Начав выбирать себе цвет для покраски стены в комнате, я столкнулся с интересной вещью. Весь этот процесс с самого начала начал напоминать работу над каким-нибудь IT-ML-Blah-blah-blah-аналитическим проектом.
Тут есть и заказчик, который не очень понимает, что именно он хочет, но хочет, чтобы все было хорошо и ему нравилось. Еще есть несколько заинтересованных лиц со стороны заказчика, которые не могут договориться по вопросу, что такое «хорошо». Есть какие-то переформулировки задачи, которые под большим вопросом релевантны этому самому «хорошо», но по-крайней мере как-то решаемы. Есть подбор методов решения и попытки их реализовывать. Есть итеративность, которая имплицитно, но монотонно, ведет к какому-то решению, которое бы всех устроило. И есть некоторые странные выводы, которые бы с трудом можно было бы сделать в «реальном» проекте, потому что из-за общей нервозности и участия в процессе денег фокус внимания редко останавливается на этих местах процесса.

В общем, если посмотреть на выбор цвета в комнате, как на аналитический процесс, может получиться интересно.
Есть вещи более отвратительные и раздражающие, чем выбор несколькими людьми цвета, в который покрасить стену в комнате, но их немного. Чаще всего они связаны с какими-нибудь болезнями или травмами.
Методичный просмотр цветов вызывает море ассоциаций с больницами, супермаркетами, госучреждениями, советскими кухнями в коммунальных квартирах и общественными туалетами. А если у тебя не вызывает, то у собеседника точно вот именно такого цвета была стена в школьном коридоре, где собеседник провел худшие годы жизни. Раздражение имеет тенденцию нарастать, а решение не приниматься.
Таким образом встает Задача. Критерии качества решения этой задачи таковы:
KPI: Степень удовлетворения всех заинтересованных лиц от цвета стены в комнате. Позитивный KPI напрямую недостижим до покраски как таковой(но 10 раз перекрашивать не хочется), поэтому приходится использовать что-то еще.
Реалистичный KPI: Степень удовлетворения всех заинтересованных лиц от выбора цвета для покраски стены (стоит отметить сразу, что удовлетворяющий всех выбор цвета не гарантирует удовлетворенность от этого цвета на стене, но выбора особо нет. Решения надо принимать в условиях, когда результат решений еще неизвестен)
Входные данные:
Ну и тут начинается процесс, знакомый любому человеку, реализующему корпоративные проекты.
Смотреть на цвета и ясно видеть, как будет это смотреться на стене, могут в основном только люди с художественным образованием. Но они не мы. Надо придумать как соотносить цвета со стенами, чтобы решение принималось быстрее и как-то более обосновано. И paint.net наше спасение. Можно панорамно сфотографировать комнату, стереть стены с фото и потом их чем-нибудь закрашивать. Может это поможет принять решение, которое всем подойдет? В нашем случае все началось с такого:
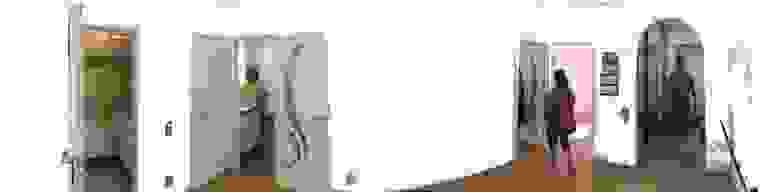
Вот она комната с плохо стертыми стенами. Теперь можно стены закрашивать во что угодно и смотреть, нравится нам это или нет. Например, сделать что-то такое:

И вроде прекрасно.
Но нет!
Мир розовых пони с вырванными глазами это не про нас. Обсуждение заинтересованных лиц по вопросу выбора цвета при наложении его на фото тоже быстро заходит в тупик. Пара часов возни с пейнтом и никакого консенсуса. Однако! У нас появился некоторый инструмент. Им можно воспользоваться. Если у нас не выходит, может есть люди, которые смогут это сделать за нас?
Экспертами были призваны все желающие подписчики ВК. Ставка была на то, что год 2018 на дворе, а все равно у нас страна советов. Всем только дай начать советовать.
Для вышеприведенного шедевра фотоискусства был сделан «сайт», который содержал фотографию комнаты и color picker который позволял менять цвет стен. Ссылка на сайт была выложена в ВК с просьбой помочь с выбором цвета.
Эксперты высказали ряд мнений, поделились своими вариантами. Увы, к консенсусу это не привело, но вызвало ряд смещений эстетических приоритетов у заинтересованных лиц. И эти смещения в дальнейшем позволили к консенсусу прийти.
Проблем у экспертов было две.
Вместе обе проблемы не давали возможности принятия решения.
Но сама формулировка проблемы экспертного мнения дала ключ к следующей итерации.
Надо иметь МНОГО оценок. Если их много, и все голоса за что-то конкретное, с этим проще смириться. Но как это сделать?
Например, сделать небольшое desktop приложение, которое бы применяло к картинке случайные варианты гаммы, а заинтересованные люди бы оценивали эти варианты от 0 до 10. Таким образом набралось более 300 разных оценок цветов в формате:
Теперь у нас появилась выборка с оценками, хотя не очень удобная для анализа. Можно переформулировать, что V от 0 до 10, это на самом деле не оценка цвета, а количество людей, которые проголосовали за этот вариант. И превратить 4-х мерный вектор в V 3-х мерных
в V 3-х мерных  . Нули, естественно, пропадают. И каждый вектор теперь является равноправным голосом за соответствующий оттенок. Удобно добавлять при этом к значениям RGB случайных небольших смещений, чтобы не получалась куча совсем уж одинаковых оттенков.
. Нули, естественно, пропадают. И каждый вектор теперь является равноправным голосом за соответствующий оттенок. Удобно добавлять при этом к значениям RGB случайных небольших смещений, чтобы не получалась куча совсем уж одинаковых оттенков.
В такой формулировке получается типичная формулировка задачи поиска максимума плотности многомерного распределения. Т.е. мы ищем такую область, в которой люди бы «голосовали» чаще всего.
Если нам хочется усилить влияние высоких оценок, мы можем брать V² при преобразовании 4-d в 3-d. Тогда, оценка 2 превращается 4 голоса, а оценка 4 в 16 голосов. Таким образом мы сможем уменьшить влияние тех цветов за которые голосовали, но не прям сильно.
Самые две простые вещи, которые приходят в голову, это что, наверное, можно приблизить полученное распределение многомерным нормальным распределением или квадратичной функцией в 3-d (что-то такое куполообразное с выраженным максимумом). Не то, чтобы все там и правда красиво описывалось такими простыми функциями, но в данном случае точно можно было немного закрыть на это глаза.
Для приближения многомерным нормальным, требуется всего лишь прикинуть по данным ковариационную матрицу и матожидания для всех маргинальных распределений. После этого можно аналитически посчитать максимум, но гораздо проще (для мозга) просто пройтись по всем возможным сочетаниям цветов с каким-то шагом, подставляя в формулу распределения параметры распределения и значения цветов. Потом взять максимальную точку.

Приближение многомерным нормальным и поиск его максимума дал неплохой сине-фиолетовый цвет нужной степени матовости:

Приближать квадратом еще проще.
Для этого в матлабе задалась функция вида для всех возможных вариаций :
:
 и методом имитации отжига минимизировалась квадратичная ошибка значения плотности точек в окрестности:
и методом имитации отжига минимизировалась квадратичная ошибка значения плотности точек в окрестности:

После настройки коэффициентов полинома, максимум считался с помощью вычисления производной от функции с помощью symbolic toolbox и далее корней от производной. Корней получалось несколько, но под параметры ограничений на значения цветов подходил один.
с помощью symbolic toolbox и далее корней от производной. Корней получалось несколько, но под параметры ограничений на значения цветов подходил один.
Приближение квадратичной функцией и поиск ее экстремума дал схожий вариант с нормальным распределением. Немного более синий и менее красный:

Но иногда можно не думать о приближениях и просто написать нейросеть, которой все данные скормить. Говорить о параметрах нейросети смысла нет особо, но было много вариантов, много архитектур и несколько разных извращений над переменными. В итоге, получилось вытащить достаточно устойчивое ее мнение относительно лучшего цвета. Предыдущие оценки «хорошести» цветов сеть устроили почти во всем, кроме зеленого. Зеленого она щедро добавила.

Кстати, если переформулировать плотности как классы, например выискивая какие-то значения больше 5, и использовать Gradient Boosting Classifier, чтобы находить области пространства, где наиболее плотны положительные оценки, получалось примерно тоже.
И тут снова проявилась проблема, которая достаточно часто проявляется в реальных проектах при презентации так называемых «промежуточных результатов». Она звучит так:
Это оно, конечно, все очень хорошо: нейросети, распределения, но почему-то хочется не этого… Хочется, чтобы как бы, хорошо.
Очень интересен тут тот момент, что то, что оценивается красивым на фотографии, не обязательно то, что ты хочешь иметь у себя на стене, если оцениваешь еще раз более внимательно!
Так и в реальных проектах какие-то показатели, опора на которые раньше казалась объективной и конструктивной, внезапно как-то приунывают при получении результата по ним (даже если, в общем, по числам выходит неплохо). И тут остается одно. Найти все хорошее, что у нас получилось и презентовать какими-нибудь красивыми картинками, чтобы всех все устроило.
Давайте как-нибудь красиво нарисуем, как голосовалось за цвета? Например, сделаем 3-d scatter plot в матлабе для HSV(255,255,255), где места, за которые голосовали, будут изображаться шариками нужного цвета. Чем больше шарик, тем больше голосовали. В нашем случае это выглядело так:
Простите, что не привел HSV к 360/100/100, было лень, а в матлабе все от 0 до 1.
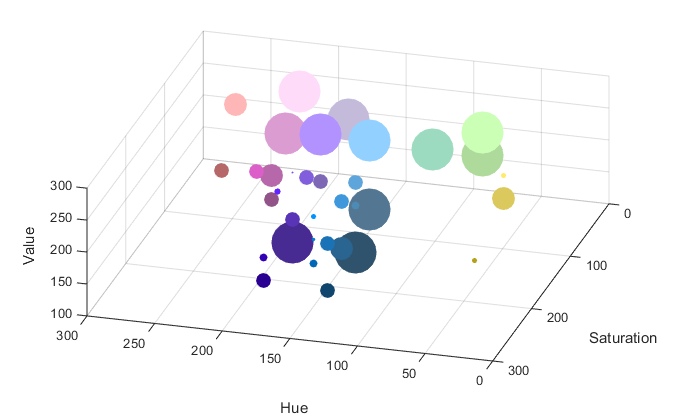
Чем больше шарик, тем больше цвет нравится
Из проекций этого графика, в том числе, становится очевидно, почему разные методы давали те результаты, что давали. Например:

Проекция Цветность/Оттенок
Из проекции Цветность/Оттенок видно, что, если строить гауссиан или приближать квадратичной функцией, максимум будет где-то между синим и фиолетовым. При этом максимум цветности будет в районе 100 и очень яркие цвета не выбираются. А нейросеть у которой пространство будет достаточно сложным с большим количеством локальных экстремумов, имеет возможность учесть и зеленую часть. Видимо там же где-то был и розоватый пик, но чуть ниже, поэтому в конечный результат не попал. И т.д.
Разглядывание визуализации показало 3 заметных псевдо-кластера.

Усредняющие способности всех грубых методов радостно сливали светло-синие и темно-синие в один средне-синий результат. При этом логика подсказала, что красить помещение в темные цвета не стоит(пусть даже они ничо на фото смотрятся), поэтому этот кластер надо отбросить. А зеленый просто никому особо не нравился, потому что вызывал всякие больнично-коммунальные ассоциации при долгом разглядывании. Зачем на тут вообще какая-то математика, ага?
В оставшемся кластере просто надо было взять условное среднее и допилить как-то руками.

На этом все заинтересованные лица согласились, что, в общем, это компромисс, на котором стоит остановиться.
Еще через пару недель реальность не слишком исказила ожидания (хотя была несколько розовее, чем реальности предполагается бывать)…

Сам по себе такой розоватый цвет, конечно, вещь вызывающая сомнения, но мы сами этого хотели. Теперь осталось только купить мебель подходящего цвета. Хм. А не стоит ли подумать об автоматической оптимальной расстановке мебели в комнате? Это типичная задача выпуклой оптимизации…
Находясь одновременно со стороны заказчика и исполнителя, я с удивлением наблюдал, как сам с собой не могу найти понимания по вопросу, в решении которого я с обеих сторон был, вроде как, заинтересован. Так же, с удивлением увидел, как те вещи, которые я полагал объективными и напрямую выводимыми из данных, которые удовлетворяют меня как исполнителя, могут меня же самого не удовлетворять как заказчика.
Безумия тут добавляет то, что я сам составлял данные, напрямую указывая в них, что именно потенциально меня может удовлетворить. И видимо, полностью адекватно составить я их не мог, по каким-то причинам, которые мне самому не слишком ясны. Например, я ставил высокие оценки темным цветам, хотя они явно не имели возможности быть выбраны в конечном итоге. Почему? Потому что на картинке это было мило. Настоящая задача же была совсем другая, но выбирать цвет из более сложных соображений на автомате было не реалистично.
В конечном итоге, в тех данных, которые я сгенерировал, было скрыто решение. Но как было сразу прийти решению, без этих странных танцев с бубном, которые подправляли мое собственное представление о том, что мне надо(или уж совсем точно не нужно), не очень ясно. Я смотрел на визуализацию с шариками и до того, как взялся за поиск максимума разными методами. Но «кластеры» увидел на ней только после.
Тут есть и заказчик, который не очень понимает, что именно он хочет, но хочет, чтобы все было хорошо и ему нравилось. Еще есть несколько заинтересованных лиц со стороны заказчика, которые не могут договориться по вопросу, что такое «хорошо». Есть какие-то переформулировки задачи, которые под большим вопросом релевантны этому самому «хорошо», но по-крайней мере как-то решаемы. Есть подбор методов решения и попытки их реализовывать. Есть итеративность, которая имплицитно, но монотонно, ведет к какому-то решению, которое бы всех устроило. И есть некоторые странные выводы, которые бы с трудом можно было бы сделать в «реальном» проекте, потому что из-за общей нервозности и участия в процессе денег фокус внимания редко останавливается на этих местах процесса.

В общем, если посмотреть на выбор цвета в комнате, как на аналитический процесс, может получиться интересно.
Постановка задачи
Есть вещи более отвратительные и раздражающие, чем выбор несколькими людьми цвета, в который покрасить стену в комнате, но их немного. Чаще всего они связаны с какими-нибудь болезнями или травмами.
Методичный просмотр цветов вызывает море ассоциаций с больницами, супермаркетами, госучреждениями, советскими кухнями в коммунальных квартирах и общественными туалетами. А если у тебя не вызывает, то у собеседника точно вот именно такого цвета была стена в школьном коридоре, где собеседник провел худшие годы жизни. Раздражение имеет тенденцию нарастать, а решение не приниматься.
Таким образом встает Задача. Критерии качества решения этой задачи таковы:
KPI: Степень удовлетворения всех заинтересованных лиц от цвета стены в комнате. Позитивный KPI напрямую недостижим до покраски как таковой(но 10 раз перекрашивать не хочется), поэтому приходится использовать что-то еще.
Реалистичный KPI: Степень удовлетворения всех заинтересованных лиц от выбора цвета для покраски стены (стоит отметить сразу, что удовлетворяющий всех выбор цвета не гарантирует удовлетворенность от этого цвета на стене, но выбора особо нет. Решения надо принимать в условиях, когда результат решений еще неизвестен)
Входные данные:
- Комната
- RGB палитра
- Заинтересованные лица, которые выбирают цвет для комнаты
Ну и тут начинается процесс, знакомый любому человеку, реализующему корпоративные проекты.
А я тут не пальцем делан, я как сейчас что-нибудь умное-математическое придумаю!
Смотреть на цвета и ясно видеть, как будет это смотреться на стене, могут в основном только люди с художественным образованием. Но они не мы. Надо придумать как соотносить цвета со стенами, чтобы решение принималось быстрее и как-то более обосновано. И paint.net наше спасение. Можно панорамно сфотографировать комнату, стереть стены с фото и потом их чем-нибудь закрашивать. Может это поможет принять решение, которое всем подойдет? В нашем случае все началось с такого:

Вот она комната с плохо стертыми стенами. Теперь можно стены закрашивать во что угодно и смотреть, нравится нам это или нет. Например, сделать что-то такое:

И вроде прекрасно.
Но нет!
Мир розовых пони с вырванными глазами это не про нас. Обсуждение заинтересованных лиц по вопросу выбора цвета при наложении его на фото тоже быстро заходит в тупик. Пара часов возни с пейнтом и никакого консенсуса. Однако! У нас появился некоторый инструмент. Им можно воспользоваться. Если у нас не выходит, может есть люди, которые смогут это сделать за нас?
Экспертное решение
Экспертами были призваны все желающие подписчики ВК. Ставка была на то, что год 2018 на дворе, а все равно у нас страна советов. Всем только дай начать советовать.
Для вышеприведенного шедевра фотоискусства был сделан «сайт», который содержал фотографию комнаты и color picker который позволял менять цвет стен. Ссылка на сайт была выложена в ВК с просьбой помочь с выбором цвета.
Эксперты высказали ряд мнений, поделились своими вариантами. Увы, к консенсусу это не привело, но вызвало ряд смещений эстетических приоритетов у заинтересованных лиц. И эти смещения в дальнейшем позволили к консенсусу прийти.
Путь к Machine Learning
Проблем у экспертов было две.
- Мнение эксперта не всегда совпадало с мнением заинтересованного лица,
- Экспертов было мало и все их мнения нельзя было сгрести в кучу, для принятия одного усредненного решения.
Вместе обе проблемы не давали возможности принятия решения.
- Если бы экспертов было много, они могли бы задавить количеством относительно какого-то варианта,
- Если бы их было мало, но у всех мнение совпадало с заинтересованными лицами, можно было просто с экспертами согласиться.
Но сама формулировка проблемы экспертного мнения дала ключ к следующей итерации.
Надо иметь МНОГО оценок. Если их много, и все голоса за что-то конкретное, с этим проще смириться. Но как это сделать?
Например, сделать небольшое desktop приложение, которое бы применяло к картинке случайные варианты гаммы, а заинтересованные люди бы оценивали эти варианты от 0 до 10. Таким образом набралось более 300 разных оценок цветов в формате:
![$\begin{pmatrix} r \in [0,255] \\ g \in [0,255] \\ b \in [0,255] \\ V \in [0,10]\end{pmatrix}$](https://habrastorage.org/getpro/habr/formulas/004/c6c/374/004c6c374b45eb15850cbcf2d2ba5618.svg)
Теперь у нас появилась выборка с оценками, хотя не очень удобная для анализа. Можно переформулировать, что V от 0 до 10, это на самом деле не оценка цвета, а количество людей, которые проголосовали за этот вариант. И превратить 4-х мерный вектор
в V 3-х мерных . Нули, естественно, пропадают. И каждый вектор теперь является равноправным голосом за соответствующий оттенок. Удобно добавлять при этом к значениям RGB случайных небольших смещений, чтобы не получалась куча совсем уж одинаковых оттенков. В такой формулировке получается типичная формулировка задачи поиска максимума плотности многомерного распределения. Т.е. мы ищем такую область, в которой люди бы «голосовали» чаще всего.
Если нам хочется усилить влияние высоких оценок, мы можем брать V² при преобразовании 4-d в 3-d. Тогда, оценка 2 превращается 4 голоса, а оценка 4 в 16 голосов. Таким образом мы сможем уменьшить влияние тех цветов за которые голосовали, но не прям сильно.
ML
Самые две простые вещи, которые приходят в голову, это что, наверное, можно приблизить полученное распределение многомерным нормальным распределением или квадратичной функцией в 3-d (что-то такое куполообразное с выраженным максимумом). Не то, чтобы все там и правда красиво описывалось такими простыми функциями, но в данном случае точно можно было немного закрыть на это глаза.
Для приближения многомерным нормальным, требуется всего лишь прикинуть по данным ковариационную матрицу и матожидания для всех маргинальных распределений. После этого можно аналитически посчитать максимум, но гораздо проще (для мозга) просто пройтись по всем возможным сочетаниям цветов с каким-то шагом, подставляя в формулу распределения параметры распределения и значения цветов. Потом взять максимальную точку.

Приближение многомерным нормальным и поиск его максимума дал неплохой сине-фиолетовый цвет нужной степени матовости:

Приближать квадратом еще проще.
Для этого в матлабе задалась функция вида для всех возможных вариаций
:
и методом имитации отжига минимизировалась квадратичная ошибка значения плотности точек в окрестности: 
После настройки коэффициентов полинома, максимум считался с помощью вычисления производной от функции
с помощью symbolic toolbox и далее корней от производной. Корней получалось несколько, но под параметры ограничений на значения цветов подходил один. Приближение квадратичной функцией и поиск ее экстремума дал схожий вариант с нормальным распределением. Немного более синий и менее красный:

Но иногда можно не думать о приближениях и просто написать нейросеть, которой все данные скормить. Говорить о параметрах нейросети смысла нет особо, но было много вариантов, много архитектур и несколько разных извращений над переменными. В итоге, получилось вытащить достаточно устойчивое ее мнение относительно лучшего цвета. Предыдущие оценки «хорошести» цветов сеть устроили почти во всем, кроме зеленого. Зеленого она щедро добавила.

Кстати, если переформулировать плотности как классы, например выискивая какие-то значения больше 5, и использовать Gradient Boosting Classifier, чтобы находить области пространства, где наиболее плотны положительные оценки, получалось примерно тоже.
И тут снова проявилась проблема, которая достаточно часто проявляется в реальных проектах при презентации так называемых «промежуточных результатов». Она звучит так:
Это оно, конечно, все очень хорошо: нейросети, распределения, но почему-то хочется не этого… Хочется, чтобы как бы, хорошо.
Очень интересен тут тот момент, что то, что оценивается красивым на фотографии, не обязательно то, что ты хочешь иметь у себя на стене, если оцениваешь еще раз более внимательно!
Так и в реальных проектах какие-то показатели, опора на которые раньше казалась объективной и конструктивной, внезапно как-то приунывают при получении результата по ним (даже если, в общем, по числам выходит неплохо). И тут остается одно. Найти все хорошее, что у нас получилось и презентовать какими-нибудь красивыми картинками, чтобы всех все устроило.
Визуализация
Давайте как-нибудь красиво нарисуем, как голосовалось за цвета? Например, сделаем 3-d scatter plot в матлабе для HSV(255,255,255), где места, за которые голосовали, будут изображаться шариками нужного цвета. Чем больше шарик, тем больше голосовали. В нашем случае это выглядело так:
Простите, что не привел HSV к 360/100/100, было лень, а в матлабе все от 0 до 1.

Чем больше шарик, тем больше цвет нравится
Из проекций этого графика, в том числе, становится очевидно, почему разные методы давали те результаты, что давали. Например:

Проекция Цветность/Оттенок
Из проекции Цветность/Оттенок видно, что, если строить гауссиан или приближать квадратичной функцией, максимум будет где-то между синим и фиолетовым. При этом максимум цветности будет в районе 100 и очень яркие цвета не выбираются. А нейросеть у которой пространство будет достаточно сложным с большим количеством локальных экстремумов, имеет возможность учесть и зеленую часть. Видимо там же где-то был и розоватый пик, но чуть ниже, поэтому в конечный результат не попал. И т.д.
Разглядывание визуализации показало 3 заметных псевдо-кластера.

Усредняющие способности всех грубых методов радостно сливали светло-синие и темно-синие в один средне-синий результат. При этом логика подсказала, что красить помещение в темные цвета не стоит(пусть даже они ничо на фото смотрятся), поэтому этот кластер надо отбросить. А зеленый просто никому особо не нравился, потому что вызывал всякие больнично-коммунальные ассоциации при долгом разглядывании. Зачем на тут вообще какая-то математика, ага?
В оставшемся кластере просто надо было взять условное среднее и допилить как-то руками.

На этом все заинтересованные лица согласились, что, в общем, это компромисс, на котором стоит остановиться.
Еще через пару недель реальность не слишком исказила ожидания (хотя была несколько розовее, чем реальности предполагается бывать)…

Сам по себе такой розоватый цвет, конечно, вещь вызывающая сомнения, но мы сами этого хотели. Теперь осталось только купить мебель подходящего цвета. Хм. А не стоит ли подумать об автоматической оптимальной расстановке мебели в комнате? Это типичная задача выпуклой оптимизации…
Выводы
Находясь одновременно со стороны заказчика и исполнителя, я с удивлением наблюдал, как сам с собой не могу найти понимания по вопросу, в решении которого я с обеих сторон был, вроде как, заинтересован. Так же, с удивлением увидел, как те вещи, которые я полагал объективными и напрямую выводимыми из данных, которые удовлетворяют меня как исполнителя, могут меня же самого не удовлетворять как заказчика.
Безумия тут добавляет то, что я сам составлял данные, напрямую указывая в них, что именно потенциально меня может удовлетворить. И видимо, полностью адекватно составить я их не мог, по каким-то причинам, которые мне самому не слишком ясны. Например, я ставил высокие оценки темным цветам, хотя они явно не имели возможности быть выбраны в конечном итоге. Почему? Потому что на картинке это было мило. Настоящая задача же была совсем другая, но выбирать цвет из более сложных соображений на автомате было не реалистично.
В конечном итоге, в тех данных, которые я сгенерировал, было скрыто решение. Но как было сразу прийти решению, без этих странных танцев с бубном, которые подправляли мое собственное представление о том, что мне надо(или уж совсем точно не нужно), не очень ясно. Я смотрел на визуализацию с шариками и до того, как взялся за поиск максимума разными методами. Но «кластеры» увидел на ней только после.







