Во многих организациях оценка подразделений осуществляется с использованием KPI (Key Performance Indicators). В организации, где я работаю, такая система называется «системой показателей деятельности», а в этой статье я хочу рассказать о том, как у нас получилось автоматизировать часть работы с показателями уложившись в месяц. При всем этом трудозатраты наши оказались не самыми большими, а заодно мы попробовали реализовать некоторые давние хотелки. В моем рассказе не будет хайповых технологий или откровений (все-таки провинциальная разработка сурова), зато будут некоторые зарисовки на тему, которые помогут понять, с чего мы начали, что у нас получилось, а также какие мысли появились у нас по итогам разработки. Если вам еще не стало скучно, прошу под кат.
В далеком уже 2006 году у нас была введена система показателей эффективности деятельности: разработано пятнадцать критериев оценки, методика их расчета, установлена ежеквартальная периодичность подсчета этих показателей. Оценка проводилась для двадцати двух филиалов организации, расположенных во всех районах нашего региона. А чтобы показатели достигались с большим энтузиазмом к ним была привязана премия – чем выше сумма показателей, тем выше место в рейтинге, чем выше место в рейтинге, тем выше премия и так каждый квартал и каждый год.
Со временем менялся состав критериев, каждый квартал то добавлялись новые, то исключались старые. На пике, примерно в 2016 году, количество показателей превышало сорок, а сейчас их всего четырнадцать.
Однако все это время процесс их расчета был однотипен. Каждый критерий рассчитывается ответственным подразделением головной организации по утвержденному именно для этого критерия алгоритму. Расчет может вестись как по простой формуле, так и по ряду сложных, может требовать сбора данных из нескольких систем, при всем этом весьма вероятно, что алгоритм будет меняться достаточно часто. А дальше все уже намного проще: рассчитанный в процентах показатель умножается на свой коэффициент, таким образом, получается балл по критерию, далее баллы ранжируются и каждое подразделение занимает место в соответствии с баллом. То же самое делается и с суммой баллов для подсчета итогового места.
С самого начала для того, чтобы учесть и подсчитать все описанное выше использовался Excel. Многие годы окончательный свод критериев и дальнейший расчет баллов и мест производился в симпатичной табличке, часть которой приведена на рисунке

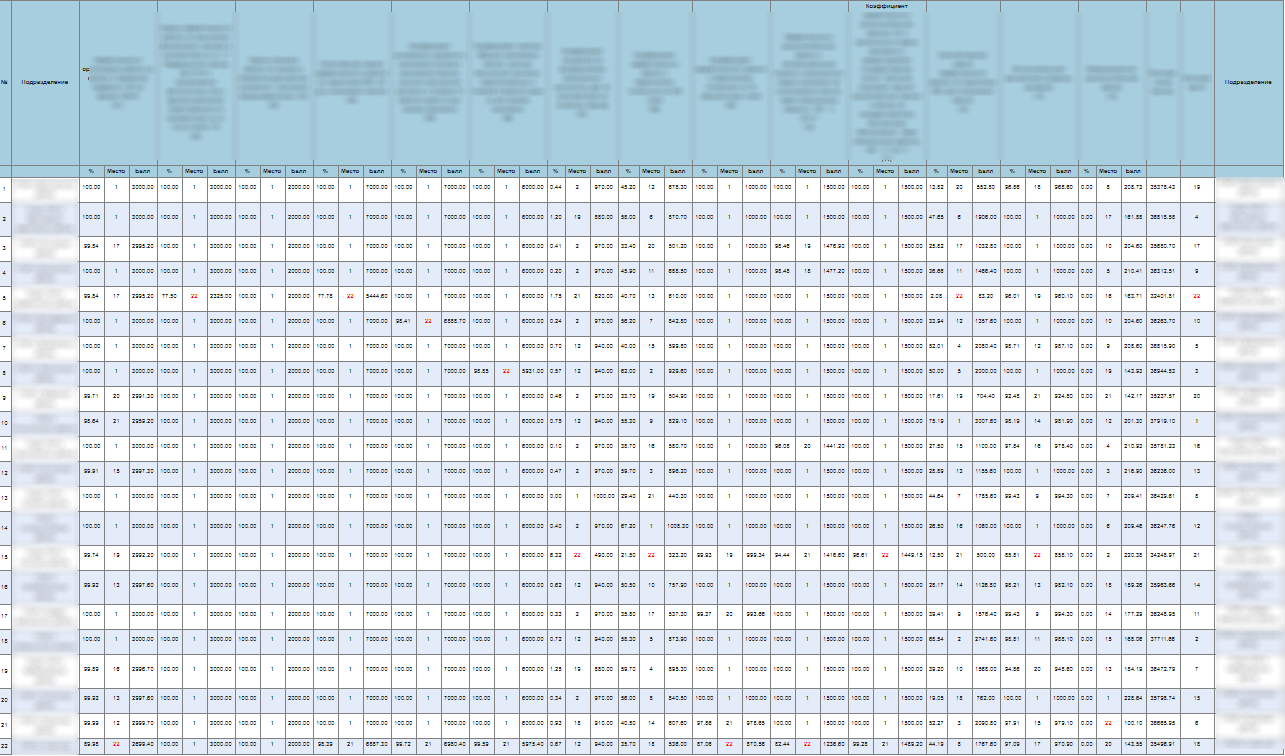
Замечу только, что в этой симпатичной табличке, большая часть колонок попросту скрыта, а в реальности в 4 квартале 2016 года она выглядела так

Согласитесь, такое количество показателей и такой объем таблицы не прибавляют ей простоты. Кроме того каждый из критериев рассчитывался отдельно, а эту сводную таблицу руками делали девушки из общего отдела. Учитывая то, что менялся не только состав критериев, но и расчеты могли переделываться по нескольку раз (на то есть много причин), последние дни каждого квартала, мягко говоря, не радовали. Приходилось постоянно менять данные в таблице, проверять и перепроверять их: вот так забудешь новую колонку добавить в сумму баллов или коэффициент не обновишь, а у кого-то из-за этого место становится ниже, а с ним и премия меньше. Поэтому после героического сведения таблицы начиналась не менее героическая проверка, проверяли и согласовывали все те, кто считал каждый критерий, руководители и даже организационно закрепленный ИТ-специалист. Учитывая, что вся работа выполнялась вручную, а расчеты показателей для сводной таблицы направлялись на почту, достаточно часто возникали ситуации, когда в сводной таблице были и ошибки в формулах и данные неактуальных версий. Капитан очевидность сообщает, что после выявления каждой ошибки процесс проверки запускался заново.
Когда все показатели подсчитаны, табличка утверждена и разослана по филиалам, там, в филиалах ее перепроверяли: а вдруг коварный Excel посчитал что-то не так? Думаю, очевидно, что составление годового отчета по критериям или анализ исторических данных оказывался не менее увлекательным квестом.
Однако с управленческой точки зрения такая система достаточно эффективна и позволяет при необходимости подтянуть проседающие направления работы, вести мониторинг и иметь представление, что же происходит в каждом из филиалов по тому или иному направлению работы. Кроме того, место филиала, рассчитанное по критериям, было интегральным показателем.
Практика доказывала необходимость и важность системы оценки. В начале 2017 года стало ясно, что расчет критериев раз в квартал позволял оценить проделанную работу, но вот мониторить ее позволял слабо. Слишком уж большой промежуток времени. В связи с этим решили, что расчет показателей станет проводиться раз в две недели, а итоги будут подводиться все так же ежеквартально. Увеличение частоты расчета действительно позволило руководителям филиалов оперативно реагировать на изменения и повысить контроль над процессами внутри их подразделений.
Вот только в головной организации мало кого радовала перспектива выполнять описанный выше процесс свода данных не ежеквартально, а каждые две недели. Как не трудно догадаться, процесс решили автоматизировать. Сроки оказались сжатыми: от момента принятия решения о переходе на новую периодичность подсчета до собственно перехода должен был пройти всего месяц. За этот срок очень желательно было придумать нечто лучшее, чем связка Excel для свода и расчета, а почты для сбора и оповещения.
Сначала шли достаточно жарки дискуссии о том, что очень-очень надо сделать автоматическим и сам расчет показателей с учетом всех их формул и источников данных. Но учитывая сжатые сроки, сложность такой функциональности и необходимость ее постоянного поддержания в актуальном состоянии удалось прийти к следующим требованиям к системе:
Функциональность совсем небольшая, но и времени немного.
Меня всегда привлекали средства быстрой разработки и автоматической генерации интерфейсов. В тех случаях, когда надо реализовывать функциональность CRUD, очень заманчивой кажется идея, когда интерфейс и часть бизнес-логики будут предоставлены так сказать из коробки. Конечно, и интерфейс будет непритязательным и логика топорной, но для многих задач этого достаточно.
Движимый этими идеями я решил попробовать что-нибудь подобное. Существуют Spring Roo, Cuba и другие интересные инструменты, но выбор пал на OpenXava. Во-первых когда-то я уже делал на ней совсем уж простенькое приложение и остался доволен, во-вторых этот фреймворк на тот момент достаточно удачно вписывался в наш технологический стек. Кроме того, очень радует наличие краткого туториала на русском языке.
Краткое описание особенностей и возможностей OpenXava можно прочитать здесь. OpenXava — это фреймворк, реализующий автоматическое построение веб интерфейса, интегрированного с базой данных, на основе JPA, и использующий аннотации для описания правил визуализации. В основе приложения лежат бизнес-компоненты – Java-классы, содержащие информацию, необходимую для создания приложений. К такой информации относится структура данных, валидаторы, допустимые представления, маппинг на таблицы базы данных. Операции над бизнес-компонентами осуществляются посредством контроллеров, из коробки умеющих CRUD, поиск, экспорт в PDF и т.п. Приложение OpenXava представляет набор модулей. Модуль связывает бизнес-компонент с одним или более контроллерами. Для отображения интерфейса используются представления, определяемые для каждого бизнес-компонента. Ничего необычного, MVC с немного своей атмосферой.
В большинстве приложений мы используем СУБД IBM DB2. Была создана небольшая база данных, хранящая справочники групп критериев и критериев, по которым ведется оценка филиалов, справочник филиалов ну и табличку, в которую заносятся рассчитанные значения критериев. Каждому критерию на определенный момент времени сопоставляется коэффициент, который будет использоваться при подсчете баллов. Каждый филиал, по каждому критерию получает оценку также на определенную дату. Данные о значениях критериев хранятся исторически, то есть актуальными на какую-либо дату данными будут являться те, которые были внесены на ближайшую дату в прошлом. Этот подход, навеянный регистрами сведений из 1С: Предприятие, мне кажется достаточно удобным: и история есть и с вопросами редактирования/удаления можно не особо париться.
Для того, чтобы получить из базы заветный отчет о показателях филиалов были созданы хранимые функции, результаты которых уже мапятся на Java-класс. Функции выглядят примерно так.
Перенос части бизнес-логики в СУБД оказывается достаточно оправданным, особенно, когда дело касается подготовки данных для разных отчетов. Операции получается записать в более лаконичной и естественной форме, на Java такие манипуляции с данными потребовали бы и большего объема кода и определенных усилий по его структуризации. Хотя относительно сложные или нетривиальные операции все же проще запрограммировать на Java. Поэтому в нашем приложении в отношении выборки данных используется подход, когда соединение наборов данных, отсечение условиям и некоторые операции, которые можно выполнить оконными функциями, выполняются в хранимых функциях и процедурах, а более сложная логика реализуется в приложении.
Как я уже говорил, для реализации приложения использовалась OpenXava. Чтобы получить с ее помощью типовой интерфейс и CRUD из коробки необходимо выполнить некоторые действия.
Начнем с того, что в web.xml надо описать фильтр и сервлет из аддона, осуществляющего навигацию по приложению:
Далее в файле controllers.xml определим используемые в приложении контроллеры. В нашем случае достаточно самого простого:
В приведенном контроллере объединены функции включенных в OpenXava по умолчанию контроллеров, о функциях которых нетрудно догадаться из названий.
И, наконец, в файле application.xml свяжем созданный контроллер и модель. Примерно так:
Как было сказано выше в основе приложения лежат бизнес-компоненты, составляющие модель приложения. Для примера рассмотрим связанный с контроллером в application.xml компонент RegValueCriteria. Этот компонент описывает значение критерия по филиалу (для краткости оставлено только описание полей класса, а методы типа геттеров и сеттеров опущу):
Кроме привычных аннотаций JPA. Можно заметить и аннотации OpenXava. Их стоит рассмотреть подробнее.
Аннотация
А выглядит это так:

Неказисто, зато с минимумом усилий. Однако есть способы немного «оживить» форму.
Для того, чтобы дата регистрации была заполнена при создании компонента использована аннотация
Для настройки выпадающих списков, содержащих связанные объекты, применяется аннотация
С помощью аннотаций можно реализовать и кое-какую бизнес-логику самой формы. Например, чтобы при изменении процента значение рассчитывалось автоматически с учетом коэффициента критерия можно применить аннотацию
Для табличного представления данных используется аннотация
Выглядеть это будет следующим образом

Радует наличие фильтров, пагинации и экспорта из коробки, однако многие детали требуют доработки напильником.
Подобным образом построена работа и с другими компонентами. Использование OpenXava позволило резко снизить трудозатраты на реализацию функций CRUD и большей части пользовательского интерфейса. Использование действий из предопределенных контроллеров и аннотаций для построения форм сильно экономит время, если не придираться к деталям и не пробовать реализовать что-то сложнее формы ввода с несколькими событиями. Хотя может быть дело в опыте.
Помните, для чего затевалось приложение? Да-да для того, чтобы табличка с показателями не героически сводилась в Excel, а создавалась автоматически на основе введенных данных. В окне браузера сводная таблица стала выглядеть так:

Детали реализации приводить не буду, поскольку с ней все не очень хорошо и смесь JSP со сгенерированным при запросе данных HTML, не то, чем стоит делиться с широкой публикой. В то же время сама выборка данных была продемонстрирована выше.
Однако хочу остановиться на одной интересной детали. Когда собирались требования к приложению, руководство очень хотело, чтобы помимо сводного отчета значения отдельного показателя можно было вывести в виде карты региона, разбитого на районы с указанием места и балла соответствующего филиала. Кто по карте узнал регион – тот молодец =)

С одной стороны, требование было опциональным, но с другой стороны и картинка обещала быть наглядной, и с точки зрения реализации интересно было попробовать. После некоторых раздумий пришла идея найти изображение региона в формате SVG и сделать из него XSLT-шаблон.
Полученный шаблон легко заполняется данными, а после этого конвертируется в PNG.
Сначала с помощью запроса, описанного выше, делается выборка данных, полученные данные преобразуются в объект такого класса:
Далее преобразуем объект в XML;
А теперь возьмем полученный XML, подготовленный XSLT-шаблон, применим преобразование и на выходе получим svg:
В принципе на этом можно было бы и остановиться, браузеры без проблем отображают SVG. Но описанные отчеты получались еще и через Телеграм-бота, поэтому SVG надо сконвертировать в какой-нибудь формат типа JPEG или PNG. Для этого используем Apache Batik
Отчет в виде карты готов. Его можно и через браузер посмотреть и у телеграм-бота запросить. По-моему неплохо.
К назначенному сроку мы успели и уже в марте 2017 года показатели эффективности вместо Excel стали регулярно заноситься в созданную систему. С одной стороны, задача-максимум решена не была, наиболее сложная часть расчетов показателей так и выполняется вручную. Но с другой стороны, реализация этих расчетов несла риски постоянной доработки. Кроме того, даже созданный простой интерфейс для сбора данных снимал огромное количество вопросов с постоянными изменениями, контролем версий и сводом экселевской таблицы. Большое количество ручной работы, проверок и перепроверок было убрано.
Нельзя не сказать, что интерфейс на Open Xavа не слишком порадовал пользователей. В первое время было много вопросов к его особенностям. В какой-то момент пользователи начали жаловаться, что на ввод данных уходит слишком много времени и вообще «мы хотим как в Экселе, только программу». Пришлось даже провести мониторинг скорости ввода на основе данных о времени создания записей. Этот мониторинг показал, что даже в самых тяжелых случаях пользователи не тратили на ввод более 15 минут, а обычно укладывались в 5-7, при том, что им необходимо было вносить данные по 22 филиалам. Такие показатели кажутся вполне приемлемыми.
Однако, хочется отметить две вещи:
Если же говорить о выгодах для организации в целом, то после внедрения приложения, как и предполагалось, степень контроля повысилась. Руководители на местах получили инструмент мониторинга показателей, с помощью которого они могут влиять на работу в более оперативном режиме, сравнивать показатели за различные периоды, не путаясь при этом в потоке рассылаемых файлов. Заинтересованность руководителей в постоянном и неусыпном контроле своего филиала была обнаружена нами весьма интересным способом: просматривая логи Telegram-бота мы заметили, что некоторые отчеты получались в 4 или 5 часов утра. Сразу видно, кто интересуется работой.
На этом все. Буду признателен за конструктивную обратную связь!
Предыстория
В далеком уже 2006 году у нас была введена система показателей эффективности деятельности: разработано пятнадцать критериев оценки, методика их расчета, установлена ежеквартальная периодичность подсчета этих показателей. Оценка проводилась для двадцати двух филиалов организации, расположенных во всех районах нашего региона. А чтобы показатели достигались с большим энтузиазмом к ним была привязана премия – чем выше сумма показателей, тем выше место в рейтинге, чем выше место в рейтинге, тем выше премия и так каждый квартал и каждый год.
Со временем менялся состав критериев, каждый квартал то добавлялись новые, то исключались старые. На пике, примерно в 2016 году, количество показателей превышало сорок, а сейчас их всего четырнадцать.
Однако все это время процесс их расчета был однотипен. Каждый критерий рассчитывается ответственным подразделением головной организации по утвержденному именно для этого критерия алгоритму. Расчет может вестись как по простой формуле, так и по ряду сложных, может требовать сбора данных из нескольких систем, при всем этом весьма вероятно, что алгоритм будет меняться достаточно часто. А дальше все уже намного проще: рассчитанный в процентах показатель умножается на свой коэффициент, таким образом, получается балл по критерию, далее баллы ранжируются и каждое подразделение занимает место в соответствии с баллом. То же самое делается и с суммой баллов для подсчета итогового места.
С самого начала для того, чтобы учесть и подсчитать все описанное выше использовался Excel. Многие годы окончательный свод критериев и дальнейший расчет баллов и мест производился в симпатичной табличке, часть которой приведена на рисунке

Замечу только, что в этой симпатичной табличке, большая часть колонок попросту скрыта, а в реальности в 4 квартале 2016 года она выглядела так

Согласитесь, такое количество показателей и такой объем таблицы не прибавляют ей простоты. Кроме того каждый из критериев рассчитывался отдельно, а эту сводную таблицу руками делали девушки из общего отдела. Учитывая то, что менялся не только состав критериев, но и расчеты могли переделываться по нескольку раз (на то есть много причин), последние дни каждого квартала, мягко говоря, не радовали. Приходилось постоянно менять данные в таблице, проверять и перепроверять их: вот так забудешь новую колонку добавить в сумму баллов или коэффициент не обновишь, а у кого-то из-за этого место становится ниже, а с ним и премия меньше. Поэтому после героического сведения таблицы начиналась не менее героическая проверка, проверяли и согласовывали все те, кто считал каждый критерий, руководители и даже организационно закрепленный ИТ-специалист. Учитывая, что вся работа выполнялась вручную, а расчеты показателей для сводной таблицы направлялись на почту, достаточно часто возникали ситуации, когда в сводной таблице были и ошибки в формулах и данные неактуальных версий. Капитан очевидность сообщает, что после выявления каждой ошибки процесс проверки запускался заново.
Когда все показатели подсчитаны, табличка утверждена и разослана по филиалам, там, в филиалах ее перепроверяли: а вдруг коварный Excel посчитал что-то не так? Думаю, очевидно, что составление годового отчета по критериям или анализ исторических данных оказывался не менее увлекательным квестом.
Однако с управленческой точки зрения такая система достаточно эффективна и позволяет при необходимости подтянуть проседающие направления работы, вести мониторинг и иметь представление, что же происходит в каждом из филиалов по тому или иному направлению работы. Кроме того, место филиала, рассчитанное по критериям, было интегральным показателем.
Система должна измениться
Практика доказывала необходимость и важность системы оценки. В начале 2017 года стало ясно, что расчет критериев раз в квартал позволял оценить проделанную работу, но вот мониторить ее позволял слабо. Слишком уж большой промежуток времени. В связи с этим решили, что расчет показателей станет проводиться раз в две недели, а итоги будут подводиться все так же ежеквартально. Увеличение частоты расчета действительно позволило руководителям филиалов оперативно реагировать на изменения и повысить контроль над процессами внутри их подразделений.
Вот только в головной организации мало кого радовала перспектива выполнять описанный выше процесс свода данных не ежеквартально, а каждые две недели. Как не трудно догадаться, процесс решили автоматизировать. Сроки оказались сжатыми: от момента принятия решения о переходе на новую периодичность подсчета до собственно перехода должен был пройти всего месяц. За этот срок очень желательно было придумать нечто лучшее, чем связка Excel для свода и расчета, а почты для сбора и оповещения.
Сначала шли достаточно жарки дискуссии о том, что очень-очень надо сделать автоматическим и сам расчет показателей с учетом всех их формул и источников данных. Но учитывая сжатые сроки, сложность такой функциональности и необходимость ее постоянного поддержания в актуальном состоянии удалось прийти к следующим требованиям к системе:
- Должен вестись справочник критериев, сохраняющий историю их изменения;
- Должна быть предусмотрена возможность ввода и хранения рассчитанных показателей, а также их преобразования в баллы как в той самой табличке;
- По значениям показателей должен формироваться отчет, доступный всем заинтересованным сторонам;
- Естественно все это должно быть снабжено веб-интерфейсом.
Функциональность совсем небольшая, но и времени немного.
Начало разработки
Меня всегда привлекали средства быстрой разработки и автоматической генерации интерфейсов. В тех случаях, когда надо реализовывать функциональность CRUD, очень заманчивой кажется идея, когда интерфейс и часть бизнес-логики будут предоставлены так сказать из коробки. Конечно, и интерфейс будет непритязательным и логика топорной, но для многих задач этого достаточно.
Движимый этими идеями я решил попробовать что-нибудь подобное. Существуют Spring Roo, Cuba и другие интересные инструменты, но выбор пал на OpenXava. Во-первых когда-то я уже делал на ней совсем уж простенькое приложение и остался доволен, во-вторых этот фреймворк на тот момент достаточно удачно вписывался в наш технологический стек. Кроме того, очень радует наличие краткого туториала на русском языке.
Краткое описание особенностей и возможностей OpenXava можно прочитать здесь. OpenXava — это фреймворк, реализующий автоматическое построение веб интерфейса, интегрированного с базой данных, на основе JPA, и использующий аннотации для описания правил визуализации. В основе приложения лежат бизнес-компоненты – Java-классы, содержащие информацию, необходимую для создания приложений. К такой информации относится структура данных, валидаторы, допустимые представления, маппинг на таблицы базы данных. Операции над бизнес-компонентами осуществляются посредством контроллеров, из коробки умеющих CRUD, поиск, экспорт в PDF и т.п. Приложение OpenXava представляет набор модулей. Модуль связывает бизнес-компонент с одним или более контроллерами. Для отображения интерфейса используются представления, определяемые для каждого бизнес-компонента. Ничего необычного, MVC с немного своей атмосферой.
Хранение данных
В большинстве приложений мы используем СУБД IBM DB2. Была создана небольшая база данных, хранящая справочники групп критериев и критериев, по которым ведется оценка филиалов, справочник филиалов ну и табличку, в которую заносятся рассчитанные значения критериев. Каждому критерию на определенный момент времени сопоставляется коэффициент, который будет использоваться при подсчете баллов. Каждый филиал, по каждому критерию получает оценку также на определенную дату. Данные о значениях критериев хранятся исторически, то есть актуальными на какую-либо дату данными будут являться те, которые были внесены на ближайшую дату в прошлом. Этот подход, навеянный регистрами сведений из 1С: Предприятие, мне кажется достаточно удобным: и история есть и с вопросами редактирования/удаления можно не особо париться.
Структура базы данных
CREATE TABLE SUMMAR.CLS_DEPART
(
ID BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
PARENT_ID BIGINT NOT NULL DEFAULT 0,
IS_DELETED INT DEFAULT 0,
NAME CLOB,
CODE VARCHAR(255),
PRIMARY KEY (ID)
);
CREATE TABLE SUMMAR.CLS_CRITERIA
(
ID BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
IS_DELETED INT DEFAULT 0,
NAME CLOB,
CODE VARCHAR(255),
PRIMARY KEY (ID)
);
CREATE TABLE SUMMAR.CLS_GROUP_CRITERIA
(
ID BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
IS_DELETED INT DEFAULT 0,
NAME CLOB,
CODE VARCHAR(255),
PRIMARY KEY (ID)
);
CREATE TABLE SUMMAR.REG_STATE_CRITERIA
(
ID BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
ID_CRITERIA BIGINT NOT NULL,
ID_GROUP_CRITERIA BIGINT NOT NULL,
TIME_BEGIN TIMESTAMP NOT NULL DEFAULT CURRENT TIMESTAMP,
TIME_END TIMESTAMP NOT NULL DEFAULT
'9999-12-31-23.59.59.000000000000',
TIME_CREATE TIMESTAMP NOT NULL DEFAULT CURRENT TIMESTAMP,
KOEFFICIENT DECIMAL(15, 2),
PRIMARY KEY (ID),
CONSTRAINT FK_CRITERIA FOREIGN KEY (ID_CRITERIA) REFERENCES
SUMMAR.CLS_CRITERIA(ID) ON DELETE NO ACTION ON UPDATE RESTRICT,
CONSTRAINT FK_GROUP_CRITERIA FOREIGN KEY (ID_GROUP_CRITERIA) REFERENCES
SUMMAR.CLS_GROUP_CRITERIA(ID) ON DELETE NO ACTION ON UPDATE RESTRICT
);
CREATE TABLE SUMMAR.REG_VALUE_CRITERIA
(
ID BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
ID_CRITERIA BIGINT NOT NULL,
ID_GROUP_CRITERIA BIGINT NOT NULL,
ID_DEPART BIGINT NOT NULL,
DATE_REG TIMESTAMP(12) NOT NULL DEFAULT CURRENT TIMESTAMP,
TIME_END TIMESTAMP NOT NULL DEFAULT
'9999-12-31-23.59.59.000000000000',
TIME_BEGIN TIMESTAMP NOT NULL DEFAULT CURRENT TIMESTAMP,
PERCENT DECIMAL(15, 5),
VAL DECIMAL(15, 5),
PRIMARY KEY (ID),
CONSTRAINT FK_CRITERIA FOREIGN KEY (ID_CRITERIA) REFERENCES
SUMMAR.CLS_CRITERIA(ID) ON DELETE NO ACTION ON UPDATE RESTRICT,
CONSTRAINT FK_DEPART FOREIGN KEY (ID_DEPART) REFERENCES
SUMMAR.CLS_DEPART(ID) ON DELETE NO ACTION ON UPDATE RESTRICT,
CONSTRAINT FK_GROUP_CRITERIA FOREIGN KEY (ID_GROUP_CRITERIA) REFERENCES
SUMMAR.CLS_GROUP_CRITERIA(ID) ON DELETE NO ACTION ON UPDATE RESTRICT
);
Для того, чтобы получить из базы заветный отчет о показателях филиалов были созданы хранимые функции, результаты которых уже мапятся на Java-класс. Функции выглядят примерно так.
Сначала получим все действующие на дату критерии, а также актуальные на эту дату коэффициенты критерия
CREATE OR REPLACE FUNCTION
SUMMAR.SLICE_STATE_ALL_CRITERIA (
PMAX_TIME TIMESTAMP
)
RETURNS TABLE (
ID_CRITERIA BIGINT,
ID_GROUP_CRITERIA BIGINT,
TIME_BEGIN TIMESTAMP,
TIME_END TIMESTAMP,
TIME_CREATE TIMESTAMP,
KOEFFICIENT DECIMAL(15, 2)
)
LANGUAGE SQL
RETURN
SELECT
RSC.ID_CRITERIA,
RSC.ID_GROUP_CRITERIA,
RSC.TIME_BEGIN,
RSC.TIME_END,
RSC.TIME_CREATE,
RSC.KOEFFICIENT
FROM
SUMMAR.REG_STATE_CRITERIA AS RSC
INNER JOIN
(
SELECT
ID_CRITERIA,
MAX(TIME_BEGIN) AS TIME_BEGIN
FROM
(
SELECT DISTINCT
ID_CRITERIA,
TIME_BEGIN
FROM
SUMMAR.REG_STATE_CRITERIA
WHERE
TIME_BEGIN < PMAX_TIME
AND TIME_END > PMAX_TIME
)
AS SL
GROUP BY
ID_CRITERIA
)
AS MAX_SLICE
ON RSC.ID_CRITERIA = MAX_SLICE.ID_CRITERIA
AND RSC.TIME_BEGIN = MAX_SLICE.TIME_BEGIN ;
Теперь получим на эту же дату значения всех критериев по всем филиалам
CREATE OR REPLACE FUNCTION
SUMMAR.SLICE_VALUE_ACTUAL_ALL_CRITERIA_ALL_DEPART_WITH_NAMES (
PMAX_TIME TIMESTAMP
)
RETURNS TABLE (
ID_CRITERIA BIGINT,
ID_GROUP_CRITERIA BIGINT,
ID_DEPART BIGINT,
DATE_REG TIMESTAMP,
PERCENT DECIMAL(15, 2),
VAL DECIMAL(15, 2),
KOEFFICIENT DECIMAL(15, 2),
CRITERIA_NAME CLOB,
CRITERIA_CODE VARCHAR(255),
GROUP_CRITERIA_NAME CLOB,
GROUP_CRITERIA_CODE VARCHAR(255),
DEPART_NAME CLOB,
DEPART_CODE VARCHAR(255),
DEPART_CODE_INT INT
)
LANGUAGE SQL
RETURN
SELECT
CDEP.ID_CRITERIA,
COALESCE(VALS.ID_GROUP_CRITERIA, 0) AS ID_GROUP_CRITERIA,
CDEP.ID_DEPART,
VALS.DATE_REG,
COALESCE(VALS.PERCENT, 0.0) AS PERCENT,
COALESCE(VALS.VAL, 0.0) AS VAL,
COALESCE(VALS.KOEFFICIENT, 0.0) AS KOEFFICIENT,
CDEP.CRITERIA_NAME,
CDEP.CRITERIA_CODE,
COALESCE(VALS.GROUP_CRITERIA_NAME, '') AS GROUP_CRITERIA_NAME,
COALESCE(VALS.GROUP_CRITERIA_CODE, '') AS GROUP_CRITERIA_CODE,
CDEP.DEPART_NAME,
CDEP.DEPART_CODE,
CDEP.DEPART_CODE_INT
FROM
(
SELECT
CCRT.ID AS ID_CRITERIA,
CCRT."NAME" AS CRITERIA_NAME,
CCRT.CODE AS CRITERIA_CODE,
CDEP.ID AS ID_DEPART,
CDEP."NAME" AS DEPART_NAME,
CDEP.CODE AS DEPART_CODE,
CAST (CDEP.CODE AS INT) AS DEPART_CODE_INT
FROM
SUMMAR.CLS_DEPART AS CDEP,
(
SELECT
*
FROM
SUMMAR.CLS_CRITERIA AS CC
INNER JOIN
TABLE(SUMMAR.SLICE_STATE_ALL_CRITERIA (PMAX_TIME)) AS ACTC
ON CC.ID = ACTC.ID_CRITERIA
WHERE
CC.IS_DELETED = 0
)
AS CCRT
WHERE
CDEP.IS_DELETED = 0
)
AS CDEP
LEFT JOIN
(
SELECT
VALS.ID_CRITERIA,
VALS.ID_GROUP_CRITERIA,
VALS.ID_DEPART,
VALS.DATE_REG,
VALS.PERCENT,
VALS.VAL,
VALS.KOEFFICIENT,
CGRT."NAME" AS GROUP_CRITERIA_NAME,
CGRT.CODE AS GROUP_CRITERIA_CODE
FROM
TABLE(SUMMAR.SLICE_VALUE_ACTUAL_ALL_CRITERIA (PMAX_TIME)) AS VALS
INNER JOIN
SUMMAR.CLS_GROUP_CRITERIA AS CGRT
ON VALS.ID_GROUP_CRITERIA = CGRT.ID
)
as VALS
ON CDEP.ID_DEPART = VALS.ID_DEPART
AND CDEP.ID_CRITERIA = VALS.ID_CRITERIA
;
В итоговом запросе пронумеруем значения показателей, ранжируем их и найдем минимальный и максимальный, это понадобится, чтобы потом рассчитать места
SELECT
ROW_NUMBER() OVER() AS ID_NUM,
RANK() OVER(
PARTITION BY ID_CRITERIA
ORDER BY VAL DESC
) AS RATING,
CASE
WHEN MAX(RANK() OVER(
PARTITION BY ID_CRITERIA
ORDER BY VAL DESC
)
) OVER() = RANK() OVER(
PARTITION BY ID_CRITERIA
ORDER BY VAL DESC
)
THEN 1
ELSE 0
END AS MAX_RATING,
CASE
WHEN MIN(RANK() OVER(
PARTITION BY ID_CRITERIA
ORDER BY VAL DESC
)
) OVER() = RANK() OVER(
PARTITION BY ID_CRITERIA
ORDER BY VAL DESC
)
THEN 1
ELSE 0
END AS MIN_RATING,
VALS.*
FROM TABLE(SUMMAR.SLICE_VALUE_ACTUAL_ALL_CRITERIA_ALL_DEPART_WITH_NAMES (?))
AS VALS
ORDER BY GROUP_CRITERIA_CODE,
CRITERIA_CODE,
DEPART_CODE_INT
Перенос части бизнес-логики в СУБД оказывается достаточно оправданным, особенно, когда дело касается подготовки данных для разных отчетов. Операции получается записать в более лаконичной и естественной форме, на Java такие манипуляции с данными потребовали бы и большего объема кода и определенных усилий по его структуризации. Хотя относительно сложные или нетривиальные операции все же проще запрограммировать на Java. Поэтому в нашем приложении в отношении выборки данных используется подход, когда соединение наборов данных, отсечение условиям и некоторые операции, которые можно выполнить оконными функциями, выполняются в хранимых функциях и процедурах, а более сложная логика реализуется в приложении.
Приложение
Как я уже говорил, для реализации приложения использовалась OpenXava. Чтобы получить с ее помощью типовой интерфейс и CRUD из коробки необходимо выполнить некоторые действия.
Начнем с того, что в web.xml надо описать фильтр и сервлет из аддона, осуществляющего навигацию по приложению:
web.xml
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<filter>
<filter-name>naviox</filter-name>
<filter-class>com.openxava.naviox.web.NaviOXFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>naviox</filter-name>
<url-pattern>*.jsp</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>naviox</filter-name>
<url-pattern>/modules/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
</filter-mapping>
<filter-mapping>
<filter-name>naviox</filter-name>
<servlet-name>naviox</servlet-name>
</filter-mapping>
<filter-mapping>
<filter-name>naviox</filter-name>
<servlet-name>module</servlet-name>
</filter-mapping>
<servlet>
<servlet-name>naviox</servlet-name>
<servlet-class>com.openxava.naviox.web.NaviOXServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>naviox</servlet-name>
<url-pattern>/m/*</url-pattern>
</servlet-mapping>
</web-app>
Далее в файле controllers.xml определим используемые в приложении контроллеры. В нашем случае достаточно самого простого:
controllers.xml
<controllers>
<controller name="Typical_View">
<extends controller="Navigation"/>
<extends controller="CRUD"/>
<extends controller="ExtendedPrint"/>
</controller>
</controllers>
В приведенном контроллере объединены функции включенных в OpenXava по умолчанию контроллеров, о функциях которых нетрудно догадаться из названий.
И, наконец, в файле application.xml свяжем созданный контроллер и модель. Примерно так:
application.xml
<application name="summar">
<module name="RegValueCriteria">
<model name="RegValueCriteria"/>
<controller name="Typical_View"/>
</module>
</application>
Как было сказано выше в основе приложения лежат бизнес-компоненты, составляющие модель приложения. Для примера рассмотрим связанный с контроллером в application.xml компонент RegValueCriteria. Этот компонент описывает значение критерия по филиалу (для краткости оставлено только описание полей класса, а методы типа геттеров и сеттеров опущу):
Класс компонента
@Entity
@Table(name = "REG_VALUE_CRITERIA", catalog = "", schema = "SUMMAR")
@XmlRootElement
@Views({
@View(members = "idCriteria [idCriteria];"
+ "idGroupCriteria [idGroupCriteria];"
+ "idDepart [idDepart];"
+ "data [dateReg, percent, val]"),
@View(name="massReg",
members = "idDepart.name, percent, val")
})
@Tab(properties=
"idDepart.name, idCriteria.name, idGroupCriteria.name, dateReg, percent, val"
)
public class RegValueCriteria implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@NotNull
@Column(name = "DATE_REG")
@Temporal(TemporalType.TIMESTAMP)
@DefaultValueCalculator(CurrentDateCalculator.class)
@Stereotype("DATETIME")
private Date dateReg;
@Column(name = "PERCENT")
@OnChange(OnChangePercentAction.class)
private BigDecimal percent;
@Column(name = "VAL")
private BigDecimal val;
@JoinColumn(name = "ID_CRITERIA", referencedColumnName = "ID")
@ManyToOne(optional = false)
@DescriptionsList(
descriptionProperties="name"
)
@OnChange(OnChangeClsCriteriaAction.class)
private ClsCriteria idCriteria;
@JoinColumn(name = "ID_GROUP_CRITERIA", referencedColumnName = "ID")
@ManyToOne(optional = false)
@DescriptionsList(
descriptionProperties="name"
)
private ClsGroupCriteria idGroupCriteria;
@JoinColumn(name = "ID_DEPART", referencedColumnName = "ID")
@ManyToOne(optional = false)
@DescriptionsList(
descriptionProperties="name"
)
private ClsDepart idDepart;
}Кроме привычных аннотаций JPA. Можно заметить и аннотации OpenXava. Их стоит рассмотреть подробнее.
Аннотация
@View позволяет управлять форматом представления полей класса, при этом с помощью специального синтаксиса в виде квадратных скобок поля можно объединять в группы и компоновать их горизонтально и вертикально с помощью символов , и ;. Если для одного компонента необходимо задать несколько отображений, то аннотации @View группируются с использованием аннотации @View. В нашем примере свойства были оформлены так:@View(members = "idCriteria [idCriteria];"
+ "idGroupCriteria [idGroupCriteria];"
+ "idDepart [idDepart];"
+ "data [dateReg, percent, val]")А выглядит это так:

Неказисто, зато с минимумом усилий. Однако есть способы немного «оживить» форму.
Для того, чтобы дата регистрации была заполнена при создании компонента использована аннотация
@DefaultValueCalculator, которая вызывает специальный объект-калькулятор. Здесь использован калькулятор из самой OpenXava, но можно сделать и кастомный. Для отображения даты с использованием соответствующего элемента управления использована аннотация @Stereotype.Для настройки выпадающих списков, содержащих связанные объекты, применяется аннотация
@DescriptionsList, в которой можно указать, какое именно свойство будет отображено в списке.С помощью аннотаций можно реализовать и кое-какую бизнес-логику самой формы. Например, чтобы при изменении процента значение рассчитывалось автоматически с учетом коэффициента критерия можно применить аннотацию
@OnChange для поля BigDecimal val. Чтобы аннотация @OnChange работала ей необходимо указать на класс, имплементирующий интерфейс OnChangePropertyBaseAction. В классе должен быть реализован единственный метод execute(), в котором входные данные берутся из представления, производится расчет и подсчитанное значение записывается обратно в представление:Класс-наследник OnChangePropertyBaseAction
public class OnChangePercentAction extends OnChangePropertyBaseAction{
@Override
public void execute() throws Exception {
BigDecimal percent = (BigDecimal)getNewValue();
if (percent != null){
Map value = (Map)getView().getValue("idCriteria");
if (value != null){
Long idCriteria = (Long)value.get("id");
Query query = XPersistence.getManager().createNativeQuery(
"SELECT KOEFFICIENT FROM SUMMAR.SLCLA_STATE_CRITERIA WHERE ID_CRITERIA = ?");
query.setParameter(1, idCriteria);
List<?> list = query.getResultList();
if (list != null && !list.isEmpty()){
BigDecimal koef = (BigDecimal) list.get(0);
BigDecimal vl = koef.multiply(percent);
getView().setValue("val", vl);
}
}
}
}
}Для табличного представления данных используется аннотация
@Tab, которая позволяет перечислить те свойства объектов, которые будут выведены в табличном представлении. В нашем примере аннотация была оформлена так:@Tab(properties=
"idDepart.name, idCriteria.name, idGroupCriteria.name, dateReg, percent, val"
)Выглядеть это будет следующим образом

Радует наличие фильтров, пагинации и экспорта из коробки, однако многие детали требуют доработки напильником.
Подобным образом построена работа и с другими компонентами. Использование OpenXava позволило резко снизить трудозатраты на реализацию функций CRUD и большей части пользовательского интерфейса. Использование действий из предопределенных контроллеров и аннотаций для построения форм сильно экономит время, если не придираться к деталям и не пробовать реализовать что-то сложнее формы ввода с несколькими событиями. Хотя может быть дело в опыте.
То, ради чего все затевалось
Помните, для чего затевалось приложение? Да-да для того, чтобы табличка с показателями не героически сводилась в Excel, а создавалась автоматически на основе введенных данных. В окне браузера сводная таблица стала выглядеть так:


Детали реализации приводить не буду, поскольку с ней все не очень хорошо и смесь JSP со сгенерированным при запросе данных HTML, не то, чем стоит делиться с широкой публикой. В то же время сама выборка данных была продемонстрирована выше.
Однако хочу остановиться на одной интересной детали. Когда собирались требования к приложению, руководство очень хотело, чтобы помимо сводного отчета значения отдельного показателя можно было вывести в виде карты региона, разбитого на районы с указанием места и балла соответствующего филиала. Кто по карте узнал регион – тот молодец =)

С одной стороны, требование было опциональным, но с другой стороны и картинка обещала быть наглядной, и с точки зрения реализации интересно было попробовать. После некоторых раздумий пришла идея найти изображение региона в формате SVG и сделать из него XSLT-шаблон.
Полученный шаблон легко заполняется данными, а после этого конвертируется в PNG.
Сначала с помощью запроса, описанного выше, делается выборка данных, полученные данные преобразуются в объект такого класса:
Классы для вывода данных на карту
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "VisualisedValuesCriteria")
public class VisualisedValuesCriteria {
private XMLGregorianCalendar date;
private String criteriaName;
private String koefficient;
private List<VisualizedValueCriteria> departValues;
public XMLGregorianCalendar getDate() {
return date;
}
public void setDate(XMLGregorianCalendar date) {
this.date = date;
}
public String getCriteriaName() {
return criteriaName;
}
public void setCriteriaName(String criteriaName) {
this.criteriaName = criteriaName;
}
public String getKoefficient() {
return koefficient;
}
public void setKoefficient(String koefficient) {
this.koefficient = koefficient;
}
public List<VisualizedValueCriteria> getDepartValues() {
if (departValues == null){
departValues = new ArrayList<>();
}
return departValues;
}
public void setDepartValues(List<VisualizedValueCriteria> departValues) {
this.departValues = departValues;
}
}
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
public class VisualizedValueCriteria {
private String departName;
private String departCode;
private String value;
private String percent;
private String colorCode;
public String getDepartName() {
return departName;
}
public void setDepartName(String departName) {
this.departName = departName;
}
public String getDepartCode() {
return departCode;
}
public void setDepartCode(String departCode) {
this.departCode = departCode;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public String getPercent() {
return percent;
}
public void setPercent(String percent) {
this.percent = percent;
}
public String getColorCode() {
return colorCode;
}
public void setColorCode(String colorCode) {
this.colorCode = colorCode;
}
}
}Далее преобразуем объект в XML;
Преобразование
Private String marshal (VisualisedValuesCriteria obj){
final Marshaller marshaller =
JAXBContext.newInstance(VisualisedValuesCriteria.class).createMarshaller();
marshaller.setEventHandler(new DefaultValidationEventHandler());
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
StringWriter writer = new StringWriter();
marshaller.marshal(obj, writer);
return writer.toString();
}А теперь возьмем полученный XML, подготовленный XSLT-шаблон, применим преобразование и на выходе получим svg:
Получаем svg
String xml = marshal(obj);
TransformerFactory factory = TransformerFactory.newInstance();
FileInputStream xsltFis = new FileInputStream("C:\\TEMP\\map_xsl.svg");
InputStreamReader xsltIn = new InputStreamReader(xsltFis, "UTF-8");
Source xslt = new StreamSource(xsltIn);
Transformer transformer = factory.newTransformer(xslt);
InputStream xmlIn = new ByteArrayInputStream( xml.getBytes( "UTF-8" ) );
Source text = new StreamSource(xmlIn);
String filename = "map" + System.currentTimeMillis() + ".svg";
String filePath = "C:\\TEMP\\" + filename;
transformer.transform(text, new StreamResult(new File(filePath)));В принципе на этом можно было бы и остановиться, браузеры без проблем отображают SVG. Но описанные отчеты получались еще и через Телеграм-бота, поэтому SVG надо сконвертировать в какой-нибудь формат типа JPEG или PNG. Для этого используем Apache Batik
Преобразуем в PNG
private String convertToPNG(final String svg, final String filename, final String filePath){
String png = filePath + filename + ".png";
try {
PNGTranscoder trancoder = new PNGTranscoder();
String svgURI = new File(svg).toURL().toString();
TranscoderInput input = new TranscoderInput(svgURI);
OutputStream ostream = new FileOutputStream(png);
TranscoderOutput output = new TranscoderOutput(ostream);
trancoder.transcode(input, output);
ostream.flush();
ostream.close();
return filename + ".png";
} catch (MalformedURLException ex) {
Logger.getLogger(ActualCriteriaValueGraphicServlet.class.getName()).log(Level.SEVERE, null, ex);
} catch (FileNotFoundException | TranscoderException ex) {
Logger.getLogger(ActualCriteriaValueGraphicServlet.class.getName()).log(Level.SEVERE, null, ex);
} catch (IOException ex) {
Logger.getLogger(ActualCriteriaValueGraphicServlet.class.getName()).log(Level.SEVERE, null, ex);
}
return null;
}
Отчет в виде карты готов. Его можно и через браузер посмотреть и у телеграм-бота запросить. По-моему неплохо.
Заключение
К назначенному сроку мы успели и уже в марте 2017 года показатели эффективности вместо Excel стали регулярно заноситься в созданную систему. С одной стороны, задача-максимум решена не была, наиболее сложная часть расчетов показателей так и выполняется вручную. Но с другой стороны, реализация этих расчетов несла риски постоянной доработки. Кроме того, даже созданный простой интерфейс для сбора данных снимал огромное количество вопросов с постоянными изменениями, контролем версий и сводом экселевской таблицы. Большое количество ручной работы, проверок и перепроверок было убрано.
Нельзя не сказать, что интерфейс на Open Xavа не слишком порадовал пользователей. В первое время было много вопросов к его особенностям. В какой-то момент пользователи начали жаловаться, что на ввод данных уходит слишком много времени и вообще «мы хотим как в Экселе, только программу». Пришлось даже провести мониторинг скорости ввода на основе данных о времени создания записей. Этот мониторинг показал, что даже в самых тяжелых случаях пользователи не тратили на ввод более 15 минут, а обычно укладывались в 5-7, при том, что им необходимо было вносить данные по 22 филиалам. Такие показатели кажутся вполне приемлемыми.
Однако, хочется отметить две вещи:
- Open Xavа неплохо показала себя как средство для быстрого создания интерфейса. Я бы даже сказал прототипа интерфейса. Также ее безусловным плюсом является общая упорядоченность и регулярность. Все формы в приложении создаются по единообразным принципам, что позволяет не придумывать велосипедов разработчику там, где не надо, а пользователю иметь дело с типовыми наборами форм. Однако попытки реализовать более сложную логику или изменить элементы управления под себя натолкнули нас на ряд проблем, с которыми за отведенное время справиться не удалось. Скорее всего, мы просто не разобрались, да и целью являлось создание простого CRUD-интерфейса с минимумом усилий. Для себя я делаю вывод, что Open Xavа интересный инструмент, в котором просто делать простые вещи, но если необходимо делать что-то сложное, то я предпочту потратить больше сил на создание клиентской части с помощью ExtJS или React, но иметь при этом большую гибкость.
- Даже уверенные пользователи тяжело воспринимают новые интерфейсы. Это конечно не секрет. По-моему мнению это в первую очередь вызвано отсутствием понимания системности многих интерфейсов. Для многих – любое приложение набор экранов, каждый из которых уникален и работает по своим неведомым принципам: например, есть форма со списком объектов/строк(форма списка), но для очень многих пользователей совсем не очевидно, что каждая такая форма в приложении может обладать единообразными функциями фильтрации, пагинации, сортировки и в целом одинаковым поведением, дополненным специфическими функциями. Усугубляется это и тем, что большое количество корпоративного программного обеспечения представляют собой почти стихийное нагромождение кнопок и форм, приправленное невнятной документацией в стиле «Нажмите эту кнопочку». С этой точки зрения интерфейсы создаваемые той же Open Xavа дисциплинируют разработчиков пользователей, создают больше порядка в голове. Правда, при таком подходе волшебные кнопочки никуда не исчезают, а становятся аккуратно разложенными по формам.
Если же говорить о выгодах для организации в целом, то после внедрения приложения, как и предполагалось, степень контроля повысилась. Руководители на местах получили инструмент мониторинга показателей, с помощью которого они могут влиять на работу в более оперативном режиме, сравнивать показатели за различные периоды, не путаясь при этом в потоке рассылаемых файлов. Заинтересованность руководителей в постоянном и неусыпном контроле своего филиала была обнаружена нами весьма интересным способом: просматривая логи Telegram-бота мы заметили, что некоторые отчеты получались в 4 или 5 часов утра. Сразу видно, кто интересуется работой.
На этом все. Буду признателен за конструктивную обратную связь!








