Когда приложение было монолитным и вдруг, раз, стало распределённым, в формулу вычисления доступности добавляется ещё одна неизвестная — сетевая. Из-за проблем с вызовами между компонентами, приложения часто валятся и начинают дрыгать ножками. А выяснение причин нестабильной работы распределённого приложения — та ещё задачка. Дополнительную неразбериху в структуру приложения вносит условный kubernetes, который по своему внутреннему усмотрению может произвольно распределять условные поды по условным нодам. Пишу «условный», потому что на месте kubernetes может быть и Swarm и Openshift и прочие и прочие.
Я к тому, что без нормальной визуализации разобраться где температурит, может быть очень непросто. Под катом моё представление о потенциальных возможностях инструментов, которые умеют рисовать карту приложения и подсвечивать места для прикладывания подорожника, а также список этих самых инструментов со скриншотами.
Давайте-ка для начала разберёмся что желательно видеть на карте приложения, потом рассмотрим подходы к мониторингу и потом перейдём к конкретным вендорам.
Что хочется видеть на карте приложения
Первое, что приходит в голову — возможность группировки нод приложения по неким критериям. Например, я говорю, что в этой группе у меня фронтэнд, а в этой бекэнд или вот тут у меня экземпляры сервиса Payments, а тут Shipping. Ну, и так далее. И люди, которые отвечают за ту или иную часть, сразу же видят полную картину происходящего в рамках своей зоны ответственности.
Второе — разнесение приложения по уровням с возможностью посмотреть, например, с точки зрения инфраструктуры, сервиса, экземпляров сервиса и т.д. Также как и в первом случае поможет определить проблемный слой.
Третье — выходы и входы этих нод, включая связи между ними. На этих ниточках хочется видеть золотые сигналы (golden signals), которые Google описывает в главе 6 Monitoring Distributed Systems книги Site Reliability Engineering. Перевод этой главы я уже как-то публиковал в блоге на Медиуме. А сигналы следующие: задержка (latency), трафик (throughput), ошибки (error rate) и насыщенность (saturation).
Возможно, я чего-то не учёл. Идите, пожалуйста, в комментарии, если считаете, что не хватает других важных вещей.
Что скрывают в себе разные подходы к мониторингу
Не знаю к ещё это можно назвать, поэтому назову подходы агентским и безагентским мониторингом. Сейчас поясню ху из ху.
Агентский мониторинг
Агентский мониторинг означает необходимость внедрения специальных агентов мониторинга в контролируемое приложение. Агенты встраивают trace ID в заголовки пакетов.
К этому типу можно отнести решения APM мониторинга и все те, которые встраиваются путём инжекции SDK в код приложения.
Плюсы: помогает с поиском корневой причины проблемы, по заголовкам можно точно отслеживать путь прохождения транзакций.
Минусы: возможные оверхеды из-за модификации алгоритма работы приложения, невозможность встраивания в устаревшие приложения, поддержка ограниченного набора языков программирования
Безагентский мониторинг
Мониторинг без модификации приложения. К этому типу можно отнести логи, трейсинг на уровне операционной системы, мониторинг сетевого трафика.
Плюсы: покрытие мониторингом различных фреймворков и языков программирования, может работать там, где невозможна инжекция trace ID, нет оверхеда на контролируемом приложении.
Минусы: без trace ID может быть сложно восстановить контекст бизнес-транзакции, отсутствие возможности слушать трафик если настроена SSL-инкапсуляция и нет ключей,
Что предлагают вендоры
Вендоров разобрал по признаку агентский/безагентский, остальные характеристики можете спросить в комментариях или личном сообщении. Самый большой опыт у меня был с Instana, Appdynamics и New Relic, если захотите посмотреть — могу помочь с демо-лицензиями на период превышающий 14 дней (так они предлагают у себя на сайтах по умолчанию).
Агентский мониторинг
Instana — инструмент для мониторинга распределённых систем. Ключевая особенность — единый агент для всех поддерживаемых технологий и сбор метрик раз в секунду.

Appdynamics — известное решение для APM-мониторинга. Умеет строить карту приложения на основе вызовов между компонентами приложения. Для мониторинга вызовов требуется установка агента.
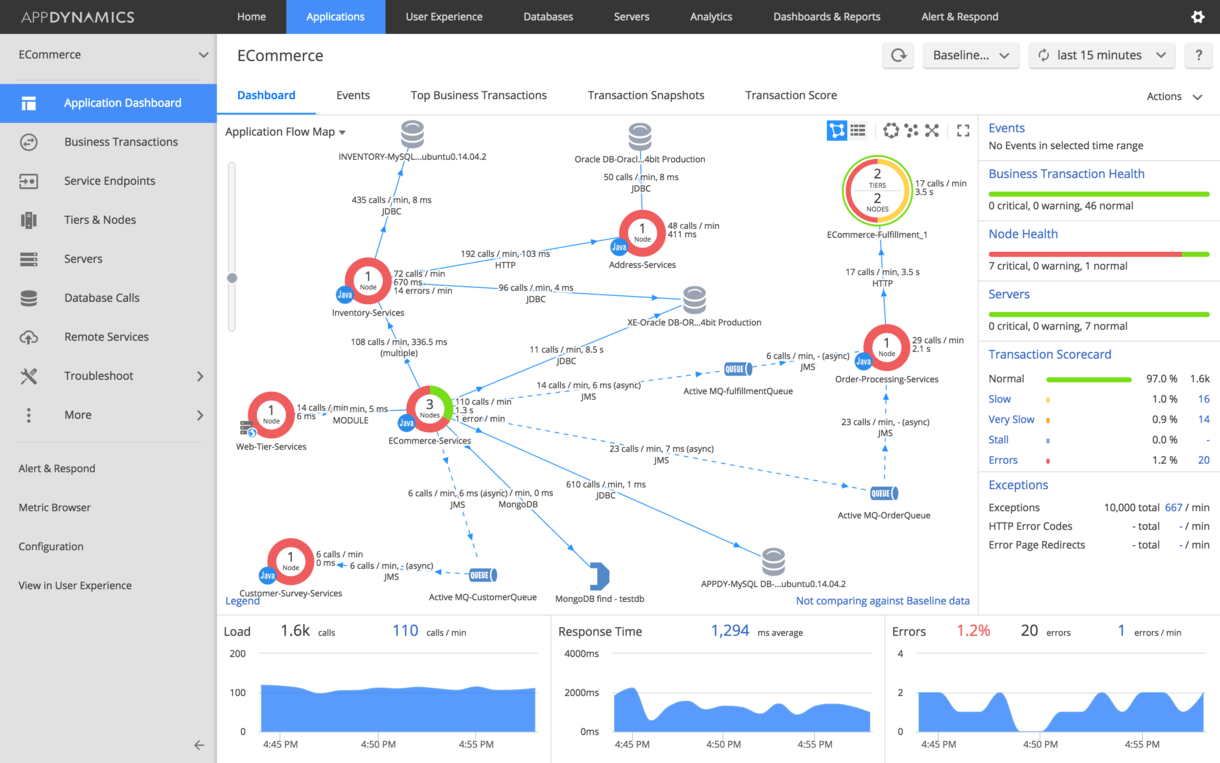
New Relic — прямой конкурент Appdynamics. Ключевое отличие — возможен мониторинг только из облака (агенты при этом всё также устанавливаются на целевые серверы). Строит карту приложений на основе вызовов.
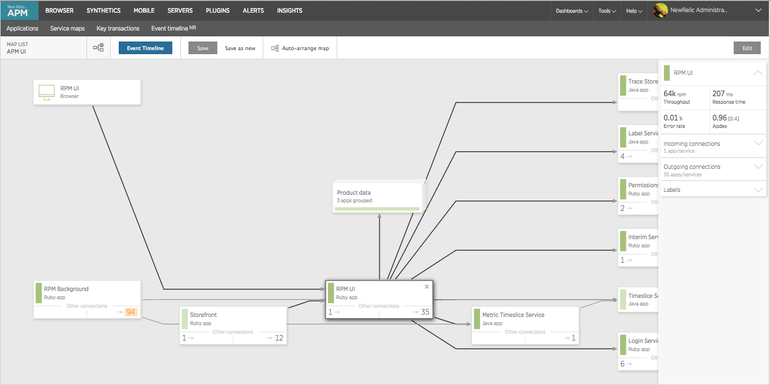
Dynatrace — инструмент APM-мониторинга. Поддерживает мониторинга различных языков программирования и может работать как из облака так и on-premise.
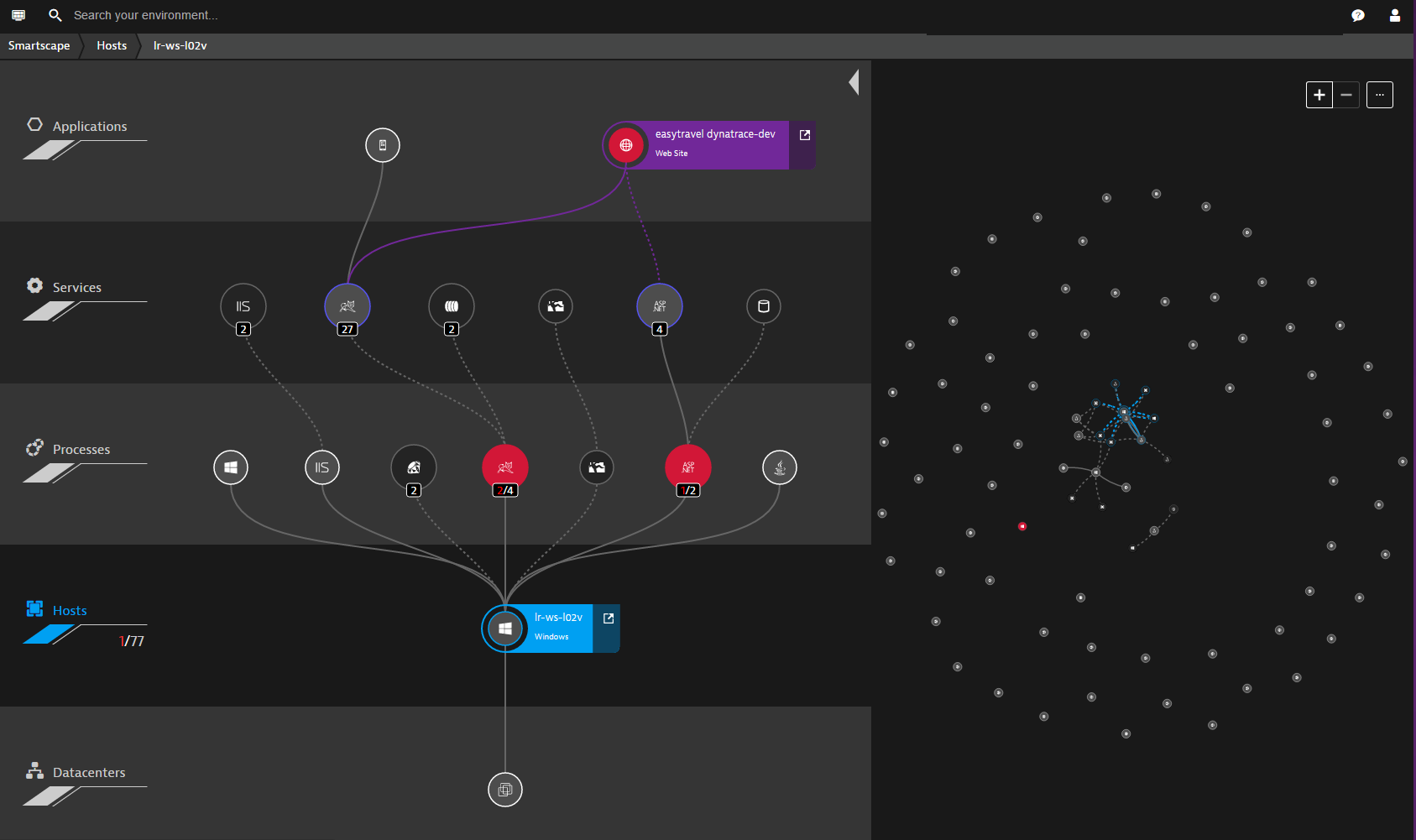
AWS X-Ray — мониторинг приложений, которые хостятся на AWS. Поддерживает визуализацию карты приложения, требует установки собственного SDK.

OpenTracing — API для инструментации распределённых приложения. Многие коммерческие и некоммерческие решения работают на базе этого API.
Jaeger — бесплатный инструмент для трейсинга с открытым исходным кодом. Построен на базе OpenTracing.
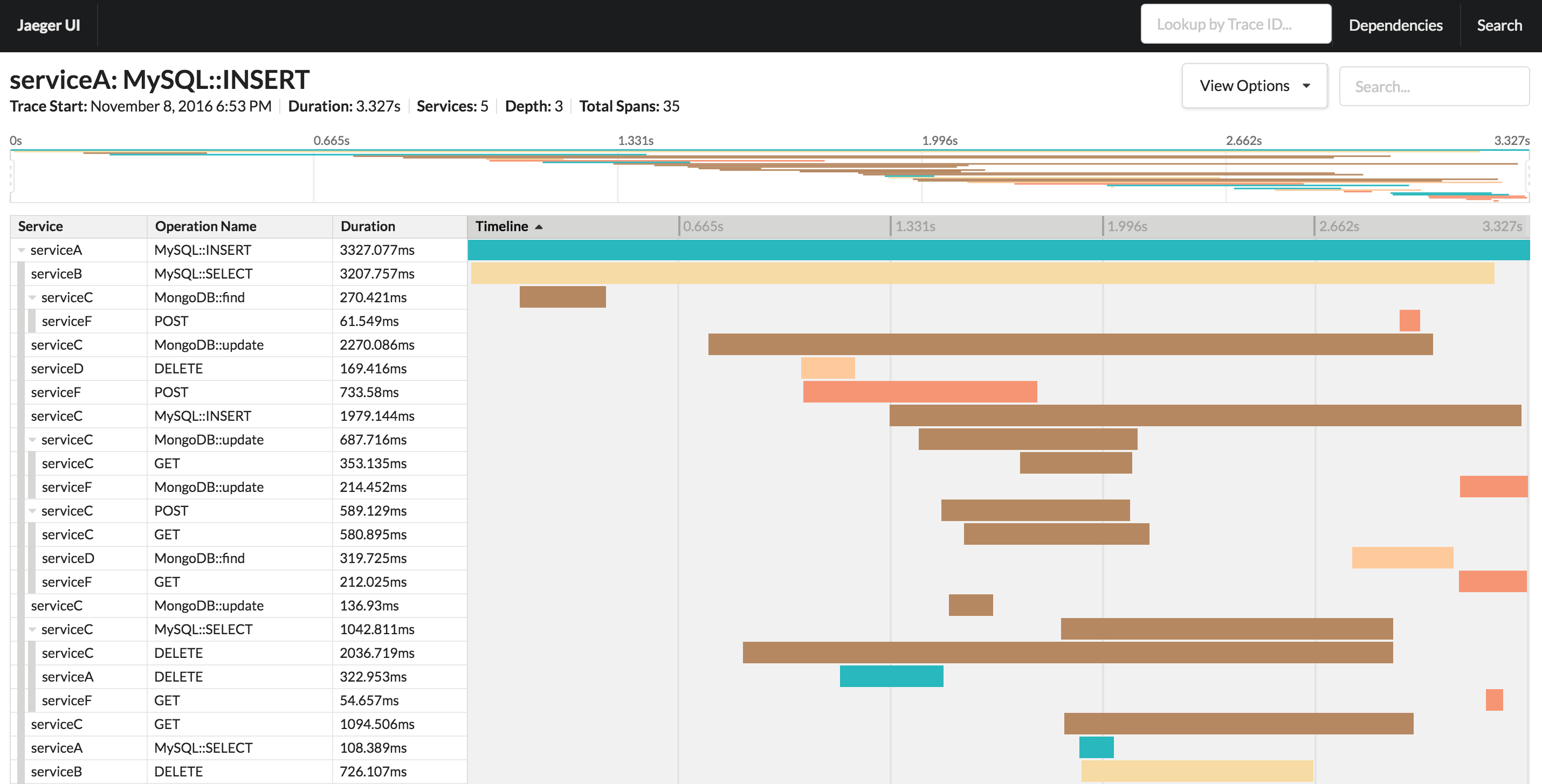
Datadog APM — коммерческий инструмент для мониторинга распределённых приложений. Работает на базе упомянутого OpenTracing.

Безагентский мониторинг
OpenZipkin — бесплатный инструмент для трейсинга распределённых приложений. Особенностью его работы является сбор данных о вызовах с помощью библиотек инструментации и дальнейшая отправка этих данных на коллектор OpenZipkin.

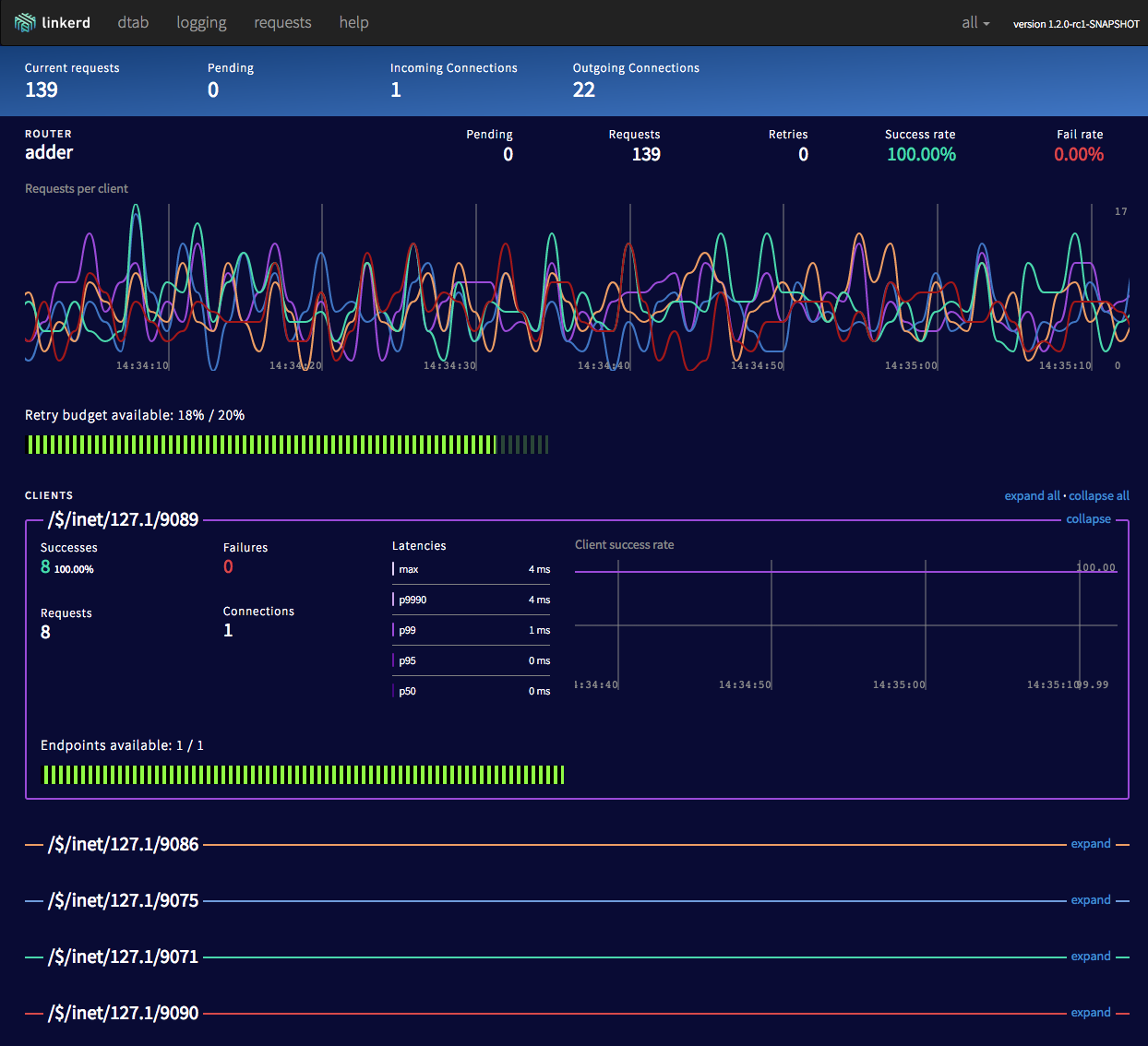
Linkerd — бесплатный инструмент для трейсинга вызовов внутри приложения. Является надстройкой над OpenZipkin, устанавливается на инфраструктуру kubernetes как sidecar-контейнер.
Envoy — бесплатный инструмент. Работает в качестве прокси, на который пересылаются данные о вызовах между компонентами приложения. Собственного веб-интерфейса нет, данные можно получить через HTTP GET запросы или отправить в statsd.
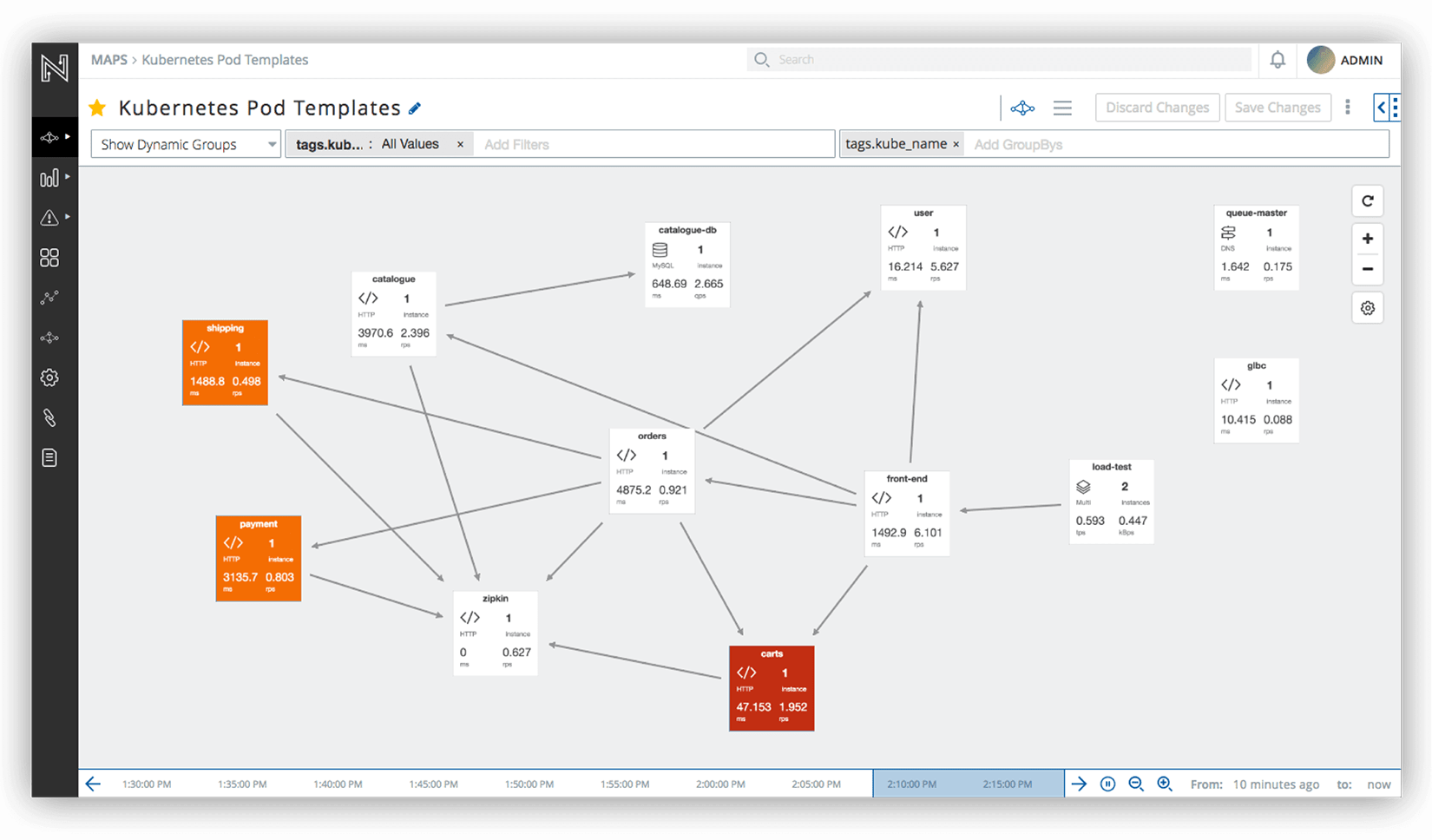
Netsil — инструмент для мониторинга распределённых приложений на основе прослушивания трафика. Работает вне зависимости от языка, на котором написано приложение.
Расскажите кто чем пользовался и какое осталось впечатление.







