о том, как использовать эту информацию внутри ELK. Что бы из всего потока данных отсеять именно трафик из Tor сети, можно создать фильтр, который будет построен по следующему сценарию:
( '1st.Exit.Node.IP' OR '2nd.Exit.Node.IP' OR .... 'Last.Exit.Node.IP' ) AND my_regexПо необходимости, после 'AND' добавляем уточнения фильтру. Для проверки работоспособности фильтра можно мануально создать конструкцию (Exit узлов с ' OR ' посередине) средствами bash и просто через clipboard проверить, верно ли функционирует поиск:
curl -XGET https://check.torproject.org/exit-addresses | egrep -o '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | sed -e ':a' -e 'N' -e '$!ba' -e 's/\n/ OR /g'Список получается большым, по этому настройка ElasticSearch по умолчанию может ругнуться, что мы использует слишком много булеан операторов, по этому увеличиваем лимит в /etc/elastcisearch/elasticsearch.yml следующей настройкой и перезагружаем демон:
indices.query.bool.max_clause_count: 2048Сила ElasticSearch в том, что он быстро фильтрует запрашиваемую информацию, поэтому результат получаем довольно быстро. Сохраняем как Search в Kibana и пользуемся. По идее мы добились поставленной задачи — коммуникация из луковых сетей у вас перед глазами.
Скорее всего, в течение часа это считаные потоки, но каждый, из которых интересен:
Обновляем фильтр
Проблема в том, что список Exit узлов непостоянен, поэтому желательно обновлять его с какой-либо регулярностью. Мануальный метод не подходит. В теории можно подыскать корректную форму POST запроса на интерфейс Kibana, которая содержит в себе значение фильтра Search и его идентификатор. Таким образом, генерируя Веб запрос, обновлять список. Но есть вариант удобнее.
Kibana всю информацию о объектах хранит в этом же ElasticSearch кластере, в системном индексе '.kibana'. Там можно найти документ, который описывает ранее созданный Search запрос, содержащий список Exit узлов:
Значит, нужно всего лишь обновлять 'query' поле конкретно этого документа в соответствии с информацией check.torproject.org/exit-adresses. Для этого я накидал Python скрипт, актуальную версию которого можно найти тут. Для ознакомления, под спойлером предоставляю последнюю на данный момент версию:
скрипт
#!/usr/bin/env python
# ----- README STARTS --------
#
# If anyone wants to use this script in their environment
# be sure to replace YOUR_SEARCH_ID with actual search ID
# within the curl command URL at line 70.
#
# Also 'post_body' variable at line 63 should be tuned according
# to your query, as it is build assuming there's some specific static
# expressions from the beginning and the of query.json file.
# See: https://github.com/dtrizna/my_ELK_scripts/blob/master/TOR_SEARCH/query.json
#
# Additionaly set correct path to query.json file
# at lines 65 and 70, replacing <PATH/TO/> entries.
#
# ----- README ENDS ----------
import re
import requests
import subprocess
# -------------------------
# GET THE LIST WITH TOR EXIT NODES FROM TORPROJECT WEB PAGE
nodes_raw = requests.get('https://check.torproject.org/exit-addresses')
nodes_raw_list = nodes_raw.text.split()
# -------------------------
# FILTER FROM WHOLE PAGE ONLY IP ADRESSES
regex = re.compile(r'\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}')
nodes = filter(regex.search, nodes_raw_list)
# -------------------------
# IP ADRESSES ARE IN UNICODE FORMAT, ENCODE THEM TO STRING
search_query = ''
i = 0
while i < len(nodes):
try:
nodes[i] = nodes[i].encode('ascii')
except UnicodeEncodeError as err:
print "Error due to IP adress encoding from Unicode to ASCII."
print "UnicodeEncodeError says: {}".format(err)
i = i + 1
# -------------------------
# CREATE KIBANA SEARCH QUERY
search_query = " OR ".join(nodes)
# -------------------------
# UPDATE FILE, THAT WILL BE USED AS BODY IN UPDATE COMMAND
# (CAN'T USE DIRECTLY, ES RETURNS ERROR, WORKS ONLY THROUGH FILE USING CURL)
with open('query.json', 'r') as file:
data = file.readlines()
# 'data' is list, every element describes line in file called in above cycle
# As there's only one line(it must be onelined, for ES to accept it),
# data[0] represents all the future POST body request.
# It has fixed values from the beginning and the end of line.
# Although middle part may vary depending on request to tor website above.
post_body = data[0][:127] + search_query + data[0][-258:]
with open('<PATH/TO/>query.json', 'w') as file:
file.writelines(post_body)
# -------------------------
# FINALY MAKE THE UPDATE REQUEST TO ELASTICSEARCH AND SEE REPLY
call = subprocess.Popen("curl -XPOST http://localhost:9200/.kibana/search/YOUR_SEARCH_ID/_update?pretty=true -d@<PATH/TO/>query.json",
shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
(result, error) = call.communicate()
print('Result is:\n {}\n'.format(result))
print("Error is: (if there's connection statistics - it's OK!)\n {}".format(error))
Скрипт получает список Exit узлов и генерирует на его базе 'query' для Search объекта. Для обновления документа пришлось все же вызвать принадлежащий ОС 'curl', так как Python API при полностью идентичных запросах вызывал у ElasticSearch ошибку сериализации, которую так и не вышло решить. 'curl' в свою очередь использует файл query.json, путь к которому нужно указать в скрипте. Вообщем подправляем код в соответсвии с предписанием README, после чего закидываем скрипт в crontab сервера и получаем динамически обновляемый серч, который можно использовать дальше.
Анализируем непосредственно сам трафик
Первое что видно — это, конечно же, множественные сканы. Вас постоянно сканируют из Tor, ну в общем, как и отовсюду. Слушают и на четвертом уровне OSI, и веб-приложения, и все остальное. Поэтому я бы советовал анализировать сетевую информацию, которая собрана не перед файрволом, а после. Во-первых, отметается все, что не прошло внутрь, а во-вторых, будете видеть уже транслированные адреса внутренних узлов.
Второе — что является основным объемом данных, это совершенно валидные запросы к сервисам в вашей сети. Сегодня это нормально анонимизировать свое пользование сетью, по-этому коммуникация из Tor в первую очередь содержит коннекции на самые популярные ваши сервера. Возможно, конечно, у некоторых организаций (которые нужны пользователям больше, чем пользователи им) появиться желание рубить эту коммуникацию на корню. Такие случаи и вправду есть. Я же придерживаюсь мнения, что мы не праве ограничивать эту сферу развития интернет-сообщества, и надо научиться этот трафик понимать.
На обе предыдущие группы особое внимание обращать не надо, учимся распозновать их, и пропускать мимо. Однако, это не все. Корректный анализ может своевременно выявить интересные факты.
Проверяйте трафик на предмет C&C (command & control) уже подвластных злоумышленнику узлов в вашей сети, будь то машина в ботнете или целевая атака.
В принципе обе следующие коммуникации должны быть проанализирована на предмет C&C:
- ICMP пакеты размером больше ping'а по умолчанию;
- DNS коммуникация с тем же симптомом — нестандартно большие пакеты;
Оба сервиса до сих пор активно используются в дикой среде для туннелирования трафика, даже в случае нацеленных Advanced Persistent Threat атак. Одним из ярких примеров в последнее время будет, например, действие группировки Cobalt в случае с атакой на тайваньский First Bank (ссылка).
Так же советую обращать внимание нестандартные Веб запросы. Тут профильтровать будет посложнее, но я бы посоветовал все же пару зацепок.
Львиная доля все того же C&C в наши дни идет через Веб, так как в том или ином виде этот трафик разрешен в любой организации. По этому интересен в принципе любой TCP 80 и 443, который связан с НЕвеб сервером из вашей сети.
Дополнительно обращайте внимание на запросы, адресованные менее популярным Web серверам. И уж особенно, если есть те, которые построены на базе фреймворков с открытым кодом, особенно, если объем трафика превышает стандартный. Для еще большей прозрачности, можно подводить в тот же ElasticSearch на отдельный индекс логи таких серверов или WAF'а, и в параллельном окне визуализации смотреть, какие HTTP поля и значения содержат непосредственно сами запросы.
Анализ данных с помощью ELK
Что бы не быть голословным, попробую показать, каким образом можно оптимизировать подобный анализ данных в ELK стеке. Остановлюсь, например, на попытке быстро идентифицировать попытки ICMP или DNS туннелирования на основе собранных данных.
Любая информация воспринимается лучше в графическом виде, по этому попробуем создать визуализацию ICMP коммуникации превышающую норму по количеству трафика. Норму определяем по наблюдению активного трафика в сети, что бы обычные ICMP операции не всплывали, но вполне могли попасться попытки залить скрипт или передать вывод команды в ICMP пакетах. Я остановился на значениях больше 2KB на поток. Для получения этого трафика из предыдущего сёрча создаем новый, в конце добавляя следующий паттерн:
netflow.in_bytes: {2000 TO *} AND netflow.protocol: 1Далее выбираем Visualize > Pie Chart. Как источник данных выбирается только что дополненный Search.
Как параметр для определения угла сектора указываем сумму параметра 'netflow.in_bytes'.
Указываем, что разделять пирог на секторы следует по IP адресу назначения.
Так как в случае с Tor сетью адрес источника ничего не говорит (одна и та же коммуникация может вестись с несколькими адресами), коннекция идентифицируется по адресу в вашей сети. Но я для удобства идентификации потока создал и второй уровень пирога, где указывается адрес узла в сети Tor.
Хочу отметить один нюанс — под упомянутые параметры Search будет попадать и обычный ping, который велся продолжительное время и собрал количество пакетов в одну сторону 25+.
Можно провести еще одну оптимизацию — мануально в Kibana создать поле, которое будет отображать количество байт на пакет в одном определенном Netflow потоке. Для этого в разделе Scripted Fields создаем единицу, которая на языке painless выполняет следующую задачу:
doc['netflow.in_bytes'].value / doc['netflow.in_pkts'].valueДобавив это поле в Search, при просмотре информации можно сразу отсеять пакеты стандартного размера. К сожалению отфильтровать потоки по этому полю нельзя, Kibana об этом сообщает при создании поля:
These scripted fields are computed on the fly from your data. They can be used in visualizations and displayed in your documents, however they can not be searched. You can manage them here and add new ones as you see fit, but be careful, scripts can be tricky!
Однако, в Dashboard можно сбоку от визуализации разместить непосредственно информацию из Search и сопоставлять данные.
Результат получается таким:
Чем шире сектор, тем больше данных получил IP адрес. Так же, в этом примере сразу видно, что все ICMP потоки имеют стандартный размер пакетов.
Аналогичный анализ подходит и для DNS коммуникации, где я остановился на потоках больше 1KB. Подправляем Search, дополненный следующим запросом и проводим те же манипуляции:
netflow.in_bytes: {1000 TO *} AND netflow.protocol: 17 AND ( netflow.l4_dst_port: 53 OR netflow.l4_src_port: 53 )Скорее всего в предложенные мной примеры могут попадать специфичные узлы в вашей сети — мониторинг или DNS сервера, их конечно же фильтруем прочь. В итоге имеем наглядную картину, которая отображает девиации актуальных сервисов. Вообще, такой анализ этих сервисов нужно проводить не только трафику, который идет из Tor, по этому этот подход можно применить вообще всей информации, полученной ElasticSearch.
В заключение
Конечно же, список возможного анализа этой информации не претендует на полноту. Это просто поверхностный пример, который желательно дальше развить. Пожалуйста, если читатель может описать методы анализа такой информации — поделитесь, мне и сообществу будет интересно.
Так же, скорее всего, любой из этих советов может быть разбит (в плане полезности) аргументами, которая мне не приходит на ум. В таком случае я очень хотел бы услышать эти доводы.
Конечно, всего этого вы не увидете, если потенциальный желающий анонимизировать своё поведение злоумышленник использует свзяку VPN — Tor — VPN или более мудреные махинации. Поэтому похожими методами лучше анализировать вообще весь трафик вашей инфраструктуры. Но и просмотр этой информации уже является очень интересным.
Спасибо за чтение! Надеюсь, было интересно/полезно.
P.S. Ответственно доработаю статью в соответствии с поправками читателя. Просьба заметки о качестве текста давать в личной почте, комментарии же оставить для обсуждения непосредственно темы статьи.







