Привет, друзья. сегодняшний материал приурочен к запуску очередного набора в группы по базовому и продвинутому курсам «Математики для Data Science».

Сегодня мы затронем некоторые размышления о методах глубокого обучения. Начнем с обзора шаблонных способов применения глубокого обучения в научной среде, а затем поговорим про сквозной процесс проектирования, а также вкратце про особенности альтернативных методов машинного обучения, которые могут оказаться более перспективными для решения специфических проблем.
Как обычно применяются методы глубокого обучения в научной среде? На высоком уровне можно сформулировать несколько шаблонных способов, с помощью которых глубокое обучение можно использовать в следующих задачах:
С помощью упомянутых шаблонов приложений с применением глубокого обучения мы рассмотрим рабочий процесс проектирования системы глубокого обучения от начала до конца. На Рисунке 1 можно увидеть, как выглядит типичный workflow (рабочего процесса) глубокого обучения.
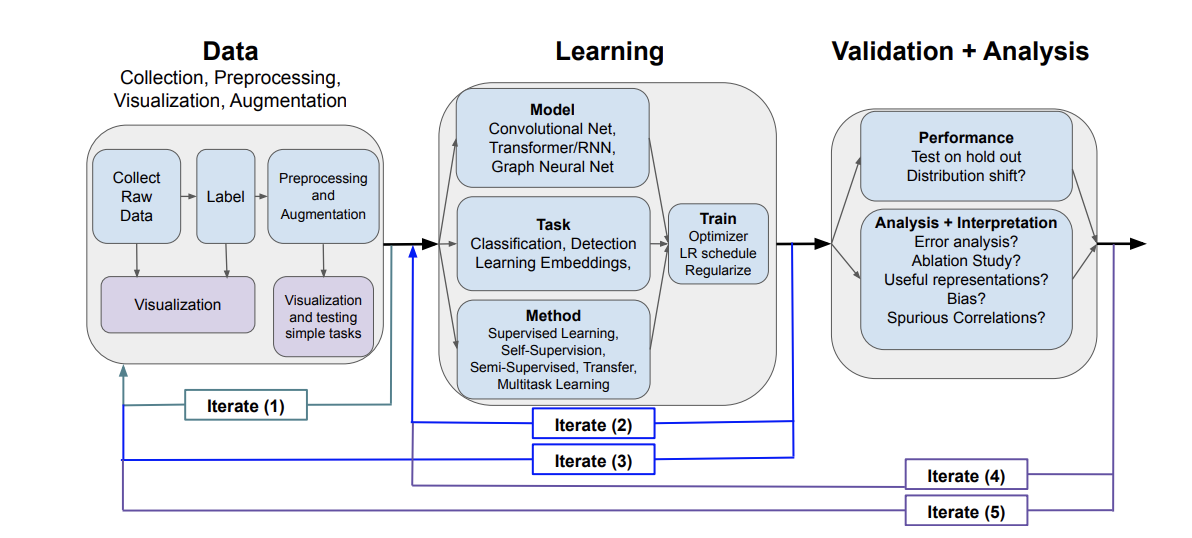
Рисунок 1: Схема типичного рабочего процесса глубокого обучения.
Типичный процесс разработки приложений с глубоким обучением можно рассматривать как состоящий из трех основных этапов: (i) этап обработки данных, (ii) компонент обучения, (iii) валидация и анализ. Каждая из этих стадий включает в себя несколько этапов и методов, связанных с ними, что также показано на рисунке. В данном обзоре мы рассмотрим большинство методов этапа обучения, и несколько техник валидации и анализа данных. Обратите внимание, что в то время, как естественная последовательность включает в себя сначала обработку данных, потом обучение, и в итоге валидацию, стандартный процесс разработки скорее всего приведет к нескольким итерациям этапов, то есть метод или выбор, сделанный на конкретном этапе, будет пересмотрен на основе результатов более позднего этапа.
Выбрав интересующую вас прогностическую проблему, можно задуматься о трех этапах проектирования и использования системы глубокого обучения: (i) этап обработки данных, например, сбор, лейблинг, препроцессинг, визуализация и т.д., (ii) этап обучения, например, выбор модели нейронной сети, определение задач и методов для обучения модели, (iii) этап валидации и анализа, где на основе полученных данных проводится оценка эффективности, а также происходит анализ и интерпретация скрытых представлений и абляционных исследований общих методов.
Естественно, эти три этапа следуют друг за другом. Однако очень часто первая попытка создания системы глубокого обучения проходит неудачно. Чтобы решить возникшие проблемы, важно помнить про итеративный характер процесса проектирования, при котором результаты работы различных этапов служат основой для пересмотра архитектуры и повторного выполнения других этапов.
На Рисунке 1 приведены примеры распространенных итераций с двусторонними соединительными стрелками: (i) стрелка Iterate (1), которая соответствует итерациям в процессе сбора данных, ведь случается так, что после визуализации данных, процесс лейблинга сырых данных может потребовать корректировки, поскольку результат оказался слишком шумным или не захватил нужную цель; (ii) стрелка Iterate (2), которая соответствует итерациям в процессе обучения, например, в случае если другая цель или метод окажутся более подходящими, или если процесс обучения нужно разбить на несколько этапов, проведя сначала self-supervision, а потом обучение с учителем; (iii) стрелка Iterate (3), которая отвечает за изменение шагов обработки данных на основании результатов этапа обучения; (iv) стрелка Iterate (4) отвечает за изменение архитектуры процесса обучения на основании результатов, полученных на этапе валидации, чтобы сократить время обучения или использовать более простую модель; (v) стрелка Iterate (5) – это адаптация шагов обработки данных на основе результатов валидации/анализа, например, когда модель опирается на ложные атрибуты данных, и нужно заново собрать данные, чтобы этого избежать.
В этом разделе мы поговорим о множестве методов, применяемых на этапе обучения, наряду с некоторыми методами, которые характерны для этапов обработки данных и валидации (например, аугментация, интерпретируемость и анализ представлений).
На этапе обучения мы рассматриваем популярные модели, задачи и методы. Под моделями (которые еще иногда называют архитектурой) мы понимаем структуру нейронной сети глубокого обучения – количество слоев, их тип, количество нейронов и т.д. Например, в задаче классификации изображений на вход подаются изображения, а на выход приходит распределение вероятностей по (дискретному) набору различных категорий (или классов). Под методами мы понимаем тип обучения, используемый для обучения системы. Например, обучение с учителем – это популярный процесс обучения, когда нейронная сеть получает на выход размеченные данные, где метки обозначают наблюдения.
В отличие от различных моделей и задач, методы могут быть подмножествами других методов. Например, self-supervision — это метод, при котором нейронная сеть обучается на экземплярах данных и метках, где метки автоматически создаются по экземплярам данных, также этот метод можно отнести к методам обучения с учителем. Звучит немного запутанно! Однако на данном этапе достаточно иметь хотя бы общее понятие о моделях, задачах и методах.
Перед тем, как погрузиться в различные методы глубокого обучения, важно сформулировать проблему и понять, предоставит ли глубокое обучение правильный инструментарий для ее решения. Мощные базовые модели нейронных сетей предлагают множество комплексных функциональных возможностей, таких как сложные преобразования изображений. Однако во многих случаях глубокое обучение может оказаться не лучшим первым шагом или вовсе не подойти для решения проблемы. Ниже мы кратко рассмотрим наиболее распространенные методы машинного обучения, особенно в научных контекстах.
Снижение размерности и кластеризация. В научной среде конечной целью анализа данных является понимание базовых механизмов, которые порождают закономерности в данных. Когда цель стоит так, то снижение размерности и кластеризация – это простые, но крайне эффективные методы по выявлению скрытых свойств данных. Они часто оказываются полезны на шаге исследования и визуализации данных (даже если позже будут применяться более сложные методы).
Снижение размерности. Методы снижения размерности бывают линейными, то есть они основываются на линейных преобразованиях для уменьшения размерности данных, или нелинейными, то есть, уменьшающими размерность с примерным сохранением нелинейной структуры данных. Популярные линейные методы снижения размерности – это Метод Главных Компонент и неотрицательное матричное разложение, а нелинейные — Стохастическое вложение соседей с t-распределением и UMAP. Множество методов уменьшения размерности уже имеют качественные реализации в таких пакетах, как scikit-learn или на github (например, github.com/oreillymedia/t-SNE-tutorial или github.com/lmcinnes/umap).
Кластеризация. Часто используемые в сочетании со снижением размерности методы кластеризации обеспечивают мощный способ выявления сходств и различий в наборе данных. Обычно используются методы, такие как метод k-средних (чаще модифицированный метод k-средних), модель смеси Гауссовых распределений, иерархическая кластеризация и спектральная кластеризация. Как и методы снижения размерности, методы кластеризации имеют хорошие реализации в таких пакетах, как scikit-learn.
Линейная регрессия, логистическая регрессия (и вариации). Возможно, самые фундаментальные методы решения задачи обучения с учителем, такие как классификация и регрессия, линейная и логистическая регрессия и их вариации (например, Lasso и гребневая регрессия) могут быть особенно полезны в случае ограниченности данных и четкого набора (возможно, предварительно обработанных) признаков (например, в виде табличных данных). Эти методы также дают возможность оценить адекватность формулировки проблемы и могут стать хорошей отправной точкой для проверки упрощенной версии решаемой задачи. Благодаря своей простоте, линейная и логистическая регрессии обладают высокой интерпретируемостью и обеспечивают простые способы выполнения атрибуции признаков.
Деревья решений, Случайный Лес и Градиентный бустинг. Другим популярным классом методов являются Деревья решений, Случайный Лес и Градиентный бустинг. Эти методы также могут работать вкупе с задачами регрессии/классификации и хорошо подходят для моделирования нелинейных отношений между входными и выходными данными. Случайный лес, который входит в ансамбль деревьев решений, часто можно предпочесть методам глубокого обучения в условиях, когда данные имеют низкое значение отношения сигнал/шум. Эти методы могут быть менее интерпретируемы, чем линейная/логистическая регрессия, однако в одной из недавних работ мы рассматривали разрабатываемые программные библиотеки, которые решают эту проблему.
Другие методы и ресурсы. Все вышеупомянутые методы, а также многие другие популярные методы, такие как графические модели, гауссовы процессы, байесовская оптимизация, подробно рассматриваются в курсе Машинного Обучения Университета Торонто или CS229 Стенфорда, в подробных статьях на towardsdatascience.com и интерактивных учебниках, таких как d2l.ai/index.html (под названием Dive into Deep Learning) и на github.com/rasbt/python-machine-learning-book2nd-edition.
Какие задачи решает дата-сайнтист? Какие разделы математики и для каких задач требуется знать? Какие требования предъявляются дата-сайнтистам? Какие знания в области математики необходимы, чтобы выделиться из толпы и обеспечить себе карьерный прогресс? Ответы на все эти вопросы и не только можно получить на нашем бесплатном вебинаре, который состоится уже 6 мая. Успейте записаться!

Сегодня мы затронем некоторые размышления о методах глубокого обучения. Начнем с обзора шаблонных способов применения глубокого обучения в научной среде, а затем поговорим про сквозной процесс проектирования, а также вкратце про особенности альтернативных методов машинного обучения, которые могут оказаться более перспективными для решения специфических проблем.
Шаблоны глубокого обучения в научной среде
Как обычно применяются методы глубокого обучения в научной среде? На высоком уровне можно сформулировать несколько шаблонных способов, с помощью которых глубокое обучение можно использовать в следующих задачах:
- Предсказания. Возможно, самый простой способ применения глубокого обучения – это использование его для решения задач прогнозирования (предсказания). Вариант использования для предсказаний очень часто используется в задачах вычислений и машинного обучения. Например, на вход может подаваться изображение биопсии, а модель должна выдать прогноз, говорящий, есть ли на снимке ткани признаки рака или нет. Такой прогностический вариант использования можно использовать в качестве средства получения модели для изучения целевой функции, в нашем случае для сопоставления входных визуальных признаков с результатом «есть рак/нет рака». Использование глубокого обучения – это способ инкапсулировать настройки в том случае, если целевая функция очень сложна и не имеет законченной математической формы или логического набора правил, который описывал бы переход от входного значения к выходному. Например, мы можем использовать модель глубокого обучения (черный ящик) для моделирования сложного процесса (например, моделирование климата), что является нетривиальной задачей для моделирования в целом.
- От предсказаний к пониманию. Одним из фундаментальных различий между научными вопросами и задачами машинного обучения, является то, что в первом случае упор делается на понимание механизмов работы тех или иных процессов. Зачастую одного только точного предсказания оказывается недостаточно. Вместо этого нам нужно интерпретируемое понимание того, какие свойства данных или какой процесс генерации данных привел к наблюдаемому результату или прогнозу. Чтобы получить такое понимание, можно обратиться к методам интерпретации и анализа представлений в глубоком обучении, которые делают акцент на том, как именно нейронная сеть делает тот или иной прогноз. Над обоими инструментами была проделана большая работа для понимания того, какие особенности входных данных являются наиболее критичными для прогнозирования результата. Также особое внимание уделяется методам прямого анализа скрытых представлений моделей нейронных сетей, которые могут помочь выявить критические свойства исходных данных.
- Сложные преобразования входных данных. Во многих областях науки резко возросло количество генерируемых данных, в особенности визуальных (например, флуоресцентная микроскопия, пространственное секвенирование, видеозаписи образцов), в связи с этим возникла острая необходимость в их эффективном анализе и автоматизированной обработке. Методы глубокого обучения, направленные на сложные преобразования входных данных, могут оказаться весьма эффективными для таких случаев как, например, использование модели сегментации для автоматической идентификации ядер на изображениях клеток на основе нейронной сети глубокого обучения или же системы оценки положения для быстрой маркировки поведения мышей на видео для нейробиологического анализа.
Workflow глубокого обучения
С помощью упомянутых шаблонов приложений с применением глубокого обучения мы рассмотрим рабочий процесс проектирования системы глубокого обучения от начала до конца. На Рисунке 1 можно увидеть, как выглядит типичный workflow (рабочего процесса) глубокого обучения.

Рисунок 1: Схема типичного рабочего процесса глубокого обучения.
Типичный процесс разработки приложений с глубоким обучением можно рассматривать как состоящий из трех основных этапов: (i) этап обработки данных, (ii) компонент обучения, (iii) валидация и анализ. Каждая из этих стадий включает в себя несколько этапов и методов, связанных с ними, что также показано на рисунке. В данном обзоре мы рассмотрим большинство методов этапа обучения, и несколько техник валидации и анализа данных. Обратите внимание, что в то время, как естественная последовательность включает в себя сначала обработку данных, потом обучение, и в итоге валидацию, стандартный процесс разработки скорее всего приведет к нескольким итерациям этапов, то есть метод или выбор, сделанный на конкретном этапе, будет пересмотрен на основе результатов более позднего этапа.
Выбрав интересующую вас прогностическую проблему, можно задуматься о трех этапах проектирования и использования системы глубокого обучения: (i) этап обработки данных, например, сбор, лейблинг, препроцессинг, визуализация и т.д., (ii) этап обучения, например, выбор модели нейронной сети, определение задач и методов для обучения модели, (iii) этап валидации и анализа, где на основе полученных данных проводится оценка эффективности, а также происходит анализ и интерпретация скрытых представлений и абляционных исследований общих методов.
Естественно, эти три этапа следуют друг за другом. Однако очень часто первая попытка создания системы глубокого обучения проходит неудачно. Чтобы решить возникшие проблемы, важно помнить про итеративный характер процесса проектирования, при котором результаты работы различных этапов служат основой для пересмотра архитектуры и повторного выполнения других этапов.
На Рисунке 1 приведены примеры распространенных итераций с двусторонними соединительными стрелками: (i) стрелка Iterate (1), которая соответствует итерациям в процессе сбора данных, ведь случается так, что после визуализации данных, процесс лейблинга сырых данных может потребовать корректировки, поскольку результат оказался слишком шумным или не захватил нужную цель; (ii) стрелка Iterate (2), которая соответствует итерациям в процессе обучения, например, в случае если другая цель или метод окажутся более подходящими, или если процесс обучения нужно разбить на несколько этапов, проведя сначала self-supervision, а потом обучение с учителем; (iii) стрелка Iterate (3), которая отвечает за изменение шагов обработки данных на основании результатов этапа обучения; (iv) стрелка Iterate (4) отвечает за изменение архитектуры процесса обучения на основании результатов, полученных на этапе валидации, чтобы сократить время обучения или использовать более простую модель; (v) стрелка Iterate (5) – это адаптация шагов обработки данных на основе результатов валидации/анализа, например, когда модель опирается на ложные атрибуты данных, и нужно заново собрать данные, чтобы этого избежать.
Фокус исследований и номенклатура
В этом разделе мы поговорим о множестве методов, применяемых на этапе обучения, наряду с некоторыми методами, которые характерны для этапов обработки данных и валидации (например, аугментация, интерпретируемость и анализ представлений).
На этапе обучения мы рассматриваем популярные модели, задачи и методы. Под моделями (которые еще иногда называют архитектурой) мы понимаем структуру нейронной сети глубокого обучения – количество слоев, их тип, количество нейронов и т.д. Например, в задаче классификации изображений на вход подаются изображения, а на выход приходит распределение вероятностей по (дискретному) набору различных категорий (или классов). Под методами мы понимаем тип обучения, используемый для обучения системы. Например, обучение с учителем – это популярный процесс обучения, когда нейронная сеть получает на выход размеченные данные, где метки обозначают наблюдения.
В отличие от различных моделей и задач, методы могут быть подмножествами других методов. Например, self-supervision — это метод, при котором нейронная сеть обучается на экземплярах данных и метках, где метки автоматически создаются по экземплярам данных, также этот метод можно отнести к методам обучения с учителем. Звучит немного запутанно! Однако на данном этапе достаточно иметь хотя бы общее понятие о моделях, задачах и методах.
Использовать глубокое обучение или нет?
Перед тем, как погрузиться в различные методы глубокого обучения, важно сформулировать проблему и понять, предоставит ли глубокое обучение правильный инструментарий для ее решения. Мощные базовые модели нейронных сетей предлагают множество комплексных функциональных возможностей, таких как сложные преобразования изображений. Однако во многих случаях глубокое обучение может оказаться не лучшим первым шагом или вовсе не подойти для решения проблемы. Ниже мы кратко рассмотрим наиболее распространенные методы машинного обучения, особенно в научных контекстах.
Снижение размерности и кластеризация. В научной среде конечной целью анализа данных является понимание базовых механизмов, которые порождают закономерности в данных. Когда цель стоит так, то снижение размерности и кластеризация – это простые, но крайне эффективные методы по выявлению скрытых свойств данных. Они часто оказываются полезны на шаге исследования и визуализации данных (даже если позже будут применяться более сложные методы).
Снижение размерности. Методы снижения размерности бывают линейными, то есть они основываются на линейных преобразованиях для уменьшения размерности данных, или нелинейными, то есть, уменьшающими размерность с примерным сохранением нелинейной структуры данных. Популярные линейные методы снижения размерности – это Метод Главных Компонент и неотрицательное матричное разложение, а нелинейные — Стохастическое вложение соседей с t-распределением и UMAP. Множество методов уменьшения размерности уже имеют качественные реализации в таких пакетах, как scikit-learn или на github (например, github.com/oreillymedia/t-SNE-tutorial или github.com/lmcinnes/umap).
Кластеризация. Часто используемые в сочетании со снижением размерности методы кластеризации обеспечивают мощный способ выявления сходств и различий в наборе данных. Обычно используются методы, такие как метод k-средних (чаще модифицированный метод k-средних), модель смеси Гауссовых распределений, иерархическая кластеризация и спектральная кластеризация. Как и методы снижения размерности, методы кластеризации имеют хорошие реализации в таких пакетах, как scikit-learn.
Линейная регрессия, логистическая регрессия (и вариации). Возможно, самые фундаментальные методы решения задачи обучения с учителем, такие как классификация и регрессия, линейная и логистическая регрессия и их вариации (например, Lasso и гребневая регрессия) могут быть особенно полезны в случае ограниченности данных и четкого набора (возможно, предварительно обработанных) признаков (например, в виде табличных данных). Эти методы также дают возможность оценить адекватность формулировки проблемы и могут стать хорошей отправной точкой для проверки упрощенной версии решаемой задачи. Благодаря своей простоте, линейная и логистическая регрессии обладают высокой интерпретируемостью и обеспечивают простые способы выполнения атрибуции признаков.
Деревья решений, Случайный Лес и Градиентный бустинг. Другим популярным классом методов являются Деревья решений, Случайный Лес и Градиентный бустинг. Эти методы также могут работать вкупе с задачами регрессии/классификации и хорошо подходят для моделирования нелинейных отношений между входными и выходными данными. Случайный лес, который входит в ансамбль деревьев решений, часто можно предпочесть методам глубокого обучения в условиях, когда данные имеют низкое значение отношения сигнал/шум. Эти методы могут быть менее интерпретируемы, чем линейная/логистическая регрессия, однако в одной из недавних работ мы рассматривали разрабатываемые программные библиотеки, которые решают эту проблему.
Другие методы и ресурсы. Все вышеупомянутые методы, а также многие другие популярные методы, такие как графические модели, гауссовы процессы, байесовская оптимизация, подробно рассматриваются в курсе Машинного Обучения Университета Торонто или CS229 Стенфорда, в подробных статьях на towardsdatascience.com и интерактивных учебниках, таких как d2l.ai/index.html (под названием Dive into Deep Learning) и на github.com/rasbt/python-machine-learning-book2nd-edition.
Какие задачи решает дата-сайнтист? Какие разделы математики и для каких задач требуется знать? Какие требования предъявляются дата-сайнтистам? Какие знания в области математики необходимы, чтобы выделиться из толпы и обеспечить себе карьерный прогресс? Ответы на все эти вопросы и не только можно получить на нашем бесплатном вебинаре, который состоится уже 6 мая. Успейте записаться!
