Комментарии 550
0. Интегрированные видяшки на x86 тоже UMA (unified memory architecture).
1. Intel/AMD — тоже SoC. Южные мосты вроде как в прошлом (т.е. в чипе).
2. Почти всё начало статьи подаётся как будто в x86 нет out-of-order-execution.
3. Ничего не сказано про просуперскалярность — тут было бы к месту.
4. Ничего не сказано про branch prediction — тоже было бы к месту.
5. Ощущение, что местами hyper-threading перепутан с out-of-order-execution.
6. Но главное, что добило:
Если мы запишем результат 03 перед тем, как начнет выполняться операция 02, то вторая операция получит неверные входные данныеЕсть такое понятие как 'registry file' — r1 в первых двух командах и r1 в третьей технически будут разными 'r1' (этих «слотов» в современных процессорах как бы не 128-1024, точных цифр не знаю).
По итогу — кроме fixed-instruction-length на декодерах разницы вроде и не видно.
Интегрированные видяшки на x86 тоже UMA (unified memory architecture).
Только AMD и только на консолях (но там тоже свои особенности с разными шинами к памяти и без общих кэшей). В ноутбуках/десктопах GPU просто выделяется отдельный пул памяти, в который CPU копирует данные, чтобы GPU мог с ними работать.
По итогу — кроме fixed-instruction-length на декодерах разницы вроде и не видно.
Кроме того, что из-за этого стало возможно сделать 8 параллельных декодеров и быстро заполнять reorder buffer в 600+ команд. У anandtech есть технический разбор микроархитектуры процессоров Apple.
Вообще эта статья для тех, кто в процессорах до этого ничего не понимал, поэтому вольно обращается с терминами.
Только AMD и только на консоляхВроде не только
docs.microsoft.com/en-us/windows/win32/direct3d12/memory-management-strategies
Технически, по идее, не должно быть препятствий, чтобы писать в ту память хоть прямо из user-space (окромя concurrency с другими приложениями). Ну и если не из user-space, то в любом случае это будет kernel memcpy, а не проброс по PCI-E.
Вроде не только
docs.microsoft.com/en-us/windows/win32/direct3d12/memory-management-strategies
Это как раз для XBox и сделано, где особенная архитектура APU и свои драйвера.
Насколько я знаю, поддержка HSA и HMM в Linux была реализована в каком-то виде под Kaveri, для специализированных задач, но статус в настоящее время непонятен.
До windows-PC и полноценных драйверов вообще дело не дошло.
Интегрированные видяшки на x86 тоже UMA (unified memory architecture).но сама память то вне чипа ) Вообще в M1 LPDDR4X на 4266 МГц, это достаточно быстрая память. Она вшита в чип, что слегка уменьшает задержки. Помимо этого в M1 двухуровневый, а не трехуровневый кеш, но большего размера. Кажется, всё вместе дает прирост.
Интересно тогда, почему nVidia/AMD не встраивают GDDR видеопамять в чип. Нагрев?
Кто бы первым это не начал делать у вас всегда была бы возможность задать вопрос:
а «почему кто-то другой этого не делает? нагрев?»
Кто то же должен быть первым.
Остальные подтянутся. Вангую: через пару лет такие чипы с памятью и у других производителей будут не экзотикой.
Кто бы первым это не начал делать у вас всегда была бы возможность задать вопрос:Почему этот первый не один из двух игроков, а некий пришедший хрен с горы?
а «почему кто-то другой этого не делает? нагрев?»
Кто то же должен быть первым.
Кто бы первым это не начал делать у вас всегда была бы возможность задать вопрос:
а «почему кто-то другой этого не делает? нагрев?»
Кто то же должен быть первым.
Почему этот первый не один из двух игроков, а некий пришедший хрен с горы?
Интерес Apple к ARM древние корни имеет. Компания Advanced RISC Machines (ARM) изначально была основана как совместное предприятие между Acorn Computers, Apple Computer (сегодня — Apple Inc.) и VLSI Technology в 1990 году.
Но в комментариях уже пояснили, что это таки делалось уже. Осталось понять почему не получило особенного развития.
Вопрос то не в этом. Вопрос почему ни один из двух основных игроков рынка этого не делал, а некий второстепенный персонаж взял и сделал.
Потому что нужен спрос.
Apple может заменять процессор. И сохранить спрос.
Поменяв ПО. Это уже было в истории Apple. У них были платформы различные — Motorola, PowerPC, Intel
Остальные «ведущие игроки» — просто железячники. На рынке ПО они не могут сделать такие вещи как «поменять ОС под новую систему команд».
Прецеденты были — Intel уже пролетала с Itanium.
Такая мысль?
Основные игроки не увидели спроса на такое, и не смогли его создать или решили не заморачиваться такой суетой.
Такая мысль?
Они не могут создать спрос. Они железячники.
А с MS видимо не договорились тогда.
MS вовсю пилит в Windows для ARM инструментарий эмуляции x86 для него для переходного периода — только вот прямо сейчас.
Ноутбуки на ARM уже много лет как выпускались. Только они никому не были нужны. Софта-то не было. Как оказалось, массовому рынку недостаточно Linux, который нужно доводить руками. Нужны системы «сел и работай». А их только 2 — MacOS и Windows. Производство ARM ноутбуков тех — и заглохло.
Вопрос почему ни один из двух основных игроков рынка этого не делал, а некий второстепенный персонаж взял и сделал.
Потому что оба "основных игрока" связаны по рукам и ногам
1) обратной совместимостью
2) многолетним участием в производственных цепочках десятков, если не сотен производителей конечных устройств
3) наличием второго игрока, продукцией которого можно вообще без проблем заменить твою продукцию в случае, если у твоей появляются проблемы с первыми двумя пунктами.
Если бы условный интел заявил, что очередное поколение процессоров будет с памятью на SoC, которую нельзя проапгрейдить, то единственное, чего он достиг бы — это практически полной потери рынка энтузиастов и прочих само-сборщиков (которые, так уж повелось, любят периодически апгрейдиться и иметь возможность это сделать). А так же огромными потерями на OEM рынке. Т.к. хоть условному производителю ноутбуков невозможность апгрейда и не настолько критична (подавляюще большинство ноутов и так с распаянной на материнке памятью), но критична логистика и всякие цепочки поставок. Если с классической схемой он мог из абсолютно одинаковых компонентов собрать 4 разных конфигурации ноута (CPU X 4GB RAM, CPU X 8GB RAM, CPU X 12GB RAM, CPU X 16GB RAM), то с "новыми улучшенными" SoC это будет уже 4 разных компонента. И проблемы с доступностью любого из них автоматически будут означать проблемы с производством и доступностью соотв. ноутбуков. А если сюда еще добавить разные модели CPU, то и вовсе получаем квадратичный рост зависимостей.
Короче говоря, Apple может себе это позволить благодаря вертикальной интеграции и отсутствию конкуренции внутри платформы. Intel и AMD — не могут, т.к. у них такой роскоши нет.
Речь же о ситуации «а еще у нас теперь будут процессоры с памятью на SoC».
Если процы получаются сказочные то на них постепенно поползут все.
А корпоративному рынку всё равно потребуется возможность создания нестандартных конфигураций, но если сейчас это CPU + RAM, то как будет потом? SoC не будут выпускать для корпоративного рынка? Или будет что-то вроде SoC(CPU+16 GB RAM) + RAM снаружи?
В таком случае эти "а еще" будут просто никому не нужны по ровно тем-же причинам. "Сказочность" памяти на SoC не решает ни одну из этих проблем. И сам по себе факт переноса памяти на SoC не делает процессор достаточно "сказочным", чтобы эти проблемы перевесить.
Попробуйте ещё раз перечитать вот этот мой коммент https://m.habr.com/ru/post/538812/comments/#comment_22586742
Эппл не решила эти проблемы, у неё их и не было.
Хоры оды поют M1 в целом, а не памяти на SoC. Помимо памяти на SoC в нем есть ещё огромная куча отличий от процессоров «основных игроков». И часть этих отличий нельзя (или по крайней мере очень трудно) перенести на x86 by design.
Эти игроки в принципе забили на ARM кусок рынка? В этом мысль?
Про память это для простоты. Изначально вопрос был почему основные два игрока рынка не сделали то что сделала сейчас Эпл.
Эти игроки в принципе забили на ARM кусок рынка? В этом мысль?
Потому что этого рынка не было.
Его только-только создает Apple. Как производитель полного цикла — процессоры, компьютеры, софт — она может это сделать.
Основные два игрока — это железячники, обслуживающие имеющиеся на рынке потребности.
Чтобы AMD/Intel стали делать под ARM нужно было чтобы сподобилась сделать полноценное решение под ARM Microsoft. А чтобы Microsoft начала делать это решение — нужно чтобы AMD/Intel сделали. Заколдованный круг.
И только производитель полного цикла не имеет тут заколдованного круга.
Чтобы AMD/Intel стали делать под ARM нужно было чтобы сподобилась сделать полноценное решение под ARM Microsoft. А чтобы Microsoft начала делать это решение — нужно чтобы AMD/Intel сделали.
Но Microsoft сделала своё решение уже 3 года назад...
Потому что этого рынка не было.qualcomm 8cx?
Потому что этого рынка не было.
qualcomm 8cx?
Назовите кто из производителей железа его покупал? Какие модели ноутбуков с этим процессором.
Рынок это наличие и спроса тоже.
А не наличие лишь только предложения.
en.wikipedia.org/wiki/Devices_using_Qualcomm_Snapdragon_processors#Snapdragon_835,_850,_7c,_8c,_8cx_and_8cx_Gen_2
А где это можно купить?
Все упомянутые ноутбуки в продаже видны только в версиях с классически процессорами.
Samsung Galaxy Book S
Lenovo Flex 5G
Surface Pro X
Более новое или только анонсировано или отменено в связи с отсутствием спроса.
Назовите кто из производителей железа его покупал? Какие модели ноутбуков с этим процессором.это же легко гуглится… Да, моделей не так много, это ведь ARM ноуты, считай тестовая продукция. Есть еще microsoft SQ1 на базе 8cx, ARM чип который идет в microsoft surface ноуты. Первые ARM MS surface кстати очень давно появились, вместе с релизом win8.
Я не спорю, что без нормальной софтовой поддержки от MS windows продукты на основе ARM процов достаточно нишевые и мало кому нужные. Я лишь отрицаю утверждение про «рынка не было».
это же легко гуглится… Да, моделей не так много, это ведь ARM ноуты, считай тестовая продукция. Есть еще microsoft SQ1 на базе 8cx, ARM чип который идет в microsoft surface ноуты. Первые ARM MS surface кстати очень давно появились, вместе с релизом win8.
Именно. Аналоги новых ноутов Apple тех что на M1 у других производителей — фактически тестовые.
И да, на ARM ноуты выпускаются давно.
Но старые модели смысла не имели, ибо были тормозными, а жрали столько же сколько классические x86.
На ARM свежих, тех, что достаточно быстры для работы — в свободной продаже есть только устройства производства Apple.
Все прочие — заявлены на сайтах производителей. Но вот в наличии их нигде нет.
Буду признателен, если вы покажите, где их реально можно купить.
Мне кажется что мы по разному понимаем потребителя продукции производителя процессоров.
По примеру М1 мы видим, что чип очень большой, без возможности масштабирования по ядрам и памяти, это цена полной интеграции. Причём если для масштабирования в райзенах надо просто добавить или улучшить чиплет, добавить планку памяти, то тут задача на порядок сложнее.
Так же при сравнениях надо учитывать, что у М1 уже 5 нм процесс, что даёт им преимущество. Посмотрим, что будет, когда нанометры будут одинаковые.
Они не забили. Не было никакого ARM рынка. Его нужно было создать. Эппл создала.
Им это было сделать на порядок проще, потому что они контролируют свою экосистему. Им достаточно сказать "ребят, через 2 года интел не нужон" и все эта экосистема дружно перейдет на ARM. Начиная с самих процессоров, продолжая прочим железом их компьютеров, поддержкой ОС, библиотек и фреймворков. И заканчивая прикладным софтом сторонних производителей, у которых во-первых есть все инструменты для поддержки ARM, а во-вторых — банально нет выбора, т.к. через 2 года их приложения превратятся в тыкву, если не обновятся.
Intel и AMD чтобы провернуть подобный трюк нужно было бы договориться с кучей производителей промежуточных звеньев на пути от CPU к потребителю. Если любое из этих звеньев откажется участвовать в затее или не справится со своей задачей — конечный потребитель продолжит пользоваться старыми привычными x86 продуктами, в которых все работает.
Посмотрите на скорость отказа от WinXP и Win7. А это ведь намного менее радикальное изменение, чем переход на абсолютно новую архитектуру CPU. Экосистема PC очень отличается от Mac.
Поэтому переход PC мира (с Intel и AMD включительно) на ARM если и произойдет, то только в случае огромного пинка в виде намного более производительных ARM маков (и M1 — это еще недостаточно сильный пинок). И даже в таком случае этот переход для PC будет значительно труднее, болезненнее и дольше, чем для маков.
Речь о том почему основные игроки не сделали ранее свой вариант того что сделала Эпл. На любой продукт есть свой покупатель. Если продукт на голову выше того что вокруг (даже в какой-то узкой области) заинтересованные люди быстро придумают как использовать себе на пользу. Вплоть до сборки своей оси.
Возникает предположение что либо выгода не так сильна как заявляют митингующие, либо есть какие-то нюансы (например масштабирование или тупиковость идеи в проекции будущего), ну или игроки мощно протупили.
Вплоть до сборки своей оси.Напомните, сколько сейчас процентов линуксоидов(не тех кто установил убунту по картинкам из интернета) и прочих систем? При этом способных портировать софт и переписать компилятор?
Когда была необходимость портировали. Без особенных эмоций, какая разница программисту что писать в рабочее время?
Про компиляторы ничего не скажу, последний раз доводилось писать оное в качестве курсовой достаточно много лет назад. А по роду деятельности не сталкиваюсь.
На любой продукт есть свой покупатель
Не на любой, а только на законченный. В случае десктопа законченный продукт помимо процессора включает в себя еще кучу всего. В экосистеме мака эту кучу всего эппл может просто взять и сделать. В экосистеме pc нужно договориться с кучей производителей и убедить каждого из них рискнуть и вложиться в поддержку новой архитектуры.
Если продукт на голову выше того что вокруг (даже в какой-то узкой области)
… то во всяких узких областях ARM уже давным давно активно используется. Просто десктоп в эти узкие области не входит.
либо есть какие-то нюансы
Да, есть. Я про них многократно написал уже. Нюанс в необходимости привлечения множества независимых производителей и их слаженной работы в случае с PC и в отсутствии такой необходимости в случае с mac.
Не на любой, а только на законченный. В случае десктопа законченный продукт помимо процессора включает в себя еще кучу всего.
Вы опять за свое. Причем тут десктоп? Речь за процессоры.
Да, есть. Я про них многократно написал уже. Нюанс в необходимости привлечения множества независимых производителей и их слаженной работы в случае с PC и в отсутствии такой необходимости в случае с mac.
Производителей чего? Цпу дали, референсный чипсет. Что еще нужно? Сейчас как-то иначе разве?
Причем тут десктоп? Речь за процессоры.
Так ARM процессоры давным-давно используются в своих нишах. Десктоп в эти ниши не входил. Благодаря Apple теперь вошел. Вероятно скоро и pc мир подтянется. Вон MS активизировались, стали активнее допиливать трансляцию x64.
Я перестаю понимать, в чем ваш вопрос. Почему Intel и AMD не делают ARM процессоры? Потому что целятся в массовый рынок, а не в нишевый, где каждый процессор в силу малого тиража будет стоить как крыло от самолета.
Производителей чего? Цпу дали, референсный чипсет. Что еще нужно? Сейчас как-то иначе разве?
И что дальше? Зачем мне инвестировать кучу бабла в производство, скажем, материнок под этот процессор, для которого нет софта, если я могу потратить эти деньги на приклеивание еще 2 RGB лампочек к материнке, на которую точно будет огромный спрос?
Потому что целятся в массовый рынок, а не в нишевый, где каждый процессор в силу малого тиража будет стоить как крыло от самолета.
В чем и был вопрос. Они забили на этот сегмент рынка. Теперь понятно.
И что дальше? Зачем мне инвестировать кучу бабла в производство, скажем, материнок под этот процессор, для которого нет софта
Почему нет софта если это ARM? Использование фич нового процессора потребует не просто обновленного компилятора а новых алгоритмов?
Использование фич нового процессора потребует не просто обновленного компилятора а новых алгоритмов?Как минимум тут нужно наличие оптимизирующего компилятора и отсутствие ассемблерных вставок.
Почему нет софта если это ARM? Использование фич нового процессора потребует не просто обновленного компилятора а новых алгоритмов?
Ну возьмите какой-нибудь девайс на Windows 10 ARM и посмотрите какое там обилие софта.
Даже если для сборки ARM версии достаточно поменять один флаг компиляции (а это далеко не всегда так просто) — нужно чтобы кто-то это сделал. И потом эту версию тестировал и поддерживал. А это никому не нужно из-за размера ниши ARM десктопов.
Я может чего не понимаю и этот процессор от Эпл имеет смысл исключительно в контексте десктопа?
Тогда я вообще не вижу смысла во всем этом диалоге.
facepalm.jpg
То есть весь сыр-бор из-за непонимания, что процессор, созданный исключительно для десктопа (при чем мобильного) имеет смысл исключительно в контексте десктопа?
Да, в таком случае диалог определенно бессмысленный. Хотя я рад, что вы в итоге все таки пришли к этому нетривиальному умозаключению.
Интелу и АМД достаточно сделать как Apple и заявить "через N лет х86 — всё, будем производить только ARM" не оставив выбора, и сразу и производители материнок подтянутся (ибо раз х86 процев не будет — под них уже не по-клепаешь) и производители софта (ибо иначе их софт будет лишь на компах N-летней давности).
Единственная сложность — это то что intel и amd должны провернуть это относительно синхронно.
Единственная сложность — это то что intel и amd должны провернуть это относительно синхронно.
Какая несущественная мелочь. Всего-то убедить конкурента не захватывать рынок, который ты ему добровольно отдал "через N лет", а вместо этого потратить кучу ресурсов на рискованный переход на новую архитектуру вместе с тобой.
Даже если на секундочку подумать, что Intel и AMD не против… То тут есть пара нюансов:
- у интел-амд дохрена патентов на х86 платформе и они принадлежат им
- в арме у них патентов или нет, или практически нет (понятно, что некоторые удастся переиспользовать — но далеко не все).
Т.е. вместо взаимного гашения вопроса об лицензионных отчислениях они будут вынуждены добавлять лицензионные отчисления… и удорожать процессоры вот на ровном месте. Далее, сразу выдать "прям топчик" на новой архитектуре у них не факт, что выйдет — а это репутационные риски. Ну и для красоты добавим, что им ещё сами процессоры с нуля придётся делать. В общем — грандиозные капитало- и репутационные вложения с непонятным итогом… Ибо вероятность выжить ниже, чем при сохранении собственной ниши.
Есть старая линейка. А появляется дополнительно новая с килер фичей.
Ну а программы портируют разумеется потребители, был бы выхлоп.
Какое ПО нужно тому же хостеру или производителю систем видеонаблюдения, или систем хранения данных и тд? В чем там особенность сборки под новую целевую платформу?
Какое ПО нужно тому же хостеруЯ не смотрел исходные коды, но вдруг условный Nginx использует ассемблерные вставки для особо критичных мест? Их портировать не очень приятно будет.
или производителю систем видеонаблюденияа вот в видеокодеках повсеместно используют ассемблер, который точно придётся переписывать (ну или в железо выносить).
Я не смотрел исходные коды, но вдруг условный Nginx использует ассемблерные вставки для особо критичных мест? Их портировать не очень приятно будет.
Разумеется. Но портирование одного сервиса раскатывается на миллионы клиентов. И уже появляется какой-то экономический выхлоп. Понятно что если каждому клиенту портировать индивидуальный софт то можно сразу застрелиться, с ногами в тазу с бетоном на краю плотины.
а вот в видеокодеках повсеместно используют ассемблер, который точно придётся переписывать (ну или в железо выносить).
А какие процессоры стоят сейчас зачастую во всех этих системах? ARM и стоит. Вопрос насколько обсуждаемый кентавр совместим с ними. И стоит ли адаптация суеты.
Через год они и вовсе могу решить перейти на какую-нибудь собственную iArch — могут позволить в рамках 100% своей экосистемы.
Справедливости ради ARM и так есть тот самый собственный iArch. Apple — один из родоначальников ARM и один из основных владельцев.
Откровенно говоря не вижу такой необходимости.
Есть старая линейка. А появляется дополнительно новая с килер фичей.
Ну а программы портируют разумеется потребители, был бы выхлоп.
Нужна критическая масса владельцев девайсов, чтобы программы начали портировать.
Нужна критическая масса программ, чтобы девайсы начали покупать.
Замкнутый круг.
Кроме Apple:
Apple, имея полный цикл производства и железа и софта и обладая внушительной властью над сторонними разработчиками — может менять платформу и уже делала это Motorola => PowerPC => Intel.
Фирма Apple может сказать и рынку (на котором она по сути монополист) и разработчикам — «или делай что я сказала, или иди в нецензурную сторону».
Кроме процессоров фирма Apple в приказном порядке это делала для многого. Хоть судьбу OpenGL и Vulkan посмотрите.
Потому что конкурентов в своей ниши у Apple нет.
И потому что Apple производит полный цикл — процессор, девайсы, софт, а также диктует свою политику разработчикам.
Ну а теперь представьте, что будет, когда тоже самое скажет какая то из фирм, поддерживающи на x86. У них у всех есть конкуренты. И клиенты уйдут к конкурентам.
Есть старая линейка. А появляется дополнительно новая с килер фичей.
В том то и дело, что киллер-фичи у M1 нет.
Это довольно хороший продукт. Но не более.
Однако у потребителей, предпочитающих Apple — нет выбора. Это не киллер-фича, это просто принуждение.
В принципе, все согласны, поскольку их пересаживают не на говно, а на процессор сопоставимый с AMD/Intel.
Что до opengl/vulkan — без их поддержки в консолях теряется весь смысл пытаться тянуть универсальный графический api.
Я не пойму почему вы упорно говорите о переходе PC мира на ARM?
Речь о том почему основные игроки не сделали ранее свой вариант того что сделала Эпл. На любой продукт есть свой покупатель. Если продукт на голову выше того что вокруг (даже в какой-то узкой области) заинтересованные люди быстро придумают как использовать себе на пользу. Вплоть до сборки своей оси.
Разработка современного процессора чрезвычайно дорогостоящая.
Ради 3,14 энтузиастов это бессмысленно.
Если только энтузиасты не согласятся покупать процессор по цене самолета. А на это согласится еще меньше небольшого числа энтузиастов.
Если продукт на голову выше того что вокруг (даже в какой-то узкой области) заинтересованные люди быстро придумают как использовать себе на пользу. Вплоть до сборки своей оси.
То есть вы предлагаете произвести миллионы процессоров (а иначе это экономически не рентабельно).
Выпустить на их базе миллионы ноутбуков.
Выложить эти миллионы ноутбуки без софта на полки магазинов.
Как вы думаете, сколько экземляров из этих миллионов без ОС будут проданы? 200 шт.?
Кто будет оплачивать весь этот банкет, все те годы, пока энтузиасты не запилят свою ОС?
Магазины? Производители процессоров или производители ноутбуков?
Речь то не о копеечных убытка. А о миллиардах.
Покупатель есть не на любой продукт, а на завершенный до логического конца продукт.
То есть без желания MS подключиться к проекту или кого-то тоже мощного в софтостроении — продукта не выйдет.
Условно говоря:
AMD + Asus + MS = должны договориться, чтобы сделать новый продукт.
Причем для всех трех компаний это миллиардные риски.
Зачем они им?
.jpg){kind=link}
Дело в том, что технологии, по которой делается память, не очень сочетается с той, по которой делается числодробилка. С флешем тоже самое, как и с DAC/ADC. Но если интерконект сделать на кремнии и с минимальными длинами — то получаются довольно вкусные и шустрые решения.
Дорого. В проф сегменте лет 5 минимум HBM для этого используется.
В первую очередь цена - т.к. пластина больших размеров,большое количество транзисторов, больше отбраковка, меньше годных чипов.
Как более дешевую альтернативу большим монолитным чипам AMD в 2015 выпустила графический процессор Fuji ( https://www.ixbt.com/video3/fiji-part1.shtml ) с HBM памятью ( https://www.ixbt.com/video3/amd-hbm.shtml ) которые находится на одной подложке
")
")
Она вшита в чип, что слегка уменьшает задержки
Там используется обычная PoP память, как в любом телефоне. Разве что только для лучшего охлаждения смещена в сторону.
Какие задержки это уменьшает и на сколько?
Без цифр ваше утверждение является пустым сотрясанием воздуха.
Помимо этого в M1 двухуровневый, а не трехуровневый кеш, но большего размера.
3-х уровневый.
3-й уровень это SLC кэш размером 16МБ, для связи блоков внутри чипа. Правда до сих пор точно не понятно как ядро с ним работает.
Какие задержки это уменьшает и на сколько?да уже то, что память физически ближе к процу на 10+ см, само по себе уменьшает задержки на несколько тактов.
Без цифр ваше утверждение является пустым сотрясанием воздуха.
3-х уровневый.«As for SLC cache, that’s for flash, not for the memory subsystem.»
3-й уровень это SLC кэш размером 16МБ, для связи блоков внутри чипа. Правда до сих пор точно не понятно как ядро с ним работает.
да уже то, что память физически ближе к процу на 10+ см, само по себе уменьшает задержки на несколько тактов.
Чистая спекуляция. Какие конкретно задержки это уменьшает?
Насколько эти несколько тактов значительны на фоне общей латентности памяти?
Если вы встали с утра с кровати, эти несколько сантиметров вас конечно приблизят к поверхности Марса (или отдалят), но не сильно.
Ладно, я понимаю что из вас клещами нужно цифры вытягивать.
У 9900K латентность DDR4 памяти 70 нс.
У Apple M1 с LPDDR4X — 96 нс.
Так что там уменьшается? Кроме расстояния есть и другие, более важные параметры.
«As for SLC cache, that’s for flash, not for the memory subsystem.»
Ну это совсем ржака. Человек просто перепутал SLC (Single Level Cell) область в SSD и SLC (System Level Cache) в SoC.
Apple говорит о System Cache, но ARM называет его SLC.
Вот, например, документации к шине Corelinк:
developer.arm.com/documentation/100180/0103/introduction/product-documentation-and-design-flow
«Configurables include size and device placement and an optional System Level Cache (SLC).»
developer.arm.com/documentation/100180/0103/slc-memory-system/about-the-slc-memory-system
Я конечно криво написал про System Level Cache — cache, но Андрей из Анандтек так же облажался :) «Такова селяви»(с)
Собственно там не только кэш, но и свитч и coherence point. Всё в одном.
Вот патент Apple на системный кэш:
patents.google.com/patent/US20140075125
У 9900K латентность DDR4 памяти 70 нс.вы сравнили in-page latency у 9900K против full random latency у M1. А на графике ниже у 9900k в тесте full random latency порядка 210 нс.
У Apple M1 с LPDDR4X — 96 нс.
Про кеш теперь еще более непонятно становится. Я в курсе что там L2 уже общий между ядрами, и не понимаю зачем тогда SLC и какую роль он играет.
random latency порядка 210 нс.
Вообще-то там такты (clocks).
210 тактов на 4ГГц это около 52нс. Т.е. даже меньше.
Я хотел использовать другой график (с нс шкалой), но там не было подписано значение.
Согласно 7-cpu www.7-cpu.com/cpu/Skylake.html
«RAM Latency = 42 cycles + 51 ns (i7-6700 Skylake)»
На частоте 4ГГц, 42 такта это 10,5 нс.
Итого получаем 63,5нс для DDR4-2400 памяти.
ЕМНИП, другие измерения что я встречал, доходили до 67-70нс.
Я в курсе что там L2 уже общий между ядрами
Между процессорными ядрами. В каждом кластере L2 свой.
У больших ядер 12МБ, у маленьких 4МБ.
и не понимаю зачем тогда SLC и какую роль он играет.
Связь всех основных блоков чипа — CPU, GPU, NPU, ISP и других.
Для эффективного обмена данными и кэш когерентности.
1. Intel/AMD — тоже SoC. Южные мосты вроде как в прошлом (т.е. в чипе).
Ммм… а не северный?
То, что я, выращивая картошку на грядке, не успеваю обеспечить ею своих соседей, не означает, что моя картошка хороша или что я как производитель круче кого-то, это означает лишь то, что я произвожу меньше, чем тем, кто желает, надо.
А ещё именно AMD-компоненты используются в игровых консолях.
Вот, почему не Intel то? Вероятно потому и.
И, пришедшая к рулю АМД, Лиза Су уже имела контакты в Сони (подробнее в тематичном ролике Pro HiTech).
Так что дело не только в том что «все в одном», т.к история показывает что и мешать вполне норм:
— xbox original — Pentium III + NVIDIA
— xbox 360 — PowerPC + ATI (тогда еще независимая)
— playstation 3 — Cell + NVIDIA
Интел -5% за год, АМД +100%Это только отражает рыночные настроения аналитиков и инвесторов. Завтра происходит землетрясение, и фабрика AMD разрушена — цена упадёт. Потеряно ли лидерство? Не факт. Никто не будет разбираться, что это была лишь запасная фабрика, цена упадёт. Лишь потом начнет отрастать, когда все разберутся.
Интел больше не технологический лидерВчера Intel начал набирать своих олдов — график сильно вырастет, хотя они (олды) ещё ничего не сделали и не произвели.
Технически, М1 — это весь компьютер на одном чипе. Он содержит CPU, графический процессор GPU, память, контроллеры входа/выхода и множество других вещей, делающих компьютер компьютером. Это мы называем системой на чипе (system on the chip, SoC).Процессоры Intel и AMD как бы тоже содержат все это. Только их чего-то не называют SoC…
Памяти то нет.
www.youtube.com/watch?v=dI1tGziCi54
www.youtube.com/watch?v=4efF1KHIbZw
там там сплошь замеры транслированного софта
Подождите, эпл же сказала что розетта всех спасет, получается соврали что ли?
Ну хорошо, ладно, розетта жрет производительность, но у вас же супер М1 который на завтрак ксеоны и эпики жрет, тож не спасает? Делааа…
«Почему все обзорщики из США используют одни и те же единственные оптимизированные под ARM бенчмарки?»
Если между несколькими обзорами прослеживается общая линия то невольно задумаешься, а не проплатили ли, но опять таки, все ж без наездов, просто наблюдения.
Вообще больше хотелось бы услышать чтонибудь по поводу всех этих глюков и ошибок снятых на видео. Или про показательный момент когда клонированная сиситема на супер М1 залогинилась ощутимо медленнее чем двухлетний интел… Про ворд который грузился пол минуты примерно. Очень знаете ли интересно послушать.
Подождите, эпл же сказала что розетта всех спасет, получается соврали что ли?А давайте тогда запускать и там и там ARM код? Спойлер: M1 выполняет x86 код через rosetta2 куда быстрее, чем x86 процы выполняют ARM код.
Ну хорошо, ладно, розетта жрет производительность, но у вас же супер М1 который на завтрак ксеоны и эпики жрет, тож не спасает? Делааа…
Если между несколькими обзорами прослеживается общая линия то невольно задумаешься, а не проплатили ли, но опять таки, все ж без наездов, просто наблюдения.у вас есть доказательства что apple хоть раз проплачивали обзоры?
Про ворд который грузился пол минуты примерно. Очень знаете ли интересно послушать.при первом запуске неоптимизированного приложения происходит трансляция.
Подождите, эпл же сказала что розетта всех спасет, получается соврали что ли?
Ну хорошо, ладно, розетта жрет производительность, но у вас же супер М1 который на завтрак ксеоны и эпики жрет, тож не спасает? Делааа…
И к чему эти язвительные замечания?
Совершенно нормальная технология для переходного периода. Прекрасно, что она есть. Переходный период пройдет без стрессов.
Или же вы считаете, что планируется жить через трансляцию вечно? У вас для этого предположения есть основания какие-то?
И к чему эти язвительные замечания?
Поймите, к самому транслятору вообще никаких претензий, криво, глючненько, но функции он свои выполняет.
Или же вы считаете, что планируется жить через трансляцию вечно? У вас для этого предположения есть основания какие-то?
Я такого не утверждал. Да и речь то не о ней.
Просто я угораю с фанатиков эпл которые на словах и бенчах чуть не сервера рвут своим М1, а когда им скидывают видео реальной работы, когда человек перенес свое окружение и все очень плохо даже по сравнению с интелом 2018 года, начинается игра тысяча и одна отмаза своего яблочного бога.
Первой отмазой пошла розетта, но т.к. видно что М1 работает откровенно хуже, получается либо розетта сожрала всю «супер» производителность либо М1 изначально ничем выдающимся не был. Отсюда мой сарказм.
Antervis
при первом запуске неоптимизированного приложения происходит трансляция.
Человек который снял часовой подробный разбор о таком нюансе бы упомянул, ну или как мининимум запустил бы ворд дважды. Это во-первых.
Во-вторых, ворд работает нативно и уже достаточно давно. Так что аргумент с розетой не прокатывает.
К тому же, а что с логином? Почему так медленно? Тоже через розетту логинимся?
Человек который снял часовой подробный разбор о таком нюансе бы упомянул, ну или как мининимум запустил бы ворд дважды. Это во-первых.так запустил или запустил бы?
Во-вторых, ворд работает нативно и уже достаточно давно. Так что аргумент с розетой не прокатывает.человек перенес окружение вместе со всеми x86 приложухами, и внезапно там не нативные версии софта :surprised_pikachu_face:
…
когда человек перенес свое окружение и все очень плохо даже по сравнению с интелом 2018 года
человек перенес окружение вместе со всеми x86 приложухами, и внезапно там не нативные версии софта :surprised_pikachu_face:Теперь домохозяйкам с макбуками нужно знать какой архитектуры какое приложения, и будет ли оно когда-то портировано. Того и глядишь, будут как линуксоиды ядро пересобирать и кеды патчить.
Теперь домохозяйкам с макбуками нужно знать какой архитектуры какое приложения, и будет ли оно когда-то портированосомневаюсь что домохозяйка будет переносить окружение, ровно как и пользоваться не типовым софтом.
сомневаюсь что домохозяйка будет переносить окружениеНасколько я знаю, это один из основных преимуществ Ap*le. Если в GNU/Linux мне нужно получить идентичное окружение, то я сам должен скопировать документы и настройки, безразлично то ли флешкой, то ли через репозиторий dot-файлов.
ровно как и пользоваться не типовым софтом.Нужно ещё знать, что типовое, а что нет. virtualbox — не типовой, оказывается.
На частоте в два раза меньшей 8 декодеров x86 точно влезут. Тем более у M1 и техпроцесс поновее 5нм/TSMC против 7нм/TSMC у Zen3.
С бизнес моделью — вообще чушь какая-то. Ничего не мешает AMD понатыкать в свои чипы CPU/GPU/DSP/ISP/"другие ускорители"/SRAM, а сверху нахлобучить DRAM. Два основных производителя и несколько разных API для работы с этой мишурой. Вот будет радость-то!
В общем, в статье ни одного существенного препятствия для того, чтобы Intel и AMD догнали и перегнали конкретно чип M1, не приведено. Предположу, что просто не ожидали такого поворота событий. Помимо этого Intel с AMD могут не бояться Apple, так как последняя существует в своём закрытом мирке. Только косвенно, из-за возросшего интереса к ARM в целом.
Меня удивило почему samsung (или аналоги, но на него больше всего надежды было) ничего не сделал подобного. Вроде и мобильный чип есть мощный (отсносительно).
Почему Samsung не сделал?
Samsung вполне себе сделал
25 часов автономной работы обеспечит Samsung Galaxy Book S с процессором Snapdragon 8cx
если же вы про производительность, то кто-то же должен быть первым. почему не Apple? какая нам разница по сути.
на данном этапе имеем то что имеем. потом — будет множество альтернатив.
но MS вполне себе серьезно пилит Windows для ARM и эмуляцию x86 в нем. Win32 уже допилили. Сейчас допиливают эмуляцию Win64
на сегодняшний момент вполне себе производительные ноутбуки на ARM, кроме Apple, уже представили Samsung, Microsoft и еще пара первых брендов.
Они пытались сделать подобную микроархитектуру, но не преуспели. Это был один из последних производителей, пытавшихся сделать свои мощные ядра, а не лицензировать у ARM.
Возможно, через некоторое время Qualcomm выпустит продукт разработок Nuvia.
Суть в том что они их производят в большом количестве. И что на их основе склепаны телефоны топовой линейки. Кем лицензированные и насколько быстрые — не настолько важно
Ещё как важно, самому самсунгу. Топовые модели он делал одновременно и на своих процессорах и на qualcomm, для разных рынков, так каждый второй обзорщик упоминал, что exynos версия медленнее и горячее, чем snapdragon, и призывал искать версию на втором. Как, думаете, сказывалось это положительно на продажах своих процессоров? Выгодно было инвестировать в разработку и производство?
В целом, у них была ставка рано или поздно обогнать стоковые ARM-ядра и получить статус "быстрейших" android-телефонов, что дало бы им большое маркетинговое преимущество.
Но за много лет не вышло, поэтому проект полностью свёрнут. Теперь модели exynos и snapdragon будут почти как близнецы братья.
На частоте в два раза меньшей 8 декодеров x86 точно влезутв случае ARM декодер берет i-е 32-битное число из памяти и декодирует независимо от остальных. В случае x86 декодер начинает с i-ого байта, пытается распарсить команду, и попутно думает, попал он в третий байт команды, пятый или четырнадцатый. И если попал не в начало команды, то надо дождаться, пока предыдущий декодер скорректирует конфликтующую команду. И логика такого декодера, сами понимаете, далека от тривиальной. Итого apple будет проще нарастить число декодеров до 16 чем intel/amd до 8.
Можно поставить предварительную стадию, которая разбивает на отдельные инструкции и попутно считая их число. Она будет достаточно простой функционально, но длинной, и всё-равно может влезть. Сомневаюсь, что у Intel/AMD не так сделано, а стоят подряд 4-е полноценных декодера x86. Вообще, кажется, читал, что декодеров там 2-3 разных типов, полный и несколько попроще.
А ещё, 8-м декодеров дадут прирост только в том случае, если конвейер инструкций не успевает за вычислительным. Вероятность, что Intel/AMD упустили это из виду, стремится к 0.
Хотя из статьи есть одна интересная идея. Каждая инструкция x86 переходит в последовательность мелких инструкций, которые зависят друг от друга. Т.е. для параллельного исполнения N инструкций x86 нужно сделать Reorder буфер(ROB) размером N*k, где k — длина x86 инструкций. У ARM, получается, ROB вмещает больше исходных инструкций и эффективнее используется. Но это проценты от общей производительности, если не меньше.
Можно поставить предварительную стадию, которая разбивает на отдельные инструкции и попутно считая их числовы просто передвинете тот же самый боттлнек в другое место.
Берём 8*16байт шину данных, формируем из неё 8 x86 инструкций и отправляем на 8м декодеров. Исходные 8*16байт данных сдвигаем на число найденных x86 инструкций с учётом их размера и добавляем новую порцию данных. Где здесь появляется боттлнек? Естественно необходимо каждый такт считывать до 8*16 байт данных, в худшем случае. Подкачка последовательных инструкций — не является боттленком уже довольно давно.
Где здесь появляется боттлнек?там, где вы должны границы каждой инструкции вычислить, то есть проанализировать что там вам на входе пришло, причем по байту. А потом надо это разреженно разложить в вашу «шину данных» (кеш инструкций), чтобы оно было выровнено. А на ARM просто берутся N*4 байт и подаются на N декодеров. И еще учтите что в вашей схеме кеш инструкций требует 16 байт на инструкцию, а на ARM — 4. То есть вам для равной производительности уже нужен кеш в четыре раза больше и в четыре раза быстрее. Собственно, поэтому x86 процы сразу декодируют невыровненные инструкции, настолько быстро, насколько могут
В аппаратуре боттлнек не может появится при вычислении границ инструкций, если последнее выполняется за такт. Если получится сделать логику, выполняющую разбиение куска данных на 8м инструкций и укладывающееся в такт, то получится только дополнительная стадия, логика и лишнее потребление на переключения. Никаких падений производительности здесь не появится.
Шина данных у меня — это строка или несколько строк кэша L1I. Разрежено разложить — это то, что я и написал. Вариантов этого разложение я могу придумать 2-3 уже сходу. Достаточно определить номер бита, с которого начинается конкретная из 8-ми инструкций. Число комбинаций конечное значение. Можно даже вручную их перебрать. Да, отличается от ARM, но особой проблемы нет, а тем более падения производительности.
Кэш не оперирует инструкциями и он не требует значений, зависящих от размера инструкций. Здесь нет большой разницы, учитывая ещё и то, что x86 код поплотнее будет, чем у ARM. Более того, у x86 есть ещё кэш microop, а это уже подобие RISC от ARM. Кстати, этот microop кэш можно трактовать как ещё и декодер инструкций, раз результат его работы такой же, как у декодера.
Достаточно определить номер бита, с которого начинается конкретная из 8-ми инструкций.ну ну вся идея в том, что на определение этого номера бита нужно времени как на сам декодинг.
Если получится сделать логику, выполняющую разбиение куска данных на 8м инструкций и укладывающееся в такт, то получится только дополнительная стадия, логика и лишнее потребление на переключенияесли вы можете реализовать такую логику, смело идите работать в intel на миллионную зарплату.
Да, отличается от ARM, но особой проблемы нет, а тем более падения производительности.вот в вашей спекуляции проблемы нет, а по факту, в реальных x64 процах, есть.
Здесь нет большой разницы, учитывая ещё и то, что x86 код поплотнее будет, чем у ARMв теории да, в реальности нет.
Вообще-то нет. Только делать это надо не совсем на чипе. Ну смотрите — да, на запуске х86 вынуждена будет работать по старым принципам, чтобы не ухудшить время запуска… но после запуска процессор чаще всего не настолько нагружен. Блин, ну посмотрите вы на Java (и прочие языки с VM, например тот же PHP, c#) и её JIT. Суть в чём? Есть ветка выполнения? Постоянно выполняется с одними и теми же условиями? Ну так перегоним её в простой код и поставим специальную команду, которая вызовает переход на обычный режим работы, если выйдем за пределы заданных условий. Т.е. 90% времени получаем изрядное ускорение работы. Да, в современных CPU есть что-то похожее. Если правильно помню термин "прогностика выполняемых операций" (атака на этот механизм вскрыла недавно Meltdown и прочие уязвимости iпроцессоров). Но ведь можно прогнозировать не только ветку выполнения, но пока процессор "idle — отдыхает" вполне же можно весь (ну или хотя бы базовый) код приложения загнать в преобразователь, который и сформирует очередь упрощённых команд. Да это потребует взаимодействия как минимум ОСи и процессора… но так они уже этим занимаются, просто придётся углубить синергию.
А в чём проблема, если ОСь знает, что надо протранслировать, а CPU — как? Ну т.е. вот загрузились, упало потребление — и командой загрузить остатки кода в оптимизитор на CPU. Нет, о проблеме, что это всё надо согласовать, ОСи надо догадаться и прочие проблемы — я в курсе, я про то, что как минимум часть бутылочно горлышка можно и обойти. И не самую маленькую, надобно сказать, часть.
Вообще в статье подано, как-будто AMD внезапно спохватились и вот недавно выпустили свои APU… которые подаются как слабое подобие M1. Однакось первые APU увидели свет лет 5 назад. И единственное различие с M1 — там не вшит вендорлок, замаскированный доп. функционалом "шифровального" юнита и L1-L3 поменьше (вроде бы)… Ах да, ещё можеть быть графическое ядро не очень-то имеет доступ к кешу. В общем статья… я даже не знаю, как такую степень безграмотного маркетинга назвать… Но пипл, да, схавает, они же не знают правду.
Не скажите. Я вот никогда не заморачиваться продукцией Apple, но сейчас, со сменой архитектуры, появился интерес, как все будет работать не в среде Intel/AMD.
У меня один глаз кровоточит, а второй, кажется мироточит. Интересный эффект.
Зачем я это прочитал? Реклама, в худшем виде.
Причем, идея то хорошая м1 красавчик, но проприетарный.
Если М1 — красавчик, то почему оригинальная статья — реклама в худшем виде?
Я понимаю что это перевод оригинальной статьи, но первый абзац — "Эти чипы быстрые. Очень быстрые. Но почему? В чем магия?"
И далее по тексту…
Мне просто интересно, что там Apple замутил такого магического ;) На сущесвующей ARM
Потому что он не настолько красавчик, насколько тут расписано. У АМД например эта концепция и технологии уже лет так как бы не 10 в апу, интел аналогично. Все современные процессоры — SoC, которым не обязателен южный мост, в которых куча ускорителей, инструкций для ускорения конкретных алгоритмов, относительно универсальных инструкций avx, превращающих их в подобие видеокарты (в плане скорости обработки матриц).
По факту — основное преимущество М1 — закрытая платформа и 5нм техпроцесс, если не сравнивать с процами из древних времён типа 9000-10000 интела, а сравнить с 5000 АМД — разница уже не столь впечатляет.
а сравнить с 5000 АМД — разница уже не столь впечатляет.
А этот 5000 АМД сможет работать в такой коробочке, как мак?
Ну я немного не в курсе, на каком сейчас этапе выпуск 5000u и 5000h, которые туда влезут, но там в общем-то и от 4000u отрыв не такой большой, как в рекламных проспектах — вполне укладывается в прирост от более тонкого техпроцесса.
, но там в общем-то и от 4000u отрыв не такой большойберем гикбенч: у 4800U 1200 однопоток, у M1 1700. Это разница в более чем 40%! У 5800U порядка 1500. Да, ryzen'ы побыстрее в многопотоке, процентов на 30, потому что там по 8 ядер, но вот загвоздка: с условным восьмиядерным M2X от apple они уже тягаться не смогут. Ну, напрямую. Посредством эксклюзивности экосистемы apple конечно же будут.
Ну гикбенч почти целиком ложится на ускорители у эпла, при том половина задач там — мягко говоря далеки от типичных задач для компьютера, но часто используемые на телефонах. Так что я бы особо не полагался на этот тест как показатель производительности процессоров для компьютера.
Ну гикбенч почти целиком ложится на ускорители у эпла
Вы где такое прочитали?
Geekbench полностью исполняется на CPU ядрах. Ни один тест там не использует ускорители, все алгоритмы реализованы в инструкциях CPU.
Пи до миллиона знаков вообще в 2 раза медленнее посчитал, но тут я допускаю что мог что-то не так под m1 скомпилировать.
А если взять zip/unzip маковский, то оказывается что m1 (из air) примерно в 1.5 раза медленнее, чем 10700 из iMac 2020 на одно ядро.а где мы можем ознакомиться с результатом этого замера?
Повторял несколько раз, процессор в обоих случаях загружен на 100%, накопитель практически гулял.
Макбук я покупал не себе, просто решил прогнать несколько тестов перед тем, как его подарить.
Полезных для себя тестов провести не смог так, как homebrew нативно под m1 на тот момент не было, а руками ставить кучу всего было лениво.
Шутки ради попробовал собрать Кликхаус через rosetta, но это прогнозируемо заняло в десятки раз больше времени, чем на iMac с 64ГБ памяти.
А бенчмарки для этих процессоров — вообще маркетинговая ерунда. Да, конвейерный DSP уделает обычный процессор в задачах, под которые заточен. Как и «декодер». Но в первую очередь, они требуют создания специальных условий для правильной работы — подготовленные данные, определенная последовательность действий и формат результата, во вторых — они имеют узкую специализацию. В задачах широкого профиля (а не задачах показывать кинчик очередному адепту яблочного культа) классический процессор будет быстрее и удобнее. Но ничего, я думаю, мессии из самой передовой компании человечества расскажут массам, как оно должно быть на самом деле и массы это схавают, конечно. Эта статья — яркий пример.
Но ничего, я думаю, мессии из самой передовой компании человечества расскажут массам, как оно должно быть на самом деле и массы это схавают, конечно.
Сначала массы анонимно пройдутся минусометом по тем кто пытается мыслить и сравнивать, а не слепо жрать чо дали.
Проблема «специальных блоков» для выполнения конкретных задач — к ним нужно специальное ПО, привязанное именно к конкретным блокам. Через год выйдет процессор Apple M2+ с другим «декодером» или блоком DSP. И вот незадача: все ПО от M1 к нему уже не подходит.
Это не так работает. Разрабатывая приложение под MacOS вы не используете инструкции сопроцессоров напрямую, а вызываете разные фреймворки, которые под капотом сами выбирают, на чём исполнять команды: на CPU, GPU, Neural Engine, ISP… Для нового чипа с новыми ускорителями будет поддержка в фреймворке, и вам вообще ничего не надо в приложении менять.
Именно по этой причине Intel и AMD не идут по такому пути. У них, кстати, очень большой набор специальных команд на все случаи жизни. Это тоже с натяжкой можно назвать «специализированными блоками», однако никто не заставляет их использовать. Это просто расширение для основного набора команд и от их наличия или отсутствия меняется только производительность в узком классе задач.
А вот у Intel и AMD как раз есть эта проблема, из-за чего совместимость приложений регулярно ломается, если программист не предусмотрел фоллбеки с AVX, например (желательно тоже оптимизированные).
А бенчмарки для этих процессоров — вообще маркетинговая ерунда. Да, конвейерный DSP уделает обычный процессор в задачах, под которые заточен. Как и «декодер». Но в первую очередь, они требуют создания специальных условий для правильной работы — подготовленные данные, определенная последовательность действий и формат результата, во вторых — они имеют узкую специализацию. В задачах широкого профиля (а не задачах показывать кинчик очередному адепту яблочного культа) классический процессор будет быстрее и удобнее.
Вы ни в бенчмарках не разбираетесь, ни статью не прочитали внимательно.
После выпуска нового процессора можно уже написанные и существующие программы оптимизировать под новые «фишки» из bitcode. ABI при этом не меняется.
Bitcode используется около 4х лет для приложений в AppStore.
к ним нужно специальное ПО, привязанное именно к конкретным блокам.
Что же это за ПО такое? Прям в регистры железу пишет небось? =)
Про операционную систему слышали что-нибудь?
Именно по этой причине Intel и AMD не идут по такому пути.
А по какому?
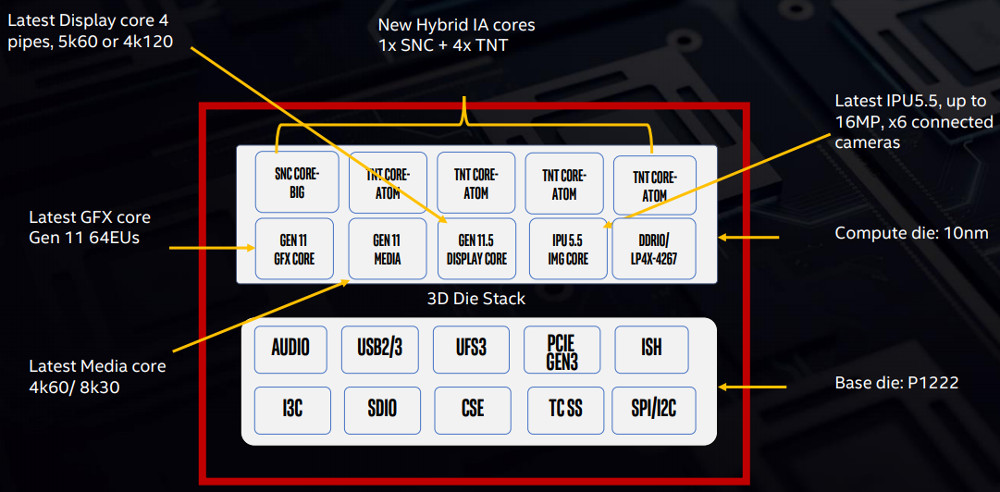
Давайте ознакомимся с «начинкой» процессора Интел:
Мы тут можем увидеть GPU, программируемый DSP для ускорения кодеков, IPU для обработки изображений с камеры.
В задачах широкого профиля (а не задачах показывать кинчик очередному адепту яблочного культа) классический процессор будет быстрее и удобнее
А в M1 не «классический процессор»? =)
О, сколько нам открытий чудных(с)
Через год выйдет процессор Apple M2+ с другим «декодером» или блоком DSP. И вот незадача: все ПО от M1 к нему уже не подходит.
Пишете нам из будущего?
Странно, ведь ПО написанное под A7, прекрасно работает на A14 и M1. Чудеса.
Ладно, ну вот у меня на руках свеженький MacBook Pro 2020, но на чипе от Intel.
Стоит ли продавать его что бы купить новенький с M1, или ноуты от Apple с чипами Intel теперь стали уже никому не нужным хламом?
Смотря чем вы занимаетесь. Уже достаточно много софта на M1 подвезли, но далеко еще не весь. Docker, например, отсутствует.
Статус "портированности" можно посмотреть тут: https://isapplesiliconready.com/
ни в коем случае. м1 сырой и далеко не так всё радужно, как пытаются доказать фанатики и маркетологи
но 13-и дюмовые маки на интеле с 2016-го года ужасны — постоянный перегрев. m1 в этом корпусе просто лучше.
так это претензия к производителю ноутбука, а не к производителю процессора.
что может процессор, какие ему нужны режимы — не секрет на этапе проектирования ноутбука.
у меня кстати как раз 13-шка. и я не представляю чего вы на ней делаете, чтобы заработать постоянный перегрев.
У вас он есть? В каком месте он сырой? Перешел с макбука с 2020 (который ice lake i5) на m1 и ни секунды не пожалел об этом.
Смысл во внедрении ARM — в возможности работать на одной зарядке аккумулятора очень долго. В x86 с этим похуже.
Как там со временем работы на одной зарядке на вашем устройстве?
Какая разница, что внутри?
Никаких лагов. Как intel не греется вообще — вентилятор не слышал ни разу. Сама ОС очень отзывчивая, многие программы, запускающиеся через rosetta2 работают быстрее, чем нативно на intel. Батарея вообще на другом уровне, ты наверняка видел разные тесты в инете.
Но все это не только благодаря m1, но также ssd быстрее, чем у всех предыдущих моделей.
Единственный минус — меньше портов usb c, у предыдущего было 4, а тут только 2.
Он реально такой, каким его показывают многие блогеры. Сначала сам не верил, все таки не хотелось признать, что купил макбук с intel, когда можно было подождать пару месяцев и купить с m1 по мощнее, но за дешевле))
Главный пункт забыли: потому что за рекламу было заплачено не меньше чем за разработку.
Главный пункт забыли: потому что за рекламу было заплачено не меньше чем за разработку.
Реклама это хорошо, но она не ускоряет работу ноутбука и не увеличивает время его работы.
Реклама позволяет больше продать.
А производство современных процессоров без огромнейших объемов невозможно, экономически нецелесообразно.
Таким образом, в план производства изначально закладывается массовая реклама, чтобы выйти на безубыточное количество продаж.
Без рекламы вы смогли бы себе позволить создать только плохой процессор по старым допотопным технологиям.
Таким образом реклама и быстрый долгоживущий ноутбук на технологически навороченном процессоре — связаны друг с другом напрямую.
за рекламу было заплачено не меньше чем за разработку.Если отмотаться далеко назад — Apple заплатила гораздо гораздо. Она очень долго и усердно к этому шла. Чтобы выжать все соки из своего процессора — им нужно было самим собирать свои ноутбуки. Чтобы программы шли идеально — они несколько раз переписывали ось.
Контроль маркетов — а значит если надо будет перекомпилировать половину всего софта — они заставят всех это сделать.
Контроль над обновлениями ПО и отказ от обратной совместимости — нельзя откатиться на прошлую версию ОС, нельзя установить (найти) прошлую версию софта, итд.
Полный контроль устанавливаемого ПО (в т.ч. постоянная отправка телеметрии — что за ПО установлено) нужно для понимания, не поломают ли они используемое всеми ПО.
Тот же переход на Swift для IOS тоже рассчитан на то, что компания сама будет контролировать компиляцию софта.
Всё сделано для того, чтобы в итоге можно было подавать хорошо оптимизированные программы в свой специально подобранный под частые параметры процессор.
Ну и повторюсь — Apple не создаёт универсальные процессоры, которые будут одинаково хороши в любых задачах — от игр до серверов. Они не поддерживают сотни моделей разнородного железа. Они собирают компьютеры под себя, тестят всё на нескольких моделях, и из-за этого им не надо беспокоиться о миллионах других компьютерах и поддержке старого софта.
А это значит, что когда Apple разрастётся, и пройдет много лет, то рано или поздно Apple придется снова задаться вопросом: Поддерживать ли обратную совместимость, или нет? По всем последним решениям Apple — им проще отказаться от старого железа, чем продолжать это поддерживать. НО в отличии от Intel, у Apple есть контроль над компиляторами, и поэтому они могут на это влиять своим рубильником. А Intel на это влияет гораздо меньше, и сама оказалась в тупике.
AMD 4800u имеет 8 полноценных ядер и SMT. Apple M1 — 4 производительных ядра и 4 слабеньких энергоэффективных (они дают примерно ту же производительность, что второй SMT поток на ядре). При этом 4800u выигрывает в лучшем случае (в разных ноутбуках производительность может отличаться) на 25% в Cinebench, при двухкратном реальном энергопотреблении (не путайте с TDP).
Энергопотребление CPU M1 измерено очень точно, и в тесте Cinebench R23 составляет 15 Вт. Максимальное наблюдаемое потребление — 21 Вт при полной загрузке всех исполняемых блоков синтетической нагрузкой.
4800u при этом может потреблять до 35 Вт в Cinebench даже в профиле на "15 Вт TDP": https://next.lab501.ro/notebook/english-lenovo-ideapad-s540-13are-vs-13iml-amd-ryzen-7-4800u-vs-intel-core-i7-10710u/14
по тестам которые я видел, вроде как до 30 ватт может доходитьэто если бенчмарк в полку утилизирует и GPU, и CPU.
Вы можете сколько угодно смотреть истеричные ролики с YouTube, зарабатывающие на хайпе, и делать вид, что это реальное положение вещей.
У меня этот M1 стоит на столе и не лагает от слова совсем. Даже перекодирование видео на всех ядрах (не на GPU) можно заметить только заглянув в диспетчер задач. Я вообще не знаю, как его заставить тормозить. При первоначальной установке у меня происходила индексация диска, скачивание и распознавание фото-библиотеки, импорт музыкальной библиотеки, установка XCode и ещё десятка приложений, а я при этом браузил вэб в Firefox и Safari и не видел даже намёка на подлагивания.
А то, что он компилирует код в 2 раза быстрее моего VR-ready десктопа и рабочего макбука — это уже приятный бонус.
компилирует код в 2 раза быстрее моего VR-ready десктопа
Странное сравнение, учитывая что VR в первую очередь хочет мощную видеокарту…
Другого десктопа у меня просто нет.
Без более-менее приличного процессора большинство игр не будет укладываться в стабильные 90 fps. Впрочем, у меня старенький i5-6600K, разогнанный до 4.5 ГГц, и он уже далеко не "топ".
Но надо понимать, с чем я сравниваю — M1 это энергоэффективный чип для ультрабуков, самый слабый из всего, что будет выпущено под Apple Silicon.
Вы можете сколько угодно смотреть истеричные ролики с YouTube, зарабатывающие на хайпе, и делать вид, что это реальное положение вещей.
Объективное сравние, тесты, видео работы… зачем нам это, мы просто обзовем это все истеричным хайпом с ютуба и отбросим. Объективность уровня «фанат эпл». Поговорку про глаза и мочеиспускание приводить не буду, но вы поняли. Если что то и «хайпует» то это вот эта статья с ее пафосом и кричащим заголовком.
При первоначальной установке у меня происходила индексация диска, скачивание и распознавание фото-библиотеки, импорт музыкальной библиотеки, установка XCode и ещё десятка приложений, а я при этом браузил вэб в Firefox и Safari
Я уже понял что объективной оценки производительности от вас ждать не стоит, но вы мне расскажите как вы столько всего ужали в свои 6-7Гб оперативы и что бы «НИЛАГАЕТ!!11». С 4Гб просто интерент серфить больновато уже, а тут столько работы.
Объективное сравние, тесты, видео работы… зачем нам это, мы просто обзовем это все истеричным хайпом с ютуба и отбросим. Объективность уровня «фанат эпл». Поговорку про глаза и мочеиспускание приводить не буду, но вы поняли. Если что то и «хайпует» то это вот эта статья с ее пафосом и кричащим заголовком.
Объективными сравнениями завален весь интернет, но вы выбрали самый трешовый источник информации — русскоязычный ютюб. Вылезайте из пузыря.
Я уже понял что объективной оценки производительности от вас ждать не стоит, но вы мне расскажите как вы столько всего ужали в свои 6-7Гб оперативы и что бы «НИЛАГАЕТ!!11». С 4Гб просто интерент серфить больновато уже, а тут столько работы.
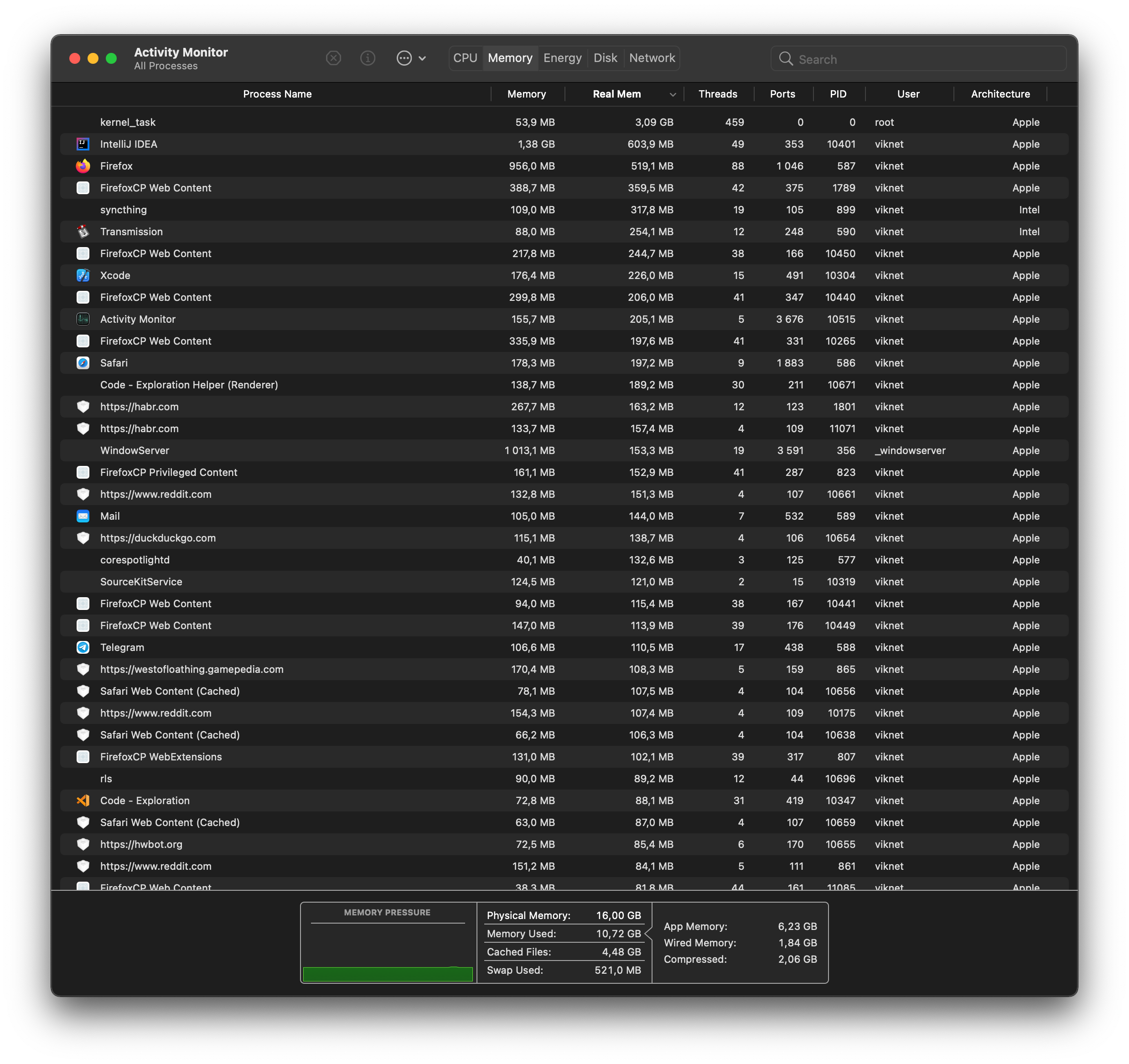
У меня 16 Гб модель, и я не могу представить, чем забить всю память сейчас. Вот так выглядит Safari с 25 вкладками, Firefox с 10 видео (youtube + twitch), XCode с небольшим iOS-проектом и запущенным приложением с локальным дебагером, IDEA с немаленьким Rust-проектом, VSCode с другим rust-проектом, торрент-клиент, мессенджеры, почта, и ещё десяток небольших приложений, которые не в топе памяти. Обычно я работаю с одним проектом одновременно, но закрывать приложения я перестал, т.к. это не влияет на работу всего остального.
{kind=link}
Да, мой стиль работы сильно отличается от вашего, это не значит, что у меня бардак и какофония :)
два браузера с 35 вкладками (Вы же их постоянно все смотрите, не так ли? Закладки ведь дураки придумали, лучше открытую вкладку держать)
Да, закладками я перестал пользоваться много лет назад, когда их количество перевалило за 10k. Я просто не возвращался к ним никогда, так уж мой мозг устроен.
А в процессе исследования новой темы у меня и 100-200 вкладок бывает, из которых какое-то количество останется "дочитать завтра" или переедет на iPad, чтобы дочитать за ужином/перед сном.
какофония от одновременно работающих YT + Twitch (Или вы их не смотрите одновременно? А если не смотрите — зачем указываете?)
Одновременно, конечно, не более одного проигрывается :) Но висящие в фоне набирают кэш и занимают оперативку, поэтому логично было их упомянуть.
3 параллельно запущенных IDE с разными проектами (И вы их все 3 параллельно разрабатываете?
Как уже сказал выше — я перестал закрывать приложения, когда ими не пользуюсь. Висит себе на отдельном рабочем столе, CPU не ест, оперативки полно — зачем закрывать-открывать попусту.
UPD: Выглядит это примерно вот так, если собрать все столы на один монитор.
{kind=link}
Простите, что не в тему, но у вас реально целая помойка в ОЗУ сейчас: два браузера с 35 вкладками
о чем вы говорите, когда браузеры даже на смартфонах приспособились работать. а смартфоны по сравнению с десктопами слабенькие.
браузеры уже лет 5 как агрессивно отключают неиспользуемые вкладки.
по моему даже излишне агрессивно.
в ряде случаев возврат на неактивные вкладки может вызвать даже перезагрузку страницы или заметную паузу, пока данные для отображения бывшей ранее неактивной вкладки подгрузятся с диска/из сети.
ситуация очень хорошо заметна, когда вы в дороге.
ноут в экономичном режиме.
сеть отключена.
открыл вкладку, ту, что просматривал еще при наличии сети — а она тю-тю, не отображается, пока сеть ноуту не дашь.
слишком агрессивно экономят ресурсы современные браузеры.
но 35 вкладок им не страшны.
3 параллельно запущенных IDE с разными проектами (И вы их все 3 параллельно разрабатываете? И не забываете смотреть YT и Twitch при этом? И 33 других вкладки посещать постоянно)…
вы хотите запретить это делать людям?
ну вот у меня 3 IDE, по сути с одним проектом: frontend, backend, db.
я время от времени правлю код в каждом из них, правки связанные друг с другом.
да Youtube поёт сейчас.
открыт Хабр.
открыто несколько вкладок с документацией.
2 мессенджера.
подключение к серверу по ssh, 2 штуки.
файловый менеджер, 2 штуки.
обычная рабочая обстановка.
что тут такого необычного вы увидели у вашего оппонента?
Я просто с трудом представляю, как люди ухитряются не закрывать программы в течение долгого времени. Возможно, это вызвано тем, что я сам и всё моё окружение пользуется Windows-компьютерами и периодически запускает компьютерные игры, или в силу ряда причин вынуждены периодически перезагружаться — оба эти сценария ставят крест на «вечнооткрытых» IDE как минимум. На рабочем компьютере я тоже порой оставляю IDE на пару дней, но не более того.
Ещё раз повторюсь: я ни в коем случае не осуждаю тех, кто не закрывает программы, и не призываю их менять свои привычки. Я просто оцениваю их со своей колокольни и удивляюсь.
Возможно, это вызвано тем, что я сам и всё моё окружение пользуется Windows-компьютерами и периодически запускает компьютерные игры, или в силу ряда причин вынуждены периодически перезагружаться — оба эти сценария ставят крест на «вечнооткрытых» IDE как минимум.
Не вижу связи.
У меня и Windows, и игры.
Перезагружаюсь раз в неделю для профилактики, обновления накатать.
Да и то не всегда. Бывали и двухмесячные марафоны без перезагрузки
Сервер знаю с Windows года 2 не перезагружался.
Из-за особенностей удалёнки мне дома приходится перезагружаться между системами каждый рабочий день — тут тоже не до «хранения» открытых программ (по крайней мере дома).
Если играть в довольно прожорливые игры, то на время игры либо всё лишнее стоит закрывать (IDE очень уж любят отъедать память как не в себя), либо изначально иметь условно не 16, а 32 ГБ памяти, а это лишние материальные затраты ради сомнительной выгоды (ведь SSD сейчас и так дают IDE быстро запускаться, да проект загружать).
Мы живем в разных вселенных, видимо.
В моей вселенной неиспользуемые приложения автоматически вытесняются в на диск. Технология, называемая виртуальной памятью, использует аппаратные возможности процессора и существует в Windows еще с 1990-х годов точно (может и раньше) и к настоящему времени доработана уже как надо (тем более, что упомянутые вами SSD сделали эту технологию довольно комфортной).
32 Г для разработчика, имхо, вообще не роскошь и стоит копейки.
мы определенно живем в разных вселенных.
в моей вселенной траты на комфортную технику на рабочем месте, за которым ты проводишь треть жизни, имхо, это отнюдь не «сомнительная», а вполне себе реальная выгода.
тут нужно пояснить, что основным рабочим местом у меня является десктоп, где за существенно меньшие деньги, чем с ноутом можно получить сопоставимую производительность как у ноута. или за те же деньги, что и ноут, можно купить намного более производительный десктоп.
если вы работаете за ноутбуком, то я понимаю ваши ограничения по железу.
Из-за особенностей удалёнки мне дома приходится перезагружаться между системами каждый рабочий день
ни в коем случае не учу вас жить
но просто подмывает напомнить о существовании виртуальных машин.
Игры упираются в видео практически всегда.
Давайте уточним.
Вы говорите «не хочу ждать пока прогрузится pycharm после запуска игры, потому я его выключу и включу заново?». А что, запуск заново у вас быстрее?
В современных компах 8+ ядер. Даже если запущенный в фоне продукт «что-то странное» сделает — ничего не поменяется по большому счету.
А уж подгрузка текстур из ssd — это сотая доля секунды, кроме случая когда у вас на саму игру памяти не хватает.
Ну кроме обновления винды, оно прекращает игру, да.
А запустить IDE заново после игры (или даже после работы в другой IDE) мне не сложно, тем более что в это время очень удобно пойти, например, заварить чай.
У меня всего-то 16 и я не помню когда я прошлый раз IDE выключал, чтоб поиграть. Я вообще ее включаю только после очередного обновления ОС и больше не выключаю.
Я не понимаю кучи вкладок, особенно если это Chrome, ведь тогда от названий остаются одни иконки и приходится наводить мышь и ждать пока он соизволит показать эту плашку с полным названием.В чём проблема распределить их между окнами, в рабочих столах в разных сеансах?
Я думаю, они слишком поздно появились, и до сих пор не имеют очевидного интерфейса управления.
Большинство пользователей (включая меня) давно наработали паттерны работы в Windows, которые не задействуют использование рабочих столов.
Я не понимаю кучи вкладок, особенно если это Chrome, ведь тогда от названий остаются одни иконки и приходится наводить мышь и ждать пока он соизволит показать эту плашку с полным названием.
Вот именно поэтому я всегда буду продолжать пользоваться Файрфоксом. Триста вкладок в 4 окнах сейчас, на прошлом 800 было, и ничего, полёт нормальный. Ну, раз в полмесяца перезапускать приходится, потому что 12 гиг ОЗУ всего...
Объективными сравнениями завален весь интернет
Отлично, значит вам не составит труда найти тест в котором выполняется одна и та же задача на разных пк и одной версии ос, а лучше сразу несколько задач.
но вы выбрали самый трешовый источник информации — русскоязычный ютюб. Вылезайте из пузыря.
Исключительно ваше ничем не подтвержденное мнение.
У меня 16 Гб модель
Купить наугад сырой продукт в максимальной комплектации. Почему я не удивлен?
Отлично, значит вам не составит труда найти тест в котором выполняется одна и та же задача на разных пк и одной версии ос, а лучше сразу несколько задач.
Компиляция в Xcode в сравнении с топовым intel Macbook Pro 16. На этом же канале много разных сравнений разных систем сборки (только смотреть надо внимательно, часть компиляторов во время записи видео ещё работала через Rosetta).
Сравнение компиляции Webkit на разных компьютерах.
Горка разных бенчмарков сред исполнения.
По поводу монтирования видео достаточно в Youtube вбить "M1 vs MBP 16", их там тысячи от разных видеоблоггеров.
Просто бенчмарки есть на anandtech, notebookcheck и многих других сайтах.
Купить наугад сырой продукт в максимальной комплектации.
Я его взял на пробу новой архитектуры, с возможностью вернуть в первые 2 недели. Теперь это мой основной компьютер.
Всем бы такие "сырые" продукты.
Всем бы такие «сырые» продукты.
А вот не надо, нравится вам — ешьте хоть лопатой. Остальных кормить не надо.
Из всего что вы привели не бенчмарк только вебкит. И только в нем почему то не видно «впечатляющей производительности». Совпадение? :)
Если сборка большого C++ проекта на скорости 12-ядерного Mac Pro не впечатляет, то мне нечего вам больше предложить.
А вот не надо, нравится вам — ешьте хоть лопатой. Остальных кормить не надо.
Вы вообще ничего не привели, кроме одного криворукого видеоблоггера, но уже несколько месяцев приходите в каждую тему о M1 и брюзжите, хотя в глаза эти маки не видели.
Вы вообще ничего не привели, кроме одного криворукого видеоблоггера
Не криворукого и не одного, а двух) То что вы их лично ненавидите не делает их тесты неправильными или ошибочными.
но уже несколько месяцев приходите в каждую тему о M1 и брюзжите
Брюзжу и буду брюзжать. А знаете почему? Потому что только так можно чего то добиться. Сломать донаты в батлфронт, перенести принятие новой политики приватности ватсап, удалить игру из каталога сони… можно добиться реально значимых вещей. Зато вот с молчанием можно творить чо угодно, убирать разьем 3.5, зарядку, телефон скоро из комплекта уберут потому что вы молчите. Теперь нормальный производительный процессор поменяли на дешевую арм затычку, а вы опять молчите. С молчаливого согласия теперь нельзя телефоном новым пользоваться если у эпл обед. И это тоже происходит с вашего молчаливого одобрения, но вы продолжайте молчать и ешьте дальше большой лопатой что вам насыпали.
хотя в глаза эти маки не видели
Ага, не хватало мне еще рублем поддерживать этот корпоративный гадюшник.
Не криворукого и не одного, а двух) То что вы их лично ненавидите не делает их етсты неправильными или ошибочными.
А то, что вы их так любите, не делает их обзоры объективным отражением действительности.
Брюзжу и буду брюзжать. А знаете почему? Потому что только так можно чего то добиться.
Всё, чего вы можете добиться — ввести в заблуждение нескольких впечатлительных пользователей хабра, задумывающихся о покупке макбука, что заставит их взять более слабые и горячие Intel-модели, которые через год будет невозможно продать.
Именно поэтому я продолжаю отвечать на ваши бессмысленные набросы — чтобы люди не делали таких ошибок.
Теперь нормальный производительный процессор поменяли на дешевую арм затычку, а вы опять молчите.
Эти "нормальные процессоры" мы видели в прошлом поколении макбуков, и "затычка" их просто уничтожает вообще по всем параметрам и посягает на десктопные процессоры.
Очнитесь, времена слабеньких ARM-процессоров давно прошли.
Про остальное я воздержусь комментировать, это уже просто нерациональный хейт.
которые через год будет невозможно продать
Простите не-мак-пользователя, но зачем продавать компьютер всего через год использования? Они настолько устаревает, что уже не годится для задач? Или это просто ритуал фанатов Apple, как и с айфонами (вышел новый == нужно покупать новый)? Просто я свой вполне бюджетный ноутбук 2012 года выпуска обновил только в 2018.
Спрашиваю не хейта ради, а из-за любопытства.
Потому что через год ноутбуки выйдут настолько лучше, что многие захотят обновиться. Редизайн + следующее поколение CPU и GPU.
Ну и софт начнёт оптимизироваться под ARM в первую очередь, ML-библиотеки поддержат Neural Engine и т.д.
Старые модели не станут электронным мусором, они ещё лет 5 будут поддерживаться, софт будет выходить. Но, на контрасте даже с M1, их привлекательность на рынке упадёт.
Или это просто ритуал фанатов Apple, как и с айфонами
Мне вот интересно, откуда у людей вот такие стереотипы про "фанатов", "ритуалы" и тому подобное?
Могу поспорить, что так как описано и через 3-4 года не будет.
Ну через полтора-два года новых маков на Intel больше не будет.
Многие разработчики под macOS уже пересели на M1, т.к. выпускать ARM-версии приложений надо, и производительности хватает с головой.
Разработка под iOS тоже сильно упрощается и ускоряется — симулятор больше не нужен, и это приличный кусок рынка недорогих (и б/y) маков.
Поколение Air перед M1 уже можно продать за более-менее нормальные деньги только тому, кто про M1 ничего не слышал — а таких людей будет всё меньше.
Разработка под iOS тоже сильно упрощается и ускоряется — симулятор больше не нужен
надуманное преимущество.
эмуляция, которое больше не нужно — довольно незначительная часть разработки.
Запуск симулятора и заливка в него приложения занимали ненулевое время. А сам симулятор ел ресурсы, которых на слабых машинах и так немного.
т.к. среди пользователей Windows/Linux/Android я подобное встречал только когда постоянно обновляют железо чтоб постоянно играть на убермаксимальных настройках (порой даже чаще, чем раз в год выходит)
во что?
что способно утилизировать производительность NVidia 3090?
какая игра?
VR-игры, например. Там всегда можно ещё чуть-чуть добавить supersampling и повысить частоту :)
А вот выйдет 4090 с ещё большей памятью, ещё большим количеством вычислительных блоков — глядишь и Cyberpunk в 8к потянет, хотя сейчас на RTX3090 это не очень получается
Мне вот интересно, откуда у людей вот такие стереотипы про «фанатов», «ритуалы» и тому подобное?Из новостей, когда за новым устройством люди занимают огромные очереди на улице, даже в мороз.
Мне вот интересно, откуда у людей вот такие стереотипы про «фанатов», «ритуалы» и тому подобное?
Из новостей и наблюдения за окружающими. Вышел новый iЭпл, сразу начинается истерика со стояниями в очередях и срочной необходимостью купить. По возможности в первый же день, что вообще уже за гранью.
Человеку который покупает новый комп, когда старый сгорел или когда перестал тянуть текущие задачи, это выглядит, как минимум, подобно смене авто по причине переполнения пепельницы. Поэтому и такие стереотипы.
Из новостей и наблюдения за окружающими. Вышел новый iЭпл, сразу начинается истерика со стояниями в очередях и срочной необходимостью купить. По возможности в первый же день, что вообще уже за гранью.1. Какой процент пользователей Эппл составляют такие люди?
2. И в чём вообще проблема? Если человека после 25 что-то радует как подростка и он может себе это что-то позволить — почему бы ему и не купить себе эту вещь, чем бы она не была — телефоном, часами или консолью?
что заставит их взять более слабые и горячие Intel-модели, которые через год будет невозможно продать.Только в младших моделях ставят новомодные чипы, в то время как в остальной технике ещё используется интел, а их уже боятся покупать. Получается, что старшие модели устареют ещё быстрее. Как же хвалёная поддержка? А ещё, злые языки говорят, что туда можно поставить другую операционную систему, врут значит?
Получается, что старшие модели устареют ещё быстрее.
Младшие модели уже устарели и сняты с производства. Сложно будет устареть быстрее.
Как же хвалёная поддержка?
Она есть. А что с ней?
А ещё, злые языки говорят, что туда можно поставить другую операционную систему, врут значит?
Не врут, можно конечно. Это штатная возможность.
Младшие модели уже устарели и сняты с производства. Сложно будет устареть быстрее.То, что они сняты с производства, ещё не означает, что ими никто больше не владеет. Если кто-то купил эту модель, например за день до анонса M1, то сколько лет он ещё сможет ею пользоваться?
Не врут, можно конечно. Это штатная возможность.Тогда почему их нельзя продать просто как x64 ноутбуки?
Если кто-то купил эту модель, например за день до анонса M1, то сколько лет он ещё сможет ею пользоваться?
Примерно 3-5 лет до прекращения обновлений ОС, 6-7 до сокращения сервисной поддержки. Пользоваться можно — пока не помрёт.
Тогда почему их нельзя продать просто как x64 ноутбуки?
Можно, конечно, но выбор "просто x64 ноутбуков" на вторичном рынке огромен, и цены там падают очень быстро.
и потенциально более длительной поддержкойХорошо сказано, «потенциально». По факту, даже без смены архитектуры, системные требования растут, обновления операционной системы перестают выходить. Что там со смартфонами, сколько поколений назад можно использовать без ограничений? И именно по этой причине пятилетний должен быть дешевле однолетнего. А если учесть вендорлок, то получается, что уже сейчас говорят о прекращении поддержки, когда она ещё не прекращена. Микрософт вполне себе продлевал поддержку операционных систем. Или вы подскажите какое ещё устройство сейчас признанно устаревающим, с гарантированным концом жизни? А дата прекращения поддержки моноблоков будет ещё позже, как минимум нужно ждать следующего поколения, а это ещё дополнительный год.
Хорошо сказано, «потенциально».
"Потенциально" — потому что никто не мешает в свою очередь продать его до окончания поддержки.
А если учесть вендорлок, то получается, что уже сейчас говорят о прекращении поддержки, когда она ещё не прекращена.
Никто об этом не говорит, это моя экстраполяция на основе предыдущих лет.
И вообще, я не к тому веду.
Для покупателя на вторичном рынке intel версия будет сильно менее привлекательной, чем arm — разница в производительности и времени автономной работы слишком велика. Поэтому цены будут падать, чтобы компенсировать эту разницу.
«Потенциально» — потому что никто не мешает в свою очередь продать его до окончания поддержки.В одном месте вы говорите, что продать не получится, сейчас говорите, что получится.
Никто об этом не говорит, это моя экстраполяция на основе предыдущих лет.Вы не первый человек, говорящий о том, чтобы не покупать на интеле.
Поэтому цены будут падать, чтобы компенсировать эту разницу.Либо это будут делать люди, боящиеся никому не продать, либо цены на arm варианты будут падать медленнее.
А там есть Intel-Air позапрошлого года, и M1-Air прошлого года, с производительностью в 2-3 раза выше
Вы о каких моделях конкретно говорите, упомянув про разницу в 2-3 раза?
Скорее всего, решения других производителей сейчас уже будут лучше почти по всем параметрам — с выходом Tiger Lake, расширением ассортимента ноутбуков на Zen 2, скорым появлением Zen 3.
И да, мак рассматривается только как железо, ОС мне не нужна.в таком случае air будет плохим выбором.
И да, мак рассматривается только как железо, ОС мне не нужна.
Сила Mac в том что это железо + ОС.
Если вам только железо — то ведущие производители-конкуренты предложат вам свои топовые устройства по той же цене и с тем же функционалом (за очень редким исключением) и с тем же качеством, — что и Apple
производительный процессор поменяли на дешевую арм затычку
ARM не значит медленно. Это просто набор инструкций. Уже сотни раз писали что x86 ISA ограничивает количество декодируемых инструкций за раз.
x86 ISA не меняется и это не предвидится. Да и смысла мало. Маленькие шаги наделают фрагментацию. И так куча разных векторных расширений.
Думаю они правильно сделали.
Брюзжу и буду брюзжать. А знаете почему? Потому что только так можно чего то добиться. Сломать донаты в батлфронт, перенести принятие новой политики приватности ватсап, удалить игру из каталога сони
Серьезно? Кто-то передумает из-за вашего мнения?
Я например смотрю тесты и все. Ну норм. Смотрю цены и… возможно беру. Как-то так наверно происходит обьективный выбор. Не?
Реальное бутылочное горлышко в OOOE ядрах это не декодер, а Register Renaming. Представьте что нужно переименовать 8 инструкций за такт. Блок переименования видит все 8, ему нужно выяснить зависимости между всеми 8 коммандами, выделить все sources для всех комманд и прочитать таблицы переименования регистров для их всех. Сложность переименования как минимум квадратичная от количества комманд в такт. То есть блок переименования на 8 инструкций будет в 4 раза больше, чем блок переименования на 4 инструкции. И это еще в лучшем случае. Не забываем, что сама процедура переименования должна завершиться на один такт, потому в следующем такте будут новые инструкции.
И все это верно для любого OOOE и вообще не зависит от оригинального instruction set.
AMD сделали renaming шириной в 6 в Ryzen, Intel шириной в 5 в IceLake. Сделать его шириной в 8 и одновременно сохранить заоблачные частоты под 5Hgz физически невозмодно на данный момент. Даже на частотах, на которых работает M1 возникает много вопросов «как они это смогли?» Есть предположение, что Apple использует скрытые предположения в блок register renaming, например что их компилятор гарантирует что в блоке из 8 инструкций никогда не будет 8 взаимно зависимых. Это бы сильно облегчило работу register renaming. Он может даже поддерживать этот случай, но сбрасываться на 4 инструкции в такт, например. Тогда на хорошем коде (а Apple контролирует свой код) все будет хорошо, а у остальных будет просто все работать.
Есть еще несколько вопросов типа «как они это сделали» вроде Data Cache 128KB на 3 такта latency или 8 блоков выполнения комманд. Это конечно все возможно, но тоже может считаться великим технологическим достижением. Но самая богатая в мире кампания может себе позволить набрать самых крутых CPU инженеров и сделать самый крутой в мире процессор на пару поколений обгонящий всех конкурентов.
Но это еще не значит, что они смогут удержать пальму первенства надолго. M1 возможно самое мощной монолитное ядро которое вообще можно построить на нынешних технологиях. Дальше нужно что-то другое, например много-кластерное ядро. Но создать такое, чтобы работало лучше монолитного прошлого поколения пока никто не смог. Посмотрим если гипотетический M3 или M4 сможет. От M2 можно обидать разве что минорных изменений и увеличения частоты, они уже на пределе.
Иногда очень хочется отследить кто первым вбросил этот тезис про «x86 ограничивает количество декодируемых инструкций за такт»
Я не так выразился. Имею ввиду что нужно сделать 3+ операций чтобы выяснить следующее смещение и параллельно начать декодировать следующую инструкцию. Получется конвеер из инструкций с долгой задержкой между.
Но это еще не значит, что они смогут удержать пальму первенства надолго.
Ни разу не собирался такое заявлять.
Насчет ренэйминга отчасти да, O(n^2) это конечно плохо. Но в идеале код может быть построен компилятором так что это не потребуется.
В общем современные компиляторы неплохо с этим справляются, как минимум в простых случаях. И используют небольшое подмножество инструкций что тут(x86) что там(ARM).
Иногда очень хочется отследить кто первым вбросил этот тезис про «x86 ограничивает количество декодируемых инструкций за такт» и преимущество ARM. Все его бездумно повторяют, потому что не имеют ни малейшего представления что это значит)
Я не стал много расписывать, но думаю эта проблема имеет свое место. (Может я и не прав, но идем далее).
Декодеры отрабатывают немного транслируя код внутрь. И там уже программа выполняется. В случай интенсивного кода(какй-нибудь вычислительный цикл) декодеры вообще не играют роли. Расход на них стремится к нулю по мере длительности исполнения этого цикла.
Но например вэб, мне кажется один из тех случаев когда это влияет.
Веб — часто подгружаемый код на той же странице или в процессе постоянного браузинга.
По моей теории на вэб это влияет в смысле длительности прогрузки страницы.
Наверно еще не качественный код на скриптовом языке может попадать в этот кейс.
Интересен ваш вариант.
Edit:
Подумал еще про ренэйминг.
То есть блок переименования на 8 инструкций будет в 4 раза больше, чем блок переименования на 4 инструкции. И это еще в лучшем случае.
Не факт что блок этот — жесткий hardware. Может там простой(ые) процессор(ы) с ПЗУ. Хотя я точно не могу говорить как лучше.
Несмотря на такую сложность можно брать 8 micro uops за раз и начинать с нескольких мест… Может таким образом константа подрезается.
Иногда очень хочется отследить кто первым вбросил этот тезис про «x86 ограничивает количество декодируемых инструкций за такт» и преимущество ARMтак статья об этом )
Реальное бутылочное горлышко в OOOE ядрах это не декодер, а Register Renaming. Представьте что нужно переименовать 8 инструкций за такт.а в ARM 32 регистра общего назначения вместо 16 в x64, это упрощает или усложняет жизнь?
От M2 можно обидать разве что минорных изменений и увеличения частоты, они уже на пределену на сегодня ядро в M1 быстрое. По факту от apple ждут процов с примерно такими же ядрами, но большим их числом.
а в ARM 32 регистра общего назначения вместо 16 в x64, это упрощает или усложняет жизнь?
В ARM это упрощает, но не значительно.
Физических регистров все равно сильно больше.
Хотя некоторые оценили.
superpowered.com/64-bit-arm-optimization-audio-signal-processing
Иногда упоминаются кейсы что возможность явного(руками) доступа к большему числу регистров лучше.
так статья об этом )
Так не у ARM никакого преимущества. Преимущество есть у Apple c его огромными финансовыми и административными ресурсами, которые позволяют нанать лучших инженеров, которые способны сделать дизайн на грани физических ограничений.
И Интел и AMD тоже смогут. Подтянуться года через 2-4.
а в ARM 32 регистра общего назначения вместо 16 в x64, это упрощает или усложняет жизнь?
Никак не влияет. У AVX тоже 32 регистра. Имя регистра будет на один бит длиннее, а алгоритмы все те же самые.
Никак не влияет. У AVX тоже 32 регистра. Имя регистра будет на один бит длиннее, а алгоритмы все те же самые.
Хм, быть того не может. Зачем же в процессе увеличили количество явно доступных регистров?
Если для удобства, то, на ассемблере даже в те времена мало кто писал.
И разве это не упрощает переименование регистров в случае когда программисту/компилятору доступно больше регистров?
Хм, быть того не может. Зачем же в процессе увеличили количество явно доступных регистров?
Количество регистров никак не позволяет делать алгоритмы в железе проще. Если есть больше регистров, компилятор сможет ими пользоваться и хранить в них какие-то значения. Скорее всего это позволит сократить количество обращений к памяти потому что больше переменных можно будет просто хранить в регистрах. В результате код может будет немного оптимальнее. Но не факт, потому что существующие ABI требуют сохранять регистры в стек на входе в каждую функцию а потом восстанавливать на выходе, что тоже накладно.
Но да, в среднем количество LOAD и STORE на Arm в программах на Aarch64 процентов на 10 меньше, в основном благодаря 32 регистрам.
Количество регистров никак не позволяет делать алгоритмы в железе проще.Я этого не говорил. Это бред.
Я как раз про распределение переменных по явно доступным регистрам. Меньше load store и потенциально меньше проблем в renaming. Что вы далее и написали.
Но действительно с тех пор больше не увеличивают. Значит смысла нет.
а в ARM 32 регистра общего назначения вместо 16 в x64, это упрощает или усложняет жизнь?
Давайте вспомним, что современные системы многопоточные.
И потоков куда больше чем ядер.
Значит происходит постоянная перезагрузка содержимого регистров.
Вряд ли в этом случае большое количество регистров является преимуществом.
Иногда очень хочется отследить кто первым вбросил этот тезис про «x86 ограничивает количество декодируемых инструкций за такт» и преимущество ARM.
Это много раз озвучивали инженеры Intel и AMD, например: https://www.realworldtech.com/forum/?threadid=196293&curpostid=196309
Есть предположение, что Apple использует скрытые предположения в блок register renaming, например что их компилятор гарантирует что в блоке из 8 инструкций никогда не будет 8 взаимно зависимых.
У них нет никакого "своего компилятора". Обычный LLVM, практически из апстрима, со стандартным таргетом.
Посмотрим если гипотетический M3 или M4 сможет.
Судя по генеральному плану перехода всех линеек на свои процессоры — у них ещё не один сюрприз в рукаве.
От M2 можно обидать разве что минорных изменений и увеличения частоты, они уже на пределе.
А "предел" частоты вы откуда взяли?
Сделать его шириной в 8 и одновременно сохранить заоблачные частоты под 5Hgz физически невозможно на данный момент.
В упор не понимаю, как сложность схемы связана с частотой.
В упор не понимаю, как сложность схемы связана с частотой.
Чем больше схема тем меньше ее предельная частота. Слишком сложная схема не будет срабатывать за такт обычного ALU.
Потому не используют full hardware умножители в CPU.
Слишком сложная схема не будет срабатывать за такт обычного ALU.
Всё равно не понимаю, откуда это следует.
В сложной схеме переходные процессы дольше идут? Переключение транзисторов замедляется? Как вы это вообще себе представляете?
То, что сложные алгоритмы чисто математически не раскладываются на однотактовое выполнение на логических элементах, к делу не относится — в таких случаях просто делают их многостадийными.
Всё равно не понимаю, откуда это следует.
В сложной схеме переходные процессы дольше идут?
Что-то вроде как-то так.
На данный момент мне уровень знаний не позволяет точно вам ответить.
Но это является проблемой. Не просто так этим занимаются.
core.ac.uk/download/pdf/234643291.pdf
Но даже интуитивно наивно полагать что можно строить цифровую схему неограниченного размера срабатывающую за тоже время без резкого увеличения power consumption и каких-либо других физ.ограничений.
В сложной схеме переходные процессы дольше идут?
Что-то вроде как-то так.
Т.е. по-вашему «сложные» схемы собираются не из тех же логических элементов, что и «простые»? Или вы представляете себе настолько гигантскую схему декодера, что в нём время распространения электрического поля в проводнике начинает быть сравнимым с временем переходного процесса при частоте 5ГГц, а при 3ГГц ещё ок?
Т.е. по-вашему «сложные» схемы собираются не из тех же логических элементов, что и «простые»?
Нет.
Из тех же — NOT, AND gates, обычно.
Я не думаю что блок ренэйминга будет настолько огромным.
Тут действительно с частотой у apple проблем не должно быть.
Или вы представляете себе настолько гигантскую схему декодера, что в нём время распространения электрического поля в проводнике начинает быть сравнимым с временем переходного процесса при частоте 5ГГц, а при 3ГГц ещё ок?
full hardware multiplier из за O(n^2) быстро вырастет до момента когда упрется в ограничения.
И тогда
То, что сложные алгоритмы чисто математически не раскладываются на однотактовое выполнение на логических элементах, к делу не относитсяК делу относится.
В умножителях Booth'а, «wallac tree» часть сложности срезается оптимизацией.
И вообще сложность алгоритма всегда к делу относится. В железе не чудеса происходят.:
Бут придумал алгоритм. Затем его реализовали в железе. Стала меньше сложность.
Напишем алгоритм умножения столбиком. shift-add.
uint64_t mul(uint64_t a, uint64_t b) {
uint64_t c = 0;
while (a != 0) {
c += b & (0 - (a & 1));
b = b << 1;
a = a >> 1;
}
return c;
}
В худшем случае 64 64-битных сдвига и 64 n-битных сложений, где n в спектре 1...64.
Для 32 бит получится 32 32 битных сдвигов и соответственно для сложений(вдвое короче, в два раза меньше)
В случае full-hardware multiplier где будут просчитаны зависимости каждого конечного бита эта O(n^2) сложность отобразится на его площади.
I specifically asked AMD's Mike Clarke about it and he mentioned that going to a wider decode than 4 would incur additional pipeline stages which would actually have a detriment on performance, and that's why they're not doing it.
Я практически уверен, что тут имеется в виду, что увеличение количества параллельных декодеров x86 чисто математически требует больше стадий, и слабо связано с физическими ограничениями полупроводников, иначе у нас уже были бы мобильные x86 чипы с 6-8 декодерами на более низкой частоте, с меньшим потреблением, но большим IPC (аналогично M1).
В упор не понимаю, как сложность схемы связана с частотой.
слабо связано с физическими ограничениями полупроводников
Так абсолютно согласен. Я даже к этому ниразу и не вел. У x86-декодеров в этом смысле задача сильно проще.
Решается за O(n) но расспараллелить сложно из-за переменной длины.
Т.е. по-вашему «сложные» схемы собираются не из тех же логических элементов, что и «простые»
Для описания сложность логики которую можно запихнуть в каждую стадию есть метрика FO4, которая
определяет задержку сигнала от прохождения через логические элементы.
www.realworldtech.com/fo4-metric
Сейчас в Intel / ARM logic depth ~15-20 (лень искать источник)
А вот к примеру в CELL IBM использовал глубину 11 чтобы достичь частоты 3,2ГГц.
Pentium4 — 12
Если вычесть защёлки, то остаётся ещё меньше.
with the circuit delay depth of 11 FO4, oftentimes only 5~8 FO4 are left for inter-latch logic flow.
www.realworldtech.com/cell/3
В упор не понимаю, как сложность схемы связана с частотой.
Сложность можно определить как количество логических операций (тех самый AND-OR-NOT gates) стоящих за другим при вычислении определенной логической функции. В современном техпроцессе время на один логический элемент занимает 10-15ps. В будущем 3нм это время может будет меньше, но тоже не факт.
Теперь если для вычисления вашей логической функции вам надо 20 логических элементов в грубину — это вычисление физически не возможно выполнить на 5GHz, в такт не влезет.
Для renaming самый сложный случай это зависимые инструкции, вернее необходимость вычисления всех зависимотей на любом уровне:
R1 = ADD R2, R3
R2 = ADD R3, R4
R5 = MOV R2
R3 = ADD R1, R5 зависит от 1 и 2 инструкции
При ренейминге R3 нужно понять откуда брать регистры источники, из таблицы renaming или из предыдущих интрукций. Некоторые комманды как MOV удаляются (или выполняются на этапе renaming) что тоже добавляет сложности. Таких комманд сейчас очень много, MOV это только самый простой случай. И в Ryzen и в M1 и в IceLake уже обнаружен Memory Renaming, то есть форвардинг данных со STORE->LOAD тоже выполняется на этапе renaming. То есть каждый потенциальный LOAD может аллоцировать новый регистр, а может брать регистр от предыдущего STORE и это тоже вычисляется на этапе renaming. В качестве домашнего задания предлагаю написать логическую функцию аллокации нового физического регистра для 8 комманды в окне на этапе renaming. Потом обсудим сложность получившейся схемы)
В современном техпроцессе время на один логический элемент занимает 10-15ps. В будущем 3нм это время может будет меньше, но тоже не факт.
Т.е. на TSMC 5nm сложные схемы должно быть труднее строить, чем на Intel 14nm?
Теперь если для вычисления вашей логической функции вам надо 20 логических элементов в грубину — это вычисление физически не возможно выполнить на 5GHz, в такт не влезет.
Да, спасибо, так довод понятнее.
Про ренейминг не могу ничего комментировать — мои знания слишком поверхностны :)
Т.е. на TSMC 5nm сложные схемы должно быть труднее строить, чем на Intel 14nm?
Наоборот, чем меньше gate delay тем выше частота, на которой можно работать. Или как вариант можно поставить больше logic gates в такт и уменьшить частоту — по этому пути пошли в Apple M1. Больше logic gates в такт — можно позволить себе более сложные алгоритмы не разбивая их на несколько тактов.
Вроде одна из самых простых вещей в modern cpu.
Или это потому что они тактируются как одна схема?
Как я понял через регистры уже задержка будет.
Сейчас страшно стало что-то глупое отморозить…
Получается для моментальной передачи между двумя любыми ALU эта сеть растет в квадрате от их количества?
Надеюсь я вас не утомил вопросами)
Просто у меня их еще есть.
Получается для моментальной передачи между двумя любыми ALU эта сеть растет в квадрате от их количества?
Так и получается
Надеюсь я вас не утомил вопросами)
Просто у меня их еще есть.
I manage ;)
Никогда не понимал смысл hardware fp.
Специфический тип данных по причине фиксированной мантиссы и экспоненты.
Можно же и софтварно реализовать, развернуть цикл.
Получится чуть больше общий поток инструкций, но можно сильно нарастить темп исполнения более простых операций.
+
Компилятор больше не будет ориентироваться на типы данных. Будет дополнительные зависимости находить, когда смешанный код.
Таким образом мне кажется компилятор можно будет сделать более продвинутым. А пока получается искусственный барьер между data types.
+
Кастомная мантисса и экспонента.
2. Как умножение за 2-3 такта происходит? Там же вроде зацикливается ALU, который для этого имеет дополнительный небольшой circuit, чем и отличается от обычных ALU.
Но это слишком быстро по моему даже для wallec tree или booth. Он как будто на повышенной частоте работает.
3. Кстати есть такое что отдельные части запускают на бОльшей частоте? Как в каком-то pentium вроде было, снаружи 3Ghz, внутри alu на 6Ghz.
FP это floating point? Тогда без комментариев. Супер популярный тип данных доступный даже в ЯВУ (float/double), почему бы не сделать его значительно быстрее?
Хотел бы я увидеть software emulation который будет работать за приемлемое время. С удовольствием включу в исходники Bochs:)
>Как умножение за 2-3 такта происходит?
Sorry, ни разу не интересовался. Это удобно рассматривать EXE-units as black box которые просто работают. Моя область это MEU + OOOE.
>Кстати есть такое что отдельные части запускают на >бОльшей частоте?
Уже нет. Мутотень с несколькими clock domains перевешивает все достоинства. В AlderLake AMX на своем clock domain сидит на меньшей частоте, такой вот огромный ALU :)
Хотел бы я увидеть software emulation который будет работать за приемлемое время. С удовольствием включу в исходники Bochs:)
Понятно что эмуляция медленная.
Но в целом.
1. В некоторых вычислениях прослеживаются участие лишь какого-то спектра чисел.
2. Иногда мантисса такая не нужна. Иногда экспонента.
3. Всякие зависимости бывает прослеживаются бит-в-бит и прочее.
4. По устройству misc cpu например сильно проще и в теории может достигать скорости достаточной для эмуляции 16 fmac fp32 per cycle
5. Для компилятора пропадает стена между типами данных = более продвинутый компилятор может вообще зависимости отдельных бит отслеживать втечение всей программы. (Ну это пока немного фантастика)
6. Кастомные типы данных из-за 1,2 и 3.
7. fixed point, правда это частный случай из п.6
И так далее.
То есть именно все вместе это могло быть лучше современного hard fp)
Ну это просто такая вот моя теория.)
P.S.
Вообще последний раз intel удвоили теоретический максимум fp32 до 32(16 fmac) per cycle в Haswell. С тех пор только задержки уменьшаются, но верхний предел тот же. У zen и arm в основном также +-. В GPU то же не сильно прогресс. «Жирные» они(fp блоки).
Почему то один qualcomm решил что достаточно int8 и сделал int8-only NPU
Хотя тренду они чуть-чуть последовали, Adreno умеет всё.
Интересно что с идеей бинаризации.
software.intel.com/content/www/ru/ru/develop/articles/optimizing-binarized-neural-networks-on-intel-xeon-scalable-processors.html
Это много раз озвучивали инженеры Intel и AMD, например: www.realworldtech.com/forum/?threadid=196293&curpostid=196309
Я не озвучивал :)
Более того — на том же форуме недавно обсуждали Uop Cache от Intel и AMD. Более 70% всех команд выполняются из Uop Cache и декодеры там вообще спят.
А пропускная способность Uop Cache уже и сейчас гораздо превышает способности Renaming у всех.
Вот только uOps Cache — это как раз костыль, чтобы меньше использовать декодеры, которые стали узким горлом. Фактически ещё один L1i, который заполняется после декодеров, и занимает намного больше места.
И, судя по всему, он не помогает догнать условный IPC у M1.
Он не для этого сделан. Даже если Uop Cache будет поставлять 16 интрукций в такт и декодеры тоже — это никак не поможет «догнать условный IPC у M1»
Потому что нужно будет 8-wide renaming, соответствующее количество ALU и соответсвующую глубину внутренних буферов. А скорее всего еще и соответствующий размер кешей данных.
Потому что нужно будет 8-wide renaming, соответствующее количество ALU и соответсвующую глубину внутренних буферов. А скорее всего еще и соответствующий размер кешей данных.
Ну смотрите, у нас уже есть перед глазами пример, что это всё возможно. ISA тут, как вы сказали, не является определяющим.
Вопрос, собственно, почему аналогичный подход не взяли на вооружение ни Intel ни AMD, если декодеры не являются узким местом? У Apple настолько более крутые инженеры/инструменты, что смогли сделать широкие алгоритмы ренейминга, которые Intel/AMD считают невозможными?
Естейственно с оговорками. Это невозможно на 5Ghz, а Apple M1 даже не 3Ghz. А частота тоже не маленький фактор в производительности.
Напомню: Performance := IPC * Freq
Да, Apple M1 порвали всех по IPC но они только приблизились к топовым Intel и AMD по производительности, потому что у них на 40% меньше частота.
Но так как Power = V*F^2
то получается что сравнимой производительности у Apple M1 гораздо ниже энергопотребление, на чем они и выигрывают.
Чего ждать в будущем?
И Интел и AMD будет наращивать IPC пытаясь догнать M1. При приросте в 15% за поколение догонят через 2-3 поколения. Apple скорее всего уже не сможет увеличивать IPC с такой же скоростью, они и так на пределе. Будут делать 5-10% и понемногу увеличивать частоту. Гипотетический Apple M3 будет на 20% больше по IPC но на 20-30% меньше по частоте и опять на примерно той же производительности как Intel и AMD. Вот только разница в энергоэффективности сильно сократится не в пользу Apple.
Это невозможно на 5Ghz, а Apple M1 даже не 3Ghz.
Маленькая поправка: M1 работает на максимальной частоте в 3.2GHz
Да, Apple M1 порвали всех по IPC но они только приблизились к топовым Intel и AMD по производительности, потому что у них на 40% меньше частота.
Но так как Power = V*F^2
то получается что сравнимой производительности у Apple M1 гораздо ниже энергопотребление, на чем они и выигрывают.
И тут уже видно, насколько это большое преимущество, когда чип для ноутбука с пассивным охлаждением приблизился к топовым десктопным чипам.
Посмотрим, что будет дальше. В кои-то веки стало снова интересно следить за развитием процессоров :)
И вообще, спасибо за ответы в этом треде, очень познавательно.
Да, Apple M1 порвали всех по IPC но они только приблизились к топовым Intel и AMD по производительности, потому что у них на 40% меньше частота.не, у вас чип хоть на 20 ггц разгонится, а задержки памяти останутся теми же. В итоге прирост перфа от частоты сильно нелинеен. Что в целом можно проследить уже на диапазоне 3-5 ггц. И кстати энергопотребление тоже нелинейно от частоты растет. Так что 3.2 ггц в M1 больше похоже на консервативный режим работы ультрабукс
Но так как Power = V*F^2
Любой сколь-нибудь интенсивный код будет декодирован однажды и исполняться пока не будет остановлен. Вклад декодеров в потребленную энергию будет стремиться к нулю по мере длительности его работы. Без uops cache(в идеальном мире с идеальной ISA) просто из цепочки (компиляция-трансляция в uops — тсполнение) трансляция кода «внутрь» исчезнет. Это как «прогрев» кода jit'ом.
Иногда очень хочется отследить кто первым вбросил этот тезис про «x86 ограничивает количество декодируемых инструкций за такт» и преимущество ARM.
Не х86, а используемая схема VLE с 1-15 байтовыми командами. И в этой статье (написанной явно не для специалистов) написано почему это мешает.
К тому же на большой частоте декодер просто может не успеть вытащить 8 инструкций, даже если они в 1 кэш-строке.
Реальное бутылочное горлышко в OOOE ядрах это не декодер, а Register Renaming.
Ага, а МОП кэши придуманы просто так, да? Они нужны чтобы увеличить ширину декодирования.
Имея 4-way декодер x86 процессоры могут доставать 6-8 МОПов, точно так же как и на ARM Cortex-A77+.
То есть блок переименования на 8 инструкций будет в 4 раза больше, чем блок переименования на 4 инструкции.
Zen2 не только переименовывает 6 МОП-ов, к тому же делает ещё и mov elimination.
С чего вы вообще взяли что переименование представляет собой проблему? Есть какие-то исследования по этому поводу?
Upd: Я тут увидел что у вас в профиле написано «CPU Core Architect @ Intel» и предполагаю что вы понимаете гораздо больше меня в этой теме. Тем не менее, я ни разу не читал что ренейм является ограничителем по производительности.
Тогда на хорошем коде (а Apple контролирует свой код) все будет хорошо, а у остальных будет просто все работать.
У них точно такой же компилятор как и у других.
Есть еще несколько вопросов типа «как они это сделали» вроде Data Cache 128KB на 3 такта latency или 8 блоков выполнения комманд.
Кэш 128КБ у них уже 3 поколения.
Это пример системного подхода.
Страницы 16КБ, ассоциативность 8.
16*8 = 128
Но M1 может и с 4КБ работать. Интересно замерить падение производительности в таких условиях.
А что с блоками выполнения?
6 int ALU операций за такт выполнял ещё A12.
В FPU части там было 3 блока Neon, а сейчас 4.
Это конечно все возможно, но тоже может считаться великим технологическим достижением.
Вы опоздали на пару лет с восторгами по этому поводу =)
Почему вы про гигантский ROB на 630 инструкций или про предсказатель ветвлений ничего не сказали?
Ага, а МОП кэши придуманы просто так, да? Они нужны чтобы увеличить ширину декодирования.
Имея 4-way декодер x86 процессоры могут доставать 6-8 МОПов, точно так же как и на ARM Cortex-A77+.
Вот блин, а я понять не мог.
Вроде x86 isa не такой уж и cisc(именно даже с т.з. внешней isa) чтобы zen 3, декодируя 4-5 инструкций, держался близко к m1.
Вроде читал статьи, а как-то пропустил этот момент.
P.S.
Комменты полезнее любой статьи)
Не х86, а используемая схема VLE с 1-15 байтовыми командами. И в этой статье написано почему это мешает.
К тому же на большой частоте декодер просто может не успеть вытащить 8 инструкций, даже если они в 1 кэш-строке.
Тут вопрос не про успеть. Декодирование вполне себе параллельная операция. Дергаем 16 байт (в новых ядрах 32 байта) и строим 32 отдельных декодера, декодер #N работает независимо в предположении, что он декодирует инструкцию которая начинается с байта N. На выходе получаем декодированные инструкции для всех возможных комбинаций instruction length. Лишнее можно выкинуть, а реальные инструкции взять. На деле конечно так никто не извращается, но реальная жизнь не сильно отличается от этой упрощенной картинки. Например один блок декодера может обрабатывать несколько offsets.
Декодер не такая страшная штука даже в х86 и уж точно там нет ничего сериального. Даже если декодировать каждый байт все равно выйдет меньше размером чем uop cache на 4000 микроопераций. Вот только это будет hotspot, горячая точка покруче FMA. Плюс у декодеров есть гораздо большая проблема — branches. В современном коде каждые 5-7 инструкций есть branch а декодировать через branch декодерам очень тяжело.
Имея 4-way декодер x86 процессоры могут доставать 6-8 МОПов, точно так же как и на ARM Cortex-A77+.
Reaming у Skylake все равно 4-way. В uops. Кстати, сколько это было инструкций уже никого после декодеров не волнует. И совсем не важно, что Uop Cache умел давать 6 в такт, а декодеры 5. Опять же uops, сколько это было инструкций уже никому не интересно. Может одна, а может и 8 из-за Macro-Fusion. И бутылочное горлышко оно здесь.
Zen2 не только переименовывает 6 МОП-ов, к тому же делает ещё и mov elimination.
С чего вы вообще взяли что переименование представляет собой проблему?
Потому что не 8 :)
Мы уже давно хотим 8, и уверен AMD тоже хотели.
Кэш 128КБ у них уже 3 поколения.
Ключевое слово «за 3 такта».
У AMD 32К за 4. У Intel 48K за 5.
Почему вы про гигантский ROB на 630 инструкций или про предсказатель ветвлений ничего не сказали?
Потому что не имею представления насколько крутой у них предсказатель ветвлений по сравнению с Intel или AMD. А про ROB — все субъективно, мы знаем как построить и больше, просто это пока никому не надо. Нужно чтобы все остальное соответствовало, в том числе и renaming и количество ALU. Архитектура должна быть сбалансированная.
Декодирование вполне себе параллельная операция.
Это понятно. И тут явное преимущество RISC с фиксированной длиной команд.
Декодер не такая страшная штука даже в х86 и уж точно там нет ничего сериального.
Ну небольшая последовательная часть определённо должна быть — та, что выбирает нужные инструкции.
Т.е. несколько зависимых мультиплексоров, управляемых некой схемой а-ля fast-carry.
В современном коде каждые 5-7 инструкций есть branch а декодировать через branch декодерам очень тяжело.
Почему кстати тяжело?
Я не знаю как именно набивается МОП-кэш,
но согласно llvm.org/devmtg/2016-11/Slides/Ansari-Code-Alignment.pdf
JMP обрывает набивку МОП-ов в way
Но внутри 1 way может быть 2 Jcc.
Т.е. они туда попадают независимо от предсказания?
В Tremont два 3-wide декодера, которые именно благодаря бранчам (выполненным) могут декодировать 6 инструкций за такт:
[2/3 инструкции]
jmp/jcc next
next:
[3/2 инструкции]
Например в конце и в начале цикла или в линейном коде для увеличения ширины декодирования с 3 до 5.
Как раз это сейчас обсуждается на RWT
www.realworldtech.com/forum/?threadid=199601&curpostid=199601
www.realworldtech.com/forum/?threadid=198791&curpostid=199084
И бутылочное горлышко оно здесь.
Это проблема Skylake что он только 4 регистра переименовывает.
А про ROB — все субъективно, мы знаем как построить и больше, просто это пока никому не надо.
Есть мнение что в ближайшем времени вырастет до 1000 инструкций.
Потому что не имею представления насколько крутой у них предсказатель ветвлений по сравнению с Intel или AMD
5900x vs 9900k
twitter.com/andreif7/status/1346441550339993600
a14 vs 9900k
twitter.com/andreif7/status/1326888473509441537
a12 vs 9900k
twitter.com/andreif7/status/1307645405883183104
Не криворукого и не одного, а двух)
Давайте отвечу цитатой:
Если между несколькими обзорами прослеживается общая линия то невольно задумаешься, а не проплатили ли, но опять таки, все ж без наездов, просто наблюдения
Потому что только так можно чего то добиться.Вы ничего не добьётесь нытьём и подтасовкой фактов.
У меня 16 Гб модель
Купить наугад сырой продукт в максимальной комплектации. Почему я не удивлен?
Всем бы такие «сырые» продукты.
А вот не надо, нравится вам — ешьте хоть лопатой. Остальных кормить не надо.
Люди разные.
У людей и доходы разные.
И их критерии на что тратить деньги, а на что не стоит — разные.
Скажем, у меня три десятка топовых мышей и клавиатур (это порядка 10-20 тыс. рублей каждая).
Взято чисто на пробу, чтобы посмотреть, что мне под руку больше подходит. Неподошедшие мне постепенно раздариваю родственникам.
А с точки зрения моего коллеги, что зарабатывает фрилансом — роскошью является 24-ти дюймовый монитор и 32 Г оперативной памяти на десктопе.
При том, что они вдвоем с женой фрилансят, и хорошо зарабатывают.
Но основной его рабочий инструмент — убогое тормозное гуано 10-ти летней давности с маленьким подслеповатым монитором, разбитой клавиатурой, где не прожимаются с первого раза пяток кнопок. Они делят его на пару с женой. Еще и с ребенком.
При этом на путешествия они огромных денег не жалеют.
А на оборудовать свое основное рабочее место более комфортно почему то не могут.
Люди разные.
У людей разные приоритеты.
Разные оценки «жалко на это тратить деньги, а на то тратить их не жалко».
Но основной его рабочий инструмент — убогое тормозное гуано 10-ти летней давности с маленьким подслеповатым монитором, разбитой клавиатурой, где не прожимаются с первого раза пяток кнопок. Они делят его на пару с женой. Еще и с ребенком.
Будь моя воля, запретил бы разработчикам использовать для работы что либо отличное от тормозного гуано 10 летней давности.
Но увы…
Но основной его рабочий инструмент — убогое тормозное гуано 10-ти летней давности с маленьким подслеповатым монитором, разбитой клавиатурой, где не прожимаются с первого раза пяток кнопок. Они делят его на пару с женой. Еще и с ребенком.
Будь моя воля, запретил бы разработчикам использовать для работы что либо отличное от тормозного гуано 10 летней давности.
Я понимаю, что вы имеете ввиду — думаете код станет лучше, программы быстрее работать начнуть.
Но нет. Это не работает.
В его случае это не так. Совершенно средний-обычный код.
Будь моя воля, запретил бы разработчикам использовать для работы что либо отличное от тормозного гуано 10 летней давности.
— Папа, на водку цену подняли, ты теперь будешь меньше пить!
— Hет, сынок, это ты будешь меньше есть!
На оптимизацию нужно время энтузиастов, либо деньги для наёмных рабочих. Выбирайте.
Ну и у меня стойкое ощущение что сейчас об оптимизации чаще всего не задумываются в принципе. Изначально пишут абы как, зато модно и молодежно.
Меня вполне устроит обновление софта раз в 5 лет а не раз в месяц.Какого софта? Условное приложение делают за год. Для того, чтобы его оптимизировать потребуется условно ещё один год. Кто в данном случае будет этот год оплачивать? Плюс ещё следуют учесть, что на современных технологиях может разрабатывать школьник, а вот уже для оптимизации знаний школьника будет недостаточно, нужно искать специалистов.
Ну а то что школьников нужно гнать от промышленной разработки, и отдать дело профессионалам мысль по нонешним временам, конечно, чудовищная. То что переделывать за школьниками выйдет дороже мысль совершенно верная.
Ну а то что школьников нужно гнать от промышленной разработки, и отдать дело профессионалам мысль по нонешним временам, конечно, чудовищная.Где вы столько профессионалов найдёте? Это во-первых. А во-вторых, профессионалы смогут чем-то помочь, если будут делать с нуля. И если для условной инди игры это ещё хоть как-то может сработать, то для огромного софта или интернет магазина — не получится. А причина в том, что в тот момент, когда школьник уже сдаст проект и перейдёт к следующему, профессионалы только альфу будут делать, ведь качественной реализации до сих пор не сделали. А альфой пользоваться не получится.
Где вы столько профессионалов найдёте? Это во-первых. А во-вторых, профессионалы смогут чем-то помочь, если будут делать с нуля.
А где их раньше находили?
А во вторых, я про разработку и говорил а не про переделку готового.
А причина в том, что в тот момент, когда школьник уже сдаст проект и перейдёт к следующему, профессионалы только альфу будут делать, ведь качественной реализации до сих пор не сделали. А альфой пользоваться не получится.
И прекрасно, и не нужно пользоваться. Будет готовый относительно качественный продукт тогда и выпускайте.
И не забывайте, что в условиях когда пишут код с оглядкой на ресурсы, за использование бессмысленных сущностей обычно начинают больно бить. Итого объемы резко иные а интерфейсы лаконичнее.
А где их раньше находили?А кто сказал, что их тогда находили? Раньше, у людей бы условный MS-DOS, NC, может ещё пара утилит и всё. Есть возможность набрать текст на двух языка, и это уже достижение, ведь для того, чтобы изменить одно слово не нужно перепечатывать всю страницу. Есть пара стратегий и всех это устраивает, никто даже и не говорит, что им это как-то надоело.
Будет готовый относительно качественный продукт тогда и выпускайте.У фирмы бюджет бесконечный, или программисты беспланые?
А кто сказал, что их тогда находили? Раньше, у людей бы условный MS-DOS, NC, может ещё пара утилит и всё.
Они самозарождались в корзинах с грязным бельем что ли?
Ровно так же как и сейчас работников нанимали.
И вы правда считаете что до виндовс вся жизнь заключалась в дос, нортоне и паре утилит?
У фирмы бюджет бесконечный, или программисты беспланые?
А какое мне до этого дело? Я про устройство мироздания а не про счастье капитализма :)
И вы правда считаете что до виндовс вся жизнь заключалась в дос, нортоне и паре утилит?Это был минимальный набор, чтобы с этим компьютером можно было что-то делать. Если нужно, то туда отдельно доустанавливалось недостающее, например текстовой процессор. Такие понятия, например как DE или WM тогда вообще никому в голову не приходили. Напомните, сколько тогда людей вообще имели в семье хотя бы один компьютер?
А какое мне до этого дело? Я про устройство мироздания а не про счастье капитализма :)Пойди туда, не знаю куда, сделай то, не знаю что, чтобы в итоге всё было хорошо.
Это был минимальный набор, чтобы с этим компьютером можно было что-то делать.
Современному и этого не нужно. Хватает биоса с броузером. Не пойму правда к чему это все.
Такие понятия, например как DE или WM тогда вообще никому в голову не приходили. Напомните, сколько тогда людей вообще имели в семье хотя бы один компьютер?
Напомните что windows взяла от atari и xerox?
Сложно сказать сколько семей имели дома ПК, от окружения зависит. Но в целом немного, дома нужны мультимедиа и игры, с мультимедией у первых ПК были определенные трудности а игры в наших широтах тогда не поощрялись на уровне образа жизни. Да и дорого было такое домой для игр покупать, 33тыр ХТ стоила, 66 АТ. Китайская денди была несравнимо дешевле.
Хватает биоса с броузеромНе хватит, хром буки не взлетели для всех без исключения.
Но в целом немногоРаньше было достаточно ходить в гости с дискетой, сейчас уже нужна автоматическая синхронизация между несколькими устройствами. Сложность остальных задач возросла подобным образом.
Не хватит, хром буки не взлетели для всех без исключения.
Дос с нортоном аналогично. ПК нужен для чего то более осмысленного чем навигация по файловой системе.
Раньше было достаточно ходить в гости с дискетой, сейчас уже нужна автоматическая синхронизация между несколькими устройствами. Сложность остальных задач возросла подобным образом.
Как по мне, так это пример когда хвост виляет собакой.
ПК нужен для чего то более осмысленного чем навигация по файловой системе.Тем не менее, даже базовая поставка сильно усложнилась. Возможно я не так выразился, однако суть заключается в том, что сейчас чисто ядра и утилит не хватит даже для первого запуска, так как сюда потребуется добавить оконный менеджер, рабочее окружение, кодеки, сетевой стек, браузер и так далее.
Как по мне, так это пример когда хвост виляет собакой.Те решения, что устраивали тогда, не устраивают сейчас. Кому продашь клон DOOM, если они уже купили оригинал?
У фирмы бюджет бесконечный, или программисты беспланые?
А какое мне до этого дело? Я про устройство мироздания а не про счастье капитализма :)
Вам до этого есть прямое дело — ибо вам потом и оплачивать конечный продукт.
Ведь все свои затраты производитель в конечном итоге получает с конечного потребителя товара/услуги.
И если продукт слишком дорогой получится — вы его не купите.
И поскольку производителю известна недостаточная ваша покупательская способность (или его оценки ошибочны, но сие не важно для принимаемого производителем решения не заниматься производством данной штуки) — вот он и не считает нужным вкладываться в то, что Вы, как конечный покупатель, не сможете себе позволить купить.
Где вы столько профессионалов найдёте? Это во-первых. А во-вторых, профессионалы смогут чем-то помочь, если будут делать с нуля.
А где их раньше находили?
Раньше покупка мало-мальски серьезной вещи была целым событием, на эти вещи копили.
Но чудес не бывает — нынешние дешевые вещи дёшевы и доступны многим потому что производители научились экономить:
Копроэкономика
В середине XX века человечество столкнулось с множеством проблем. Во-первых, на горизонте замаячили перенаселение, нехватка ресурсов и третья мировая война. Во-вторых, рыбалка стала ни к черту. Кроме того, производственные мощности наращивались слишком быстро. Если вы производите сто автомобилей в минуту, и они не ломаются еще десять лет, то уже через год вы со своим заводом идете нахуй, и вам обидно.
История не сохранила имени человека, которому впервые в голову пришла светлая мысль производить не автомобили, а говно. Но мы, конечно, можем представить, что поначалу его идеи воспринимались в штыки.
― Дык ведь покупать не будут, ― мотал головой слесарь. Тупой, упрямый.
― Что б вы понимали! ― волновался молодой специалист, потрясая перед чумазым лицом слесаря пачкой графиков. ― У меня за плечами Итон! Это не у меня говно, а вы значете что! Вы сами! Вы!
― Ну и что я? ― спрашивал слесарь, разворачиваясь. Его уже начинал интересовать этот молодой человек.
Молодой человек не отвечал, но его все равно били. Однако упорству сильных поем мы песню, и через несколько лет бессмысленных блужданий по цехам и корпоративным лабиринтам в производство запустили первую экспериментальную партию говна. Акционеры наверняка переживали. Директор завода ― сам старый мастеровой ― с тревогой смотрел на конвейер, с которого сходили автомобили, слепленные из настоящего говна. Это был волнующий момент, все было ново и, если можно так выразиться, свежо.
И вопреки всем ожиданиям молодой специалист оказался прав. Покупатели полюбили говно пуще всего остального и даже обнаружили в нем неожиданные для конструкторов достоинства. Говно поставили на поток.
Очень скоро производители автомобилей поняли, что в производстве говна есть три важных элемента: реклама, дизайн и цена.
Благодаря рекламе любое говно можно продать. Благодаря дизайну можно продать говно чуть дороже. А правильно выбранная цена ― не слишком дорого, но и не слишком дешево ― не дает покупателю признаться, что он купил говно.
Успех говна на рынке оказался столь ошеломляющим, что очень скоро подобные практики стали общепринятыми, и не только в автомобильной индустрии.
Конечно, малину всем слегка подпортили японцы, которые плохо знали английский язык и ничего не слышали о теории успешного говна, но и они, в конце концов, включились в общую гонку.
Продажи говна породили индустрию сервисов (которая чинила говно), рекламную индустрию (которая придумывала новые названия для говна) и сеть магазинов Wal-Mart.
Полный текст можно прочитать по ссылке:
Копроэкономика
И прекрасно, и не нужно пользоваться. Будет готовый относительно качественный продукт тогда и выпускайте.
И не забывайте, что в условиях когда пишут код с оглядкой на ресурсы, за использование бессмысленных сущностей обычно начинают больно бить. Итого объемы резко иные а интерфейсы лаконичнее.
Программы и магазины в основном выпускают, чтобы зарабатывать — так как на дальнейшую разработку и поддержку нужны ресурсы.
1)Допустим, качественный софт х6 денег в мес и 12мес (разница в стоимости качественного разработчика и школьника)
2)Не качественный — x1 и 2мес.
Второй вариант, уже выпустил продукт, сырой и местами без плюшек — но уже работает, можно пробовать в маркетинг.
За 2-3 мес пусть не так гладко и красочно все было, но получили свою часть рынка и вышли на какой-то профит, и теперь уже могут нанять профессионалов из варианта 1, пока школьники пилят свою халтурную поделку и несут прибыль, часть ее уходит в маркетинг и часть на качественную реализацию, а вы еще пилите свой качественный проект из варианта 1.
В итоге, вы заканчиваете, на маркетинг денег уже нет или меньше, чем нужно, и не понятно выстрелит или нет, и как выстрелит. Вы потеряете больше, если не выстрелит.
А поделка 2 — если не выстрелит — не велика потеря, можно начать пилить новую.
Как итого, через 1.5 года в 1 варианте уже такая же качественная версия, как и у вас, только есть рынок(если выстрелило) и есть бюджеты. А вы вначале пути и с неясными перспективами, и такие проекты жалко закрывать, так как было похоронено уже много бюджета.
Чикагская поленница тоже не качественная архитектура, но свою роль выполнил и в последствии был переписан более качественно.
Но будь моя воля
запретил бы разработчикам использовать для работы что либо отличное от тормозного гуано 10 летней давности.А дизайнерам интерфесов еще и память бы 2GB ограничил.
Как итого, через 1.5 года в 1 варианте уже такая же качественная версия, как и у васА вот этого, к сожалению, не происходит. По факту имеем жирное не оптимизированное изделие требующее топовых CPU, кучу RAM и SSD дисков. Качество, это не только и не столько отсутствие багов, но еще и требовательность к ресурсам.
получили свою часть рынка и вышли на какой-то профит, и теперь уже могут нанять профессионалов из варианта 1
Да, могут — но зачем им это делать, если свою часть рынка уже получили? Намного выгоднее весь профит направить в маркетинг, а клиент "просто" купит ещё палку оперативы.
Ну а то что школьников нужно гнать от промышленной разработки, и отдать дело профессионалам мысль по нонешним временам
Школьники там не просто так:
Ибо лично Вы в том числе, как конечный потребитель — вовсе не жаждете оплачивать возросшую стоимость конечного продукта, создаваемого исключительно профессионалами высшей квалификации.
Разумеется, ситуация не только к браузерам относится.
Представьте ситуацию: Nvidia выпустила свои RTX-карты, а Epic Games такие: «Ну мы свежую версию Unreal Engine выпустили всего полгода назад, так что ждите ещё 4 года, потом выйдет версия с лучами».
Я это всё к тому, что где-то можно и раз в 5 лет обновляться, а где-то это весьма сомнительное решение.
Это очень плохая идея. Конечно, если целевая аудитория продукта — люди, сидящие на тормозном гуано 10 летней давности, то насаждение подобного железа разработчикам еще имеет какой-то смысл. В противном случае разработка дорожает, а иногда вообще становится невозможной.
Предельный случай: Вот Apple выкатила M1. А разработчики сидят на 10 летнем гуано. Что они смогут выпустить под новый проц? Примерно ничего.
Вот так выглядит Safari с 25 вкладками, Firefox с 10 видео (youtube + twitch),Не могу говорить за остальное, но 10 каких-нибудь вкладок можно и с 4 Гб держать.
Объективное сравние, тесты, видео работы… зачем нам это, мы просто обзовем это все истеричным хайпом с ютуба и отбросим. Объективность уровня «фанат эпл». Поговорку про глаза и мочеиспускание приводить не буду, но вы поняли. Если что то и «хайпует» то это вот эта статья с ее пафосом и кричащим заголовком.итак, еще раз. Вы взяли один обзор, который замеряет производительность M1 в задачах эмуляции, выдавая это за нативный перф, и пытаетесь доказать что остальные сотни обзоров не объективны и вообще дутый хайп. Знаете что мне это напоминает?
У меня этот M1 стоит на столе и не лагает от слова совсем. Даже перекодирование видео на всех ядрах (не на GPU) можно заметить только заглянув в диспетчер задач. Я вообще не знаю, как его заставить тормозить. При первоначальной установке у меня происходила индексация диска, скачивание и распознавание фото-библиотеки, импорт музыкальной библиотеки, установка XCode и ещё десятка приложений, а я при этом браузил вэб в Firefox и Safari и не видел даже намёка на подлагивания.Вы приписываете это процессору, забывая, что мультизадачностью занимается операционная система. И если без мощнейшего процессора обеспечить отсутствие лагов у них не получается, то комментарии излишни.
если я выше скинул видео в котором четко видно, что при реальном использовании M1 тупо лагает
«Секс — это скучно, я читал»
Как владельцу Air на M1, смешно читать такое, когда никаких лагов нет при включении пары IDE (XCode + IntelliJ), браузера с кучей закладок и еще какой-то ерунды по мелочи на фоне. Хотя бы сами попробовали, а не писали про «фанатиков, который слепо жрут, что дадут», составляя мнение по видео на YouTube.
Как владельцу Air на M1, смешно читать такое, когда никаких лагов нет при включении пары IDE (XCode + IntelliJ), браузера с кучей закладок и еще какой-то ерунды по мелочи на фоне.С каких это пор, элементарное переключение между окнами вызывает лаги? И потом, переключение между окнами выполняется операционной системой.
Простите, а при чем тут лаги при переключении между окнами? Честно, не могу сообразить. Вы точно отвечали на мой комментарий? :)
Простите, а при чем тут лаги при переключении между окнами?Хорошо, какие здесь лаги вообще могут быть? Это работает одинаково, плюс минус на любом железе, за исключением каких-то слабых конфигураций.
Я хоть где-то упомянул про достижение? Нет. Я лишь указал пример «реального использования», о котором говорил тот, кому я отвечал. Переключения окон еще какие-то приплели, о которых я вообще не говорил.
Как я понимаю, суть в том, что Apple сделала множество специализированных фреймворков, являющихся частью ОС, через которые программисты получают доступ к различным функциям M1 с ее сложной архитектурой, и потом будет развивать чип в любую сторону, свободно меняя функции компонентов и сохраняя совместимость на уровне API, а Intel и AMD зависят от производителей ПО, коих много (Microsoft, Linux и т.д.) и не могут идти по этому пути. Им, фактически, придется писать свои фреймворки, заменяющие функции ОС, конкурируя с производителями ОС (как я понимаю, фраза про конфликт про это).
и не могут идти по этому пути
Но ведь они уже давно идут по этому пути — драйверы видеокарт.
К счастью для Intel и AMD, Apple не продают свои чипы на рынок, поэтому пользователи вынуждены смириться с тем, что производители чипов им предлагают. Покупатели могут лишь спрыгнуть с корабля, но этот процесс медленный. Вы не сможете быстро сменить платформу, так как инвестировали в нее уже немало. А молодые профессионалы с деньгами, которые не успели еще выбрать свою платформу, могут инвестировать все больше в Apple, укрепляя свои позиции на премиум рынке и, следовательно, свои акции на рынке ПК.До сегодняшнего дня, ни разу не видел, чтобы проприетарность платформы столь нагло преподносилась как преимущество. И если в случае с обычными x64 можно как минимум свободно выбирать между производителями, как процессора, так и других компонентов, операционных систем, то в случае с Ap*le — это сильнейший вендорлок, как минимум если туда не ставить только свободный софт.
Если на ARM станет много очень производительных, компактных заменителей ПК (imac, mac mini, macbook) это повлечет за собой значительное количество софта. Если еще и виртуализация софта для 86 будет нормально работать и игрушки пойдут, то выпуск новых аналогов от MS неизбежен.
ru.wikipedia.org/wiki/Larrabee
Ну, эта ситуация постепенно меняется. Большое количество разработчиков на маке (не только iOS) – ситуация сравнительно недавняя, например. Сама Apple заявляет, что 50% покупателей Mac – это люди, которые переходят с других ОС (правда не знаю, как они смогли собрать такую статистику).
Особенно заметен процесс по рынку США, где Apple набрала за год 5%. https://gs.statcounter.com/os-market-share/desktop/united-states-of-america
Надо еще заметить, что значительно выросло качество кросс-платформенных средств в приложении к макос. Раньше кросс-платформенные приложения работали на макос достаточно криво и разительно отличались от родных, а теперь все гладко и красиво. Поэтому разработка на две платформы сразу стала уже нормой.
А еще там внезапно не работает virtualbox. И судя по их форуму — не будет.
Но пока ничего работающего нет. У паралелей пока только обещания.
А для чего-то простого есть UTM и другие оболочки для qemu.
Требуется только бесплатная регистрация, если ещё нет аккаунта.
Отклик всех программ заметно шустрее стал, хотя основная часть и работает через розетку.
Да, докер демона локально пока нет (мне лично и не нужен), но клиент через Homebrew ставится, и вполне можно использовать удаленный демон на переходное время.
В целом я очень доволен переездом, все прошло очень гладко, никаких проблем никакой софт не вызвал.
И батарея теперь реально по 15-20 часов работает, просто песня.
Брать сейчас новый мак на интеле означает вложить деньги еще на 2-3 года в УЖЕ заведомо устаревшее железо.
Не удивлюсь, если через год-другой свежий софт под интел-маки вообще перестанут собирать, как это произошло в свое время с PowerPC.
Можно создать формат исполняемого файла, в котором будут выровнены по 16байтовой границе не только данные, но и инструкции. Память при этом будет расходоваться неэффективно, но можно будет проще его разбирать.
Перерасход памяти большой. И еще значительнее — перерасход кеша.
Но собственно при переходе на 64бит тоже средняя длина инструкции была значительно увеличена, в 1.8 раз вроде бы.
Изменения в ОС — минимальны. Изменения в процессоре — отдельная инструкция переключащая режим на «упрощенный». Сами декодеры, естественно, прийдется менять.
Да и вообще это вариант пришедший сразу, сходу. Думаю есть еще много других чуть более сложных решений.
Да, но только в x86 длина инструкции не ограниченна (хотя сейчас уже ограничили до 15 байт, но все же).
После этого пролистал по диагонали.
На интеловые mac mini ставится (если верить гуглу) i7-8700, явно не ноутбучный процессор.
У меня игровой ноут с приличным охлаждением, проц 8750h, и то, когда я запускаю компиляцию в 12 потоков, он сначала прогревается, а потом скидывает частоту где-то до 3.4. Да и когда был макбук про 2015, он вел себя примерно так же. А mac mini справляется с десктопным процом.
Из того, что я вычитал, есть задушенная до 10 Вт версия, и есть не задушенная. А сколько она потребляет и выделяет — я так и не нашел.
И есть сомнения, что macbook pro рассчитан на 50-60 вт. Процессор 9880H (и 8950HK — так и не понял, какой именно ставился на маки) имеет tdp 45 Вт, и в новостях было, что он жестко троттлился и был медленнее i7.
кстати, а откуда информация про 40 Вт."In multi-threaded scenarios, power highly depends on the workload. In memory-heavy workloads where the CPU utilisation isn’t as high, we’re seeing 18W active power, going up to around 22W in average workloads, and peaking around 27W in compute heavy workloads". В их тестировании максимальное суммарное потребление всего мак мини было порядка 31 Вт, 40 я взял с запасом чтобы не наврать.
Из того, что я вычитал, есть задушенная до 10 Вт версия, и есть не задушенная. А сколько она потребляет и выделяет — я так и не нашел.
Процессор 9880H (и 8950HK — так и не понял, какой именно ставился на маки) имеет tdp 45 ВтTDP, который заявляет intel, и реальное выделение чипа в сколь угодно актуальном режиме работы это две разные вещи. То, что называют «троттлингом», обычно относится к режиму работы с потреблением выше TDP.
кстати, а откуда информация про 40 Вт.
Максимальное измеренное потребление CPU — 21 Вт, GPU — 11 Вт, плюс RAM, NPU, IO-контроллеры: общее предельное тепловыделение ~40 Вт.
Из того, что я вычитал, есть задушенная до 10 Вт версия, и есть не задушенная.
Нет никаких задушенных версий. Есть только младшая модель Air, в которой задействовано 7 GPU ядер из 8.
Процессор 9880H имеет tdp 45 Вт
TDP процессоров Intel имеет мало отношения к реальному тепловыделению.
так и не понял, какой именно ставился на маки
Есть сайт с техническими характеристиками всех выпущенных моделей маков.
и в новостях было, что он жестко троттлился и был медленнее i7.
Это была неправильно настроенная система питания. Поправлено через 2 недели после запуска софтварным апдейтом.
Очень сомневаюсь. Башни на 150 выглядят немного иначе.да, но цифру в 150 Вт не я придумал.
Ну и? Магия существует? А дальше? Вот у меня ssd. Классно, супер. Загрузка быстрая. SMART зелёный. Начинаю копировать данные на диск, и скорость падает ниже hdd. И я задолбался искать решения в интернете — ни один поисковый запрос мне не помог. Т.е. я сейчас должен поменять ssd (это понятно) на другое ssd (да, это не обсуждается), но КАК я должен выбрать ssd, которое будет работать, а не тормозить?
Начинаю копировать данные на диск, и скорость падает ниже hdd.
Откуда? Вы уверены, что там, откуда копируете — скорость адекватная?
Или с одного логического раздела того же диска на логический раздел того же диска?
И они же после установки им SSD бегают несколько дней с выпученными глазами и рассказывают всем встречным о том что МАГИЯ оказывается существуетНикакой магии не заметил. Перезагрузка ожидаемо ускорилась, всё остальное ожидаемо осталось без изменений. Магией это является только для тех, кто не знает чего можно ожидать.
которые уже сегодня производят чипы для ARM и Apple.
В смысле, производят чипы для ARM? ARM стали продавать чипы?
Активный переход с дискретных процессоров к системам на чипе лишает нас
возможности апгрейда и кастомизации железа.
Но в мире существует технология, способная решить эту проблему — это FPGA.
Если бы появились универсальные платформы, которые представляют собой
один простой CPU для запуска первичной системы, а-ля UEFI, и большой FPGA,
на которой собирается основная SoC, то это было бы круто.
Нужен ARM? Пожалуйста, купи бинарь у Apple или другой компании и добавь в конфигурацию загрузки. Нужен x86? Купи его бинарь у Intel или AMD. Нужна графика? Так её можно купить у AMD или Nvidia. Нужно что-то свое? Напиши сам на Verilog.
Правда, тут есть одна проблема. Если железо спиратить простому юзеру просто нереально, то конфиги к FPGA — запросто.
Правда, тут есть одна проблема. Если железо спиратить простому юзеру просто нереально, то конфиги к FPGA — запросто.И с какой частотой эти FPGA работают?
К примеру, Lattice продает свои FPGA почти в два раза дешевле,
чем Xilinx или Intel(Altera). При этом, там даже фарша больше.
Если бы FPGA применялись более массово, то они стали бы еще дешевле.
Там нет оверсложной технологии производства. По большому счету,
они производятся теми же технологическими процессами, что и
обычные процессоры. Тут только вопрос стоит в рабочих частотах и плотности интеграции. У FPGA эти параметры похуже будут, но если заморочиться, то можно
почти вплотную приблизиться.
почему бы не сделать универсальную плату с FPGA, на которую будут не напаивать разные чипы, а накатывать разные бинари?И что вы с этой платой будете делать? К SSD подключать или в старые игры играть?
Я совсем недавно хейтил АРМ, типа какая гадкая архитектура. Но потом больше находил информации по ассемблеру, а так же написал код хэша MD5 для ARM и для x86. И у меня вышло, Athlon II X4 640 даёт 6.36 такта на байт, а код для кортекса 3 инструкции/такт даёт 4 т/б, при этом более современный Skylake даёт 4.97 т/б.
wasm.in/threads/druzja-naskolko-vashi-asm-kody-realno-ehffektivny.32768/page-2#post-425854
Всё просто, архитектура ARM потенциально быстрей x86!
Я совсем недавно хейтил АРМ, типа какая гадкая архитектура.
Внутри x86 давным давно уже не x86. Трансляция же из x86 во внутреннее представление занимает мизер ресурсов.
Видно, что переводчик старался, правя гугл-транслит, вот только незнание темы сказывается.
1. Введение. Как писал в свое время Кузнецов: «если новый компьютер не будет раза в три быстрее, я в его сторону даже не посмотрю». В моем понимании «в пух и прах», «просто уничтожают их» это на порядок быстрее. Там, где тормозило — теперь летает. У новых М1 там, где тормозило тормозит, может быть, чуток меньше.
2. «M1 — это не центральный процессор» и далее. Цитата: «Это только часть объяснения, почему люди, которые занимаются видео и графикой на компьютерах с процессором М1, отмечают прирост производительности. Дело в том, что задачи выполняются на том процессоре, который для этого был создан.» Сразу встает вопрос: а в других компьютерах разве не так? SoC в статье превозносится как выдающееся решение. Вот только хорошо оно лишь для Apple. В более-менее полноразмерных ПК это напрочь убивает возможность пользоваться нормальной видеоподсистемой и т.п. Про апгрейд даже и писать не хочется. В общем решение для чего-то маленького, переносного.
3. UMA. Сколько раз я видел эти качели… Единая память — разделение — опять единая…
Разным устройствам под крышкой SoС нужна разная пропускная способность. Попытки объединения приводят к тому, что приходится вводить кэши. Отсюда проблема с актуальностью, локальностью и т.д. Еще DMA до кучи.
Даже для двух устройств — CPU и GPU можно обойтись разноскоростной памятью. Вот только подход Apple требует самой быстрой памяти, да еще и в большом количестве. А значимой разницы в скорости это не даст.
4. Почему AMD и Intel не следуют… А вот тут главный вопрос этой истории.
Сразу скажу — я обеими руками «За» более быстрые процессоры. Позиция Intel уже осточертела.
Но! Apple компания «все-в-одном» — конгломерат. Она жестко контролирует свой сегмент рынка, как в железе, так и в ПО. Железо последние годы не развивается, ПО новыми прорывными функциями тоже обделено. Стагнация. Новый процессор — новые версии программ для потребителя. Разработчики смогут продавать их вообще не внося изменений по-сути. Перекомпилировал, подогнал — и — вуаля — доход. Apple тоже долька достанется. Не хочешь переходить на новую версию ПО? Так поддержка версий для х86 скоро прекратится. Хочешь новую версию? Будь добр купить комп на новом процессоре. Опять доход. Встряска рынка. Плюс избавление от старых программ, разработчики которых не захотят или не смогут выпускать версии под новое железо. Не секрет, что многие программы создавались большими коллективами, а затем малыми силами осуществляется техподдержка, правятся ошибки, потихоньку копятся изменения для новых версий. Теперь этот рынок встряхнется как во времена перехода с PowerPC. И это очень хорошо, на мой взгляд. Да и Intel придется что-то делать в ответ на тоскливые взгляды своих фанатов в сторону МАКов.
Теперь об х86. Дело в том, что там просто чудовищных размеров зоопарк старой техники, узкоспециализированных программ. Помнится даже на авианосцы Windows ставили. Микрософт опять-таки. Переобуться без потерь не получится. Были же времена попытки перехода на RISC. Это ядро, вроде бы, еще бьется там, под крышкой новенького Core. А еще есть AMD. Конкурент. Промахнешься — сожрут.
5. Опережающее выполнение и далее.
Сразу вопрос к знающим. Команды 01-03 на иллюстрации. Что за ассемблер с тремя операндами?
Опережающее выполнение команд и предсказание ветвления выдается автором как панацея. Да. Так оно и было. Лет десять тому назад или даже больше. Intel в каждом поколении бодро рапортует о нововведения, призванных улучшить быстродействие этого блока на 5%-10%. В данный момент я даже боюсь представить что там, в этих конвейерах, происходит. Но я уверен в одном, если бы удвоение числа конвейеров давало бы резкий прирост их давно бы уже было в два раза больше. А большая длина инструкций CISC при нормальном компиляторе не дает какое-то значимое для быстродействия количество промахов алгоритма предсказания ветвления.
6. По поводу Ryzen.
«Если Apple захотят больше мощности, они добавят больше ядер, и это позволит дать больше производительности, не увеличивая сильно потребление энергии.» А вот не факт, далеко не факт. По Амдалу линейной зависимости не будет. Хотя тестов многоядерных процессоров вагон и маленькая тележка — там все видно. На некоторых задачах выигрыш будет. Но ведь мы хотим все и сразу.
7. Все очень спорно. Как писал Кир Булычев, качественные изменения человечество предугадывать не умеет, а количественные и не особо нужны. Время покажет.
«Intel даже хуже, ведь они на данный этап официально проигрывают гонку производительности, а их GPU очень слабы для интеграции в чипах SoC.». Вопрос: а нафига оно им? Не думаю, что встроенное видео от Apple когда-нибудь сможет сколько-нибудь сравниться с одновременно существующей видеокартой уровня RTX2060 (на данный момент).
По поводу «счастья для Intel и AMD, что Apple не продает свои чипы на рынок». Только для ультраноутбуков и моноблоков. Уже с нормальных ноутов Apple была бы в пролете, либо выпускала бы под сотню разных модификаций своих чипов.А в настольных системах SoC от Apple вообще ловить нечего. Да и не пойдут они на такое снижение маржи. В аналогичной ситуации они, помнится, почти до банкротства добрались, но не полезли на нормальный рынок, предпочтя отсидеться в своей нише.
8. Ну и последнее:
«А молодые профессионалы с деньгами, которые не успели еще выбрать свою платформу, могут инвестировать все больше в Apple, укрепляя свои позиции на премиум рынке и, следовательно, свои акции на рынке ПК.»
Ради этого предложения статья и написана.
Если дочитали до конца — спасибо вам.
ПС. Ни разу не поклонник какой-либо фирмы из вышеупомянутых.
Intel в каждом поколении бодро рапортует о нововведения, призванных улучшить быстродействие этого блока на 5%-10%. В данный момент я даже боюсь представить что там, в этих конвейерах, происходит. Но я уверен в одном, если бы удвоение числа конвейеров давало бы резкий прирост их давно бы уже было в два раза больше. А большая длина инструкций CISC при нормальном компиляторе не дает какое-то значимое для быстродействия количество промахов алгоритма предсказания ветвления.там хитрее чутка. Бранч предиктор в современном проце угадывает очень много, 98+% переходов. Казалось бы, там уже нечего улучшать. Однако вкупе с улучшением бранч предиктора увеличивают и глубину спекулятивного исполнения (что и оказывает влияет на перф), и соответственно миспредикты становятся более дорогими.
7. Все очень спорночет ага, очень спорно у вас получилось
«Intel даже хуже, ведь они на данный этап официально проигрывают гонку производительности, а их GPU очень слабы для интеграции в чипах SoC.». Вопрос: а нафига оно им?мне кажется вы сильно недооцениваете рынок ноутов на встроенной графике.
Не думаю, что встроенное видео от Apple когда-нибудь сможет сколько-нибудь сравниться с одновременно существующей видеокартой уровня RTX2060 (на данный момент).так они может для более требовательных ноутов и дискретную сделают? В смысле отдельный чип. Так то понятно, что встроенная на ~10 Вт не обгонит дискретку на 65 Вт. В конце концов, по слухам apple планируют рабочие станции до 32 ядер, и графика помощнее им там тоже понадобится.
Потому что по моим ощущениям с тех пор ни в 3 раза, ни тем более на порядок, десктоп уже быстрее не становится
1. Вы с 2012 года комп не меняете, как я?)
Потому что по моим ощущениям с тех пор ни в 3 раза, ни тем более на порядок, десктоп уже быстрее не становится
Поменял недавно.
Как раз модель 2012 года была.
Разница очень даже существенная.
Разумеется, если взять нормальный а не бюджетный M2, десктопный процессор не бюджетный, достаточно оперативки и хорошую дискретную видеокарту.
Про 3 раза не скажу, но дико комфортно после компьютера 2012 года.
У меня i7 с 32 гб памяти 2012 года. Менял с тех пор видеокарту на 1060.
Жене пару лет назад покупал ноут msi с i7, 16 гб памяти, дискретной видеокартой и ssd на м2 850 evo, разницы в скорости кроме бенчмарков особой не увидел. Жена говорит, что на моем десктопе программы, для которых покупался ноут (Autocad и Revit) работают лучше
16 ядерный райзен 3950x в ряде задач (компиляция, кодирование видео) примерно а три раза быстрее моего предыдущего i7 6700k. А 5950x еще быстрее должен быть.
16 ядерный райзен 3950x в ряде задач (компиляция, кодирование видео) примерно а три раза быстрее моего предыдущего i7 6700k.
Корректно ли сравнивать топовый Райзен с нетоповым даже в те времена Интелом?
6700k был топовым в ширпотребной десктопной линейке. И 3950x — топовый в ширпотребной десктопной линейке. Так что всё честно.
Если Apple захотят больше мощности, они добавят больше ядер, и это позволит дать больше производительности, не увеличивая сильно потребление энергии
Это могут все конкуренты сделать также.
Распаралелливание программам плохо дается, исключения редки.
Найти там М1 на (!) 347 месте, посмеяться над автором и закрыть статью.
На самом деле достаточно открыть рейтинг производительности: technical.city/ru/cpu/rating
Найти там М1 на (!) 347 месте, посмеяться над автором и закрыть статью.
Достаточно обратить внимание на энергопотребление — и уже можно смеяться над вами и больше не считать то, что вы пишите, заслуживающим внимания.
Это всё равно что написать статью «Почему велосипед такой быстрый», в комментах кинут ссылку на таблицу скоростей велосипедов и мотоциклов, а в ответ «Зато мотоцикл больше бензина ест!!1»
Ну вот опять в подобных статьях путают тёплое с мягким. Статья как называется? «Почему чип Apple M1 такой быстрый?» Не «энергоэффективный», а «быстрый».
Разве там написано «самый быстрый»?
Если «незаметно» переходить от производительности к энергопотреблению, то в топ вообще вырываются калькуляторы, особенно на солнечных панелях, потому что им даже батарейки не нужны (при соблюдении условий эксплуатации), но звучит как бред, не так ли?
Firestorm обгоняет большинство процессоров Intel и самый быстрый чип от AMD — Ryzen
Ни тут, ни в остальной статье практически не обсуждается энергоэффективность. Тут нас пытаются убедить, что чип, якобы, самый быстрый, что не является истиной.
Так что ваш комментарий больше похож на истерику фаната огрызков. Однако, если вы не будете читать то что я пишу — я буду вам лишь благодарен. Истеричек среди читателей мне не надо.
Достаточно открыть рейтинг производительности: technical.city/ru/cpu/rating
Как этот рейтинг строится?
Не нашел на сайте ни описания методологии тестирования, ни источников данных бенчмарков (если они только агрегатор), ни хотя-бы банально формулы получения значения "Общая производительность в тестах", по которому в итоге и ранжируются процессоры.
Ткнул наугад несколько процессоров — у всех набор бенчмарков разный. Для самого M1 единственный бенчмарк — это Cinebench 15. Этой версии скоро 8 лет, если что. И очевидно, нативной поддержки M1/ARM в ней нет. Что, пардон, там сравнивается вообще?
Не то чтобы в нормальных рейтингах M1 был в абсолютном топе по raw performance. Он все таки больше про performance/watt. Но в данном случае если что и заслуживает высмеивания, так это "рейтинг", который вы приводите как аргумент.
Если вы хотите следовать букве формализма, тогда будьте добры, разработайте какой-нибудь абсолютно объективный способ тестирования для объективно разных платформ, а потом критикуйте.
Это был просто пример, первый попавшийся под руку, но весьма показательный.
Ну да, если непонятно откуда взять непонятно какие числа, а потом их сравнить, то в результате получится непонятно что. Действительно очень показательно.
тогда будьте добры, разработайте какой-нибудь абсолютно объективный способ тестирования для объективно разных платформ, а потом критикуйте.
То есть после сайта с рандомными числами в ход пошел аргумент "сперва добейся"?) Сильно.
Проблема вашего рейтинга не в необъективности методологии сравнения, а в отсутствии методологии как таковой. Там сравниваются значения, которые получены неизвестно как.
Есть хочется объективных сравнений, то можно начать со все того-же Cinebench, но версии 23, которая есть нативно под m1. Там в однопотоке m1 показывает себя вполне себе на уровне топовых CPU от AMD и Intel.
В многопотоке начинает уступать

Не доверяете cinebench — возьмите например XcodeBenchmark. Там m1 тоже очень даже в топе.
Не нравится XcodeBenchmark — возьмите что угодно другое. Но напишите, что вы взяли, что и как меряли и как потом сравнивали результаты. Тогда можно будет предметно рассуждать почему ваш бенчмарк хороший и абсолютно объективный или плохой и относительно субъективный. В случае же с вашим рейтингом рандомных чисел предмета для обсуждения нет в принципе, вот и все.
По вашим же скринам он далеко не первый, тогда как в статье безапеляционно заявляется, цитирую «обгоняет большинство процессоров Intel и самый быстрый чип от AMD — Ryzen».
Следуйте букве формализма до конца, признайте, что ваш «топовый M1» отсасывает у Ryzen (ваш же скрин).
Что касается аргументации это было не «сперва добейся», а «предложите лучший вариант», если он у вас есть. А то пока это уже шизофренией попахивает. Вы своими же скринами показали, что M1 проигрывает Ryzen'у, тогда как в статье утверждается ровно обратное.
Ну так напишите им и добавьте данный бенч в список, там и посмотрим каким он станет в рейтинге.
Зачем? Я думаю, у них достаточно источников энтропии для наполнения своего "рейтинга".
По вашим же скринам он далеко не первый, тогда как в статье безапеляционно заявляется, цитирую «обгоняет большинство процессоров Intel и самый быстрый чип от AMD — Ryzen».
Тут конечно переводчик накосячил, в оригинале формулировка более мягкая (almost beats) и более очевидная (Firestorm… beats… Intel cores… and… AMD Ryzen cores).
Firestorm, in contrast, beats most Intel cores and almost beats the fastest AMD Ryzen cores
Но тем не менее, даже из этого перевода понятно, что речь идет о сравнении ядра Firestorm с ядрами интела/амд. Т.е. об однопоточной нагрузке.
Следуйте букве формализма до конца, признайте, что ваш «топовый M1» отсасывает у Ryzen (ваш же скрин).
Протрите глаза от пелены ненависти к Эппл и любви к отсасываниям и перечитайте все таки статью. Лучше в оригинале.
Вы своими же скринами показали, что M1 проигрывает Ryzen'у, тогда как в статье утверждается ровно обратное.
Нет, в статье этого не утверждается. И мои скрины никак статье не противоречат.
«предложите лучший вариант», если он у вас есть
Я предложил целых два. Хотя по сравнению с вашим рейтингом, который вы упорно продолжаете защищать, даже userbenchmark — лучший вариант.
Зачем? Я думаю, у них достаточно источников энтропии для наполнения своего «рейтинга».
Ну у вас явно какая-то тяга везде вставлять ваше ценное мнение, может хоть где-нибудь приложите в какое-то полезное русло.
Тут конечно переводчик накосячил, в оригинале формулировка более мягкая (almost beats) и более очевидная (Firestorm… beats… Intel cores… and… AMD Ryzen cores).
В такой формулировке это и вовсе просто пространные рассуждения.
речь идет о сравнении ядра Firestorm с ядрами интела/амд. Т.е. об однопоточной нагрузке
Собственно это ничего не меняет. Добавьте в свой скрин больше мощных чипов от AMD и Intel, у вас и синглкор скрин будет выглядеть так, что M1 в конце списка окажется. Что-то лопочите про объективность, а потом в качестве примера приводите скрин с рандомно выбраными ядрами (который тоже, впрочем, показывает что M1 далеко не первый, лол).
Протрите глаза от пелены ненависти к Эппл и любви к отсасываниям и перечитайте все таки статью. Лучше в оригинале.
Статья данная имеет низкий технический уровень и интереса для меня не представляет. А вот для балаболов вроде вас, конечно, в самый раз.
Что касается «любви к отсасываниям», я бы вам порекомендовал следить за собственным языком, а то как-то некрасиво выглядит, очень напоминает поведение некоторых человекообразных обезьян, типа капуцинов.
Нет, в статье этого не утверждается. И мои скрины никак статье не противоречат.
Ну вот же вы сами процитировали, ещё и оригинал:
Firestorm almost beats the fastest AMD Ryzen cores
Смотрим ваш скрин. Где там almost beats? Вы на разницу посмотрите. 7к против 11к. Это не «алмост битс».
Нет, в статье этого не утверждается. И мои скрины никак статье не противоречат.
Ну что тут сказать. У вас, видимо где-то с восприятием русского языка ещё нарушения.
Я предложил целых два
Вы не предложили ни единого, вы просто трепитесь. То что в мире существует тысячи бенчмарков и дураку понятно. А вот рейтингов что-то не густо, по понятным причинам. Если вас указанный «рейтинг» не устраивает, камон, делайте свой.
Добавьте в свой скрин больше мощных чипов от AMD и Intel, у вас и синглкор скрин будет выглядеть так, что M1 в конце списка окажется.
Давайте больше конкретики. Какие именно чипы мне добавить? Ниже вы там 9980XE просили добавить. И как-то "в конце списка" оказался он, а не m1.
Смотрим ваш скрин. Где там almost beats? Вы на разницу посмотрите. 7к против 11к. Это не «алмост битс».
Я же вам даже жирненьким выделил. Ядро, core. Однопоточная нагрузка. Зачем вы продолжаете цепляться к multicore? Никто кроме вас не утверждал, что там m1 в топе.
А вот рейтингов что-то не густо, по понятным причинам. Если вас указанный «рейтинг» не устраивает, камон, делайте свой.
Почему же? Таких как ваш — полно. Могу и свой сделать вечерком, если у вас такая любовь к рандомным числам.
Если пропустить бессмысленный треп, то вот вам рейтинг. Правда тут не совсем так как вы любите. Цифры не с потолка, а по результатам конкретного бенчмарка
https://browser.geekbench.com/mac-benchmarks
Я в качестве аргумента привожу верифицируемые и сравнимые данные. Если вы проявите немного самостоятельности и пройдетесь по сайту, то обнаружите, что там рядом есть точно такой-же рейтинг процессоров без привязки к платформе: https://browser.geekbench.com/processor-benchmarks
M1 в нем нет, но если совершить еще одно небольшое усилие, то можно обнаружить, что он там был бы на 1 месте. https://browser.geekbench.com/macs/mac-mini-late-2020
Я же вам даже жирненьким выделил. Ядро, core. Однопоточная нагрузка. Зачем вы продолжаете цепляться к multicore?
А смысл с этого в 21 году то?
Очень напоминает аргументацию синего лагеря год назад на смежных ресурсах до выхода Ryzen 5xxx-серии, вида «У нас на 1 ядро в бусте до 5.3 Ггц выдает на 4фпс больше, так что интел — всё еще лучшие процы», и пофиг что во всём остальном интел уже тогда сливался и даже для большинства игр уже отнюдь не однопоток решал (про всякие рендеры, нейронки и прочую полезную деятельность я вообще молчу).
А уж если сравнивать решения одного ценового сегмента, так вообще беда была…
Собственно это ничего не меняет. Добавьте в свой скрин больше мощных чипов от AMD и Intel, у вас и синглкор скрин будет выглядеть так, что M1 в конце списка окажетсякуда больше то? В топе гикбенча у лидера 1682, а M1 выдает за 1700. В топе cinebench, который вы скинули, M1 на девятом месте, с разрывом меньше 10% относительно 160-ваттников от AMD и 45-ваттника от intel.
Вы не предложили ни единого, вы просто трепитесь. То что в мире существует тысячи бенчмарков и дураку понятно. А вот рейтингов что-то не густо, по понятным причинам. Если вас указанный «рейтинг» не устраивает, камон, делайте свой.да дофига этих рейтингов, толку с них, если в них данные боты заполняют? Или вы готовы мириться с любыми допущениями, неточностями, и лютым бредом в этих рейтингах, ровно до тех пор, пока они подтверждают вашу точку зрения?
Пример, когда приводят бенч мака на макоси, сравнивая его с бенчем пекарни на винде — это вот как раз из этой серии.
Я повторюсь ещё раз, мне вообще до фонаря сколько какой проц выдаёт попугаев. Факт в том, что в статье написано, чёрным по белому, мол М1 — самый быстрый камень. Но почему-то когда начинаешь сравнивать, вдруг оказывается, что надо сравнивать как-то по особенному, потому что в приведённых примерах сравнение якобы необъективно.
Ну давайте тогда, разрабатывайте сами бенч, который будет как-то вычислительную сложность итогового тестового алгоритма выравнивать с учётом архитектуры чипа, будет учитывать архитектуру ОСи, на которой запущен и т.д. и т.п. тогда будет объективность.
Я вам по секрету скажу, никакой особой объективности во всех этих бенчах нет. Почитайте истории про то как nVidia свои дрова оптимизировала чтобы в бенчах лидировать, было такое несколько лет назад.
Главный спорный момент тут в том, что утверждение будто бы псевдо-SoC бьёт топовые AMD и Intel это булщит в любом случае.
Пример, когда приводят бенч мака на макоси, сравнивая его с бенчем пекарни на винде — это вот как раз из этой серии.если мы берем код бенчмарка, одинаковый для разных платформ, компилим под две платформы, на них соответственно запускаем, чем это не объективное сравнение? У вас конечно же могут быть претензии к алгоритму бенчмарка, но тогда надо говорить предметнее. Пока что причины почему про тот же antutu забыли, а geekbench взлетел, связаны с тем, что второй запускает один и тот же код на разных платформах.
Я повторюсь ещё раз, мне вообще до фонаря сколько какой проц выдаёт попугаев.когда люди вам говорят что на M1 у них код компилится быстрее чем на i9 mac pro, вам это тоже до фонаря? А ядер в нём поменьше, значит в этой задаче они не могут быть медленнее, так?
Факт в том, что в статье написано, чёрным по белому, мол М1 — самый быстрый камень.… Главный спорный момент тут в том, что утверждение будто бы псевдо-SoC бьёт топовые AMD и Intel это булщит в любом случае.в статье черным по белому написано что ядро чипа M1 почти самое быстрое, даже в сравнении с ядрами топовых intel/amd. А вот в переводе статьи написана фигня, но это никто и не оспаривает.
Ну давайте тогда, разрабатывайте сами бенч, который будет как-то вычислительную сложность итогового тестового алгоритма выравнивать с учётом архитектуры чипа, будет учитывать архитектуру ОСи, на которой запущен и т.д. и т.п. тогда будет объективность.эти вещи учтены в компиляторных оптимизациях, применяющихся при компиляции бенчмарка под платформу. Подавляющее большинство кода написано в абстракции от железа, на котором он будет исполняться. Часто сравнивают например производительность M1 при исполнении кода через rosetta2 и нативное исполнение x64, такие сравнения объективные? Ни разу ведь, потому что код совершенно разный. А их на ваших аггрегаторах дофига.
Почитайте истории про то как nVidia свои дрова оптимизировала чтобы в бенчах лидировать, было такое несколько лет назад.наверно можно оптимизировать чип чтобы он лучше себя показывал в паре бенчей, но уж точно не во всех. И тем более запаритесь оптимизировать чип под задачи обработки текста.
если мы берем код бенчмарка, одинаковый для разных платформ, компилим под две платформы, на них соответственно запускаем, чем это не объективное сравнение?
В том и проблема, что нет. Во первых, на платформах используются разные компиляторы, которые из одного кода на выходе дадут разный асемблер. Во вторых, даже у разных чипов разный подход к обработке одного и того же байткода. Если это чипы одной архитектуры, то логично их сравнивать. А если мы сравниваем разные архитектуры, тогда для объективности нужно сравнивать как каждая из них решает конкретный тип задач.
Возьмите ASIC-майнеры — там далеко не самый совершенный кремний, но в своей строго специализированной задаче они оставят далеко позади любой современный процессор. Значит ли это, что они самые быстрые на сегодняшний день?
когда люди вам говорят что на M1 у них код компилится быстрее чем на i9 mac pro, вам это тоже до фонаря? А ядер в нём поменьше, значит в этой задаче они не могут быть медленнее, так?
Если бы в статье было просто написано «маки на данных чипах — самые быстрые», никаких вопросов бы не были.
эти вещи учтены в компиляторных оптимизациях, применяющихся при компиляции бенчмарка под платформуЭто откуда у вас такая уверенность?
А их на ваших аггрегаторах дофига.
Ещё раз, это был всего лишь пример. Автор в статье оперирует псевдо-техническими понятиями, выгораживая чип как гениальное техническое решение. Приведение в пример любого рандомного агрегатора ничуть не хуже с точки зрения аргументирования — это ровно то натягивание совы на глобус.
наверно можно оптимизировать чип чтобы он лучше себя показывал в паре бенчей, но уж точно не во всех
Ну, то есть вы всё же признаёте, что какой-то один бенч считать объективным не очень правильно и нужны как раз агрегаторы, которые будут учитывать несколько, м?
В том и проблема, что нет. Во первых, на платформах используются разные компиляторы, которые из одного кода на выходе дадут разный асемблеркак вы собрались сравнивать чипы разных ISA на одинаковом ассемблере?
Если это чипы одной архитектуры, то логично их сравнивать. А если мы сравниваем разные архитектуры, тогда для объективности нужно сравнивать как каждая из них решает конкретный тип задач.ну вот для работы мне нужен ноут, который будет быстрым в браузере и программировании, то есть в задачах обработки текста. Значит я могу полагаться на бенчмарки, основанные на замерах производительности браузера и компиляции, так? А M1 там очень хорош
Это откуда у вас такая уверенность?от примерного представления как работает компилятор… Или вы про случаи реализаций алгоритмов через ручную векторизацию? В таких случаях качество реализации будет влиять больше, чем проц.
Автор в статье оперирует псевдо-техническими понятиями, выгораживая чип как гениальное техническое решениену согласитесь что сделать проц, способный потягаться с чипами в 2+ раза большего энергопотребления, довольно-таки круто. Работая на частоте в полтора раза ниже!
Это откуда у вас такая уверенность?от представления как работает компилятор?
Ну, то есть вы всё же признаёте, что какой-то один бенч считать объективным не очень правильно и нужны как раз агрегаторы, которые будут учитывать несколько, м?одно дело взять набор конкретных бенчмарков с воспроизводимыми цифрами и привести табличку, как они себя ведут для двух сравниваемых процов. Другое — взять всё множество доступных бенчей для каждого чипа по отдельности, не проверяя бенчи на адекватность, подставить циферки этих бенчей в никому не известную формулу и выдать прожеванный результат, который ни воспроизвести, ни перепроверить. Вы наверно хотите видеть сведенный в пару цифр результат прогона набора типовых бенчей, с кодом, одинаковым на разных платформах? Я вас удивлю, но именно так и работает гикбенч )
Т.е. вы в качестве аргумента приводите бенчи, где мак сравнивается с маком? Ахахах
Пример, когда приводят бенч мака на макоси, сравнивая его с бенчем пекарни на винде — это вот как раз из этой серии.
Забавно, что человека, который выдаёт /dev/random за бенчмарки, не устраивает ни сравнение в пределах одной платформы, ни сравнение кроссплатформенное :)
GB5 CPU/SPEC это бенчи, ориентированные на вычисления. Им плевать какая ОС. Windows, Linux, MacOS или Haiku. Они тестируют не ОС, не какие либо внешние акселераторы, а центральный процессор.
Ну давайте тогда, разрабатывайте сами бенч, который будет как-то вычислительную сложность итогового тестового алгоритма выравнивать с учётом архитектуры чипа, будет учитывать архитектуру ОСи, на которой запущен и т.д. и т.п. тогда будет объективность.
Так делал GB3 — для мобильных процессоров были свои датасеты. Поэтому результаты эти гроша ломаного не стоят.
Если вы изменили датасет или провели какую-то адаптацию под ОС, результат становится некорректным и сравнивать их друг с другом нельзя без учёта допустимой погрешности.
Почитайте истории про то как nVidia свои дрова оптимизировала чтобы в бенчах лидировать, было такое несколько лет назад.
В случае nVidia имеем байткод, который компилируется под целевую архитектуру GPU в рантайме. Компилятор драйвера может делать что угодно.
В случае CPU мы имеем заранее скопилированный под целевую архитектуру код. Никто его не меняет.
Автор в статье оперирует псевдо-техническими понятиями
И сколько вы из них слышали? =)
Знаете что хотя бы парочка означает?
Статья для людей которые что-то про процессор слышали,
а не для профессионалов.
выгораживая чип как гениальное техническое решение.
На это есть все основания.
habr.com/ru/post/538812/#comment_22587668
Забавно, что человека, который выдаёт /dev/random за бенчмарки, не устраивает ни сравнение в пределах одной платформы, ни сравнение кроссплатформенное :)
Хах. Вообще-то вы выдёргиваете из контекста — в первом случае речь про то, что такое сравнение странно использовать, когда ты говоришь, что чип лучше чем принципиально другая архитектура, а во втором речь о том, что объективных тестов единицы.
Если вы изменили датасет или провели какую-то адаптацию под ОС, результат становится некорректным и сравнивать их друг с другом нельзя без учёта допустимой погрешности.Ощущение, будто вы не бенчи сравниваете, а способы защиты их от фальсификации. К чему это вообще?
В случае CPU мы имеем заранее скопилированный под целевую архитектуру код. Никто его не меняет.Слышали что-нибудь о различиях в оптимизации различных компиляторов на разных платформах, м?
И сколько вы из них слышали? =)
Я понимаю, что вам, вероятно, сложно это представить, но у меня профильное образование.
такое сравнение странно использовать, когда ты говоришь, что чип лучше чем принципиально другая архитектура
Странно? Это самый идеальный вариант — тестирование на той же самой ОС, с тем же самым компилятором, только с другим процессором. Уровень достоверности результатов тут максимальный.
а во втором речь о том, что объективных тестов единицы.
Все объективные тесты показывают высокое быстродействие M1.
Оно не везде максимальное, но это low-end процессор от Apple, который приближается к прожорливым 5GHz десктопным процессорам.
Ощущение, будто вы не бенчи сравниваете, а способы защиты их от фальсификации.
Это принципиальный момент — если результат не валидный, что вы собрались сравнивать?
Слышали что-нибудь о различиях в оптимизации различных компиляторов на разных платформах, м?
Верно, как и то, что программы могут быть заточены под определённое железо, например AVX2.
Поэтому, к примеру, anandtech использует один компилятор (Clang). x86 и ARM бэкенды в нём достаточно зрелые.
Я понимаю, что вам, вероятно, сложно это представить, но у меня профильное образование.
Инженер-бенчмарколог? ;-)
Представить действительно сложно, потому что вы демонстрируете непонимание базовых вещей (к этому нет претензий) и пытаетесь спорить с фактами, что уже вызывает вопросы.
Объяснить разброс результатов в вашем рейтинге вы не можете?
habr.com/ru/post/538812/#comment_22589186
Если M1 вы называете «посредственное распиаренное говно», то что же такое i7-1065G7 (предыдущий флагман Интел) с 429 места?
technical.city/ru/cpu/Core-i7-1065G7
«Место в рейтинге производительности 429»
Жду таких же ярких эпитетов.
Странно? Это самый идеальный вариант — тестирование на той же самой ОС, с тем же самым компилятором, только с другим процессором.
Замедленные «устаревшие» айфоны передают привет. Вот такое почитай (и это не единичный случай): developer.apple.com/forums/thread/651399
Уровень достоверности результатов тут максимальный.
Это верно. Но тогда не надо писать что «чип быстрее большинства решений от Intel и AMD». Надо писать «На данной платформе чип быстрее большинства решений от Intel и AMD».
Тогда и претензий будет в разы меньше.
Это принципиальный момент — если результат не валидный, что вы собрались сравнивать?
Мы в текущем контектсе, всё же подразумеваем, что пользователи проводят честное тестирование, не изменяя бенчи.
Мы в текущем контектсе, всё же подразумеваем, что пользователи проводят честное тестирование, не изменяя бенчи.вы же выше писали что бенчмарки должны быть написаны с учетом особенностей каждой целевой платформы?
А товарищ выше за каким-то хреном завёл речь о намеренном изменении бенча для ускорения выполнения теста.
Чувствуете разницу?
Всё верно, под «учётом особенностей» я подразумеваю нормализацию времени работы алгоритма.что такое «нормализация времени работы алгоритма»?
А товарищ выше за каким-то хреном завёл речь о намеренном изменении бенча для ускорения выполнения теста.а товарищ понял вас так же, как и я. Выражайтесь яснее
что такое «нормализация времени работы алгоритма»?
Ну, по простому например — один чип умеет распарллеливать какие-то инструкции, а второй нет. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
а товарищ понял вас так же, как и я. Выражайтесь яснее
Отнюдь, его дальнейшие ответы говорят о том, что его заботит именно возможность подделки результатов.
один чип умеет распарллеливать какие-то инструкции, а второй нет. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
Еще у одного чипа выше частота, а у другого — ниже. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
А также у одного чипа больше объем кеша, а у другого — меньше. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
Кроме того, один чип лучше предсказывает ветвления, а другой — хуже. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
Помимо этого не стоит забывать, что у одного чипа больше ядер, а у другого — меньше. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
Ну и в конце концов, один чип потребляет больше энергии, а другой — меньше. Поэтому первый для одной задачи априори будет быстрее и сравнивать их одинаковым алгоритмом смысла нет.
Короче, я вас понял. Чипы лучше вообще не сравнивать. Ведь априори один быстрее окажется, так что какой смысл?
Если уж совсем невмоготу, то сравнивать исключительно по рандомным числам из ноунейм рейтинга. Ведь если никто не знает, откуда взялись сравниваемые значения — то и придраться никто не сможет. А если все таки придерется — всегда можно ответить "сам дурак" "камон, делайте свой".
Тут конечно переводчик накосячил, в оригинале формулировка более мягкая (almost beats) и более очевидная
Спасибо, исправил
Где тут, например, 9980XE
Смотрите, в этом и прелесть нормальной методологии по сравнению с рандомными числами. Если вы знаете, каким образом получаются сравниваемые значения, то вы можете просто загуглить "9980XE Cinebench R23" и узнать, что в однопотоке 9980XE набирает ~1100 попугаев с копейками. Или, изъясняясь близкими вам терминами, отсасывает у Firestorm.
почему M1 сравнивается не с текущим флагманом, а с 10850H?
А результаты "текущего флагмана" попробуйте узнать сами в качестве домашнего задания. Как это делать я описал выше. Я верю, что у вас все получится и вы разберетесь, кто у кого отсасывает. Я без понятия, что вы называете текущим флагманом. Разобраться в текущих номерах моделей интела из 5-6 цифр и 1-3 букв решительно невозможно.
www.cpu-monkey.com/en/cpu_benchmark-cinebench_r23_single_core-15
Т.е. даже по предложенному вами тесту он не «almost beats the fastest AMD Ryzen cores».
Выходит вы даже по вашим же аргументам, извините, оподливились.
Ну да, ну да. Вхождение в топ-10 наравне с десктопными cpu — это вовсе не показатель топовости. А разница аж в целых 7,5% с топ-1 — так вообще полный провал.
Дайте тогда свое определение "almost beats". Какой должна быть разница, чтобы вы ее признали за "almost beats"?
На олимпийских играх нынче отставание на 7.5% это даже не «бронзовая медаль».
На олимпийских играх нынче отставание на 7.5% это даже не «бронзовая медаль».тем не менее участники олимпийских игр наголову превосходят простых смертных…
Так что он ну скажем «где-то на уровне простых смертных». Лучше старичков, лучше ограниченных (лоу вроде Ryzen 3 и мобильных процов), но не более того.
Он уступил актуальному десктопному потребительскому лоу-миду (ryzen 5) который будет в большинстве офисных и средне-бюджетных домашних машин, т.е даже не миду (Ryzen 7) или флагману (Ryzen 9).ну это всё еще 65-ваттный десктопник на 5 гигагерцах против 25-ваттного мобильного чипа на 3.2. Это как сказать что «Вася бегущий всё-таки чутка обогнал Петю идущего, значит Вася быстрее». А если «Петя» побежит?
Обычно когда говорят что «M1 сравнялся с десктопными ryzen» пытаются донести мысль а-ля «вау M1 даже может в чем-то потягаться аж даже с ними!» а не «мобильный M1 уделал все десктопники на свете, склонитесь смерды!». Например если говорить о тех же мобильных AMD, 25-ваттник 5800U процентов на 15 быстрее своего предшественника 4800U в однопотоке; однако при этом всё еще процентов на 20 уступает M1. И даже их топовый мобильный и весьма горячий 5900HX.
Но это значит лишь что он ест меньше и греется меньше. Однако цепляться за эту характеристику при обсуждении производительности — ну такое себе (на что тут неоднократно и указали). Если бы они добились такой энергоэффективности при той же архитектуре — это было бы их достижением. А так — просто особенность архитектуры.
С частотой уже интереснее. Но тут вопрос — а может ли этот ARM в принципе в те же 5 Ггц, что и AMD/Intel? Если нет, то и обсуждать тут нечего ибо это будет обсуждение вида «ах если бы да кабы».
Так что пока что картина выглядит как «m1 на своих пиковых параметрах — уступает конкурентам на своих пиковых параметрах» (ну или «M1 на своих пиковых параметрах может соперничать с даунклокнутыми конкурентами».
Вот если в него завезут 5 Гц (хотя бы при тех же 65вт что и у конкурентов) и он будет их рвать, или (что еще интереснее) если он будет их рвать будучи на более низких частотах (и рвать в чем-то актуальном, а не в синглкоре) — тогда уже будет любопытно.
И лучше бы если бы он это делал в задачах, которые решаются на большистве ПК (в т.ч. рассчитанных на много RAM, применение внешних GPU и прочие радости), а не в Macbook-специфичных. Иначе он будет мало отличим от ASIC'ов, которые тоже свои задачи отлично решают, а вот общие задачи не решают никак.
Если бы они добились такой энергоэффективности при той же архитектуре — это было бы их достижением. А так — просто особенность архитектуры.ну так ARM чипы apple сильно превосходят ARM чипы конкурентов (qualcomm/samsung), в этом тоже нет достижения? Не вижу смысла в этом вашем аргументе
Если нет, то и обсуждать тут нечего ибо это будет обсуждение вида «ах если бы да кабы».Вы сейчас сначала обвинили меня в спекуляции, и тут же спекулируете что M1 работает на пределе возможностей. Но что мешает ARM работать на 5 ГГц? Это же ортогональная архитектуре характеристика, обусловленная по большей части техпроцессом.
Так что пока что картина выглядит как «m1 на своих пиковых параметрах — уступает конкурентам на своих пиковых параметрах»
Вот если в него завезут 5 Гц (хотя бы при тех же 65вт что и у конкурентов) и он будет их рвать, или (что еще интереснее) если он будет их рвать будучи на более низких частотах (и рвать в чем-то актуальном, а не в синглкоре) — тогда уже будет любопытно.если в него завезут 4 гигагерца, он (экстраполируя) будет рвать своих 5-6-гигагерцовых конкурентов в синглкоре, если в него завезут больше ядер (а ядра нынче наращиваются проще чем однопоточная производительность), будет уделывать и в мультикоре. И не надо недооценивать значимость однопоточной производительности. Банальный парсинг json'а уже эффективно не распараллелишь.
И лучше бы если бы он это делал в задачах, которые решаются на большистве ПК (в т.ч. рассчитанных на много RAM, применение внешних GPU и прочие радости), а не в Macbook-специфичных«большинство ПК» это либо офисные печатные машинки, либо бюджетные игровые. Еще в большинстве ПК нет ни поддержки thunderbolt3, необходимой для эффективной утилизации внешних GPU, ни 32 гигабайт RAM. О каких задачах речь то? Если я разработчик и выбираю ноут для разработки, то мне фиолетово какой там у ноута фпс в киберпанке, для этого у меня есть ПК. И макбук будет вполне адеватным выбором. А если мне нужна рабочая станция для CAD/ML или прочих прелестей, я подберу железо под задачу.
ну так ARM чипы apple сильно превосходят ARM чипы конкурентов (qualcomm/samsung), в этом тоже нет достижения?Ну так и сравнивайте в бенчах с другими АРМ-чипами, и статьи пишите «Почему M1 быстрее Snapdragon 12345». А то как «быстрее» — так десктопных, а как указывают в комментариях, что он быстрее только в конкретных ноутбучных задачах —
для этого у меня есть ПК
Не знаю как остальные, а я сижу на десктопе, и 200 ватт одному процессору не является такой уж проблемой.
Зато это является проблемой в дальнешем увеличении производительности этого самого процессора.
Достаточно открыть рейтинг производительности: technical.city/ru/cpu/rating
Найти там М1 на (!) 347 месте, посмеяться над автором и закрыть статью.
Пока что посмеяться можно только над теми, кто смотрит производительность на подобных бредовых сайтах.
Может объяснить какие там используются бенчмарки и как усредняются их результаты?
Тупо складывают все циферки и делят на количество? :)
Вы когда покупаете овощи в магазине, тоже кидаете всё в один пакет и взвешиваете по среднему арифметическому от цены?
Если вы хотите следовать букве формализма
Интересно. От вас просто требуется объяснить что за цифры вы тут привели.
Оценка с точки зрения абсолютной объективности это уже следующий шаг.
разработайте какой-нибудь абсолютно объективный способ тестирования
Какой разработали вы?
Какой разработали вы?
А я не делал никаких утверждений касательно производительности чипа.
Если хотите поумничать на тему сравнения скорости чипов, будьте добры показать рейтинг, который, по вашему, более объективен, чем тот который привёл я.
Пока всё выглядит так, словно вы отвалили кучу бабок за посредственное распиаренное говно, о котором идёт речь в статье, и вас, почему-то задевает, что оно, оказывается, далеко не топовое по производительности. Что ж, могу только посочувствовать.
А я не делал никаких утверждений касательно производительности чипа.
Вы утверждали, что ваша сслыка ведет на рейтинг производительности. А она ведет на рейтинг непонятно чего. Объяснить, откуда именно получаются значения из вашего рейтинга "производительности" вы до сих пор не смогли.
Если хотите поумничать на тему сравнения скорости чипов, будьте добры показать рейтинг, который, по вашему, более объективен, чем тот который привёл я.
Целых 2 штуки показал.
Пока всё выглядит так, словно вы отвалили кучу бабок за посредственное распиаренное говно, о котором идёт речь в статье, и вас, почему-то задевает, что оно, оказывается, далеко не топовое по производительности.
Вы там с крестиком и трусами разберитесь, что ли.
я не делал никаких утверждений касательно производительности чипа.
…
посредственное распиаренное говно… далеко не топовое по производительности
И приведите хоть один нормальный бенчмарк, демонстрирующий посредственную производительность M1. Для объективности — при близких паспортных TDP. В идеале — при близком фактическом потреблении энергии.
я не делал никаких утверждений касательно производительности чипа.
чип, якобы, самый быстрый, что не является истиной.
посредственное распиаренное говно
Ну ок =) К слову, в комментах есть разработчик процессоров Интел и он ваше мнение не разделяет.
будьте добры показать рейтинг, который, по вашему, более объективен, чем тот который привёл я.
Абсолютно любое измерение, о котором известно ЧТО измеряется, является более объективным чем рандомные цифры без источника.
Вот пример грамотно проведённого тестирования с код базой бенчмарка, который является индустриальным стандартом:
www.anandtech.com/show/16252/mac-mini-apple-m1-tested/4
Кому «отвалили бабок»? Интел, чтобы они сделали более медленный процессор?
и вас, почему-то задевает, что оно, оказывается, далеко не топовое по производительности
Я довольно однозначно показал что меня забавляет — это когда люди врываются с рандомными цифрами, о природе и значении которых они ничего не могут сказать и начинают ими пытаться что-то доказать.
Вот смотрите, в вашем
самый совершенный процессор Интел 2020г — Core i7-1185G7 на 318 месте (на данный момент).
technical.city/ru/cpu/Core-i7-1185G7
А древний i7-980X, который ему и в подмётки не годится на… 123
Это значит что надо срочно выбрасывать TigerLake и искать Gulftown на али?
Интересно, как сравнивались 22-ядерный Intel Xeon E5-2699A v4 с TDP 145W (на 222 месте) и ультрабучный 4750U с TDP 15W (на 209).
коих пока ещё очень многоСколько уже лет браузеры, офисные приложения, средства обработки графики и видео (особенно рендеринг) умеют пользоваться преимуществами многопоточности? А ещё не завбывайте, что даже если приложения А и Б работают только в одном потоке, то одновременно работающие А+Б — уже два потенциально выжирающих ресурсы потока. Если таковых становится 5 и более, то быстрые ядра M1 как-то кончаются.
Если бы в статье было бы написано что «M1 быстрее в однопоточных операциях чем топовые десктопные чипы жрущие 50-150 ватт», вопросов было бы в разы меньше, согласитесь.в статье так и написано, а вы читали перевод
И блок комментариев тоже встроим с оригинального сайта заодно…
Простите, а мы в камментах к статье разве беседуем?вы пытаетесь спорить с утверждением, которого не существует. Существует лишь ошибка перевода
Это система множества чипов, лежащих в одной кремниевой обертке. CPU же — это один из этих чипов. Технически, М1 — это весь компьютер на одном чипе. Он содержит CPU, графический процессор GPU, память, контроллеры входа/выхода и множество других вещей, делающих компьютер компьютером. Это мы называем системой на чипе (system on the chip, SoC).
То есть любой современный интел/амуде тоже SoC с контроллерами памяти и другой периферией внутри?
Apple лишь пошла более радикально по этому пути. Вместо множества ядер общего назначения, чип М1 внутри содержит:
Intel лишь пошла более радикально по этому пути. Вместо множества ядер общего назначения, чип Core i-7 внутри содержит:
— Центральный процессор CPU — “мозги” системы на чипе. Выполняет большинство задач компьютера и программ
— Графический процессор GPU — используется в обработке графики и изображения, в том числе и в играх.
— Блок обработки изображений ISP — используется для увеличения производительности во время работы приложений по обработке графики.
— Обработчик цифровых сигналов (digital signal processor, DSP) — Выполняет более сложные математические функции, чем центральный процессор, включая декомпрессию музыкальных и видеофайлов.
— Блок нейронной обработки (Neural processing unit, NPU) — используется в топовых смартфонах, чтобы ускорить работу машинного обучения и AI.
— Кодировщик видео (Video encoder/decoder) — для энергоэффективного преобразования видео разных форматов.
— Блок безопасности (Secure Enclave) — шифрование, аутентификация и безопасность.
— Блок единой памяти (кэш) — позволяет модулям чипа взаимодействовать максимально быстро.
Если системы SoC такие “умные”, то почему Intel и AMD не следуют той же стратегии?
Делают.
Почему выполнение ОоОЕ процессорами Intel и AMD уступает чипу М1?
Видимо потому, что так написал какой-то дурень в рекламной статье.
Самый большой и “подлый” процессор Intel имеет на борту 4 декодера. А чип М1 — неслыханные 8 декодеров — значительно больше, чем кто бы то ни было до этого.
Что насчёт плотности кода и разного объёма инструкций для декодирования?
Для процессоров CISC зачастую нет других решений, кроме микро-операций, формирующих длинные последовательные цепочки. Это исключает использование ОоОЕ.
Схуяле? После декодирования CISC свои микроинструкции и переставляет (спекулятивное исполнение) или объединяет в одну длинную (суперскалярность).
Правда не совсем понял, что мешает Intel и Amd частично перейти на Arm и сделать все это «более менее грамотно» вместе с крупными производителями софта вроде Microsoft?
В конечном итоге, непрерывное увеличение лидирования Apple и в этом направлении вынудит отстающих объединяться, не смотря на их фрагменитрованность.
Или тут все упирается в legacy-код для x86?
Спасибо. Как уже отметили выше, проблема перехода на ARM заключается как раз в обратной совместимости и договоренностях с другими производителями железяк для компьютера.
Никогда нельзя исключать и человеческий фактор, ведь принимает решение об экспериментах в области применения ARM тоже человек — СЕО — а он может и не верить в ARM в силу субъективных суждений
Я вот честно не понимаю одного. Где этот процессор быстрый? Неужели с бесконечным бабками можно аж настолько ссать в уши людям?
Есть у меня ноутбук асус какой-то там, сейчас такие стоят 30к на Авито, в нем 7700hq и 1050ти.
6к БМ Рав в фхд он рендерит на процессоре 18 к/с, на видеокарте 24 к/с. Очень быстрый М1 этим занимается со скоростью 12 к/с.
Скорость тут в чем? Во вранье? Современный (почти) ноутбук с ртх2060 делает это уже со скоростью 45 к/с.
Поясните мне почему такой быстрый М1 быстрый только в статьях в интернете?
— M1 (почти) самый быстрый существующий процессор!
— Только в однопоточном режиме, а у нас уже много лет как умеют параллелить вычисления, так что не принимается.
— Зато он потребляет меньше энергии!
— Ты говорил про производительность, а как тебе привели адекватный контраргумент — сразу же съехал на энергопотребление. Это вообще-то разные величины.
— Сам дурак!
Ну право, сколько можно?
На этот раз компиляция исходников WebKit.
Результат: Macbook Pro i9, который стоит в несколько раз дороже, отстает по всем тестам. Не просто отстает, а очень серьезно.
Было бы интересно сравнить время сборки (кросскомпиляции) одного и того же проекта для одной и той же целевой платформы на x86_64 и M1.
Конкретно в этом случае сложно что-то комментировать, т.к. тут мало того, что нет ссылки на тест, так еще и результаты по сути не указаны, лишь загадочное "Не просто отстает, а очень серьезно".
Но в целом — нет, вы не особенный. Об этом задумывались многие. И именно поэтому в большинстве тестов (во всяком случае тех, на которые я натыкался) сравнивается именно кросс-компиляция для одной и той же целевой платформы. Либо под iOS (т.е. целевая архитектура arm64), либо Universal binaries под macOS (т.е. целевые и arm64, и x86_64).
Почему чип Apple M1 такой быстрый?