Сегодня расскажем, как можно обеспечить эффективный мониторинг для сложного ИТ-продукта и какие процессы можно автоматизировать, чтобы упростить работу саппорт-инженеров.
Именно с мониторинга стоит начинать постановку продукта на техподдержку. И уже на этом фундаменте выстраивать технологию обработки обращений (Incident Management) и развивать системный подход к решению проблем (Problem Management).
Мониторинг даёт возможность выстраивать проактивный подход в техподдержке. Специалисты узнают о проблемах не когда сбой уже произошёл, а реагируя на первые тревожные сигналы.
В общем и целом мониторинг отвечает на два главных вопроса:
Жива ли вообще система?
Могут ли пользователи выполнять нужные им операции?
Далее расскажем, как организовать мониторинг, который даст вам эти ответы.
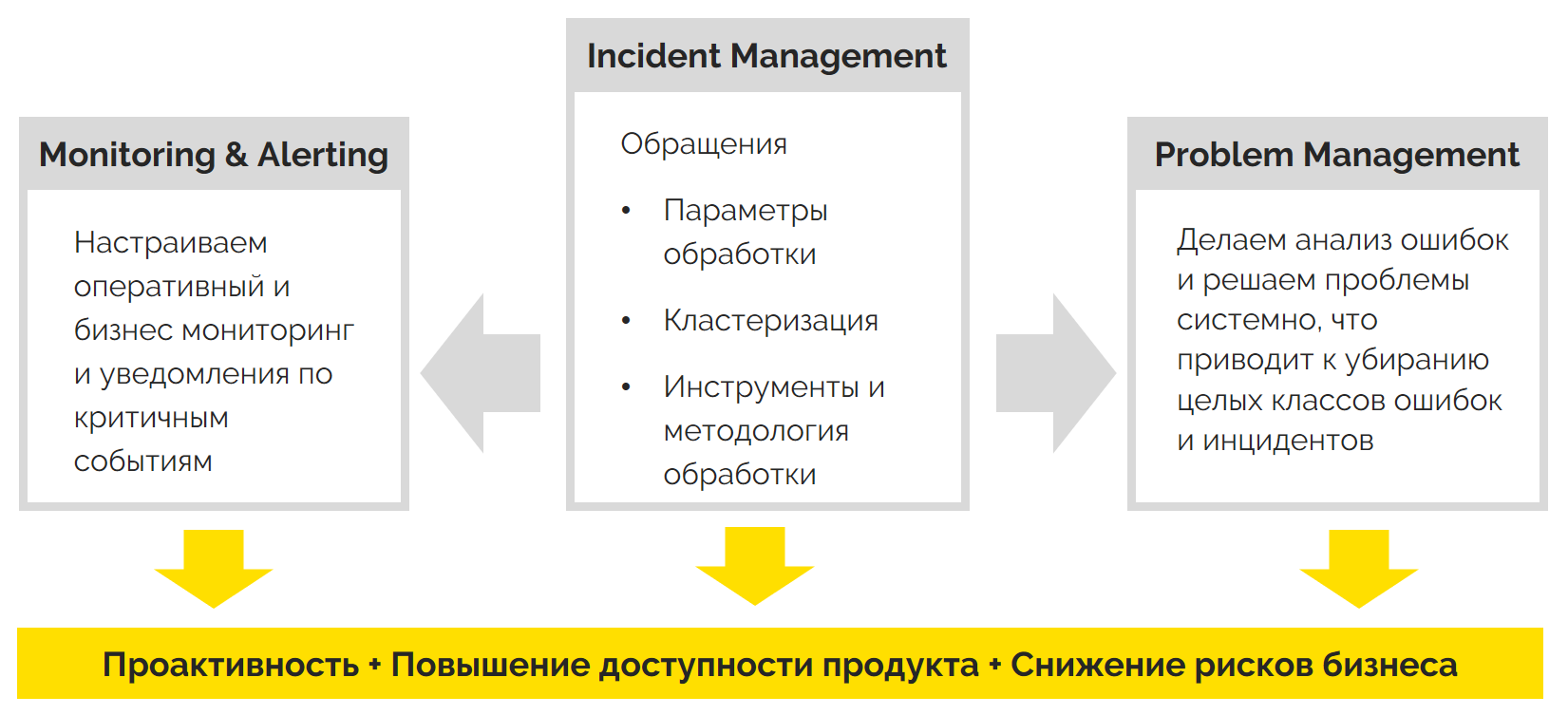
Какой бывает мониторинг
Технический – проверяет состояние программно-аппаратных компонентов.
Этот мониторинг отвечает на вопросы: как работает каждый отдельный компонент системы? Все ли сервисы пингуются? Не теряются ли запросы к модулям? Всё ли в порядке с сетевой инфраструктурой?
Бизнесовый – проверяет состояние ключевых фич и их влияние на бизнес-показатели.
Здесь применяются пользовательские сценарии, чтобы проверить, как система справляется со своими верхнеуровневыми функциями.
Как правило, с техническим мониторингом у команд проблем не возникает. Трудности зачастую вызывает настройка бизнес-мониторинга – нашему подходу к решению этой задачи и посвящен этот выпуск.
Четыре шага к запуску бизнес-мониторинга
1. Встаем на место пользователя
На первом шаге вы описываете все действия, которые пользователи выполняют в продукте. Расписываете по шагам, что нужно сделать в интерфейсе, чтобы получить тот или иной результат.
Удобно это делать в таблице. На этом этапе в ней появляются колонки:
цель
действия,
критерии критичности,
тип ситуации (штатная/нештатная)

На выходе вы получаете подробное руководство по всем операциям, для которых в принципе используется продукт. По этим данным далее можно готовить тесты, чтобы автоматически проверять, выполняет ли система свои задачи с точки зрения непосредственных пользователей.
2. Переводим с человеческого на машинный
Чтобы автоматизировать эти проверки, это руководство нужно перевести на язык скриптов. Действия пользователя нужно соотнести с конкретными запросами в конкретные сервисы.
Чтобы понять, на что смотреть в выдаче, в таблице добавляем данные:
URL,
тип запроса,
данные,
на что смотрим в ответе.
По результатам этой работы ваша таблица превращается из описания сценариев в полное руководство со всеми запросами, данными в логах, которые говорят о положительном или негативном результате (работает – не работает).

3. Налаживаем авторизацию (опционально)
Большинство корпоративных систем закрыты от внешнего интернета, и для таких случаев нужно решить вопрос авторизации. То есть технически обеспечить возможность системам мониторинга отправить запрос в микросервис и получить данные.
Для этого пишется отдельный модуль, который умеет получать авторизационные данные и передавать их службе мониторинга. Технически это похоже на кукисы в браузере – система, которую мы отслеживаем, передаёт авторизационному сервису токен с ограниченным периодом жизни, а средства мониторинга по этому токену подтверждают право доступа.
4. Автоматизируем и запускаем в работу
Теперь можно начинать автоматизацию и готовить алёрты для процессов. Разработчики пишут скрипты, чтобы имитировать пользовательские действия по списку сценариев. Здесь нужно опираться на бизнес-задачи, смотреть, к какому времени поддержка должна узнать о сбое процесса, чтобы успеть предпринять действия.
Эти скрипты можно «скормить» практически любой системе мониторинга. Лично нам нравится Zabbix, но это может быть Grafana или другой аналитический движок, с которым вы работаете. В вашей таблице есть всё что нужно для настройки.
В результате у нас появляется механизм, который умеет авторизоваться в системе и отправить post-запросы её службам. Остаётся обозначить пороговые значения алёртов и настроить логику отчётов. И ваш мониторинг запущен в эксплуатацию.
Заключение
Наш опыт показывает, что зачастую продуктовая команда сама усложняет себе задачу, слишком погружаясь в технологические параметры. На самом деле процесс прост и прозрачен. Мы показали это на живом примере.
Ключ к решению – это побывать в шкуре пользователя, который каждое утро заходит в систему и проверяет, справляется ли она с его задачами. Если идти к технике через смысл продукта, путь к цели становится гораздо короче, а результаты мониторинга оказывается проще трактовать и контролировать.
В следующем посте поделимся инструментами, которые помогают нашей поддержке работать с мониторингом без лишних манипуляций с кодом.







