Комментарии 24
Можно переписать на int-ы конкретно преобразование Фурье (и есть уже куча готовых библиотек для этого), но переписывать большие сложные алгоритмы использующие самую разную математику с плавающей точки на int-ы не практично, так как чрезвычайно затратно по объему квалифицированного труда инженеров. И вот в таких случаях posit может проявить себя, если будет реализован в железе. Плюс далеко не во всех приложениях важен объем памяти, где-то важнее точность и используют расширенные представления чисел с плавающей точкой в 10 или 16 байтов, а с posit для этих приложений может хватить и 64-битных чисел (а может и не хватить — зависит от задачи). То есть смысл в нем был бы при аппаратной поддержке в процессоре именно как для прямой замены float/double, прозрачной для 99.999% кода, не требующей изменений в программах, кроме некоторых самых корных функций системных библиотек и компиляторов.
Позит — это не волшебная палочка какая-то, чтобы 8 байт в 16 превращать. Максимальное теоретическое преимущество posit64 над float64 по длине мантиссы — 7 бит, потому что у float64 11 бит порядка, а у posit64 минимум 4.
Это понятно, но если не хватает 52 битов в double, то иногда используют расширенную точность ради нескольких битов. Которая у некоторых платформ была реализована в виде 16-байтовых значений (IBM 370+, SPARC, Power с его double-double, может что-то еще). Overkill когда это для дополнительных пары битов, но если железо таково, то использовали это для быстроты работы. Плюс даже на x86 из-за проблем с выравниванием обычно пишут 10-байтовые long double по адресам кратным 16, а не 10.
А, ну если так — то да, может где-то быть полезно. Но тут вопрос, стоит ли овчинка выделки. А то, скажем, при покупке GPU платишь и за блок single-precision, и за блок half-precision, даже если нужны исключительно double и ни битом меньше. А тут аппаратная поддержка ещё одного типа с плавающей точкой, нужного не только лишь всем.
for (int i = 0; i < data.size(); i++)
{
double v = data[i];
data_posit[i] = Posit32(v).getDouble();
data_float[i] = float(v);
}Реализация Posit отсюда.
gitlab.com/cerlane/SoftPosit/blob/master/source/c_convertPosit32ToDec.c
Я посмотрел код использованной вами реализации и она значительно отличается от оригинала, есть подозрения :)
И не понятно каким образом Posit 32 «уползла» от float32, вроде бы они «совместимы».
Хорошо бы добавить в статью типичный кейс числа double, которое вы используете со значениями мантисс/экспонент и таки обоснование почему Posit32 «уползает» по точности.
Я думал вы как автор топика попробуете это самостоятельноМне, как автору двух топиков было интересно разобраться, кто прав. Сравнивать между собой различные реализации Posit уже не интересно. Если вам это интересно — сравнивайте, пишите, и тоже станете автором своего собственного топика.
Я посмотрел код использованной вами реализации и она значительно отличается от оригинала, есть подозрения :)Я его выбрал, потому что:
— 214 звёзд
— 20 форков
— хорошо написан
— есть тесты
— С++
обоснование почему Posit32 «уползает» по точностиПодробно расписано здесь.
Раздел 1.2:
The following lemma is quite useful when experimenting with
posits:
Lemma 1.1 (Exact cast to FP64). Any Posit8, Posit16 or Posit32
except NaR is exactly representable as an IEEE-754 FP64 (double precision) number.
Я его выбрал, потому что: хорошо написан
В комментариях к вашей прошлой статье уже обсуждали, что написана эта реализация спорно. В частности, у меня были вопросы к реализации извлечения корня.
ogamespec, было бы действительно здорово, если вы сравните две реализации posit-ов. Или повторите тесты с библиотекой от авторов posit-а. Я, как человек не знающий С/С++, это сделать не могу :(
#include "pch.h"
#include "CppUnitTest.h"
/// BFP
#include "posit.h"
/// SoftPosit
extern "C"
{
#include "platform.h"
#include "internals.h"
};
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace PositConvertUnitTest
{
TEST_CLASS(PositConvertUnitTest)
{
public:
TEST_METHOD(TestMethod1)
{
Logger::WriteMessage("0: ");
TestPositConv(0);
Logger::WriteMessage("1: ");
TestPositConv(1.0);
Logger::WriteMessage("EPSILON: ");
TestPositConv(DBL_EPSILON);
Logger::WriteMessage("MIN: ");
TestPositConv(DBL_MIN);
Logger::WriteMessage("MAX: ");
TestPositConv(DBL_MAX);
}
void TestPositConv(double v)
{
Posit32 p32(v);
double vBfp = p32.getDouble();
posit32_t bits = { 0 };
bits.v = p32.getBits();
double vSP = convertP32ToDouble(bits);
Assert::IsTrue(vBfp == vSP);
Logger::WriteMessage(("double:" + std::to_string(v)
+ ", posit32 bits: " + to_hexstring(bits.v)
+ ", posit32->Bfp:" + std::to_string(vBfp)
+ ", posit32->SP: " + std::to_string(vSP)
+ "\n").c_str());
}
std::string to_hexstring(uint64_t value)
{
std::stringstream stream;
stream << "0x" << std::hex << value << std::dec;
return stream.str();
}
};
}
Лог:
0: double:0.000000, posit32 bits: 0x0, posit32->Bfp:0.000000, posit32->SP: 0.000000
1: double:1.000000, posit32 bits: 0x40000000, posit32->Bfp:1.000000, posit32->SP: 1.000000
EPSILON: double:0.000000, posit32 bits: 0x20000, posit32->Bfp:0.000000, posit32->SP: 0.000000
MIN: double:0.000000, posit32 bits: 0x1, posit32->Bfp:0.000000, posit32->SP: 0.000000
MAX: double:179769313486231570814527423731704356798070567525844996598917476803157260780028538760589558632766878171540458953514382464234321326889464182768467546703537516986049910576551282076245490090389328944075868508455133942304583236903222948165808559332123348274797826204144723168738177180919299881250404026184124858368.000000, posit32 bits: 0x7fffffff, posit32->Bfp:1329227995784915872903807060280344576.000000, posit32->SP: 1329227995784915872903807060280344576.000000
Обе библиотеки конвертируют одинаково по edge-кейсам.
Если утверждения авторов верны, то погрешность, вносимая преобразованием Double→Posit→Double будет ближе к Doublе, чем к Float
Простите, а почему ближе к Double? Не ровно посередине между Float и Double? Признаюсь, я не погружался глубоко в тему и читал только статьи на Хабре, и Posit32 сравнивается с Float. В этой статье есть табличка с динамическими диапазонами:
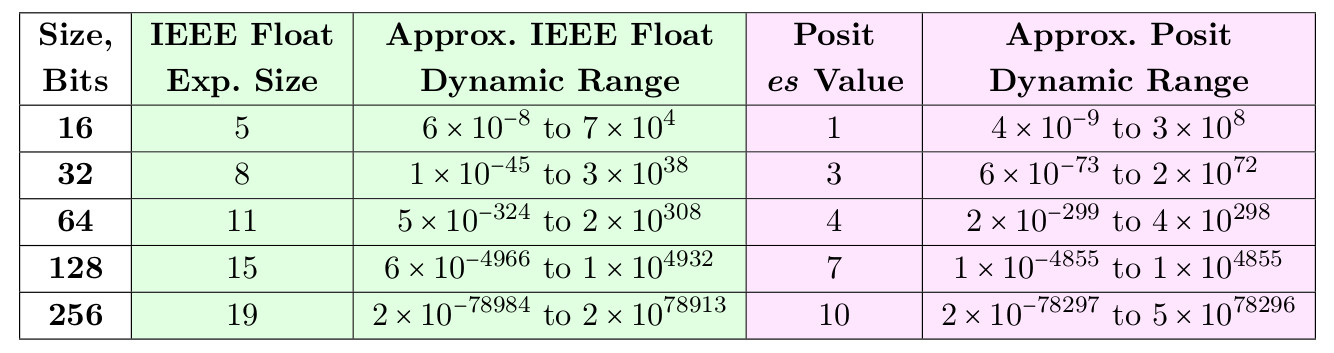
, и там Posit с es value=3 (что бы это ни значило) гораздо ближе к Float, чем Double.
Кроме того, в комментариях я видел утверждения, что Posit32 by design превосходит Float по точности в диапазоне до 10^6, за что расплачивается меньшей точностью на числах 10^20. Это соответствует действительности?
С 64-double нужно сравнивать 64-posit.
Но тут 64-posit даже не приводится и ни капли не тестируется ((
Спектральный анализ не подтвердил заявления авторов о том, что использование формата Posit в качестве хранения может обеспечить точность близкую к Double.На правах автора предыдущей статьи: такого не утверждалось. У Double мантисса 52 бита для любых значений. Тут не нужен спектральный анализ чтобы осознать что 32-битным Posit не достичь аналогичной точности для любых значений.
Утверждалось что Posit32 могут успешно заменить Double там, где Float32 использовать недопустимо, но не из-за точности представления, а из-за накопления ошибок при вычислениях.
Posit32 дадут меньше шума чем Float32 для нормализованных значений с не очень большим разбросом. И потому могут быть хорошей альтернативой Float (предоставляя лучшую точность) или Double (там где настолько высокая точность представления ценой увеличения объема в 2 раза не нужна).
Если точности Float32/Posit32 недостаточно, можно попробовать использовать Posit64. По идее они должны давать меньше шума чем Double даже на относительно высоких амплитудах. Очень интересно было бы увидеть аналогичные графики для них.
Испытания Posit по-взрослому. Спектральный анализ