Комментарии 156
Как то смущают все эти $$display$$\begin{align}…
в мобильной версии Хабра
Boomburum
Интересная статья спасибо.
Мне кажется, в идеальной модели нужно как-то учесть (без понятия правда как):
1) число реально больных больше чем выявленных (не понятно на сколько, можно попробовать опираться на рандомизированнын исследования с антителами, но они дадут информацию только о той стране или вообще только локальной местности), а число выявленных это функция зависящая от общего числа больных, количества проведенных тестов и политики тестирования (которая у каждой страны разная). Например сильный рост в начали эпидемии в штатах и италии возможно объясняется тем что вирус уже сильно успел распространиться, пока тесты никто не делал (точнее делали только тем кто был в зоне риска)
2) учесть самоизоляцию и просто изоляцию (она снижает распространяемость), сразц извиненияюсь если это уже учтено, но я не заметил
3) географические очаги (т. е. вот в москве был экспоненциальный рост, в других регионах было тихо, потом в москве рост начал снижаться, а в других местах полезла экспонента)
4) еще бы добавить массовые мероприятия, которые привели к текущему резкому росту (пасху, очереди в метро, и прочее)
Спасибо за развернутый комментарий! Все это нужно учитывать, согласен. Скоро попробую модель, учитывающую географию, а там посмотрим и другие пункты. Ход наших с вами мыслей схож. Увы, предиктивные возможности любой модели без очень подробного учета всех факторов весьма ограниченные.
Мне кажется вместо подгонки графиков, нужно разбивать кривую на отдельные участки:
1. Этап начала развития эпидемии, когда диагностирования нет и идет скрытое распространение в популяции. В это время количество реальных случаев растет быстрее количества диагностированных, а смертей практически нет. Для covid-19 инкубационный период от 2 до 14 дней (чаще всего 5-6), а R0=3+
С учетом того что люди контактируют не со всеми подряд упростим до R0=2. Через 5 дней у нас будет 31 бессимптомный больной, а еще через 5 дней будет около 1000 бессимптомных больных и всего несколько десятков явных случаев.
На этом этапе круг распространения ограничен спецификой социальных связей: кто-то может заразить одного человека за 5 дней, а кто-то троих за 1 день. Но даже с учетом заниженных показателей, 1000 человек за 2 недели кажется реалистичной цифрой.
В качестве мер борьбы помогает ранний запрет на въезд и/или изоляция на время инкубационного периода при въезде (диагностирование симпотомов менее эффективно).
Можно приравнять продолжительность этого этапа к длительности инкубационного периода.
2. Этап первоначального тестирования, но карантина еще нет. Тут мы видим постепенный рост, потому что много скрытых больных, а тестов еще мало, но постепенно два этих показателя сходятся. Со временем цифры начинают расти, но вначале они показывают только количество средних и тяжелых случаев. Количество реальных больных изолированных от популяции низкое, многие в легкой форме болеют дома и продолжают заражать окружающих. Еще мало смертей, либо они не попадают в статистику. К этому моменту соотношение зараженных интравертов/экстравертов стабилизирует R0, но начинает играть фактор плотности населения и ограниченная популяция в городах. Кто-то уже начинает избегать скопления людей, но остается вероятность попадании вируса в благоприятную среду поэтому результат может сильно отличаться. По сути этот этап обуславливает финальную картину, которую мы видим сейчас.
В Москве первый официальный случай был 2 марта, а первые адекватные меры приняты только 23 марта. За это время 1000-кратный рост дает 1 миллион заболевших до введения карантина.
На этом этапе помогает отслеживание и изолирование всех контактов больного, а также тестирование при подозрении на легкую форму.
В других странах ситуация похожая, так что можно выделить на этот период 14 дней.
3. Этап введения карантина, за это время ежедневное количество тестов выходит на приемлиемый уровень, а прирост новых реальных случаев постепенно сокращается. При этом как раз тут мы и видим экспоненту, больше тестов — больше выявленных больных. Прибавим к инкубационному периоду еще период вирусовыделения (для covid-19 это 8-20 дней после выздоровления) и получим примерно месяц стабильного роста выявленных случаев. По сути на этом и следующем этапе мы видим лишь проекцию реальной картины на растущее количество проводимых тестов.
Рост реального числа больных должен прекратиться примерно через месяц после введения карантина
4. Этап выхода на пик эпидемии, когда количество новых реальных заражений резко падает, родных и близких перезаражали, у большинства проявились симптомы в легкой или тяжелой форме. Но количество выявленных больных все еще растет, потому что тестирование отображает реальную картину с некоторой задержкой.
Если выходить из карантина раньше выздоровления скрытых больных, то мы рискуем попасть на вторую волну с более высокой базой, но меньшим R0, что приведет к карантину с аналогичными цифрами.
Этот этап можно приравнять к максимальному времени на выздоровление/отсутствия вирусовыделения, а это еще примерно месяц.
Итого для covid-19:
1. Заражение: 14 дней (инкубационный период)
2. Реакция: 14+ дней (в зависимости от страны)
3. Карантин: 1+ месяц (инкубационный период + период вирусовыделения)
4. Выздоровление: 1 месяц (период выздоровления)
Сейчас Москва должна подходить к пику по реальному количеству заражений и 1 миллион больных не кажется фантастикой. Не факт что мы увидим миллион в официальных цифрах, т.к. к этому моменту большая часть переболеет в легкой форме. Как вариант похожие цифры может показать тестирование на антитела. Общего выздоровления и выхода из карантина не стоит ждать до 1 июня, снятие карантина до этого момента спустя 2 недели приведет к такому же карантину на 1+ месяц.
P.S. оценки этапов лучше проводить не по странам, а по отдельным городам, при этом этапы в городах могут не совпадать по длительности. Также нужно смотреть соотношение тестирования на количество случаев и количество жителей, а также то что данные приходят с задержкой. При расчете скорости распространения необходимо учитывать плотность проживания на километр, а при учете смертности процент пожилого населения и возможности медицинской системы. В общем удачи с расчетами :)
Речь идет о больших n и d > 1. При маленьких n верно и вправду только то, что вы написали. Публикация не научная, а научно-популярная, поэтому формулы не нумеровал.
Да, все верно. Собственно, это и запись формулами фразы про удлиннение ребра на 2P.
У вас ошибка в том, что n'(k+1) = an'(k), a -> 1 не значит, что (n'(k+1) — n'(k)) -> 0.
Контрпример элементарный — достаточно взять n'(k+1) = n'(k) + c где c — некоторая константа > 0. Очевидно что n'(k+1) — n'(k) -> c > 0, но при этом мы можем взять a = 1 + c/n'(k) -> 1
В частности, представить в таком виде можно полиномы, с-но ваше доказательство — это не доказательство линейного роста, а доказательство степенного.
Ну и второе — в модели не учитывается инфицирующая доза. Есть подозрение, что мы видим два кластера. В одной заражение идет малой инфицирующей дохой и вызывает бессимптомное течение с выделением малых доз. В другой — больные с тяжелым течением выделяют дозы в 10**4 раз больше, а зараженные от них имеют тяжелое течение. Кластеры не совсем независимые, старик или больной СПИДом и от малой дозы получит тяжелое течение, а ребенок от большой дозы — легкое. Но все-таки кластеры явно есть.
Слово «явно» нельзя употреблять по отношению к неизвестным величинам, это ошибка. Весьма вероятно, что на самом деле восприимчивы все или почти все (вирус не просто так настолько заразен — у человека нет против него качественного способа реагирования, чтобы сразу на входе его «рубануть»), а заболеют не 100% исключительно потому, что вирусу с какого-то момента будет сложно находить ещё не переболевших.
Тем более нельзя необоснованные позитивные предположения полагать в стратегии планирования реальных действий. В случае ошибки мы серьёзно огребаем и уже ничего не можем сделать задним числом.
у человека нет против него качественного способа реагирования, чтобы сразу на входе его «рубануть»
Когда неспецифический иммунитет не справляется, минимальная инфицирующая доза — несколько вирусов. Как пример — оспа. С другой стороны, когда неспецифический иммунитет справляется, минимальная инфицирующая доза (инфицирующая 1% населения) — бывает и больше 10**11 бактерий. У ковида минимальная инфицирующая доза - 10**3-10**4, я даже где-то видел оценку 10**5. Так что «рубануть на входе» — вполне получается.
Весьма вероятно, что на самом деле восприимчивы все или почти всеНу от дозы 10**30 действительно заболеют все, включая привитых, переболевших, людей в противочумных костюмах и даже трупы. :-) Но такую дозу только в лаборатории создать можно.
На самом деле мало восприимчивы дети — у них мало рецепторов ACE2. Плюс восприимчивость зависит от конкретного варианта ACE2 (вот препринт).
В любом случае — есть бритва оккама. Если модель в определенных точках (например пик заболеваемости) дает неверный процент переболевших — значит надо подкручивать восприимчивость, а не придумывать «увеличение коэффициента выздоровления γ в 1,7 раз».
Пока я знаю лишь один пример, когда заразилось 60%. На остальных судах (включая алмазную принцессу со средним возрастом пассажиров 69 лет) предел — заражение прекращалось на 20%. Измерения антител в самых зараженных местностях тоже не дали более 20-30% переболевших.
Тем более нельзя необоснованные позитивные предположения полагать в стратегии планирования реальных действий.А не обоснованные негативные по вашему можно? Вы что из секты 35% летальности? Между прочим, ВВП на 8% в любой стране эквивалентно сокращению населения на 5-6 миллионов человек.
То есть ценой спасения лишних 20-30 тысяч будут смерти миллионов. Пока речь идет о том, чтобы не допустить перегрузки здравоохранения и увеличения летальности в десяток раз — цена более-менее оправдана. Когда речь идет о произвольных подгонках в уравнения — цена в сотни раз превышает предотвращаемый ущерб.
Я вам советую обратить внимание на Австрию. С 14 апреля там открылись хозяйственные магазины. С 1 мая работу продолжат торговые центры и парикмахерские.Как видите — число заражений в Австрии медленно падает, несмотря на постепенную отмену карантина. А это означает, что произошло истощение числа восприимчивых.
При 9 миллионах населения в Австрии и 15 тысячах официальных заболевших — это возможно только в случае, если восприимчивы далеко не все. Я вполне верю, что на самом деле переболело 750 тысяч, причем большинство — бессимптомно. А вот в 5 миллионов — уже не верю.
aikarimov — расскажите, сколько раз надо подкручивать вашу модель для Австрии?
Пока я знаю лишь один пример, когда заразилось 60%.
Одного примера достаточно, чтобы сказать, что восприимчиво (то есть заболеют при обычных длительных контактах) не менее 60%. В лучшем случае. Говорить о невоспримчивости можно если человек никогда не заразиться при любых обычных контактах (специальное заражение в лаборатории не берем), а пример авианосца показывает — таких не более 40%.
Идея что в гражданской жизни не будет настолько тесных контактов — требует доказательств, скорее всего без карантина половые контакты (и сон в одной постеле с партнером), нахождение на переполненной дискотеке или поезда в метро в час пик — легко дадут не меньшую дозу вируса, чем проживание в одной казарме.
ВВП на 8% в любой стране эквивалентно сокращению населения на 5-6 миллионов человек.
Слово любой легко опровергается одним примером — например ВВП РФ изменялся до 8 раз (в долларах) в разные года. И падание на 40-50% не приводило огромному росту смертей
Одного примера достаточно, чтобы сказать, что восприимчиво (то есть заболеют при обычных длительных контактах) не менее 60%.
Нет, конечно. С чего бы?
Можно пытаться натянуть сову на глобус и пытаться доказывать что французы более воспримчивы, чем другие европейцы или что молодые и здоровые более воспримчивы старых и больных, но никаких подтверждений этому не найдено — скорее набоорот.
Одного примера достаточно, чтобы сказать, что восприимчиво (то есть заболеют при обычных длительных контактах) не менее 60%. В лучшем случае. Говорить о невоспримчивости можно если человек никогда не заразиться при любых обычных контактах (специальное заражение в лаборатории не берем), а пример авианосца показывает — таких не более 40%.
Одной точки на графике достаточно чтобы делать выводы?)
Каждый корабль — небольшой кластер из подвыборки кораблей.
Ваша гипотеза «если в одном из кластеров заразилось 60% -> при длительном контакте восприимчиво не менее 60%». Не хотите ее честно проверить?
Возьмите остальные корабли, которые были в примерно похожих условиях, посмотрите на каком количестве из них ваше предсказание сбывается. Затем можно прикинуть вероятность верности вашего утверждения — теорема байеса как раз подойдет.
Например предположим, что у нас 1 такой случай из 5. При этом вы утверждаете, что заражаться должно 60% или больше, ну скажем, с вероятностью 90%(мы же не живем в мире бесконечно вероятных событий, правда?)
Тогда мы должны наблюдать, что ваше предсказание выполняется на 9/10 кораблей. Но пока что у нас оно выполнилось на одном из 5. Вероятность того, что мы оказались в ситуации, где ваше утверждение верно, а наша выборка сломана — это вероятность того, что мы случайно собрали выборку так, что в ней оказался всего 1 зараженный по вашему правилу корабль. Не буду утруждать себя калькуляциями, но для этого надо 4 раза угадать один из десяти кораблей, не соответствующих вашему правилу. Наши шансы настолько хреново составлять выборку — не велики. А следовательно, скорее всего проблема в вашем утверждении а не нашей выборке.
PS
Комментарий математический, я данные по кораблям не смотрел и о них ничего не говорил. Если вы по реальным кораблям самостоятельно проведете эти калькуляции, и окажется, что вашей гипотезе соответствуют 4/5 кораблей — это тоже будет отличный результат, которым можно поделиться. Истинность изначального утверждения про 60% я не оспаривал, просто заметил, что если такой корабль действительно один — это весьма маловероятно. Если он не один, или есть другие примеры замкнутых сообществ подтверждающие ваши выводы — отлично, буду рад о них узнать.
Если вы утверждаете, что «ВВП на 8% в любой стране эквивалентно сокращению населения на 5-6 миллионов человек.» покажите 20-24 миллионов дополнительный смертей в РФ за эти 4 года.
Говорить о невоспримчивости можно если человек никогда не заразиться при любых обычных контактахВ такой формулировке восприимчивы даже иммунные. Просто иммунные или болеют бессимптомно (с повышением С-реактивного белка и иных показателей) или не болеют (но можно отследить заражение по подъему IgM). Важно-то не это — а то, что иммунные не передают инфекцию дальше. То есть размножение патогена у них не доходит до выделения доз, больших минимально инфицирующей.
Одного примера достаточно, чтобы сказать, что восприимчиво (то есть заболеют при обычных длительных контактах) не менее 60%.А китайцы намеряли (по ПЦР) при тесных и семейных контактах шанс 1.3% для детей до 15 лет и 3.5% для взрослых. Это при китайских размерах семьи и китайской скученности. В целом у них вышло шанс заразить хоть кого-то в китайской семье — 15%, что показывает что в среднем у них по 6 человек в семье.
Так что вы не правы, никакого шанса 60% заразится от больного в семье — нет.
Ещё раз повторю, что восприимчивость имеет смысл лишь в контексте инфицирующей дозы. Там, где доза велика (тяжелые больные в тесном помещении) — там восприимчивость больше.
Но тут есть иной момент — тесты по ПЦР показывают прежде всего заразность. А тесты по ИФА дают в 5-10 раз больше число переболевших. То есть китайский результат можно трактовать как восприимчивость 17-35% при том, что лишь 3.5% распространяют вирус дальше.
Например ВВП РФ изменялся до 8 раз (в долларах) в разные года.В смысле курс доллара менялся? :-)


А теперь доказывайте, что совпадение провалов случайно. :-)
Ну от дозы 10**30 действительно заболеют все, включая привитых, переболевших, людей в противочумных костюмах и даже трупы. :-) Но такую дозу только в лаборатории создать можно.
10 в 30-й штук вирусов — это речь о миллиардах тонн и кубических километрах:). Это далеко не масштаб лабораторий.
Размеры — 50-200 нанометров, считаем 100 нм. Тогда в кубометре — 10**27 вирусов, а 10*30 — всего лишь тысяча кубов.
Так что по размеру ошиблись сильно, зато по весу — всего на полтора порядка.
Это далеко не масштаб лабораторий.Помнится в одной из лабораторий атомную бомбу сделали. Причем не в единичном экземпляре. :-)
P.S. Как ни странно, российская атомная бомба тоже делалась в лаборатории, причем номер 2.
Посчитаем, размер генома — 0.03 мегабаз, то есть 3*10**-5 пикограмм, то есть 3*10**-17 грамм. Таким образом 10**17 вирусов весят 3 грамма, 10**23 — 3 тонны, 10*30 — 10 миллионов тонн.
Размеры — 50-200 нанометров, считаем 100 нм. Тогда в кубометре — 10**27 вирусов, а 10*30 — всего лишь тысяча кубов.
Я конечно не могу гарантировать правильность своих прикидок, т.к. сам не измерял, а пришлось использовать источники. Но по крайней мере мои прикидки не противоречат здравому смыслу, в то время в этих расчетах получается какая-то дикая плотность. По крайней мере мне не приходит сразу в голову никаких веществ с плотностью в 10 тыс. тонн на кубометр в нормальных условиях.
Короче, вы правы, там объем на пару порядков больше.
Пока я знаю лишь один пример, когда заразилось 60%. На остальных судах (включая алмазную принцессу со средним возрастом пассажиров 69 лет) предел — заражение прекращалось на 20%. Измерения антител в самых зараженных местностях тоже не дали более 20-30% переболевших.
На алмазной принцессе был карантин и люди сидели в своих каютах безвылазно. И даже в этом случае получилось 20%. Да и Шарль-де-Голль не единственный пример. 60%+ переболевших получается по серологическим тестам в городках на севере Италии. Так что не могу серьёзно воспринимать ваши выводы.
В Альцано 12 тысяч человек, в Нембро — 11 тысяч, Сериатте — 21 тысяча. Всего тестов было 1500, то есть тестирование выборочное. При этом поголовное тестирование медиков выявило 23,4%.
Тут большой вопрос — было ли тестирование действительно случайным, бесплатным и не дающим преимуществ или наоборот, на тесты была предварительная запись. Потому что результаты можно прочесть и как «60% переболевших имеют антитела» или «60% тех, кто думает, что переболел, действительно переболели».
Ну как пример — я на подобные тесты пойду одним из первых, так как переболел (неофициально) в начале апреля. И эта справка мне нужна, не только чтобы убедить адептов секты "летальность 35%" среди знакомых, но и чтобы спокойно передвигаться по городу.
Так что "опрос пользователей интернета показал, что 100% пользуются интернетом".
А если мы хотим предсказать, что будет при снятии карантина, то у нас разные сценарии для исчерпания числа восприимчивых и для ситуации, когда его не было. Очень существенно разные. И точка, когда можно снимать карантин — года так на 3 гуляет.
Ну и да, наличие принципиально невосприимчивых не влияет на модель. Так что не понятно, о каких разных сценариях исчерпания вы говорите.
А эффективность карантина — вполне измеряется по данным до и после его введения.
Хорошую аппроксимацию я вам и полиномом 13 порядка сделаю.Но мы не обсуждаем здесь апрокситмацию. Смоделированы именно механики.
А эффективность карантина — вполне измеряется по данным до и после его введения.Но это апостериорные данные. А для предсказания нужны априорные. Постфактум-то я вам, что хотите, предскажу без всяких моделей.
Но это апостериорные данные. А для предсказания нужны априорныеНеважно, какие это данные. Важно, что они известны уже месяц-два. И их можно использовать при прогнозировании снятия карантина.
Полином тоже «моделирует». Причем в данном случае — с почти той же адекватностью. Механика, не учитывающая важные факторы — это ровно та же подгонка коэффициентов полинома. Просто подгоняемая функция иная. Ну так почти любую функцию с 7 параметрами можно весьма точно подогнать.
Я вам уже пояснил, что это эквивалентно моделируется через коэффициент передачи.Нет, не моделируется. Пониженный коэффициент передачи даст десяток раз более затяжную эпидемию. Невосприимчивые снижают и общее число переболевших и длину эпидемии.
Ещё раз повторю, что почти любую функцию с 7 параметрами можно весьма точно подогнать под известные данные. Но прогностические качества такой функции — близки к нулю.
Полином тоже «моделирует».Так «моделирует» а не моделирует. Разница принципиальна.
Но прогностические качества такой функции — близки к нулю.Тогда они точно так же будут близки к нулю, если мы добавим еще пару параметров, которые вы предлагаете.
Восприимчивость части населения — это очень известный параметр в модели SEIR, он имеют физический смысл при моделировании. То, что предложил aikarimov (введение произвольных функций и произвольная коррекция «на лету») — это как раз «моделирование», то есть просто подгонка под известные данные. Ваша идея — пожонглировать R произвольным образом — тоже физический смысл не отражает.
Так что прогнозные свойства модели при учете неполной восприимчивости как раз увеличатся. Собственно, как и при любом введение в модель реальных свойств физического мира.
Ваша идея — пожонглировать R произвольным образом — тоже физический смысл не отражает.У вас ни какая модель не обойдется без жонглирования каким-то параметром. Просто потому, что релаьных данных ни у кого нет.
Давайте уточним еще раз — я не защищаю модель автора. Я говорю, что предлагаемые вами коррекции не дадут принципиально более хорошей модели.
Торф — тлеет, R близок к 1. Вечером чуть костер не потушили — утром легонько тлеет в двух метрах.
Опилки — имеют огромный R, они вспыхивают. Но чуть песком забросали — все, гореть перестали. Ну разве что в отдельных местах чуть вспыхивает. Причем можно закидывать не песком, а чем-то горящим, вроде сырых сучьев. Это и есть уменьшение процента восприимчивых.
Во-вторых, надо отдельно доказать, что R после отмены будет равно таковому до введенияА что тут доказывать? Это аксиома. Если мы отменяем все карантинные меры — количество контактов восстанавливается. Измеряемый R, разумеется будет меньше — но как раз за счет уменьшения числа восприимчивых.
Реальных данных вполне достаточно. Это прежде всего процент имеющих иммунитет, измеряемый R (через время удвоения регистрируемых в день случаев), количество населения.
Я говорю, что предлагаемые вами коррекции не дадут принципиально более хорошей модели.См. выше о принципиальном отличии моделей. То есть одна из двух моделей принципиально неверна. У них общее — только начало процесса, а завершение — совсем разное.
Вы так рассуждаете, как будто бы у нас детерминированная задача типа как про столкновение шариков в школьной физике, где ввел известные начальные — получил точные конечные. Но с сабжем так не получится. Параметры системы во-первых не известны априорно, во-вторых — не стационарны. На этом можно закрывать вопрос — интереса кроме чисто академического оно не представляет.
А интерес чисто практический. Вот, например, графики, что будет при ослаблении карантина по разным провинциям Италии. Получается, что 3 провинциях из 7 — карантин можно ослабить на 20%, а вот на 40% — не стоит.
А вот ещё прогноз по той же Италии. С планированием коек, реанимаций и ИВЛ. А вот и прогноз по России.

Видите, когда можно отменить самоизоляцию? :-)
А интерес чисто практический.Был бы практическим, если бы прогнозы работали.
Проблема только в том, что заранее вы не можете указать, какие конкретно прогнозы сбудутся. И никто не может. А потому практической пользы от них нет.
Вот у вас есть пять разных прогнозов с непересекающимися доверительными интервалами. Какую вы видите практическую пользу в сравнении с отсутствием этих прогнозов?
У трейдеров интереснее — у них несколько десятков индикаторов рынка. Ничего, как-то справляются.
Всегда есть шум
Польза в том, что неточный прогноз — на порядок лучше отсутствия.Вот я сделал вам прогноз на основе броска монетки. Правда ли стало лучше?
Польза в том, что неточный прогноз — на порядок лучше отсутствия.
Индюка кормили 100 дней.
Прогноз для индюка (какой-то, неточный) на 101 день: снова дадут еду.
Реальность: на 101 день повар сделал из индюка суп.
Повар все 101 день прогнозировал, что индюка откармливают на суп. Это был точный прогноз.
Индюк сделал неточный прогноз.
Последствия для индюка — негативные от неточного прогноза.
Для повара — позитивные, от точного прогноза.
Суть: неполная индукция не всегда может использоваться для предсказания.
Сем сложнее система — тем этот эффект существеннее.
Поэтому важнее не прогнозы, а методы реакции на события. Если возможно, то прогнозами лучше вообще не пользоваться при оценке сложных нелинейных искусственных систем (экономика, техника, социум). А для некоторых природных — можно, но тоже весьма ограниченно.
И у индюка точность прогноза -99%. То есть очень хорошая.
Но обычно кто-то угадывает.
«Тетлок изучал проблему «экспертов» в политике и экономике. Он просил специалистов из разных областей оценить вероятность того, что в течение заданного временного периода (около пяти лет) произойдут определенные политические, экономические и военные события. На выходе он получил около двадцати семи тысяч предсказаний почти от трех сотен специалистов. Экономисты составляли около четверти выборки. Исследование показало, что эксперты далеко вышли за пределы своих допусков на ошибку. Обнаружилась и экспертная проблема: между результатами докторов наук и студентов не было разницы. Профессора, имеющие большой список публикаций, справлялись не лучше журналистов. Единственной закономерностью, которую обнаружил Тетлок, была обратная зависимость прогноза от репутации: обладатели громкого имени предсказывали хуже, чем те, кто им не обзавелся.» (Талеб «Черный лебедь»)
И таких исследований — не одно и не два. Описано еще у Канемана «Думай медленно — решай быстро».
Тысячи прогнозов. Уровень попадания- не выше случайного, «ткнуть пальцем в небо».
И это для обычных ситуаций, не кризисов, не в войны.
Кто-то угадывает. Но его не слушают в момент «гадания» и делают все по иному прогнозу. И только потом, делают ретроспекцию и «он угадал!».
И что? Все равно это никак не влияет на экономику.
Экономика живет своей жизнью. Экономисты — своей. А реальный мир — своей. И они крайне редко пересекаются.
А на самом деле — товарные запасы прогнозируются, годовые бюджеты — прогнозируются, нагрузки на сети связи — прогнозируются, дорожная сеть — прогнозируется.
У Milfgard была серия статей по прогнозированию запасов в рознице.
Прогнозы — да, не идеальны, но с ними лучше, чем без них. Мала точность прогнозов, пересекающих точки бифуркации. Ну и очень долгосрочных. А так… по магазину с оборотом миллион — списывается по истечению срока реализации — 1%, нехватка ассортимента — порядка 0.1%. Это вот точность краткосрочных прогнозов.
Но проблема в том, что из этого не следует возможность прогнозирования чего угодно на любом интервале с какой либо определенной погрешностью.
Например, с появлением автомобиля все прогнозы по сену улетели в дым. Вероятно, то же самое будет с долгосрочными прогнозами по нефти после распространения электромобилей.
Другой момент, что эпидемии вполне прогнозируются, даже «на глазок». Помнится мой прогноз (в конце марта) по Италии был 200-300 тысяч официально заболевших и 20-30 тысяч погибших. Ну по погибшим — занизил, будет 35 тысяч, по заболевшим — похоже угадал.
Вот тут мой прогноз по России, через 2 месяца — проверяйте. И это — без матаппарата, самый примитивный вариант
А так… по магазину с оборотом миллион — списывается по истечению срока реализации — 1%, нехватка ассортимента — порядка 0.1%. Это вот точность краткосрочных прогнозов.
Все верно. Для постоянных и даже для изменяющихся условий вполне применимы методы прогнозирования (так называемый «среднестан», «русло»).
Вот только рассмотрите тот же самый прогноз тоже на короткий срок (1 месяц), но на интервале 15 марта — 15 апреля 2020 года для России. На этом интервале все полетело нафиг, все прогнозы — недействительны. Ну и потом, в момент редких и существенных событий («крайнестан»,«джокер») убытки от такого события могут быть настолько огромными — что сожрут прибыль за несколько лет. Примеров таких масса, особенно в финансах и экономике. В торговле — тоже немало.
Я же хочу обратить внимание на то, что надо использовать совершенно разный математический аппарат для медленно меняющихся процессов и для оценки возможности резких «всплесков» в этих же процессах. Ну и в реальности надо обращать внимание на «эргодичность» при анализе.
И это для обычных ситуаций, не кризисов, не в войны.Не, это как раз про бифуркации. То есть в одном из смыслов — кризисы.


В этой модели реально переболеют 75 миллионов (50%) при выявляемости 20% и восприимчивости 100%.
Её ошибка ровно та же — восприимчивость считается 100%.

Смотрите на график новых случаев (зеленая линия внизу). Пик Москва прошла 7 мая. Питер отстает от Москвы недели на 2-3, мы пик пройдем числа 25 мая. По России — будет два горба, отдельно Москва, отдельно остальная страна.
Мой прогноз по данным — 500 тысяч официально заболевших, 6 тысяч официально умерших. Неофициально — переболеет 15-20 миллионов.
Единственное, в чем я согласен — это сроки отмены карантинных мер. Разрешение выезда за границу для граждан — через 3 года, разрешение спортивных мероприятий — через 5 лет, разрешение оппозиционных митингов — через 20 лет, официальная отмена запрета на дарение масок — через 50 лет.
А интерес чисто практический. Вот, например, графики, что будет при ослаблении карантина по разным провинциям Италии.
Чтобы посчитать, что будет при ослаблении карантина — надо знать эффект карантина. А он неизвестен.
Ещё раз повторю: при нормальных методах обработки видно, что в Швеции на пасхальных каникулах народ сидит дома — R в эти дни немного падает.
С чего вы взяли, что падает-то?
То есть виден эффект от трехдневного карантина.
Эм, нет, не виден. Если вы про падение на выходных — это не из-за изменения R, наоборот, согласно вашим графикам R не меняется на выходных. Это четко видно. Потому что если бы R менялся на выходных, мы бы видели это падение не на самих выходных — а в смещении на инкубационный период.
Мы же видим уменьшение учтенных случаев. Т.е. на выходных просто хуже идет учет — что вполне логично.
Это график R, на нем нет учтенных случаев.
Ну так, а R считается по числу учтенных случаев. Уменьшается прирост учтенных случаев — падает R. Или откуда вы думаете взялось это "реальное R"? :)
Если вы считаете, что меньший учет идет по выходным — R должен падать каждый понедельник-вторник. А на графике — падание только на пасхальные выходные. Получается, что меньший учет был в рабочие дни?
Ну ладно, это я придираюсь. Понятно, что обычному человеку из наложения эффектов не выделить разные составляющие. Это надо иметь большой опыт графики читать. Когда у тебя на графике систематика, НЧ-волны, коррелированный тренд + ВЧ-шум — как-то научаешься выделять.
Странно полагать, что эти измерения хоть насколько-то точны — корыто от не корыта отличается одной точкой. То, что в модели оно оказалось там же — случайность.
Пардон, когда учитываются случаи? Когда падает R?
Да.
Какой между ними лаг?
Никакого. С чего бы там быть лагу?
Если вы считаете, что меньший учет идет по выходным — R должен падать каждый понедельник-вторник.
Там никакого лага нет. В выходные меньший прирост учтенных заболевших (т.к. учет ведется хуже), а меньший прирост учтенных заболевших — это меньший R.
R должен падать каждый понедельник-вторник. А на графике — падание только на пасхальные выходные.
Он должен падать каждые выходные. И падает каждые выходные на графике.
А на те данные, что были до середины марта, не смотрите вообще — там нет никаких данных на самом деле, только шум.
То есть вы думаете, что люди заражаются и сразу же учитываются в статистике?
Эм, нет, с чего вы взяли? Я говорю что те люди которые когда-то заразились и оказываются впоследствии учтены — сразу как оказываются учтены влияют на R. По-этому между фактом учета и фактом изменения R лага нет.
С другой стороны, между самим фактом заболевания и фактом учета — лаг есть. По-этому, если на выходных падает заболеваемость — вы это увидите с лагом, а если падает "учитываемость" — без лага. Мы на графике видим без лага.
Потому как обычно R считают на момент заражения, а не на момент учета зараженных.
Теперь вам осталось только доказать эту теорию. Исходя из формул в данной статье.Еще раз повторяю — там бред. Если вы так не считаете, могу задать и вам те же самые вопросы, что и автору.
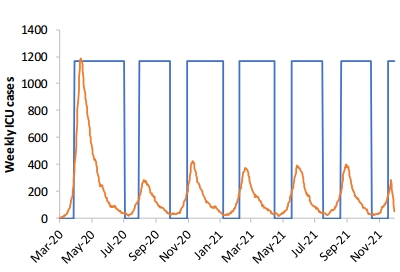
Как видите, исходя из теории, модель сдерживания дает несколько лет периодически вводимого карантина. С другой стороны, переболело слишком мало народу, чтобы обеспечить групповой иммунитет по модели смягчения (если считать всех восприимчивыми).
То есть, действительно, aikarimov прав — модель SEIRD не работает. Но его мысли о линейном росте — мне кажутся не совсем верными. Они могут быть верны для маленьких городков, где все ходят пешком и каждый лень встречают одних и тех же прохожих. Но не для больших городов, где каждый день — новые лица в транспорте, магазине, на улице.
При этом любая эпидемия ОРВИ — затрагивает всего несколько процентов населения. И длится примерно 3-4 месяца — 6-8 недель подъем, 6-8 недель спад. Маловероятно, что с ковидом будет иначе.
Отсюда — идеи о восприимчивости и инфицирующей дозе. Суть в том, что тяжесть заболевания зависит от инфицирующей дозы, а выделяемая доза — зависит от тяжести заболевания. Грубо говоря, доза, заражающая 50% населения — на несколько порядков больше дозы, заражающей 1% населения.
Поэтому в расчетах нужно или отдельно считать выделение и Rt для разных больных (и в разных стадиях) или принять, что восприимчивость весьма невысока, не больше 20-30 населения.
Это не означает, что невосприимчивые вообще не заболеют — это означает, что чтобы они заболели, на них нужно кашлять долго, упорно и не одному больному — а многим.
Поэтому R0, посчитанный по больным в средней и тяжелой форме — не верен для больных в бессимптомной и легкой форме.
Грубо говоря, я считаю, что эпидемия затихает не из-за карантина, а вопреки карантину. То есть работает модель смягчения, при которой эпидемия затихает из-за исчерпания восприимчивых.
Кто прав — увидим по Италии, где с 4 мая отменены некоторые карантинные меры. Ну и по другим странам. Думаю, что в ближайший месяц будет понятнее, какая из моделей реально сработала в Европе.
Ну бред в части не означает, что бред везде.
Увы, псевдонаучный бред в самом начале. Ну, вы можете воспроизвести предлагаемую математическую модель эпидемии по тем формулам? Типа как у SEIRD? Хотя бы, на какие классы делится популяция у автора той статьи? Дифф. (интегро-дифференциальные, etc.) уравнения можете воспроизвести по формулам?
Поэтому в расчетах нужно или отдельно считать выделение и Rt для разных больных (и в разных стадиях)
Вы сами дали ссылку на статью из Википедии на ситуацию на Diamond_Princess и привели R0=14.8, но, судя по всему, поленились пройти по ссылке на статью, где это число находится. Посмотрите PDF и (обобщенные на две взаимодействющие популяции) уравнения. И да, отмечу, что там никаких Rt в рассмотрение не вводится, а R0 (для первых 14 дней и последующих) восстанавливается из результатов подгонки имеющихся исторических кривых методом наименьших квадратов, как произведение двух параметров SEIR модели:
- Overall transmissibility and contact rate (1/day)
- Infectious period or time to removal (days)
Т.е. ваши предположения вполне себе могут быть проверены с помощью обобщенных SEIR моделей без использования непонятного R(t). Только вот параметров у таких моделй будет неприлично много для их определения по имеющейся кривой статистике.
отмечу, что там никаких Rt в рассмотрение не вводится,Ну почему же, там
The R0 was 14.8 initially and then Rt declined to a stable 1.78 after the quarantine. Впрочем, они там больше используют β — это коэффициент репродукции в день, R=β*T, где T — число дней.The effective reproduction number Re can be reduced by intervention measures such as social distancing, while R0 remains unaffected, as it is a measure of the rate of infections when there are no interventions.Увы, псевдонаучный бред в самом начале.Тут конкретней надо. Любая модель — это упрощение.
Поэтому детсадовцы вполне знают, что тяжелые капли падают быстрее легких (видно по стеклу автобуса), а взрослые дико удивляются, что тела упавших с самолета — относительно целые. А чему тут удивляться, скорость падения, что с 20ого этажа, что с 10 км практически одинакова.
Так что теоретически неверная модель может давать лучшие результаты в конкретных случаях. Это называется «парный баг» и должно быть по личному опыту известно каждому программисту.
Ну почему же, там The R0 was 14.8 initially and then Rt declined to a stable 1.78 after the quarantine. Впрочем, они там больше используют β — это коэффициент репродукции в день, R=β*T, где T — число дней.
Да, только вот это Rt — просто по написанию совпадает c Rt из той статьи на хабре, где:
R_t = R_0(1 - P_t) (2)что в некотором смысле эквивалентно первому или второму дифф.уравнению SEIR, где в правой части входят -beta*S*I и если E=0 и D=0, то S=1-I. А I там растет экспоненциально… Ну и понеслось жонглирование формулами.
А в статье по ссылке из Википедии Rt=beta_t*T т.е. это просто изменившееся R0 вследствие карантинных мер, начиная с 14 дня. И оно фиттится по всей исторической кривой. И, кстати — вывод из статьи, что если бы карантин не ввели, то за тот же период заболело бы сильно больше народу, типа 79%.
Да, только вот это Rt — просто по написанию совпадает c Rt из той статьи на хабре, где:
R_t = R_0(1 — P_t) (2)
И по написанию и по размерности и по смыслу. Rt — это эффективное репродукционное число.
Pt — это доля тех, кого уже нельзя заразить (заболевших, переболевших, умерших). 1-Pt — это доля тех, кто может заразится. Ну и очевидно, что в отсутствие карантина Rt=R0*(1-Pt).
Грубо говоря, эта формула означает, что если 90% заразилось, то не зараженных остается лишь 10%, а Rt — будет в 10 раз меньше R0.
Короче, мне кажется, что вам просто нужно на пальцах объяснять каждую формулу.
P.S. SEIR — это не догма, это всего лишь модель. Причем не идеально работающая модель.
И по написанию и по размерности и по смыслу. Rt — это эффективное репродукционное число.
Ну так это разное число в двух обсуждаемых вами статьях.
Ну и очевидно, что в отсутствие карантина Rt=R0*(1-Pt).
Только вот число (доля) активных заразных в текущий момент времени, это не P(t), а меньшая величина. От нее нужно вычесть число recovered, deaths и exposed. И замена R0 на Rt в формуле экспоненциального начального роста это безосновательное жульничество.
Потому как обычно R считают на момент заражения, а не на момент учета зараженных.
Это в теории. А на практике информации о моменте заражения нет — по-этому считают момент учета.
Если вы считаете иначе, и что автора каким-то способом эту информацию о моменте заражения получил — укажите, что это за способ и докажите, что автор его использовал.
Ну или просто можете посмотреть на график выявленных случаев и убедиться, что там на нем то самое "корыто" ровно в том же месте, что и на вашем графике R. Ни чуть не сдвинуто.
В статье есть R — но там это количество recovered. Вы же обсуждаете влияние R0, как я понимаю?
Мы про R0, оно в статье есть. Вот в этой:
https://habr.com/ru/post/500218/
Мы про нее.
А тогда зачем?
А почему вы у меня спрашиваете? :)
На формулы посмотрите. Там N0 — количество инфицированных в определенный момент времени и Nt — количество заболевших через t дней
Ну все верно, N0 — начальное количество (т.е. 1 больной, если начинать статистику с 1) и t — время от начала эпидемии, собственно. Никакого смещения на инкубационный период там не делается. Если делается — извольте процитировать. Ну и как я уже сказал: "можете посмотреть на график выявленных случаев и убедиться, что там на нем то самое "корыто" ровно в том же месте, что и на вашем графике R" — без какого-либо смещения. Т.о. падение R на графике — это не результат того что меньше людей заболело, а результат того, что меньше больных выявлено. Потом после выходных наоборот происходит всплеск вверх — выявляют "недовыявленных" за выходные.
Кто прав — увидим по Италии, где с 4 мая отменены некоторые карантинные меры.
В Италии, с-но, от 40 до 60% переболевших в северных областях (и, видимо, 40-60% — это как раз и есть предел восприимчивого населения). Естественно, там и без карантина все на убыль пойдет уже :)
Еще это как бы намекает на эффективность карантина — карантин настолько эффективен, что за месяц этого карантина переболела половина населения.
Никакого смещения на инкубационный период там не делаетсяА его и не сделать — там же 14 дней с медианой на N5. То есть, общая длина фронтов на выходе превышает длину входного импульса. Совершенно очевидно, что эффект кратковременных воздействий умеренной амплитуды необнаружим на фоне шума.
Если делается — извольте процитировать.Легко В качестве времени заразности больного D для Covid-19 было взято значение 10. Это собственно время от заражения до изоляции.
В Италии, с-но, от 40 до 60% переболевших в северных областяхПруф можно? На поголовные или действительно случайные тесты? Или это те тесты в маленьких городках, на которые понабежали люди, думающие, что они переболели? Ну так опрос пользователей интернета показал, что 100% используют интернет. А тест тех, кто думает, что переболел, показал, что 60% точно переболели. А остальные 40% — возможно тоже переболели, но не имеют антител (ибо есть ещё и клеточный имумнитет).
Легко В качестве времени заразности больного D для Covid-19 было взято значение 10.
Так это не смещение, во-первых (никто там на D график не смещает), а во-вторых — время заразности больного и инкубационный период это два совершенно разных числа, для которых даже неизвестно отношение друг к другу (какое больше — а какое меньше). Еще раз — если вы считаете, что в указанной модели где-то используется смещение ни инкубационный период — приведите цитату, явную (так и должно быть написано — сдвигаем на средний инкубационный период), а еще объясните, почему результат этой модели по факту смещения не имеет — т.е., падает число выявленных случаев и синхронно падает R.
Не понятно вообще, с чем вы спорите — я вам еще три поста назад привел доказательство того, что смещение в рассматриваемой модели отсутствует. Четко, ясное и однозначное.
Т.о. падения R которые вы видите — это падение в числе учета, а не в числе заболевших. Это факт, он есть, оспорить его нельзя.
Пруф можно?
Это результаты серологических тестов.
А тест тех, кто думает, что переболел, показал, что 60% точно переболели. А остальные 40% — возможно тоже переболели, но не имеют антител (ибо есть ещё и клеточный имумнитет).
Ну т.е. как минимум 40-60% переболело. Оценка снизу нас вполне устраивает.
По цитате:
У нас есть люди, которые переболели, у них была температура и кашель
Сорян, но если у человека была температура и кашель — он чем-то переболел, конечно, но далеко не факт, что коронавирусом.
Легко В качестве времени заразности больного D для Covid-19 было взято значение 10. Это собственно время от заражения до изоляции.
А далее автор той статьи воспользовался своей рекуррентной формулой, которая не является решением его же уравнений. Я проверил. И данные и код опубликованы там под спойлером.
Ну так, а R считается по числу учтенных случаев. Уменьшается прирост учтенных случаев — падает R. Или откуда вы думаете взялось это «реальное R»? :)
Объясните, пожалуйста, как конкретно рассчитывается R по имеющимся данным статистики? И как это рассчитанное значение может использоваться для предсказания?
Возможно, такая статистика связана с тем, что детей просто берегут в других странах(в Украине часть детей все еще играет на улице и власти особо ничего не делают с этим).
Да, возможно, детям делают больше тестов. Но врятли вот прям в два раза больше.
В третьих — пневмоний у детей намного больше. Ну как пример — у меня порядка 20 пневмоний до 18 лет и всего две позже. А если каждую пневмонию считать ковидной… Ну в общем, даже если пневмония бактериальная, то получить в больнице вдобавок ещё и ковид — легко. Особенно на уровне ПЦР+. То есть ковид — без симптомов, пневмония — бактериальная, по сумме — пишем ковидная пневмония.
Поскольку в Украине тесты делают только тяжелым и медикамА остальным пишут ковид вообще на глазок или по КТ?
Возьмите данные NL, которые правильно скорректированы по датам (в отличие от worldmeters.info) — карантин 14 марта:
www.rivm.nl/coronavirus-covid-19/grafieken (ziekenhuis — госпитализации, overledenen — смерти).
Еще можете взять данные по IC (реанимации) — www.stichting-nice.nl.
Дело в том, что брать крупные страны, крайне не выгодно в связи с разными очагами, которые то вспыхивают, то утихают. В этом плане небольшие, но густонаселенные страны могут дать и хорошую статистику и понимание коэффициентов.
Как по мне, так кривую надо в первую очередь подгонять под кол-во смертей, потому что очевидно они стабильно выявляются в отличие от случаев.
Я тут уже дня три пытаюсь решить вот такую задачу, используя данные института Хопкинса с github'а, а именно данные на каждый день о заразившихся (confirmed), выздоровевших (recovered) и умерших (deaths).
- Давайте для простоты предположим, что выздоровевшие выздоравливают за одно и то же (пока неизвестное) число дней dt_recovered.
- Умершие умирают тоже за одно и тоже количество дней (но другое). dt_death.
Кстати — этим объясняется, почему мы пока (в России) видим что число выздоровевших на сегодня, заметно меньшее числа заразившихся. Та же история в умершими, которых совсем мало. Причем упрощение о равенстве дней в больнице — не сильное. То же самое произойдет при наличии разброса.
Заодно становится понятно, что утверждение (СМИ и пр.) о малой летальности, вычисляемое как отношение кумулятивных сумм умерших вплоть до сегодняшнего дня к кумулятивной сумме заразившихся снова вплоть до сегодняшнего дня в России — жульничество! Ведь делить надо на кумулятивную сумму до сегодня минус dt_deaths (которое может оказаться и месяцем по оценкам знакомых врачей). Но тогда, в прошлом число заразившихся как бы не на порядок меньше было. А тогда и летальность возрастает на порядок :(
Ладно, вернемся к задаче… Очевидно, что в упрощенной модели число заболевших за какую-то старую дату должно быть равно:
N_confirmed(t) = N_recovered(t+dt_recovered) + N_deaths(t+dt_deaths).
Вот… Данные есть, времена целые. Вроде и дел-то перебрать примерно 30x30 вариантов времен и найти, какая комбинация дает минимум суммы квадратов отклонений:
sum((N_confirmed(t) — N_recovered(t+dt_recovered) — N_deaths(t+dt_deaths))**2/N_confirmed(t)
Веса разные, потому что распределения Пуассона.
Однако, не выходит каменный цветок :( Т.е. минимум (даже несколько) находится, но вот качество воспроизведения кривой N_confirmed(t) совершенно неудовлетворительное.
P.S. Принимаются любые советы…
Автор, классический МНК в таком фитинге применять нельзя, т.к. для корректности классического МНК случайная ошибка должна быть случайной величиной, которая статистически не зависит от факторов. У нас же ошибка в количестве заболевших растет пропорционально самому количеству заболевших — и, с-но, растет при росте факторов, которые влияют на скорость роста количества заболевших. Как минимум, здесь надо переходить к логарифмам приращений (вообще это обязательный первый шаг при анализе подобных процессов) — хотя принципиально это проблему и не решит.
А еще у вас первый фактор по котором проводится фитинг (суммарное число заболевших) может быть существенно больше второго (число активных случаев) — такие факторы надо приводить к одному масштабу.
Никогда ранее не занимался моделированием эпидемий, но у меня возникает закономерный вопрос: кто-то вообще оценивал правдоподобность замены стохастических процессов усредненными?
Эти вопросы в общем-то давно исследованы в рамках матстата — и такая замена корректна, при выполнении определенных условий для статистического распределения.
В случае наличия штук вроде "суперраспространителей" — эти условия вполне могут не выполняться. Но, проблема — в этом случае процесс в принципе становится непрогнозируемым без априорной информации никак вообще. Не будет существовать алгоритма, который бы позволил рассчитать параметры модели по имеющимся выборкам. В таких случаях обычно можно оценить ряд дифференциальных/топологический инвариантов траектории, некоторые ее метрические характеристики — но они обычно представляют исключительно математический интерес и бесполезны в качестве чего-то, на основании чего можно сформировать какой-то вменяемый прогноз.
Колебания с периодом в 7 дней с большой вероятностью не колебания заболеваемости, а колебания диагностики. В Германии в среду и пятницу у обычных врачей сокращенные дни, а в субботу и воскресенье принимают только дежурные при экстренных случаях. На это накладывается еще опоздание данных. Если в понедельник пришли отчеты за выходные, то их впишут скорее всего уже понедельником.
Вероятностные расчеты должны вестись отталкиваясь, в свою очередь, от биномиального распределения концентрации патогена в заданном объеме аэрозоли, для вероятности заражения более 0,5.
Поэтому либо домен бинома не правильно оценен.
Возможны как полный провал счетовода, так и недоработки по оценке влияния погоды.
Либо вероятностный расчет не верен.
На самом деле данных для коррекции и того и другого уже в избытке. Отсутствует работа ( труд ) проделанный над материалом.
Модель работает.
Количество выявленных случаев зависит от возможностей тестирования (количества тестов) и методики выборки для тестирования.
Верно, я тоже на это обратил внимание.
Разница между ростом заболевших и ростом обнаруженных новых заболевших при тестировании — может быть существенная.
Более интересен показатель «количество смертей в день» для России. Он существенно не меняется с середины апреля.
Само количество тоже интересное: 1451 (на сегодня).
При выявленных 155 000 заболевших.
Получается, что смертность в отношении к выявленным случаям будет 0,93%. Много или мало? На «супер-пупер-мега вирус» — не похоже вроде.
Оба показателя «умершие» и «выявленные» могут быть неточными.
И теперь анализ и предположение (весьма дикое, кстати).
Исходные данные:
относительная стабильность количества смертей в день (колебание 100+-20 в день),
при росте количества проведенных тестов растет количество выявленных больных
выявлены не все больные
причины смерти «от коронавируса» указываются достаточно точно, хотя могут и незначительно искусственно завышаться «на местах»
Предположение:
«Эпидемия» началась раньше, примерно в 10-11 месяце 2019 года.
Сейчас видно «плато» по количеству умерших.
Не стоит принимать в расчет количество выявленных больных, реальное количество больных или уже переболевших, или болеющих без симптомов может быть существенно выше.
Если взять данные по Германии и США за основу, и в модели по России сдвинуть время на 4 месяца назад, причем скорректировать коэффициенты регрессии по текущим реальным данным смертности в день. Могут получиться более реальные прогнозы… Наверное.
У меня не хватит квалификации сделать это самому, поэтому выношу на обсуждение.
Интересно было бы использовать для оценок модели с нечеткой логикой, в которых можно использовать интервалы значений с их вероятностью. Вроде в матлабе все это есть. Я давно туда не лазил…
И немного совсем в иную сторону. Про определение «эпидемия».
Если выявлено 155 000 больных на территории всей России при населении 144 млн, и данная ситуация считается «эпидемией», то формальный «эпидемический порог» для данного заболевания составляет менее 0,2%. Обычно эпидемией считается заболевание с эпидемическим порогом более 1%. Хотя и не всегда.
И тут возникает вопрос: или это не эпидемия, или количество больных намного выше, или
эпидемический порог назначен «с фонаря» (точнее от паники и ВОЗ), или есть еще какой-то неизвестный мне вариант (что скорее всего).
Мне ещё вот что стало интересно. В последние дни кривая заболеваемости снова пошла на взлёт — достаточно чётко видно вот здесь на втором графике, что в 20-х числах апреля была как раз та сама прямая, про которую речь в статье, а дальше снова подьём (есть подозрение, что за счёт заразившихся в Пасху — как раз примерно две недели инкубационного периода). Это как-то можно учесть в описываемой модели?
1. Главная проблема полное игнорирование вами «невидимого» сектора заражённых, которых в разы больше. Например у меня нет ни одного знакомого, кто бы находится в больнице с коронавирусом, зато есть троё разных приятелей, которые в апреле тихо лежали дома и никому из медиков не «палились», что у них ковид.
2. Надо понимать, откуда берётся статистика. Есть куча зависимостей типа «если — то»: «Если заболел — то протестировали на вирус». И это первое, что приходит в голову. Тут где-то рядом бродит теорема Байеса.
3. Когда Собянин говорит, что провели выборочный скрининг населения и установили, что заболело или переболело 2% населения Москвы, это же полный трэш. Люди просто безграмотны! Хочется спросить, а точность тестов какая? Собянин не понимает, что для того, чтобы «заметить» хоть со сколько-нибудь приличной сигмой (погрешностью) 2% больных. Точность тестов должна быть в разы лучше 98%. Что очевидно не так.
Пока слова Собянина можно интерпретировать так. Ошибка тестов у нас в районе 2%, поэтому, сколько заболевших мы сказать не можем, но точно не выше 1%, а скорее всего много меньше.
зато есть троё разных приятелей, которые в апреле тихо лежали дома и никому из медиков не «палились», что у них ковид.
А у них таки ковид?
Кроме того, личный пример непоказателен.
Как они поняли, что у них ковид? И так, ради общего интереса — зачем они «не палились»?
N — общий размер популяции,
Секундочку, а где же невосприимчивые? Они тоже должны входить в сумму.
Я эту статью смотрю 5ого мая. На картинках обещают снижение числа дневных случаев в районе начала мая. А worldometers настаивает, что оно растёт. Кто прав?
Ну понятно, же, что у картинок своя жизнь, а у реальности другая, все эти попытки предсказаний очень похожи, на расчёт получения Джек-пота в казино, потому и результат соответствующий.
Никакая математика тут не справится, нет пока технологий, способных верно решать уравнения, с таким количеством неизвестных.
Основа науки, это получение более-менее повторяющегося результата, с последующей попыткой подобрать более-менее вменяемой объяснение, под этот результат.
Я вам открою секрет, многим неизвестный, — модели того типа, что рассматривается в посте, специалистами никогда и ни при каких условиях не используются для прогнозирования. Они для этого не предназначены и никогда не были предназначены просто by design.
никогда и ни при каких условиях не используются для прогнозирования.
Используются для прогнозирования. Например, если нужно получить гранты для исследований. В общем, для целей получения бабла в том или ином виде.
Более совершенные модели используются в Германии (описано тут)
В этой статье используются.
То, что они не предназначены для этого — не имеет никакого значения. Чем же еще пользоваться? :)
Мне обычно именно так заявляют экономисты, когда используют еще более примитивные линейные модели, одно параметрические, без учета структуры системы. Да еще и построенные на основании неверных, несвоевременных статистических данных. «Чем же еще пользоваться? Мы иного не знаем...».
В приведенной выше статье модель вполне адекватная существующим представлениям биологов, медиков и математиков. То, что «Они для этого не предназначены и никогда не были предназначены просто by design.» — тоже верно. Но для теории ad hoc — вполне годиться.
Используются для прогнозирования. Например, если нужно получить гранты для исследований. В общем, для целей получения бабла в том или ином виде.
Так-то конечно да, для того, чтобы бабла с лопухов снять — можно использовать что угодно.
Чем же еще пользоваться? :)
Тут пункта два:
- Вообще пользоваться есть чем, но это сложно, очень. На самом деле, я сомневаюсь что в мире в принципе больше ~десятка специалистов, которые были бы способны нормально решить подобного рода задачу прогнозирования. И под "решением" я подразумеваю не "взял и посчитал" — а то, что такому человеку можно будет некоторый штат выдать в подчинение и потребовать какого-то вменяемого результата во вменяемые сроки. Таких же, что "взял и посчитал" не существует вообще.
- Если уж и хочется воспользоваться чем-то заведомо некорректным можно сделать прикидку на глаз или подбросить монетку — прогностическая ценность таких подходов не сильно ниже. Зато гранта не получишь, это да :)
В приведенной выше статье модель вполне адекватная существующим представлениям биологов, медиков и математиков.
Да, но такие модели используются не для прогнозирования поведения системы, а для качественного анализа режимов ее работы. Например, мы из такой модели можем почерпнуть общий вид кривой и возможный вид соотношений между зависимыми переменными, можем попытаться классифицировать решения (в общем случае это не будет тривиальной задачей). Но вот доводить до чисел смысла нет никакого.
это сложно, очень.
я сомневаюсь что в мире в принципе больше ~десятка специалистов, которые были бы способны нормально решить подобного рода задачу прогнозирования.
Это да, согласен с Вами.
Но есть есть и еще хуже предположение. Что задача среднесрочного предсказания поведения даже простых систем со сложными нелинейными связями — вообще не решаема. Вообще никак, никакими методами.
Беда немного в другом. Аналитики применяют заведомо негодные методы, просто потому, что искать иные — лень.
Пример реальной беседы на кафедре экономики одного ВУЗА:
— Статистические методы в экономике нельзя использовать.
— Не может быть! Все знают, что можно.
— Вот книга, вот примеры, вот все описано.
— Уупс… Действительно нельзя, согласен. Но может быть как-то, для оценок, для идеальных ситуаций, для обучения можно использовать!
— Нет, совсем нельзя.
— А что тогда использовать? Какие иные методы? Мы же всегда использовали эти, вот в книгах и методичках это описано.
— Нелинейная динамика, нечеткая логика, имитационные модели, фракталы…
— Не, это сложно, незнакомо. Давайте так: иного я не знаю, буду все равно использовать статистические методы.
— Но ведь это же неверно! Вы же студентов ерунде учите!
— И что? Они все равно не слушают, ничего не помнят, не знают и знать не хотят. Так что какая разница?
Что задача среднесрочного предсказания поведения даже простых систем со сложными нелинейными связями — вообще не решаема. Вообще никак, никакими методами.
Зачастую — да, это так. Просто математически, есть системы которые предсказать не получится.
Задача прогнозирования систем с хаотическим поведением, аналогичным турбулентному течению жидкости не решаема, потому что соседние траектории в фазовом пространстве расходятся экспоненциально во времени (при малом dt) — ошибка в начальных условиях растет экспоненциально.
Согласен, но у того же Глейка описан метод построения модели частоты падения капель из крана, в зависимости от угла поворота вентиля. И там дается пример выбора такого фазового пространства, что в нем процесс становится виден в виде некоей просто описываемой кривой. Мы (на кафедре в Плешке) пробовали применить это подход к технико-экономическим системами. В определенном «фазовом пространстве» с определенной точки зрения сложная псевдо-хаотическая структура становится представима в виде модели из однотипных «слоев». Что-то типа композитного материала, кристаллическая матрица и эластичный слой. Тогда становятся видны закономерности развития таких систем. По факту, случайно подобрали фазовое пространство в котором описание поведения системы стало достаточно простым для описания и понимания.
Есть системы находящиеся в устойчивом равновесии, а есть в неустойчивом — маятник и перевернутый маятник два простых примера.
Согласен. Есть и варианты, когда система «рисует» в фазовом пространстве линию притяжения (аттрактор). Или может быть несколько стабильных состояний (фибрилляция сердца пример).
На микро-уровне аттрактор Лоренца состоит из непересекающихся линий. И не хаос, и не порядок. Что-то среднее, но малопонятное. При «отдалении» — линии как-бы сливаются.
У эпидемии тоже есть куча отдельных линий поведения «акторов», цепочки и цепная реакция. Если найти такое фазовое пространство, в котором совокупность этих «линий» будет выглядеть более-менее осмысленно (проглядывается какая-то закономерность) — то может быть удастся существенно упростить и улучшить модель.
Это пока начальные идеи, может быть неточно описаны.
Насчет минздрава. Скорее всего тут влияют какие-то иные факторы, не всегда видимые. Например, количество инфицированных зависит от количества проводимых тестов. Или включен какой-то искусственный механизм ограничения или увеличения числа инфицированных в отчетах.
Вопрос почему мы видим линейный рост числа инфицированны
Это достаточно очевидно — экспоненциальный рост будет только тогда, когда всегда есть бесконечное число соседей для заражения (с-но это равномерно двигающаяся волна в бесконечномерном пространстве). На практике же это не так, на практике пространство конечномерно. Например — размножение бактерий само по себе экспоненциально, но на двумерной подложке, после достижения максимальной плотности — квадратично. Соответственно, рост заболеваемости на длинной перспективе не может быть более чем квадратичен — просто в силу физических ограничений. Популяция людей распределяется на двумерной сфере. Ну а дальше просто уменьшается процент восприимчивой популяции — и мы видим замедление роста.
модели того типа, что рассматривается в посте, специалистами никогда и ни при каких условиях не используются для прогнозирования
Как показывает реальность, для прогнозирования используют вообще всё, при этом особый приоритет часто получают непонятные догадки, которые Ваши модели, на порядок превосходят, кстати, против них вообще ничего не имею, читал с интересом, спасибо.
Как и в случае США, реальные данные содержат ясно выраженные колебания с периодом в 7 дней. Это значит, что в выходные дни число контактов увеличивается, а следовательно, растет и число зараженных.
а может потому что суббота/воскресенье — выходные дни и тесты не делают просто так. У нас лабы тест делали в субботу утром а результат дали в понедельник вечером, если бы делали в будни то было бы быстрее. тут нужно брать недельную среднюю чтоб увидить тренд
все: сидят в самоизоляции
aikarimov спустя месяц: «ну и где ваш экспоненциальный рост?»
Все выкладки тут бесполезны по простой причине — нет на самом деле у вас данных. Текущие данные по выявленным — просто результат тестирования. Чем больше тестов, тем больше выявлено. Реальной картины заболевших никто не знает. Отсюда и артефакты типа линейной зависимости — производство и закупка тестов идет не по экспоненте.
Учтите что много безсимптомных, и они заразны, так что больше всего инфекция сейчас распространяется теми людьми, которые возможно даже не задумывались сделать тесты.
А еще методология в каждой стране своя, свои тесты, периодически методологию меняли. Как у нас например, в ковидные стали записывать не только с тестами а вообще всех с симптомами ОРВИ похожими на ковид.
Всё ниже написанное есть только фантазия непричастного человека.
Слышите, это всё фантазия, ни в коем случае не правда.
Фантазии ON.
Официальная статистика с Яндекса, они же наше всё?
За пятое мая +76 случаев по отдельной области, а если вдруг вам попадётся файлик xlsx со сводом по области, то вы увидите +72 случая.
А за 4 мая, так и вообще на Яндексе +133 случая, в файлике +55 случаев.
Фантазии OFF.
Вы учитываете, что официальная статистика может быть отличной от реальности?
с симптомами ОРВИ похожими на ковид.Ковид это и есть симптомы в первую очередь.
U07.2 — COVID-19, virus not identified
Use this code when COVID-19 is diagnosed clinically or epidemiologically but laboratory testing is inconclusive or not available. Use additional code, if desired, to identify pneumonia or other manifestations
Пока все, что нам остается — меньше посещать общественные места, пользоваться правильными респираторами
Статья про «правильные» респираторы по новым данным выглядит как избыточная защита. Вот советы врача на передовой Доктор Дэвид Прайс, рекомендации значительно отличаются:
Эта болезнь обычно передаётся, когда вы прикасаетесь к чему-то инфицированному: к человеку или поверхности с вирусом. А потом трогаете руками собственное лицо. Он проникает через ваши глаза, нос или рот.
… по тем данным, которыми я сейчас обладаю, чтобы действительно заразиться воздушно-капельным путём — вам нужно иметь очень длительный и устойчивый контакт с инфицированным. То есть провести с ним 15-30 минут, а то и более, в незащищенной среде (без маски) в закрытой комнате.
Аргумент в пользу врача так же выше в комментариях:
У ковида минимальная инфицирующая доза — 10**3-10**4, я даже где-то видел оценку 10**5. Так что «рубануть на входе» — вполне получается.
Получается что фильтровать наночастицы размером в доли микрона нет необходимости? Именно на размере единичного вириона ~100 нм и строилась аргументация о требовании к высочайшей степени защиты. Если отталкиваться от размера аэрозоля 10-100 мкм (чем больше, тем опаснее), то и требования к защите снижаются на порядок, вплоть до того что достаточно соблюдать дистанцию рекомендуемую (понятно что такие не всегда возможно и возвращаемся к необходимости средств защиты). Плюс не каждая частица аэрозоля будет содержать достаточное количество вирионов, я с трудом представляю себе ситуацию, когда случайная частица летающая в воздухе размером в 10 микрометров будет представлять собой концентрированный сгусток вирионов в количестве до 10**5 с минимальным количеством посторонней материи. Это в каком состоянии человек может выделять такую концентрацию?
Похоже, что занести большую дозу вирионов >10**5, обеспечивающих тяжелое течение заболевание можно только контактным методом, и люди это делают неконтролируемо трогая лицо. Вот такая ситуация и наблюдается постоянно, например через ручки дверей, тележек и денежные купюры. Тут уже нет микроскопических одиночных частиц, вполне себе макромасштабы и практически неограниченное количество вирионов.
Так же мои личные наблюдения по попаданию посторонних частиц в глаза. У меня аллергия на пыльцу некоторых растений, когда попадает в глаза начинается зуд. В обычных условиях пыльца в глаза не попадает, ресницы мешают конвективному перетоку воздуха, частицам пыльцы нет возможности добраться до роговицы глаза. Пыльца попадает при ветре свыше 2 м/с, тогда пыльца уверенно переносится горизонтально и прилипает к роговице. Таким образом глаза выглядят весьма защищенными от аэрозоля, так как в обычных условиях нет потока воздуха перпендукулярного роговице. Попасть конвективным способом на роговицу частица аэрозоля может с вероятностью в тысячи раз ниже, чем на слизистую носа или легких (так как дыханием захватываются).
В целом теория совпадает с наблюдением врача. Соответственно уделять внимание прежде всего стоит контактному способу передачи вируса (по сути безлимитному по количеству переносимых вирионов), как указано у автора статьи, выделив приоритет этим методам защиты
мыть руки, не забывать протирать спиртом смартфон после того, как достали его на улице
Ну и вот видим, что моделирование не сработало. Видимо, забыли добавить коэффициенты(
Заодно, было бы интересно посмотреть как майские праздники сыграют.
Пандемия COVID-19 глазами математика, или почему классическая модель SEIRD не работает