Комментарии 140
Глобальная ошибка, присутствующая примерно во всех существующих процессорах. Была бы полной жопой, если бы не высокая сложность практической реализации, из-за которой хакеры на неё забьют.То есть в дальнейшем стоит ждать у журналистов нечто типа «данный зловред не мог быть продуктом вирусописателя-одиночки и значит написан спецслужбой xx»
AMD, похоже, наполовину безопаснее прочих, хотя и непонятно, почему.вангую, что у них какая-нибудь случайно оказавшаяся ошибка с отбросом «не пригодившихся данных» (например — порча какого-нить бита), поэтому он не дает признака нахождения в кеше. И если раньше они грустили (типа «а могли бы работать на полтора процента быстрее»), то теперь радуются по этому поводу.
Буду рад, если автор статьи меня поправит.
В живую бы эту атаку пощупать.
gist.github.com/ErikAugust/724d4a969fb2c6ae1bbd7b2a9e3d4bb6
olartamonov это оно?
Оно же с комментарием: github.com/Eugnis/spectre-attack
если бы не высокая сложность практической реализации,
Думаю для направленных атак банков, крупных компаний и прочее могут и сделать троян или еще что.
Главное чтобы на основании этих уязвимостей не нашли чего похлеще…
У кого горит CVE-2017-5715, aka #Spectre branch target injection.
Есть unstable microcode от Intel, можно пробовать лечиться и баловаться.
Changelog:
2018-01-04 — Henrique de Moraes Holschuh hmh@debian.org
intel-microcode (3.20171215.1) unstable; urgency=high
- Add supplementary-ucode-CVE-2017-5715.d/: (closes: #886367)
New upstream microcodes to partially address CVE-2017-5715 - Updated Microcodes:
sig 0x000306c3, pf_mask 0x32, 2017-11-20, rev 0x0023, size 23552
sig 0x000306d4, pf_mask 0xc0, 2017-11-17, rev 0x0028, size 18432
sig 0x000306f2, pf_mask 0x6f, 2017-11-17, rev 0x003b, size 33792
sig 0x00040651, pf_mask 0x72, 2017-11-20, rev 0x0021, size 22528
sig 0x000406e3, pf_mask 0xc0, 2017-11-16, rev 0x00c2, size 99328
sig 0x000406f1, pf_mask 0xef, 2017-11-18, rev 0xb000025, size 27648
sig 0x00050654, pf_mask 0xb7, 2017-11-21, rev 0x200003a, size 27648
sig 0x000506c9, pf_mask 0x03, 2017-11-22, rev 0x002e, size 16384
sig 0x000806e9, pf_mask 0xc0, 2017-12-03, rev 0x007c, size 98304
sig 0x000906e9, pf_mask 0x2a, 2017-12-03, rev 0x007c, size 98304 - Implements IBRS and IBPB support via new MSR (Spectre variant 2
mitigation, indirect branches). Support is exposed through cpuid(7).EDX. - LFENCE terminates all previous instructions (Spectre variant 2
mitigation, conditional branches).
https://debian.pkgs.org/sid/debian-nonfree-amd64/intel-microcode_3.20171215.1_amd64.deb.html
https://newsroom.intel.com/wp-content/uploads/sites/11/2018/01/Intel-Analysis-of-Speculative-Execution-Side-Channels.pdf
3.2 Branch Target Injection Mitigation
This mitigation strategy requires both updated system software as well as a microcode update to be loaded to support the new interface for many existing processors.
In particular, the capabilities are:
Indirect Branch Restricted Speculation (IBRS): Restricts speculation of indirect branches.
Single Thread Indirect Branch Predictors (STIBP): Prevents indirect branch predictions from
being controlled by the sibling Hyperthread.
Indirect Branch Predictor Barrier (IBPB): Ensures that earlier code’s behavior does not control
later indirect branch predictions.
(в статье не упоминали, что lfence требует каких-либо обновлений микрокода, называя метод "mitigation strategy is focused on software modifications.")
https://access.redhat.com/articles/3311301 — правки ядра (еще не принято в github.com/torvalds/linux), после которых появляются /sys/kernel/debug/x86/pti_enabled, /sys/kernel/debug/x86/ibpb_enabled, /sys/kernel/debug/x86/ibrs_enabled
Упоминания о LFENCE в Changelog не моего авторства, поэтому пока могу только предполагать.
Тем не менее, стоит обратить внимание, что LFENCE в Changelog упоминается в контексте "Spectre variant #2". Тогда как в публикации Intel в контексте "Bounds Check Bypass Mitigation", т.е. "Spectre variant #1".
Поэтому напрашивается предположения:
- либо в Changelog очепятка (2 вместо 1) и на разных моделях было отличие в поведении
LFENCE, которое исправлено в этом микрокоде; - либо поведение
LFENCEвсё-таки имеет какой-то эффект на "Spectre variant #2", но в публикации Intel это упустили в спешке.
P.S. А как микрокоды из deb-файла извлечь?
Так-то и я укрепился в симпатии к райзенам)
Напомню, что ещё одним условием было отсутствие других участвующих в процессе переменных в кэше
Вот этот момент не совсем понятен. Речь о переменных, которые проверяются в условии if (как array_size), или о чем-то еще?
ну так, диванная теория, основанная на комментариях к toy example с gist'a
ps скорее всего — это глупость
Это такой себе side-channel инжениринг.
У AMD уже давно кеши больше чем Intel, при этом в производительности на ватт они проигрывают, это показывает серверный сегмент, где считается каждая копейка. Первым делом напрашивается ответ, что это из-за маркетинга «игра в бизнес сегменте проиграна, а пользователям — главное цифры в даташите». Но производство процессоров — вещь недешевая, и если уже, даже ради маркетинга, в процессоре добавлен лишний кеш, — его грех не задействовать. Массив — это указатель на указатели, и в принципе, вытягивание значения из кеша, это операция, которую тоже можно распараллелить, И коль у нас много кеша, то мы можем без потери ресурсов грузить избыточную информацию в кеш, не обязательно первого уровня. Предсказатель встречая выгрузку из массива может жестко загружать весь массив в кеш верхнего уровня, с доставкой нужного значения в кеш первого уровня — это может съекономить такты в будущем, поскольку работа с массивами в большинстве случаев производится в цикле с одним массивом, а лишнего кеша у нас дофига.
Ну и еще пару моментов есть, которые меня подталкивают к этой теории, но как я уже объяснил, все это на грани интуиции и информации из тестов toy example.
Для проверки, я бы попробовал все ри уязвимости, но с более структурами данных чем массивы, мне знаний C и ассемблера на хватит, а более высокоуровневые языки могут все поломать.
Довод против: CPU не знает размер массива.
Не обязательно грузить весь массив, достаточно заполнять 16 линий и атакующий сможет узнать из байта только ниббл.
- Фактически вы просто предлагаете увеличить линию кэша в 16 раз.
1.1. Чего это будет стОить? (Увеличится требуемый объём кэша — точно проц станет допоже; увеличится поток данных из DRAM — возможно, проц станет медленней). - Увеличиваем в 16 раз размер элемента массива — и по прежнему узнаём весь байт.
- Допустим, мы можем за раз узнать только нибл. Вот проблема-то — атака замедлилась в два раза.
Но вот если добавить поддержку в компилятор (дать CPU hint — размер массива) — загрузка в кэш всего массива может оказаться выгодной...
Как мы помним, Meltdown не работает на процессорах, вовремя — до окончания выполнения — проверяющих условия доступа процесса к чужой памяти даже в случае спекулятивного выполнения.Там где-то опечатка или ошибка в тексте, но не соображу, где именно.
www.reddit.com/r/windows/comments/7oap39/patch_windows_7_kb4056894
answers.microsoft.com/en-us/windows/forum/windows_7-update/stop-0x000000c4-after-installing-kb4056894-2018-01/f09a8be3-5313-40bb-9cef-727fcdd4cd56?auth=1
Видимо чтобы подгорало не только у обладателей процессоров intel.
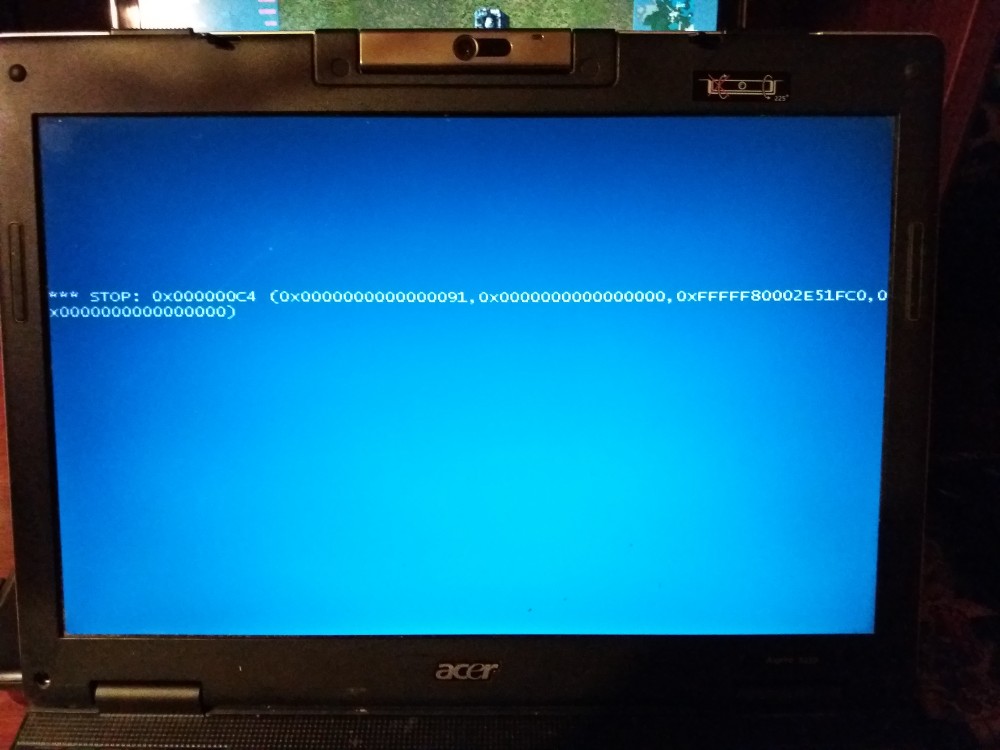
Автоматически система не смогла восстановить свою загрузку. Вручную удалось откатить на точку восстановления, которая создалась перед установкой обновления. Потом запретил установку обновления KB4056894.
Важным моментом в атаке, кстати, является пункт «медленно и печально» — если array1_size лежит готовый где-то в кэше, процессор может не заморачиваться со спекулятивным вычислением, а просто быстро посчитать условие. Поэтому array1_size должен быть в ОЗУ, откуда его придётся долго доставать.
Только что проверял у себя на AMD. Видел инвалидацию кеша в примере из статьи — не понимал зачем она там нужна. Сам запускал не пример, а свою реализацию, там размер массива был вообще не в переменной а захардкожен. Аналог переменной x гарантировано был в кеше т.к. её только недавно записали. Всё работало.
На другом проце (тоже AMD) — не работало. Сейчас прочёл эту статью, дописал переменную с размером массива и её инвалидацию — заработало. Так что это не жёсткое требование, где-то работает, где-то нет.
Что особенно цинично, базовую возможность проведения атаки нам обеспечила проверка индекса массива, необходимая для обеспечения безопасности кода.
Нет, если бы там не было этой проверки, то её не пришлось бы взламывать, а программа бы неспекулятивно сделала тоже самое что тут получается только спекулятивно.
На Linux с включённым BPF
Про FreeBSD тоже было.
А как насчет других BSD?
ЗЫ. Ну хоть майнить на них вариант остаётся :)
всё очень хрупко, что и позволяет, приняв рюмку коньяка, забить.
… а вполне конкретная дырка, как минимум в Chrome.
Говоря русским языком, позволяет все нужные нам структуры создать своими руками и при этом сразу внутри атакуемого процесса.
Другое дело, что таких мало, я в пользовательском окружении сходу кроме браузера с JS ничего и не назову. В серверном — вон, ядро линукса или BSD с BPF. То есть в общем величина дырки имеет более-менее разумный размер, позволяющий её закрыть.
Другое дело, что таких мало, я в пользовательском окружении сходу кроме браузера с JS ничего и не назову.А приложение на смартфоне с уязвимым arm может заглянуть дальше песочницы?
В ART (Android 5.0 и новее) — почти наверняка не может, там приложение при установке компилируется в нативный код, а не в байткод для выполнения в виртуалке, соответственно, методы изоляции должны быть такие же, как для обычного приложения. А через них Spectre ходить не умеет, если заранее не найдёт снаружи готовый подходящий код, на выполнение которого сможет повлиять.
Но тут может быть интересный вопрос по поводу того какая часть ядра и/или критичных андроидных сервисов действительно находится за пределами маппинга памяти, а какая просто защищена доступом (а значит потенциально уязвима для Meltdown). Потому что все процессы являются форками «зиготы», которая много фреймворков содержит. Это неплохо для производительности, но сколько интересного в действительности попадает в адресное пространство процесса… Тут сложно сказать
Т.е. каждое приложение запускается под своим «пользователем», что и обеспечивает песочницу
Нет, если у нас есть какая-то виртуальная машина, в которой крутится нескомпилированный код, то этот код будет работать в адресном пространстве и с привилегиями виртуальной машины, как JS в браузерах или BPF в ядрах, а значит, может использовать Spectre напрямую. От того, чтобы он куда не положено не лазил, его сама VM и ограничивает. И «пользователи» — это высокоуровневая сущность VM, к разделению на уровне процессов она не имеет отношения; с точки зрения CPU тут процесс один — сама VM.
А вот ART один раз собирает готовый нативный бинарник, который уже можно выплюнуть в отдельный самостоятельный процесс.
а значит потенциально уязвима для Meltdown
Meltdown на ARM есть только на самых свежих ядрах.
Основная масса неподдерживаемого барахла на рынке — либо на ядрах, умеющих только Spectre, либо не умеющих вообще ничего.
Нет, если у нас есть какая-то виртуальная машина, в которой крутится нескомпилированный код, то этот код будет работать в адресном пространстве и с привилегиями виртуальной машины, как JS в браузерах ...
Я как раз говорю о том, что каждое приложение в Андроиде (даже до ART) это отдельный процесс под отдельным пользователем (UID связан с приложением) с точки зрения Линукса, который его крутит. Именно так гарантируется песочница (в другой каталог файл не запишешь/не прочитаешь, потому что у процесса, который твою VM крутит нет правов кроме как на запись в свои каталоги, ядро ограничивает ресурсы «на пользователя» и прочее).
Естественно, если не рутить телефон, но это отдельная тема.
Но в каждой этой копии VM есть куча шареной памяти от изначальной зиготы (которая содержит кучу фреймворков). И в каждом телефоне ХЗ чего интересного в этой памяти можно найти, если суметь до нее добраться.
И тут уже интереснее можно ли использовать Spectre и/или Meltdown.
Хотя, очевидно, это все пока что из области ковыряния в носу — реальный хак на этом сделать навряд ли выйдет в обозримое будущее…
Расшаренная память (библиотеки, сам форк и т.п.) никак не поможет, на Spectre нельзя через общую библиотеку перебраться из одного процесса в другой. Любое изменение в этой памяти со стороны процесса вызовет copy-on-write и будет видно только самому процессу.
Meltdown при этом будет работать совершенно спокойно, но Meltdown подвержены только три ядра — A15, A57, A72. На этих ядрах массовость имели самсунговские Galaxy Note и Galaxy S (Exynos), потом MTK Helio X20, потом Snapdragon 650/652/653.
Самсунг с большой вероятностью выпустит патчи, если ещё нет. На Снапдрагоне смартфонов не так много, на MTK на глазок побольше, но это всё уже тонет в массе бюджетных моделей, которые выгоднее делать на сборках дешёвых ядер, без всякого этого вашего big.LITTLE. Так что, если Самсунг из списка вычеркнуть, для атакующих становится уже не особо интересно.
Причина там та же, но их «Variant 3a» позволяет читать не память, а лишь отдельные системные регистры, de jure недоступные непривилегированному процессу.
Тоже неприятно, но не смертельно.
Т.е. да, куча народу прочитала статью. Сколько из них пошло и отключило у себя SharedArrayBuffer?
Примерно ни один.
Но это локальная проблема, она будет устранена до конца января — как раз с обновлением браузеров проблем никаких нет, они это сами делают.
Да и лично мне от ощущения, что у меня в браузере есть дырка, которая будет там еще пару недель, как-то не по себе.
Security: Chrome provides high-res timers which allow cache side channel attacks
Reported by mseaborn@chromium.org, Jul 8 2015
и там же
Jul 15 2015, I have a PoC of the «Spy in the Sandbox» attack that works based on Shared Array Buffers instead of via high-resolution timing.
Конкретную проблему в конретном Chrome зарепортили два года назад. Но PoC на то время позволял всего лишь следить за движениями мышки вне браузера и обнаруживать сетевую активность. Сейчас появился PoC который позволяет через нее читать память процесса, и только после этого производители бразуеров зашевелились и выпустили «патч». Точнее, выпустят через две недели. В виде отключения Shared Array Buffers. В остальных приложениях никто ничего проверять и закрывать не собирается.
stackoverflow.com/questions/11227809/why-is-it-faster-to-process-a-sorted-array-than-an-unsorted-array
Я не совсем понял, проясните пожалуйста. В статье написано, что при замере времени доступа к каждому элементу массива можно понять, получен ли элемент из кэша, либо вытянут из RAM. Узнать, это одно, а получить данные из кэша от другого процесса — не одно и то же. Правильно ли я понимаю, что при доступе к элементу массива в атакующем процессе он будет в итоге содержать данные из кэша от другого процесса?
Однако можно понять, закэшировано ли значение, хранящееся в памяти по определённому адресу, или нет.
Поэтому изобретаются всякие косвенные методы передачи нужного значения через кэш, наиболее понятный из которых — проведение атаки так, чтобы интересующее нас значение в момент атаки подставилось в индекс какого-либо массива, который мы можем дальше перебрать легальным образом. При этом нас даже не волнует, в каком виде мы получим собственно значения этого массива, нам достаточно, что на нужном индексе мы увидим более быстрый возврат из него (он закэширован в ходе атаки), а этот индекс и есть искомая величина.
Meltdown работает именно так. В Spectre есть сложности, связанные с тем, что всю эту схему надо организовать внутри атакуемого процесса, поэтому там могут и более сложные схемы косвенного анализа кэша применяться.
Надеюсь что с новогодними подарками, будет как с продолжением Half — Life (третьей части не будет).
Я не знаю, реализуемо ли это путём нового микрокода, или необходимы аппаратные модификации.
Если сделать так, что закэшированные одним процессом данные не смогут быть доступны другому (ввести в кэш аналог PCID), то это очень сильно ударит по производительности.
Собственно, на производительность это никак не повлияет, поскольку переключение между режимами происходят не слишком часто
Да, примерно каждые две-три миллисекунды на средне нагруженной системе.
На сколько у вас там предполагается обрушить производительность обнулением кэша каждые 2 мс, процентов на сорок?
можно все порешать поместив все
В смысле, исправить приложение? Каждое? Классное решение, ага.
Если коротко, то — начнем с этого — само по себе оседание значения в кеше и неочистка его после «отката» — само по себе это не уязвимость?..
А вот возможность целенаправленно осадить в кэше значение из закрытой для данного процесса памяти — значительная. Не должно быть у процесса доступа к чужой памяти, ни в каком виде, ни в явном, ни в неявном.
Просто есть ощущение, что Meltdown — это «Spectre, который проявляется не только в данном процессе, но и в памяти ядра». Я не прав?
Ну правда, у меня ощущение, что есть «основная уязвимость», которая позволяет проанализировать память. Происходит это благодаря механизмам: спекулятивного выполнения, косвенной адресации и измерения таймингов. Для атаки необходимо вынудить нужный процесс сделать нужные действия. Это «как бы Spectre».
А есть вторая уязвимость («как бы Meltdown»), которая позволяет применить этот процесс прямо, из атакующего процесса, т.к. вторая уязвимость — это первая, но косвенная адресация может произойти и в память другого процесса.
Где я не прав? Это не копательство в терминологии, я пытаюсь понять, где я не прав. Спасибо!
Meltdown достаточно легко устраняется в железе, как устранить первый вариант Spectre, не обрушая производительность процессора, вообще не очень понятно.
Ну если бы все, что обнаружилось в Spectre, было бы строго неверно (т.е. НЕ работало), то Meltdown был бы возможен?
Единственное критичное для него условие, помимо наличия спекулятивного выполнения — это запоздалая генерация процессором исключения, в результате чего при спекулятивном выполении не ограничиваются права доступа к памяти.
Прочие меры относятся к «а давайте уберём из процессора кэш» или «а давайте выключим спекулятивное выполнение», это из того же разряда, что и «а давайте лечить головную боль гильотиной».
Прочие меры относятся к «а давайте уберём из процессора кэш» или «а давайте выключим спекулятивное выполнение», это из того же разряда, что и «а давайте лечить головную боль гильотиной».
Да, именно такое ощущение у меня и сложилось. Что основное даже не в спекулятивном выполнении, а в связке
- оседание в кеше (не важно, из-за чего),
- косвенная адресация (!),
- возможность (прямого или косвенного) измерения таймингов косвенной адресации
Но, видимо, этих трех вещей недостаточно, и тут я, наверное, и не понимаю…
1) Meltdown: проверка прав доступа после выполнения спекулятивной инструкции. Достаточно легко устраняется в железе процессора.
2) Spectre №1: тренировка предсказателя ветвлений, позволяющая одному процессу влиять на другой. Устранить без потери эффективности очень сложно.
3) Spectre №2: тренировка предсказателя переходов, позволяющая одному процессу влиять на другой. Устранить с несущественной потерей эффективности можно.
Вы не можете отключить спекулятивное выполнение от кэша, оно в этом случае просто потеряет смысл. Разве что сделать для него свой кэш, который будет синхронизироваться с основным.
Но
Оседание в кэше — не причина, а следствие их [уязвимостей]., и без Spectre/Meltdown вышеуказанное не легко/невозможно.
А причина головной боли — наличие головы.
Не надо ложных аналогий.
Вы не можете отключить спекулятивное выполнение от кэша, оно в этом случае просто потеряет смысл.
И? это как-то опровергает то что я написал выше? Да, нельзя отключить, а это значит что базовая суть уязвимости принципиально неисправима в данной архитектуре. Можно только затыкать её частные дыро-проявления.
Разве что сделать для него свой кэш, который будет синхронизироваться с основным.
Интересная идея, но не поможет. Во-первых, у меня есть подозрение что заметная часть кеша заполняется именно спекулятивными операциями (и без этого эффективность кеша резко упадёт), а, во-вторых, читать задержки можно тоже спекулятивно, хоть и чуть сложнее, таким образом получив доступ и к спекулятивному кешу.
Суть всех этих технологий в том что бы максимально ускорить выполнение операций. А ускорение всегда может быть измерено, как бы вы ни старались этого избежать. Нельзя убрать измеряемый эффект ускорения, не убрав само ускорение (то есть не обесценив то, ради чего изначально затевался и кеш и спекулятивные исполнения).
А насколько сложно было бы просто чистить кэш от следов "несыгравшего" спекулятивного выполнения?
2) Spectre №1: тренировка предсказателя ветвлений
3) Spectre №2: тренировка предсказателя переходов
Непонятно. Я думал, «предсказатель ветвлений» и «предсказатель переходов» — одно и то же. А здесь подразумевается, что это разные механизмы?
Вот это непонятно, ну да в другой программе что-то закэшировано и будет выполняется быстрее.
А как мы измерим время работы другой программы с точностью необходимой для отличия незакэшированных данных от кэешированный?
Ведь явно даже программа предоставляющая COM/dbus интерфейс не подходит так как там «оверхед» в виде инструкций работающих с памятью там присутсвует.
В остальных случаях могут подойти более изощрённые способы атаки, их есть ещё несколько, помимо попыток найти читающийся напрямую массив.
Спасибо большое за подробное объяснение. Как заставиить атакуемое приложение положить нужные данные в кэш — совсем все понятно. Но хуже всего у атакующего, как я понял с чтением из кэша. Все сводится к угадыванию значения, причем маркером того что угадал правильно является время отклика. Поправьте меня пожалуйста если я не прав.
Собственно вопроса 2:
- каким образом злоумышленник анализирует время с нужной точностью и не влияя на исследуемый процесс.
- Как убедиться что в кэше есть только нужное значение и ничего больше (про очищение кэша понятно, но ведь в это время в него пишут сотни запущенных и продолжающих работать процессов, + само атакуемое приложение может писать много чего)
2. Маловероятно, что кто-то будет случайно в то же время — а оно очень небольшое, это доли микросекунды — читать тот же или близкий участок памяти. На практике error rate получается 0,02-0,03 % на сканировании десятков мегабайт памяти на живой системе.
Т.е. open-source получает преимущество)
В общем эта атака видиться на вполне конкретные важные цели, а не на обычного массового пользователя и ее нельзя использовать в ботнетах.
Вопрос вот о чем, поидее java-байткод компилируется каждый раз при запуске кода (да, есть возможности оптимизации, но по-умолчанию машиннозависимый код не храниться между запусками программы), и вроде как предсказать адреса памяти невозможно (в том смысле что непонятно как)
Я запустил Java-машину, ей ОС для работы выделила кусок свободной памяти.
Поидее предсказать заранее какой диапазон адресов достанется программе как минимум трудно.
Далее Java-машина забрала байткод и стала генерировать платформозависимые инструкции, которые уже привязываются к реальным адресам памяти.
Да, если считать адреса переменных в памяти относительно начала выделенной Java-машине области то вероятно получится +- одни и те же адреса, но ведь для того чтобы украсть из них данные с помощью Spectre нужно знать абсолютный адрес. Или нет?
Не понимаю как решается вопрос вычисления в такой ситуации точного адреса переменной при неизвестном адресе начала выделенной Java-машине памяти.
Новогодние подарки, часть вторая: Spectre