(Начало: 1, 2) Что ж, подходим к самому интересному — разбору предложений. Тема эта многогранна и многоуровнева, так что подступиться к ней не очень просто. Но ведь трудности лишь закаляют :) Да и выходные, текст пишется легко…
Начнём с такого понятия, как синтаксический анализ предложений (по-английски parsing). Суть этого процесса состоит в построении графа, «каким-либо образом» отражающего структуру предложения.
Я говорю «каким-либо образом» потому, что на сегодня не существует единственно принятой системы принципов, на которых строится упомянутый граф. Даже в рамках одной концепции взгляды отдельных учёных на зависимости между словами могут различаться (это напоминает разногласия в трактовке морфологических явлений, о чём шла речь в предыдущей части).
Наверно, прежде всего надо разделить способы построения графа (обычно — дерева) зависимостей на phrase structure-based parsing и dependency parsing.
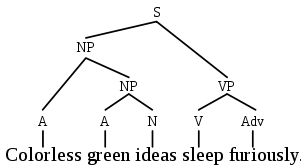
Представители первой школы разделяют предложение на «составляющие», далее каждая составляющая разбивается на свои составляющие — и так до тех пор, пока не дойдём до слов. Эту идею хорошо иллюстрирует рисунок из Википедии:

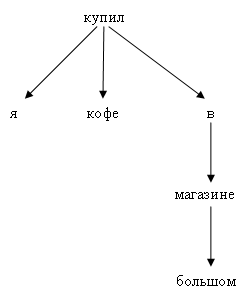
Представители второй школы соединяют зависящие друг от друга слова между собой непосредственно, без каких-либо вспомогательных узлов:

Сразу скажу, что мои симпатии на стороне второго подхода (dependency parsing), но оба они заслуживают более детального обсуждения.
Начав с символа S, можно сгенерировать любую строку вида a...ab...b. Существует также универсальный алгоритм разбора такой грамматики. Скормив ему входную строку и набор правил грамматики, можно получить ответ — является ли строка корректной строкой в рамках данного языка или нет. Можно получить и дерево разбора, показывающее, каким образом строка выводится из начального символа S.
Допустим, строке aabb соответствует вот такое дерево:
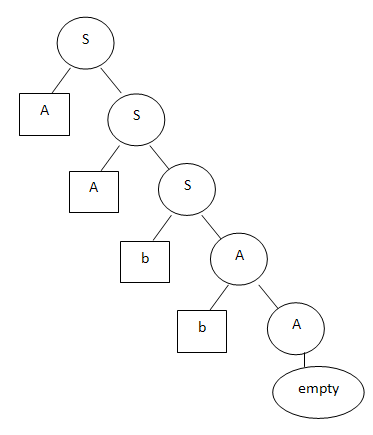
Явный плюс этого метода состоит в том, что грамматики Хомского — формализм давно известный. Существуют давно разработанные алгоритмы разбора, известны «формальные свойства» грамматик, т.е. их выразительные способности, сложность обработки и т.п. Кроме того, грамматики Хомского успешно применяются при компиляции языков программирования.
Сам Хомский прежде всего лингвист, и свои работы он примерял на естественный язык, английский, в первую очередь. Поэтому в англоязычной компьютерной лингвистике влияние его трудов достаточно велико. Хотя «в лоб» сейчас формализмы Хомского, насколько мне известно, при обработке текстов на естественном языке не применяют (они недостаточно развиты для этого), дух его школы живёт.
Хороший пример синтаксического анализатора, строящего подобные деревья — Stanford parser (есть онлайн-демо).
Вообще этот подход тоже трудно назвать особо свежим. Все ссылаются на работы Люсьена Теньера (Lucien Tesniere) пятидесятых годов как на первоисточник. Упоминают и более ранние мысли (но из той же оперы, что называть отцом ООП Платона, т.к. он ввёл в оборот понятие «мира идей», то есть абстрактных классов). Однако в компьютерной лингвистике dependency parsing долгое время был на втором плане, в то время как грамматики Хомского активно применялись. Вероятно, ограничения подхода Хомского особенно больно ударили по языкам с более свободным (чем в английском) порядком слов, поэтому самые интересные работы в области dependency parsing до сих пор выполняются «снаружи» англоязычного мира.
Основная идея dependency parsing — соединять между собой зависимые слова. Центром практически любой фразы является глагол (явный или подразумеваемый). Далее от глагола (действия) можно задавать вопросы: кто делает, что делает, где делает и так далее. Для присоединённых сущностей тоже можно задать вопросы (в первую очередь, вопрос «какой»). Например, для приведённого выше дерева «я купил кофе в большом магазине» можно воспроизвести такую цепочку вопросов. Корень — купил (действие фразы). Кто купил? — Я. Что купил? — Кофе. Где купил? — В магазине. В каком магазине? — В большом.
Здесь тоже есть множество технических тонкостей и неоднозначностей. Можно по-разному обрабатывать отсутствие глагола. Обычно всё равно подразумевается глагол «to be»: «Я [есть] студент». В предикативных предложениях дело обстоит сложнее: На улице сыро. Не скажешь же, что на улице есть сыро :) Не всегда понятно, что от чего зависит, и как это трактовать. Например, «я не пойду сегодня на работу». Как соотносится с прочими словами частица «не»? Как вариант, можно считать, что здесь используется глагол «недеяния» «не_пойду» (пусть в русском такого нет, но по смыслу подходит). Не совсем понятно, как лепить однородные члены, соединённые союзом. «Я купил кофе и булочку». Например, можно лепить к «купил» слово «и», а к «и» присоединять уже «кофе» и «булочку». Но есть и другие подходы. Довольно тонкий момент возникает при взаимодействии слов, образующих некое единство: «я буду ходить на работу». Понятно, что «буду ходить» — это по сути один-единственный глагол (то есть действие) будущего времени, просто создан он двумя словами.
Если хочется посмотреть на такой анализатор в действии — могу посоветовать сайт фирмы Connexor.
Чем dependency parsing притягателен? Приводят разные аргументы. Например, говорится, что соединяя между собой слова, мы не создаём дополнительных сущностей, и, стало быть, упрощаем дальнейший анализ. В конце концов, синтаксический анализ — это лишь очередной этап обработки текста, и дальше надо представлять, что с полученным деревом делать. В каком-то смысле дерево зависимостей «чище», ибо показывает явные семантические связи между элементами предложения. Далее, нередко утверждают, что dependency parsing больше подходит для языков со свободным порядком слов. У Хомского все зависимые блоки так или иначе действительно оказываются рядом друг с другом. Здесь же в теории можно иметь связи между словами на разных концах предложения (хотя и здесь технически не так всё просто, но об этом позже). В принципе, уже этих аргументов для меня достаточно, чтобы примкнуть к лагерю Теньера :)
Надо сказать, что существуют формальные доказательства близости получающихся деревьев. Где-то проскакивала теорема о том, что дерево одного вида можно сконвертировать в дерево другого вида и наоборот. Но на практике это не работает. По крайней мере, на моей памяти никто не пытался получить дерево зависимостей путём преобразования выходных данных Stanford parser'а. Видимо, не всё так просто, да и ошибки множатся… сначала стэнфордский парсер ошибётся, потом алгоритм конвертации ошибётся… и что получится в конце? Ошибка на ошибке.
(UPD: упомянутые ребята из Стэнфорда всё же протестировали метод конвертации выходных данных своего парсера в dependency-структуры. Однако должен заметить, что при такой конвертации получаются только проективные деревья, речь о которых идёт в пятой части).
Наверно, на сегодня хватит. Продолжим в следующей части.
Начнём с такого понятия, как синтаксический анализ предложений (по-английски parsing). Суть этого процесса состоит в построении графа, «каким-либо образом» отражающего структуру предложения.
Я говорю «каким-либо образом» потому, что на сегодня не существует единственно принятой системы принципов, на которых строится упомянутый граф. Даже в рамках одной концепции взгляды отдельных учёных на зависимости между словами могут различаться (это напоминает разногласия в трактовке морфологических явлений, о чём шла речь в предыдущей части).
Наверно, прежде всего надо разделить способы построения графа (обычно — дерева) зависимостей на phrase structure-based parsing и dependency parsing.
Представители первой школы разделяют предложение на «составляющие», далее каждая составляющая разбивается на свои составляющие — и так до тех пор, пока не дойдём до слов. Эту идею хорошо иллюстрирует рисунок из Википедии:
Представители второй школы соединяют зависящие друг от друга слова между собой непосредственно, без каких-либо вспомогательных узлов:
Сразу скажу, что мои симпатии на стороне второго подхода (dependency parsing), но оба они заслуживают более детального обсуждения.
Школа Хомского
Разбор «по составляющим» явно вырос из грамматик Хомского. Если кто не знает, грамматика Хомского представляет собой способ задания правил, описывающих предложения языка. С помощью такой грамматики можно как генерировать фразы, так и анализировать. Например, следующая грамматика описывает «язык», состоящий из произвольного количества букв a, за которым следует произвольное количество букв b:S -> aS | bA | 'empty'
A -> bA | 'empty'
Начав с символа S, можно сгенерировать любую строку вида a...ab...b. Существует также универсальный алгоритм разбора такой грамматики. Скормив ему входную строку и набор правил грамматики, можно получить ответ — является ли строка корректной строкой в рамках данного языка или нет. Можно получить и дерево разбора, показывающее, каким образом строка выводится из начального символа S.
Допустим, строке aabb соответствует вот такое дерево:
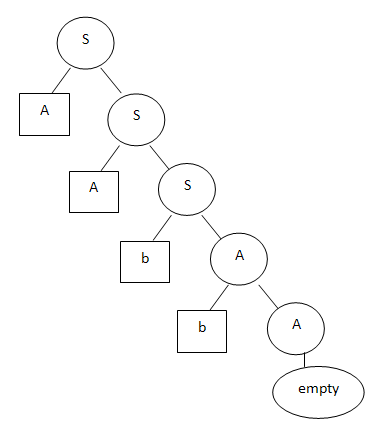
Явный плюс этого метода состоит в том, что грамматики Хомского — формализм давно известный. Существуют давно разработанные алгоритмы разбора, известны «формальные свойства» грамматик, т.е. их выразительные способности, сложность обработки и т.п. Кроме того, грамматики Хомского успешно применяются при компиляции языков программирования.
Сам Хомский прежде всего лингвист, и свои работы он примерял на естественный язык, английский, в первую очередь. Поэтому в англоязычной компьютерной лингвистике влияние его трудов достаточно велико. Хотя «в лоб» сейчас формализмы Хомского, насколько мне известно, при обработке текстов на естественном языке не применяют (они недостаточно развиты для этого), дух его школы живёт.
Хороший пример синтаксического анализатора, строящего подобные деревья — Stanford parser (есть онлайн-демо).
Модель отношений между словами
Вообще этот подход тоже трудно назвать особо свежим. Все ссылаются на работы Люсьена Теньера (Lucien Tesniere) пятидесятых годов как на первоисточник. Упоминают и более ранние мысли (но из той же оперы, что называть отцом ООП Платона, т.к. он ввёл в оборот понятие «мира идей», то есть абстрактных классов). Однако в компьютерной лингвистике dependency parsing долгое время был на втором плане, в то время как грамматики Хомского активно применялись. Вероятно, ограничения подхода Хомского особенно больно ударили по языкам с более свободным (чем в английском) порядком слов, поэтому самые интересные работы в области dependency parsing до сих пор выполняются «снаружи» англоязычного мира.
Основная идея dependency parsing — соединять между собой зависимые слова. Центром практически любой фразы является глагол (явный или подразумеваемый). Далее от глагола (действия) можно задавать вопросы: кто делает, что делает, где делает и так далее. Для присоединённых сущностей тоже можно задать вопросы (в первую очередь, вопрос «какой»). Например, для приведённого выше дерева «я купил кофе в большом магазине» можно воспроизвести такую цепочку вопросов. Корень — купил (действие фразы). Кто купил? — Я. Что купил? — Кофе. Где купил? — В магазине. В каком магазине? — В большом.
Здесь тоже есть множество технических тонкостей и неоднозначностей. Можно по-разному обрабатывать отсутствие глагола. Обычно всё равно подразумевается глагол «to be»: «Я [есть] студент». В предикативных предложениях дело обстоит сложнее: На улице сыро. Не скажешь же, что на улице есть сыро :) Не всегда понятно, что от чего зависит, и как это трактовать. Например, «я не пойду сегодня на работу». Как соотносится с прочими словами частица «не»? Как вариант, можно считать, что здесь используется глагол «недеяния» «не_пойду» (пусть в русском такого нет, но по смыслу подходит). Не совсем понятно, как лепить однородные члены, соединённые союзом. «Я купил кофе и булочку». Например, можно лепить к «купил» слово «и», а к «и» присоединять уже «кофе» и «булочку». Но есть и другие подходы. Довольно тонкий момент возникает при взаимодействии слов, образующих некое единство: «я буду ходить на работу». Понятно, что «буду ходить» — это по сути один-единственный глагол (то есть действие) будущего времени, просто создан он двумя словами.
Если хочется посмотреть на такой анализатор в действии — могу посоветовать сайт фирмы Connexor.
Чем dependency parsing притягателен? Приводят разные аргументы. Например, говорится, что соединяя между собой слова, мы не создаём дополнительных сущностей, и, стало быть, упрощаем дальнейший анализ. В конце концов, синтаксический анализ — это лишь очередной этап обработки текста, и дальше надо представлять, что с полученным деревом делать. В каком-то смысле дерево зависимостей «чище», ибо показывает явные семантические связи между элементами предложения. Далее, нередко утверждают, что dependency parsing больше подходит для языков со свободным порядком слов. У Хомского все зависимые блоки так или иначе действительно оказываются рядом друг с другом. Здесь же в теории можно иметь связи между словами на разных концах предложения (хотя и здесь технически не так всё просто, но об этом позже). В принципе, уже этих аргументов для меня достаточно, чтобы примкнуть к лагерю Теньера :)
Надо сказать, что существуют формальные доказательства близости получающихся деревьев. Где-то проскакивала теорема о том, что дерево одного вида можно сконвертировать в дерево другого вида и наоборот. Но на практике это не работает. По крайней мере, на моей памяти никто не пытался получить дерево зависимостей путём преобразования выходных данных Stanford parser'а. Видимо, не всё так просто, да и ошибки множатся… сначала стэнфордский парсер ошибётся, потом алгоритм конвертации ошибётся… и что получится в конце? Ошибка на ошибке.
(UPD: упомянутые ребята из Стэнфорда всё же протестировали метод конвертации выходных данных своего парсера в dependency-структуры. Однако должен заметить, что при такой конвертации получаются только проективные деревья, речь о которых идёт в пятой части).
Наверно, на сегодня хватит. Продолжим в следующей части.







