
DevOps — это маркетинговое словечко, за которым ничего нет! Или все-таки есть? Может быть, DevOps — это набор «правильных» инструментов, или это такая специальная культура. И кто вообще должен этим заниматься, что из себя представляет DevOps-инженер? Одним словом, есть некоторые разночтения в понятиях, и очень много мифов. Некоторые совсем тривиальные, и мало кто в них поверит, а некоторые пускают корни в умах уважаемых специалистов. Разбираться будем вместе с опытными DevOps’ерами Александром Титовым и Иваном Евтуховичем (evtuhovich). Хотя они и считают, что DevOps — это решение проблемы производства цифровых продуктов и называть так отдельного человека это в стиле российского бизнеса.
О спикерах: Александр Титов и Иван Евтухович представляют компанию Экспресс 42, которая занимается консалтингом в области DevOps. Среди её клиентов много известных компаний, например, МТС, Райффайзенбанк банк, Альфа-Банк и другие.
За 5 лет работы собралась куча мифов про DevOps, которые существуют в обществе. В своем докладе на РИТ++ 2017 Александр и Иван рассуждали на эту тему. Иван в безапелляционном тоне объявлял расхожее мнение, а Александр пытался убедить слушателей в том, что это лишь миф.
Видимо, доводам, которые приводятся в статьях и докладах, люди не до конца верят. Попробую еще раз рассказать про это. Это мое личное мнение, которое подкреплено личным опытом.
Я часто вижу такую ситуацию. Обычная компания, ничего в ней не происходит до тех пор, пока генеральный директор или совет директоров не заболеет digital трансформацией. Это очень заразная болезнь, которая обычно распространяется на конференциях для генеральных директоров или топ-менеджмента. После этого у него в голове возникают слова Agile, DevOps, digital, product и пр. Человек собирает подчиненных и говорит: «Ребята, нам нужен Agile, DevOps, digital, поищите и сделайте».
На самом деле не задача директора в этом всем разбираться. Он для себя вывел, например, как увеличить revenue, value streams и понял, что это коррелирует друг с другом.
Дальше ребята собираются и начинают думать, что с этим делать. Почитали в Википедии про DevOps: «Методология, объединяющая разработчиков, эксплуатацию, тестирование для непрерывной поставки ПО».
В их компании поставка ПО непрерывная, деплоются раз в 3 месяца. Разработчики и сисадмины постоянно вместе посещают бары — никакой проблемы со взаимодействием нет. Надо принять волевое решение и переименовать какой-нибудь отдел в DevOps.
В конечном итоге либо отдел качества переименовывают в DevOps, либо отдел эксплуатации — в зависимости от опыта людей, которые это делают. Но что с ним делать с этим отделом, если там quality/issue инженеры? Это же неправильно, надо и их переименовать в DevOps-инженеров.
Переименовываются сотрудники, размещаются новые вакансии. Я регулярно просматриваю DevOps-вакансии, потому что мы и наши клиенты ищем себе инженеров. Вы можете тоже зайти на hh.ru, Мой круг и посмотреть вакансии DevOps-инженеров. Они все настолько разные!
Нельзя выделить вообще никакую строгую стандартизацию либо типизацию: от людей, настраивающих pipeline на Jenkins, до тестировщиков, которые пишут автотесты; от специалистов по деплою на Амазон, до тех, кто настраивает мониторинг, выкатывает софт и т.д. Все возможные профессии, которые есть в IT, маркируются DevOps-инженер.
Исключением являются небольшие компании, которые действительно делают цифровые продукты, в которых есть реальная непрерывная поставка ПО. Они ищут людей, которые все в одном, потому что сложно выделить отдельную квалификацию. Тогда просто выкладывается вакансия DevOps-инженер, в которую пишется вообще все, что есть — Jenkins, Ansible, Chef, Docker, Kubernetes, Silex, Prometheus. Мне нравится, что люди часто пишут еще и с ошибками названия технологий.

В целом я не против названия DevOps-инженер или DevOps-отдел. Но самое важное, для чего нужен DevOps — это для создания потока ценности целиком в компании. DevOps должен покрывать все — начиная с аналитики и заканчивая конкретной эксплуатацией. Это не отдельная профессия или выделенная роль, а просто штука, которая решает задачу быстрого производства цифровых продуктов.
Первое упоминание этого слова датируется 2009 годом, когда Патрик Дебуа сказал на конференции:
Если вы ищите DevOps-инженера, подумайте, зачем он вам нужен. Лучше выделить конкретную компетенцию и искать ее на рынке, чем непонятного специалиста.
Расскажу свою интерпретацию того, откуда появилась эта проблема. Когда вся эта история с DevOps только начиналась, всю работу действительно делали специалисты-многостаночники. Например, один человек строил delivery pipeline, настраивал мониторинг и т.д. Я сам с того же самого начинал и все делал сам, потому что не знал, кому можно это поручить: мне надо здесь исследовать, тут прикрутить, там сделать. В итоге я был специалистом-многостаночником, который и Linux настраивал, и на Chef писал, и для Zabbix API прикручивал, и т.д. Приходилось делать все.
Но на самом деле это не работает.

Это известный пример роста производства на булавочной фабрике из книги Адама Смита. На самом деле историю про эти булавки придумал не он, а лишь честно украл из британской энциклопедии.
На самом деле эта логика никуда не делась. Когда я слышу, что специалисты должны быть кросс-функциональными, на самом деле думаю, что команды должны быть кросс-функциональными, но ни в коем случае не специалисты. Иначе мы приходим к истории, когда нам нужно произвести 48 000 булавок, а людей просто не хватает.
В книге «Проект „Феникс“. Роман о том, как DevOps меняет бизнес к лучшему» описана история про Брендона, который делает в компании все, и все в него затыкается, как в бутылочное горлышко. Это как раз история про клевого специалиста-многостаночника.
Но тут же возникает вопрос — если нанимать не многостаночника, то кого нанимать? На этот вопрос нет четкого ответа, проблема в том, что мы в нашем российском сообществе мало про это говорим. Мы любим набросить проблемы, но решать их никто не любит. Мы не выделяем конкретные специализации для людей, которые занимаются DevOps.
Попробую выделить эти роли крупными мазками и приглашаю вас к этой работе, потому что без разделения ролей, мы будем все время рассуждать про специалистов-многостаночников.
Чем отличается этот разработчик от выпускника типичного российского ВУЗа? Разработчик из типичного российского вуза умеет писать алгоритмы — и собственно все. DevOps-разработчик не только умеет писать описания, но и знает, как это описание воплощается в жизнь.
Я пришел в IT из радиоэлектроники и для меня было поразительно то, что здесь происходит: люди думают, что принципиальная схема — это и есть работающий продукт. У инженера-радиоэлектронщика такого мифа в голове нет, а в IT — есть.
Нужны разработчики, которые знают, что принципиальная схема — это не работающий продукт. Их мало, они приходят из смежных областей — например, вот из радиоэлектроники. Люди, которых готовят российские ВУЗы, этого не знают. Они думают, что мы написали код — и ладно.
Если вы собрались внедрять DevOps у себя в компании, эту компетенцию чаще всего проще нарастить внутри: обозначить проблему, если не можете сами, нанять человека, который обучит людей, даст им нужные категории, как работать с софтом в продакшене.
На самом деле эта роль настолько богата, что ее можно дробить дальше. По сути дела, она включает в себя менеджера-владельца продукта, который владеет продуктом платформы непрерывной поставки, и отдельные компетенции людей, которые эту платформу поставки строят. Но это для крупных компаний.
Для мелких компаний все проще. Это инженер, который хорошо знаком с системой управления конфигурацией, знает Docker, Kubernetes, может сделать на их основе непрерывный процесс поставки ПО и отдать разработчику.
Это сервисы, которые предоставляются разработчику как продукт. Заметьте, вы можете прийти на Амазон и купить эти отдельные сервисы. Амазон можно рассматривать как модель ролей DevOps, то есть то, что у них продается, можно вырастить у себя внутри.
Это не тот человек, который собирает build. Он управляет зависимостями, версиями, фасилитирует команды о договоренности на интеграционных окружениях, следит за работой конвейера непрерывной поставки и т.д.
Часто это мужчина, но это фея, которая наделяет вашу команду волшебством, чтобы она могла непрерывно поставлять ПО.
Откуда взялся этот миф?

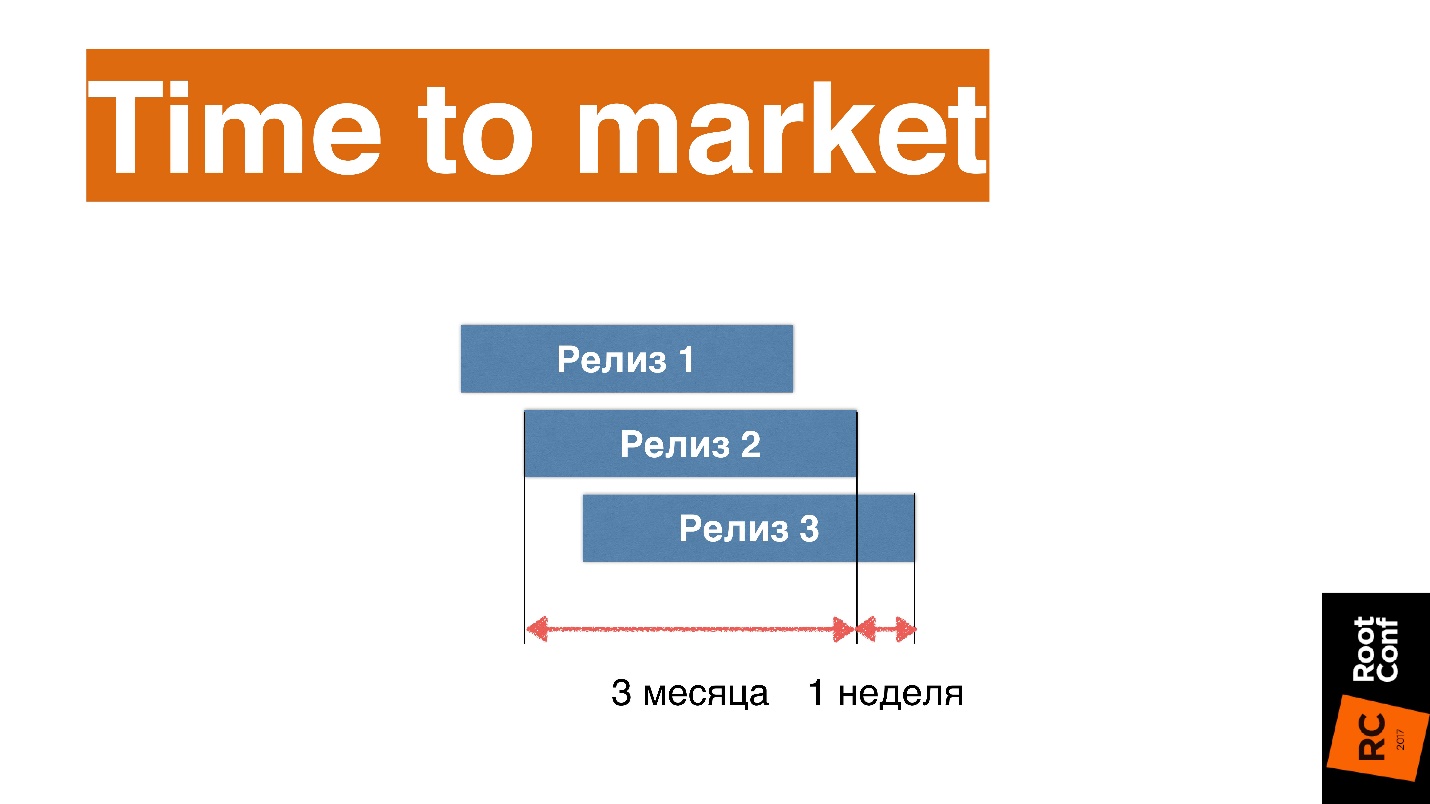
Дело в том, что люди непрерывную поставку ПО пытаются измерять релизами в единицу времени. Спрашивают: «Если раз в неделю мы выкатываемся — это DevOps?» Вообще говоря, это хороший результат. Но на самом деле у них есть разные релизные циклы — даже внутри одной команды —отдельных компонент фитч. При этом релизный цикл занимает три месяца, а деливирят они действительно раз в неделю — по разным релизным циклам. Получается хак, который называют DevOps. На самом деле произошла подмена понятий.
Основной смысл DevOps в том, чтобы обеспечивать time-to-market. Это не количество выкатов в единицу времени, а время, которое проходит от написания первой строчки кода до выкатки в продакшен. Здесь показатель неделя — это уже реально круто, а три месяца — реально не круто. Это уже не DevOps.
Time-to-market нужен компаниям, которые делают цифровые продукты для того, чтобы делать своим клиентам хорошо. Цифровая компания — это бизнес-люди, product-owner и прочие, и инженеры, которые пишут софт. Обычно в этих компаниях огромное количество обратных связей, потому что лично с клиентами они не работают.
Uber лично с клиентом не общается до тех пор, пока тот не будет недоволен их услугами. В этом случае человек открывает телефон, а там у него Get, Яндекс-такси, Максим. Он может принять решение и быстро перейти к другому игроку. Поэтому надо очень быстро отрабатывать обратную связь от рынка, вдобавок рынок (клиенты) еще постоянно меняется.
Поэтому основным параметром, двигающим DevOps в организации, является реальный time-to-market. Если у вас компания, которая не делает цифровое ПО для больших рынков, то, скорее всего, и DevOps не нужен. Это просто модное словечко, которое прилетело в голову генеральному директору, и он не до конца его понял.
Со стороны это выглядит примерно так.

Амазон реально деплоится раз в 11 секунд — то есть от написания кода до выкатки может проходить 11 секунд. На самом деле за этим стоит огромная работа и применение огромного количества DevOps-практик.
Я набросал основные DevOps практики, которые сфокусированы исключительно на time-to- market, без которых невозможно достичь получения непрерывной обратной связи от ваших клиентов и от рынка.
Звучит хорошо и довольно просто — давайте выкатывать на 0,1% пользователей. Но для этого нужно проделать колоссальную работу, например, перейти от монолитной архитектуры к микросервисной.
Это мониторинг как тестирование, когда разработчик в виде кода описывает, что надо мониторить в продакшене. После этого пуляет артефакт вместе с описанием, что нужно мониторить, и сразу же на всех стадиях конвейера непрерывной поставки все добавляется в мониторинг. Можно реально посмотреть, что происходит с приложением.
Когда вы выкатили на 0,1%, вы можете понять, работает ли софт так, как надо, или с ним что-то не так. Бесполезно выкатывать на 0,1%, если вы не знаете, что происходит с софтом.
Это когда по ID вы можете посмотреть в системе, как менялись данные клиента: вот он пришел на фронтенд, оттуда на бэкенд, далее в очередь, в очереди он забрался асинхронным воркером, асинхронный воркер сходил в базу, изменил состояние кэша — это все логируется. Без этого найти, что произошло в системе, невозможно, и выкатка на 0,1% тоже.
Представляете, вы решили выкатывать на всех 2 000 посетителей фестиваля «Российские интернет-технологии» какой-то новый софт, но сквозного логирования у вас нет. Эти 2 000 человек пишут, что у них не работает. Вы их спрашиваете, что не работает, потому что с вашей точки зрения происходит какой-то полтергейст. Бесполезная тема.
Автоматическое тестирование давно известно, существует много лет и использовалось для улучшения качества ПО. Здесь к автотестам нужно относиться несколько по-иному — как к форме договоренности между командами. Команды, вместо того, чтобы во время интеграции решать кучу мелких проблем в софте, договариваются, что каждая команда пишет автотесты и эти проблемы решает еще на этапе разработки отдельного модуля, элемента и т.д. Написание автотестов — это отдельная история.
Все описанные кирпичики — DevOps-практики для TTM — это куча времени и работы, если вы не начинаете с нуля, а, например, переписываете монолит. Но без них высокого time-to-market не достичь.

В целом, это обычный инженерный взгляд, но часто бывает так:

Я уже описал, сколько всего надо проделать, чтобы перейти к непрерывной поставке. Плюс еще надо внутри команды договориться. Если мы пишем автотесты, это именно про договоренность внутри команды, кроме того, что надо иметь навык написания автотестов.
Часто, когда хотят внедрить DevOps, устанавливается Kubernetes, используется какое-то время, а потом оказывается, что руками было бы проще, что компонентов много, они иногда глючат, и пока все это не нужно.
Мощными инструментами просто заколачиваются гвозди. Конечно, DevOps — это не только про правильные инструменты. Но при этом реально существует класс инструментов, которые имеют прямое отношение к DevOps и созданы как раз тем сообществом, которое было рождено Патриком Дебуа.
Для каждого этого инструмента есть еще и инструкции по применению: не просто описание того, как его установить или как он устроен внутри, но и мануал, как им пользоваться.
Например, когда вы ставите Git, вы же не разбираетесь досконально, как хэширование внутри устроено. Кто-то знает, кто-то нет, но в целом это знание бесполезно. То же самое с Kubernetes — это знание нужно только инженерам, которые его сопровождают. А инженерам вокруг надо знать, как с ним работать. Именно это знание важно, про него не стоит забывать.
На заре нашей компании у нас были пара внедрений Chef, которые управляли конфигурацией, только пока мы были в этой компании. Как только мы уходили, Chef оставался отдельно, а процесс возвращался в старое русло. Это были наши, так сказать, пробные камни. Но, тем не менее, такие истории у нас были.
Потому что, когда вы работаете со сложной экосистемой, причем практически с закрытыми глазами, то есть у вас есть черный ящик и куча людей, которые им пользуются, вам реально надо много думать.
Но в то же самое время, философия — это не самое важное. Есть еще знания и конкретные навыки, есть инструменты и подходы, которые также входят в DevOps. Наличие культуры не порождает наличие необходимых процессов. Появление определенной культуры за два дня тренинга специально обученных коучей ни к чему не приведет.
Мало того, если после тренинга не начать сразу что-то делать, все, что было на тренинге вложено в головы, выветривается и проходит бесследно. Мы, как люди, которые проводили много тренингов, это знаем точно. Мы и сами ходили на тренинги. Это не работает.
Мало узнать новый образ мышления, надо с ним сразу попробовать что-то делать руками — с теми инструментами, которые используются, и желательно на реальной задаче.
Поэтому DevOps — это не только философия, а философия — это часть DevOps. Я исповедую мнение, что DevOps — это часть большой Agile-философии. Есть Agile-ценности, и DevOps в них входит, как набор инженерных практик и инструментов, которые помогают эти ценности реализовать.
Да, действительно это так. Но могу сказать еще круче. Все дисциплины, которые используются в ITIL, есть на химическом заводе, в том числе:
Это общие дисциплины инженерии. Проектному менеджменту уже 100 лет, им примерно столько же — сколько фабрики работают, столько эти дисциплины существуют. Просто уже существующие дисциплины в свое время были переложены под IT, которое на тот момент было.
Это IT кардинальным образом отличается от IT, которое делает цифровые продукты. Это отдельная тема для разговора. Смысл в том, что дисциплины те же, но содержание и наполнение другое: стандарты, подходы, методики, инструменты.
Вообще ITIL сделан для другого. Поэтому с одной стороны, да, действительно похожи, но, с другой стороны, неприменимы, их невозможно использовать.
Это примерно та же самая история, как и с ITIL.

Но есть реальное сообщество, которое стартовало после слов Патрика Дебуа. Регулярно проводится мероприятие, которое называется DevOps Days и в 2017 году проходило в Москве. Таких мероприятий в мире ежегодно проводится порядка 150. Думаю, будет еще больше.
Эти люди говорят о чем-то, нормальные хардкорные чуваки решают нормальные, в том числе и инженерные проблемы, а не только менеджерские. То есть в этом есть смысл, а если в этом есть смысл, значит, это не просто маркетинговое словечко.
Мой совет для людей, которые думают, что это маркетинговое словечко, обратить внимание на контент, который производит DevOps Days, там нет вендорского налета и хайпа. В России тоже есть куча ресурсов:
Здесь обсуждаются проблемы DevOps — можно прийти, послушать и понять, что в этом нет маркетинга. Люди занимаются DevOps потому, что им это реально надо.
О спикерах: Александр Титов и Иван Евтухович представляют компанию Экспресс 42, которая занимается консалтингом в области DevOps. Среди её клиентов много известных компаний, например, МТС, Райффайзенбанк банк, Альфа-Банк и другие.
За 5 лет работы собралась куча мифов про DevOps, которые существуют в обществе. В своем докладе на РИТ++ 2017 Александр и Иван рассуждали на эту тему. Иван в безапелляционном тоне объявлял расхожее мнение, а Александр пытался убедить слушателей в том, что это лишь миф.
Миф № 1. DevOps может делать DevOps-отдел или DevOps-инженер
Для того, чтобы сделать нормальный DevOps, мы нанимаем DevOps-инженеров либо создаем DevOps-отдел, и все — у нас в компании полный DevOps!Это очень забористое высказывание, которое мы постоянно слышим. Есть огромное количество материалов, в которых рассказывается, почему не существует DevOps-инженеров, почему не надо создавать DevOps-отдел и т.д. Но все равно DevOps-отделы возникают, туда набирают DevOps-инженеров, вакансий DevOps-специалистов становится все больше.
Видимо, доводам, которые приводятся в статьях и докладах, люди не до конца верят. Попробую еще раз рассказать про это. Это мое личное мнение, которое подкреплено личным опытом.
Я часто вижу такую ситуацию. Обычная компания, ничего в ней не происходит до тех пор, пока генеральный директор или совет директоров не заболеет digital трансформацией. Это очень заразная болезнь, которая обычно распространяется на конференциях для генеральных директоров или топ-менеджмента. После этого у него в голове возникают слова Agile, DevOps, digital, product и пр. Человек собирает подчиненных и говорит: «Ребята, нам нужен Agile, DevOps, digital, поищите и сделайте».
На самом деле не задача директора в этом всем разбираться. Он для себя вывел, например, как увеличить revenue, value streams и понял, что это коррелирует друг с другом.
Дальше ребята собираются и начинают думать, что с этим делать. Почитали в Википедии про DevOps: «Методология, объединяющая разработчиков, эксплуатацию, тестирование для непрерывной поставки ПО».
В их компании поставка ПО непрерывная, деплоются раз в 3 месяца. Разработчики и сисадмины постоянно вместе посещают бары — никакой проблемы со взаимодействием нет. Надо принять волевое решение и переименовать какой-нибудь отдел в DevOps.
В конечном итоге либо отдел качества переименовывают в DevOps, либо отдел эксплуатации — в зависимости от опыта людей, которые это делают. Но что с ним делать с этим отделом, если там quality/issue инженеры? Это же неправильно, надо и их переименовать в DevOps-инженеров.
Переименовываются сотрудники, размещаются новые вакансии. Я регулярно просматриваю DevOps-вакансии, потому что мы и наши клиенты ищем себе инженеров. Вы можете тоже зайти на hh.ru, Мой круг и посмотреть вакансии DevOps-инженеров. Они все настолько разные!
Нельзя выделить вообще никакую строгую стандартизацию либо типизацию: от людей, настраивающих pipeline на Jenkins, до тестировщиков, которые пишут автотесты; от специалистов по деплою на Амазон, до тех, кто настраивает мониторинг, выкатывает софт и т.д. Все возможные профессии, которые есть в IT, маркируются DevOps-инженер.
Исключением являются небольшие компании, которые действительно делают цифровые продукты, в которых есть реальная непрерывная поставка ПО. Они ищут людей, которые все в одном, потому что сложно выделить отдельную квалификацию. Тогда просто выкладывается вакансия DevOps-инженер, в которую пишется вообще все, что есть — Jenkins, Ansible, Chef, Docker, Kubernetes, Silex, Prometheus. Мне нравится, что люди часто пишут еще и с ошибками названия технологий.

В целом я не против названия DevOps-инженер или DevOps-отдел. Но самое важное, для чего нужен DevOps — это для создания потока ценности целиком в компании. DevOps должен покрывать все — начиная с аналитики и заканчивая конкретной эксплуатацией. Это не отдельная профессия или выделенная роль, а просто штука, которая решает задачу быстрого производства цифровых продуктов.
Первое упоминание этого слова датируется 2009 годом, когда Патрик Дебуа сказал на конференции:
— Мы начали использовать новый подход. Мы теперь производим цифровые продукты и у нас есть проблема — по-старому ничего не работает. У меня одного не получается ее решить. Приглашаю всех в сообщество, чтобы вместе разбираться, как с этим жить. Давайте назовем эту проблему DevOps.DevOps — это решение проблемы производства цифровых продуктов. Называть так отдельного человека в стиле нашего российского бизнеса: нет человека — нет проблемы, есть человек — есть решение. Обратная логика.
Если вы ищите DevOps-инженера, подумайте, зачем он вам нужен. Лучше выделить конкретную компетенцию и искать ее на рынке, чем непонятного специалиста.
Справка для бережливых людей: обычно системный администратор со знанием Docker от DevOps-инженера со знанием Docker, отличается не знаниями, а ценником: первый условно стоит 90 000, второй — 150 000. Можно сэкономить.Раньше была популярна фраза «перекинуть лист через стену», когда разработка перекидывала в эксплуатацию — «Ставьте!», те кидали обратно — «Не встает!». С появлением DevOps-отдела мы перекидываем через стену два раза: сначала разработка в DevOps-отдел, а те уже в Ops-отдел.
Миф № 2. DevOps — это про то, что надо нанимать специалистов-многостаночников, которые умеют все
Расскажу свою интерпретацию того, откуда появилась эта проблема. Когда вся эта история с DevOps только начиналась, всю работу действительно делали специалисты-многостаночники. Например, один человек строил delivery pipeline, настраивал мониторинг и т.д. Я сам с того же самого начинал и все делал сам, потому что не знал, кому можно это поручить: мне надо здесь исследовать, тут прикрутить, там сделать. В итоге я был специалистом-многостаночником, который и Linux настраивал, и на Chef писал, и для Zabbix API прикручивал, и т.д. Приходилось делать все.
Но на самом деле это не работает.

Производительность
- 18 ремесленников многостаночников, которые сами могут сделать булавку, делают в день 360 булавок
- 18 ремесленников, разделенных по 18 специализациям, делают 48 000 булавок.
Это известный пример роста производства на булавочной фабрике из книги Адама Смита. На самом деле историю про эти булавки придумал не он, а лишь честно украл из британской энциклопедии.
На самом деле эта логика никуда не делась. Когда я слышу, что специалисты должны быть кросс-функциональными, на самом деле думаю, что команды должны быть кросс-функциональными, но ни в коем случае не специалисты. Иначе мы приходим к истории, когда нам нужно произвести 48 000 булавок, а людей просто не хватает.
В книге «Проект „Феникс“. Роман о том, как DevOps меняет бизнес к лучшему» описана история про Брендона, который делает в компании все, и все в него затыкается, как в бутылочное горлышко. Это как раз история про клевого специалиста-многостаночника.
Но тут же возникает вопрос — если нанимать не многостаночника, то кого нанимать? На этот вопрос нет четкого ответа, проблема в том, что мы в нашем российском сообществе мало про это говорим. Мы любим набросить проблемы, но решать их никто не любит. Мы не выделяем конкретные специализации для людей, которые занимаются DevOps.
Попробую выделить эти роли крупными мазками и приглашаю вас к этой работе, потому что без разделения ролей, мы будем все время рассуждать про специалистов-многостаночников.
DevOps, другие роли:
- Разработчик с представлением об архитектуре и работе софта в продакшене (пишет тесты и инфраструктурный код)
Чем отличается этот разработчик от выпускника типичного российского ВУЗа? Разработчик из типичного российского вуза умеет писать алгоритмы — и собственно все. DevOps-разработчик не только умеет писать описания, но и знает, как это описание воплощается в жизнь.
Я пришел в IT из радиоэлектроники и для меня было поразительно то, что здесь происходит: люди думают, что принципиальная схема — это и есть работающий продукт. У инженера-радиоэлектронщика такого мифа в голове нет, а в IT — есть.
Нужны разработчики, которые знают, что принципиальная схема — это не работающий продукт. Их мало, они приходят из смежных областей — например, вот из радиоэлектроники. Люди, которых готовят российские ВУЗы, этого не знают. Они думают, что мы написали код — и ладно.
Если вы собрались внедрять DevOps у себя в компании, эту компетенцию чаще всего проще нарастить внутри: обозначить проблему, если не можете сами, нанять человека, который обучит людей, даст им нужные категории, как работать с софтом в продакшене.
- Инфраструктурный инженер (пишет обвязки для инфраструктуры, предоставляет разработчику платформу)
На самом деле эта роль настолько богата, что ее можно дробить дальше. По сути дела, она включает в себя менеджера-владельца продукта, который владеет продуктом платформы непрерывной поставки, и отдельные компетенции людей, которые эту платформу поставки строят. Но это для крупных компаний.
Для мелких компаний все проще. Это инженер, который хорошо знаком с системой управления конфигурацией, знает Docker, Kubernetes, может сделать на их основе непрерывный процесс поставки ПО и отдать разработчику.
- Разработчик инфраструктурных сервисов (DBaS, Monitoring as Service, Logging as Service)
Это сервисы, которые предоставляются разработчику как продукт. Заметьте, вы можете прийти на Амазон и купить эти отдельные сервисы. Амазон можно рассматривать как модель ролей DevOps, то есть то, что у них продается, можно вырастить у себя внутри.
- Релиз-менеджер (управляет процессом и зависимостями)
Это не тот человек, который собирает build. Он управляет зависимостями, версиями, фасилитирует команды о договоренности на интеграционных окружениях, следит за работой конвейера непрерывной поставки и т.д.
Часто это мужчина, но это фея, которая наделяет вашу команду волшебством, чтобы она могла непрерывно поставлять ПО.
Миф 3. Мы разрабатываем корпоративную IT-систему, и у нас DevOps уже с 1995 года
Мы много лет ее разрабатываем корпоративную IT-систему, релизимся каждую неделю. Весь ваш DevOps — это просто пацаны в джинсах с подворотами пришли и переобозвали то, что мы умеем делать уже много лет.Кстати, довольно интересно, что обычно в таких командах реально включается DevOps процесс, когда происходят инциденты. В таких ситуациях границы резко размываются между отдельными командами разработчиков, тестировщиков и пр. У них включается свой собственный процесс, который был наработан годами. Он не формализован вообще, но действительно похож на DevOps.
Откуда взялся этот миф?
Дело в том, что люди непрерывную поставку ПО пытаются измерять релизами в единицу времени. Спрашивают: «Если раз в неделю мы выкатываемся — это DevOps?» Вообще говоря, это хороший результат. Но на самом деле у них есть разные релизные циклы — даже внутри одной команды —отдельных компонент фитч. При этом релизный цикл занимает три месяца, а деливирят они действительно раз в неделю — по разным релизным циклам. Получается хак, который называют DevOps. На самом деле произошла подмена понятий.
Основной смысл DevOps в том, чтобы обеспечивать time-to-market. Это не количество выкатов в единицу времени, а время, которое проходит от написания первой строчки кода до выкатки в продакшен. Здесь показатель неделя — это уже реально круто, а три месяца — реально не круто. Это уже не DevOps.
Time-to-market нужен компаниям, которые делают цифровые продукты для того, чтобы делать своим клиентам хорошо. Цифровая компания — это бизнес-люди, product-owner и прочие, и инженеры, которые пишут софт. Обычно в этих компаниях огромное количество обратных связей, потому что лично с клиентами они не работают.
Uber лично с клиентом не общается до тех пор, пока тот не будет недоволен их услугами. В этом случае человек открывает телефон, а там у него Get, Яндекс-такси, Максим. Он может принять решение и быстро перейти к другому игроку. Поэтому надо очень быстро отрабатывать обратную связь от рынка, вдобавок рынок (клиенты) еще постоянно меняется.
Поэтому основным параметром, двигающим DevOps в организации, является реальный time-to-market. Если у вас компания, которая не делает цифровое ПО для больших рынков, то, скорее всего, и DevOps не нужен. Это просто модное словечко, которое прилетело в голову генеральному директору, и он не до конца его понял.
Со стороны это выглядит примерно так.

Амазон реально деплоится раз в 11 секунд — то есть от написания кода до выкатки может проходить 11 секунд. На самом деле за этим стоит огромная работа и применение огромного количества DevOps-практик.
DevOps-практики для TTM
Я набросал основные DevOps практики, которые сфокусированы исключительно на time-to- market, без которых невозможно достичь получения непрерывной обратной связи от ваших клиентов и от рынка.
- Стратегии выкатки (голубо-зеленые выкатки, канареечные релизы, а/б-тестирование)
Звучит хорошо и довольно просто — давайте выкатывать на 0,1% пользователей. Но для этого нужно проделать колоссальную работу, например, перейти от монолитной архитектуры к микросервисной.
- Непрерывный мониторинг
Это мониторинг как тестирование, когда разработчик в виде кода описывает, что надо мониторить в продакшене. После этого пуляет артефакт вместе с описанием, что нужно мониторить, и сразу же на всех стадиях конвейера непрерывной поставки все добавляется в мониторинг. Можно реально посмотреть, что происходит с приложением.
Когда вы выкатили на 0,1%, вы можете понять, работает ли софт так, как надо, или с ним что-то не так. Бесполезно выкатывать на 0,1%, если вы не знаете, что происходит с софтом.
- Сквозное логирование
Это когда по ID вы можете посмотреть в системе, как менялись данные клиента: вот он пришел на фронтенд, оттуда на бэкенд, далее в очередь, в очереди он забрался асинхронным воркером, асинхронный воркер сходил в базу, изменил состояние кэша — это все логируется. Без этого найти, что произошло в системе, невозможно, и выкатка на 0,1% тоже.
Представляете, вы решили выкатывать на всех 2 000 посетителей фестиваля «Российские интернет-технологии» какой-то новый софт, но сквозного логирования у вас нет. Эти 2 000 человек пишут, что у них не работает. Вы их спрашиваете, что не работает, потому что с вашей точки зрения происходит какой-то полтергейст. Бесполезная тема.
- Автотесты (как форма договоренности между командами)
Автоматическое тестирование давно известно, существует много лет и использовалось для улучшения качества ПО. Здесь к автотестам нужно относиться несколько по-иному — как к форме договоренности между командами. Команды, вместо того, чтобы во время интеграции решать кучу мелких проблем в софте, договариваются, что каждая команда пишет автотесты и эти проблемы решает еще на этапе разработки отдельного модуля, элемента и т.д. Написание автотестов — это отдельная история.
Все описанные кирпичики — DevOps-практики для TTM — это куча времени и работы, если вы не начинаете с нуля, а, например, переписываете монолит. Но без них высокого time-to-market не достичь.
Миф 4. DevOps — это «правильные» инструменты
DevOps можно сделать, используя «правильные» инструменты: возьмем Kubernetes, обмажем его Ansible, поставим Prometheus, сбоку привертим Mesosphere, и все это Docker обмотаем — и сразу наступит в организации полный DevOps!

В целом, это обычный инженерный взгляд, но часто бывает так:

Я уже описал, сколько всего надо проделать, чтобы перейти к непрерывной поставке. Плюс еще надо внутри команды договориться. Если мы пишем автотесты, это именно про договоренность внутри команды, кроме того, что надо иметь навык написания автотестов.
Часто, когда хотят внедрить DevOps, устанавливается Kubernetes, используется какое-то время, а потом оказывается, что руками было бы проще, что компонентов много, они иногда глючат, и пока все это не нужно.
Мощными инструментами просто заколачиваются гвозди. Конечно, DevOps — это не только про правильные инструменты. Но при этом реально существует класс инструментов, которые имеют прямое отношение к DevOps и созданы как раз тем сообществом, которое было рождено Патриком Дебуа.
Для каждого этого инструмента есть еще и инструкции по применению: не просто описание того, как его установить или как он устроен внутри, но и мануал, как им пользоваться.
Например, когда вы ставите Git, вы же не разбираетесь досконально, как хэширование внутри устроено. Кто-то знает, кто-то нет, но в целом это знание бесполезно. То же самое с Kubernetes — это знание нужно только инженерам, которые его сопровождают. А инженерам вокруг надо знать, как с ним работать. Именно это знание важно, про него не стоит забывать.
На заре нашей компании у нас были пара внедрений Chef, которые управляли конфигурацией, только пока мы были в этой компании. Как только мы уходили, Chef оставался отдельно, а процесс возвращался в старое русло. Это были наши, так сказать, пробные камни. Но, тем не менее, такие истории у нас были.
Миф 5. DevOps — это «философия», специальная культура, которая родилась на Западе и не может быть перенесена на российские реалии.
Многие считают, что есть мифический запад, где мифические единороги делают мифический DevOps, а мы друг другу грубим и здесь DevOps никак не родится.Это очень сложный вопрос. Действительно, цифровые технологии рождаются в коллективах, в которых очень открытый ум, работает критическое мышление и т.д.
Потому что, когда вы работаете со сложной экосистемой, причем практически с закрытыми глазами, то есть у вас есть черный ящик и куча людей, которые им пользуются, вам реально надо много думать.
Но в то же самое время, философия — это не самое важное. Есть еще знания и конкретные навыки, есть инструменты и подходы, которые также входят в DevOps. Наличие культуры не порождает наличие необходимых процессов. Появление определенной культуры за два дня тренинга специально обученных коучей ни к чему не приведет.
Мало того, если после тренинга не начать сразу что-то делать, все, что было на тренинге вложено в головы, выветривается и проходит бесследно. Мы, как люди, которые проводили много тренингов, это знаем точно. Мы и сами ходили на тренинги. Это не работает.
Мало узнать новый образ мышления, надо с ним сразу попробовать что-то делать руками — с теми инструментами, которые используются, и желательно на реальной задаче.
Поэтому DevOps — это не только философия, а философия — это часть DevOps. Я исповедую мнение, что DevOps — это часть большой Agile-философии. Есть Agile-ценности, и DevOps в них входит, как набор инженерных практик и инструментов, которые помогают эти ценности реализовать.
Миф 6. В ITIL уже заложен DevOps, и не надо старое выдавать за новое. В DevOps используются те же самые практики.
Да, действительно это так. Но могу сказать еще круче. Все дисциплины, которые используются в ITIL, есть на химическом заводе, в том числе:
- инцидент-менеджмент;
- управление конфигурацией;
- управление изменениями;
- управление мощностями;
- управление доступностью.
Это общие дисциплины инженерии. Проектному менеджменту уже 100 лет, им примерно столько же — сколько фабрики работают, столько эти дисциплины существуют. Просто уже существующие дисциплины в свое время были переложены под IT, которое на тот момент было.
Это IT кардинальным образом отличается от IT, которое делает цифровые продукты. Это отдельная тема для разговора. Смысл в том, что дисциплины те же, но содержание и наполнение другое: стандарты, подходы, методики, инструменты.
Вообще ITIL сделан для другого. Поэтому с одной стороны, да, действительно похожи, но, с другой стороны, неприменимы, их невозможно использовать.
Миф 7. DevOps — это маркетинговое словечко, за которым ничего нет
Все повесили этот лейбл, и все стало такое DevOps’ное, а на самом деле это слово ничего не значит. Помните, был расцвет Agile Java разработчиков, прямо так в вакансиях и писали.Сейчас я затрону очень полемическую тему. Наши господа интеграторы и крупные вендоры послушали, о чем говорят гениальные директора, и переименовали свои продукты в DevOps-продукты. Те продукты, которые были сделаны для старого корпоративного IT, а не для производства цифрового продукта, они просто переименовали — было HP OpenView, стало DevOps HP OpenView — и все.
Это примерно та же самая история, как и с ITIL.
Но есть реальное сообщество, которое стартовало после слов Патрика Дебуа. Регулярно проводится мероприятие, которое называется DevOps Days и в 2017 году проходило в Москве. Таких мероприятий в мире ежегодно проводится порядка 150. Думаю, будет еще больше.
Эти люди говорят о чем-то, нормальные хардкорные чуваки решают нормальные, в том числе и инженерные проблемы, а не только менеджерские. То есть в этом есть смысл, а если в этом есть смысл, значит, это не просто маркетинговое словечко.
Мой совет для людей, которые думают, что это маркетинговое словечко, обратить внимание на контент, который производит DevOps Days, там нет вендорского налета и хайпа. В России тоже есть куча ресурсов:
- https://www.meetup.com/DevOps-Moscow-in-Russian/
- http://devopsdeflope.ru
- https://www.2d1o.ru
- http://hangops.ru
Здесь обсуждаются проблемы DevOps — можно прийти, послушать и понять, что в этом нет маркетинга. Люди занимаются DevOps потому, что им это реально надо.
Вопросы-ответы
По нашей практике, техническая часть внедрения DevOps — это четверть работы. Гораздо больше времени занимают именно организационные вопросы, как втянуть людей из компании клиента в этот процесс. В противном случае будет действительно так, что DevOps сбоку припеку стоит, а процесс остался таким, как он был раньше.
Померять на отдельных этапах можно, но если делаются какие-то кусочные изменения, то от этих KPI не очень легко на душе, потому что общий процесс все равно плохой.
Есть два варианта, когда вы двигаетесь в эту сторону:
Например, мы выкатили что-то, нам сразу надо подтянуть данные из мониторинга. Нам прежде всего нужно, чтобы команда, которая этот компонент разрабатывает, дала контекст этого изменения сразу же в этот же чат. Когда мы интегрируемся, выкатываем компонент, у нас последние логи в чатик постятся, все сообщения мониторинга, сообщения системы, туда же написали ребята, что поменялось. Я могу быстро сделать вывод, что не так с моим приложением, либо попросить ребят откатить, либо самому быстро пофиксить и т.д.
Поэтому ChatOps — это одна из неотъемлемых практик именно на этапе интеграции.
— Вы сказали, что был фейл при внедрении практик DevOps. Люди поработали при вас с Chef, а потом вернулись обратно. Какова на вашей практике статистика таких откатов к предыдущим методологиям работы?— До какого-то момента, пока мы этим не занимались, было 50%. Половина откатывалась, потому что мы совсем не рассказывали, как мы это делаем. Кстати, это тоже очень важно для тех, кто занимается DevOps. Если у вас есть фишка, надо ее до людей донести. Мы сами не понимали, что надо все рассказать, в слова облечь, договориться и т.д.
По нашей практике, техническая часть внедрения DevOps — это четверть работы. Гораздо больше времени занимают именно организационные вопросы, как втянуть людей из компании клиента в этот процесс. В противном случае будет действительно так, что DevOps сбоку припеку стоит, а процесс остался таким, как он был раньше.
— Каким образом измеряется эффективность внедрения этих практик?— Единственный параметр — time-to-market. Но дело в том, что если ты меняешь целиком весь процесс, старый KPI теряет смысл. Поэтому мы говорим, что если вас интересует time-to-market, вам есть смысл в это играть, KPI все равно придется переделывать. Но сделать DevOps кусочно — это не реально.
Померять на отдельных этапах можно, но если делаются какие-то кусочные изменения, то от этих KPI не очень легко на душе, потому что общий процесс все равно плохой.
— Интересно из вашей практики, это тактика «все или ничего», или возможно сочетание DevOps со старой каскадной RUP технологией? Если возможно, то что, куда и как сегментируется?— С RUP, конечно, сочетание возможно. Итерационная модель в целом предусмотрена.
Есть два варианта, когда вы двигаетесь в эту сторону:
- У вас менеджмент достаточно зрел и понимает, что надо подготовить почву для того, чтобы можно было производить цифровые продукты. Тогда все нормально уживается вместе, только нужно на основе того, что есть, построить конвейер непрерывной поставки хотя бы в приблизительном виде, чтобы он более-менее автоматически функционировал. Пусть он будет не весь в мониторинге, пусть не будет канареечных деплоев, но нужно, чтобы он был. Людей учат работать с этим и он нормально вписывается в любой процесс, просто надо понимать ограничения в этот момент.
- Если вы уже делаете цифровой продукт, то, скорее всего, Rup процесс будет ограничительным, потому что там очень много ограничений. Тогда эта история совместного уживания будет плачевна. Скорее всего, она просто разрушит Rup процесс сама, потому что бизнес будет говорить: «Давай, давай, быстрей! Быстрей!» — в итоге произойдет саморазрушение. Конечно, лучше, когда происходит осознанное разрушение, если же вы не учитываете этот момент, то оно может так рухнуть, что вся разработка разрушится при этом.
— Есть такая штука ChatOps. Как вы считаете, это неотъемлемая часть или это отдельная вещь, никак не связанная с DevOps?ChatOps — это неотъемлемая часть. Как я уже говорил, взаимодействие разработчиков очень важно, в том числе, договоренность об автотестах. Интеграция отдельных компонент без ChatOps очень сложна.
Например, мы выкатили что-то, нам сразу надо подтянуть данные из мониторинга. Нам прежде всего нужно, чтобы команда, которая этот компонент разрабатывает, дала контекст этого изменения сразу же в этот же чат. Когда мы интегрируемся, выкатываем компонент, у нас последние логи в чатик постятся, все сообщения мониторинга, сообщения системы, туда же написали ребята, что поменялось. Я могу быстро сделать вывод, что не так с моим приложением, либо попросить ребят откатить, либо самому быстро пофиксить и т.д.
Поэтому ChatOps — это одна из неотъемлемых практик именно на этапе интеграции.
Эта статья — расшифровка одного из лучших выступлений на RootConf 2017, конференции по эксплуатации и DevOps в составе фестиваля РИТ++. Следующий фестиваль пройдет в конце мая, и мы уже можем рассказать о некоторых интересных заявках:
- Михаил Кузьмин из JetBrains планирует разобрать множество вопросов, связанных с этим процессом continuous delivery в управлении инфраструктурой.
- Иван Глушков из Postmates предлагает перенести опыт работы с обычными пакетными менеджерами на k8s.
- Вместе с Александром Хаёровым (Ingram Micro Cloud) постараемся восполнить пробелы и поговорим о сетевой магии kubernetes — от пода до ingress.
Посмотрите полный список заявок на RootConf или на весь РИТ++, выбирайте наиболее значимые для себя, а это ссылка на бронирование билетов, цена которых еще будет повышаться.
