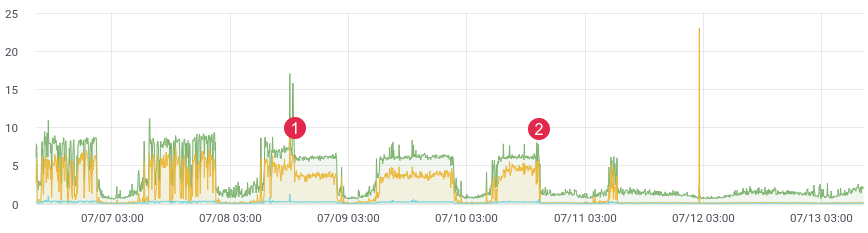
прим. latency/time.
Наверное перед каждым возникает задача профилирования кода в продакшене. С этой задачей хорошо справляется xhprof от Facebook. Вы профилируете, к примеру, 1/1000 запросов и видите картину на текущий момент. После каждого релиза прибегает продакт и говорит «до релиза было лучше и быстрее». Исторических данных у вас нет и доказать вы ничего не можете. А что если бы могли?
Не так давно, переписывали проблемный участок кода и ожидали сильный прирост производительности. Написали юнит-тесты, провели нагрузочное тестирование, но как код поведет себя под живой нагрузкой? Ведь мы знаем, нагрузочное тестирование не всегда отображает реальные данные, а после деплоя необходимо быстро получить обратную связь от вашего кода. Если вы собираете данные, то, после релиза, вам достаточно 10-15 минут чтобы понять обстановку в боевом окружении.
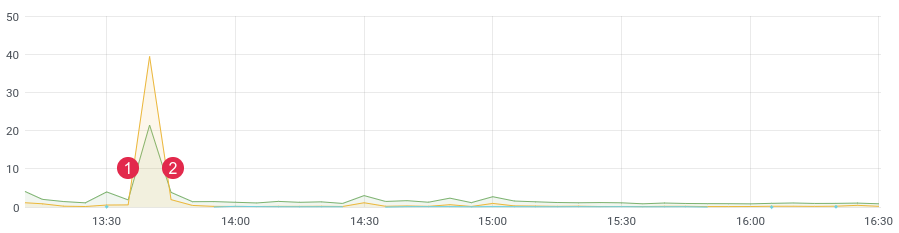
прим. latency/time. (1) деплой, (2) откат
Стек
Для своей задачи мы взяли колоночную базу данных ClickHouse (сокр. кх). Скорость, линейная масштабируемость, сжатие данных и отсутствие deadlock стали главными причинами такого выбора. Сейчас это одна из основных баз в проекте.
В первой версии мы писали сообщения в очередь, а уже консьюмерами записывали в ClickHouse. Задержка достигала 3-4 часа (да, ClickHouse медленный на вставку по одной записи). Время шло и надо было что-то менять. Реагировать на оповещения с такой задержкой не было смысла. Тогда мы написали крон-команду, которая выбирала из очереди необходимое количество сообщений и отправляла пачку в базу, после, помечала их обработанными в очереди. Первые пару месяцев все было хорошо, пока и тут не начались в проблемы. Событий стало слишком много, начали появляться дубли данных в базе, очереди использовались не по-прямому назначению (стали базой данных), а крон-команда перестала справляться с записью в ClickHouse. За это время в проект добавилось ещё пара десятков таблиц, которые необходимо было писать пачками в кх. Скорость обработки упала. Необходимо было максимально простое и быстрое решение. Это подтолкнуло нас к написанию кода с помощью списков на redis. Идея такая: записываем сообщения в конец списка, крон-командой формируем пачку и отправляем её в очередь. Дальше консьюмеры разбирают очередь и записывают пачку сообщений в кх.
Имеем: ClickHouse, Redis и очередь (любую — rabbitmq, kafka, beanstalkd…)
Redis и списки
До определенного времени, Redis использовался как кэш, но всё меняется. База имеет огромный функционал, а для нашей задачи необходимы всего 3 команды: rpush, lrange и ltrim.
С помощью команды rpush будем записывать данные в конец списка. В крон-команде читать данные с помощью lrange и отправлять в очередь, если нам удалось отправить в очередь, то необходимо удалить выбранные данные с помощью ltrim.
От теории — к практике. Создаем простой список.

У нас есть список из трех сообщений, добавим ещё немного…
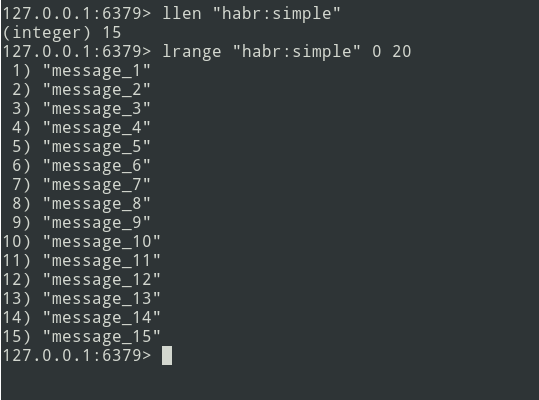
Новые сообщения добавляются в конец списка. С помощью команды lrange выбираем пачку (пусть будет =5 сообщений).
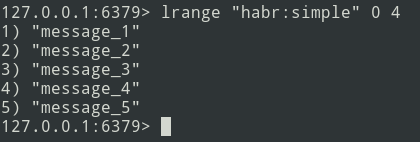
Далее пачку отправляем в очередь. Теперь необходимо удалить эту пачку из Redis, чтобы не отправить её повторно.
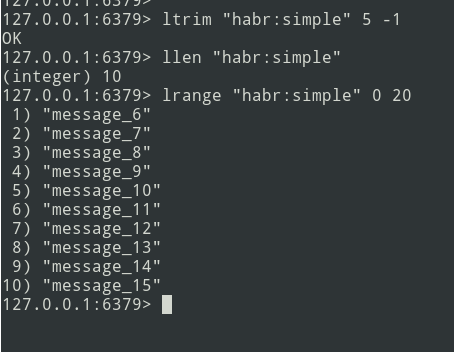
Алгоритм есть, приступим к реализации.
Реализация
Начнем с таблицы ClickHouse. Не стал сильно заморачиваться и определил всё в тип String.
create table profile_logs
(
hostname String, // хост бэкэнда, отправляющего событие
project String, // название проекта
version String, // версия фреймворка
userId Nullable(String),
sessionId Nullable(String),
requestId String, // уникальная строка для всего запроса от клиента
requestIp String, // ip клиента
eventName String, // имя события
target String, // URL
latency Float32, // время выполнения (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);Событие будет таким:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}Структура определена. Чтобы посчитать latency нам нужен временной промежуток. Засекаем с помощью функции microtime:
$beginTime = microtime(true);
// код который необходимо отслеживать
$latency = microtime(true) - $beginTime;Для упрощения реализации, будем использовать фреймворк laravel и библиотеку laravel-entry. Добавим модель (таблица profile_logs):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}Напишем метод tick (я сделал сервис ProfileLogService), который будет записывать сообщения в Redis. Получаем текущее время (наш beginTime) и записываем его в переменную $currentTime:
$currentTime = \microtime(true);Если тик по событию вызван впервые, то записываем его в массив тиков и завершаем метод:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}Если тик вызывается повторно, то мы записываем сообщение в Redis, с помощью метода rpush:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));Переменная $this->ticks не статическая. Необходимо зарегистрировать сервис как singleton.
$this->app->singleton(ProfileLogService::class);Размер пачки ($batchSize) можно сконфигурировать, рекомендуется указывать небольшое значние (например, 10,000 элементов). При возникновении проблем (к примеру, не доступен ClickHouse), очередь начнет уходить в failed, и вам необходимо отлаживать данные.
Напишем крон-команду:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// все данные храним в json, необходимо применить decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// отправляем в очередь для записи в ch
\dispatch(new BulkWriter($bulkData));
// удаляем пачку из redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);Можно сразу записывать данные в ClickHouse, но, проблема кроется в том, что крон работает в однопоточном режиме. Поэтому мы пойдем другим путем — командой сформируем пачки и отправим их в очередь, для последующей многопоточной записи в ClickHouse. Количество консьюмеров можно регулировать — это ускорит отправку сообщений.
Перейдем к написанию консьюмера:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}Итак, формирование пачек, отправка в очередь и консьюмер разработаны — можно приступать к профилированию:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;Если все сделано верно, то данные должны находиться в Redis. Запутим крон-команду и отправим пачки в очередь, а уже консьюмер вставит их в базу.
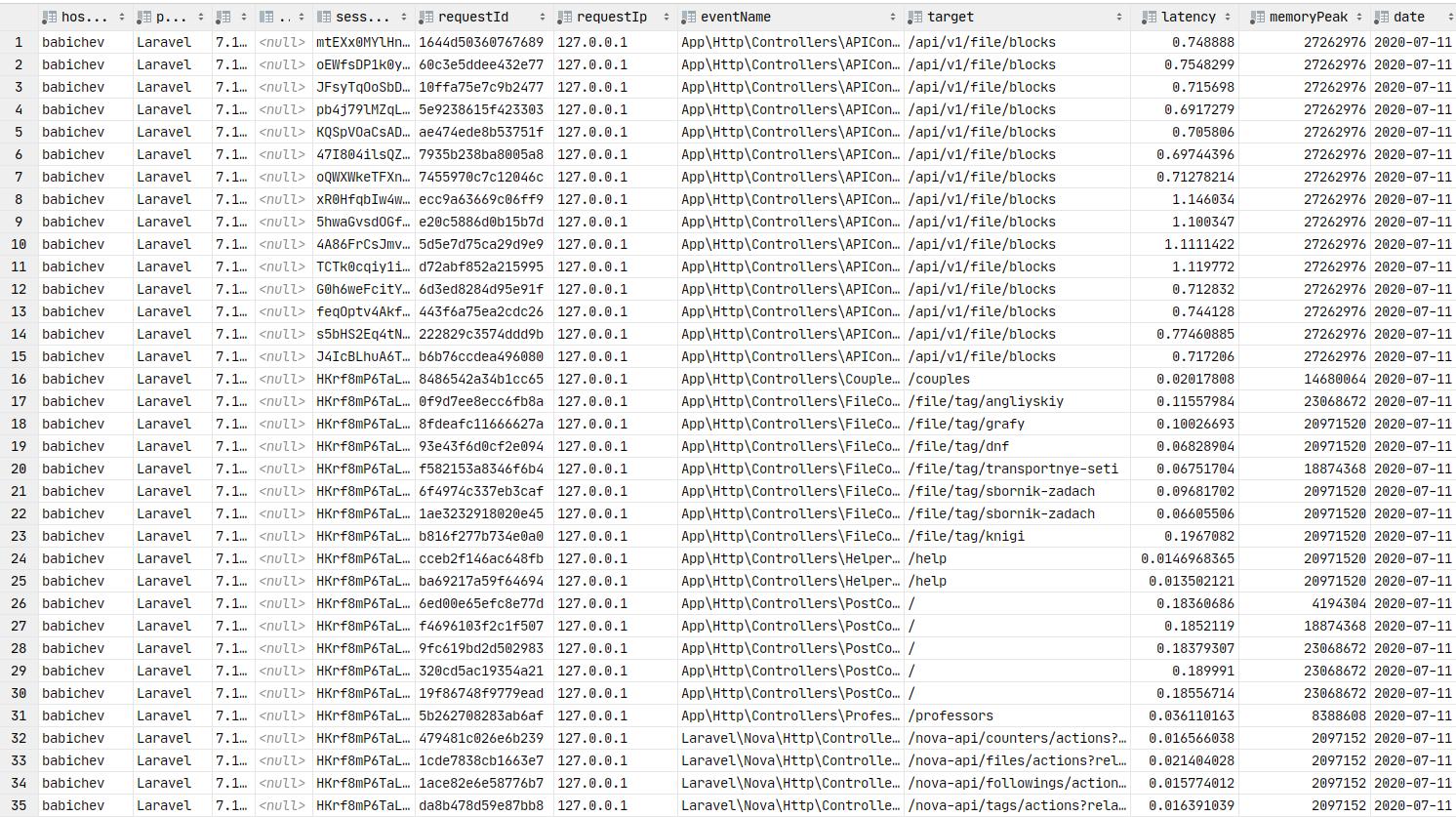
Данные в базе. Можно строить графики.
Grafana
Теперь перейдем к графическому представлению данных, что является ключевым элементом этой статьи. Необходимо установить grafana. Опустим процесс установки для debain-подобных сборок, можно воспользоваться ссылкой на документацию. Обычно, этап установки сводится к apt install grafana.
На ArchLinux установка выглядит следующим образом:
yaourt -S grafana
sudo systemctl start grafanaСервис запустился. URL: http://localhost:3000
Теперь необходимо установить ClickHouse datasource plugin:
sudo grafana-cli plugins install vertamedia-clickhouse-datasourceЕсли установили grafana 7+, то ClickHouse работать не будет. Нужно внести изменения в конфигурацию:
sudo vi /etc/grafana.iniНайдем строку:
;allow_loading_unsigned_plugins =Заменим её на эту:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasourceСохраним и перезапустим сервис:
sudo systemctl restart grafanaГотово. Теперь можем перейти в grafana.
Логин: admin / пароль: admin по умолчанию.

После успешной авторизации, нажмем на шестеренку. В открывшемся popup-окне выберем на Data Sources, добавим соединение с ClickHouse.
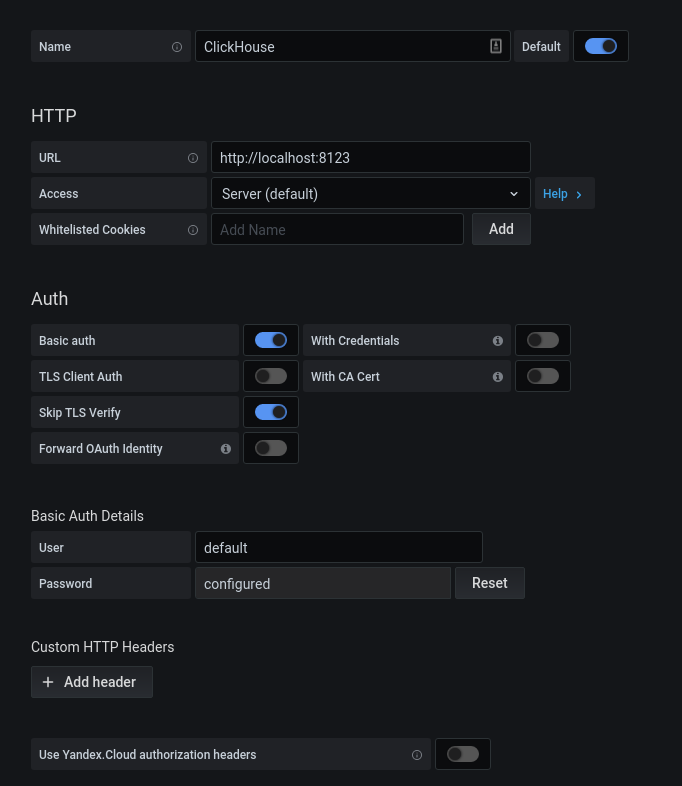
Заполняем конфигурацию кх. Нажимаем на кнопку «Save & Test», получаем сообщение об успешном соединении.
Теперь добавим новый dashboard:
Добавим панель:

Выберем базу и соответствующие колонки для работы с датами:
Перейдем к запросу:
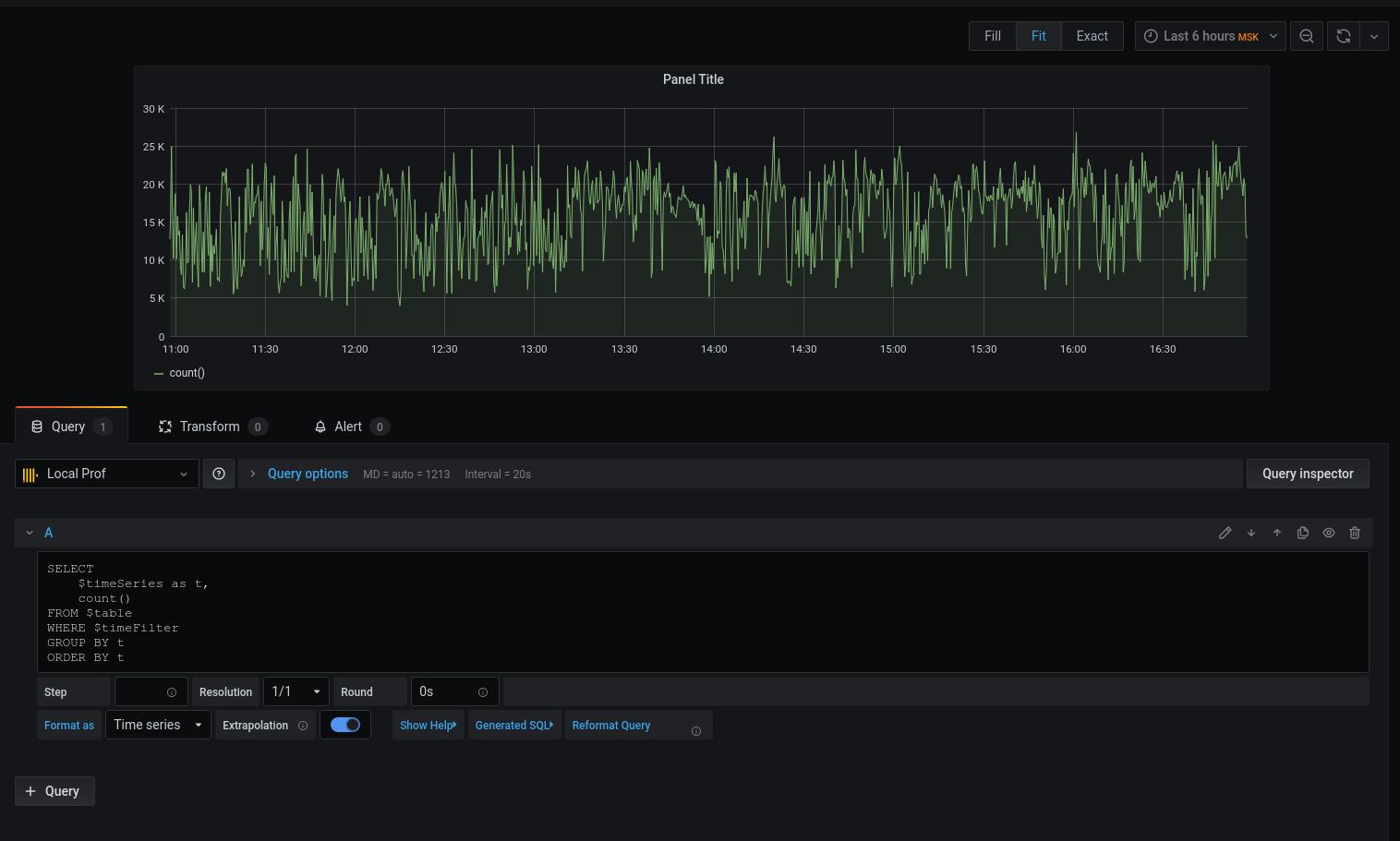
Получили график, но хочется конкретики. Давайте выведем средний latency с округлением даты-с-временем вниз до начала пятиминутного интервала:
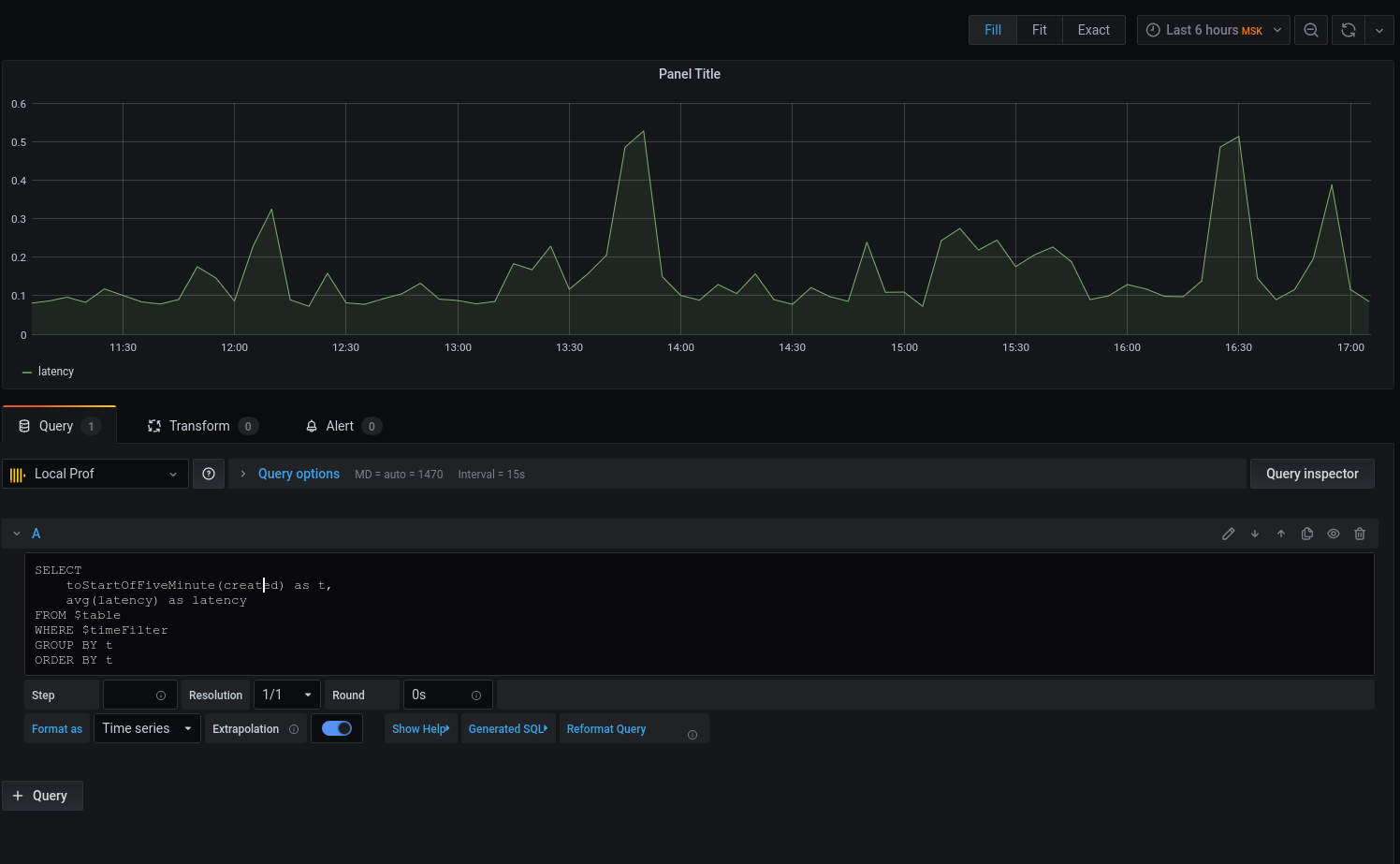
Теперь на графике отображаются выбранные данные, можем ориентироваться на них. Для оповещений настроить триггеры, группировать по события и многое другое.
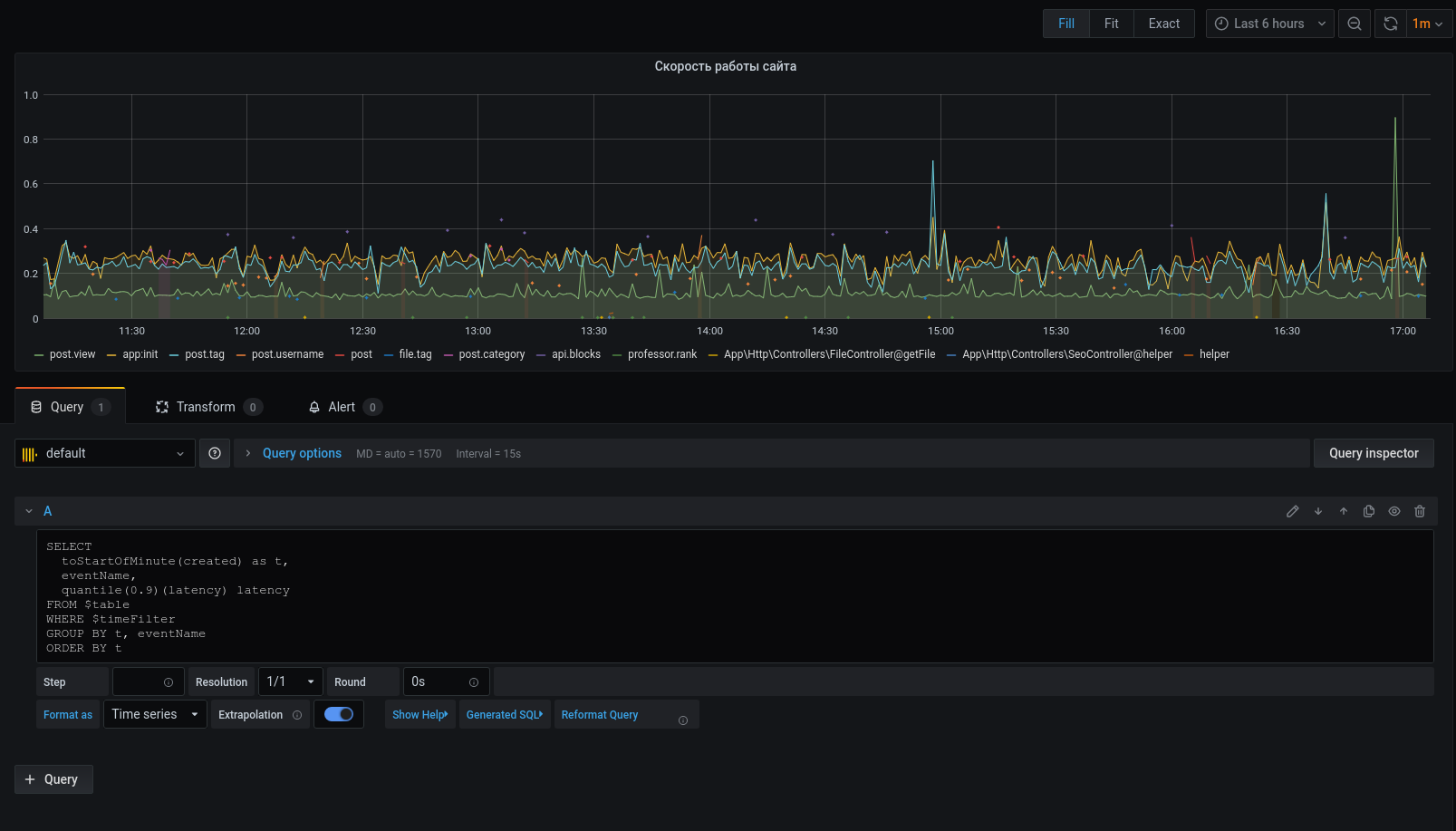
Профилировщик, ни в коем случае, не является заменой инструментам: xhprof (facebook), xhprof (tideways), liveprof от (Badoo). А только дополняет их.
Весь исходный код находится на github — модель профилировщика, сервис, BulkWriteCommand, BulkWriterJob и middleware (1, 2).
Установка пакета:
composer req bavix/laravel-profНастройка соединений (config/database.php), добавляем clickhouse:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
Начало работы:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
// код
app(ProfileLogService::class)->tick('event-name');Для отправки пачки в очередь нужно добавить команду в cron:
* * * * * php /var/www/site.com/artisan entry:bulkТакже необходимо запустить консьюмер:
php artisan queue:work --sleep=3 --tries=3Рекомендуется настроить supervisor. Конфиг (5 консьюмеров):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse нативно умеет тянуть данные из очереди kafka. Спасибо, sdm







