Этот пост можно было б начать по разному. Можно по делу: как необходима система мониторинга для поиска ошибок системы и как она помогает обнаружить узкие места. Но, сейчас лето, время отдыха на природе, и начну с того, как я решил узнать, как же часто менятеся прогноз погоды, с помощью популярного средства мониторинга Cacti. Под катом, о любопытный читатель!, тебя ждут рассказы о том как настроить мониторинг произвольных данных в Cacti, да не просто, а с картинками.
Итак, за неделю до 19 июня(пятница, сами понимаете...) я начал смотреть, какая же будет погода? Смотрел у Яндекса — уж больно люблю я этих web-метеороголов. Погода менялась изо дня в день и мне стало интересно — а какова частота этих изменений? Ощущение погоды — вещь субъективная, а частота изменения прогноза на сайте — вполне измеряемая. Для этих целей я и решил использовать давно знакомое средство мониторинга Cacti. Статья предназначена в основном для программистов и системных администраторов, поэтому вопрос как поставить Cacti я не рассматриваю — эти люди либо уже поставили, либо справятся за 5 минут.
Если вам интересно, как же часто меняется погода в прогнозах, но Cacti не интересен, проматывайте сразу в конец.

В основе Cacti лежит RRDTool — средство для работы с круговыми базами данных(RRD — round-robin database). Такие базы данных рассматривают временную координату состоящей из интервалов и записывают значения хранимого параметра в узлах таких интервалов, интерполируя в случае необходимости измеряемое значение. В одной базе данных может быть несколько RRA(round-robin archive) — этим достигается возможность хранить величину с разными интервалами времени(то есть с разной детальностью). Все эти операции Cacti скрывает от пользователя — все что нам нужно для того что бы наладить мониторинг величины — это предоставить средство для получения этой величины и сказать Cacti что нужно запускать poller(сборщик данных — вытаскивает данные из всех исчтоников и сохраняет их в ту самую RRD).
Для начала, несколько слов о «сущностях», которые есть в Cacti. Они перечислены в левом меню в панели администратора:
Итак:
Чтобы узнать прогноз в данный момент времени, нужно закачать страничку с погодой яндекса и распарсить. Так как заранее мы не знаем, какой день нас интересует, сделам скрипт, который будет на вход принимать дату, на выходе выдавать температуру днем для нее. Обращаться каждые 5 минут к яндексу не стоит — врядли погода будет меняться так часто, поэтому сделаем так, чтобы скрипт кэшировал данные. Не буду особо углубляться здесь, просто приведу код скрипта:
Теперь, когда готов скрипт, его нужно куда-нибудь поместить(тут уж на ваше усмотрение). Я, например, положил в /usr/share/cacti/. Но, не забудьте учесть права на чтение и запуск(так же на создание файла) — poller будет запускать этот скрипт под пользоватлем www-data. Далее создаем Data Input Method:
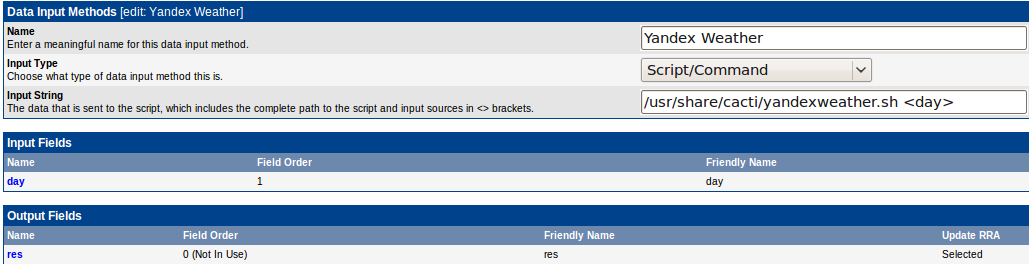
С помощью конструкции <day> делаем шаблонный параметр для метода ввода. Его нужно декларировать в списке Input Fields — чтобы Data Template знал о нем. Так же надо декларировать Output Field с именем res(имя не важно, так как у нас скрипт возвращает одно значение). Делать Data Input Method одно удовольствие, самое интересное впереди)
Cоздаем Data Template:
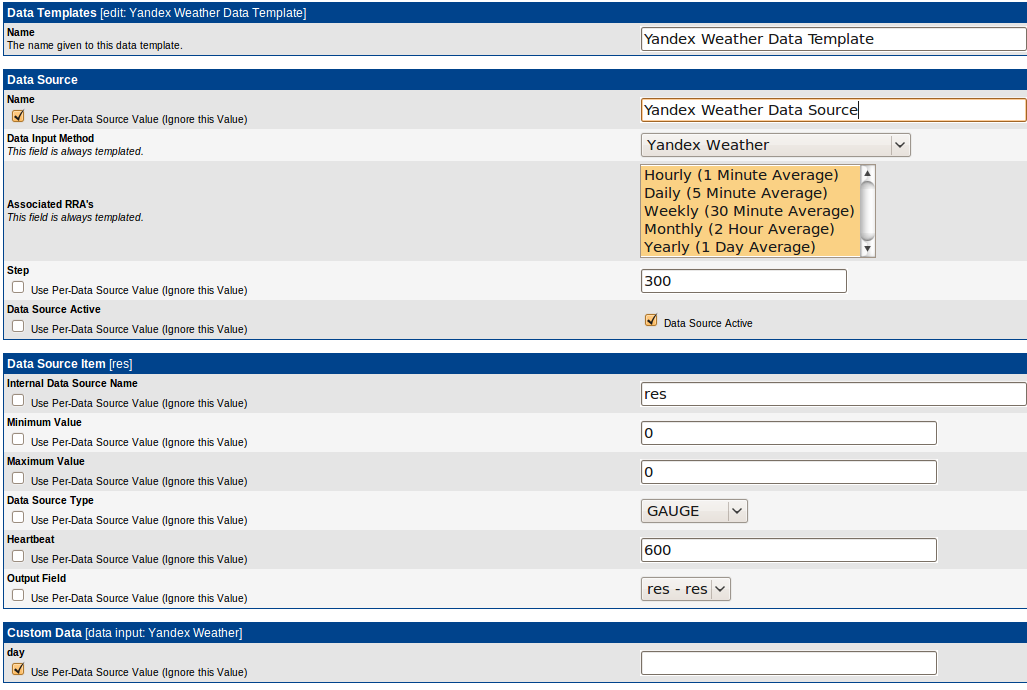
По умолчанию, нам предлагают ввести все параметры, но некоторые из них можно делегировать Data Source. В нашем случае, мы делегируем название и параметр для скрипта Data Source.
Сделать Data Source тоже довольно просто:
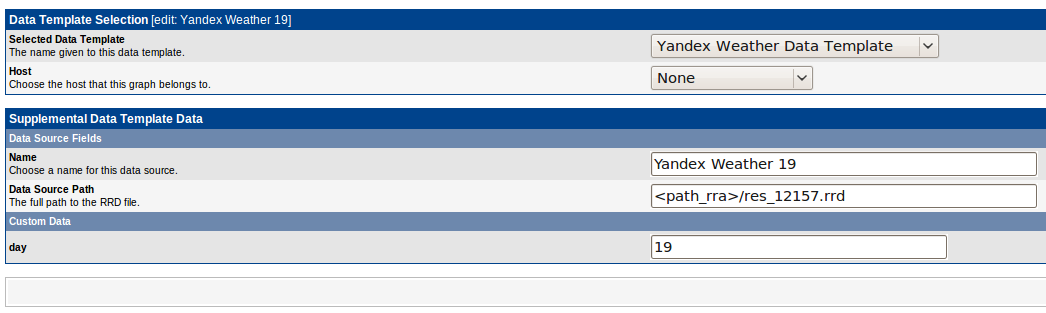
Выбираем только что созданный Data Template, имя хоста можно оставить пустым — в нашем случае все происходит на локальной машине. Пишем уникальное имя для Data Source(уникальность не требуется — это нужно что бы потом было легче вставлять в график) и день, который мониторим, в нашем случае 19е число. Имя файла вычисляется на основе id данного Data Source — но можно выбрать и свое(главное что бы не было коллизий).
Больше всего, пожалуй, настроек у графиков. Создаем новый Graph Template и видим:
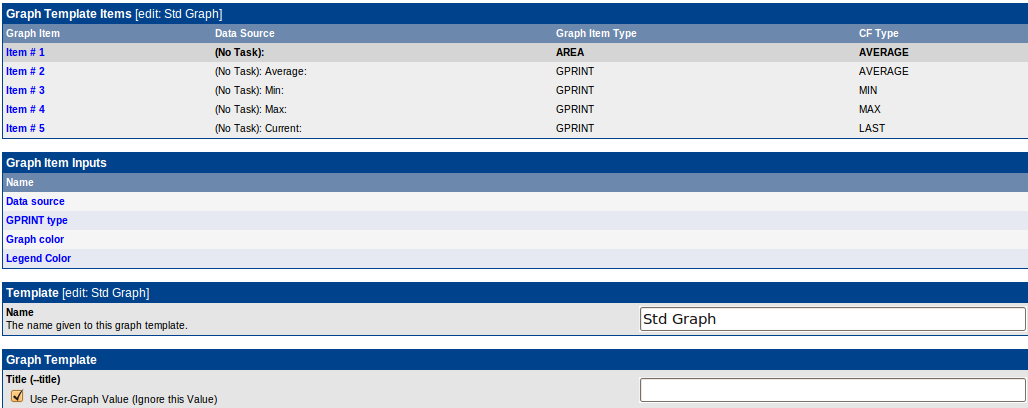
Сначала перечислены элементы графика — линии, легенды, прочие подписи. Далее шаблонные параметры(куда ж без них, это же шаблон). И потом идет куча параметров графика(я их не стал приводить на рисунке, они довольно очевидные — пределы, логарифмический масштаб и прочие ненужные в нашем случае вещи).
Для начала создаем визуальные элементы(на риснуке настройки для графика, подписи можно сделать по аналогии):
Оставляем имя Data Source и цвет пустыми — вынесем их потом в шаблонные паратмеры. Основные параметры визуального элемента:
Когда визуальные элементы описаны, можно создать шаблонные параметры в списке Graph Item Inputs:
В этом окне нужно указать, что мы хотим шаблонизировать(источник данных, цвет, прозрачность либо еще что-то) и на какие элементы это будет распространяться. В нашем случае нужно сдалать шаблонный источник данных для всех элементов.
Теперь, когда у нас есть источник данных и шаблон графика, создаем собственно график в меню Graph Managment:
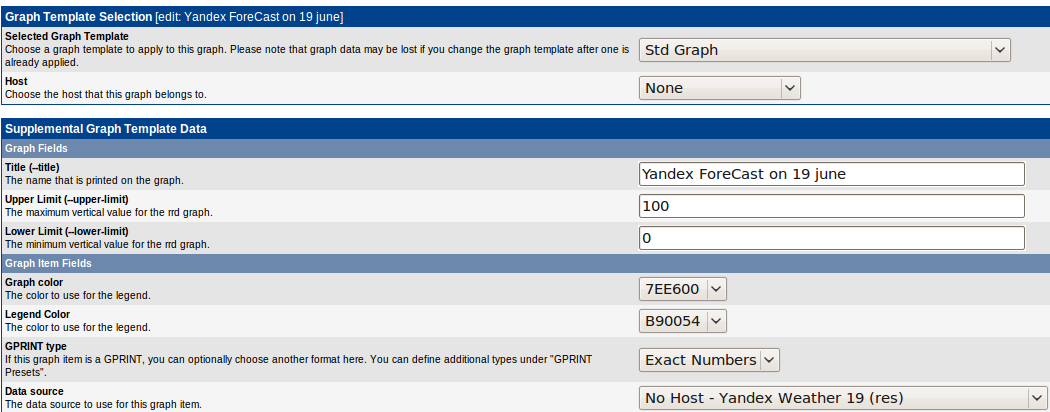
Если все сделано правильно, то график должен появиться сразу. Но есть одно НО — для отрисовки данных на графике должно пройти как минимум два polling`а — то есть, около 10 минут.
В процессе настройки новых источников данных удобно пользоваться отдалочной информацией, которой в Cacti достаточно:
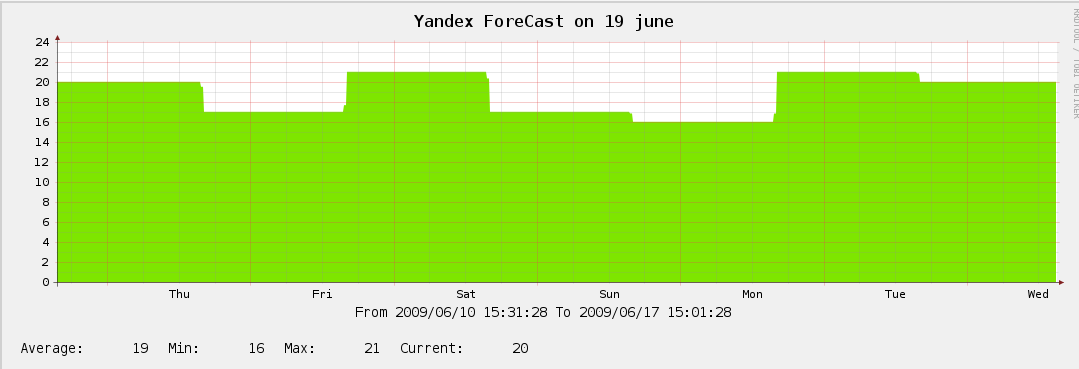
Итак, то, ради чего были все пляски с бубном, динамика изменения прогноза погоды на 19 июня by Yandex.Погода:
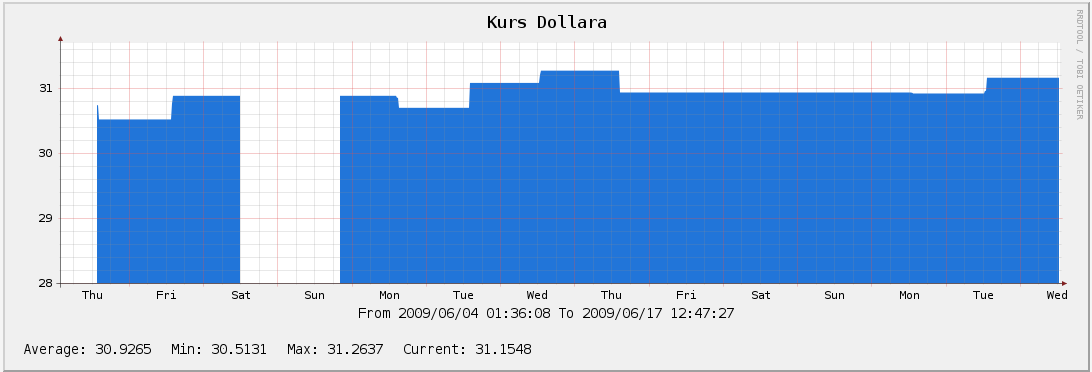
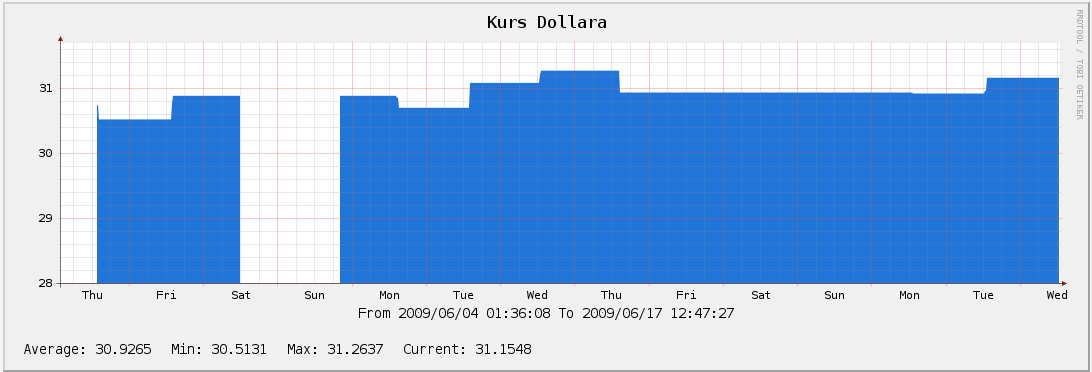
И, в качестве бонуса, динамика изменения курса доллара by ЦБ РФ(там есть пустой участок — это не символ кризиса, а я просто сервер вырубил):
Что захотите замониторить вы — ошибки апача, количество юзеров, либо количество песен в вашем плэйлисте — вопрос фантазии. Удачи всем, кто заинтересуется, в экспериментах с Cacti!
P.S. Пока я писал этот пост, Яндекс решил, что 19го будет еще холодней на два градуса… Но тем не менее погода от Яндекса очень классная, ее даже парсить было приятно.
P.P.S. Cacti далеко не единственное средство для работы с RRD — есть Munin, Ganglia, Nagios и еще куча всего.
Итак, за неделю до 19 июня(пятница, сами понимаете...) я начал смотреть, какая же будет погода? Смотрел у Яндекса — уж больно люблю я этих web-метеороголов. Погода менялась изо дня в день и мне стало интересно — а какова частота этих изменений? Ощущение погоды — вещь субъективная, а частота изменения прогноза на сайте — вполне измеряемая. Для этих целей я и решил использовать давно знакомое средство мониторинга Cacti. Статья предназначена в основном для программистов и системных администраторов, поэтому вопрос как поставить Cacti я не рассматриваю — эти люди либо уже поставили, либо справятся за 5 минут.
Если вам интересно, как же часто меняется погода в прогнозах, но Cacti не интересен, проматывайте сразу в конец.
Философия Cacti
В основе Cacti лежит RRDTool — средство для работы с круговыми базами данных(RRD — round-robin database). Такие базы данных рассматривают временную координату состоящей из интервалов и записывают значения хранимого параметра в узлах таких интервалов, интерполируя в случае необходимости измеряемое значение. В одной базе данных может быть несколько RRA(round-robin archive) — этим достигается возможность хранить величину с разными интервалами времени(то есть с разной детальностью). Все эти операции Cacti скрывает от пользователя — все что нам нужно для того что бы наладить мониторинг величины — это предоставить средство для получения этой величины и сказать Cacti что нужно запускать poller(сборщик данных — вытаскивает данные из всех исчтоников и сохраняет их в ту самую RRD).
Для начала, несколько слов о «сущностях», которые есть в Cacti. Они перечислены в левом меню в панели администратора:
Итак:
- Data Input Method — описывает то, как будут получаться данные. Основные способы — это SNMP(интересная тема, но не будем углубляться) и внешний скрипт — наш случай
- Data Template — описывает как часто и с какими параметрами будет использоваться Data Input Method
- Data Source — собственно RRD — хранит данные в файлике, создается на основе Data Template
- Graph Template — шаблон графика. Можно описать в нем все детали отображения, кроме источника данных, а можно создать шаблонные параметры для цвета, прозрачности и прочего
- Graph — собственно график. Приготовить можно смешав Data Source, Graph Template и указав все шаблонные параметры из Graph Template
- Graph Tree — дерево графиков — если у вас графиков много(например мониторим 10 машин), то удобно создать иерархию
- Есть еще много чего, но нам оно пока не понадобится.
Скрипт для добычи погоды
Чтобы узнать прогноз в данный момент времени, нужно закачать страничку с погодой яндекса и распарсить. Так как заранее мы не знаем, какой день нас интересует, сделам скрипт, который будет на вход принимать дату, на выходе выдавать температуру днем для нее. Обращаться каждые 5 минут к яндексу не стоит — врядли погода будет меняться так часто, поэтому сделаем так, чтобы скрипт кэшировал данные. Не буду особо углубляться здесь, просто приведу код скрипта:
- #!/bin/bash
- cd /usr/share/cacti
- flagdate=$(date "+%Y-%m-%d %H:00")
- flagfile=yandex.flag
- touch $flagfile -d"$flagdate"
- if [ ! -e index.html -o index.html -ot $flagfile ]; then
- wget http://weather.yandex.ru/27612/ -O index.html > /dev/null 2>&1
- fi
- day=$1
- pos=$(cat index.html | grep "<th class=\"weekday\">" -A1 | grep -o "<th class=\"week[^0-9]*[0-9]*[^0-9]*</th>" | grep -o "[0-9]*" | grep $day -n | grep -o "^[0-9]")
- let pos=pos+1
- res=$(cat index.html | grep "<tr class=\"data day\">" -A1 | grep -o "+[0-9]*" | sed -n "$pos""p")
- echo $res | grep -o "[0-9]*"
Data Input Method
Теперь, когда готов скрипт, его нужно куда-нибудь поместить(тут уж на ваше усмотрение). Я, например, положил в /usr/share/cacti/. Но, не забудьте учесть права на чтение и запуск(так же на создание файла) — poller будет запускать этот скрипт под пользоватлем www-data. Далее создаем Data Input Method:
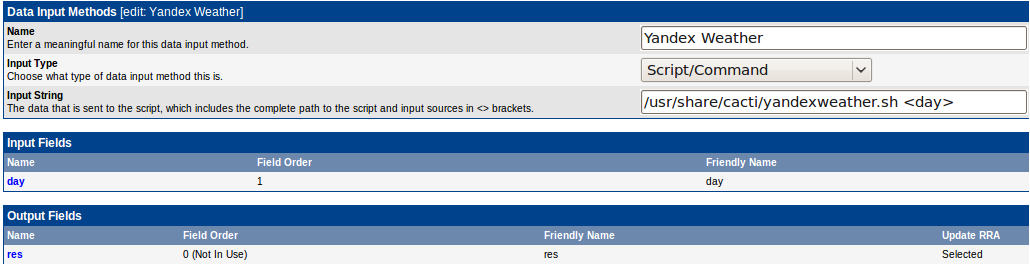
С помощью конструкции <day> делаем шаблонный параметр для метода ввода. Его нужно декларировать в списке Input Fields — чтобы Data Template знал о нем. Так же надо декларировать Output Field с именем res(имя не важно, так как у нас скрипт возвращает одно значение). Делать Data Input Method одно удовольствие, самое интересное впереди)
Data Template
Cоздаем Data Template:
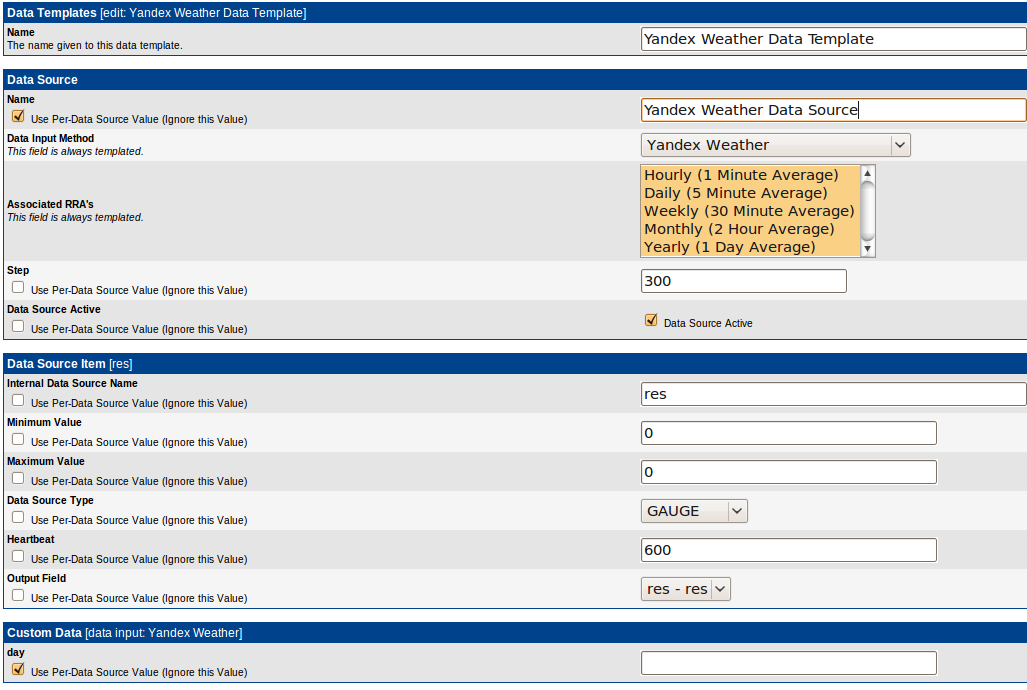
По умолчанию, нам предлагают ввести все параметры, но некоторые из них можно делегировать Data Source. В нашем случае, мы делегируем название и параметр для скрипта Data Source.
Data Source
Сделать Data Source тоже довольно просто:
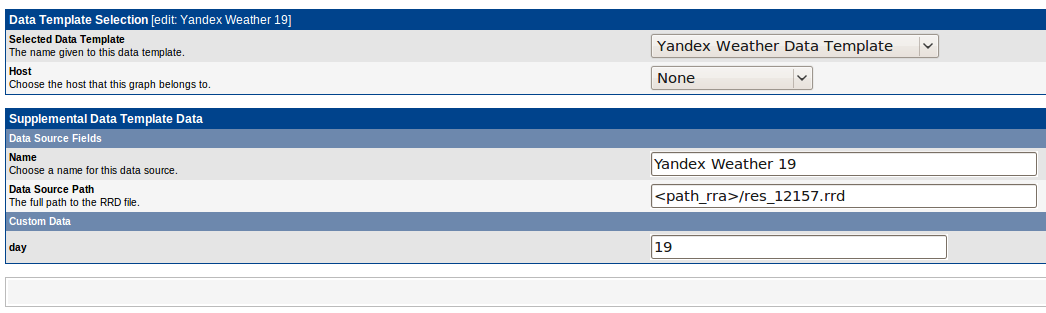
Выбираем только что созданный Data Template, имя хоста можно оставить пустым — в нашем случае все происходит на локальной машине. Пишем уникальное имя для Data Source(уникальность не требуется — это нужно что бы потом было легче вставлять в график) и день, который мониторим, в нашем случае 19е число. Имя файла вычисляется на основе id данного Data Source — но можно выбрать и свое(главное что бы не было коллизий).
Graph Template
Больше всего, пожалуй, настроек у графиков. Создаем новый Graph Template и видим:
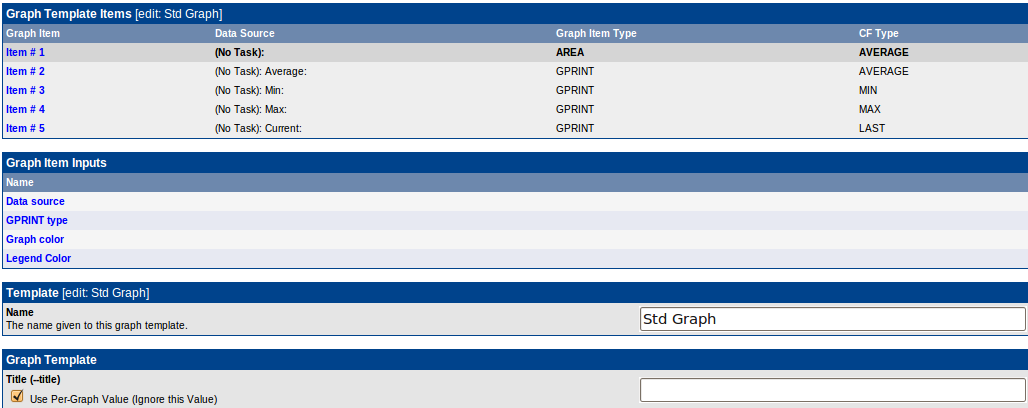
Сначала перечислены элементы графика — линии, легенды, прочие подписи. Далее шаблонные параметры(куда ж без них, это же шаблон). И потом идет куча параметров графика(я их не стал приводить на рисунке, они довольно очевидные — пределы, логарифмический масштаб и прочие ненужные в нашем случае вещи).
Для начала создаем визуальные элементы(на риснуке настройки для графика, подписи можно сделать по аналогии):
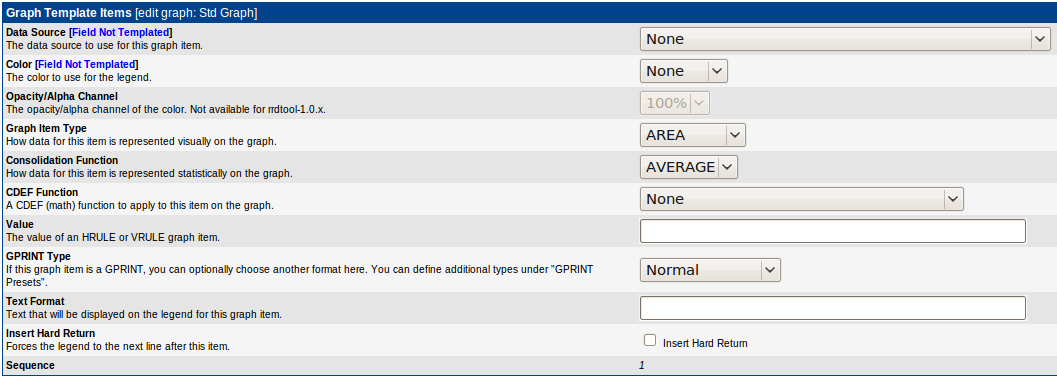
Оставляем имя Data Source и цвет пустыми — вынесем их потом в шаблонные паратмеры. Основные параметры визуального элемента:
- Graph Item Type — тип элемента. В нашем случае будет AREA(собственно график) или GPRINT(подпись внизу графика — будем писать среднее и максимальное значения)
- Consolidation Function — для графика должна быть AVERAGE, при создании подписей можно выбрать так же LAST/MAX/MIN
- GPRINT Type — для подписей можно указать расширенный формат вывода. Свой формат можно создать в меню Graph Managment -> GPRINT Presets. Там обычный формат printf, ничего интересного)
Когда визуальные элементы описаны, можно создать шаблонные параметры в списке Graph Item Inputs:
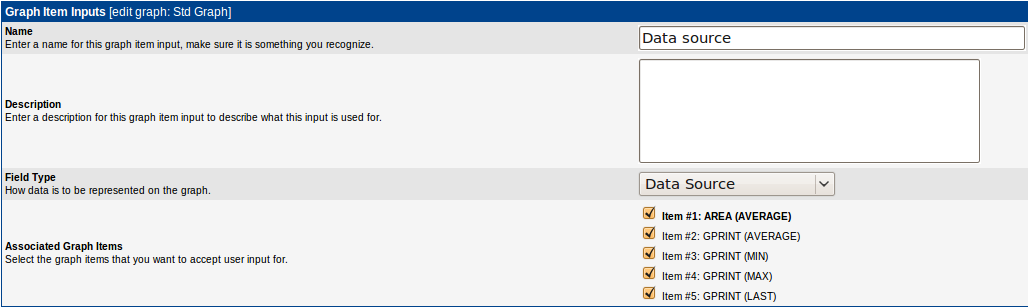
В этом окне нужно указать, что мы хотим шаблонизировать(источник данных, цвет, прозрачность либо еще что-то) и на какие элементы это будет распространяться. В нашем случае нужно сдалать шаблонный источник данных для всех элементов.
Почти Финал
Теперь, когда у нас есть источник данных и шаблон графика, создаем собственно график в меню Graph Managment:
Если все сделано правильно, то график должен появиться сразу. Но есть одно НО — для отрисовки данных на графике должно пройти как минимум два polling`а — то есть, около 10 минут.
В процессе настройки новых источников данных удобно пользоваться отдалочной информацией, которой в Cacti достаточно:
- В /var/log/cacti/ много логов, в частности ошибки поллера poller-error.log
- В меню System Utilities -> View Cacti Log File
Финал
Итак, то, ради чего были все пляски с бубном, динамика изменения прогноза погоды на 19 июня by Yandex.Погода:

И, в качестве бонуса, динамика изменения курса доллара by ЦБ РФ(там есть пустой участок — это не символ кризиса, а я просто сервер вырубил):
Что захотите замониторить вы — ошибки апача, количество юзеров, либо количество песен в вашем плэйлисте — вопрос фантазии. Удачи всем, кто заинтересуется, в экспериментах с Cacti!
P.S. Пока я писал этот пост, Яндекс решил, что 19го будет еще холодней на два градуса… Но тем не менее погода от Яндекса очень классная, ее даже парсить было приятно.
P.P.S. Cacti далеко не единственное средство для работы с RRD — есть Munin, Ganglia, Nagios и еще куча всего.







