Доброе время суток, читатель. Возможно, вы уже читали мои предыдущие статьи, и знаете, что я занимаюсь написанием собственной ОС. Сегодня мы поговорим, и рассмотрим несложный и достаточно быстрый алгоритм для управления памятью — менеджер памяти — критически важная часть ОС, ведь быстрая, надежная и нерастратная работа с памятью залог хорошей ОС.
Искал я несложные и адекватные идеи для менеджера и в рунете, и на англоязычных сайтах — всё никак не мог найти никаких хороших статей про адекватный, работающий не за O(N) аллокатор. Что же, сегодня мы рассмотрим более хорошую идею для менеджера памяти, продолжение помещаю под кат.
Из вики: Менеджер памяти — часть компьютерной программы (как прикладной, так и операционной системы), обрабатывающая запросы на выделение и освобождение оперативной памяти или (для некоторых архитектур ЭВМ) запросы на включение заданной области памяти в адресное пространство процессора.
Предлагаю так же перед продолжением прочитать эту статью.
Что же, наверное самый простой из всех аллокаторов — Watermark Allocator. Суть его примерно следующая: вся память разбита на блоки, у блока есть заголовок, в котором лежит размер этого и предыдущего блока, статус блока(занят/свободен), зная адрес блока мы за O(1) можем получить адрес следующего и предыдущего блока.
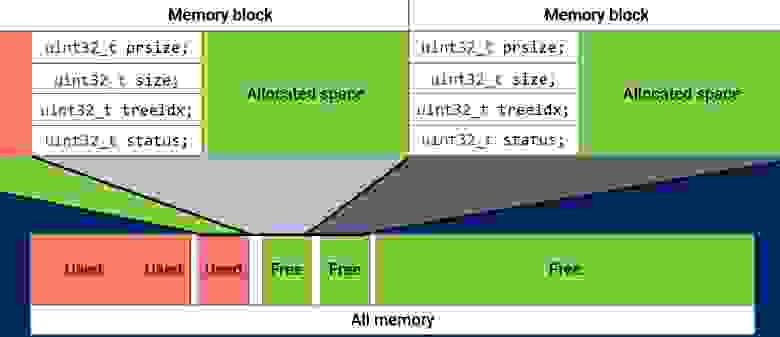
Но, как вы понимаете, могут начать образовываться дыры, в которых 2 и более свободных блоков — память дефрагментированна, при высвобождении можно просматривать соседние блоки, и в случае, когда один или два свободны — мержить их в один.
Мы знаем, что нам надо искать только среди свободных блоков. Бегать только по свободным улучшает скорость в среднем в два раза, но это всё равно линия. Что же, зачем нам бегать по всем блокам, ища размер, если мы можем организовать дерево из свободных блоков! Изначально у нас только один свободный блок, а дальше мы добавляем свободные блоки в бинарное дерево поиска, ключом будет — размер блока. Таким образом, чтобы выделить память нам достаточно найти блок в дереве, у которого размер больше или равен тому, что нам нужен. Это мы спокойно делаем за O(log N), просто спускаясь по дереву вниз. Дальше мы либо режем блок на два, либо полностью отдаем его тому, кто запросил память. Дальше мы удаляем блок из дерева за O(1). И, если надо, вставляем оставшуюся часть блока обратно за O(log N). Для высвобождения нам достаточно вставить блок обратно, и не надо забывать про фрагментацию.
Логично, что использовать простое дерево не надо, надо использовать самобалансирующееся дерево, Red-Black или AVL. Хранить дерево блоков можно в статическом массиве, или же придумать как это сделать по-другому.
Собственно, код:
Удачи и этичного хакинга! Любая объективная критика приветствуется, цель статьи не сказать, что это вах какой аллокатор, а просто рассказать о аллокаторе, который будет лучше, чем тупые реализации простых аллокаторов.
Искал я несложные и адекватные идеи для менеджера и в рунете, и на англоязычных сайтах — всё никак не мог найти никаких хороших статей про адекватный, работающий не за O(N) аллокатор. Что же, сегодня мы рассмотрим более хорошую идею для менеджера памяти, продолжение помещаю под кат.
Теория
Из вики: Менеджер памяти — часть компьютерной программы (как прикладной, так и операционной системы), обрабатывающая запросы на выделение и освобождение оперативной памяти или (для некоторых архитектур ЭВМ) запросы на включение заданной области памяти в адресное пространство процессора.
Предлагаю так же перед продолжением прочитать эту статью.
Watermak Allocator
Что же, наверное самый простой из всех аллокаторов — Watermark Allocator. Суть его примерно следующая: вся память разбита на блоки, у блока есть заголовок, в котором лежит размер этого и предыдущего блока, статус блока(занят/свободен), зная адрес блока мы за O(1) можем получить адрес следующего и предыдущего блока.

Выделение памяти
Для выделения памяти нам просто напросто нужно бежать по блокам, и искать блок, размер которого больше или равен размеру требуемой для выделения памяти. Как вы уже поняли, асимптотика O(N) — плохо.Высвобождение памяти
Для высвобождения памяти нам достаточно установить статус блока как «свободный» — O(1) — супер!Но, как вы понимаете, могут начать образовываться дыры, в которых 2 и более свободных блоков — память дефрагментированна, при высвобождении можно просматривать соседние блоки, и в случае, когда один или два свободны — мержить их в один.
Аллокатор за логарифмическую скорость
Мы знаем, что нам надо искать только среди свободных блоков. Бегать только по свободным улучшает скорость в среднем в два раза, но это всё равно линия. Что же, зачем нам бегать по всем блокам, ища размер, если мы можем организовать дерево из свободных блоков! Изначально у нас только один свободный блок, а дальше мы добавляем свободные блоки в бинарное дерево поиска, ключом будет — размер блока. Таким образом, чтобы выделить память нам достаточно найти блок в дереве, у которого размер больше или равен тому, что нам нужен. Это мы спокойно делаем за O(log N), просто спускаясь по дереву вниз. Дальше мы либо режем блок на два, либо полностью отдаем его тому, кто запросил память. Дальше мы удаляем блок из дерева за O(1). И, если надо, вставляем оставшуюся часть блока обратно за O(log N). Для высвобождения нам достаточно вставить блок обратно, и не надо забывать про фрагментацию.
Логично, что использовать простое дерево не надо, надо использовать самобалансирующееся дерево, Red-Black или AVL. Хранить дерево блоков можно в статическом массиве, или же придумать как это сделать по-другому.
Собственно, код:
char * malloc(size_t size) {
if (!size) {
return 0;
}
char * addr = 0;
int i;
for (i = 0; i < allocationAvlTree.size; )
{
int r;
node_t *n;
n = &allocationAvlTree.nodes[i];
/* couldn't find it */
if (!n->key) {
return NULL;
}
r = allocationAvlTree.cmp(n->key, size);
if (r <= 0)
{
//We're lucky today.
//Get memory block header
alloc_t * block = (size_t)n->val - sizeof(alloc_t);
//Set to used
block->status = 1;
//Set size
block->size = size;
alloc_t * next = (size_t)n->val + size;
next->prev_size = size;
next->status = 0;
next->size = n->key - size - 16;
avltree_remove(&allocationAvlTree, n->key, n->val);
if (n->key - size - 16)
avltree_insert(&allocationAvlTree, next->size, (size_t)next + sizeof(alloc_t));
memset((size_t)block + sizeof(alloc_t), 0, block->size);
block->signature = 0xDEADBEEF;
unlockTaskSwitch();
return (size_t)block + sizeof(alloc_t);
}
else if (r > 0)
i = __child_r(i);
else
assert(0);
}
return 0;
}
void free(void * mem) {
if (!mem)
return;
//Get current alloc
alloc_t * alloc = ((unsigned int)mem - sizeof(alloc_t));
if (alloc->signature != 0xDEADBEEF)
return;
alloc->status = 0;
alloc_t * left = ((unsigned int)alloc - sizeof(alloc_t) - alloc->prev_size);
if (left->signature == 0xDEADBEEF&&left->status == 0&&left->size==alloc->prev_size)
{
//Merge blocks
if (avltree_remove(&allocationAvlTree, left->size, (uint)left + sizeof(alloc_t))) {
left->size += sizeof(alloc_t) + alloc->size;
alloc = left;
}
else assert(0);
}
alloc_t * right = (uint)alloc + sizeof(alloc_t) + alloc->size;
if (right->prev_size&&right->status == 0&&right->signature == 0xDEADBEEF)
{
if (avltree_remove(&allocationAvlTree, right->size, (uint)right + sizeof(alloc_t)))
alloc->size += sizeof(alloc_t) + right->size;
else assert(0);
}
avltree_insert(&allocationAvlTree, alloc->size, (uint)alloc + sizeof(alloc_t));
}
Удачи и этичного хакинга! Любая объективная критика приветствуется, цель статьи не сказать, что это вах какой аллокатор, а просто рассказать о аллокаторе, который будет лучше, чем тупые реализации простых аллокаторов.








