Комментарии 88
бла бла бла
вся статья о том, что кеш нам нужен, или не нужен, так нужен или нет, нет или да, да или нет, нужен или не нужен?
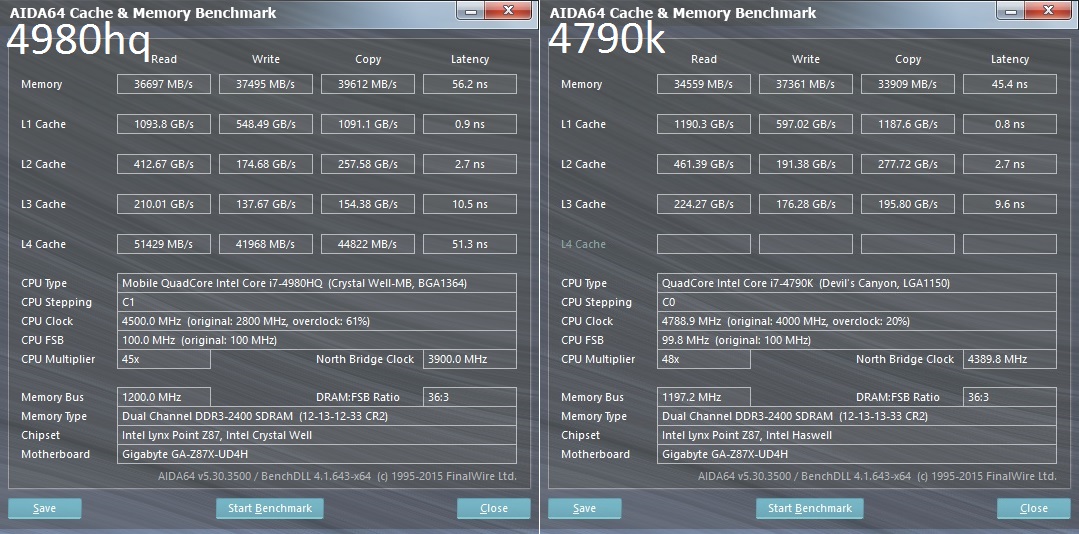
1) інтел лет 5 назад уже обещала л4, так и не сделалаСправедливости ради, L4 кеш у них таки был — на ноутбучных Crystall Well и Broadwell. Там он шел на отдельном чипе под IHS. Учитывая, что скорость у него была, как у нынешней хорошей DDR4, неплохо показывал себя как минимум в игрушках. Китайцы даже начали припаивать к ним подложки и продавать как процессоры в 1150 сокет, пока их со всех торговых площадок не поперли за сомнительное качество пайки этой самой подложки.
{kind=link}

Мне кажется в скорости SSD сейчас мало что упирается. Это может дать прирост только программам, которые активно используют дисковые операции. В основном вся программа находится в оперативной памяти.
Это иллюзии.
Как только у вас мало что станет упираться в скорость ссд, то у вас начнут отмирать скриптовые языки — php, python, js, ruby.
Ибо проигрыш компилируемым языкам в реальных приложениях станет просто абсолютно не приличным.
Но пока мы этого не наблюдаем. Зато наблюдаем vscode, slack и кучу всего на бекенде веба на скриптовых языках.
Не понял, как это связано и что мешает им начать отмирать сейчас? Неприличный проигрыш сам по себе не явлется причиной, они и сейчас уже проигрывают. Скрипты же один раз загружаются в память и дальше используются уже оттуда?
Как только у вас мало что станет упираться в скорость ссд, то у вас начнут отмирать скриптовые языки — php, python, js, ruby.Ни в коем разе не фанат ни одного из этих языков, но проблема зачастую а) в сетевом I/O б) в пользовательском вводе-выводе. Диск не грузится на 100% в подавляющем большинстве реальных приложений.
И вообще прочтённый в память скрипт не может тормозить из-за ССД, потому что он в памяти.
Как писали здесь, возникает проблема с охлаждением такого бутерброда.
Ничего дополнительно для этого в плане архитектуры делать не нужно.
Программы с компактным «ядром данных» сейчас уже почти не реагируют на скорость основной памяти — изменение ее скорости даже в 2-3 раза меняет общую скорость работы таких программ только на несколько %. Как раз потому что почти вся работа идет уже в кэшах процессора.
P.S.
Несколько ГБ внутри процессора не будет, это речь только L4 кэшах на других отдельных технологиях — типа чипа HBM памяти на одной подложке и под одной крышкой рядом с кристаллом процессора. Несколько ГБ обычного SRAM кэша внутрь процессора пока запихнуть невозможно. Даже текущие несколько десятков МБ кэша почти половину всех транзисторов в современных процессорах занимают. SRAM при наличии «лишних» транзисторов пойдет на дальнейшее увеличение объемов L2 и L3 кэшей.
Действительно случайное чтение у SSD раз в 10 медленнее, т.к. по задержкам доступа даже EDO RAM в сотни раз лучше SSD: меньше 100 наносекунд у EDO против нескольких десятков микросекунд у хороших NVMe SSD.
pci 4.0 не существует, есть PCI-E 4.0.
Скорость SSD на PCI-E 3.0 4x упирается в 3,5 Гбайт/с, 7 Гбайт/с — предел для PCI-E 4.0 4x, который в 2020 году вряд ли будет достигнут.
Что-то мне не нравится эта пирамида, страшно подумать, как когерентность будет поддерживаться. С моего дивана кажется, что нужно снизить многозадачность на ядро/процессор, максимально перейти к NUMA и допилить предвыборку в компиляторах. Не вижу ничего ужасного, если ОС будет предоставлять аппаратный пул потоков, а на материнках рядом с памятью будет рядок Slot A.
1. А почему ширина шины памяти до сих пор 64 бита, а не 512, как бывает у видеокарт?
2. Почему процессорные кеши занимают намного больше места, чем ОЗУ?
А почему ширина шины памяти до сих пор 64 бита, а не 512, как бывает у видеокарт?А потому, что у GPU строго параллельный (по числу ядер) процесс выполнения, а CPU зачастую с отдельными байтиками ковыряется.
Почему процессорные кеши занимают намного больше места, чем ОЗУ?А потому, что кеш — статическая память, каждая ячейка — триггер, минимум 6 транзисторов, а ОЗУ — динамическая память, 1 транзистор на ячейку.
2) Потому что статическая память, а не динамическая.
У ГПУ внутри обычно тоже не одна широкая шина на 512 бит, а несколько отдельных по 64 или 128 бит, просто для упрощения пишут общую сумму всех шин.
Да и 512 бит даже в топовых ГПУ сейчас уже не применяется, 256-384 бита максимум. На младших моделях 128-192 бита.
Почему уже выше написали — дорого и сложно на платах такое количество контактов и дорожек разводить так чтобы они друг другу и другим схемам на плате не мешали. Поэтому выпустив несколько моделей с 512бит шиной после этого от таких широких шин отказались.
Только вот ранее толку от него не было.
А вот в видяхах толк от большей разрядности шины памяти был.
Это Dual Channel и т.д.
И что же это по-вашему?
Каждый канал DIMM представляет свой контроллер памяти, точно так же как и для видеокарт.
Просто у видеокарты (к примеру) 16 контроллеров * 32 бит GDDR5, а у какого-нибудь EPYC — 8 каналов * 64 bit DDR4.
Что в обоих случаях даёт эффективную ширину 512-бит. HBM имеет широкую шину, но разницы тут нет принципиальной.
А вот в видяхах толк от большей разрядности шины памяти был.Это зависит сугубо от задачи. Если вы обрабатываете скалярные данные, вам ПСП и ну нужна — вы её физически не сможете реализовать.
Используйте многопоточный код + SIMD — тогда и будет толк от ПСП.
А дальше в зависимости от количества этих самых стеков подключенных к процессору. От 1 до 4 в настоящий момент существуют варианты, так что от 1024 до 4096 бит суммарно.
Единственное большое изменение в ddr 5 такое же как как и было во всех предыдущих версиях DDR — это очередное удвоение частоты шины и удвоение размера предвыборки данных, позволяющие данные по шине слать в удвоенном темпе при сохранении частоты работы самих микросхем памяти примерно на том же уровне. ПС станет еще больше, но и относительные задержки тоже в очередной раз вырастут.
Все остальные изменения в стандарте второстепенные — чуть ниже стандартное рабочее напряжение, увеличение максимально возможной емкости одного модуля и другие.
Режим с 2 подканалами это просто логическая организация, когда вместо 1 канала в 64 бита его можно представить как 2 виртуальных канала по 32 бита. Но общая ширина и ПС не меняются от этого.
- Изменить архитектуру процессора так, чтобы в нём было много регистров. Я думаю, 32 или 64 регистра общего назначения — нормально.
- Изменить архитектуру процессора так, чтобы для разных режимов процессора (как правило, их два: user-space и kernel-space; по хорошему надо бы иметь отдельный interrupt-space) был свой набор регистров. Ну, user-space и kernel-space должны иметь общие регистры для обмена данными при системных вызовах; а вот для interrupt-space нужен полностью собственный набор регистров. Это избавит от необходимости сохранять регистры в память при переключении контекста. Впрочем, потребность в кэше это вряд ли снизит.
- Изменить архитектуру процессора так, чтобы в нём был регистровый файл. С т.з. программ — это как бы оперативная память, но отдельная для каждого ядра; так что обращения в регистровый файл не приводят в обращению в оперативную память.
- Изменить архитектуру компьютера, отказавшись от общей памяти для всех ядер. В каком-то смысле это эквивалентно увеличению скорости оперативной памяти — время отклика сохраняется, а вот скорость чтения/записи больших объёмов растёт примерно пропорционально количеству пулов памяти. Ну и количество коллизий при одновременном обращении нескольких ядер в память — тоже снизится.
Изменить архитектуру процессора так, чтобы в нём было много регистров. Я думаю, 32 или 64 регистра общего назначения — нормально.
Мне кажется это нереально, учитывая то, что для каждой команды для работы с регистрами есть свой микрокод, это очень усложнит структуру процессора.
{kind=link}
«Полезные» регистры — части с ZMM0-ZMM31, ST(0)-ST(7), и RAX-R15.
Проблема в другом — когда у вас много регистров у вас получается более «рыхлым» код.
Оптимум где-то между 16 и 32 регистрами (зависит от задач).
Изменить архитектуру процессора так, чтобы в нём было много регистров. Я думаю, 32 или 64 регистра общего назначения — нормально.
Давно уж сделано. ЕМНИП, в Эльбрусе вообще 192 архитектурных регистра.
Изменить архитектуру процессора так, чтобы для разных режимов процессора (как правило, их два: user-space и kernel-space; по хорошему надо бы иметь отдельный interrupt-space) был свой набор регистров. Ну, user-space и kernel-space должны иметь общие регистры для обмена данными при системных вызовах; а вот для interrupt-space нужен полностью собственный набор регистров. Это избавит от необходимости сохранять регистры в память при переключении контекста. Впрочем, потребность в кэше это вряд ли снизит.
Зачем такие сложности, если можно сделать регистровое окно поверх большего количества архитектурных регистров? Например, у Вас есть 128 физических регистров и хотите сделать окно в 32 регистра. Тогда нужно добавить команды циклического сдвига окна на +32 (call) и -32(return), простое переименование регистров (номер физического регистра = номер архитектурного + 32 * номер окна) и механизм вытеснения данных в память из этого регистрового файла при сдвиге окна на уже занятое место.
3 пункт вообще не понял: сами по себе регистровые файлы уже давно сделаны. Это те самые регистровые файлы, про которые Вы говорите, или нет?
Изменить архитектуру компьютера, отказавшись от общей памяти для всех ядер.
Тоже не вполне понял. Вы имеете в виду сделать верхний уровень кэш-памяти приватным для каждого ядра?
В каком-то смысле это эквивалентно увеличению скорости оперативной памяти — время отклика сохраняется, а вот скорость чтения/записи больших объёмов растёт примерно пропорционально количеству пулов памяти.
Почему?
Ну и количество коллизий при одновременном обращении нескольких ядер в память — тоже снизится.
И опять-таки почему?
Давно уж сделано. ЕМНИП, в Эльбрусе вообще 192 архитектурных регистра.Ну так давно пора внедрять процессоры с большим количеством регистров вместо дурацкого *86.
Зачем такие сложности, если можно сделать регистровое окно поверх большего количества архитектурных регистров?Для того, чтобы при переключении в другой режим не надо было программно давать приказ на переименование регистров. Особенно актуально это для прерываний.
Это те самые регистровые файлы, про которые Вы говорите, или нет?Вариантов реализации регистрового файла много. Какие-то уже реализованы.
Нет. Я имею в виде — раздельную оперативную память (ту, котоорая сейчас DDR3 или типа того — DIMM-модули). Ну и надо сделать раздельные шины для доступа к этим модулям памяти.Изменить архитектуру компьютера, отказавшись от общей памяти для всех ядер.Вы имеете в виду сделать верхний уровень кэш-памяти приватным для каждого ядра?
Даже не знаю, как ответить. Настолько очевидно, что мне непонятно, что Вам непонятно.В каком-то смысле это эквивалентно увеличению скорости оперативной памяти — время отклика сохраняется, а вот скорость чтения/записи больших объёмов растёт примерно пропорционально количеству пулов памяти.Почему?
Независимо от того, сколько у нас модулей памяти (или дисков — к ним это тоже относится), время отклика остаётся неизменным. Ну, фактически по определению.
При этом если направить запросы в разные модули памяти, то они могут отдавать или принимать данные параллельно. Поэтому предельная скорость растёт пропорционально количеству пулов памяти; а реально — ну, как повезёт.
Опять очевидно.Ну и количество коллизий при одновременном обращении нескольких ядер в память — тоже снизится.И опять-таки почему?
Допустим, у меня есть два ядра (в одном чипе или в разных). Допустим, у них раздельный кэш (с общим кэшем — ситуация сложнее). При промахе какого-то ядра в кэш — обращение направляется в память.
Если два ядра одновременно промахнулись в кэш и поэтому обратились в память (точнее, второе ядро обратилось в память тогда, когда первое ядро ещё обслуживается), то происходит коллизия.
Однако, если выдать каждому ядру свой пул памяти и свою шину — то коллизий не м.б. в принципе. Очевидно.
А плата за это = трудности при переносе задачи с одного ядра на другое. И трудности при обмене данными между программами, выполняющимися на разных пулах памяти; в т.ч. невозможность запуска разных потоков одного процесса на разных ядрах.
А ещё при раздельной памяти — не надо синхронизировать кэш. Это тоже заметный выигрыш по цене. Но плата за это — названа выше.
Ну так давно пора внедрять процессоры с большим количеством регистров вместо дурацкого *86.
Главное при этом — не добавлять новые команды в дополнение к существующим. Больше префиксов богу префиксов.
И, кстати, как тогда быть с суперскалярностью и предсказателем переходов? Увеличение числа регистров сильно это дело усложнит.
Для того, чтобы при переключении в другой режим не надо было программно давать приказ на переименование регистров. Особенно актуально это для прерываний.
А чем переименование плохо? Особенно учитывая, что в современных процессорах переименование и так используется, просто оно скрыто от программиста.
Нет. Я имею в виде — раздельную оперативную память (ту, котоорая сейчас DDR3 или типа того — DIMM-модули). Ну и надо сделать раздельные шины для доступа к этим модулям памяти.
И это все равно не поможет преодолеть фундаментальное ограничение в виде задержки доступа к памяти. Да, за счёт отсутствия необходимости разрешения коллизий можно сэкономить пару тактов, но эта выгода незначительна по сравнению со временем доступа к самой памяти.
Кстати, уже есть пример подобной организации памяти: Threadripper (ядро Zen) в NUMA-режиме. Правда, из Zen 2 этот режим выпилили, решив проблемы с масштабируемостью.
При этом если направить запросы в разные модули памяти, то они могут отдавать или принимать данные параллельно. Поэтому предельная скорость растёт пропорционально количеству пулов памяти; а реально — ну, как повезёт.
Там современные процессоры уже умеют в многоканальный доступ. А если, следуя вашему предложению, разделить память на пулы, то получим в итоге замедление: если раньше одно ядро могло использовать сразу несколько каналов, то теперь сможет только одно.
Будущее, как мне кажется, за увеличением ширины шины — пока что тут есть куда расти.
Главное при этом — не добавлять новые команды в дополнение к существующим.Набор команд надо составлять заново.
И, кстати, как тогда быть с суперскалярностью и предсказателем переходов?От супескалярности следует отказаться. Ну или прописывать её явно, выделив в команде поле под это дело.
При большом числе регистров — зависящие по данным команды можно разнести далеко.
А чем переименование плохо?Если для режима обработки прерываний используется свой набор регистров — то м.б. уверенным, что он остаётся нетронутым между прерываниями, при переключении в остальные режимы. Можно ли гарантировать эио при переименовании?
И это все равно не поможет преодолеть фундаментальное ограничение в виде задержки доступа к памяти.Если обращения в память редкие — на задержки можно наплевать.
Да, за счёт отсутствия необходимости разрешения коллизий можно сэкономить пару тактовПроблема не в экономии тактов, а в лимите на количество ядер.
Допустим, у нас есть одно ядро с одним мегабайтом кэша. На типичной программе miss_rate=1%, при этом miss_time=10%, т.е. шина «процессор-память» занята 10% времени.
Почему такая разница?
Каким будет miss_time, если miss_rate=100%?
Хорошо, а что будет, если у меня не одно ядро, а десять или двенадцать? На них работают независимые программы — с другими кодом и данными.
Кстати, уже есть пример подобной организации памяти: Threadripper (ядро Zen) в NUMA-режиме.Это явно не оно. Это скорее отключение синхронизации кэшей — т.е. UMA:S (Uniform Memory Access: Separate). По методам работы в таком режиме — оно напоминает NonMA (раздельную память), но допускает динамическое перераспределение памяти (процедура сложная, но полезная), обмен данными через память (через динамическое перераспределение памяти), а также коллизии при одновременных hit_miss.
Там современные процессоры уже умеют в многоканальный доступ.Если несколько ядер в одном чипе — то очень сложно сделать раздельные шины к разным модулям памяти. Коллизии при доступе к шине — остаются.
раньше одно ядро могло использовать сразу несколько каналовА зачем ему это?
Будущее, как мне кажется, за увеличением ширины шины — пока что тут есть куда расти.Вроде, наращивать количество дорожек уже некуда.
От супескалярности следует отказаться. Ну или прописывать её явно, выделив в команде поле под это дело. При большом числе регистров — зависящие по данным команды можно разнести далеко.
Что-то Itanium с таким подходом не взлетел.
А суперскалярность — хорошее подспорье для предсказателя переходов. Конечно, вы можете это реализовать статически в compile-time, но в силу огромной сложности это будет менее эффективно.
Если обращения в память редкие — на задержки можно наплевать.
Тогда и общий доступ к памяти не будет проблемой.
Вроде, наращивать количество дорожек уже некуда.
HBM-память, SoC.
Конечно, вы можете это реализовать статически в compile-time, но в силу огромной сложности это будет менее эффективно.
Скорее не из-за огромной сложности (реализовать аналог на самом процессоре сложнее, чем программно), а из-за недостаточности данных в статике. То есть предсказатель перехода в процессоре имеет больше данных, чем компилятор.
А так да, это известная проблема VLIW.
То есть предсказатель перехода в процессоре имеет больше данных, чем компилятор.Дело не в предсказателе переходов, а, банально, в частоте.
Из-за которой «поход в память» — это целое событие, 300-400-500 тактов. Понятно, что большая часть идёт из кеша, только одно обращение из нескольких десятков реально идёт в память… но когда это происходит — суперскаляр перестраивает план вычислений, а VLIW ждёт. Долго ждёт.
Out-of-order действительно сам организует порядок исполнения операций, и пока одна команда ждёт данных, может запустить не зависящие от неё операции. При этом в динамике он знает, где какие адреса и потому знает, где будут конфликты => имеет больше свободы в размещении команд. Компилятор в данной ситуации имеет меньше свободы, так как вынужден использовать различные сложные варианты анализа адресов и консервативно оценивать возможность возникновения конфликтов. Поэтому в идеале in-order подход с явным параллелизмом проиграет out-of-order'у.
В реальной же ситуации у нас кроме самого OoO/in-order начинают играть прочие факторы. Например, предподкачка данных или ограниченность буфера предвыборки команд в out-of-order. Ну и оптимизации размещения данных в памяти со стороны компилятора. Так что в реальном мире не настолько очевидно, кто кого и как обыгрывает.
При этом в динамике он знает, где какие адреса и потому знает, где будут конфликтыНе знает. В том-то и дело, что не знает. Ни VLIW не знает, ни механизм OoO. Последнему, впрочем, это не нужно: он видит какие инструкции из «пула» можно исполнять (хотя бы и спекулятивно), а какие «застряли».
Но в кеш он не смотрит и ему это не нужно. Все решения принимаются «пост-фактум». А для VLIW-компилятора это-таки нужно.
Так что в реальном мире не настолько очевидно, кто кого и как обыгрывает.Настолько. Единственное место, где VLIW прижился — это видеокарты. Там применяется интересный трюк: так как потоков у нас там не много, а очень много, то как только задача уходит в память — на её место грузится другая задача. Из многих тысяч имеющихся.
В однопотоке VLIW «сливает» и достаточно сильно, увы.
Не знает. В том-то и дело, что не знает. Ни VLIW не знает, ни механизм OoO. Последнему, впрочем, это не нужно: он видит какие инструкции из «пула» можно исполнять (хотя бы и спекулятивно), а какие «застряли».
Эээ, а как они тогда вообще работают с памятью, не зная адресов? Ну и Вы только что отказали OoO в возможности корректно обрабатывать как минимум конфликты типа write after read по одному и тому же адресу.
Но в кеш он не смотрит и ему это не нужно. Все решения принимаются «пост-фактум». А для VLIW-компилятора это-таки нужно.
Вы имеете в виду, что VLIW-компилятору нужно знать, окажутся ли данные в кэше или в памяти? Если это правильная трактовка, то да, в идеале это нужно знать. Но имхо с достаточно хорошо отработавшими оптимизациями размещения данных в памяти и всякими предподкачками доля промахов кэша достаточно мала, чтобы не сильно потерять в производительности, предположив все данные лежащими в L1.
В однопотоке VLIW «сливает» и достаточно сильно, увы.
I need proof.
ЕМНИП, в какой-то статье я читал, что однопоточно Эльбрус 1 ГГц был эквивалентен чему-то типа 2,6 ГГц Интела. Но это нужно гуглить.
Эээ, а как они тогда вообще работают с памятью, не зная адресов?Причём тут адреса? Речь идёт про наличие данных в кеше!
Ну и Вы только что отказали OoO в возможности корректно обрабатывать как минимум конфликты типа write after read по одному и тому же адресу.write after read — это, вроде бы, вообще не конфликт. Может вы имеете в виду read after write? Да, на эту тему что-то вроде есть bypass'ы — но это всё равно не критично. Они только в последних поколениях появились.
Но имхо с достаточно хорошо отработавшими оптимизациями размещения данных в памяти и всякими предподкачками доля промахов кэша достаточно мала, чтобы не сильно потерять в производительности, предположив все данные лежащими в L1.Вопрос в том, что такое «не сильно потерять в производительности». Раза в два — это «сильно» или «не сильно»?
Ещё раз: современным процессорам требуется 300-500 тактов на один поход в память. За это время можно исполнить тысячу операций, а то две!
В случае с ОоО — решение элементарно: если инструкция «залипла», то мы можем весь дальнейший план действий «пересчитать» — то, что от неё зависит — отложить, то что не за висит — продолжать исполнять.
А что в случае с VLIW делать? Предусматривать множество планов, где каждая операция может «зависнуть»? Так никакого кода не хватит, чтобы все такие случаи грамотно учесть.
ЕМНИП, в какой-то статье я читал, что однопоточно Эльбрус 1 ГГц был эквивалентен чему-то типа 2,6 ГГц Интела. Но это нужно гуглить.Погуглите. И вчитаейтесь.
Потому что если взять картинки от МЦСТ, то там все проблемы видны очень отчётливо. То есть не сразу, но если подумать.
То есть на первый взгляд — всё как вы говорите. Частота ниже, эффективность — та же, всё зашибись, ща токо частоту поднять… А вот нетути. За счёт чего вы её собрались поднимать-то?
Посмотрите на процессоры из той таблички:
Intel ULV 1GHz:
техпроцесс — 130nm
транзисторов (на ядро) — 77 million
тепловыдедление (на ядро) — 7W
Эльбрус-2C+:
техпроцесс — 90nm
транзисторов (на ядро) ~100 million
тепловыдедление (на ядро) ~ 10W
В том-то и дело, что сравнение у МЦСТ — вполне честное (в смысле архитектуры — так-то Pentium на несколько лет раньше появился, но это уже не про архитектуру), но люди додумывают невесть что.
Да, у ОоО процессора частота — вдвое выше… ну и что? Если техпроцессы одинаковы и транзисторов требуется больше и тепловыделение у нас больше тоже, то… таки это слив, извините.
На плавучке — да, Эльбрус отыгрывается, но плавучка — это ныне вотчина GPU и TPU, там совсем другие числа получаются…
Причём тут адреса? Речь идёт про наличие данных в кеше!
Мы ж про конфликты говорили. А это неразрывно связано с адресами.
Впрочем, если Ваша речь — про наличие данных в кэше, то я и не возражал вроде…
write after read — это, вроде бы, вообще не конфликт. Может вы имеете в виду read after write? Да, на эту тему что-то вроде есть bypass'ы — но это всё равно не критично. Они только в последних поколениях появились.
Я имел в виду именно то, что написал. RAW (read after write) к теме разговора не относится. WAR — вполне однозначно конфликт: если поменять операции местами, то изменится результат read => изменится результат исполнения программы. И этот конфликт OoO обязан так или иначе решить.
Отдельно про байпассы: это ж седая древность. ЕМНИП, эти штуки ещё с самого появления конвейеров появились. Просто много байпассов в процессоре сложно делать, вот и ставят их только на самые перспективные в смысле ускорения пары стадий конвейера.
Вопрос в том, что такое «не сильно потерять в производительности». Раза в два — это «сильно» или «не сильно»?
Откуда данные про 2 раза?
А что в случае с VLIW делать? Предусматривать множество планов, где каждая операция может «зависнуть»? Так никакого кода не хватит, чтобы все такие случаи грамотно учесть.
Ваш вариант про предусмотреть всё такое, разумеется, не катит. Но ведь есть другие оптимизации, и я их даже перечислил.
Конечно, в идеальном исполнении с идеальным компилятором VLIW проиграет OoO. Но реально надо уже смотреть на конкретные реализации.
WAR — вполне однозначно конфликт: если поменять операции местами, то изменится результат read => изменится результат исполнения программы. И этот конфликт OoO обязан так или иначе решить.Нет там конфликта. Если вы запись спекулятивно сделаете — то это может не только на последующее чтение повлиять, но эти и другие процессоры могут «увидеть». Потому спекулятивная запись идёт в специальный буфер и старое значение в памяти не теряется.
Ниоткуда — это ж просто вопрос. Что такое «сильно» для вас.Вопрос в том, что такое «не сильно потерять в производительности». Раза в два — это «сильно» или «не сильно»?Откуда данные про 2 раза?
Конечно, в идеальном исполнении с идеальным компилятором VLIW проиграет OoO. Но реально надо уже смотреть на конкретные реализации.Ну вот конкретно в конкретных реализациях — остался один Эльбрус. И то потому, что у них нет готового суперскаляра, чтобы свой VLIW выкинуть. Все остальные уже от VLIW отказались.
Как нам тут подсказывают — уже даже и в GPU отказались…
Последнюю WLIW архитектуру в GPU похоронили ЕМНИП вместе c семейством AMD Radeon 6xxx (Northern Islands, 3е и последнее поколение VLIW архитекрутры AMD TeraScale 3), производство которого завершилось около 8 назад. Вроде с тех пор больше никто из крупных производителей графики с VLIW не экспериментировал.
Да, предсказатель переходов в процессоре имеет статистику в реальном времени и может адаптироваться под данные, чего никогда нельзя добиться в статике.
Я же имел в виду ещё и спекулятивное выполнение, когда процессор выполняет одновременно обе ветки кода, а затем одну отбрасывает. Это можно сделать и на VLIW, но сложно.
Я же имел в виду ещё и спекулятивное выполнение, когда процессор выполняет одновременно обе ветки кода, а затем одну отбрасывает. Это можно сделать и на VLIW, но сложно.
В смысле сложно? Если сделать в системе команд спекулятивные операции (а в VLIW Эльбрусе они есть — пруф), то это окажется не сложнее, чем в суперскаляре: оставшиеся механики отставки результата операции совпадают.
UPD. Погорячился, косвенно относится. У меня сложилось впечатление, что это такой интересный предсказатель переходов. В принципе, там нужно предусмотреть очистку конвейера от уже начатых операций, но всё же это не спекулятивность.
В Pentium 4 это частично делается вообще во время создания трассы, а частично — посредли конвеера. Вот тут исследовали чем всё это заканчивается.
С учётом того, что во VLIW шедулер — вообще где-то в компиляторе… стоит ожидать подобных же эффектов.
Я же имел в виду ещё и спекулятивное выполнение, когда процессор выполняет одновременно обе ветки кода, а затем одну отбрасывает.Нету такого в современных процессорах, как это ни удивительно. Были попытки когда-то что-то такое сделать… но оказалось, что это банально невыгодно.
А Intel и AMD от такого отказались когда смогли довести точность работы блока предсказания ветвлений до уровней >99.x%. Из-за чего эффективность подобных схем дающих выигрыш только в каких-то долях % от общего количества условных переходов, но при этом повышающих потребление энергии (за счет исполнения ненужной ветви инструкций) и служащей потенциальном источником дыр в безопасности стала весьма сомнительной.
Хотя блоки аппаратной предвыборки данных вроде бы все еще могут смотреть обе ветви кода, но уже только с целью заранее на всякий случай подтащить данные из памяти в кэш, но не начиная исполнение побочную ветви кода до момента самого перехода.
2) Поздравляю, вы изобрели ARM FIQ режим.
3) Регистровый файл есть в любом процессоре :)
4) Поздравляю, вы изобрели RAW/CELL/Epiphany (Parallella).
2) Я его не изобретал. Я именно оттуда и взял идею.
При этом, очевидно, я имею полное право агитировать за чужую идею.
3) Вроде, ARM-32 не имеет регистрового файла.
А что значит «в любом»? В восьмибитных процессорах разве есть регистровый файл?
4) Я не понял, про что это Вы. Перечисленные слова слишком многозначны, не гуглятся.
Многие современные ARM чипы этот режим вообще не поддерживают.
У ARMv8 и остальных RISC процессоров 31-32 регистра было изначально.
А что значит «в любом»?ru.wikipedia.org/wiki/Регистровый_файл
Перечисленные слова слишком многозначны, не гуглятся.
www.princeton.edu/~wentzlaf/documents/Taylor.2001.HotChips.Raw.pdf
en.wikipedia.org/wiki/Cell_(microprocessor)
www.parallella.org
В этих (и других) процессорных архитектурах у каждого ядра есть локальная память, что позволяет им работать на полной скорости без снуп-трафика.
С основной памятью работа ведётся через коммутатор/DMA.
— полоса существенно выше, чем доступ к основному объёму RAM (ширина шины, частота, задержки, протокол доступа, число каналов);
— объём существенно больше, чем L3, минимум — раз в 10-100;
— не обязательно делать именно классический кэш, но обязательно иметь более широкие аппаратные возможности доступа, чем к основному объёму RAM;
— нахрен слоты/разъёмы, длинные линии и прочие гадости;
— бонусом — существенно меньшее удельное потребление.
Проблемы с классической оперативной памятью связаны с ограничениями при размещения оной на материнской плате:
— ограниченная ширина шины, нужно соблюдать ЭМС (ширина дорожки и отступы и ещё дохрена всего), быстро растёт занимаемая площадь;
— ограниченная макс. длина шины, нужно соблюдать ЭМС (потери, стабильность импеданса на ПП, помехи, и т.д.);
— ограниченная мин. длина шины, т.к. размеры DIMM — огромны, даже 4 распаянных чипа нехило добавляют площади, длина дорожек тоже получается относительно большой;
— увеличение числа слоёв ПП — дорого, могут быть проблемы с контролем и надёжностью.
— с дальнейшим ростом частоты (- требований к ЭМС) рост сложности ПП будет расти намного быстрее
Только бонуса в виде меньшего потребления энергии у нее нет, наоборот работа со сверхширокими шинами (у HBM это от 1024 бит и выше) съедает больше энергии несмотря на то что длина этих шин стала во много раз меньше.
Все остальное присутствует.
Причина ввода кэшей историческая — малая скорость памяти в сравнении со скоростью самого процессора + их удаленность от CPU (изначально они были вне процессора), что приводило к потере в скорости передачи. Потому их стали вводить в сам процессор (и ближе и, в итоге, быстрее). Чиплеты (all-in-one) по сути нивелируют необходимость в L4.
А когда в CPU начали добавлять всё больше и больше ядер, а также всё больше контроллеров DRAM для их загрузки, к иерархии добавили ещё более крупные блоки кэшей L3.
Я как бы намекаю, что L3 — это не изобретение архитектуры Bloomfield, Pentium EE ещё на 130 нм имел такой.
Кэш – король быстродействия: нужен ли процессорам четвёртый уровень кэширования