Или как правильно закоптиться в нейросети

Курочка снесла яичко. Сам процесс выглядит ужасно. Результат — съедобно. Массовый геноцид кур.
В этой статье будет описано:
- Где, как и почему можно получить небольшое качественное самообразование в сфере работы с нейросетями БЕСПЛАТНО, СЕЙЧАС и СОВСЕМ НЕ БЫСТРО;
- Будет описана логика рекурсии и будут порекомендованы книги по теме;
- Будет описан список основных терминов, которые нужно разобрать на 2-3 уровня абстракции вниз;
- Будет приведен ipynb-notebook, который содержит необходимые ссылки и базовые подходы;
- Будет немного своеобразного саркастичного юмора;
- Будут описаны некоторые простые закономерности, с которыми вы столкнетесь при работе с нейросетями;
Статьи про нейрокурятник
Заголовок спойлера
- Вступление про обучение себя нейросетям
- Железо, софт и конфиг для наблюдения за курами
- Бот, который постит события из жизни кур — без нейросети
- Разметка датасетов
- Работающая модель для распознавания кур в курятнике
- Итог — работающий бот, распознающий кур в курятнике
Философское вступление начинается тут
С чего начать?
Заголовок спойлера
Можно начать с того, что моя девушка написала прекрасную статью про свое путешествие и установку системы наблюдения за курами в курятник. Зачем? Потому что прикладная задача мотивирует гораздо больше, чем задачи на Kaggle, где все тоже далеко не идеально (лики в 1/2 задач, побеждающие архитектуры — это стеки из 15 моделей, оверфиттинг для поиска немасштабируемых закономерностей итд итп). Моя задача — написать нейросети и код на питоне, который будет отличать кур, и, возможно, логировать события в жизни кур в нашу любимую СУБД. В процессе можно научиться много чему интересному и, возможно, даже изменить свою жизнь, поделившись своими мини-наработками. И приятно, и полезно и весело.
Можно также начать с того, что в принципе сейчас наблюдается новая ветка «пузыря» на рынке технологий — все резко побежали «в AI». Раньше все бежали в IT, в онлайн, в «бигдату», в «сколково», в AR/VR. Если посидеть в тематических российских чатах, то там люди как правило или пишут все с нуля на {вставить свой экзотический язык} или делают одноразовых чат-ботов, осваивая средства пиарящихся корпораций. Но ведь если следовать таким принципам в своем само-образовании, то учиться надо у ярых фанатов своего дела, которые делают то, что они делают, не ради наживы, а ради прекрасного.
И тут мне на помощь пришел неизвестный человек, который вставил строчку в мой файл, куда я собирал образовательные полезности в сфере работы с данными. Что удивительно, эти люди (fast.ai — ссылка, которую кто-то вставил) проделали просто гигантскую работу по популяризации и обучению даже с нуля, следуя принципу инклюзивности и целостности образования против эксклюзивности и принципа «башни из слоновой кости». Но обо все по порядку.

Подход к образованию in a nutshell.
Сами авторы расскажут лучше меня.
Я видел один раз в как в чате ods (если знаете что это, поймете) сформировалась команда, которая заняла второе место на соревновании по распознаванию снимков спутника, но общее количество человеко-часов нужно для такого выступления не мотивирует участвовать в таких конкурсах с учетом неидеальности мира. Также в принципе отношение вознаграждения исследователей к общей цене конкурса не внушает энтузиазма.
Поэтому все нижеописанное сделано для нейрокурятника и только для него.
На всякий случай уточню, что в мои задачи НЕ входит:
Я хочу поделиться прекрасными вещами и приобщить к ним максимальное число людей, дав максимально простое и широкое описание пути, который сработал для меня.
Можно также начать с того, что в принципе сейчас наблюдается новая ветка «пузыря» на рынке технологий — все резко побежали «в AI». Раньше все бежали в IT, в онлайн, в «бигдату», в «сколково», в AR/VR. Если посидеть в тематических российских чатах, то там люди как правило или пишут все с нуля на {вставить свой экзотический язык} или делают одноразовых чат-ботов, осваивая средства пиарящихся корпораций. Но ведь если следовать таким принципам в своем само-образовании, то учиться надо у ярых фанатов своего дела, которые делают то, что они делают, не ради наживы, а ради прекрасного.
И тут мне на помощь пришел неизвестный человек, который вставил строчку в мой файл, куда я собирал образовательные полезности в сфере работы с данными. Что удивительно, эти люди (fast.ai — ссылка, которую кто-то вставил) проделали просто гигантскую работу по популяризации и обучению даже с нуля, следуя принципу инклюзивности и целостности образования против эксклюзивности и принципа «башни из слоновой кости». Но обо все по порядку.

Подход к образованию in a nutshell.
Сами авторы расскажут лучше меня.
Я видел один раз в как в чате ods (если знаете что это, поймете) сформировалась команда, которая заняла второе место на соревновании по распознаванию снимков спутника, но общее количество человеко-часов нужно для такого выступления не мотивирует участвовать в таких конкурсах с учетом неидеальности мира. Также в принципе отношение вознаграждения исследователей к общей цене конкурса не внушает энтузиазма.
Поэтому все нижеописанное сделано для нейрокурятника и только для него.
На всякий случай уточню, что в мои задачи НЕ входит:
Очень толстый слой сарказма
- Написать курс, чтобы потом продать лиды его молодых выпускников в Mail.ru xD;
- Писать про то, как мне нравится Caffe против Theano или Tensorflow — это все не имеет разницы до промышленного профессионального уровня, если вы не исследователь в этой сфере со стажем и не пишете научные статьи;
- Писать нейросети с нуля на {ваш экзотический язык};
- Продавать вам что-то за деньги (только идеи и бесплатно);
Я хочу поделиться прекрасными вещами и приобщить к ним максимальное число людей, дав максимально простое и широкое описание пути, который сработал для меня.
Философское вступление заканчивается тут
Описание того, как научиться тренировать нейросети
TLDR (в порядке установки / изучения от простого к сложному)
Если вы хотите эффективно и современно тренировать нейросети для прикладной цели (а не переписать все на {X} или собрать ПК с 10 видеокартами), то вот краткий и очень рекурсивный гайд:
Список тут
- 1. Изучите хотя бы основные понятия:
- Линейной алгебры. Цикл вводных видео. Начните хотя бы с них;
- Математического анализа. Цикл вводных видео;
- Почитайте про градиентный спуск. Вот обзор методов и вот визуализация. Остальное найдете сами в курсах;
- 2. Если вы вообще не знаете ни про что из списка, будьте готовы вложить 200-300 часов своего времени. Если только нейросети и / или питон — то 50-100 часов;
- 3. Заимейте себе Ubuntu или ее аналог (да здравствуют комменты в стиле «не труЪ»). Мой краткий обзорный гайд (интернет поможет найти более подробные технические гайды). Конечно, также можно извратиться через виртуалки, докеры, мак итд итп;
- 4. Поставьте себе третий питон (как правило уже стоит из коробки, 2017 год). Именно третий. Но лучше лишний раз сказать. Не пытайтесь менять системный питон в Линуксе — все сломается;
- 5.Если вы не очень знакомы с питоном, то (все, опять же гуглится):
- Самый простой и бесплатный источник уровня «база» и бесплатный (никаких курсов за 30-50к рублей, чтобы потом пойти работать инструктором на эти же курсы за 30к рублей, когда заявлена средняя зп якобы в 100к рублей);
- Идеальная входная точка рекурсии по использованию питона для работы с данными;
- 6. Поставьте себе jupyter notebook и это расширение (вам нужно code folding). Очень сокращает время работы. Правда;
- 7. Купите себе видеокарту (сейчас выгоднее купить, чем арендовать — начало 2017):
- 8. Лучшие образовательные (БЕСПЛАТНЫЕ) ресурсы:
- www.fast.ai — входная точка рекурсии. Там безумного много информации в блоге, в видео, на форуме, в вики и notes;
- Великолепная книга про нейросети и первый код из нее на третьем питоне (гуглите, может кто-то задебажил весь код, я заленился после первых двух глав);
- Великолепный курс Andrew Ng и его интерпретация на питоне;
- 9. Jupyter notebook (html ipynb), который:
- Содержит иерархическую структуру ячеек, в каждой из которых описано что делается и зачем;
- Основные инклюды, утилиты и библиотеки разбиты по типам;
- Приведены ссылки на основные источники, нужные, чтобы понять, что происходит;
- Приведен сахар для работы с Keras (подробнее без продаванства тут, сами люди из fast.ai рекомендуют именно ее);
- Для датасета машин проезжающих за окном получена точность предсказания класса в ~80% (рандом дает 50%, но картинки говенные и мелкие);
- Для датасета с соревнования distracted driving полученная точность предсказания 10 классов в ~50% и ошибкой, которая точно входит в топ 15-20% решений в мире;
To-do list для достижения лучших результатов (на distracted driving, к примеру, можно получить ~60-75% точности):
Список улучшений на будущее
- Использование визуализаций для понимания того, чему учится сеть;
- Использование тренировочного сета в 300-500 картинок, чтобы быстро понять какие параметры искажения картинок лучше всего подходят;
- Использование test датасета (или cross-validation) для увеличения точности. Нужно добавлять не более 25-30% таких картинок (semi-supervised learning);
- Использование тонкой настройки imagenet как как дополнительной опции для модели;

Если вы дочитали до сюда — то вот вам курочка, с которой сняли подозрения, что она не несется. В суп она пойдет гораздо позже за счет этого.
Опишу теперь то, что показалось занятным из процесса непосредственно обучения нейросетей (не тех, которые в голове, а тех, которые в питоне):
Список тут
- Датасет с машинами показал, что если картинки маленькие и выборка из классов смещенная (один класс больше чем другой), то модель будет хорошо определять только один класс;
- Начинайте с маленького сета, чтобы модель тренировалась за несколько десятков секунд и настройте мета-параметры изменения изображений;
- Если у вас есть некой приложение из распознавания движения + нейросети, то лучше сразу обрезайте картинки в open-cv, не оставляйте на потом;
- У нейросетей есть так называемый эффект «easy way out», когда кост-функция может относительно долго находиться в локальном минимуме, потому что предсказать 50% вероятность попадания постоянно в 1 класс проще, чем учиться;
- Пробуйте сначала простые архитектуры, усложняйте постепенно. Если тренируется медленно — возьмите маленькую выборку или проверьте свою модель;
- Простая архитектура + пробуйте разные мета-параметры (learning rate);
- Если кост-функция не уменьшается совсем, то где-то в модели если досадная опечатка. Проще все ее найти можно сравнив свою модель с моделью другого человека;
- Сейчас на уровне программного сахара (keras) есть уже огромное количество state-of-the-art фич, таких как:
- Нормализация изображений;
- Искажение изображений;
- Dropout;
- Convolutions;
- Итераторы для последовательного чтения файлов;
- Из интересного (не из области стакания 15 моделей) в соревнованиях Kaggle я бы отметил использование комбинаций таких вещей как:
- Предобработка изображений, поиск контуров и фигур с помощью open-cv;
- Сверточные нейросети для основной классификации;
- Нейросети для создания мета-данных про картинки — например тут сначала они ищут у китов головы, и только потом определяют кита;
- Собрал тут интересное про последние архитектуры на Kaggle
А вот набор картиночек
Заголовок спойлера
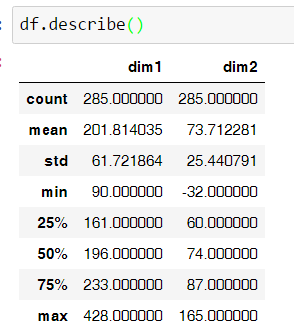
Первые 285 автомобилей имеют скромные размеры в пикселях + там все смазано...

Когда хочется побыстрее обрезать картинки, а думать не хочется рождаются вот такие уродливые решения
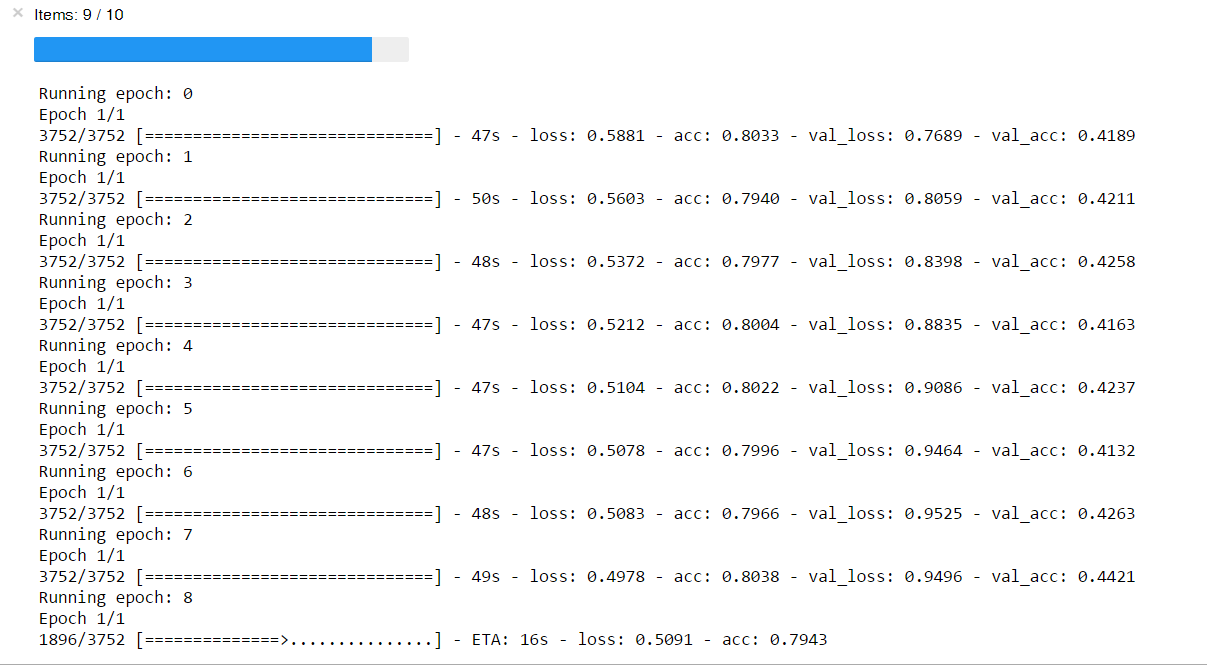
Разница в точности на тренировке и валидации намекает, что датасет перекошен, маленький и вообще. Зато красивый прогресс-индикатор.

Не куры, но виновники торжества. Очень смазанные — в движении
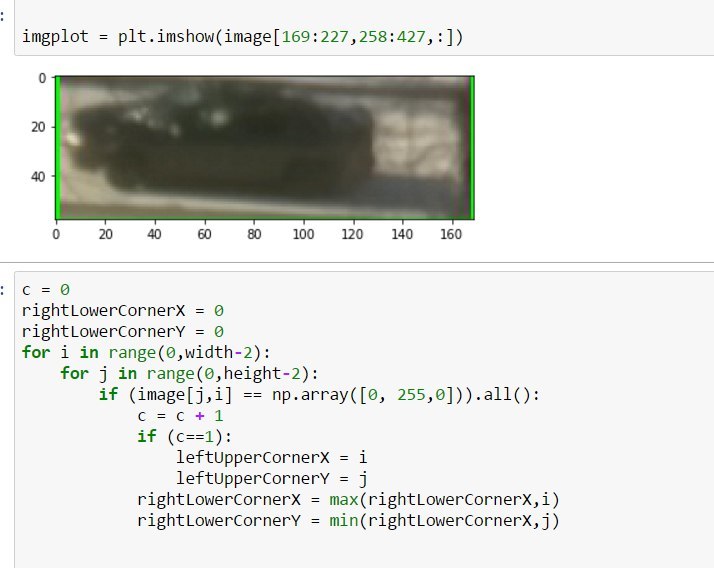
Радости нет границ, когда быдлокод, написание которого растянулось на час, начал работать и обрезать машину.

На практике места в памяти видео-карты хватает или с запасом, или его сразу не хватает. Тяжело подобрать размер картинки и размер batch'а, чтобы и рыбку съесть и…
Правило пальца — сверточные слои требуют много памяти, а dense слои — много времени.

Сравните полезную площадь на этой картинке...

И сколько тут полезных пикселей =) Да у курицы голова больше машины (в пикселях) — моя видеокарта будет страдать

Не расчитал — память кончилась и все упало. А функции очистки, кроме как перезапуска я не нашел пока
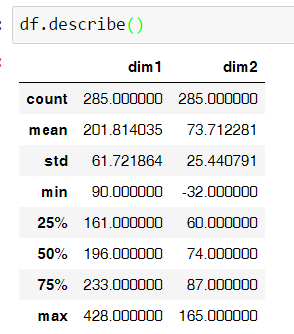
Первые 285 автомобилей имеют скромные размеры в пикселях + там все смазано...

Когда хочется побыстрее обрезать картинки, а думать не хочется рождаются вот такие уродливые решения
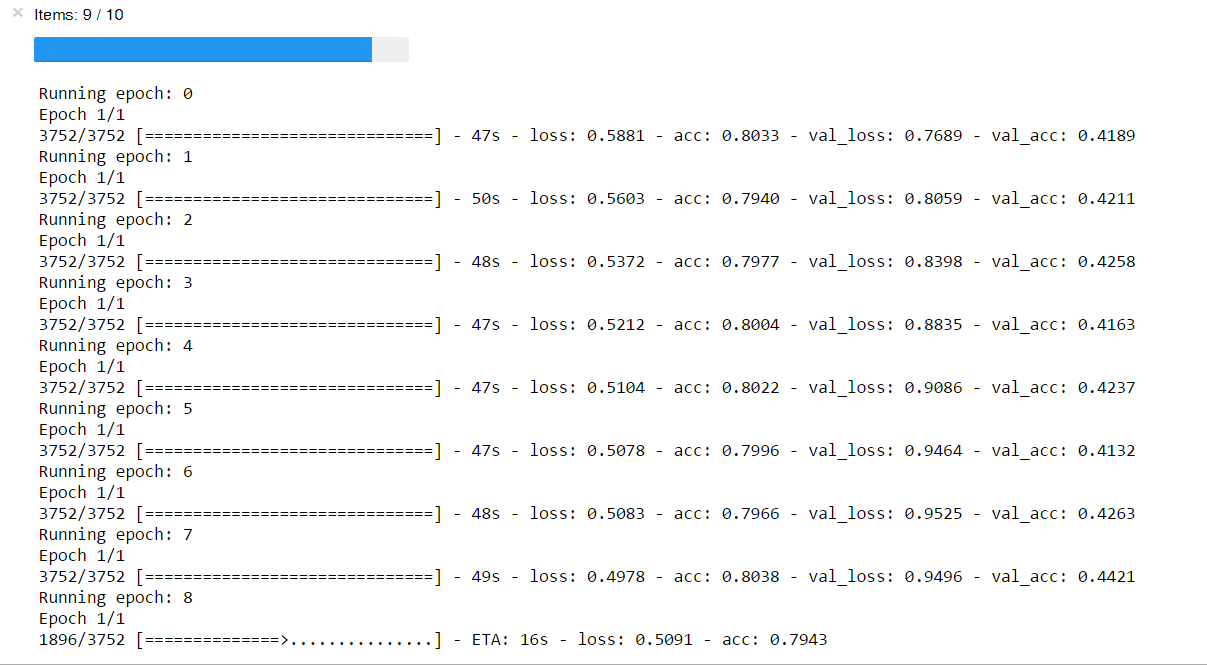
Разница в точности на тренировке и валидации намекает, что датасет перекошен, маленький и вообще. Зато красивый прогресс-индикатор.

Не куры, но виновники торжества. Очень смазанные — в движении
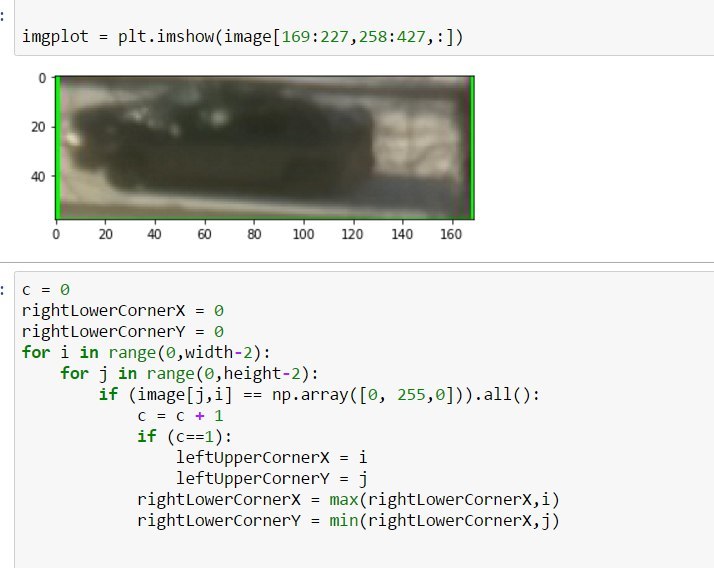
Радости нет границ, когда быдлокод, написание которого растянулось на час, начал работать и обрезать машину.
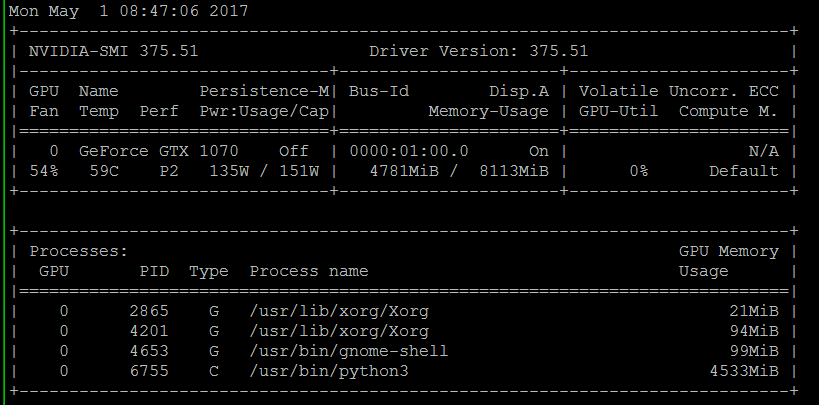
На практике места в памяти видео-карты хватает или с запасом, или его сразу не хватает. Тяжело подобрать размер картинки и размер batch'а, чтобы и рыбку съесть и…
Правило пальца — сверточные слои требуют много памяти, а dense слои — много времени.

Сравните полезную площадь на этой картинке...

И сколько тут полезных пикселей =) Да у курицы голова больше машины (в пикселях) — моя видеокарта будет страдать
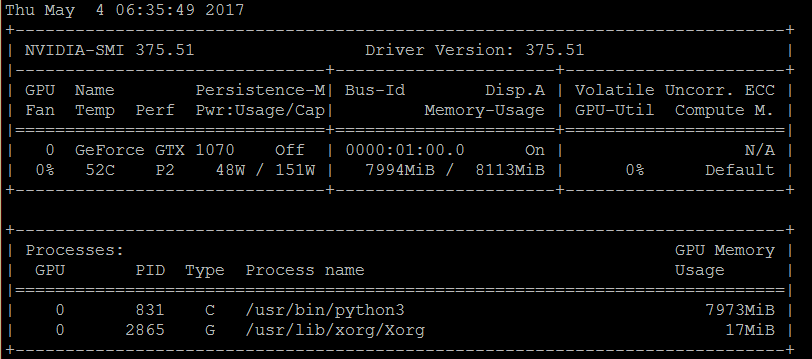
Не расчитал — память кончилась и все упало. А функции очистки, кроме как перезапуска я не нашел пока







