Стиль описания конечного автомата как образ мышления
Когда нужно преодолеть врожденную параллельность FPGA, и появляется желание заставить схему работать последовательно, по алгоритму, на помощь приходят конечные автоматы, про которые написано не мало академических и практических трудов.
Например, очень популярной является работа: Clifford E. Cummings, The Fundamentals of Efficient Synthesizable Finite State Machine Design using NC-Verilog and BuildGates. Всякий раз, когда специалисты решают обсудить, как правильно писать конечные автоматы, кто-то обязательно достает эту публикацию.
Статья стала настолько авторитетной, что многие даже не стараются анализировать аргументы автора. В частности, бытует мнение, что профессионалы всегда используют двухчастный способ описания конечных автоматов, имеется ввиду, описание конечных автоматов в 2 always блока. Это утверждение продолжает вызывать жаркие споры, и я хочу пояснить различия в описаниях конечного автомата с разным количество always блоков.
В беседах с коллегами я понял, что споры о том, как надо писать конечные автоматы в 1 или 2, 3 always блока, связаны с разным представлением (осознанием) реализуемого алгоритма, разным типом мышления. Попробую показать это на примере.
Я полагаю, что эта статья не первая статья о FSM и Verilog в вашей жизни, поэтому я не буду объяснять ни что такое конечный автомат, ни как он описывается на Verilog, а перейду сразу к делу.
Представьте, вы сидите дома, вам нужно сходить в магазин, купить хлеба, и вернуться обратно. Реализовать такое поведение просто — это алгоритмическая последовательность действий, ее можно описать так:
- Одеться и выйти на улицу
- Пойти в магазин, взять хлеб
- Оплатить его в кассе
- Вернуться домой и раздеться
Для многих такое описание покажется естественным. Четкая последовательность действий, похожа на строки программы. Однако, тот же алгоритм можно описать и по другому:
- Из дома направиться на улицу
- С улицы направиться в магазин (хлебный отдел)
- Из хлебного одела направиться в кассу
- Из кассы направиться домой
при этом
- когда мы дома — мы раздеты
- когда мы на улице — мы одеты
- когда мы в магазине (хлебном отделе) — мы берем хлеб
- когда мы у кассы — мы платим деньги
Интересно, хоть кто-то сейчас подумал, что последний вариант логичнее, чем первый?
Так или иначе, оба этих описания имеют представление в виде конечного автомата. Первое в виде описания с одним always блоком, а второе — с двумя или тремя. Оговорюсь, что описание в 2 и 3 always блока — это близнецы-братья, отличаются только техническими нюансами, которые нам сейчас не важны.
Покажем, как описания представляются в виде автомата:
У нас есть состояния автомата: HOME_STATE, STREET_STATE, MARKET_STATE, CASHIER_STATE, есть выходы автомата (наши действия): GET_DRESSED_ACT, UNDRESS_ACT, TAKE_BREAD_ACT, PAY_MONEY_ACT
Описание с 1 always блоком, выглядит так:
always @(posedge clk)
begin
if(reset)
begin
State <= HOME_STATE;
Action <= UNDRESS_ACT;
end
//---------------------------------
else
begin
case(State)
//-----------------------------
HOME_STATE:
begin
Action <= GET_DRESSED_ACT; //одеться
State <= STREET_STATE; //и пойти на улицу
end
//-----------------------------
STREET_STATE:
begin
State <= MARKET_STATE; //пойти в магазин
Action <= TAKE_BREAD_ACT; //взять хлеб
end
//-----------------------------
MARKET_STATE:
begin
State <= CASHIER_STATE; //пойти в кассу
Action <= PAY_MONEY_ACT; //оплатить хлеб
end
//-----------------------------
CASHIER_STATE:
begin
State <= HOME_STATE; //пойти домой
Action <= UNDRESS_ACT; //и раздеться
end
//-----------------------------
default: //если не знаем где мы (чего быть не может, но вдруг)
begin
State <= HOME_STATE; //идём домой
Action <= UNDRESS_ACT; //и раздеваемся
end
endcase
end
end
Теперь описание с 2 alwaysблоками:
//технический блок для организации переходов
always @(posedge clk)
begin
if(reset)
State <= HOME_STATE;
else
State <= NextState;
end
//блок работы автомата: выбор перехода и действия
always @(*)
begin
case(Sate)
//-----------------------------
HOME_STATE: //когда мы дома
begin
Action = UNDRESS_ACT; //мы раздеты
NextState = STREET_STATE; //собираемся идти на улицу
end
//-----------------------------
STREET_STATE: //когда мы на улице
begin
Action = GET_DRESSED_ACT; //мы одеты
NextState = MARKET_STATE; //собираемся в магазин
end
//-----------------------------
MARKET_STATE: //когда мы в магазине
begin
Action = TAKE_BREAD_ACT; //берем хлеб
NextState = CASHIER_STATE; //собираемся в кассу
end
//-----------------------------
CASHIER_STATE: //когда мы у кассы
begin
Action = PAY_MONEY_ACT; //мы платим деньги
NextState = HOME_STATE; //собираемся пойти домой
end
//-----------------------------
default://если не знаем где мы (чего быть не может, но вдруг)
begin
NextState = HOME_STATE; //мы хотим домой
Action = GET_DRESSED_ACT; //мы одеты (на всякий случай)
end
endcase
end
Хочу обратить внимание на особенности этих 2 описаний, которые и являются причиной священной войны за число блоков always.
1 always блок
HOME_STATE:
begin
Action <= GET_DRESSED_ACT; //одеться
State <= STREET_STATE; //и пойти на улицу
end
2 always блока
HOME_STATE: //когда мы дома
begin
Action = UNDRESS_ACT; //мы раздеты
NextState = STREET_STATE; //собираемся идти на улицу
end
Автомат с 1 always блоком в текущем состоянии определяет, какие действия он собирается делать дальше, не заботясь о том, что он делает сейчас. А автомат с 2 always блоками, в текущем состояние определяет, что он делает сейчас, и его не заботит, что он будет делать дальше или делал до этого.
Нельзя однозначно сказать какое поведение лучше или правильнее. Все сильно зависит от задачи, от реализуемого автоматом алгоритма. Для демонстрации изменим ситуацию. Теперь у вас есть дом, работа, бар. Вы ходите на работу — работать, в бар — пить пиво. В бар вы ходите как из дома по выходным, так и с работы в пятницу.
В первой реализации, с 1 always, вам надо внимательно следить куда вы собираетесь идти чтобы случайно не начать пить пиво на работе или работать в баре. Во второй реализации, с 2 always блоками, вы защищены от этого. Тут все четко определено: состояние на работе — работаем, состояние в баре — пьем пиво.
С другой стороны, в описании с 2 always блоками, придя в бар с работы, вы не сможете не пить пиво. Состояние в этой реализации жестко фиксирует действие бар — пьем пиво. А в описании с 1 always блоком, ваши действия в баре определяются в момент выхода из прошлого состояния. С работы вы можете пойти в бар и выпить виски. Каждый второй поход из дома в бар может заканчиваться вечеринкой. Текущее состояние в баре никак вас не ограничивает.
Оба автомата имеют свое место в проектах, просто нужно правильно определить, какие особенности будут полезны в конкретной ситуации.
Если у вас сложная сеть переходов и в разные состояния вы попадаете многими путями, имеет смысл использовать схему с 2 always блоками. У вас не будет шанса забыть задать какой то из выходов автомата при очередном переходе.
С другой стороны, если вы пишите простой автомат с практически линейной структурой, можно использовать описание с 1 always блоком. Фактически вы задаете последовательность на выходе, а состояния используете просто для организации последовательного выполнения. Так как выходы автомата не зависят от текущего состояния, не надо будет прописывать их значение в каждом состоянии, описание будет короче и логичнее.
В статье, с которой мы начали, хорошо показано почему надо использовать описания с 2 и 3 always блоками, а описание с 1 always блоком отмечено как самое плохое. Автор рекомендует избегать такого описания. Поэтому хочется привести пример реального интерфейса удобного для описания в 1 always блок и защитить данный вид описания. Для сравнения я приведу тот же автомат описанный в 3 always блока. Необходимо 3, а не 2 блока, потому, что мы будем использовать регистровые выходные сигналы.
И так, у нас есть модуль, который реализует запись в асинхронную память. На вход модуль принимает строб чтения либо записи, данные и адрес для записи, адрес для чтения. На выход модуль выдает сигнал завершения чтения или записи и считанные данные. Модуль управляет простой асинхронной памятью, имеющей следующие временные диаграмы работы.

Основной смысл модуля по стробу чтения либо записи «развернуть времянку», выдержать заданные интервалы, а по завершению выдать 1 тактовый сигнал готовности. Нам необходимо соблюдать следующие интервалы
- Rs — время установки адреса и сигнала выбора памяти перед чтением
- Rp — время выдержки сигнала разрешения выхода памяти до появления корректных данных
- Rh — время выдержки сигнала выбора памяти после снятия разрешения выхода
- Ws — время установки адреса, данных и сигнала выбора памяти перед записью
- Wp — длительность выставления сигнала разрешения записи
- Wh — время выдержки данных и адреса после снятия сигнала разрешения записи
Интервалы мы будем измерять в количестве тактов входной частоты и зададим интервалы константами READ_SETUP, READ_PULSE, READ_HOLD и WRITE_SETUP, WRITE_PULSE, WRITE_HOLD.
Описание с 1 always блоком:
module mem_ctrl_1
(
//system side
input clk,
input reset,
input w_strb,
input r_strb,
input [7:0] s_waddress,
input [7:0] s_raddress,
input [7:0] s_data_to,
output reg [7:0] s_data_from,
output reg done,
//memory side
output reg [7:0] m_address,
output reg [7:0] m_data_to,
input [7:0] m_data_from,
output reg cs_n,
output reg oe_n,
output reg we
);
//------------------------------------------------------
parameter PAUSE_CNT_SIZE = 16;
parameter READ_SETUP = 5;
parameter READ_PULSE = 3;
parameter READ_HOLD = 1;
parameter WRITE_SETUP = 5;
parameter WRITE_PULSE = 3;
parameter WRITE_HOLD = 1;
//------------------------------------------------------
reg [PAUSE_CNT_SIZE - 1 : 0] PCounter;
//------------------------------------------------------
reg [3:0] State;
localparam [3:0] IDLE = 0;
localparam [3:0] PREPARE_READ = 1;
localparam [3:0] READ = 2;
localparam [3:0] END_READ = 3;
localparam [3:0] PREPARE_WRITE = 4;
localparam [3:0] WRITE = 5;
localparam [3:0] END_WRITE = 6;
//------------------------------------------------------
always @(posedge clk)
begin
if(reset)
begin
done <= 1'b0;
m_address <= 8'd0;
m_data_to <= 8'd0;
s_data_from <= 8'd0;
cs_n <= 1'b1;
oe_n <= 1'b1;
we <= 1'b0;
State <= IDLE;
PCounter <= 0;
end
else
begin
//счётчик всегда считает до 0
if(PCounter != 0)
PCounter <= PCounter - 1'b1;
//всегда снимаем сигнал готовности,
//он не больше 1 такта
done <= 1'b0;
case(State)
//--------------------------
IDLE:
begin
if(w_strb == 1'b1) //запрос записи
begin
cs_n <= 1'b0;
m_data_to <= s_data_to;
State <= PREPARE_WRITE;
m_address <= s_waddress;
PCounter <= WRITE_SETUP;
end
else if(r_strb == 1'b1) //запрос чтения
begin
cs_n <= 1'b0;
m_address <= s_raddress;
State <= PREPARE_READ;
PCounter <= READ_SETUP;
end
end
//--------------------------
PREPARE_READ:
begin
if(PCounter == 0)
begin
State <= READ;
oe_n <= 1'b0;
PCounter <= READ_PULSE;
end
end
//--------------------------
READ:
begin
if(PCounter == 0)
begin
State <= END_READ;
oe_n <= 1'b1;
PCounter <= READ_HOLD;
s_data_from <= m_data_from;
end
end
//--------------------------
END_READ:
begin
if(PCounter == 0)
begin
State <= IDLE;
cs_n <= 1'b1;
done <= 1'b1;
end
end
//--------------------------
PREPARE_WRITE:
begin
if(PCounter == 0)
begin
State <= WRITE;
we <= 1'b1;
PCounter <= WRITE_PULSE;
end
end
//--------------------------
WRITE:
begin
if(PCounter == 0)
begin
State <= END_WRITE;
we <= 1'b0;
PCounter <= WRITE_HOLD;
end
end
//--------------------------
END_WRITE:
begin
if(PCounter == 0)
begin
State <= IDLE;
cs_n <= 1'b1;
done <= 1'b1;
end
end
//--------------------------
default: //невозможная ситуация
begin
done <= 1'b0;
m_address <= 8'd0;
m_data_to <= 8'd0;
s_data_from <= 8'd0;
cs_n <= 1'b1;
oe_n <= 1'b1;
we <= 1'b0;
State <= IDLE;
end
endcase
end
end
endmodule
Описание с 3 always блоками:
module mem_ctrl_3
(
//system side
input clk,
input reset,
input w_strb,
input r_strb,
input [7:0] s_waddress,
input [7:0] s_raddress,
input [7:0] s_data_to,
output reg [7:0] s_data_from,
output reg done,
//memory side
output reg [7:0] m_address,
output reg [7:0] m_data_to,
input [7:0] m_data_from,
output reg cs_n,
output reg oe_n,
output reg we
);
//------------------------------------------------------
parameter PAUSE_CNT_SIZE = 16;
parameter READ_SETUP = 5;
parameter READ_PULSE = 3;
parameter READ_HOLD = 1;
parameter WRITE_SETUP = 5;
parameter WRITE_PULSE = 3;
parameter WRITE_HOLD = 1;
//------------------------------------------------------
reg [PAUSE_CNT_SIZE - 1 : 0] PCounter;
//------------------------------------------------------
reg [3:0] State;
reg [3:0] NextState;
localparam [3:0] IDLE = 0;
localparam [3:0] PREPARE_READ = 1;
localparam [3:0] READ = 2;
localparam [3:0] END_READ = 3;
localparam [3:0] PREPARE_WRITE = 4;
localparam [3:0] WRITE = 5;
localparam [3:0] END_WRITE = 6;
//------------------------------------------------------
//технический блок
always @(posedge clk)
begin
if(reset)
State <= IDLE;
else
State <= NextState;
end
//------------------------------------------------------
//выбор перехода
always @(*)
begin
//по умолчанию сохраняем текущее состояние
NextState = State;
case(State)
//--------------------------------------
IDLE:
begin
if(w_strb == 1'b1) //запрос записи
begin
NextState = PREPARE_WRITE;
end
else if(r_strb == 1'b1) //запрос чтения
begin
NextState = PREPARE_READ;
end
end
//--------------------------------------
PREPARE_READ:
begin
if(PCounter == 0)
begin
NextState = READ;
end
end
//--------------------------------------
READ:
begin
if(PCounter == 0)
begin
NextState = END_READ;
end
end
//--------------------------------------
END_READ:
begin
if(PCounter == 0)
begin
NextState = IDLE;
end
end
//--------------------------------------
PREPARE_WRITE:
begin
if(PCounter == 0)
begin
NextState = WRITE;
end
end
//--------------------------------------
WRITE:
begin
if(PCounter == 0)
begin
NextState = END_WRITE;
end
end
//--------------------------------------
END_WRITE:
begin
if(PCounter == 0)
begin
NextState = IDLE;
end
end
//--------------------------------------
default: NextState = IDLE;
endcase
end
//-------------------------------------------
//задание выхода
always @(posedge clk)
begin
if(reset)
begin
cs_n <= 1'b1;
oe_n <= 1'b1;
we <= 1'b0;
end
else
begin
//чтобы значение выхода изменялось вместе с изменением
//состояния, а не на следующем такте, анализируем NextState
case(NextState)
//--------------------------------------
IDLE:
begin
cs_n <= 1'b1;
oe_n <= 1'b1;
we <= 1'b0;
end
//--------------------------------------
PREPARE_READ:
begin
cs_n <= 1'b0;
oe_n <= 1'b1;
we <= 1'b0;
end
//--------------------------------------
READ:
begin
cs_n <= 1'b0;
oe_n <= 1'b0;
we <= 1'b0;
end
//--------------------------------------
END_READ:
begin
cs_n <= 1'b0;
oe_n <= 1'b1;
we <= 1'b0;
end
//--------------------------------------
PREPARE_WRITE:
begin
cs_n <= 1'b0;
oe_n <= 1'b1;
we <= 1'b0;
end
//--------------------------------------
WRITE:
begin
cs_n <= 1'b0;
oe_n <= 1'b1;
we <= 1'b1;
end
//--------------------------------------
END_WRITE:
begin
cs_n <= 1'b0;
oe_n <= 1'b1;
we <= 1'b0;
end
endcase
end
end
//-------------------------------------------
//обработка задания адреса и данных
//эти сигналы задаются только на границе переходов
always @(posedge clk)
begin
if(reset)
begin
m_address <= 8'd0;
m_data_to <= 8'd0;
s_data_from <= 8'd0;
done <= 1'b0;
end
else
begin
if ((State == IDLE) && (NextState == PREPARE_WRITE))
begin
m_address <= s_waddress;
m_data_to <= s_data_to;
end
else if ((State == IDLE) && (NextState == PREPARE_READ))
m_address <= s_raddress;
//----------------------------------------------------------------
if ((State == READ) && (NextState == END_READ))
s_data_from <= m_data_from;
//----------------------------------------------------------------
if ((State == END_READ) && (NextState == IDLE))
done <= 1'b1;
else if ((State == END_WRITE) && (NextState == IDLE))
done <= 1'b1;
else
done <= 1'b0;
end
end
//-------------------------------------------
//обработка счетчика паузы
always @(posedge clk)
begin
if(reset)
begin
PCounter <= 0;
end
else
begin
//счетчик все время идет до 0, кроме
//моментов смены состояния, когда задается величина
//паузы для следующего состояния
if ((State == IDLE) && (NextState == PREPARE_WRITE))
PCounter <= WRITE_SETUP;
else if((State == PREPARE_WRITE) && (NextState == WRITE))
PCounter <= WRITE_PULSE;
else if((State == WRITE) && (NextState == END_WRITE))
PCounter <= WRITE_HOLD;
//----------------------------------------------------------
else if((State == IDLE) && (NextState == PREPARE_READ))
PCounter <= READ_SETUP;
else if((State == PREPARE_READ) && (NextState == READ))
PCounter <= READ_PULSE;
else if((State == READ) && (NextState == END_READ))
PCounter <= READ_HOLD;
//----------------------------------------------------------
else if(PCounter != 0)
PCounter <= PCounter - 1'b1;
end
end
endmodule
Вот результат моделирования работы описаний
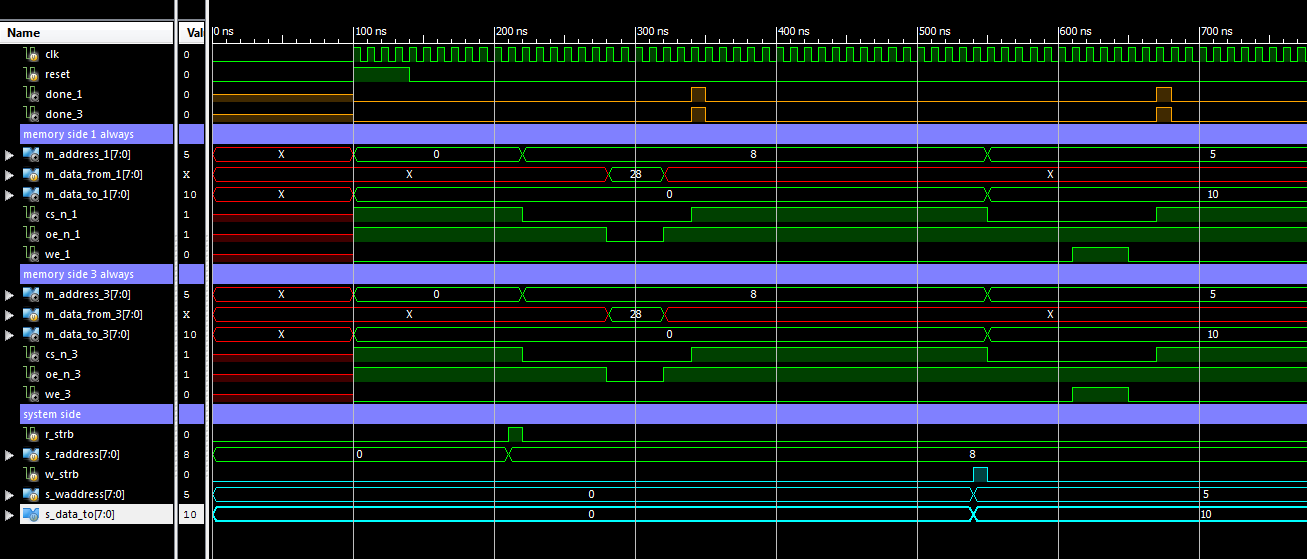
Как мы видим, ведут они себя одинаково и соответствую желаемым временным диаграммам памяти. Описание в 3 always блока получилось в большее число блоков, иначе блок задания выходов сильно бы усложнился. Заряжать счетчик, сохранять данные для записи в память и обратно нам надо в одном конкретном такте. Для этого нужно либо добавлять однотактные состояния в автомат, либо создавать конструкции выделения этих тактов. Я предпочел второй вариант и вынес конструкции в отдельные блоки, чтобы не усложнять блок задания выходов.
Так или иначе, в этом примере мы видим насколько больше получается описание в 3 always блока (брутто 287 строк против 181). В нем больше мест, где можно совершить ошибку. Отлаживается оно тоже сложнее. Если вы просматривали эти два описания, то могли заметить, что в первом описании вся картина работы видна сразу, а во втором мы всегда видим какую то часть. Полная картина разнесена по всему файлу.
Разбирать так описанный чужой автомат отдельное «удовольствие». Особенно, если условия переходов зависит от выходов автомата (в нашем случает состояние задает счетчик, а счетчик задает условие перехода). Сначала смотришь значение выходов в текущем состоянии, потом летишь в блок переходов и смотришь, куда мы переходим в данном состоянии и при таком значении выходов. Потом опять мотаешь в блок задания выходов, смотришь их изменения от нового состояния.
Автомат описанный в 2 always блока анализируется чуть проще, у него выходы и переходы часто лежат рядом в одном блоке, но ровно до момента, пока мы не захотим защелкнуть состояние выхода в регистр. Тут начинают появляться регистры с парными комбинаторными значениями их следующего состояния, потом начинают добавляться условия защелкивания и мы возвращаемся к исходному упражнению.
Надеюсь теперь описание с 1 always блоком, потеряет титул «самое плохое описание, старайтесь его избегать». Конечно не стоит всегда использовать только этот вид описания. При ветвистых сетях переходов 1 блоковое описание правда неудобно. Быстро разрастается по объему кода и перестает управляться. Однако выкидывать его из арсенала разработки однозначно не стоит.







