Комментарии 38
Лайфхак: Не забываем про разную длину волн и для каждой частоты рассчитываем свою расчетную задержку tnКак я понимаю, задержка как раз от частоты то и не зависит. Просто на разных частотах фаза получится разная.
А вы случайно не знаете доступные на рынке готовые микрофоны для конференций, построенные по такому принципу? В идеале хотелось бы, чтобы один такой микрофон покрывал полусферу радиусом метра 4.
Да и вопрос выбора сложнее чем кажется. Вопрос о деталях скрыт в слове «покрывал»:
слушать нужно один источник, или многоканальный, да и нужно ли отслеживать перемещения источника.
Обычно используется несколько направленных микрофонов (под разными углами в одном корпусе с микрофоном с круговой направленностью), и приоритетная динамическая обработка. Для подавления эха и акустической обратной связи, используется цифровая обработка в которой иногда используют сигнал с микрофона круговой направленности.
Смотрите что предлагают Shure, Beyerdynamic.
сравнивали отладочные платыТолько теоретически, бабло и возможность доставки понимаете ли.
системы активного шумоподавления (не наушники, а в пространстве)Шот система телепатии дала сбой. Уточните, шумы собрались прям в определенной области давить? Если да, то это романтично называется «материализация фантома». И это тема прям не ответа на коммент, а чуть поширше.
групповая задержка
рецепт MEMS микрофоны. И высокие частоты дискретизации. И обработка, чтоб получить желаемый, а не такой как получился на картинке, эффект, на частоте гдет от 44100
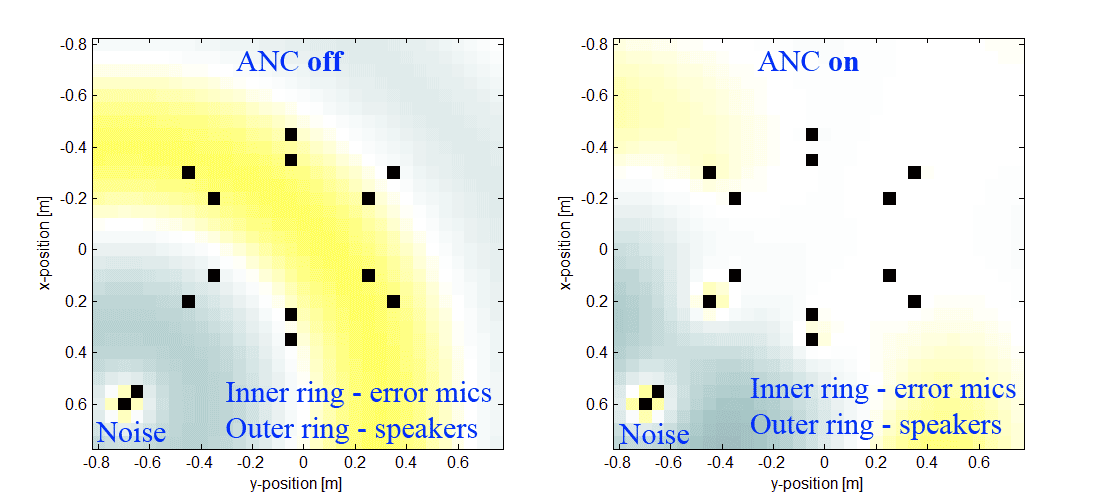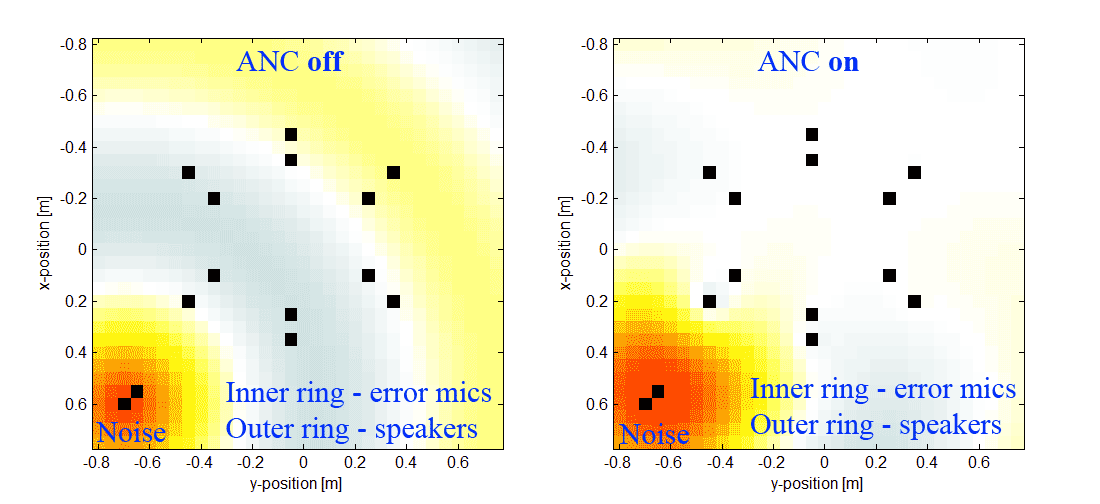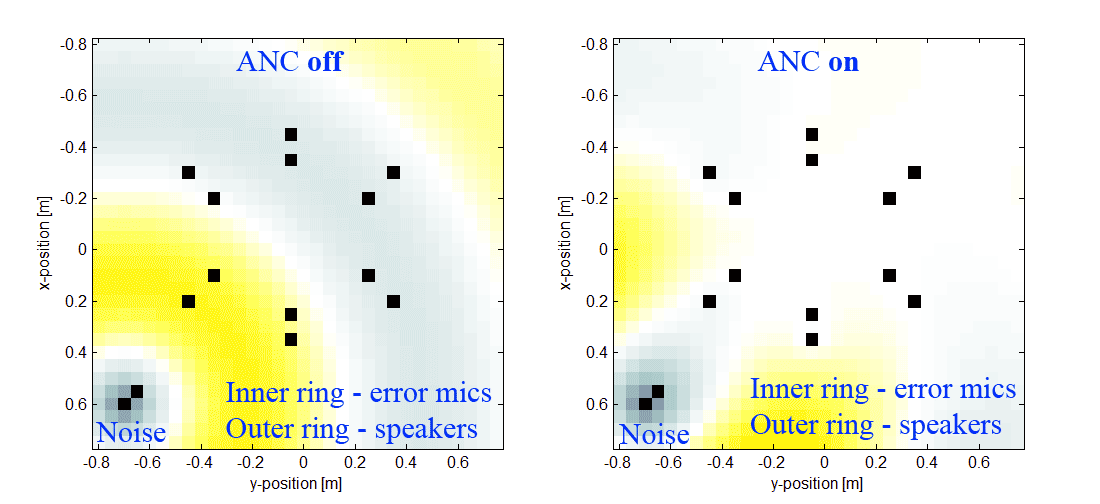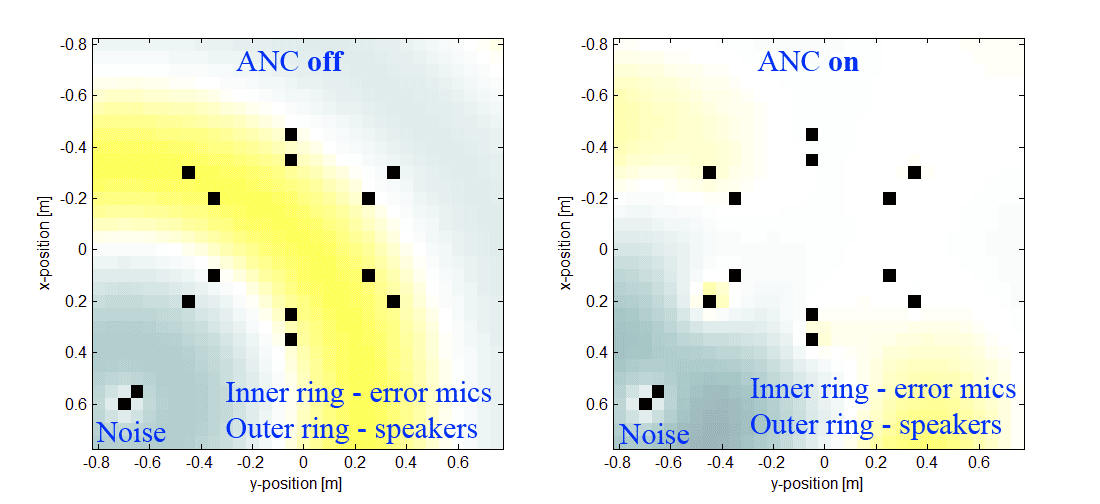

Есть еще и видос реальной работающей системы, которая слегка снижает шум кухонного комбайна. Хочется отойти от отладочной платы и сделать свою железку.
И нюансы воспроизведения сигнала, особенно на НЧ, фигня в том что типичный конструктор узч полагает что ему достаточно просто усилить сигнал с минимальными искажениями, наивный, полагает что дельта напряжения на выходе усилителя, даст нам дельту давления, и она её конечно даст, но лишь в некоторых случаях, и точную лишь приблизительно…
Серьёзно, я начал играться в эти игры в начале нулевых, ну очень соблазнительно было поиграться с фар (хотя-бы оффлайн), когда есть возможность качественной многоканальной записи…
… записываешь фоны для кино, а потом синхронизируешь с движением камеры, или какой-нибудь фестиваль барочной музыки в старинном соборе, можно и ревер задавить и микрофоны расставить постфактум, а уж подавление акустических шумов в коридоре казалось вообще детской забавой, казалось…
А насчет желания отойти от опытов на девборде и про сделать свою железку — я как раз работаю на фирме по производству железок. Так что немного в теме. Можем обсудить, может подскажу чего.
Про картинки — для понимания и советов надо подробней про использованый вами девборд, излучатели. О кстати и видос показать можно. Если тайна — то в личку.
Примерная диаграмма направленности будет выглядеть как то так
Так оно выглядит на какой-то конкретной, достаточно высокой частоте!
Там далее по ссылке, более правдивые картиночки, с учётом апературы и количества микрофончиков, при самом тупом их расположении. Но и тут ложка дёгдя, про рост электронных шумов с ростом числа микрофонов ни гу-гу, а частотное разрешение на графиках линейно, а не логарифмично как принято в звуковых измерениях, и принято не просто так, ибо слуховые анализаторы у человеков имеют совсем не линейное разрешение по частоте, и у меня есть сильные подозрения что это умышленно, ибо на низких частотах, всё совсем не весело :-)
… вот и получается, что борьба-то не за что, на самом деле, традиционные схемы построения направленных микрофонов ни чем не хуже, а только лучше по шумам и искажениям, ибо физику не обманешь, хочешь хорошую направленность бери большую апературу, хочешь линейности ачх (а здесь об это вообще не упоминается), располагай элементы с умом, и вообще всё придумано до нас, на самом деле
хочешь линейности ачх
У меня вообще про методы формирования луча вскользь, так как писал в популярном стиле, но про методы формирования луча, отличные от DAS такие как JIO-RLS, вроде ж упомянул.
обычными методами добится сравнимого с матричным микрофоном качества сложно
Многие производители оборудования и просьюмеры (в том числе пользователи и конструкторы спец.средств) не согласятся, даже если чисто за сигнал\шум говорить, ведь и с одного микрофона можно стационарный шум съесть…
Но хорошо яичко ко христову дню, для мобильных девайсов где звук перед передачей жестоко оптимизируют и пожмут, для распознования где направление может иметь значение, но опять-же, по уму надо работать с «акустическим полем» а не симулировать направленный микрофон…
и с одного микрофона можно стационарный шум съесть
Можно. Но у каждого «сьесть» есть своя цена. А с акустическим полем работать, имея n распределенных микрофонов, с известными характеристиками, с высокой частотой дискретизации как то проще. Да, и с достаточными вычислительными ресурсами.
там еще много всякого интересного.
Из из не самоделок стрелковых — WALKER`S Alpha 360 Quad.
Может со временем что то свое застартаплю
У меня есть Alexa Echo и действительно, когда включен телевизор кодовое слово колонка может определить и активизироваться, а вот потом, когда она начинает делать анализ в облаке на фоне шумов она перестает что-то понимать, несмотря на наличие 8 микрофонов и всяких хитрых методов обработки.
В таком случае приходится или кричать или фоновый звук уменьшать.
И мне кажется что просто математикой эту проблему не решить.
Так вот, бредовая идея — вместо того чтобы затачиваться в обработку, в физику и в матан, не проще ли взять и раскидать по комнате еще несколько дополнительных микрофонов и анализировать инфу с них для эффективного шумоподавления и определения источника голосовых команд?
Сейчас есть недорогие сенсоры с микрофоном и с вайфай на борту.
Вообще все это напоминает ситуацию с Wi-Fi в части детекции слабого сигнала от клиента.
По моему и термин beamforming впервые появился именно у производителей вайфай железок и в принципе он должен был решить похожую проблему — «услышать» слабый сигнал от смартфона.
Но такую проблему лучше решает в Wi-Fi или меш сеть или WDS, т.е. тупо увеличиваем покрытие количеством точек и все это работает лучше beamforminga.
Здесь можно сделать тоже самое — разбросать микрофоны с вай-фай/блютус по комнате, которые бы слали все на центральную станцию и обрабатывать все соответствующим алгоритмом.
взять и раскидать по комнате еще несколько дополнительных микрофонов
Практикую такой подход. Распределенная сеть микрофонов. Кстати доп микрофоны — те же matrix voice только модификация с ESP32
По моему и термин beamforming впервые появился именно у производителей вайфай железок
Этот термин появился в радиолокации и эхолокации лет наверное 60 назад.
Чем пользуется автор и что у него есть рассказать по этому вопросу?
Что касается парадигмы DOA и beamformer. Соотнести грамотно ширину бимформера и ошибку по определению направления так, чтобы попадать туда, куда нужно — основное противоречие. Начать статью я бы посоветовал с разъяснения и сравнения подходов и аппаратных решений, разделив их на Near Field, Far Field. Хочу отметить, что есть решения их 2х микрофонов, которые решают задачу качественнее, чем те массивы, которые вы в статье описываете и даете на них ссылки. Без решения задачи создания системы распознавания речи работа с аппаратными решениями лишена полностью смысла, а в плане качестве разочарует даже при попытке это проанализировать на слух.
есть решения их 2х микрофонов
это как раз в основном Near Field, есть решения на 2х в Far, но обычно требуются достаточные расстояния между микрофонами.
и это уже работает.
А какие критерии оценки?
И по возможности не про распознавание, а про различение источников
Основной критерий — сколько процентов слов распознается верно. Другие критерии не нужны. Методики испытаний разные, конкретно для 2х микрофонов я лично делал пассивный неподвижный источник шума и говорящего. Дистанции разные.
основной частый способ DOA это анализ корреляций и другого разного между парами микрофонов (обычно противолежащими по диаметру). И в круговом массиве можно набрать статистику от пар с расстоянием между микрофонами — от диаметра (макс для данного размещения) и до минимального между микрофонами — если брать пары по хордам.
Так вот, проблема пары, по моему опыту и по мнению, в разном качестве различения направления, в зависимости от ориентации пары на источник. И как раз потому и анализирую несколько пар. Предел ставит вычислительная сложность анализа. Минимум естественно — на одной паре.
касается парадигмы DOA и beamformer
Может, для разьяснение некоторых нюансов их взаимоотношений напишу еще статью.
Как тема, например: комбинирование расстояния и направления для улучшеной локализации.
Проблем, если много источников, и они широкополосные, масса. И еще ж с нашей железяки, требуют в это время играть музыку или говорить чего нибудь.
И вдобавок, мы в основном, снимаем звук не в акустически нейтральном помещении, то есть еще и добавляется интерференция не только с соседними источниками, но и с отражениями.
Ну и добавочно, некоторые источники не хотят спокойно стоять, а еще и перемещаются. Рассматриватся будет состояние дел вообще и мой рецепт способ играть в DOA в частности.
Это может разьяснит, что там происходит под капотом как вовремя начального определения слова активации, так и во время передачи потока на распознавание
Far Fields mic (Mic array) — незаметный герой в умной колонке