Всем привет. «Не возвращаясь» к нашим баранам из предыдущей статьи "И снова про MS Excel", хочу показать, что же все-таки у меня получилось для работы со скриптами First Response Kit (sp_Blitz) от Brent Ozar и компании. Нравится данный набор и для анализа загруженности SQL Server-а и оптимизации запросов на оном. Причем сам Brent предлагает нечто подобное за денюжку. Для тех кто пользовался, пользуется или думает пользоваться данным набором скриптов - предлагаю взглянуть на то что у меня получилось
Начало
Записавшись как-то на онлайн классы Brent-а мне понравились его скрипты, которые он раздает абсолютно бесплатно и манера подачи материала. Ну и так, как его обучение происходит на базе скриптов то постоянно приходится вызывать ту или иную хранимку (здесь и далее - «хранимые процедуры») и листать полученные датасеты пытаясь выбрать для себя необходимое. «А почему бы не автоматизировать это убрав лишнее» - пришло в голову и работа закипела. Периодически отвлекаясь на другие дела, в итоге я довел функциональность до желаемо-минимально-необходимой с чем и спешу поделиться с общественностью.
Понимаю, что наверняка людей которые начнут говорить, что «написать подобное можно было на чем угодно только не на эксельке» наверняка здесь гораздо больше, сразу предлагаю им не тратить свое время и перейти на следующую тему. Меня же, кстати заинтересовала тема об автоматизации работы с Tinkoff API из статьи - "Что недоговаривают Тинькофф Инвестиции. Вытаскиваем все данные по портфелю через API в большую таблицу Excel", но об этом позже.
«Берём глыбу и отсекаем всё лишнее»
Изначально, в зависимости от установленных параметров каждая хранимка может возвращать один или несколько датасетов. Какие-то из них могут быть пустые, какие-то получаются слишком широкими. Ээээх, да ну к чему все разговоры. Возможно проще раз показать, чем 100 раз сказать. На видео ниже видно, как из кучи нужной (и не очень) информации формируется итоговый результат
В итоге сформировались основные правила работы с датасетом о которых я вам сейчас расскажу.
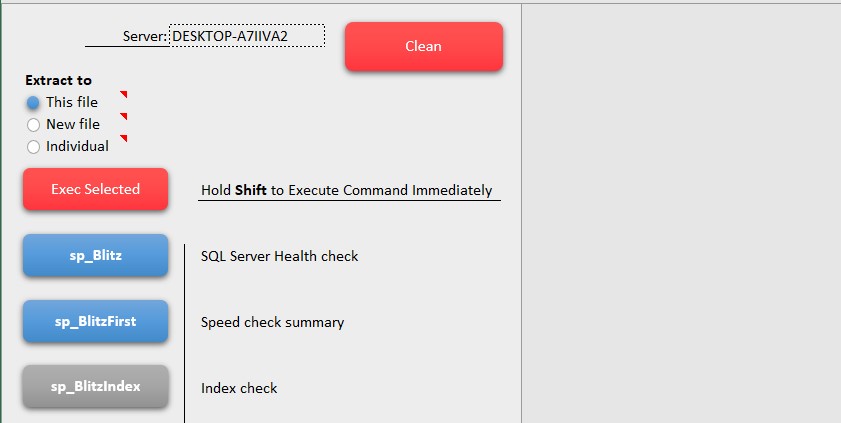
Для начала укажем имя SQL Server в конфигурационном xml файле config.xml атрибут server (в нашем примере DESKTOP-A7)
<configuration database="StackOverflow" schema="dbo" notes="" version="0.1" server="DESKTOP-A7" application_name="sp_Blitz_Excel" active_cell="A1">Далее рассмотрим блок на примере вызова хранимки - sp_BlitzFirst
<query name="sp_BlitzFirst" show_all_dataset="no" show_everything="no">
<body>
<![CDATA[
exec dbo.sp_BlitzFirst @ExpertMode = 1, @SinceStartup = 1
]]>
</body>
<format name="sp_BlitzFirst_3" skip="yes">
<column name="run_date" hide="yes" />
</format>
<format name="sp_BlitzFirst_11" worksheet_name="First_Waits" order_by="-Avg ms Per Wait" skip="no" extract_address="B2" freeze="F3" hide_grid="yes" hide_heading="yes" >
<column name="wait_type" width="22.7" href_from="URL"/>
<column name="wait_category" width="16" />
<column name="Number of Waits" width="18" format="#,##0" databar="yes" bar_color="5920255" />
<column name="Avg ms Per Wait" format="#,##0.00" databar="yes" bar_color="8700771" />
</format>
</query>Атрибут name в тэге query именует датасет и дальнейшее форматирование внутри датасета происходит в соответсвии с данным именем. Если мы запустим команду без блоков форматирования, то мы получим листы в эксельке именованные примерно следующим образом

Насколько я понял копаясь в данных, эти номера - 11,12,13 и т.д. - номера датасетов сформировавшихся внутри хранимки и на клиента уже передается вот такой номер датасета, а не сквозной. Что в целом нам на руку. Берем название листа и формируем блок:
<format name="sp_BlitzFirst_11" worksheet_name="First_Waits" order_by="-Avg ms Per Wait" skip="no" extract_address="B2" freeze="F3" hide_grid="yes" hide_heading="yes" >
<column name="Pattern" width="14" />
<column name="Sample Ended" width="17" />
<column name="wait_type" width="22.7" href_from="URL"/>
<column name="wait_category" width="16" />
<column name="Wait Time (Hours)" width="22.7" hide="yes" />
<column name="Signal Wait Time (Hours)" />
<column name="Number of Waits" width="18" format="#,##0" databar="yes" bar_color="5920255" />
<column name="Avg ms Per Wait" format="#,##0.00" databar="yes" bar_color="8700771" />
</format>в целом все должно быть предельно просто:
worksheet_name - задает читабельное имя листа.
order_by - задает сортировку таблицы на данном листе. Если первым символом стоит знак минус, то сортировка идет в обратном порядке.
skip - указывает на то, что нам данный датасет интересен и мы не хотим его пропускать.
extract_address - задает начальный адрес выгрузки таблицы
freeze - адрес заморозки и разделения заголовка в листе
hide_grid - прячем сетку на листе
hide_heading - прячем заголовки строк/столбцов
Примерно так же банально просто указывается формат столбцов. Остановлюсь на нескольких атрибутах. Атрибут href_from - в нем указывается название поля из которого берем URL для данного поля. Атрибут databar указывает на то, что нужно включить визуализацию в данном столбце по значению, а bar_color - задает цвет данной визуализации.
Список всех (насколько я вспомнил) атрибутов можно найти на листе с банальным названием FAQ.

Управление
Кнопка Clean приводит всю книгу в подряд подчищая мусор удалив все нагенерированное.
Кнопка Exec Selected запускает процесс формирования отчетов согласно выбраных хранимок.
Блок кнопок с названиями хранимок работают как чекбоксы: синий — функция включена. серый - выключена. Стандартные чекбоксы на меня наводят тоску и заставляют щуриться. Если же удерживая клавишу шифт щелкнуть по любой из данных кнопок, то запустится только эта хранимая процедура, вне зависимости «включена» ли она и все остальные кнопки.

Стандартные радиокнопки тоже на мой взгляд не комильфо и в итоге появился блок указывающий куда делать выгрузку

Ну вот в целом и все. Буду рад ответить на вопросы, если таковые найдутся и расширить функционал если у пользователей появится интерес. Ах да, если кто-то дочитал до этого места, то вот вам ссылка на данное рукоделие.
Ну и «вишенка на торте» — загрузил все в гитхаб.
Всем доброй пятницы, и отличных выходных!







