Комментарии 40
Ну и конечно не могу удержаться, чтобы не запостить такую картинку, какую изначально хотелось. Но она слишком прекрасна, чтобы быть в статье.

А вы попробуйте демку. Вероятно, если вы задаете такой вопрос, вы говорите на каком-то еще славянском языке?
Неправильное ударение, внезапно, не сильно портит результаты. Ну и вообще акустическая модель даже английскую или немецкую речь перевод во что-то похожее на "транслит".
Сильно портит то, что пост-процессинг настроен именно на русский язык. Но как настроить его на расшифровку другого языка "транслитом" я честно говоря не знаю.
Украинский точно можно хакнуть натренировав пост-процессинг после ручных словарей перехода, т.к. просто поменяв буквы на их русские "аналоги".
Привет! Спасибо за статью. Хорошо, что тесты похожи на нормальные, а не как обычно "мы всех везде победили".
Есть кое-какие замечания.
1) По поводу Librispeech. Это не "маленький идеализированный тестсет, вводящий всех в заблуждение". Это задача, показывающая качество, которое может вытащить алгоритм из стандартизированных данных. Когда выходит статья с очередным рекордом на librispeech, автор не хочет сказать "я всех обманул цифрой качества на аудиокнигах". Он говорит "мы, человечество, теперь можем вытаскивать больше качества из таких данных".
Да, было бы лучше вытаскивать их из более разнообразных данных — но на Западе серьезно относятся к авторским правам. Поэтому собрать корпус лучше — это суперсложная задача. Заметь, Librispeech это не выборка из аудиокниг — это выборка из аудиокниг со свободной лицензией! Вот интересная ссылка насколько у них все с этим серьезно: https://open-education.net/libraries/google-otsifrovala-25-mln-knig-pochemu-ih-nelzya-chitat/
А без этого корпуса было бы невозможно сравнить алгоритмы. Скажем, кое-где в твоих тестах Яндекс лучше. У них лучше алгоритм или больше данных? Непонятно.
"я всех обманул цифрой качества на аудиокнигах". Он говорит "мы, человечество, теперь можем вытаскивать больше качества из таких данных"
Тут как бы согласен, просто у таких вещей очень долгий цикл после которого они начинают быть полезными.
И выигрыш, к сожалению, получает не общество в целом, а только "толстые коты".
В случае с CV профита настолько много, что он аж льется через край.
но на Западе серьезно относятся к авторским правам
На Западе к ним, равно как и к вами персональным данными относятся — просто никак. Там абсолютно легально DMV продают перс. данные, банки легально все продают налево-направо, список бесконечен. Так что давайте без Запада.
Скорее там просто есть некий занавес "цивильности" над разборками.
может вытащить алгоритм из стандартизированных данных
Это ничего не говорит про генерализацию, про то как получить робастные модели, про то сколько реально нужно данных итд итп
Грубо говоря — трансформеры на миллиард параметров — зло, сам модуль — добро.
Раздувать compute можно, как мы видем на примере NLP хайпа, можно почти до безумия.
Скорее там просто есть некий занавес "цивильности" над разборками.
+1. Но положение исправляется, как мы видим по ситуации с фейсбуком.
Это ничего не говорит про генерализацию, про то как получить робастные модели, про то сколько реально нужно данных итд итп
+1. Надеюсь, академический корпус нужного размера появится.
Для некоторых частных задач (вроде распознавания в шуме) есть другие корпуса.
Кстати, ответ на вопрос "почему либриспич такой маленький" очень простой. Я помню, когда он появился, и тогда такой корпус считали большим. Ну или средним.
Для разбиения корпуса на фразы его автор, Даниэль Повей сотоварищи, использовали модель, обученную на wall street journal, на 40 что-ли часах (ЕМНИП). Если посмотреть README к wsj, там предложено несколько способов получить этот крупный по меркам 90х годов корпус — на магнитных лентах, на пачке компакт-дисков, итд (опять же, ЕМНИП).
Надеюсь, через пяток лет и корпуса 10к+ часов будут считаться небольшими.
ну собственно за это мы и топим
никто не помнит имена авторов ImageNet, но все помнят ImageNet
если сделать OpenSTT на 3+ иностранных языках — то есть небольшая надежда, что FAIR как-то подтянется. они приватно подтянулись — они 100% книжки размечают там сидят в своем огромном датасете (см. их последние публикации — они даже до semi-supervised нормального догадались даже, кек)
но Dark Forest просветлеет только когда все поймут, что король голый
2) Насчет критики индустрии. Что-то справедливо. Что-то нет. То, что снимет большую часть твоей критики, содержится здесь.
Большинство научных статей, которые мы прочли, как правило, были написаны исследователями из “индустрии” (напр. Google, Baidu, и Facebook).
На самом деле, публикационно активны ребята из исследовательских подразделений: Google Labs, Facebook AI Research, Baidu-чтототам. Это!!! академические!!! ученые, которые занимаются исследованиями за деньги и с ресурсами IT-гигантов.
Статьи от практиков, которые делают сервисы этих компаний, изредка встречаются — и с непривычки вызывают удивление "я думал у них там космические корабли бороздят, а в реальности — то же, что и у нас, с поправкой на масштаб".
Это!!! академические!!! ученые, которые занимаются исследованиями за деньги и с ресурсами IT-гигантов.
Ну… мы же так и написали?
Статью переводили на русский и сокращали в 3 раза, но вероятно это при переводе потерялось.
По статьям видно, что их пишут не практики.
Статьи от практиков, которые делают сервисы этих компаний, изредка встречаются
Вот-вот.
Последняя статья от FAIR неплохая на эту тему.
3) Нельзя доверять открытым или чужим тестам. Даже твоим, при всем уважении, и к сожалению.
Как только у разработчика системы появляется тест, он может начать выдавать на нем любые результаты от 5% до 95% качества. В зависимости от скромности. Почти любой алгоритм тюнится, а если не тюнится — можно на выходе "подкостылить"
Ты этого не делаешь, но когда твой конкурент начал этим заниматься — ты проиграл. Если ты видишь на открытом тесте у конкурента +1% качества от твоего, ты не можешь быть уверен, что это честный результат.
Когда разработчик не хочет никого обмануть, частенько случаются ошибки и самообман. Вроде протечек тестовых данных в трейн. Скажем, записи из именно этой службы такси были в твоем трейне? А у Яндекса? А у Николая Шмырева?
Ты написал очень хороший текст про "тёмный лес", я после него даже книжку Ли Цисиня прочитал. Вот это именно оно.
Dark Forest
Методология тестов описана тут — https://www.silero.ai/stt-quality-metrics/
Верить или не верить — личное дело каждого
Ты этого не делаешь, но когда твой конкурент начал этим заниматься — ты проиграл.
На самом деле даже лгать не надо
Можно просто взять свой датасет, выбрать реально сложные примеры, затюниться на них, и вуаля
Если ты видишь на открытом тесте у конкурента +1% качества от твоего, ты не можешь быть уверен, что это честный результат
Но вот когда я вижу датасет конкурента, который КОНКУРЕНТ приватно мне дал pro bono
И на нем у него результат хуже, это информация
Ну или наоборот когда у меня просто нет такого домена вообще и результат не плохой, но не супер секси — вот это информация
Собственно так и живем
Про протечки — ну тут скажем так на таком количестве данных надо мыслить доменами, а не ликами
Почти любой алгоритм тюнится
И тут я честно заявляю
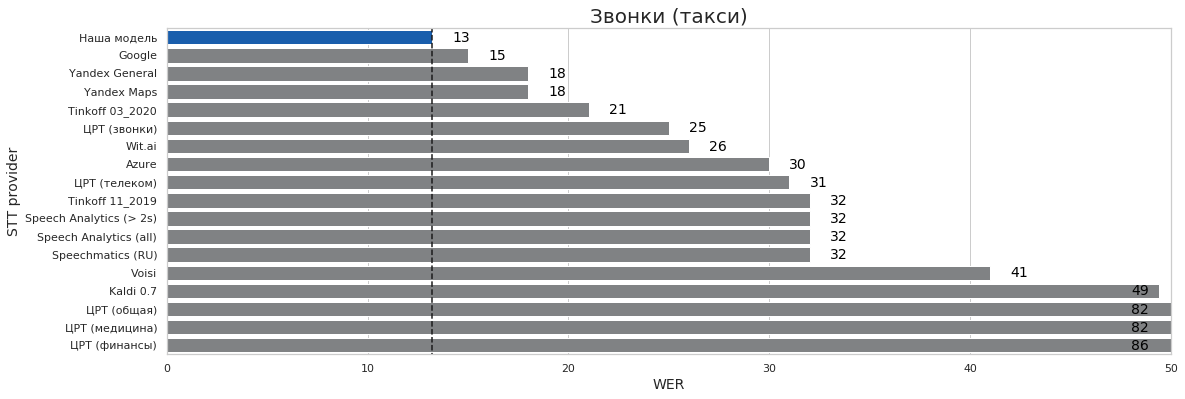
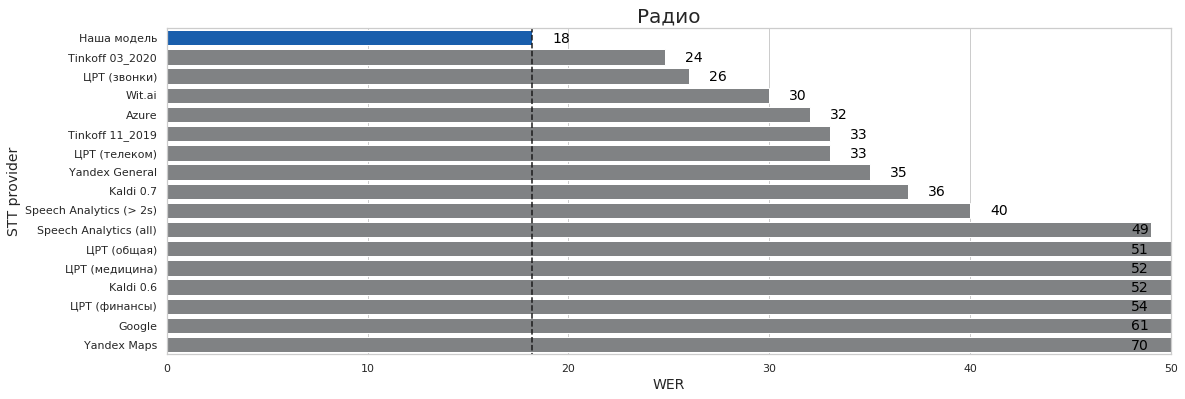
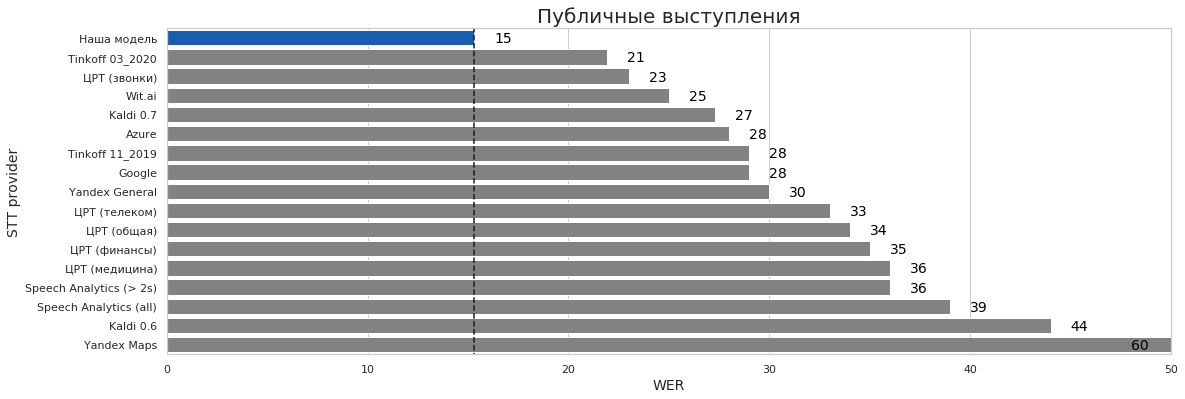
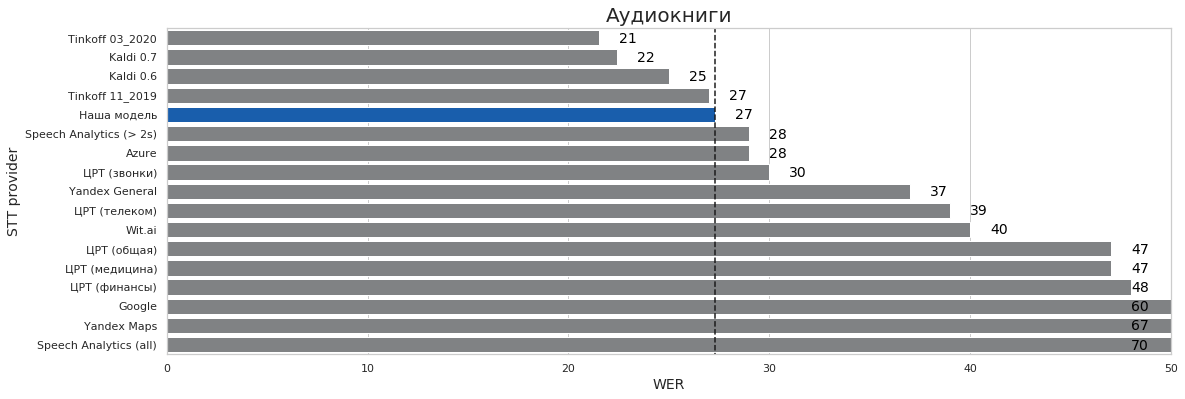
Эти все тесты (кроме такси где словарь накинул 1 пп) — ЭТО ОДНА И ТА ЖЕ МОДЕЛЬ
Да она тюнится на всем чем есть. Но не вал сетах, которые дают внешние люди
Но вот когда я вижу датасет конкурента, который КОНКУРЕНТ приватно мне дал pro bono
И на нем у него результат хуже, это информация
Ну или наоборот когда у меня просто нет такого домена вообще и результат не плохой, но не супер секси — вот это информация
И тут я честно заявляю
Эти все тесты (кроме такси где словарь накинул 1 пп) — ЭТО ОДНА И ТА ЖЕ МОДЕЛЬ
Да она тюнится на всем чем есть. Но не вал сетах, которые дают внешние люди
Я тоже не занимался такой фигнёй уже много лет. И больше не хочу никогда. Но про незнакомых людей можно верить только инфе «Я хуже всех на этом тестсете, настолько, что никто не должен рассматривать меня как поставщика». «Тёмный лес» — отличная метафора.
sad but true
тут я больше скажу
по сути единственное что работает — когда есть третья сторона, которая
- выложила и разметила все датасеты
- поддерживает говно-врапперы над АПИ всех паблик сервисов
- тестирует раз в месяц
- постоянно улучшает нормализацию
- не принимает взятки и не слушает угрозы
и четвертая сторона, которая мотивированно выносит мозг третьей
битва гугла и фейсбука тут кстати весьма показательна
...
понятное дело мы все эти пункты сделали приватно
чтобы вынести это в паблик, нужен инженерный effort, который по сути растворится в воздухе — надо или иметь глубокие карманы или стальные нервы
а самое большое — нужно сделать это не раз, а нужно быть готовым В ЛЮБОЙ МОМЕНТ ВРЕМЕНИ ответить за каждую строчку кода. как за прод короче. сделать это всем в подарок, или запилить новые фичи? =)
на практике мы имеем хейт под статьей про open stt v0.5 (я бы еще принял хейт под 1.0, но там я был удивлен), 4 бекеров хостинга датасета т.к. все самые умные, могу продолжить список =)
Да, уточню:
Вроде протечек тестовых данных в трейн. Скажем, записи из именно этой службы такси были в твоем трейне?
Неаккуратно написал. Я уверен, что протечки именно тестов в трейн у тебя не было. Это правильнее назвать адаптацией на узкий домен.
4) И, еще оно замечание, вернее предложение: перестать называть систему Николая Швырева "Kaldi", это всех путает. Его система называется alpha-cefei или vosk, думаю, Николай сам прояснит.
В реальности, Kaldi это фреймворк, на котором Николай сделал свою систему. И если продолжать этот подход, то вашу систему надо назвать "PyTorch 1.0", гуглевскую "TensorFlow x.y", а еще нескольких участников твоего сравнения тоже "Kaldi".
Ожидал увидеть сравнение разных систем, но в статье только сравнение в стиле «сравнение обычного стирального порошка и нашего», хорошо что на вашем сайте есть сравнение всех систем между собой.
Для тех кому лень искать на сайте:



- Libri Speech & Common Voice ~ 2к часов
- Некоторые (не помню, что точно значит) данные из интернета ~ 2к часов
- Синтезированная речь (Текст модели GPT-2 начитан Voicery) ~ 1k часов
- Аудиокниги (LibriVox) — 65k часов
У этой группы крутые советники — Kelly Davis, Mark Liberman, Andrew Ng и Dan Povey.
Пара вопросов:
1. С точки зрение текущего состояния предметной области и доступных фреймворков, как бы вы оценили Kaldi?
2. Если порассуждать на тему больших датасетов (> 100k часов) и подходов к построению state-of-the-art моделей (будь то классические DNN/HMM модели или end-to-end) и доступных фреймворков (например, Kaldi), CPU память имеет хоть какое-либо влияние на скорость/качество обучения или нет? Скажем, система с несколькими десятками террабайт RAM и 8-16 GPU которая вместит весь рабочий сет в /dev/shm. Или стандартный размер в 256GB-1TB которые доступны в большинстве серверных машин с 8 картами «just right»?
Одна из рабочих групп MLPerf — Datasets работает над большим публичным набром данных для SST. Сейчас размер примерно 70 тысяч часов, цель — 100 тысяч.
А где вы нашли про 70к часов?
Просто ваша ссылка введет на закрытую Google группу.
Референсная модель RNN transducer, которая (грубая оценка) должна обучиться на 100к часах за 10-30 дней на 64х RTX 2080 картах
Ну… как обычно =)
Libri Speech & Common Voice ~ 2к часов
Некоторые (не помню, что точно значит) данные из интернета ~ 2к часов
Синтезированная речь (Текст модели GPT-2 начитан Voicery) ~ 1k часов
Это норм, чтение тоже довольно простой домен
Аудиокниги (LibriVox) — 65k часов
В реальности это сильно избыточно, т.к. домен книг не то, чтобы важный или сложный.
У этой группы крутые советники — Kelly Davis, Mark Liberman, Andrew Ng и Dan Povey.
Интересно, по ссылке написаны другие люди
Если они сделают так же как ChexNet, то наверное они только отбросят прогресс в этой области на несколько лет =)
Про ваши вопросы — прошу простить за прямоту, но звучит так, как будто вы хотите получить бесплатную консультацию. Если вам интересно и у вас есть интересные данные, мы можем обучить модель на ваших данных под ключ, мои контакты есть в миллионе мест в интернете.
А где вы нашли про 70к часов?
Интересно, по ссылке написаны другие люди
Я знаю Питера и Виджея, это те персонажи в таблице, они возглавляют ту группу и рассказывали про текущий статус пару недель назад.
Про ваши вопросы — прошу простить за прямоту, но звучит так, как будто вы хотите получить бесплатную консультацию. Если вам интересно и у вас есть интересные данные, мы можем обучить модель на ваших данных под ключ, мои контакты есть в миллионе мест в интернете.
Упс, мне действительно просто интересно, извиняюсь что не так выразился. Я в прошлом работал над бенчмарками для DL приложений и мы в том числе запускали Kaldi в разных конфигурациях на фишере (2k часов). Когда все данные были в памяти, Kaldi работал пошустрее (понятно почему). Мы даже переписали nnet1 (да, давно было)) что-бы ускорить тренировку на CPU. В те времена Ден Повей говорил, что если ты не исследователь из Google, Baidu и т.п., то с Kaldi легче получить хорошие результаты. Ситуация, судя по всем, поменялась с тех пор.
Про первое — написал им, мне даже уже ответили.
Может сделаем проект с ними)
Про второе — отвечу честно, не большой специалист по плюсам, перлу или на чем там еще написан Калди. Мы сами его не рассматривали, т.к. мне показалось, что технологически это тупик.
В те времена Ден Повей говорил, что если ты не исследователь из Google, Baidu и т.п., то с Kaldi легче получить хорошие результаты. Ситуация, судя по всем, поменялась с тех пор.
Нынче уж nnet3:)
На мой взгляд, ситуация и изменилась, и не изменилась.
По-прежнему, калди just works и просто даёт приличный результат.
В то же время, end2end методы, если их как следует накормить данными, позволяют получать такие же результаты, что гибриды HMM/NN (которые часто делают на калди). Ну, плюс-минус три копейки. Да и данные, чтобы ими накормить end2end'ы, сейчас у многих появляются, а не только у гугля с фейсбуком.
При этом, есть риск больно вляпаться в не сразу очевидные особенности метода (например: сложность сделать стриминг; сложность сделать персонализацию или адаптировать под тематику; зависимость от длины записи; у некоторых — слабоватое максимально достижимое качество либо прожорливость до gpu и данных. Там в каждой избушке свои погремушки).
Но и можно получить необычные для гибридов плюшки: возможность сделать удобную для некоторых мобильных девайсов распознающую нейроночку, возможность распознавать OOV (некоторые умеют), применимость опыта из распространенных в cv и nlu тулов. Это все можно и на гибридах, но не из коробки.
В общем, сейчас можно выбирать.
IMHO.
По-прежнему, калди just works и просто даёт приличный результат.
Тут сложно сравнивать яблоки с апельсинами, но на сайте Николая написано, что он мол 10 лет пилит свое решение — ну то есть оно явно уже "зрелое".
Но судя по тестам — решение довольно неплохо работает на доменах, на которых его тренировали, а вот с генерализацией беда. Но данные там явно брались из широкого числа доменов. То есть получается это проблема подхода в целом? Или дело в чем-то ином? Может Николай ответит.
В то же время, end2end методы, если их как следует накормить данными, позволяют получать такие же результаты, что гибриды HMM/NN (которые часто делают на калди). Ну, плюс-минус три копейки. Да и данные, чтобы ими накормить end2end'ы, сейчас у многих появляются, а не только у гугля с фейсбуком.
Ну, фишка в том, что если бездумно кормить e2e, то вряд ли что-то хорошее получится)
Там еще и часто пишут про 8 — 100 видеокарт.
Прямо e2e это наверное и правда про 100к часов, но генерализацией там тоже пахнуть не будет.
сложность сделать стриминг; сложность сделать персонализацию или адаптировать под тематику;
Почему? У нас проблема со стримингом состоит только в том, что его надо поддерживать, а если оно и так быстро работает ...
зависимость от длины записи;
Опять же почему?
Короткие записи немного грустят, но это логично — мало контекста.
Но и можно получить необычные для гибридов плюшки: возможность сделать удобную для некоторых мобильных девайсов распознающую нейроночку, возможность распознавать OOV (некоторые умеют), применимость опыта из распространенных в cv и nlu тулов. Это все можно и на гибридах, но не из коробки.
Я бы сказал это в принципе фишка современных фреймворков.
Имхо лучше всегда использовать низкоуровневый код на каком-то общем тулките.
Таким образом вы наследуете весь прогресс человечества в этой области в целом с нулевым костом.
Вообще, сравнивать решение Николая с твоим или с решением еще какой-то компании не верно. Потому, что мы не знаем, сколько и каких там данных. А также, для чего эта система делалась, и с какими усилиями.
И даже если один человек пробует два разных подхода на одинаковых данных и говорит, что один из них отстой — возможно, он что-то просто не осилил.
Хорошо сравнить именно методы, думаю, сейчас можно только на либриспиче. Несмотря на все недостатки, ничего лучше нет.
Ну а если нужно сравнение для практических целей — то заказчику надо брать свои данные, делать свой тест и сравнивать коммерческие системы. Иначе как-то никак.
Хорошо сравнить именно методы, думаю, сейчас можно только на либриспиче
Но никто, почему-то, не сравнивает (буду рад ошибиться).
И не пишет обзорных статей, в т.ч. сравнивая compute и time-to-market ...
Вообще, сравнивать решение Николая с твоим или с решением еще какой-то компании не верно. Потому, что мы не знаем, сколько и каких там данных.
Это так же верно, как и то, что конечному пользователю все эти нюансы глюбоко безразличны.
Но никто, почему-то, не сравнивает (буду рад ошибиться).
И не пишет обзорных статей, в т.ч. сравнивая compute и time-to-market ...
Обзорных статей не видел. Но вот этого достаточно, чтобы ориентироваться: github.com/syhw/wer_are_we. Посмотрев в статью и увидев «x% при обучении на librispeech» (или switchboard/fisher/chime) я уже что-то понимаю. Если там написано «учился на собственном сете» или «учился на сете, который мало кто исследовал» — то информации очень мало.
Про compute и time2market никто не пишет, да, но это ведь инженерно-коммерческие вопросы, там еще огромная пачка переменных (какой market? на чем compute? какая у тебя орг.структура — можешь дешево тюниться под заказчика или покрываешь всех в среднем? тыщи их).
Это так же верно, как и то, что конечному пользователю все эти нюансы глюбоко безразличны.
Ты пишешь вначале про способность фреймворка (даже не метода) к генерализации, потом про решение Николая, а этот коммент про то, что пользователю все равно. Это разные вещи. Резюмируя мою позицию,
* фреймворки (калди vs pytorch vs tensorflow) — не сравниваем, ни к чему.
* метод (гибрид/LAS/...) — сравниваем на распространенном в мире бенчмарке.
* коммерческие решения — на заведомо неизвестном вендору тесте, сделанном из данных заказчика.
Все остальное — путь к ошибкам.
При этом, есть риск больно вляпаться в не сразу очевидные особенности метода (например: сложность сделать стриминг; сложность сделать персонализацию или адаптировать под тематику; зависимость от длины записи; у некоторых — слабоватое максимально достижимое качество либо прожорливость до gpu и данных. Там в каждой избушке свои погремушки).
Я имел в виду, что если кто-то заходит в эту область, он выбирает какой-то «алгоритм» (ну, не совсем алгоритм, а метод что-ли; не знаю, как назвать точнее. скажем, гибрид или классический ctc, или что-то с attention, или rnn-t, или что там еще).
Если не повезет, у алгоритма будет какая-то из перечисленных выше (или каких-то других) особенностей. Из статей это не всегда очевидно. Придется импровизировать или переделывать. Это долго.
Вы, может быть, сразу все удачно выбрали. Или переделывали несколько раз. Я не утверждал, что выданный мной список проблем нерешаемый.
Посмотрев в статью и увидев «x% при обучении на librispeech» (или switchboard/fisher/chime) я уже что-то понимаю.
Там compute может отличаться на 2 порядка
Это делает такие сравнения даже вредными
Про compute и time2market никто не пишет, да, но это ведь инженерно-коммерческие вопросы, там еще огромная пачка переменных
В NLP и CV уже люди дошли, что таки писать все-таки надо про эти вещи
Хоть как-то
метод (гибрид/LAS/...) — сравниваем на распространенном в мире бенчмарке.
Правильно все нормировать по времени и по compute
В идеале по косту, но это сказка конечно уже
Из статей это не всегда очевидно. Придется импровизировать или переделывать. Это долго.
Поэтому всегда лучше выбирать агностик вещи и не зависеть от барина…
Если конечно есть цель достигнуть результата, а не просто получить строчку в рейтинге
Там как бы 3 датасета, считали метрики на каждом отдельно
Остальные системы — старались минимум 1-2 часа опрашивать
Где лимиты не жесткие — опрашивали все целиком. Допустим не очень система из Англии… вообще округляет до 60 секунд)
Также вот только что сравнили локальную модель с внутренней нормализацией и АПИ с публичной нормализацией — разница меньше 0.5пп WER
Понижаем барьеры на вход в распознавание речи