Привет, хабровчане!
Меня зовут Алексей. На этот раз я вещаю с рабочего места в ИТАР-ТАСС.
В данном небольшом тексте я познакомлю вас с методом расчета PageRank © (далее буду называть его ПР) на простых, понятных примерах, на языке R. Алгоритм является интеллектуальным достоянием Google, но, ввиду его полезности для задач анализа данных, применяется много в каких задачах, которые можно свести к поиску больших узлов на графе и ранжированию их по значимости.
Упоминания крупной компании в посте не является рекламой.
Так как я не профессиональный математик, в качестве пособия использую — и рекомендую вам — данную статью и этот туториал.
Понять как это работает не сложно. Есть набор элементов, которые связаны между собой. Вот как именно они связаны — это вопрос широкий: может быть, через ссылки (как у Гугла), возможно, через упоминания друг друга (почти те же ссылки), может быть априорно заданы вероятности переходов между элементами (матрица марковского процесса) без уточнения физического смысла связи. Хочется присвоить этим элементам некий критерий важности, который бы нес информацию о вероятности того, что данный элемент будет посещаться некой абстрактной путешествующей по графу частицей в процесс диффузии.
Гм, звучит не очень понятно. Проще представить парня замак ноутбуком, который сёрфит по страницам из поисковой выдачи, покуривая кальян, переходит по ссылкам с одной страницы на другую и все чаще и чаще оказываться на одной и той же странице (или страницах).
Это происходит из-за того, что некоторые страницы, которые он посещают содержат такую интересную информацию в первоисточнике, что другие страницы вынуждены ее перепечатывать с указанием ссылки.
Такого парня в Гугле назвали Random surfer. Он и является частицей в процессе диффузии: дискретной смены положения на графе с течением времени. А вероятность, с которой он посетит страницу при времени диффузии стремящемся к бесконечности, — это и есть ПР.
Условимся — мы работаем с 10 элементами, в таком маленьком, уютном графчике.
Каждый из 10 элементов (нод) содержит от 10 до 14 упоминаний других нод в случайном порядке, исключая себя. На текущий момент просто решим, что данные упоминания — это вэб ссылки.
Ясно, что может получиться так, что какой то из элементов упоминается чаще других. Проверим это.

Так выглядит наша матрица ссылок (называемая по-английски чаще всего adjacency matrix).
Сумма в каждом столбце больше нуля, что означает наличие связи из каждого элемента с каким-либо другим элементом (это важно для дальнейшего анализа).
Можем создать на основе этой таблицы так называемую Affinity matrix, или, по-нашему, матрицу близости (и также ее называют матрицей переходов), которую математики называют стохастичной матрицей (column-stochastic matrix): main source
Присвоим ее переменной с именем A.

Самое главное сейчас, что сумма во всех столбцам равна единице.
Вот она — матрица переходов, она же марковская, она же похожести. Цифири — это вероятности переходов из элемента в столбце в элемент в строке.
Это, конечно, не настоящие «похожести». Настоящие были бы, например, если посчитать косинус угла между представлением документов. Но важно то, что матрица переходов приводится к (псевдо-) вероятностям, чтобы сумма по каждому столбцу была равна единице.
Посмотрим на марковский граф переходов (наша A):

Все примерно равномерно запутано ). Это потому, что мы задали равновероятные переходы.
А теперь время магии!
Для стохастичной матрицы A первое собственное значение должно равняться единице, а соответствующий ей собственный вектор и есть вектор PageRank.
Вот это и есть вектор значений ПР — это нормализованный собственный вектор матрицы переходов A, соответствующий собственному значению этой матрицы, равному единице, — доминантный собственный вектор.
Теперь уже можно отранжировать элементы. Но в силу специфики эксперимента они имеют очень похожий вес.
Матрица переходов A может не удовлетворять условиям стохастичности.
Во-первых, могут быть элементы, которые никуда не ссылаются, то есть с отсутствием обратной связи (на них самих ссылаться могут). Для больших реальных графов это вполне вероятная проблема. Это означает, что одна из колонок матрицы будет иметь только нули. В этом случае решение через собственные вектора не будет работать.
В Гугле решили данную проблему заполнением столбца равномерным распределением вероятностей p = 1/N. Где N — число всех элементов.
Во-вторых, в графе могут быть элементы с обратной связью друг на друга, но не остальные элементы графа. Это также непреодолимая проблема для линейной алгебры в силу нарушения предположений.
Решается введением константы, называемой Damping factor, которая обозначает априорную вероятность перехода из любого элемента на любой другой даже если ссылок нет физически. Иными словами, диффузия возможно при попадании в любое состояние.
Если применить эти преобразования к нашей матрице, то ее опять можно решать через собственные вектора!
В-третьих, банально матрица может получиться не квадратной, а это критично! Я не буду останавливаться на данном моменте, так как верю, что вы сами разберетесь как это исправить.
Но есть более быстрый и точный метод, который также экономнее по памяти (что может быть актуально для больших графов): Power method.
Voila!
На этом я буду заканчивать туториал. Надеюсь, вы найдете его полезным.
Забыл сказать, что для построения матрицы переходов (вероятностей) можно использовать похожесть текстов, количество упоминаний, факт наличия ссылки, и другие метрики, которые приводятся к псевдо-вероятностям или являются вероятностями. Довольно интересный пример — это ранжирование предложений в тексте на матрице похожести мешков слов tf-idf для выделения предложения суммаризирующего весь текст. Могут быть и другие творческие применения ПР.
Я рекомендую попробовать самостоятельно поиграть с матрицей переходов и убедиться, что получаются прикольные значения ПР, которые при этом еще и достаточно легко трактуются.
Если вы увидите неточности или ошибки у меня — укажите в комментариях или сообщении, а я все поправлю.
Весь код собран здесь:
P.S.: вся эта затея также легко реализуется на других языках, по крайней мере, на Python я все сделал без затруднений.
Меня зовут Алексей. На этот раз я вещаю с рабочего места в ИТАР-ТАСС.
В данном небольшом тексте я познакомлю вас с методом расчета PageRank © (далее буду называть его ПР) на простых, понятных примерах, на языке R. Алгоритм является интеллектуальным достоянием Google, но, ввиду его полезности для задач анализа данных, применяется много в каких задачах, которые можно свести к поиску больших узлов на графе и ранжированию их по значимости.
Упоминания крупной компании в посте не является рекламой.
Так как я не профессиональный математик, в качестве пособия использую — и рекомендую вам — данную статью и этот туториал.
Интуитивное понимание ПР
Понять как это работает не сложно. Есть набор элементов, которые связаны между собой. Вот как именно они связаны — это вопрос широкий: может быть, через ссылки (как у Гугла), возможно, через упоминания друг друга (почти те же ссылки), может быть априорно заданы вероятности переходов между элементами (матрица марковского процесса) без уточнения физического смысла связи. Хочется присвоить этим элементам некий критерий важности, который бы нес информацию о вероятности того, что данный элемент будет посещаться некой абстрактной путешествующей по графу частицей в процесс диффузии.
Гм, звучит не очень понятно. Проще представить парня за
Это происходит из-за того, что некоторые страницы, которые он посещают содержат такую интересную информацию в первоисточнике, что другие страницы вынуждены ее перепечатывать с указанием ссылки.
Такого парня в Гугле назвали Random surfer. Он и является частицей в процессе диффузии: дискретной смены положения на графе с течением времени. А вероятность, с которой он посетит страницу при времени диффузии стремящемся к бесконечности, — это и есть ПР.
Простая реализация расчета ПР
Условимся — мы работаем с 10 элементами, в таком маленьком, уютном графчике.
# clear environment
rm(list = ls()); gc()
## load libs
library(data.table)
library(magrittr)
library(markovchain)
## dummy data
number_nodes <- 10
node_names <- letters[seq_len(number_nodes)]
set.seed(1)
nodes <- sapply(
seq_len(number_nodes), function(x)
{
paste(
c(
node_names[-x]
, sample(node_names[-x], sample(1:5, 1), replace = T)
)
, collapse = ' '
)
}
)
names(nodes) <- node_names
print(
paste(nodes, collapse = '; ')
)
## make long dt
dt <-
data.table(
citing_node = node_names
, cited_node = nodes
) %>%
.[, .(cited_node = unlist(strsplit(cited_node, ' '))), by = citing_node] %>%
dcast(
.
, cited_node ~ citing_node
, fun.aggregate = length
)
dt
apply(dt[,-1,with=F], 2, sum)
## affinity matrix
A <- as.matrix(dt[, 2:dim(dt)[2]])
A <- sweep(A, 2, colSums(A), `/`)
A[is.nan(A)] <- 0
rowSums(A)
colSums(A)
mark <- new("markovchain", transitionMatrix = t(A), states = node_names, name = "mark")
plot(mark)
Каждый из 10 элементов (нод) содержит от 10 до 14 упоминаний других нод в случайном порядке, исключая себя. На текущий момент просто решим, что данные упоминания — это вэб ссылки.
Ясно, что может получиться так, что какой то из элементов упоминается чаще других. Проверим это.
Кстати, рекомендую для экспериментов юзать пакет data.table. В связке с принципами tidyverse все получается эффективно и быстро.
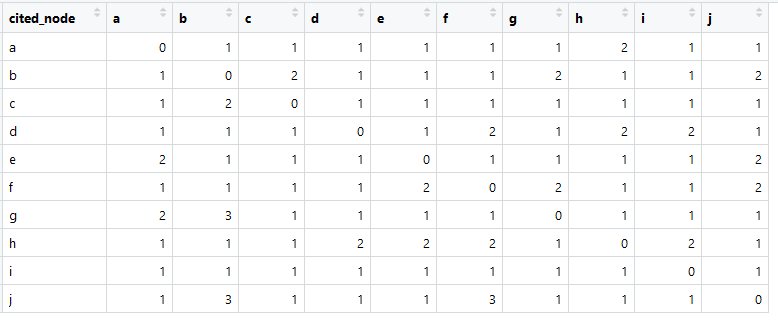
Так выглядит наша матрица ссылок (называемая по-английски чаще всего adjacency matrix).
Сумма в каждом столбце больше нуля, что означает наличие связи из каждого элемента с каким-либо другим элементом (это важно для дальнейшего анализа).
> apply(dt[,-1,with=F], 2, sum)
a b c d e f g h i j
11 14 10 10 11 13 11 11 11 12
Можем создать на основе этой таблицы так называемую Affinity matrix, или, по-нашему, матрицу близости (и также ее называют матрицей переходов), которую математики называют стохастичной матрицей (column-stochastic matrix): main source
Присвоим ее переменной с именем A.
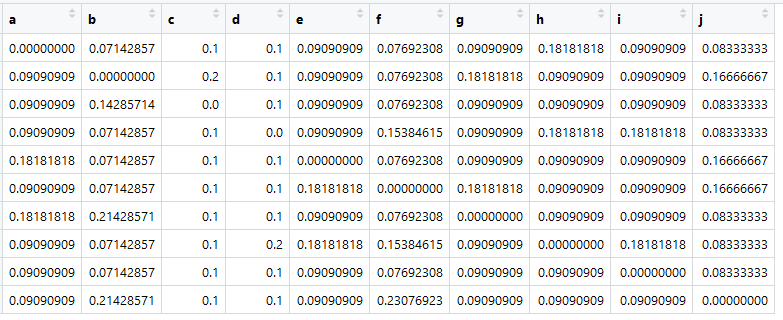
Самое главное сейчас, что сумма во всех столбцам равна единице.
> colSums(A)
a b c d e f g h i j
1 1 1 1 1 1 1 1 1 1
Вот она — матрица переходов, она же марковская, она же похожести. Цифири — это вероятности переходов из элемента в столбце в элемент в строке.
Это, конечно, не настоящие «похожести». Настоящие были бы, например, если посчитать косинус угла между представлением документов. Но важно то, что матрица переходов приводится к (псевдо-) вероятностям, чтобы сумма по каждому столбцу была равна единице.
Посмотрим на марковский граф переходов (наша A):
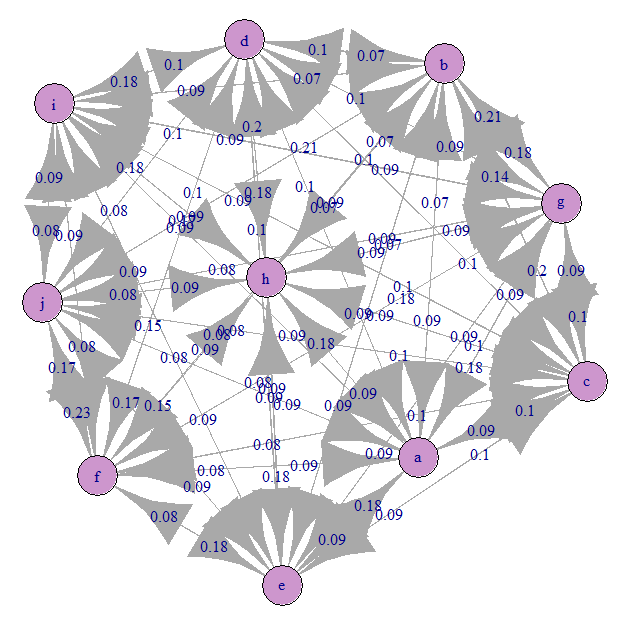
Все примерно равномерно запутано ). Это потому, что мы задали равновероятные переходы.
А теперь время магии!
## calculate pagerank
ei <- eigen(A)
as.numeric(ei$values[1])
pr <- as.numeric(ei$vectors[,1] / sum(ei$vectors[,1]))
sum(pr)
names(pr) <- node_names
print(round(pr, 2))
Для стохастичной матрицы A первое собственное значение должно равняться единице, а соответствующий ей собственный вектор и есть вектор PageRank.
> print(round(pr, 2))
a b c d e f g h i j
0.09 0.11 0.09 0.10 0.10 0.11 0.10 0.11 0.08 0.11
Вот это и есть вектор значений ПР — это нормализованный собственный вектор матрицы переходов A, соответствующий собственному значению этой матрицы, равному единице, — доминантный собственный вектор.
Теперь уже можно отранжировать элементы. Но в силу специфики эксперимента они имеют очень похожий вес.
Проблемы и их решение с помощью power-метода
Матрица переходов A может не удовлетворять условиям стохастичности.
Во-первых, могут быть элементы, которые никуда не ссылаются, то есть с отсутствием обратной связи (на них самих ссылаться могут). Для больших реальных графов это вполне вероятная проблема. Это означает, что одна из колонок матрицы будет иметь только нули. В этом случае решение через собственные вектора не будет работать.
В Гугле решили данную проблему заполнением столбца равномерным распределением вероятностей p = 1/N. Где N — число всех элементов.
dim.1 <- dim(A)[1]
A <- as.data.table(A)
nul_cols <- apply(A, 2, function(x) sum(x) == 0)
if(
sum(nul_cols) > 0
)
{
A[
, (colnames(A)[nul_cols]) :=
lapply(.SD, function(x) 1 / dim.1)
, .SDcols = colnames(A)[nul_cols]
]
}
A <- as.matrix(A)
Во-вторых, в графе могут быть элементы с обратной связью друг на друга, но не остальные элементы графа. Это также непреодолимая проблема для линейной алгебры в силу нарушения предположений.
Решается введением константы, называемой Damping factor, которая обозначает априорную вероятность перехода из любого элемента на любой другой даже если ссылок нет физически. Иными словами, диффузия возможно при попадании в любое состояние.
d = 0.15 #damping factor (to ensure algorithm convergence)
M <- (1 - d) * A + d * (1 / dim.1 * matrix(1, nrow = dim.1, ncol = dim.1)) # google matrix
Если применить эти преобразования к нашей матрице, то ее опять можно решать через собственные вектора!
В-третьих, банально матрица может получиться не квадратной, а это критично! Я не буду останавливаться на данном моменте, так как верю, что вы сами разберетесь как это исправить.
Но есть более быстрый и точный метод, который также экономнее по памяти (что может быть актуально для больших графов): Power method.
## pagerank function (tested on example from tutorial)
rm(pagerank_func)
pagerank_func <- function(
A #transition matrix
, eps = 0.00001 #sufficiently small error
, d = 0.15 #damping factor (to ensure algorithm convergence)
)
{
dim.1 <- dim(A)[1]
A <- as.data.table(A)
nul_cols <- apply(A, 2, function(x) sum(x) == 0)
if(
sum(nul_cols) > 0
)
{
A[
, (colnames(A)[nul_cols]) :=
lapply(.SD, function(x) 1 / dim.1)
, .SDcols = colnames(A)[nul_cols]
]
}
A <- as.matrix(A)
M <- (1 - d) * A + d * (1 / dim.1 * matrix(1, nrow = dim.1, ncol = dim.1)) # google matrix
rank = as.numeric(rep(1 / dim.1, dim.1))
## iterate until convergence
while(
sum(
(rank - M %*% rank) ^ 2
) > eps
)
{
rank <- M %*% rank
}
return(rank)
}
pr2 <- pagerank_func(A)
pr2=as.vector(pr2)
names(pr2)=node_names
Voila!
> print(round(pr, 2))
a b c d e f g h i j
0.09 0.11 0.09 0.10 0.10 0.11 0.10 0.11 0.08 0.11
> print(round(pr2, 2))
a b c d e f g h i j
0.09 0.11 0.09 0.10 0.10 0.11 0.10 0.11 0.08 0.11
На этом я буду заканчивать туториал. Надеюсь, вы найдете его полезным.
Забыл сказать, что для построения матрицы переходов (вероятностей) можно использовать похожесть текстов, количество упоминаний, факт наличия ссылки, и другие метрики, которые приводятся к псевдо-вероятностям или являются вероятностями. Довольно интересный пример — это ранжирование предложений в тексте на матрице похожести мешков слов tf-idf для выделения предложения суммаризирующего весь текст. Могут быть и другие творческие применения ПР.
Я рекомендую попробовать самостоятельно поиграть с матрицей переходов и убедиться, что получаются прикольные значения ПР, которые при этом еще и достаточно легко трактуются.
Если вы увидите неточности или ошибки у меня — укажите в комментариях или сообщении, а я все поправлю.
Весь код собран здесь:
Код
# clear environment
rm(list = ls()); gc()
## load libs
library(data.table)
library(magrittr)
library(markovchain)
## dummy data
number_nodes <- 10
node_names <- letters[seq_len(number_nodes)]
set.seed(1)
nodes <- sapply(
seq_len(number_nodes), function(x)
{
paste(
c(
node_names[-x]
, sample(node_names[-x], sample(1:5, 1), replace = T)
)
, collapse = ' '
)
}
)
names(nodes) <- node_names
print(
paste(nodes, collapse = '; ')
)
## make long dt
dt <-
data.table(
citing_node = node_names
, cited_node = nodes
) %>%
.[, .(cited_node = unlist(strsplit(cited_node, ' '))), by = citing_node] %>%
dcast(
.
, cited_node ~ citing_node
, fun.aggregate = length
)
dt
apply(dt[,-1,with=F], 2, sum)
## affinity matrix
A <- as.matrix(dt[, 2:dim(dt)[2]])
A <- sweep(A, 2, colSums(A), `/`)
A[is.nan(A)] <- 0
rowSums(A)
colSums(A)
mark <- new("markovchain", transitionMatrix = t(A), states = node_names, name = "mark")
plot(mark)
## calculate pagerank
ei <- eigen(A)
as.numeric(ei$values[1])
pr <- as.numeric(ei$vectors[,1] / sum(ei$vectors[,1]))
sum(pr)
names(pr) <- node_names
print(round(pr, 2))
## pagerank function (tested on example from tutorial)
rm(pagerank_func)
pagerank_func <- function(
A #transition matrix
, eps = 0.00001 #sufficiently small error
, d = 0.15 #damping factor (to ensure algorithm convergence)
)
{
dim.1 <- dim(A)[1]
A <- as.data.table(A)
nul_cols <- apply(A, 2, function(x) sum(x) == 0)
if(
sum(nul_cols) > 0
)
{
A[
, (colnames(A)[nul_cols]) :=
lapply(.SD, function(x) 1 / dim.1)
, .SDcols = colnames(A)[nul_cols]
]
}
A <- as.matrix(A)
M <- (1 - d) * A + d * (1 / dim.1 * matrix(1, nrow = dim.1, ncol = dim.1)) # google matrix
rank = as.numeric(rep(1 / dim.1, dim.1))
## iterate until convergence
while(
sum(
(rank - M %*% rank) ^ 2
) > eps
)
{
rank <- M %*% rank
}
return(rank)
}
pr2 <- pagerank_func(A)
pr2=as.vector(pr2)
names(pr2)=node_names
print(round(pr, 2))
print(round(pr2, 2))
P.S.: вся эта затея также легко реализуется на других языках, по крайней мере, на Python я все сделал без затруднений.







