Комментарии 41
Приведённые примеры отбирались вслепую, или все же были выбраны для вашей модели одни из наиболее удачных? Поймите меня правильно, просто ваши примеры, хоть их всего два, выглядят более естественными (на мой субъективный, разумеется, взгляд), чем остальные. Круто в любом случае.
Это первые два примера из 10 которые я сделал для статьи. Подумал, что все 10 это уж очень много текста. Вообще они средние, есть получше, но есть и хуже ситуации. YaML, например, знает, что теорию гравитации создал Ньютон, а моя модель пишет упорно, что Кант. Скорее всего связано с тем, что Яндекса все-таки был терабайт текста и обучалась она дольше.
В том то и дело, что ваши результаты впечатляют именно с учётом того, на каком, сравнительно малом, объёме данных и с использованием каких скромных ресурсов была обучена модель. Поэтому, присваивание Канту теории гравитации ей уж можно простить) Важно, что (по крайней мере в примерах выше) она не теряет контекст.
Возможно, если получится довести до ума, дообучить на большом объеме и поправить узкие места в коде, напишем статью с детальным описанием подхода и выложим какой-то вариант для всех.
Любая обучающаяся система будет работать плохо, если ей дать неправильные данные для обучения, мозг человека не исключение. Это не отменяет ценности таких систем для практики в решении практических задач.
PS. Пример с 2+2=5 немножко уже стал банальным. Если уж на то пошло, что 2+2=4 это не всегда непреложная истина. Например, в эксперименте с рассеянием электронов на щелях, можно взять два электрона и на вход и в результате «сложения» получить на выходе 4 или 0 в зависимости от места расположения детектора.
В копирайтинге нейросети используются уже какое-то время, есть специальные сервисы вроде copy.ai, conversion.ai, aiwriter.ru, но смысл их не в том, чтобы делать работу за копирайтера, они предлагают варианты из которых человек выбирает нужный и соединяет все вместе. Таким образом, отвечает за инстинность контента все равно человек.
Сетка от Яндекса прямо с момента открытия доступа агрится на любую фигню, видя там то порно, то политику. AI Dungeon в последнее время изображает из себя непримиримого борца с CP и видит детское порно даже во фразах типа «Ah, what a sweety boy!», причём если срабатываний фильтра будет слишком много, то может и бан прилететь.
С учётом того, как быстро по всему миру нарастает госцензура, а также активность разного рода упоротых (религиозные моралфаги, SJW), то можно не сомневаться, что достаточно скоро цензура будет абсолютно во всех «общественных» сетках. Ещё и данные куда следует передавать будут о тех, кто излишне часто нарывается на срабатывание этой цензуры.
В итоге, чтобы иметь возможность генерировать абсолютно любые тексты, не боясь срабатывания всяких идиотских фильтров, сеть нужно запускать локально, на собственной машине.
Плюсую.
Строить продукт, который зависит от положения Луны и настроения 25-летних менеджеров в долине — в принципе сомнительная затея. Понятно, что вы не можете произвести свои видеокарты (но AMD все дышит в спину, и если Nvidia споткнется хотя бы на год… их догонят), но алгоритмами надо обладать полностью, хотя бы до возможности репликации (фреймворки есть альтернативные). Иначе на следующей развилки, вашу судьбу решат корпорации добра.
Сегодня люди-олени, завтра Россия плохая, послезавтра нужно поклоняться и вставать на колено.
Сетка от Яндекса прямо с момента открытия доступа агрится на любую фигню, видя там то порно, то политику.
Да уж, это точно. Например, на "Балабол балабола перебалаболил" - "Балабоба не принимает запросы на острые темы, например, про политику или религию... "
Интересно, кого их нейросеть считает балаболами - политиков или священников?
Или если, например, банк заблокировал вашу карточку, потому что их нейросетке показалось подозрительным что-то из совершённых операций, то бесполезно просить у саппорта ответить, что же конкретно из сделанного вами считается «недопустимым». Потому что реакция нейросети идёт по всей совокупности параметров, и не то что саппорт, но и сами её разработчики не способны объяснить, почему она сагрилась. Они знают только, что вероятность ложно-положительного срабатывания их модели составляет 1 случай на десять миллионов пользователей в месяц, и с этим уже можно работать. А если кому не повезло… ну, тут ничего не поделаешь.
Такая проблема есть, конечно. В медицине это особенно существенно. Но существуют и интерпретируемые нейросетевые модели, и эта область развивается. Фактически, у банка может быть не нейросеть, а более простая модель, причины поведения которой можно понять. Но тот человек, который сидит на суппорте возможностями для этого не обладает.
С другой стороны, есть обычные программы, которые стали настолько сложными, что никто точно не знает, как и почему они работают. Да и люди не всегда могут объяснить свое решение. "Нутром чую" - популярное объяснение. Или встречается ситуация когда человек поступает неразумно, но для других притягивает какое-то логическое объяснение, которое не имеет отношение к реальной причине. То что вы описываете, это не столько проблема технологий, сколько того, что тем кто их использует в принципе наплевать на то, что кому-то "не повезло". Ну и опять в этом есть еще один аспект, мы все хотим и привыкли, что платежи и переводы проходят за минуту, а то и за секунду, а не за пять дней. Чтобы так работало, контроль операций просто должен быть автоматическим и достаточно надежным. Уберем все нейросети и "черные ящики", получим ситуацию, когда перевод идет неделю, как было раньше.
Интерпретация нейросетевых моделей для меня очень важна. Я вот не различаю людей, одежду, еду, и перекрёстки (и даже не догадывался об этом до последних лет). И я всегда очень удивлялся (скорее раздражался) тому, что окружающие люди не могут интерпретировать свои нейросети и отвечать на мои простые, казалось бы, вопросы.
—Смотри, Вася идёт.
—Как ты понял, что это Вася, а не, например, Петя?
—Но у него лицо Васи.
—А какое лицо у Васи?
—Ну, я не знаю. Такое, как у человека, который к нам сейчас идёт.
—Но у него лицо такое же, как у всех остальных. Два глаза, один рот, один нос. Ладно, я сам у него спрошу.
…
—Привет, Вася. Скажи, чем ты отличаешься от других людей в этом городе?
—Я не знаю…
—Ну а я тем более не знаю!
Или про перекрёстки:
—Поворачивай направо! Сейчас проедешь!
—Откуда ты знаешь, что надо поворачивать направо?
—Ну это же наш поворот домой! Мы уже два года тут живём!
—Как ты поняла, что это наш поворот?
—Не знаю… По совокупности признаков.
—Какие признаки ты используешь?
—Не знаю!
—Странно. Вот я знаю, какие признаки я использую.
—Да ну! Вот скажи, как ты до сюда доехал?
—Там был перекрёсток, у которого кафе с красно-белым тряпичным навесом. Вижу навес — поворачиваю направо.
—А перед этим?
—Перед этим был перекрёсток, где слева двухэтажное здание, справа — трёхэтажное. Вижу такое — поворачиваю направо.
—А до этого?
—Там была огромная вывеска Ikea. Вижу вывеску, и через 200 метров съезжаю направо.
—Ладно… Ладно… А как ты тогда доехал до дома вчера???
—Вчера не было дождя. Дорогу по недождевому городу я худо-бедно запомнил. Сейчас пошёл дождь, я и не узнаю вообще ничего.
—Как это может быть? Мне, например, вообще неважно, идёт дождь, или нет.
—Значит, ты построила какие-то инвариантные признаки… Научи меня! Я тоже так хочу!
—Отстань!
—Ну пожалуйста! Ну хотя бы скажи, где ты сама этому научилась? Этому учили в четвёртом классе, который я пропустил, да? Учебник специальный? Может «дороговедение»?
—Замолчи уже!
.
Придерживаюсь мнения, что тренировка все более гигантских трансформеров сродни полету на Луну посредством постройки башни. Везде есть какие-то пузыри (умножьте цифры из таблички выше еще на 10, ведь нужно проверять гипер-параметры), и тот факт, что OpenAI хочет потратить еще US$100m на финансирование стартапов, мне тоже кажется показательным;
Нахожу еще весьма смешным то, что когда OpenAI не опубликовали свою модель, Google модели похожего масштаба как раз тихо опубликовал (поправьте меня кто следит)… и никто не заметил, угадайте почему (мое мнение — потому что это очередной пузырь и оплаченный маркетинг);
Про "стерильность" наших компаний в плане генерации новых идей автор (и сомнительную полезного публикуемых вещей) и без меня сказал;
Насчет решения downstream задач — тут уже спорно, среднего размера пре-тренированный трансформер может помочь с задачами, где надо понимать язык. Но это не сильно большой процент задач. Чаще нужно или иметь датасет или просто написать генератор данных, ну или размеры моделей или их токенизация делают их использование невозможным;
С
self-attentionсамими модулями тут сложнее, их довольно неплохо можно комбинировать со свертками;
Аналогичный бред начинается уже и в CV и в речи, но на проекты, подобные этому, внимания люди мало обращают;
Фактически, судя по всему размер имеет большее значение чем архитектура Transformer, можно сделать аналогичную модель на сверточных сетях и получить аналогичный результат. Ценность большого размера именно в low-shot learning, когда данных ну просто нет, или их дорого получать (например, диалоговые системы) или сложно размечать (научные тексты). В этом плане нас GPT2-XL реально несколько раз спасал, когда был сложный заказ. Кое-где это действительно волшебство, но волшебство довольно неустойчивое и требующее навыка в обращении с ним.
С другой стороны ресурсозатраность кажется непропорционально большой. Мы в 2015 делали генератор обобщения отзывов (по задаче похожий на то, что Яндекс сейчас делает в Маркете), и генератор заголовков объявлений для контекстной рекламы. И в итоге там было 50 нейронов в скрытом слое и 250000 параметров, и он генерировал таки отзывы и заголовки, чуть похуже качеством, но всегда по заданной теме (можно почитать тут habr.com/ru/company/meanotek/blog/259355 и тут www.dialog-21.ru/digests/dialog2015/materials/pdf/TarasovDS2.pdf. Так что часто можно в архитектуру вложить некоторые свойства, которые решают конкретную задачу и требуют в 100 раз меньше ресурсов. Но это долго и возни много. А большую модель подключил и можно радоваться, думать не надо.
PS Полеты на Луну были бы дешевле, если бы удалось построить «башню» (космический лифт) на орбиту, но это похоже технически невозможно или крайне проблемно сделать.
Полеты на Луну были бы дешевле, если бы удалось построить «башню» (космический лифт)
Ну так про это прям рядом)) https://habr.com/ru/post/565558/
Ценность большого размера именно в low-shot learning, когда данных ну просто нет, или их дорого получать (например, диалоговые системы) или сложно размечать (научные тексты).
На генеративных задачах мы не сравнивали, но на более приземленных задачах — сетки допустим с мешками н-грамм, которые были инициализированы через FastText были ничем не хуже и меньше оферфитились (и были на порядки меньше и быстрее).
С другой стороны ресурсозатраность кажется непропорционально большой.
Самые маленькие модели из вашей таблицы — 1-5 миллионов рублей.
Но я почему-то уверен, что типичный пользователь трансформеров на самом деле мог бы просто заюзать классификатор из FastText с таким же результатом. Генеративные модели в любом случае это дорогая погремушка, кроме очень сильно узких краевых кейсов.
Рисунок 1 Колонии E.Coli на чашках Петри — это подпись, а
Рисунок 1 показывает нам изображение колоний E.Coli — это упоминание рисунка в тексте.
обучающих примеров 10 штук. Какая будет точность у FastText?
Задача номер два. Нужно из команд вида:
Создать новый объект, называемый большой треугольник и поместить его в начало координат, увеличив размер в 3 раза — достать имя объекта, куда надо поместить, сколько сделать размер. Написать человек может что угодно и как угодно. Примеров для обучения 5-6 штук. С таким числом примеров эти задачи ничего не берет кроме ручного придумывания правил, что долго и плохо. А GPT-2XL их неплохо решает.
Это краевые кейсы. 95% задач это просто классификация предложений.
За 6 лет работы компании в чистом виде классификация предложений попадалась может быть 2-3 раза на примерно 600 проектов. На практике редко кому нужны классические задачи обработки языка. Людям нужно "сделать чат-бот, чтобы все понимал и отвечал на вопросы на основании текста сайта" или "достать из PDF файла с договором важные условия, определив в чем их суть", "разделить транскрипт видео на подразделы и написать к ним заголовки", "найти противоречия в инструкциях", "достать из описания товара параметры и на их основании написать новое описание" - т.е. продукт который решает их реальную задачу, в которой много исключений и мало данных.
В точных формулировках, описанных выше, большая часть этих задач является научной фантастикой, если вы продавали клиентам supervised методы на таких задачах, то мне очень грустно, что вы обманывали клиентов, особенно 6 лет назад (ну или более вероятно как обычно продавался студент с регуляркой под соусом ИИ).
Я часто видел мышление клиентов после таких "продуктов" — заплатили много денег, эффект около нулевой, мы больше не верим в ИИ.
Какие-то из таких вещей можно решить правилами или сильно урезав задачу, сделать что-то вменяемое. Говорить, что продукт реально решает задачу "все понимать и искать противоречия", особенно на "600 проектов", это шарлатанство. Удивительно, что Алиса в которой 10,000 сценариев не может "все понимать и искать противоречия".
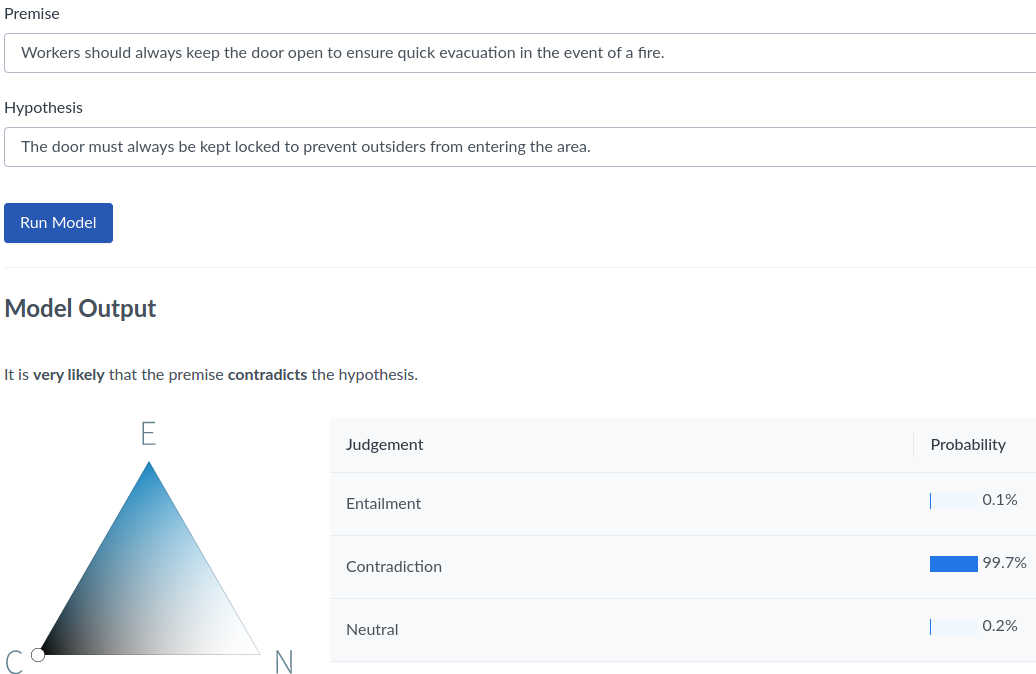
Скриншот это публичное демо с AllenNLP, даже не настроенное на задачу. (перевод: 1. «Рабочие должны всегда держать дверь открытой, для обеспечения быстрой эвакуации в случае пожара», 2. «Дверь всегда должна быть запертой, чтобы посторонние на заходили на территорию». Вывод модели: противоречие, 99.7%)
и опять для заданной области это отлично работает.
Ну вы сами все сказали. Ключевой момент состоит в том, что чтобы работало в области заказчика — количество усилий будет больше, чем экономический эффект на порядки.
Может конечно на ваших "600 проектах" не нужна стабильность или генерализация алгоритмов, но я встречал много кейсов, где люди через два раза работающего чат-бота на сайте производителя краски путают с сильным ИИ.
Возвращаясь к изначальной точке, откуда начался спор — я как раз выше и писал, что с помощью большой языковой модели усилия нужные для решения задачи становятся намного меньше и многие задачи, которые раньше было не практично решать, становятся доступными.
А можно небольшое пояснение по поводу того, как такие сети решают такие задачи? Насколько я понимаю, они просто предсказывают следующее слово на основе контекста. Как при помощи этого можно найти противоречия в инструкциях не могу придумать.
Какое-то у вас обучение бестолковой. Генераторы псевдонаучного бреда были ещё в конце 90-х.
Никакого интеллекта нет и быть не может без понимания смысла.
Вот когда ваш бот сможет осознать хотя бы "мама мыла раму", тогда и приходите.
Типичным методом проверки этой возможности является сравнить вероятности, которые модель назначает разным фразам.

Мы можем видеть, что модель может сделать правильный выбор.
Бредогенераторы в 90-х были либо модели на правилах, которые писал человек, либо марковские цепи, которые создавали совсем плохой текст. С тех пор ситуация сильно изменилась. Языковая модель, помимо тривиального примера выше, может решать задачи вроде «Чемодан не пролезает в дверной проем, потому что он слишком большой. Что слишком большое?» или выбрать правильную фразу из «Озеро высохло теперь в нем нет воды» и «Озеро высохло, теперь в нем можно купаться». Я писал больше на тему знаний, которыми обладает языковая модель например тут.
Пора забыть о том, что было в 90-х, 30 лет это эпоха для ИИ, все очень сильно изменилось.
Осознать - это не философское понятие, а вполне реальное, и сводится по сути к набору связок понятийных смыслов и причинно-следственных связей.
А кто делает текст осмысленным или безсмысленным - только человеческое восприятие? Тогда о каком машинном обучении, и, прости хосспади, ии может идти речь?
"Рама мыла маму" заиграет новыми красками, если вдруг окажется, что Рама - это имя.
Как я показал выше, с точки зрения правильной связки слов между собой, модель вполне «осознает» написанное, так как может решать задачи, требующие знания связей слов.
Осознать — это не философское понятие, а вполне реальное, и сводится по сути к набору связок понятийных смыслов и причинно-следственных связей.
Можно ссылочку на определение осознания?
30 миллиардов параметров: реально ли обучить русский GPT-3 в «домашних» условиях?