

Как сделать так, чтобы любой разработчик мог быстро накидать решение своей проблемы и гарантированно доставить его в прод? Деплоить приложение просто. Сделать из него полноценный продукт, чтобы десяток команд использовал его на сотне инстансов — сложнее. А если речь про мастер-систему на несколько терабайт, то уровень тревожности повышается, руки потеют, а база трещит по швам (может быть).
Я хочу поделиться способом деплоить без простоя и без отказа в обслуживании. Пайплайн на Jenkins, ноль посредников, 500 инстансов в production-среде за 60 минут. Всё это в опенсорсе. За подробностями приглашаю под кат.
Меня зовут Роман Проскин, я занимаюсь созданием и поддержкой высоконагруженных систем на основе Tarantool в Mail.ru Group. Расскажу, как наша команда строила деплой приложения на Tarantool, который обновляет код в production-среде без простоя или отказа в обслуживании. Опишу проблемы, с которыми мы столкнулись в процессе, и какие решения выбрали в итоге. Надеюсь, наш опыт будет полезен при построении вашего деплоя.
Задеплоить приложение просто. Для Tarantool есть утилита cartridge-cli (github). С ней кластерное приложение будет развёрнуто где-нибудь в Docker за пару минут. Гораздо сложнее сделать из решения «на коленке» полноценный продукт. Он должен легко справиться с сотнями инстансов. При этом нужно быть востребованным в десятках команд разного уровня подготовки.
Идея нашего деплоя очень простая:
- Берёшь два железных сервера.
- На каждом запускаешь по инстансу.
- Объединяешь их в один набор реплик.
- Обновляешь по очереди.
Но когда речь заходит о мастер-системе с объёмом данных в несколько терабайт, то уровень тревожности повышается, руки потеют, а база трещит по швам (может быть).
Задаём начальные условия
У системы есть жёсткий SLA: необходимо обеспечить доступность 99 % с учётом плановых работ. Это означает, что в году есть суммарно 87 часов, когда мы можем позволить себе не отвечать на запросы. Кажется, что 87 часов — это много, но…
Проект рассчитан на объём данных около 1,8 Tб. Только рестарт будет занимать 40 минут! Само обновление, если изменения накатывать вручную, добавит ещё сверху. В неделю совершаем три обновления: итого 40*3*52/60 = 104 часа — SLA нарушен. А это лишь плановые работы без учёта аварий, которые непременно произойдут.
Приложение разрабатывалось под высокую пользовательскую нагрузку, а значит, должно было отвечать требованиям стабильности. Чтобы не терять данные в случае отказа узла, мы решили территориально разделить наш кластер на два ЦОДа. Так мы определились с механизмом деплоя, который бы не нарушал SLA. Пусть инстансы обновляются не сразу, а пачками по дата-центрам.
На второй ЦОД можно перевести нагрузку, тогда в течение всего обновления кластер будет доступен на запись. Это классический поплечевой деплой и одна из стандартных практик disaster recovery.
Возможность обновления по дата-центрам — это один из ключевых элементов деплоя без простоя. Подробнее о процессе я расскажу под конец статьи, а пока остановлюсь на особенностях нашего бесчеловечного деплоя и трудностях, с которыми мы столкнулись
Проблемы
Переводим трафик через дорогу
Есть несколько дата-центров и запросы могут поступить в любой из них. Поход за данными в соседний ЦОД увеличит время ответа на 1-100 мс. Чтобы избежать перекрёстного трафика, мы дали нашим дата-центрам метки активный и резервный. Балансировщик (nginx) настраивается так, чтобы трафик всегда бежал в активный дата-центр. В случае падения или недоступности Tarantool в активном ЦОДе происходит автоматическое переключение на резерв.
Каждый пользовательский запрос важен, поэтому нужен способ гарантированно сохранять подключения. Для этого мы написали отдельный ansible-плейбук, который переключает трафик между ЦОДами. Переключение реализовано с помощью директивы
backup в описании upstream для сервера. Лимитом выбираются апстримы, которые станут активными. Остальным прописывается backup: nginx пустит на них трафик, только если все активные будут недоступны. При изменении конфигурации открытые подключения не закрываются, а новые запросы пойдут на роутеры, которые не попадают под рестарт.Что можно предпринять, если в инфраструктуре нет внешнего балансировщика? Напишите свой мини-балансер на Java, который будет следить за доступностью инстансов Tarantool. Но эта отдельная подсистема будет требовать и собственного деплоя. Другой вариант — встроить механизм переключения внутрь роутеров. Одно остаётся неизменным: HTTP-трафик нужно контролировать.
С nginx разобрались, но проблемы на этом не закончились. Переключение нужно проводить и для мастеров в наборах реплик. Как я уже упоминал, данные необходимо держать близко к роутерам, чтобы исключить лишние походы по сети. Более того, при падении текущего мастера (то есть экземпляра хранилища с правами на запись) механизм failover срабатывает не моментально. Пока кластер принимает общее решение о недоступности инстанса, все запросы к затронутой части данных будут ошибочны. Для решения этой проблемы тоже понадобилось составить плейбук, где мы использовали GraphQL-запросы к API кластера.
Механизмы смены мастеров и переключения пользовательского трафика являются последними ключевыми элементами деплоя без простоя. Контролируемый балансировщик позволяет избежать потери соединений и ошибок в обработке пользовательских запросов, а смена мастеров — ошибок с доступом к данным. Вместе с обновлением по плечам из этих трёх столпов получается отказоустойчивый деплой, который мы в дальнейшем ещё и автоматизировали.
Боремся с legacy
У заказчика уже был готовый механизм раскатки: роли, которые пошагово разворачивали и настраивали инстансы. Затем пришли мы с волшебным ansible-cartridge (github), который решит все проблемы. Мы не учли лишь, что сам ansible-cartridge представляет из себя монолит — одну большую роль, разные стадии которой разделены метками и отдельными задачами. Чтобы полноценно его использовать, нужно было изменить процесс доставки артефакта, пересмотреть структуру директорий на целевых машинах, сменить оркестратор и сделать многое другое. Я потратил месяц на доработку деплоя с помощью ansible-cartridge. Монолитная роль просто не вписывалась в готовые плейбуки. В таком виде использовать её не вышло, и меня остановил справедливый вопрос коллеги: «А оно нам надо?»
Мы не сдавались — от цельного куска отделили настройку кластера, а именно:
- объединение экземпляров хранилища в наборы реплик;
- бутстрап vshard (механизм шардирования данных в кластере);
- настройку failover (автоматическое переключение мастеров в случае падения).
Это заключительные этапы деплоя, когда все инстансы находятся в рабочем состоянии. К сожалению, все остальные этапы пришлось оставить как есть.
Выбираем оркестратор
Код на серверах бесполезен, если его нельзя запустить. Нужна утилита для запуска и остановки инстансов Tarantool. В составе ansible-cartridge есть задачи для создания systemctl service-файлов и работы с rpm-пакетами. Но спецификой нашей задачи было наличие закрытого контура у заказчика и отсутствие привилегий sudo. Это означает, что воспользоваться systemctl мы не могли.
Вскоре мы нашли оркестратор, который не требует постоянных root-привилегий — supervisord. Пришлось предварительно установить его на все серверы, а также решить локальные проблемы с доступом к socket-файлу. Для работы с supervisord появилась собственная ansible-роль: в неё вошли задачи по созданию конфигурационных файлов, обновлению конфига, запуску и остановке инстансов. Этого было достаточно, чтобы выйти в production.
Ради эксперимента мы добавили в ansible-cartridge возможность запуска приложения с помощью supervisord. Этот способ оказался менее гибким и пока ожидает доработки в отдельной ветке.
Уменьшаем время загрузки
Какой бы оркестратор мы не использовали, мы не можем ждать по часу, пока инстанс запустится. Пороговое значение — 20 минут. Если инстанс будет недоступен дольше этого порога, то сработает автоматическая авария и запишется в систему учёта. Частые аварии влияют на ключевые показатели команд и могут подорвать планы по развитию системы. Совсем не хочется терять премию из-за банально необходимого деплоя. Во что бы то ни стало нужно уложиться в 20 минут.
Факт: время загрузки напрямую зависит от объёма данных. Чем больше нужно поднять из логов в оперативную память, тем дольше инстанс запускается после обновления. Также нужно принять во внимание, что экземпляры хранилища на одной машине будут конкурировать за ресурсы: Tarantool при построении индексов задействует все ядра процессора.
Исходя из наблюдений, размер
memtx_memory на один инстанс не должен превышать 40 Гб. Такое значение оптимально для того, чтобы восстановление инстанса занимало менее 20 минут. Количество инстансов на одном сервере рассчитывается отдельно и тесно связано с инфраструктурой проекта.Подключаем мониторинг
За любой системой нужно наблюдать, и Tarantool не является исключением. Наш мониторинг появился не сразу. Целый кварта́л ушёл на получение необходимых доступов, согласования и настройку окружения.
В процессе разработки приложения и написания плейбуков мы слегка доработали модуль metrics (github). Теперь можно разделять метрики по названию инстанса, с которого они прилетели — сделали глобальные лейблы. Как результат интеграции с системами мониторинга появилась целая роль для кластерных приложений. Новый тип метрик quantile тоже возник в результате обобщения требований к нашей системе.
Теперь мы видим текущее количество запросов к системе, размер используемой памяти, лаг репликации и многие другие ключевые метрики. Дополнительно на них настроены оповещения с уведомлением в чаты. Самые критичные проблемы попадают в общую систему автоаварий и имеют чёткий SLA на устранение.
Немного про инструменты. Подробное описание где, что и как брать, собрано в etcd, откуда агент telegraf получает свои указания. Метрики в JSON-формате складируются в InfluxDB. В качестве визуализатора мы использовали Grafana, для которого даже написали шаблонный дэшборд. Ну и, наконец, алерты настроены через kapacitor.
Конечно, это далеко не единственный вариант реализации мониторинга. Можно использовать Prometheus, причем metrics как раз умеет отдавать значения в нужном формате. Для алертов может пригодиться и zabbix, например.
Подробнее про настройку мониторинга для Tarantool рассказал мой коллега в статье «Мониторинг Tarantool: логи, метрики и их обработка».
Настраиваем логирование
Нельзя ограничиваться мониторингом. Для получения полной картины происходящего с системой следует собирать всю диагностику, а это подразумевает и логи. При этом чем выше уровень логирования, тем больше отладочной информации и тем больше лог-файлы.
Место на диске не бесконечно. Наше приложение могло генерировать до 1 Тб логов в день при пиковой нагрузке. В такой ситуации можно добавлять диски, но рано или поздно кончится либо свободное место, либо бюджет проекта. А ведь бесследно терять отладочную информацию тоже не хочется! Что делать?
Одной из стадий деплоя мы добавили настройку logrotate: держим пару 100-мегабайтных файлов в сыром виде и ещё парочку сжимаем. При нормальной эксплуатации этого достаточно, чтобы найти локальную проблему в течение суток. Логи лежат в строго определённой директории в JSON-формате. На всех серверах крутится демон filebeat, который собирает логи приложений и отправляет их на длительное хранение в ElasticSearch. Этот подход спасает от ошибок переполнения дисков и оставляет возможность анализировать работу системы при длительных проблемах. А ещё этот подход хорошо встраивается в деплой.
Масштабируем решение
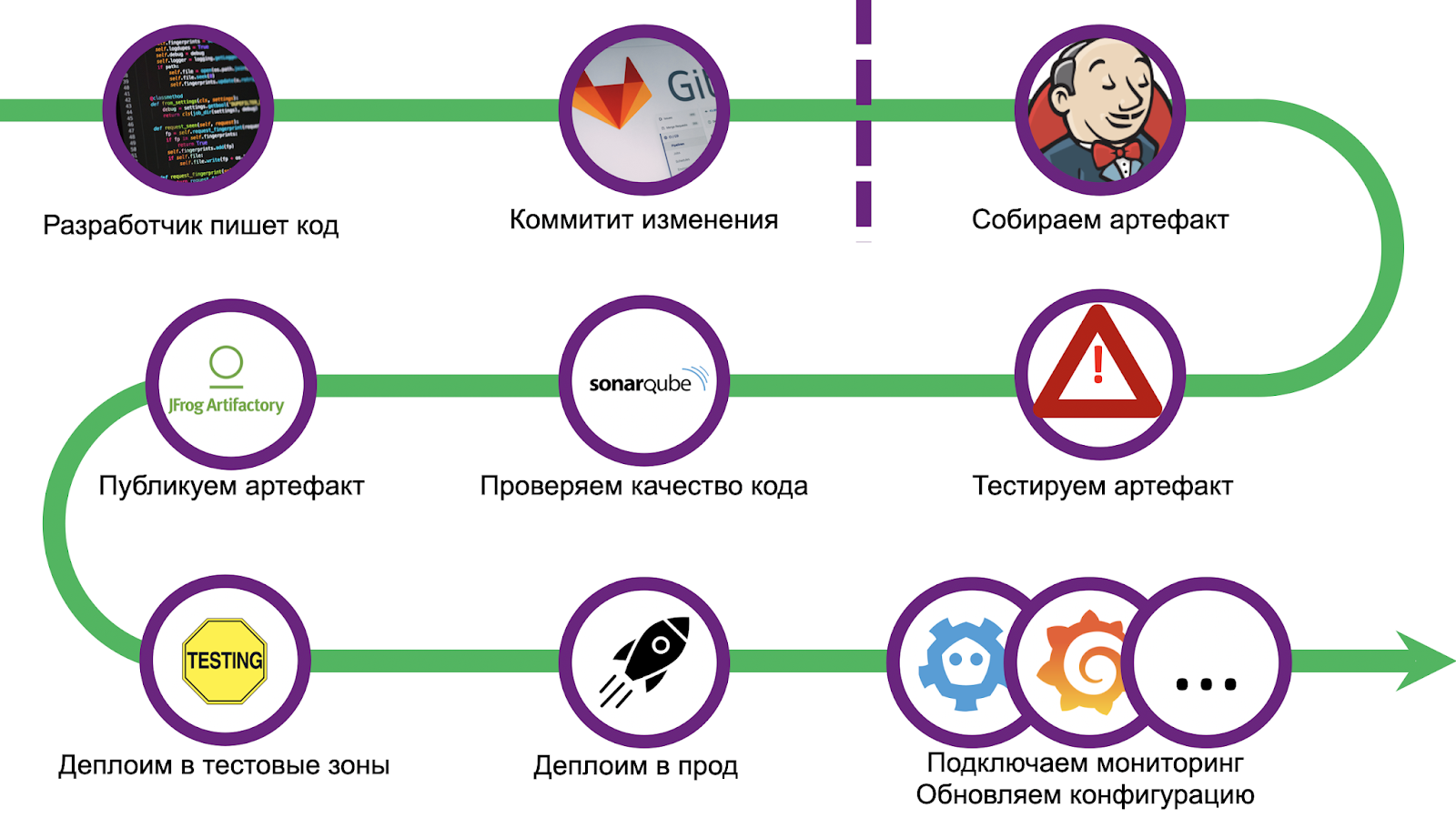
Путь был долгий и тернистый, мы набили приличное количество шишек. Чтобы не повторять ошибки, мы стандартизировали деплой и воспользовались связкой CI/CD — Gitlab + Jenkins. Масштабирование тоже вызвало ряд проблем, отладка решения заняла не один месяц. Но мы справились, а теперь готовы поделиться опытом с вами. Пройдёмся по шагам.
Как сделать так, чтобы любой разработчик мог быстро накидать решение своей проблемы и гарантированно доставить его в прод? Отобрать у него Jenkinsfile! Необходимо очертить жирные границы, выход за которые означает невозможность деплоя, и направить разработчика по этому пути.
Мы сделали полноценное приложение-пример, которое точно так же выкатили в прод и которое является исчерпывающим начальным звеном. Но мы с заказчиком пошли ещё дальше: написали утилиту для автоматического создания шаблона, которая настраивает git-репозиторий и Jenkins-задачи. На всё про всё разработчику понадобится меньше часа, и проект окажется в проде.
Пайплайн начинается со стандартной проверки кода и настройки окружения. Дополнительно мы подкладываем инвентари для последующего деплоя в несколько функциональных тестовых зон и прод. Затем наступает этап модульных тестов.
Используется стандартный для Tarantool тестовый фреймворк luatest (github). В нём можно писать как модульные, так и интеграционные тесты, есть вспомогательные модули для запуска и настройки Tarantool Cartridge. Также в последних версиях можно включить coverage. Запускаем простой командой:
.rocks/bin/luatest --coverageПо окончании тестов собранная статистика отправляется в SonarQube — ПО для оценки качества и безопасности кода. Внутри у нас уже настроен Quality Gate. Под проверку подпадает любой код в приложении вне зависимости от языка (Lua, Python, SQL и т.д.). Однако встроенного обработчика для Lua нет, поэтому для представления coverage в generic-формате у нас имеются подключаемые модули, которые устанавливаются до начала тестов.
tarantoolctl rocks install luacov 0.13.0-1 # утилита для сбора coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 # дополнительные отчетыПростой консольный вариант можно посмотреть так:
.rocks/bin/luacov -r summary . && cat ./luacov.report.outОтчёт для SonarQube формируется командой:
.rocks/bin/luacov -r sonarПосле coverage наступает этап линтера. Мы используем luacheck (github), который также является одним из подключаемых модулей Tarantool.
tarantoolctl rocks install luacheck 0.26.0-1Результаты линтера тоже отправляются в SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.luaСтатистика покрытия кода и линтер учитываются совместно. Для прохождения Quality Gate должны быть выполнены все условия:
- покрытие кода тестами должно быть не менее 80 %;
- изменения не должны вносить новых запахов;
- общее количество критических проблем — 0;
- общее количество некритичных косяков меньше 5.
После прохождения Quality Gate нужно испечь артефакт. Поскольку мы решили, что все приложения будут использовать Tarantool Cartridge, то для сборки применяем cartridge-cli (github). Это небольшая утилита для локального запуска (по сути, разработки) кластерных приложений на Tarantool. Еще она умеет создавать Docker-образы и архивы с кодом приложения, причем как локально, так и в Docker (например, если нужно собрать артефакт под другую архитектуру). Сборка
tar.gz выполняется командой:cartridge pack tgz --name <nаme> --version <vеrsion>Полученный архив далее заливаем в любой репозиторий, например, в Artifactory или Mail.ru Cloud Storage.
Деплоим без простоя
И заключительный шаг пайплайна — сам деплой. В зависимости от состояния правок раскатка выполняется в разные тестовые зоны. Одна зона выделена под любой чих: каждый пуш в репозиторий запускает весь пайплайн. Ещё есть несколько функциональных зон, где можно протестировать взаимодействие с внешними системами, для этого необходимо создать merge request в master-ветку репозитория. А вот в production раскатка запускается только после принятия изменений и нажатой кнопки merge.
Напомню ключевые элементы нашего деплоя без простоя:
- обновление по дата-центрам;
- переключение мастеров в наборах реплик;
- настройка балансировщика на активный дата-центр.
При апгрейде нужно следить за совместимостью версий и схемы данных. Обновление остановится, если на любом из шагов возникнет ошибка.
Схематично обновление может быть представлено следующим образом:
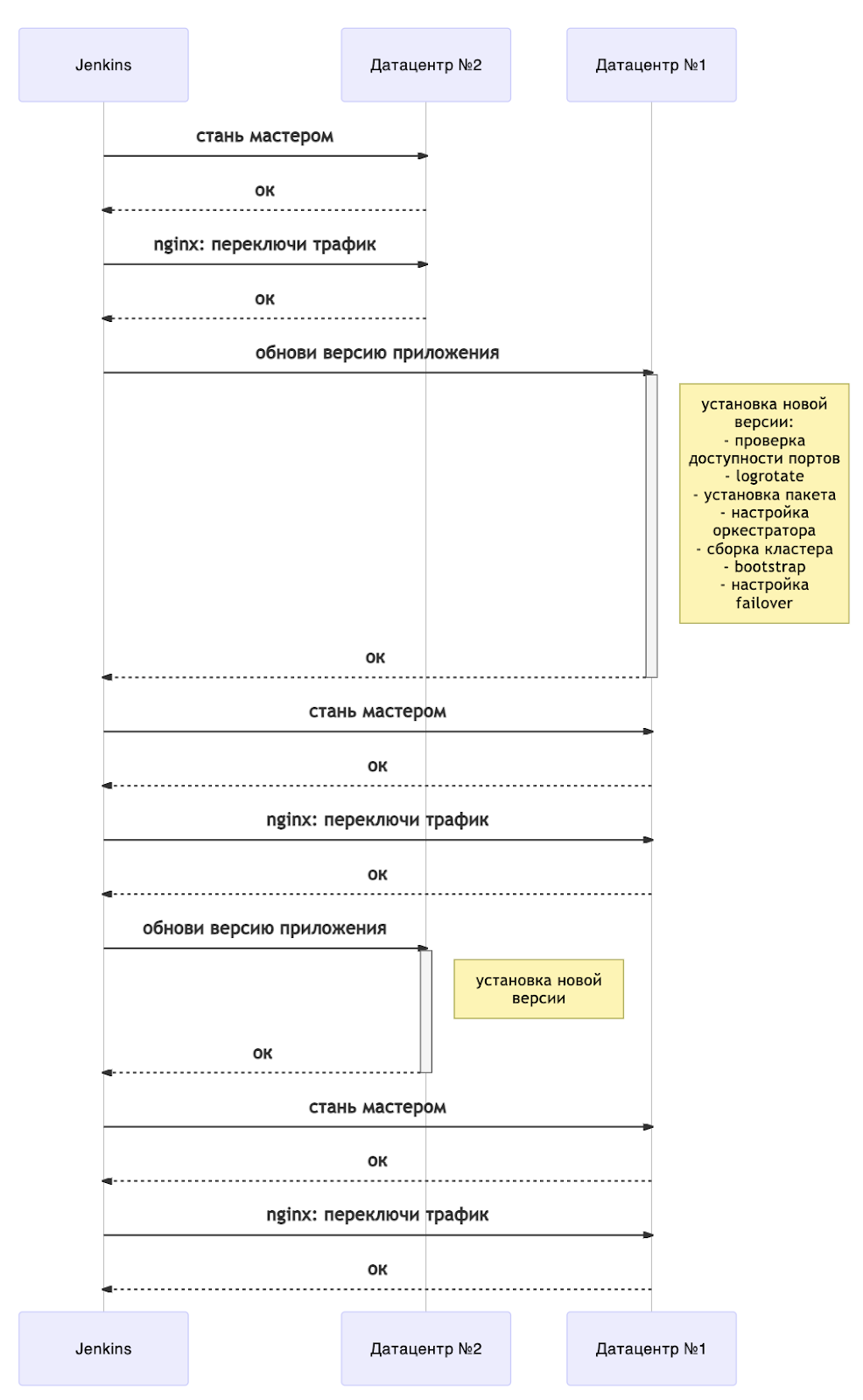
Сейчас любое обновление сопровождается перезапуском серверов. Чтобы понимать, когда можно продолжить деплой, у нас есть отдельный плейбук ожидания состояния инстансов. В Tarantool Cartridge есть конечный автомат, и мы ждём состояния RolesConfigured, которое означает полную настройку инстанса (а для нас — готовность принимать запросы). Если же приложение деплоится в первый раз, то нужно ожидать состояния Unconfigured.
В целом, схема показывает общее представление деплоя без простоя. Оно легко масштабируется на бóльшее количество дата-центров. В зависимости от потребностей, можно обновлять все резервные «плечи» сразу после смены мастеров (то есть вместе с дата-центром №1) или по очереди.
Конечно же, мы не могли не принести наши наработки в опенсорс. Пока что они доступны в моём форке ansible-cartridge (opomuc/ansible-cartridge), но в планах перенести это в мастер-ветку основного репозитория.
Пример можно найти тут (example). Для его корректной работы на сервере должен быть настроен
supervisord для пользователя tarantool. Команды для настройки можно подсмотреть тут. Архив с приложением также должен содержать бинарь tarantool. Последовательность команд для запуска поплечевого деплоя:
# Устанавливаем приложение (для начального деплоя)
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# Теперь обновим версию до 1.2.0
# Переносим мастер в dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# Обновляем основной ДЦ — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# Переносим мастер в dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# Обновляем резервный ДЦ — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# Удостоверимся в том, что мастеры в dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1Параметр
base_dir указывает на путь к «домашней» директории проекта. После раскатки будут созданы подкаталоги: <base_dir>/run— для сокетов управления и pid-файлов;<base_dir>/data— для .snap и .xlog файлов, а также конфигурации Tarantool Cartridge;<base_dir>/conf— для настроек приложения и конкретных инстансов;<base_dir>/releases— для версионирования и исходного кода;<base_dir>/instances— для ссылок на актуальную версию по каждому экземпляру приложения.
Параметр
cartridge_package_path говорит сам за себя, но есть особенность:- если путь начинается с
http://илиhttps://, то артефакт будет предварительно загружен из сети (например, с поднятого рядом artifactory). - в остальных случаях поиск файла происходит локально
Параметр
app_version будет использоваться для версионирования в папке <base_dir>/releases. Значение по умолчанию — latest.Тэг
supervisor означает, что в качестве оркестратора будет использован supervisord.Есть множество вариантов запуска деплоя, но самый надёжный — старый добрый
Makefile. Условную команду make deploy можно включить в любой CI\CD и всё будет работать точно так же.Итоги
Вот и всё! У нас появился готовый пайплайн на Jenkins, мы избавились от посредников, а скорость доставки изменений стала безумной. Количество пользователей растёт, в production-среде крутится уже 500 инстансов, развёрнутых исключительно с помощью нашего решения. Нам есть куда расти.
И пусть сам процесс деплоя по плечам далёк от идеала, он даёт прочную опору для дальнейшего развития DevOps-процессов. Можно смело брать нашу реализацию, чтобы быстро доставить систему в прод и не бояться делать частые правки.
А ещё для нас будет уроком, что нельзя принести монолит и надеяться на его повсеместное использование: необходима декомпозиция плейбуков, выделение ролей под каждый этап инсталляции, гибкий способ представления инвентаря. Когда-нибудь наши наработки попадут в master, и всё будет ещё лучше!
Ссылки
- Пошаговое руководство для ansible-cartridge:
- Про Tarantool Cartridge можно почитать тут.
- Про деплой в Kubernetes:
- Мониторинг Tarantool: логи, метрики и их обработка.
- За помощью обращайтесь в Telegram-чат.
