Здравствуйте, коллеги! В этой статье я кратко расскажу об особенностях построения решения по классификации тем обращений клиентов в контактный центр, с которыми мы столкнулись при разработке.
Определение тем обращений используется для отслеживания тенденций и прослушивания интересующих записей. Традиционно, эта задача решается путём проставления соответствующего тега оператором, но при данном подходе большую роль играет «человеческий» фактор, и тратится много человеко-часов работы операторов.

Для решения этой задачи, нашей командой – Data4 была разработана система определения темы на основе классификации текстов.
На входе использовался 2 канальный WAV файл, с частотой 8 кГц. Файл транскрибировался с помощью системы распознавания речи. Опыт показал, что качество распознавание русской спонтанной речи на наших данных составляло 60-70% по метрике WER. Данное качество затрудняет применение методов разложения предложений в граф и т. д., и для визуального анализа, но является достаточным для статистического анализа.
Была протестирована гипотеза, что помимо текста, на качество прогноза могут влиять параметры речи, такие как паузы, перебивания и соотношения количества речи оператора к количеству речи абонента. Для выявления данных признаков мы использовали детектор наличия речи, который работает следующим образом:
Проверка показала, что полученные из обработки сигнала признаки не вносят положительного вклада в нашу модель. Обучение проводилось на маленькой выборке (1 тыс. записей для каждого класса), возможно, при большей обучающей выборке возможен другой результат.
Для построения классификатора на основе текстов, требовалось перевести тексты в векторы признаков. Для этого мы использовали метод TF – IDF. TF – IDF это статистическая мера, для оценки важности слова в контексте документа, являющегося частью коллекции документов, в которой вес слова пропорционален количеству употреблений этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции. Для снижения размерности была использована процедура лемматизации форм слов.

Чтобы не учитывать редко используемые слова, и часто используемые слова, мы используем список стоп слов для русского языка и экспериментально ограничили длину вектора признаков 3000, a минимальную частоту встречаемости токена 2. Дополнительно, в список стоп слов были внесены слова из нецензурной лексики, междометия, союзы, частицы, так как в подавляющем большинстве случаев они являлись результатом ошибочной работы системы распознавания речи либо не несли существенной информации. Оставшиеся слова несут достаточно информации, чтобы использовать их векторное представление для обучения классификатора тем.

Метрикой качества была выбрана F мера. F мера учитывает значения точности (precision) и полноты (recall) и вычисляется по формуле: F = 2 P*R / (P + R), где P – точность, R – полнота.
Для минимизации эффекта переобучения использовалась L2 регуляризация и кросс-валидация с 10 блоками.
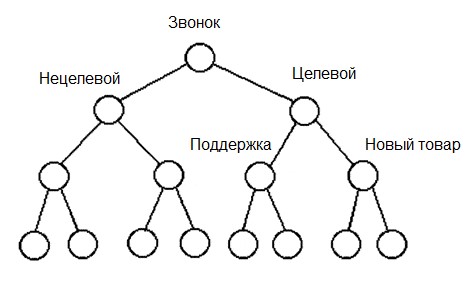
Мы использовали бинарный классификатор, основанный на предположении, что тему можно выделить путём противопоставления остальных тем, а темы внутри тем представить в виде дерева.
Тестирование алгоритмов показало, что для задачи классификации текстов обращений лучшие результаты дают логистическая регрессия и случайный лес решений. При этом логистическая регрессия показывала устойчивые результаты на нескольких наборах данных, при этом случайный лес показал максимальное качество, но необходимость дополнительной ручной настройки при изменении набора данных.
По метрике качества F1 мера для взвешенных классов содержащих не менее 1 тыс. примеров было достигнуто качество равное 0,98. Следует заметить, что такое качество было достигнуто только для ряда тестовых данных. Для некоторых классов, содержащих 250–300 примеров максимальное значение составляло 0,7. Это объясняется формализацией разделения тем и частотной встречаемостью темы в наборе текстов для обучения модели. Так, качество классификации целевых и нецелевых звонков будет выше качества классификации запросов клиентов о конкретных услугах и для тех видов, которые встречаются чаще.
Резюме:
Для классификации тем обращений в контактный центр рационально использовать алгоритм на основе логистической регрессии для достижения устойчивого качества, или алгоритм на базе случайного леса решений, который требуется предварительно настроить. На вход алгоритма подаётся вектор признаков, полученный из текста. Для достижения высокого качества по метрике F1 мера, следует использовать обучающую выборку, в которой содержится минимум 1 тыс. примеров каждого класса.
Полезные ссылки для работы с текстами:
Big-ARTM — State-of-the-art Topic Modeling
Gensim — Topic Modeling for Human
Обзор подходов к классификации текстов
Классификация методом нейронных сетей
Классификация методом SVM
P.S. Благодарю Анну Ларионову за вклад в подготовку статьи и разработку решения.
Определение тем обращений используется для отслеживания тенденций и прослушивания интересующих записей. Традиционно, эта задача решается путём проставления соответствующего тега оператором, но при данном подходе большую роль играет «человеческий» фактор, и тратится много человеко-часов работы операторов.

Для решения этой задачи, нашей командой – Data4 была разработана система определения темы на основе классификации текстов.
На входе использовался 2 канальный WAV файл, с частотой 8 кГц. Файл транскрибировался с помощью системы распознавания речи. Опыт показал, что качество распознавание русской спонтанной речи на наших данных составляло 60-70% по метрике WER. Данное качество затрудняет применение методов разложения предложений в граф и т. д., и для визуального анализа, но является достаточным для статистического анализа.
Была протестирована гипотеза, что помимо текста, на качество прогноза могут влиять параметры речи, такие как паузы, перебивания и соотношения количества речи оператора к количеству речи абонента. Для выявления данных признаков мы использовали детектор наличия речи, который работает следующим образом:
- сигнал переводится в частотную область быстрым преобразованием Фурье;
- сигнал делится на фреймы 25 миллисекунд.;
- для каждого фрейма определяются первые 13 мел-частотных кепстральных коэффициентов и их первая и вторая дельта;
- полученный вектор признаков подаётся на классификатор, на основе XGboost.
Проверка показала, что полученные из обработки сигнала признаки не вносят положительного вклада в нашу модель. Обучение проводилось на маленькой выборке (1 тыс. записей для каждого класса), возможно, при большей обучающей выборке возможен другой результат.
Для построения классификатора на основе текстов, требовалось перевести тексты в векторы признаков. Для этого мы использовали метод TF – IDF. TF – IDF это статистическая мера, для оценки важности слова в контексте документа, являющегося частью коллекции документов, в которой вес слова пропорционален количеству употреблений этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции. Для снижения размерности была использована процедура лемматизации форм слов.

Чтобы не учитывать редко используемые слова, и часто используемые слова, мы используем список стоп слов для русского языка и экспериментально ограничили длину вектора признаков 3000, a минимальную частоту встречаемости токена 2. Дополнительно, в список стоп слов были внесены слова из нецензурной лексики, междометия, союзы, частицы, так как в подавляющем большинстве случаев они являлись результатом ошибочной работы системы распознавания речи либо не несли существенной информации. Оставшиеся слова несут достаточно информации, чтобы использовать их векторное представление для обучения классификатора тем.

Метрикой качества была выбрана F мера. F мера учитывает значения точности (precision) и полноты (recall) и вычисляется по формуле: F = 2 P*R / (P + R), где P – точность, R – полнота.
Для минимизации эффекта переобучения использовалась L2 регуляризация и кросс-валидация с 10 блоками.
Мы использовали бинарный классификатор, основанный на предположении, что тему можно выделить путём противопоставления остальных тем, а темы внутри тем представить в виде дерева.

Тестирование алгоритмов показало, что для задачи классификации текстов обращений лучшие результаты дают логистическая регрессия и случайный лес решений. При этом логистическая регрессия показывала устойчивые результаты на нескольких наборах данных, при этом случайный лес показал максимальное качество, но необходимость дополнительной ручной настройки при изменении набора данных.
По метрике качества F1 мера для взвешенных классов содержащих не менее 1 тыс. примеров было достигнуто качество равное 0,98. Следует заметить, что такое качество было достигнуто только для ряда тестовых данных. Для некоторых классов, содержащих 250–300 примеров максимальное значение составляло 0,7. Это объясняется формализацией разделения тем и частотной встречаемостью темы в наборе текстов для обучения модели. Так, качество классификации целевых и нецелевых звонков будет выше качества классификации запросов клиентов о конкретных услугах и для тех видов, которые встречаются чаще.
Резюме:
Для классификации тем обращений в контактный центр рационально использовать алгоритм на основе логистической регрессии для достижения устойчивого качества, или алгоритм на базе случайного леса решений, который требуется предварительно настроить. На вход алгоритма подаётся вектор признаков, полученный из текста. Для достижения высокого качества по метрике F1 мера, следует использовать обучающую выборку, в которой содержится минимум 1 тыс. примеров каждого класса.
Полезные ссылки для работы с текстами:
Big-ARTM — State-of-the-art Topic Modeling
Gensim — Topic Modeling for Human
Обзор подходов к классификации текстов
Классификация методом нейронных сетей
Классификация методом SVM
P.S. Благодарю Анну Ларионову за вклад в подготовку статьи и разработку решения.







