Комментарии 182
А пока хоть бы Близы добавили нормальный ИИ в игру. Так ведь не станут — это ж снизит посещаемость Battle.Net…
Т.е. идеальной игрой, которую сделает ИИ, станет этакий экран с абстрактной анимационной картинкой, гипнотизирующей человека и заставляющего его вываливать все деньги из своих карманов.
Мирового коллапса это пока не вызвало.
Мне кажется, утечка информации в играх — последнее, чего следует опасаться в связи с развитием искусственного интеллекта.
Персональный шпион-НПЦ в любимой игре, которому ты наивно доверишь свои самые интимные секреты — вот о чем я подумал. Сейчас такое возможно лишь на самом примитивном уровне, а с ИИ-НПЦ можно попытаться вытянуть из юзера нужную информацию путем индивидуального подхода.
того что бы кинуть все силы на разработку против серьезных болезней.Кто такое сказал? Сейчас есть разработки в этом направлении. Так ИИ лучше ставит диагнозы, чем врачи. У бота множество данных о симптомах, их скармливают машине, а она просто мимикрирует и выдает результаты.
А вот это суровая правда, сейчас ИИ используется для того что бы получше впаривать людям не нужное им говноВот почему сразу ненужное? Вполне себе нужное.
После чего уже можно спокойно начинать разбирать планету, чтобы получить ресурсы необходимые для производства 6 октиллионов скрепок — люди больше мешать не будут. Собственно люди тоже на скрепки пойдут.
Вы можете обучить его быть глупым, средним… Лишь бы при этом оно выглядело человечно. Неписи в современных игрушках раздражают не глупостью, а механичностью, неестественностью. Они выглядят тупой неживой декорацией. И геймдизайнерам приходится идти на сотню ограничений и уловок, чтобы это было как можно менее заметно. И всё равно не помогает.
Лично меня в этой демонстрации СтарКрафта больше всего впечатлило не то, что нейросеть размазала противников почти всухую (этого следовало ожидать рано или поздно), а то, что она легко и изящно проходит тест Тьюринга.
Самое революционное в этой сетке то, что она побеждает сильных игроков, при этом имея более низкий средний APM. А еще то, что она попутно решает задачи в духе «как двигать камерой, чтобы видеть самое интересное».
А кто сказал, что оно должно быть умнее человека?
Вы можете обучить его быть глупым, средним…
Ага, для реалистичных NPC надо не просто создать сильный ИИ, но еще и заставить его отыгрывать роль! Чтобы он тактично уходил от каверзных вопросов игрока, придерживаясь механики игровой вселенной. А это уже не просто сильный ИИ, а очень сильный! Не каждый профессиональный GM так может.
Давайте, для начала, представим себе, что NPC разговаривает в разных «интонациях» и чуть разными словами, в зависимости от его настроения и вашей силы/поведения. Просто, смоделировать нормальную особенность человека — по-разному реагировать на разных собеседников.
Уже будет какая-никакая жизнь.
А выбор ваших реплик в диалоге еще очень долго придется делать из списка — тут да, непросто.
Лично меня в этой демонстрации СтарКрафта больше всего впечатлило не то, что нейросеть размазала противников почти всухую (этого следовало ожидать рано или поздно), а то, что она легко и изящно проходит тест Тьюринга.Это в каком таком месте она тест Тьюринга проходит? В том самом, в котором ее более низкий средний апм становится супервысоким текущим апмом, и сетка за счет микроконтроля уровня СУПЕРБОТ9000 разбирает куда более сильную армию противника? Да и продула она именно в тот единственный раз, когда перед ней поставили задачу двигать камерой.
Самое революционное в этой сетке то, что она побеждает сильных игроков, при этом имея более низкий средний APM.
Ну стоит уточнить, что продул агент с камерой который учился 5 дней всего, другие же агенты без камеры учились по 200 лет каждый, а таких агентов было более 1000 и вот с ними уже было 0 шансов у человека. Я как любитель в старкрафт могу сказать, что тест Тюринга ИИ проходит он действует как человек но при этом почти не совершает ошибок. Самые значительные отклонения от человека заключаются в начальной разведке, да и в разведке в целом и видно, что разведка дроном это некий рудимент обучения на людях, бот пытается повторить эти действия но не до конца и не понимает зачем ему это.
Если не требовать от бота, чтобы он побеждал чемпионов, а просто понизить ему пиковый APM до человеческого, скажем, 300. Я вам ручаюсь как многолетний житель серебряно-золотой лиги СК2 — если этого бота пустить туда и научить его в конце партии вежливо говорить «gg», даже опытный игрок не отличит его от человека.
Сыграйте с ним 10 игр и вы будете побеждать даже с APM 30. А вот реальных игроков с тем же APM — даже в бронзе — победить куда труднее.
Стандартный бот выигрывает, потому что у него есть мапхак. Ему невозможно устроить «surprise attack». В этом его единственное и ключевое преимущество.
И, кстати, пиковый APM (вернее, конечно, EPM) в 300 — это далекоо не «бронза».
{kind=link}
На нем не только средний APM но и мгновенный и распределение по времени. Так вот — мгновенный, тоже не превышает человеческого уровня.
На нем не только средний APM но и мгновенный и распределение по времени. Так вот — мгновенный, тоже не превышает человеческого уровня.
Мгновенный апм TLO — это рапид фаер, то есть зажимается одна кнопка и набивается апм нонстопом (с-но, сами то не могли догадаться, что 2к апма для человека — физически невозможное значение?). Игнорируйте его график и сравнивайте хвосты с маной — там все сразу понятно, даже без учета того, что процент "бесполезных кликов" у маны, опять таки, сильно выше чем у альфы.
Вы можете обучить его быть глупым, средним… Лишь бы при этом оно выглядело человечно
Скорее всего, будут оптимизировать под целевые поведенческие паттерны игрока. Условно, не «победил» -> плюс в карму, а
«игрок играл еще более часа после конкретной битвы» -> плюс,
«игрок выключил комп после битвы» -> «минус»,
«игрок задонатил после битвы» -> «100 плюсов»,
«игрок удалил акк после битвы» -> «100 минусов».
Но, разумеется, куда более аккуратнее, и с более микроструктурными метриками
она легко и изящно проходит тест Тьюринга.
при этом имея более низкий средний APM
APM — APM-ом, а точность кликов и скорость реакции совершенно нечеловеческие. И в 10 первых ихрах бот видел всю карту сразу (хоть и с туманом войны) и камеру никуда не двигал. Разработчкики, конечно, говорили, что, мол, он внимание фокусировал вроде как в одном месте, но там был момент, где бот контролировал одновременно 3 группы юнитов с разных сторон, когда окружал армию противника.
В последней игре, вроде как, ввели понятие камеры для бота и он ее проиграл.
Интересно посмотреть на игру ИИ который изначально с подобными ограничениями учился играть.
UPD: bigfatbrowncat опередил и дал более развернутый ответ ))
И если от них там будет требоваться работа — большинство просто перестанет играть. «Долбанутые» геймеры останутся, конечно, но кассу они не делают.Это всё равно что говорить о профессиональном спорте. Чемпионы мире — еще те… «долбанутые».
А человек настолько легко это делает, что ему кажется, что этот процесс настолько прост, что его можно вообще не реализовывать в ИИ, что абсолютно неверноВ каком возрасте человек делает это легко? Нужны годы, чтобы научить говорить, а потом еще и понимать. Да, пока ИИ не может. Но, закликать человека — легко…
Как раз такого рода задачи ИИ уже относительно хорошо решает. См. например датасет bAbI. Там как раз такого рода примеры:
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom
И более сложные запутанные ситуации. Но в целом верно, существующие системы обучения ИИ оторваны от реального мира и нет никаких гарантий, что из предоставляемых им датасетов можно извлечь эту информацию. О том что на самом деле происходит в описываемом тексте. Не говоря о практически отсутствующей у текущих слабых ИИ возможности делать последовательные рассуждения.
После обеда Юлия пошла в парк.
Вчера Юлия была в школе.
Юлия ходила в кино этим вечером.
Q: Куда Юлия пошла после парка? A: В кино.
Q: Где Юлия была перед парком? A: В школе.
Предложения специально перепутаны местами. Про сегодняшний день первое и третье предложение, а второе про вчерашний. Причем в первом предложении ничего не говорится о том, в какой день после обеда это произошло. Нужно из общего контекста понять, что речь идет о сегодняшнем дне.
Это довольно близко к вашему примеру, не так ли? Из него тоже нужно выделить временную последовательность событий, что и в каком порядке происходило. Хотя предложения в тексте вашего примера тоже идут не в хронологическом порядке, как и в Task 14. Вот в какой последовательности у Кати прошел день:
1. Катя долго собиралась.
2. Катя опоздала.
3. Катя обнаружила, что торт съеден.
Приведенные вами вопросы — это вопросы по контексту. Просто чуть более сложный вариант, но принципиально такой же, как восстанавливать из контекста, что первое и третье предложение в примере из Task 14 касаются сегодняшнего дня.
Ну и не надо забывать, что bAbI это игрушечный сборник задач. Один из первых такого рода.
А ИИ этого не делает, ИИ лишь выдаёт результат, который по сути функция от вводных данных.
Строго говоря, «вообразить» что-то – это тоже функция от входных данных. Это просто промежуточное представление. А именно благодаря «промежуточным» слоям нейросети последнее время так хорошо работают. То, что называется Deep Learning, это и есть «вообразить», как вы называется.
Более конкретный пример: автоэнкодер. У него в середине слой очень маленького «разрешения», поэтому нейросети «приходится» при тренировке придумать очень скомпрессированное представление того, что ей подали на вход.
Схема:

Отсюда же картинки про «сумму» очков и лица:

Есть некое промежуточное представление того, что такое «очки», и как их «надевать» на лицо.
Почему это не «воображение»?
Строго говоря, «вообразить» что-то – это тоже функция от входных данных.
Нет. Если вы слышите, как кошка лазит за шкафом, у вас в воображении появляется и кошка и шкаф и примерное расположение кошки. А входные данные это шум. А в другой ситуации, например в гостях у друга, у которого собака, или если у вас нет кошки, такой же шум даст другую картинку в воображении.
То есть это функция не только от входных данных, а еще и от предыдущих запомненных. Их тоже можно считать входными, но вопрос в том, как они появляются в воображении из входных данных на тот момент.
У них формируются некие собственные внутренние понятия и объекты в процессе обучения, а так же память о предыдущих событиях (уже непосредственно в процессе работы) влияющая на то, как будут обработаны новые входные данные.
Например если это чат бот или преводчик текста — ответ на конкретный вопрос или перевод конкретного предложения будет существенно различаться в зависимости от того, о чем шла речь раньше (в предыдущих фразах разговора или ранее по тексту).
Когда подросток читает «Таинственный возраст» он создаёт мир, в котором есть всё, что описано в книге по тексту книги.
Когда нейросеть «читает» этот же текст, то она ничего подобного не делает.
Неверное утверждение. Нейросеть как раз делает то, что и подросток — создает, воображает модель мира. Другое дело, что ни одну нейросеть пока не обучали на таком же объеме данных, как получает за жизнь подросток.
Пруф. По одной картинке (слева) нейросеть воображает целый лабиринт, который мог бы соответствовать этой картинке. Это и есть воображение (или внутренняя модель мира в сознании), о котором вы говорите.
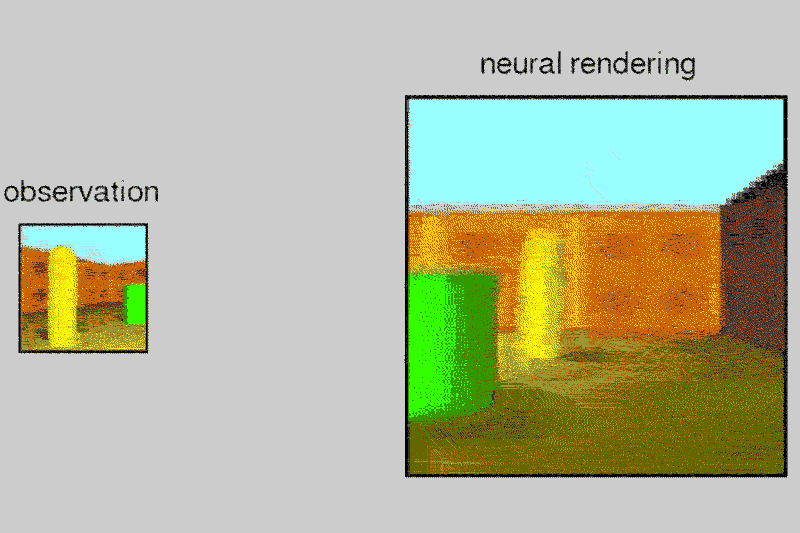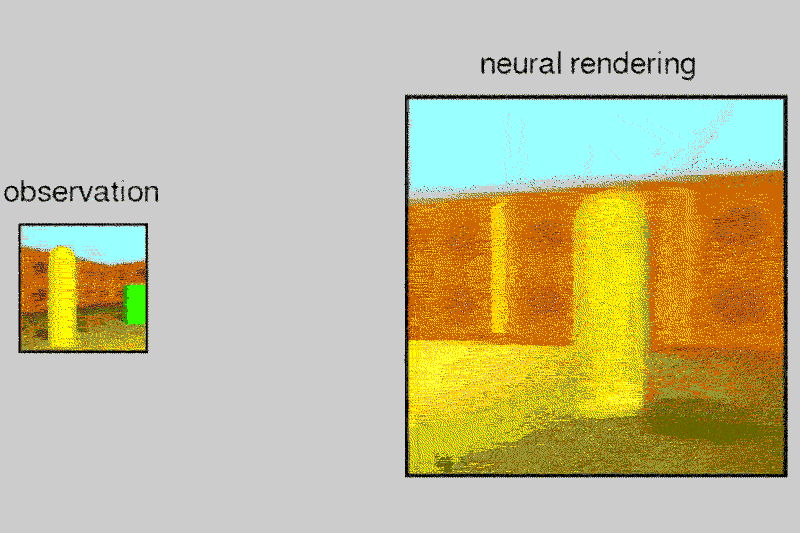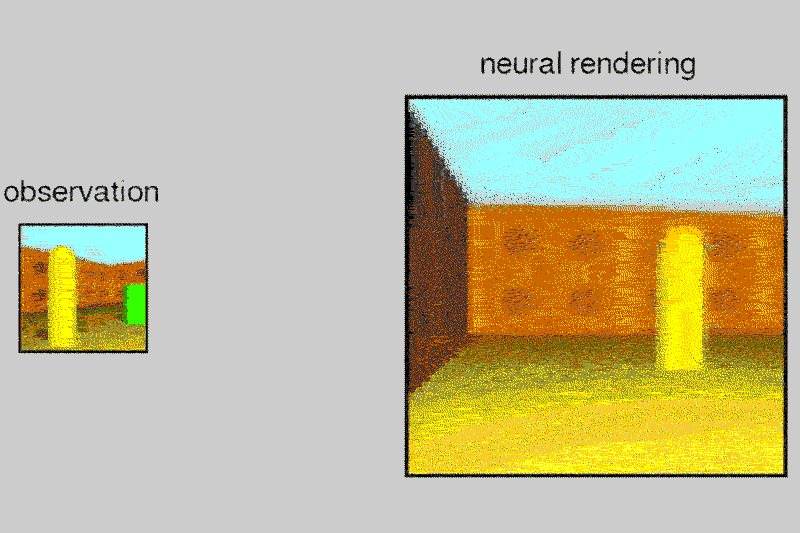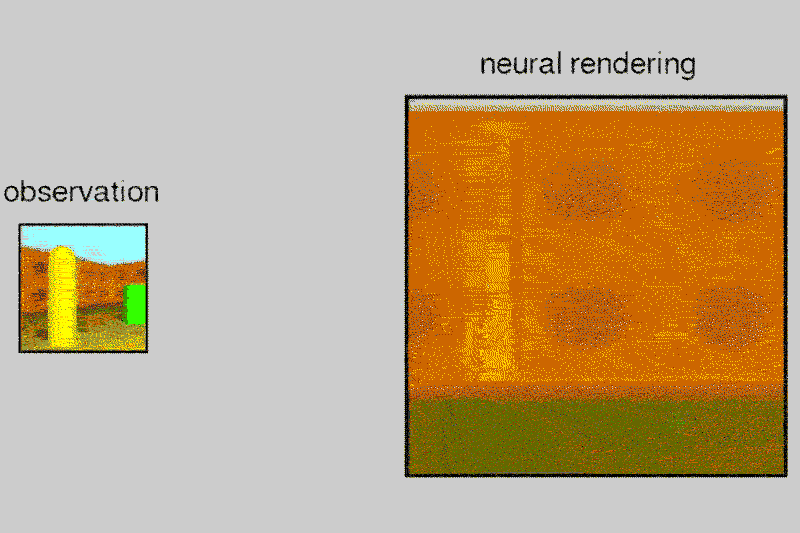
Неверное утверждение. Нейросеть как раз делает то, что и подросток — создает, воображает модель мира.
Нейросеть решает конкретную задачу, на которую вы ее обучите. Это совсем другое.
Человеческий разум не может быть смоделирован целиком не из-за какой-то особенной сущности, а всего лишь из-за чрезвычайной сложности.
Но возможность смоделировать его поведение в рамках решения отдельной задачи (а задачи эти всё продвинутее и все более творческие по своей сути) уже убедительно доказана.
Человеческий мозг, в конечном счете, тоже решает одну единственную задачу. Победить в эволюционной гонке.
Вообще-то нет. Не решает он такой задачи.
Эволюцию среди людей никто не отменял. Она видоизменилась — правила игры стали сложнее, чем у животных. Но все элементы — борьба за лидерство, адаптация, брачные игры — всё осталось таким же. Укажите мне, пожалуйста, на любую деятельность человека, которую нельзя было бы вписать в модель эволюции.
Если не решает, то человек не оставляет потомства. Или его потомство голодает/живет под мостом/умирают от болезней (вставьте свой вариант).
Ну так на практике это весьма часто происходит, ergo, не решает.
Укажите мне, пожалуйста, на любую деятельность человека, которую нельзя было бы вписать в модель эволюции.
Натянуть сову на глобус, безусловно, можно всегда, ведь если привести пример людей, которые не ставят целью классические "жена-дети", то вы бодро отрапортуете, что это компенсация.
Но вы забываете одну простую вещь — у эволюции нет никакой цели. Эволюция (как и природа в общем) не обладает разумом и не способна к целеполаганию.
По-этому никакой задачи, вообще говоря, перед мозгом (и вообще любыми органами) не стоит. Все органы работают совершенно случайным образом, сформировавшимся исторически, в качестве казуса (те, у кого органы работали плохо, очевидно умерли). Вот и все.
если привести пример людей, которые не ставят целью классические «жена-дети», то вы бодро отрапортуете, что это компенсация...
Я не буду рапортовать, что это — компенсация. Я скорее скажу, что человека общество поставило в такие условия, в которых желание размножаться у него отсутствует. Причин может быть масса. От банального эгоцентризма до выстраданного протеста в виде нежелания рожать детей в это общество.
Кстати, есть огромное количество примеров, когда человек сознательно берет на себя ответственность, строит семью, понимая, что будет тяжело, делает детей, хотя знает, сколько с ними трудностей. И это всё — ради того, чтобы обеспечить своему роду жизнь после своей смерти. Способность потеснить своё личное эго ради чего-то большего — тоже некислый такой эволюционный плюс.
Когда вы говорите про органы, то вы учитываете только выживание отдельного организма. А он на масштабах эволюции не значит ничего. Самый здоровый, но бесплодный получает премию Дарвина уже во втором поколении.
Когда я говорю «задача», я не имею в виду, что пришел учитель и сказал «пишите Д/З». Я имею в виду, что мозг потребляет энергию, которую существо вынуждено добывать прилагая серьезные усилия. И чтобы оправдать свое существование в теле, он должен что-то производить. Мозг производит интеллектуальные усилия — с целью улучшить условия жизни как отдельной особи, так и общества в целом.
Я имею в виду, что мозг потребляет энергию, которую существо вынуждено добывать прилагая серьезные усилия. И чтобы оправдать свое существование в теле, он должен что-то производить.
Нет, он никому ничего не должен. Потому что, еще раз — у природы нет целеполагания.
Мозг производит интеллектуальные усилия — с целью улучшить условия жизни как отдельной особи, так и общества в целом.
Мозг производит интеллектуальные усилия просто потому, что он так устроен. Точно так же у Солнца нет цели вставать на востоке и заходить на западе. Просто так устроена солнечная система. Никак по-другому Солнце действовать просто не может. Как и мозг.
у природы нет целеполагания.
Ну хорошо, нет — так нет. Природа не имеет своего разума, сознания, у нее нет ни целей, ни средств, ничего. Вопрос смысла жизни сам по себе некорректен, все деяния тщетны, так как ничего не меняют.
Какой тогда смысл в нашей с вами дискуссии?
Всегда очень интересно, зачем в споре апеллировать к тщетности бытия, если этот аргумент никак не помогает выиграть спор — он только делает этот спор бессмысленным.
Я сказал «цель — выживание», потому что мне так подсказывает мой собственный инстинкт самосоханения, который, полагаю, есть и у вас. Можно, конечно, от него отказаться, но это сразу выводит нас с вами из множества разумных живых существ, потому что (я в этом убежден) без этого инстинкта полноценный разум невозможен, ибо без мотивации нет развития.
Всегда очень интересно, зачем в споре апеллировать к тщетности бытия
Чет непонятно, как вы от отсутствия целей у природы пришли к тщетности бытия.
Я сказал «цель — выживание»,
Цель чего?
Цель живого существа. Основная задача живого существа — выжить и оставить потомство. Основная цель живого существа — решить его основную задачу.
Честно говоря, у меня такое ощущение, что я не с человеком беседу веду, а с андроидом, построенном на формальных логических описаниях… Извините.
>Чет непонятно, как вы от отсутствия целей у природы пришли к тщетности бытия.
Когда вы сказали «у природы нет целеполагания», вы вывели дискуссию с уровня обсуждения смысла жизни конкретной популяции особей (о которой говорил я) на уровень смысла жизни как таковой. А этот уровень здравому смыслу неподвластен. Он уже из области веры скорее. На это я вам и указал, назвав «обсуждением тщетности бытия».
И кто ему такую задачу поставил?
> Когда вы сказали «у природы нет целеполагания», вы вывели дискуссию с уровня обсуждения смысла жизни конкретной популяции особей
Так нет никакого смысла жизни конкретной популяции особей. О том и речь.
Вещи работают так, как они работают просто потому, что эти вещи так устроены. Не потому, что есть какая-то «цель» или «задача».
Моя основная аксиома: смысл жизни состоит в сохранении жизни. Не данной конкретной особи, а жизни как таковой, как явления.
Эта аксиома дает возможность каких-либо осмысленных построений, выделения целей и результатов. Достигнутых или нет.
Выходить за рамки этой аксиомы в данной дискуссии я отказываюсь, так как мне это просто неинтересно.
Отсутствие у самой природы как таковой смыслов и целей не мешает нам ей эти смыслы придавать и цели обозначать. Просто для того, чтобы наши с вами мыслительные действия можно было вести.
А без цели мысль бесполезна. Она просто не работает.
Моя основная аксиома: смысл жизни состоит в сохранении жизни. Не данной конкретной особи, а жизни как таковой, как явления.
Ваша аксиома ложна. У жизни (как таковой, не конкретной особи) нет никакой цели. Потому что у жизни нету сознания. А без сознания цели быть не может.
Отсутствие у самой природы как таковой смыслов и целей не мешает нам ей эти смыслы придавать и цели обозначать. Просто для того, чтобы наши с вами мыслительные действия можно было вести.
Попытка основывать рассуждения на базе заведомо ложного утверждения уж точно не прощает мыслительные действия. Наоборот.
А без цели мысль бесполезна. Она просто не работает.
Моя мысль — замечательно работает.
Попробуйте сделать из своей мысли хоть пару хоть сколь-нибудь конструктивных выводов. Извлеките из нее практическую пользу для себя :)
Мы с вами давно уже перешли из плоскости научного спора в дискуссию двух людей с разным мировоззрением. Так что давайте прекратим спорить.
Вы считаете заявление «у природы нет цели, так как нет сознания» ценным. Я считаю его очевидным и неинтересным. Мне куда интереснее проанализировать, какие цели я бы задал природе, если бы находился на месте разумного творца. Высокомерно звучит, но интересно. Потому что из этих рассуждений можно почерпнуть много инженерных идей. Или сюжет для фантастического романа.
Мне куда интереснее проанализировать, какие цели я бы задал природе, если бы находился на месте разумного творца.
Но это же совершенно другой вопрос :)
Можно отвечать на него совершенно независимо по сравнению с: "какая у природы цель?"
Потому что из этих рассуждений можно почерпнуть много инженерных идей. Или сюжет для фантастического романа.
Но тогда ответ следует брать какой-то менее тривиальный, чем "сохранение жизни" :)
И, да, если бы вы находились на месте разумного творца — то зачем бы вы сделали миллионы "лишних" галактик? :)
А кто сказал, что они «лишние»? На них тоже есть жизнь. Много разных вариантов жизни.
На них тоже есть жизнь. Много разных вариантов жизни.
Ок. Давайте вместо "лишних галактик" будет "лишних систем". Или там тоже жизнь есть по-вашему? :)
Смысл воображения не в том, чтобы получить видео, а чтобы там были отдельные наблюдаемые объекты. Если там один объект "двигающееся изображение", такое воображение ничего не дает.
Например, здесь правильно будет если нейросеть будет распознавать понятия "столбик", "стена", "пространство", характеристики цвет, высота, их различие, сможет представить столбик отдельно от всего остального с разных сторон.
Чтобы у нейросети были информационные элементы, с которыми можно связать все эти слова, поданные на вход текстом. Или в отладчике их выделить каким-нибудь анализатором. Видео здесь скорее дальше чем ближе к тому что требуется.
Эта задача называется object detection
При чем тут object detection вообще?
Насколько я понимаю, object detection это определение классов, причем на конкретном изображении. Я говорю про определение конкретных объектов, и возможность манипулировать ими в дальнейшем без изображения. И самое главное, нейросеть сама должна определять список значимых фич, а не по специальному набору изображений с заранее известным результатом.
Главное — чтобы была цель у всего этого. Можно, например, поставить перед ИИ цель выбраться из лабиринта. Но это я уже пытаюсь конкретную задачу придумать.
Так или иначе, если сеть способна выделить общие свойства у юнитов в Старкрафте и оперировать в незнакомой ситуации на основании имеющегося опыта, а именно этому ее и учили создатели, можно говорить именно о зарождении на этом этапе некоторого прототипа «фантазии».
«представить себе столбик» означает смоделировать его в сознании как часть некоторого процесса.
Нет. Это означает отдельный объект. Например, вы можете представить этот столбик отдельно на черном фоне, хотя никогда такую картинку не видели. Взаимодействие с другими объектами это отдельное понятие, они выражаются другими словами (обычно глаголами). Неважно, с целью или нет, важно что отдельно. Это и позволяет использовать понятия отдельно от ситуаций, в которых они появились, применять в других, комбинировать, давать названия. На картинке выше сеть объекты не выделяет, она помнит всю картинку целиком.
А вы, кстати, в курсе, что «стоять» — это тоже глагол, который тоже выражает действие? В этом смысле у нас получается сосем даже не просто объект «столбик» сам по себе, а связь «столбик стоит перед черным фоном». То есть он даже не совершая активных действий, всё равно, зараза, что-то делает.
Нельзя представить себе просто абстрактный столбик. Чем дольше вы о нем думаете, тем большим количеством связей с другими предметами, свойствами и действиями вы его снабжаете. Это, как раз, и есть — фантазия, которая тащит всякий «хлам» из подсознания (то есть, из предыдущего опыта) и подсовывает его в ваш «идеальный столбик».
Мой, например, получился из бетона, высотой около метра, торчащий из асфальта, слегка покосившийся, чуть-чуть надтреснутый у верхней трети, а возле него пробивается трава и одуванчик. Один. Желтый. Скучаю по лету…
На картинке выше сеть объекты не выделяет, она помнит всю картинку целиком.
А скажите на милость, с чего вы это взяли?
Я вот, например, убежден, напротив, что если бы она не была способна внутри себя отделить стоблик от стены на фоне, она бы точно не смогла построить комнату с ним в перспективе. То есть я уверен, что она отделила одно от другого уверенно и четко. Просто, нам с вами об этом забыла рассказать. Это произошло где-то в глубине сети.
А вы, кстати, в курсе, что «стоять» — это тоже глагол, который тоже выражает действие?
А я не сказал "стоять") Я вообще ни про какое действие не думал. Если подумать, то скорее будет "висеть". Но суть в том, что у меня не было ассоциации ни с каким действием, но при этом я могу представить его в любом действии — стоит, лежит, и т.д.
Неважно, насколько столбик детальный. Тут я например говорю про конкретный зеленый столбик. Нейросеть не может его выделить в памяти отдельно (то есть представить).
А скажите на милость, с чего вы это взяли?
Там это видео приводится как пример воображения, я говорил конкретно о нем.
Это произошло где-то в глубине сети.
В этом и суть. Если это размазано по сети и переплетено с другими параметрами, этим нельзя оперировать, нельзя использовать в другой ситуации, любое изменение окружения может повлиять на распознавание. Отсюда же и adversarial attacks всякие.
В этом и суть. Если это размазано по сети и переплетено с другими параметрами, этим нельзя оперировать, нельзя использовать в другой ситуации
Человек расстроен. Он долго изучал способ создать искусственный разум и в итоге ему это удалось. Существо начало мыслить и действовать. Но когда он залез к нему в мозг, он обнаружил, что НЕ ПОНИМАЕТ, как оно внутри устроено, как оно работает. Злая ирония! Мы сделали ИИ, но не можем разобраться, как его нарезать на маленькие кубики, чтобы каждый кубик выполнял отдельную функцию, понятную нам.
Сюрприз! Современный Deep Learning так и работает. Никто не понимает до конца, как устроены нейросети. Я сейчас говорю не о топологиях, а о том «чуде мысли», которое позволяет нейросети не только интерполировать между двумя заданными вариантами, но и экстраполировать ответ, проявлять ту самую «фантазию». Никто не может этого понять. И это нереально круто и интересно всем, кроме зануд, которые мечтают препарировать искусственный мозг и узнать, «где же у него кнопка».
Но когда он залез к нему в мозг
Я же не говорил ничего про отладку, только про поведение самой сети.
Никто не понимает до конца, как устроены нейросети
Так они не до конца и работают как человек.
но и экстраполировать ответ, проявлять ту самую «фантазию»
Я бы не назвал это фантазией, именно потому что сеть не может представить конкретный объект.
А это значит, что она — умеет отделять объекты друг от друга
Или что там ассоциативный массив jpg -> avi.
Смысл воображения не в том, чтобы получить видео, а чтобы там были отдельные наблюдаемые объекты. Если там один объект «двигающееся изображение», такое воображение ничего не дает.
Это вопрос терминологии. То что мы называем воображением — представляя столбики или сопутствующие обстоятельства — в нейросетях называется вектором контекста. Его выделять нейросеть учится, обучаясь на больших объемах данных. Потом ей достаточно увидеть один желтый столбик, сложить эти входные данные с вектором контекста, и она получает общее представление о ситуации. Причем сложить в буквальном смысле — конкатенацией двух векторов. После чего простой регрессией из этого общего вектора она может рендерить картинку, выделять отдельные столбики на фото, да что угодно.
Вектор контекста может быть неявно закодирован в весах сети, как в этом случае, а может в зависимости от архитектуры выдаваться на выходе в явном виде, с последующей конкатенацией с текущими входными данными.
В общем случае вектор контекста (это буквально либо числа в весах, либо числа в специальном выходном векторе) содержит недостающую информацию для решения задачи. А это и есть воображение, о котором тут говорят. Знания о внешнем мире и т.д.
Есть архитектуры, в которых нейросеть представляет в динамике разные варианты развития событий (на основе предобученной model-based модели), и учится дальше чисто по своему воображению. В точности как мы, прокручивая в голове ситуации и пытаясь найти решение. Там действительно все очень похоже. Если кто-то указывает на принципиальные отличия человеческого мышления от того, что происходит в нейросетях, то это просто от недостатка знаний о современном состоянии машинного обучения. Вопрос о возможности или невозможности сильного ИИ уже давно не стоит, теперь это лишь вопрос времени.
То что мы называем воображением — представляя столбики или сопутствующие обстоятельства — в нейросетях называется вектором контекста.
Подождите, какой такой контекст. Я могу вообразить этот столбик отдельно, поместить его мысленно в другую ситуацию, представить 10 штук в ряд. Это наоборот отделение объекта от контекста, в котором он появился.
После чего простой регрессией из этого общего вектора она может рендерить картинку, выделять отдельные столбики на фото, да что угодно.
Так надо не всю картинку рендерить, как на анимации, а отдельные объекты. Тогда это будет похоже на воображение. Иначе это просто видеокодек, который работает с пикселями.
Если я правильно понимаю, конкретно у этой нейросети нельзя взять часть вектора контекста и отрендерить из него зеленый столбик на темном фоне с разных сторон, который не будет двигаться по экрану как он двигается на полном изображении? Ну, без низкоуровневых хаков типа брать из вывода нейросети ограничивающий прямоугольник.
Вопрос о возможности или невозможности сильного ИИ уже давно не стоит, теперь это лишь вопрос времени.
Согласен, я говорю лишь о технических различиях.
Подождите, какой такой контекст. Я могу вообразить этот столбик отдельно, поместить его мысленно в другую ситуацию, представить 10 штук в ряд.
Вы это всё когда-то видели. В той или иной степени сходства. Возможно, десять в ряд не видели, но видели три в ряд. А дальше — экстраполируете.
Фантазия — это перебор известных элементов в новые конструкции. В качестве доказательства приведу очевидную мысль. Может существовать слепой от рождения скульптор. Но слепой от рождения художник существовать не может.
Бетховен писал музыку, бдучи глухим, потому что его мозг был достаточно нартенирован, чтобы представить себе, как звучат записанные ноты. Слышать было уже не обязательно (хотя не дай боже оказаться на его месте). Но будь он глух от рождения, не было бы великого композитора.
Возможно, десять в ряд не видели, но видели три в ряд. А дальше — экстраполируете.
Ну и что? Это никак не противоречит моим словам, даже подтверждает. Именно представление объектов по отдельности и дает возможность экстраполировать и комбинировать.
Топология, которую научили создавать пространственное представление по фотографии, внутри себя — в скрытых слоях — отделила объекты от фона. Без этого она бы не смогла работать, потому что минимальная последовательность действий — найти, отделить, перегруппировать — должна быть выполнена.
А это значит, что она — умеет отделять объекты друг от друга, просто мы не понимаем, как она это делает.
Наше с вами непонимание процесса мышления не отменяет факт существования этого процесса.
Важно отметить, что скорость действия программы и её область видимости на поле боя были ограничены, чтобы AlphaStar не получила несправедливого преимущества над людьми.
На другом ресурсе видел информацию о том, что хотя туман войны и был для ИИ, но по имеющемуся API программа получала информацию о видимых вражеских юнитах на всём видимом участке без необходимости двигать камеру. Когда эту возможность отключили человек выиграл. Но была оговорка что в таком режима ИИ учился играть намного меньше времени.
Стоит отметить что все же небольшое преимущество у AlphaStar было — несмотря на то, что туман войны закрывал карту для нейросети так же, как и для человека, программа получала для обработки не частичное изображение известной области (условный экран), а видела сразу все, что позволяет увидеть игра. Благодаря этому нейросети не приходилось постоянно переключаться между разными зонами карты для контроля за происходящим. Когда же для еще одного демонстрационного матча с MaNa разработчики заставили AlphaStar играть с обычным ограничением масштаба видимой области, то нейросеть проиграла человеку. Правда, в DeepMind отмечают, что самостоятельно двигающая камеру версия программы обучалась в «лиге AlphaStar» всего семь дней.
Это определённо выходит за рамки моего понимания человеческих возможностей. о_о
Это просто к тому, что в играх нет и десятой доли всех возможных вариантов развития событий из реальной жизни (в том-же старкрафте нет дезертиров, морали, погоды и т.д.)
Или вон как на недавних учениях — столкнулись два корабля НАТО :)
Все учесть невозможно, так что только на реальной жизни и можно обучать систему для реальной жизни…
А вот с реальными боевыми конфликтами так не получится. :)
Чтоб система этому научилась надо все это заложить в «правила». Даже варианты того, что прапорщик разбавил топливо, солдаты напились, а генерал продал план наступления противнику. И разных сценариев (а тем-более их сочетаний) можно придумать столько, что невозмножно будет в обозримое время заложить все это в программу обучения.
Ну и количество вариантов срабатываний разных событий мне кажется легко переплючент количество вариантов в ГО :)
Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями. Проблема только в обучении, в реальной жизни обучить сложновато, не хватит людей и русурсов, а вот создать симуляцию боевых действий пусть даже не со всеми возможными параметрами уже даст многократное преимущество перед противником.
пусть даже не со всеми возможными параметрами
И если при проверке в реальности возникнет такой неучтенный параметр, то все что планирует делать ИИ идет в топку, т.к. он просто не поймет что произошло.
И это если говорить про какие-то параметры, которые можно предположить, а вот как быть с управлением техникой? Мастерство экипажа в симуляциях одинаковое для всей однотипной техники, а в реале это очень сильно разнится, и один и тот-же самолет будет показывать разные результаты в зависимости от пилота — будем учитывать в симуляции каждого человека? Так у нас нет их параметров, есть только ТТХ техники…
Мне бы очень хотелось посмотреть на ИИ в настолках с кубиками (например тот-же Вархаммер). Вот где куча вариантов состава армии, и куча рандома в виде кубиков, и пусть попробует собрать армию против любого противника, да еще и научится играть не зная, как войска себя поведут, это только в старкрафте войска беспрекословно выполняют приказы и всегда попадают в цель.
Нет, научится не играть, а выигрывать.
Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями.
Если вы это сделаете, то сможете легко выиграть любую войну и без ИИ.
ИИ может пригодиться в автономном вооружении, умных ракетах, дронах.
Танки сейчас тоже скорее для красоты, уничтожаются на счет раз с ПТРК
А люди уничтожаются из автомата, сейчас тоже скорее для красоты, корабли уничтожаются торпедой, сейчас тоже скорее для красоты, самолеты уничтожаются ракетой…
Может не стоит так категорично утверждать?
В пехотинца тоже снайпер из любого угла. Это не говорит о том что пехоте в город нельзя. А танк — это лучшая броня из придуманной, да не идеальная, но ничего лучше нет. Плюс пушка на гусеницах. Может сложить целое здание. Естественно танк без пехоты не идёт. И пехоте без танка неуютно. И тыл должен быть прикрыт, а не на середину площади с разбегу. И все последние конфликты в Сирии и Донбассе только подтверждают необходимость танков в том числе в городских боях.
Ваши «все последние конфликты» — это не война, а локальные подавления бегающих с калашами. Будь это настоящий соперник, он за 100км мимоходом выпустил бы пару ракет, и сгорели бы все эти железные тушки. И не важно, прикрыт у них был «тыл» или нет. Вылезайте из WOT.
Танки, пехота и прочее, могут пригодиться в локальных конфликтах для подавления незаконных бандформирований. А исходно я полез в дискуссию о том, что ИИ якобы мог бы пригодиться для просчета какой-то тактики на поле боя, что неактуально уже лет как минимум 50.
P.S. Я даже представить боюсь как оно будет играть за зергов.
Для этого он поиграет еще недельку и будет на том же уровне, что и с картой.
Дудки, он «сдулся» потому что заставили играть с ограниченным объемом информации. Т.е видит не всю карту, а как человек — кусочками.
С другой стороны, если уж была бы задача «поставить ИИ в равные условия с человеком», то надо было создавать аппаратную человекоподобную платформу, а не эмулировать ограничения. Т.е. играть должен был человекоподобный робот (причём без подключения к сети), таращащийся в монитор и тыкающий механическими пальцами в клавиатуру и мышь. Вот если бы такая связка обыграла бы профессиональных игроков, то это бы реально пугало…
У калькулятора тоже превосходство в вычислениях, это ничего не означает.
habr.com/ru/post/437486
Заголовок: «ИИ обыграл профессионалов в SC2 10-0!»
Где-то далеко внизу: «ИИ играл за одну расу, один матчап, на одной карте, с полным контролем всей карты, не закрытой туманом войны, по одной игре с разными агентами (т.е. без возможности людей адаптироваться)».
Не многовато ли ограничений? Пока звучит как: «ИИ смог обыграть человека в шахматы! Правда, человек играл без ферзя, слонов, коня и ладьи. А еще ему нельзя было ходить на клетки по е6, е2 и б4 и можно есть фигуры соперника только первыми тремя пешками».
Я даже не удивлюсь, если матчи были подтасованными и сыгранными по сценарию. TLO вообще детские ошибки допускал с варпом сталкеров на поле боя.
Не хочется умалять заслуги разработчиков, которые сделали то, чего раньше не делал никто, но стоит объективно оценивать результат. Правда на такую объективность денег не выделят :(
А про невозможность людей адаптироваться это просто смешно. Мана входит в 10ку лучших игроков-протосов планеты, поверьте, на своё обучение он потратил гораздо больше времени чем этот ИИ. И на таком уровне просто не сущестует понятия «адаптироваться». Те игроки к которым можно адаптироваться ничего не достигают.
Но смысл же не в этом. Я удивляюсь комментаторам которые пытаются доказать, что ИИ в чём-то вёл себя «нечестно». Да ребят, ему не нужно нажимать на клавиши, смиритесь. Чтобы соответствовать вашим представлениям о «честности» я так понимаю дип майнд должны посторить андроида да?
Вы можете сравнить с предыдущими достижениями в этой области habr.com/ru/post/370431 вот статья например и осознать что это просто невероятный скачок вперёд.
Вот что сам MaNa пишет на реддите, когда его спросили, чем бот был лучше/хуже человека:
I would say that clearly the best aspect of its game is the unit control. In all of the games when we had a similar unit count, AlphaStar came victorious. The worst aspect from the few games that we were able to play was its stubbornness to tech up. It was so convinced to win with basic units that it barely made anything else and eventually in the exhibition match that did not work out. There weren’t many crucial decision making moments so I would say its mechanics were the reason for victory.
То есть, бот тупо рашил базовыми юнитами не особо заботясь о стратегии, и это работало. В этом нет никакой особой интеллектуальности, тупо победа за счет лучшей механики микроконтроля.
Это как называть бота в Counter-Strike прорывом в ИИ и скачком вперёд, потому что он хедшоты делает со 100% точностью. "The goal is to create artificial intelligence, not artificial aiming"
Есть лишь один вопрос. Почему до вчерашеного дня никому и никогда не удавалось создать бота для Старкрафт который бы победил человека даже имея неорганиченыц АПМ и скрипты для микроконтроля?
Потому что со всем остальным (кроме бешеного APM) у тех ботов было совсем плохо, они были слишком «запрограммированные» и негибкие, что позволяло легко найти брешь в их алгоритме и нагнуть их.
Но при наличии минимального интеллекта у игрока (что DeepMind вполне себе демонстрирует), сверхчеловеческое микро уже не «контрится» — тонкий игровой баланс Старкрафта на такое просто не рассчитан.
Это как в средневековье пригнать трактор и говорить, что нечестно на нём побеждать на рыцарском турнире, вы же в него соляру заливаете, а не овёс. Но трактор-то не для турниров, на тракторе поле можно вспахать, ребят.
Человек однозначно проиграет в этой борьбе, тут даже никаких вопросов нет.
В доте все еще не проиграл :)
И есть еще один немаловажный момент — изменения правил у игр. Баланс часто меняют, патчи выходят регулярно, и человек к ним подстраивается намного быстрее, а ИИ придется тренировать по-новой в некоторых случаях.
По поводу честности: к таким заявлениям приводят желтые заголовки. Никто не спорит, что это очередной огромный прорыв в области обучения ИНС человеческим играм. Претензия именно к прямому обману обывателя, который, не разбираясь в деталях, будет думать, что «скоро будем жить в постапокалипсисе из терминатора».
P.S. По поводу времени на обучение: а давайте посмотрим не по критерию «время на обучение», а по критерию «количество игр, на которых был обучен ИИ». Все зависит метрики, по которой сравнивать.
Я удивляюсь комментаторам которые пытаются доказать, что ИИ в чём-то вёл себя «нечестно». Да ребят, ему не нужно нажимать на клавиши, смиритесь.
Смотрите. Если вы на бнете будете микрить сталкерами как АльфаСтар, то вас забанят ;)
Мана входит в 10ку лучших игроков-протосов планеты, поверьте, на своё обучение он потратил гораздо больше времени чем этот ИИ.
А если в количестве игр посчитать?
Уточнение: ИИ не видел скрытые туманом войны области. Он просто видел карту разом. Как играть на растянутой миникарте.
Во многом согласен, но разные агенты это, объективно, плюс в копилку AlphaStar.
Пока мир не может сделать одного бота чтобы побороть прогеймеров, ребята одновременно сделали 5 разных, со стабильно хорошими результатами.
Адаптироваться на лету к разным противникам это как люди выигрывают на ладдере, турнирах и становятся прогеймерами.
А вообще, если Близы не профукают такую возможность, они смогут доточить баланс до идеального. Например, добавят маленький откат навыку «сесть в бункер». Сделают блинк не мгновенным, а занимающим, скажем, 10 миллисекунд (чтобы снаряд успел попасть). И т. п…
На даннвй момент игра сбалансирована только на уровне человеческой реакции. Но никто не мешает сделать ее такой, чтобы уравнять шансы как для людей, так и для «сверхлюдей».
— Он лучше строит, почти всегда у AlphaStar больше ресурсов и юнитов.
— Он лучше микрит, stalker с blink у ИИ практически бессмертный. Такая эффективность управления недоступна человеку и ломает баланс. Immortal должен побеждать stalker, но нет, под управлением ИИ stalker побеждает.
— Он может разбивать армию на много кусочков, окружать и «дергать» армию противника со всех сторон. Человек такого не может, просто не внимания.
— Он не учится в процессе игры, прилетел дроп, и AI продолжал гоняться за ним пока не проиграл.
AlphaStar в основном побеждал за счет нечеловечески точного и быстрого управления юнитами. Он не показывал чудеса стратегии или какие-то крутые игровые идеи. Просто он умеет быстро елозить мышкой и делает это в 1000 раз быстрее и точнее человека. Надежда людей в этом противостоянии только на то, что всю дурь из AlphaStar не получится выбить и всегда будут новые стратегии, к которым он не готов, как тот дроп из 2х immortal.
И надо быть справедливым к людям, если бы они играли с AlphaStar несколько дней подряд, то счет был бы 0-10 в пользу людей. Уже в 6 игре Mana нашел фатальный недостаток у ИИ.
Просто если бы они выставили адекватное ограничение APM (думаю они пытались), то игроки-люди разделали бы бота под орех, и никакой красивой презентации для инвесторов не вышло бы. А у них дедлайны, надо что-то показать.
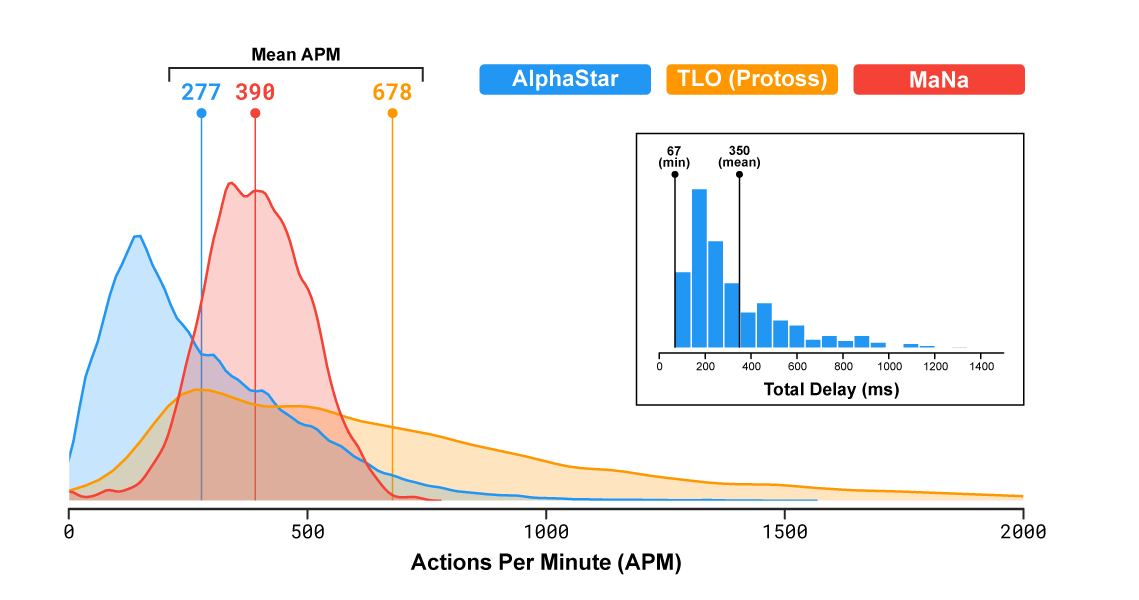
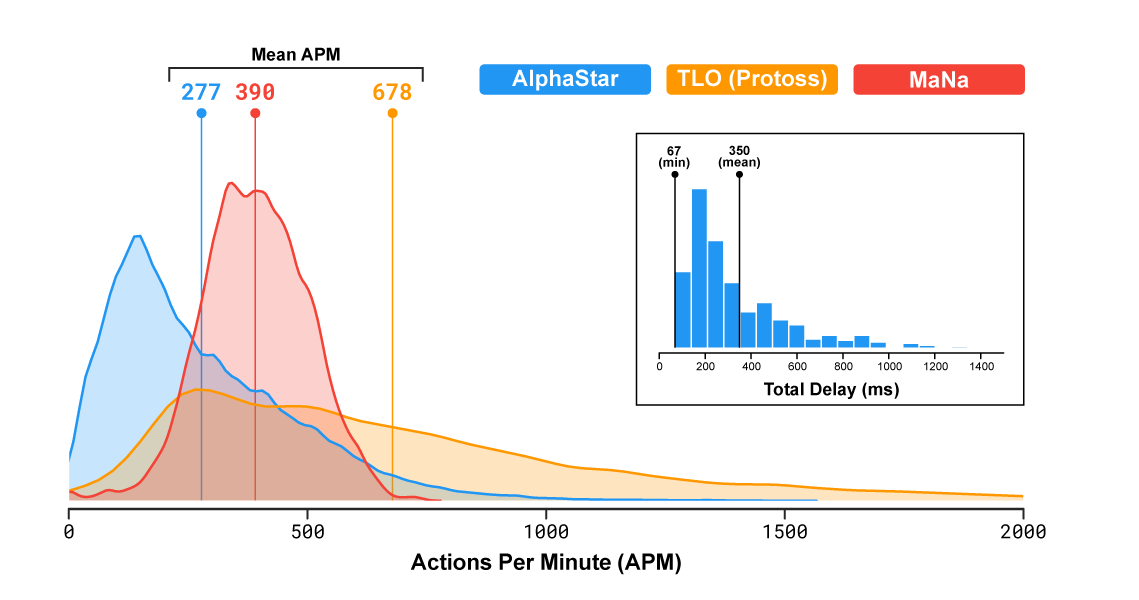
Вот тут AMA на reddit с разработчиками, и там выясняется что лимитер APM был настроен так, что даже (теоретически) допускались кратковременные burst'ы под 2500 APM (на практике мы видели 1500 в боях), что конечно полный бред, ни один человек никогда так не сможет кликать — чисто физически эффективный APM не может быть выше 200-300, все что выше это бессмысленные «раскликивания», возможно даже с помощью макросов клавиатурных. Причем бот кликает с суперточностью, ему не надо рамкой выделять юнитов и елозить курсором, он может суперточно выбрать любой набор юнитов в любых местах карты одновременно — ему даже и камерой не нужно было елозить, он играл с «зумхаком» все игры кроме последней (где он позорно слился). Это профанация полная, рассчитанная то чтобы впечатлить и убедить тех, кто в SC никогда не играл. Манипулирование числами и статистикой (это я про их «средний APM даже ниже чем у игроков-людей» и красивые графики распределений, где сравниваются яблоки и апельсины).
Если верить этому графику, то средний АПМ был выше не у ИИ, а у MaNa (390 vs 277), при этом максимальный — у TLO (2000 vs 1600).
{kind=link}
Конечно надо учитывать что у TLO такой высокий апм из-за хоткеев (багнутая фича — частое использование хоткеев сильно завышает АПМ). И конечно у ИИ нет спама, в отличие от людей. Поэтому возможно в 2-3 раза выше эффективный апм, но не на порядки же.
«Зумхак» тоже преимущество, но бот по-прежнему оперирует неполной информацией (ту же информацию имеет любой про-игрок который смотрит на миникарту — тот же Серрал потому и выигрывает всегда; у него отличный map presence, вне зависимости от того где его камера в какой-либо момент).
Ну и 200-300 эффективный АПМ физически всё же возможен, если использовать множество способностей, хоткеев (уместных) и быстро-часто направлять юнитов по какой-нибудь оптимальной кривой.
В конце концов печатать-то люди вполне успешно умеют с эффективной средней скоростью в 700-1400 букв минуту (не все, конечно, но всё же — достаточно взглянуть на klavogonki.ru).
А так — я, как мл-тосс, впечатлён. Убрать все преимущества и подучить нейросеть играть «с камерой» — и всё равно будет игрок уровня грандмастера. Да даже сейчас думаю он как минимум любого мастера обыграет в большинстве случаев, даже если сильнее АПМ поуменьшат и «с камерой».
А самое главное — со стороны не то чтобы легко отличить, компьютер или человек играет.
У ИИ есть спам
Только в тех ситуациях, когда APM больше «не на что» было потратить эффективно, т.е. не в моментах интенсивных стычек. Этому AI научился у людей, так как первую версию обучали на реплеях, перед тем как она начала играть сама с собой. Но поскольку это не влияло на винрейт, ИИ «не смог забыть» эту привычку. А вот в критические моменты он тратил свой APM очень эффективно, так как это влияло на винрейт при обучении.
Этот график — профанация и притягивание за уши… Какой нафиг APM в 2000 у человека, и какая разница какой APM «средний» если важно то, какой он пиковый в критические моменты игры, и какой процент полезных действий в этом APM, ведь большая часть человеческого APM это спам-клики и перемещение камеры, при том что боту же даже камеру перемещать не надо было.
Вот очень хороший пост в /r/MachineLearning где все четко расставляют по полочкам:
> Поэтому возможно в 2-3 раза выше эффективный апм,
Но в Старкрафте это гигантское преимущество и полностью меняет игру, при в 2-3 раза большем APM чем у топовых прогеймеров, оптимальным стилем игры становится массить блинк сталкеров и давить ими c трех сторон одновременно. В Старкрафте в балансе многое рассчитано на то, что идеальный контроль у человека невозможен, и баланс старкрафта во многом про искусство эффективного менеджмента ограниченного количества действий в секунду. Если его не ограничивать, то игра просто теряет смысл.
"Он не учится в процессе игры, прилетел дроп, и AI продолжал гоняться за ним пока не проиграл."
Чисто технически это можно сделать, нет проблем. Проблема в необходимости огромного количества материала для обучения.
Но надо отдать «Дипмайнду» должное, в плане «микро» он весьма неплох.
А вообще, если устраивать соревнование «человек против машины», мне кажется, человеку тоже надо выдать пачку костылей, для компенсации. Самым простым будет уменьшение скорости до Normal, чтобы примерно сравнять возможности по микро-контролю.
Старкрафт-2 все-таки не только и не столько стратегия, сколько соревнование «кликеров», он нарочно неудобный для определенных вещей. Хотя и гораздо более простой нежели первая часть серии, где нужно было совсем всё-всё делать руками — например, вейпоинты на минералы не работали, у выделенных «магических» юнитов не работали способности, если к выделению примешивались юниты другого типа, а сами способности «кастовались» у всей группы на одну и ту же точку. Наверное, у «alphaGo» в этом случае было бы еще больше преимуществ.
В целом мне не понравилось, они просто вывели идеальные билды и тайминги и тупо перемасили и переконролили человека.
Я бы лучше посмотрел против кингкобры, который я думаю его бы в легкую зафатонил.
И ещё, нужно было дать время подготовиться игрокам, если б они нашли слабые стороны значит это херовый ИИ, если б ИИ в процессе адаптировался значит хороший.
Я думаю, что пока оно училось играть на уровне алмазной лиги, оно весьма успешно научилось отбиваться от фотонок. И не только.
На последнем матче была выпущена явно сырая, недоученная сетка. Он не отбился не из-за ограниченного поля видимости, а из-за того, что он не научился в новой механике правильно ориентироваться. Возможно, надо было доработать топологию. Ошибка со сталкерами, пытавшимися достать дроп с берега — вообще похожа на программерский баг. Хотя, я деталей не знаю — утверждать наверняка не могу.
Вот только нюанс: для того, чтобы отдать приказ боевой единице не чаще, скажем, чем раз в секунду, надо на эту секунду вперед прогнозировать. Именно способностью к долгосрочным прогнозам на основе неточных данных до сего момента человек обыгрывал ботов. И именно по причине куцей способности к предсказанию, бот вынужден «перекликивать» человека в разы, чтобы играть на том же уровне. Он тупо меняет мнение с частотой 100 герц.
А бот, основанный на нейросетях, «мыслит» так же, как и мы с вами. Он оценивает свои шансы, прогнозирует и отдает приказы на несколько секунд вперед. Именно поэтому у него, как у человека, APM так сильно плавает, в зависимости от того, насколько «горяча» ситуация. И, да, он не промахивается по юнитам и не делает лишние тычки. Но, полагаю, прогеймеры тоже промахиваются довольно редко, а «тычками» только руки прогревают. Так что оценка APM довольно объективна.
Вот в который раз убеждаюсь, что людям нельзя показывать полработы. Извините.
В десяти играх машина успешно предсказывала поведение игрока, делала контры (без этого она бы продула даже в алмазе) и играла на высочайшем уровне. И я говорю не только про пресловутый APM. Простой смертный бы ее и с зарезанным APM-ом не обыграл.
Но стоило товарищам провести ПУБЛИЧНЫЙ эксперимент и выдать НЕДОДЕЛАННУЮ сеть (другую, при том), которая сделала явно тривиальную ошибку, как эта ошибка распространяется на всю серию экспериментов и объявляется универсальной.
Неужели не очевидно, что тут явная бага была? Они что-то не учли. Возможно, в топологии, возможно — в контексте.
В подтверждение моих слов уточню: если бы она в первых десяти играх не могла прогнозировать (а это ей приходилось делать ибо юниты противника она и там не видела), то что же тот же MaNa не размазал ее таким же (или сходным) очевидным способом? Зачем ему было продувать 5 игр, чтобы отыграться в 6й?
В десяти играх машина успешно предсказывала поведение игрока, делала контры
Действительно, общеизвестно же, что сталкеры — это контра имморталам!
В подтверждение моих слов уточню: если бы она в первых десяти играх не могла прогнозировать (а это ей приходилось делать ибо юниты противника она и там не видела), то что же тот же MaNa не размазал ее таким же (или сходным) очевидным способом?
Потому что нейронные сети не умеют прогнозировать. Альфазеро не прогнозирует, что будет строить противник, это не человек. Она не рассуждает. Она просто знает, что, статистически, если в момент Х строить юнита Y и потом отсылать его в Z — вероятность победы выше.
Лет десять назад нейронные сети уже давали профит, трейдерские форумы об этом говорили…
p.s. на истории не научиться как следует, учиться надо на реальных действиях ибо каждое действие меняет реакцию рынка, но для нейронных сетей нужны данные и желательно значительно больше чем кажется необходимо. Конкретно этот обсуждаемый ИИ использует следующий подход — играть сам с собой, т.е. чтобы создать торговый алгоритм, ему необходимо создать эмитатор рынка, который ведет себя похожим образом… это конечно решит задачу получения дохода но выглядит слишком избыточной по сложности, что то мне кажется эта задача пока не по зубам.
Нейросеть AlphaStar обыграла профессионалов StarCraft II со счётом 10−1