Статья рассказывает об организации отказоустойчивого файлового сервера на базе пакета Samba. Для понимая материала нужно иметь общее представление об администрировании ОС Linux, а также иметь опыт работы с обычной версией Samba.

Samba – это сервис CIFS, разработанный для того чтобы обеспечить семантику протокола CIFS (и соответственно доступ с машин под управлением Windows) к среде, использующей POSIX файловую систему. Основная функция Samba – преобразовать богатую семантику, которую используют клиенты на базе Windows к значительно более бедной семантике файловой системы POSIX.
Чтобы производить такие преобразования Samba использует множество внутренних баз метаданных, содержащих дополнительную информацию, используемую при преобразовании семантики.
Дополнительные параметры в частности отвечают за такую вещь, как одновременное открытие одного и того же файла с разных клиентов и многое другое.
Эта информация в обязательном порядке обрабатывается перед непосредственным открытием файла в POSIX.
Таким образом, осуществляется прозрачный доступ с клиентов Windows к POSIX файловой системе.
Отказоустойчивость Samba базируется на трех положениях:
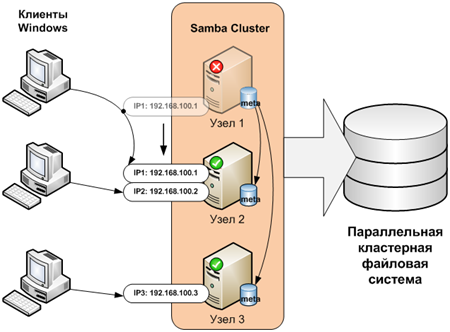
Данная статья описывает только механизм создания отказоустойчивого сервиса CIFS. Обязательным условием для его реализации является применение параллельной кластерной файловой системы, которая используется непосредственно для хранения файлов.
Описание кластерных систем выходит за рамки данной статьи. Как пример, можно использовать файловые системы GPFS или Lustre.
Обычные не кластерные версии Samba используют для хранения данных очень простую и не требовательную к ресурсам базу данных, называемую Trivial Database (TDB).
TDB организована по принципу «ключ — значение» и по организации схожа с Berkley DB. TDB обеспечивает очень быстрый множетсвенный доступ как на чтение, так и на запись от различных процессов в POSIX системе. Поддерживается отражение в память (mmap) на большинстве архитектур.
Каждое клиентское подключение к файловой системе обслуживается собственным процессом демона smbd. Между собой эти процессы взаимодействуют через базу TDB.
Первые попытки реализовать кластерную версию SAMBA заключались в том, чтобы просто разместить файлы, содержащие TDB на кластерной файловой системе, такой как GPFS или Lustre.
Такие реализации SAMBA работали, но были крайне медленными. Снижение скорости происходило из-за высоких накладных расходов и латентности в протоколах синхронизации кластерных файловых систем. В то время, как для успешной работы Samba нужно обеспечить очень быстрый доступ к TDB.
Фундаментом функционирования кластерных файловых систем, является то, что они предохраняют данные от потерь. Даже если клиент начал запись данных, а узел, куда предполагалось их записать, вышел из строя, они не потеряются.
Таким образом, кластерная файловая система должна или записывать данные на общее хранилище или рассылать изменения на все узлы кластера.
Однако это утверждение не вполне верно для метаданных Samba. В определенной ситуации, потеря этих данных не скажется на возможности осуществлять необходимое преобразование семантики между CIFS и POSIX.
Таким образом, становится возможным реализовать кластерную систему, которая не требует общего хранилища метаданных и репликации данных при записи.
Сразу скажем, что это относиться не ко всем метаданным.
Существуют два вида TDB баз данных — постоянные и не постоянные.
Постоянные (Persistent) — содержат долговременную информацию, которая должна сохранятся даже после перезапуска. Эти базы данных в значительной степени чащи используются для чтения, чем для записи. Скорость доступа на запись к этому виду баз данных не является критичной. Главным здесь является надежность.
Непостоянные — такие как база данных блокировок или сессий. Хранимые здесь данные обладают коротким жизненным циклом. Частота записи в эти базы данных очень высокая. Они также часто упоминаются как «normal TDB».
Для успешной работы Samba особенно важна высокая производительность при работе с «normal TDB».
Потеря информации возможна только для непостоянных баз данных.
В таблицах ниже приведен перечень и описание баз, используемых в кластерной реализации Samba.
Таблица 1 Постоянные (Persistent) базы TDB
Таблица 2 временные (normal) базы TDB
Таким образом, мы видим какую информацию мы можем потерять. Это информация о сессиях, блокировках, а также, по всей видимости (данные в Интернет отсутствуют) специфическая информация необходимая для работы кластера.
При выходе узла из строя, все открытые на нем файлы будут закрыты, соответственно потеря вышеперечисленной информации не будет критичной.
Ключевым компонентом в Samba кластере является демон CTDBD. Он обеспечивает поддержку кластерного варианта баз данных TDB, названных CTDB (Cluster Trivial DataBase), с возможностью их автоматического восстановления.
Также CTDBD занимается мониторингом узлов кластера и выполняет его автоматическую реконфигурацию в случае сбоя.
Обеспечение балансировки нагрузки еще одна задача CTDBD.
В зависимости от типа базы данных, обработка ее ведется по-разному.
Ключевой особенностью временных TDB является то, что для них нет необходимости содержать все записи в рамках кластера. В большинстве случаев временные TDB содержат только записи относящиеся к соединениям данного конкретного узла. Соответственно, при его падении, будут потеряны только эти данные.
Система CTDB использует распределенный протокол для операций над базами метаданных между демонами CTDBD на каждом узле, а также локальный протокол для коммуникации внутри узла между демонами Samba и демонами CTDBD.
Дизайн CTDB использует двухуровневую систему хранения записей. На первом уровне для каждой записи определяется хозяин местоположения – «location master». Этот хозяин привязывается к записи по ее ключу.
На втором уровне определяется roving «data master» (перемещаемый или бродячий хозяин данных). Им является последний узел, который модифицировал запись.
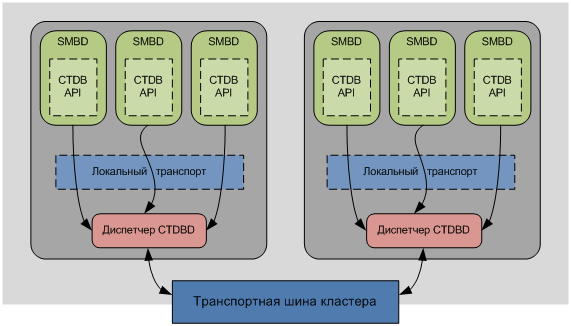
«Location master» всегда знает на каком узле находится запись и соответственно какой узел является «data master». «Data master» в свою очередь содержит наиболее актуальную копию записи.
Каждая запись содержит глобальный порядковый номер – RSN (record sequence number) – 64-х битное целое число, которое увеличивается каждый раз, когда «data master» перемещается с узла на узел. Смена владельца записи «Data Master» всегда происходит через «Location master».
Узел содержит только те записи в локальной TDB, к которым он уже имел доступ. Данные автоматически не распространяются на другие узлы, а могут быть переданы только по запросу.
Только один узел содержит актуальную копию записи – «Data Master». Когда какой-нибудь узел хочет записать или прочитать запись, он сначала проверяет является ли он «data master» для этого узла. Если да, то он производит прямую запись в TDB. Если нет, то он запрашивает с текущего «data master» актуальное содержимое записи, забирает себе роль «data master» и затем производит прямую запись.
Таким образом, запись и чтение данных всегда происходит локально, что значительно повышает производительность.
Когда какой-либо узел умирает, записи для которых он являлся «data master» теряются.
CTDBD начинает процесс восстановления. Для этого выбирается узел хозяин процесса восстановления – «recovery master». После того как узел выбран, на кластерной файловой системе он устанавливает блокировку на определенный файл (который задается в конфигурации), дабы другие узлы не могли более претендовать на роль «recovery master».
«Recover Master» собирает наиболее актуальные версии записей со всех узлов. Актуальность определяется по значению RSN. Наиболее актуальной считается запись с большим RSN.
Для этой базы данных каждый узел всегда имеет полную актуальную копию базы.
Чтение происходит всегда из локальной копии. Когда какому-либо узлу необходимо произвести запись, он выполняет транзакцию, которая полностью блокирует всю базу данных на всех узлах.
Затем он выполняет необходимые ему операции записи. После чего изменения записываются в локальные копии базы данных на всех узлах и транзакция завершается.
Таким образом, на всех узлах кластера всегда содержится полная и актуальная копия базы данных. Задержки, возникающие в процессе синхронизации, являются не критичными, из-за не высокой частоты изменений в этих базах.
При сбое одного из узлов, вся необходимая информация есть на остальных членах кластера.
В дополнение к защите баз метаданных CTDBD использует интегрированный механизм защиты от сбоев протоколов TCP/IP.
Он состоит в использовании кластером набора публичных IP адресов, которые распределяются по узлам кластера. Эти адреса могут переноситься с узла на узел посредством обновлений в протоколе ARP (Address Resolution Protocol).
В случае выхода из строя какого-либо узла, все его публичные ip адреса будут переданы на работающие узлы.
Публичными являются адреса, через которые происходит обращение клиентов. Для коммуникаций между уздами кластера используются внутренние ip адреса.
Узел, который принял на себя IP адрес другого, знает о старых TCP соединениях только то, что они были, и не знает «TCP squence number» соединений. Соответственно, не может их продолжить. Также как и клиент, ничего не знает о том, что соединения теперь осуществляются с другим узлом.
Для того чтобы избежать задержек связанных с переключением соединения используется следующий прием. Для понимания этого приема нужно понимать основные принципы функционирования протокола TCP.
Новый узел, получив себе ip адрес, посылает клиенту пакет с флагом ACK и заведомо неправильным «squence number» равным нулю. В ответ клиент, в соответствии с правилами работы протокола TCP, отправляет назад пакет ACK Reply с корректным «squence number». Получив корректный «squence number» узел формирует пакет с флагом RST и этим «squence number». Получив его, клиент незамедлительно перезапускает соединение.
Задержки весьма минимальные. Без применения этой методики клиент может долгое время ждать от сервера пакета TCP ACK.
Как уже говорилось выше, при сбое одного из узлов и переносе ip адреса, вся ответственность за продолжение работы после сбоя лежит на клиенте. Все открытые файлы ассоциированные со сбойным узлом закрываются.
Если вы копируете или читаете какой-либо файл в проводнике Windows, то при сбое вы получите ошибку. Однако, если вы используете средства, которые могут возобновлять подключение после потери связи, все пройдет гладко. Например, утилита xcopy с ключем «/z». При копировании файлов с помощью этой утилиты вы получите только лишь небольшую задержку на время переключения ip адреса. Затем, копирование продолжиться.
Подключение к сетевым ресурсам также не теряется.
Если вы открыли какой-либо файл в редакторе, и момент сохранения не приходится на переезд ip адреса, то сбои также не отражаются на работе.
Таким образом, часть ответственности за восстановление работы после сбоя в данном случае перенесено на клиента.
Настройка Samba кластера
Настройка кластера состоит из двух шагов:
Начиная с версии 3.3 исходные тесты Samba имеют встроенную поддержку кластеризации. Тем не менее, для работы в кластере вы должны скомпилировать пакет с использованием специальных ключей.
С сайта enterprisesamba.com можно скачать скомпилированную версию Samba с поддержкой кластеризации для популярных дистрибутивов: RHEL, SLES, Debian.
Важное замечание. Для того, чтобы клиенты Windows могли успешно аутентифицироваться в Samba кластере, желательно использовать внешнюю авторизацию. Например, через Active Directory.
Для доступа пользователей Windows к Posix файловой системе Samba устанавливает соответствие между Windows пользователем и пользователем POSIX системы (например, Linux). Пользователь Windows должен осуществить доступ к файловой системе POSIX из-под имени какого-либо известного POSIX операционной системе пользователя. Авторизация пользователя Windows происходит независимо от авторизации пользователя в POSIX ОС.
Т.е. для того, чтобы пользователь Windows смог получить доступ необходимо:
Таблица связей между пользователями и пароли могут храниться в базе данных CTDB и распределятся внутри кластера. Однако, локальная база пользователей такой возможностью не обладает. Т.е. каждый раз при создании пользователей в Samba мы должны будем создавать на всех узлах кластера соответствующие локальные учетные записи.
Это неудобно. Для того чтобы этого избежать, имеет смысл совместно с локальной базой пользователей использовать внешнюю базу. В нашем случае используется интеграция с Active Directoty. Кластер Samba является членом домена.
В файле /etc/nsswitch.conf необходимо прописать:
passwd: files winbind
group: files winbind
shadow: files winbind
Это значит, что кроме локальных файлов поиск пользователей и групп будет осуществляться в Active Directory через winbind. Сервис winbind позволяет пользователям домена Windows авторизоваться на машинах Unix. Таким образом, осуществляется прозрачное управление доступом.
Авторизация в домене Active Directory осуществляется по протоколу Kerberos. Необходимо выполнить соответствующие настройки для библиотеки Kerberos – «/etc/krb5.conf».
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = IT-DYNAMICS.RU – домен Active Directory
dns_lookup_realm = true – избавляет от необходимости прописывать сервера вручную
dns_lookup_kdc = true – избавляет от необходимости прописывать сервера вручную
ticket_lifetime = 24h
forwardable = yes
[domain_realm]
.it-dynamics.ru = IT-DYNAMICS.RU
.it-dynamics.ru = IT-DYNAMICS.RU
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}
Ну и, наконец, необходимо настроить саму Samba.
[global]
clustering = yes
netbios name = smbcluster
workgroup = otd100
security = ADS
realm = IT-DYNAMICS.RU
encrypt passwords = yes
client lanman auth = no
client ntlmv2 auth = yes
passdb backend = tdbsam
groupdb:backend = tdb
idmap backend = tdb2
idmap uid = 1000000-2000000
idmap gid = 1000000-2000000
fileid:algorithm = fsname
vfs objects = gpfs fileid
gpfs:sharemodes = No
force unknown acl user = yes
nfs4: mode = special
nfs4: chown = yes
nfs4: acedub = merge
registry shares = yes
Ключевой параметр в /etc/samba/smb.conf – «clustering = yes». Включаем поддержку кластеризации. В параметрах «netbios name» прописываем имя нашего кластера, которое будет общим для всех узлов.
Для того чтобы осуществить прозрачное управление общими ресурсами, необходимо включить в настройках Samba поддержку registry – «registry shares = yes». В противном случае, если настройки общих папок содержаться в smb.conf, мы будем вынуждены осуществлять синхронизацию этого файла между всеми узлами кластера.
В любом случае, «/etc/samba/smb.conf» должен быть одинаковым на всех узлах.
Для успешной авторизации пользователей, кластер Samba необходимо ввести в домен Active Directory командой: net ads join -U Administrator
Где «Administrator», пользователь, обладающий правами на добавление компьютеров в домен.
CTDB поставляется в виде отдельного пакета. Исходные тексты могут быть загружены с ctdb.samba.org. Также здесь имеются скомпилированные версии для RHEL x64. Для x86 можно скачать src.rpm и скомпилировать самостоятельно.
Параметры CTDB находятся в файле /etc/sysconfig/ctdb.conf
Данный файл также должен быть одинаковым на всех узлах кластера.
Важнейшие параметры:
CTDB_RECOVERY_LOCK=/gpfs-storage/ctdb/lock
Определяет местоположение lock файла, который используется при выборе «recovery master» при восстановлении после сбоя. Обязательно должен располагаться на кластерной файловой системе с поддержкой блокировок.
CTDB_PUBLIC_INTERFACE=eth1
Интерфейс, через который будет осуществляться взаимодействие клиентов с кластером.
CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses путь к файлу, содержащему возможные публичные ip адреса, через которые будет осуществляться работа с кластером.
CTDB_MANAGES_SAMBA=yes
Демон CTDB управляет сервисами Samba. Это удобно для корректной работы Samba в кластере. CTDB сам будет запускать или выключать Samba когда это необходимо. При этом Samba из автозапуска должна быть убрана.
CTDB_MANAGES_WINBIND=yes
Аналогично предыдущему случаю – управление Winbind.
CTDB_NODES=/etc/ctdb/nodes
Список внутренних адресов улов кластера. Файл nodes обязательно должен быть уникальным на всех узлах.
В файле /etc/ctdb/public_addresses необходимо прописать все возможные публичные ip адреса для подключения клиентов.
В файле /etc/ctdb/nodes нужно прописать внутренние ip адреса всех узлов кластера.
Возможны два способа балансировки нагрузки:
Сразу отметим, что ни один из методов не позволяет выполнять балансировку в зависимости от загрузки серверов. Балансировка по большому счету сводится к поочередному перенаправлению клиентов на разные узлы кластера.
В этом случае в DNS для одного имени кластера прописывается несколько ip адресов. При обращении клиентов, сервер DNS поочередно выдает им разные ip адреса кластера. Таким образом, каждый следующий клиент подключается к новому ip адресу и так далее по кругу.
В этом случае весь кластер представлен клиентам через один ip адрес. Один из узлов выбирается как LVSMaster. Ему присваивается ip адрес кластера. Все клиенты отправляют запрос на этот адрес. Затем LVSMaster перенаправляет запрос одному из узлов. Узел, в свою очередь, непосредственно отвечает клиенту без привлечения LVSMaster.
Схема с использованием LVS может дать очень неплохие результаты при множественных операциях чтения. В то время как при операциях записи все будет упираться в быстродействие и пропускную способность сети у LVSMaster.
Управление осуществляется при помощи команды ctdb. По умолчанию выполняется на текущем узле. При помощи ключа «-n» можно задать другой узел.
Ctdb status – выдает состояние кластера
Number of nodes:2
pnn:0 172.0.16.101 OK
pnn:1 172.0.16.102 OK (THIS NODE)
Generation:985898984
Size:2
hash:0 lmaster:0
hash:1 lmaster:1
Recovery mode:NORMAL (0)
Recovery master:0
Состояние узла может быть:
RECOVERY MASTER – узел, выбранный мастером восстановления
Ctdb ip показывает публичные ip адреса кластера и их распределение по узлам
Public IPs on node 1
128.0.16.110 node[1] active[eth0] available[eth0] configured[eth0]
128.0.16.111 node[0] active[] available[eth0] configured[eth0]
Первая строчка – текущий нод, на котором выполнена команда.
Ctdb pnn – отображает номер узла на котором выполнена команда
Ctdb disable – перевести текущий узел в положение Disable
Ctdb enable – вернуть из положения Disable
Ctdb stop — перевести текущий узел в положение Stop (произойдет реконфигурация кластера)
Ctdb continue – вернуть из положения Stop (произойдет реконфигурация кластера)
moveip public_ip node вручную переносит публичный ip адрес с одного узла на другой
ctdb getdbmap – выводит на экран список баз CTDB.
Number of databases:13
dbid:0x1c904dfd name:notify_onelevel.tdb path:/var/ctdb/notify_onelevel.tdb.0
dbid:0x435d3410 name:notify.tdb path:/var/ctdb/notify.tdb.0
dbid:0x42fe72c5 name:locking.tdb path:/var/ctdb/locking.tdb.0
dbid:0x1421fb78 name:brlock.tdb path:/var/ctdb/brlock.tdb.0
dbid:0xc0bdde6a name:sessionid.tdb path:/var/ctdb/sessionid.tdb.0
dbid:0x17055d90 name:connections.tdb path:/var/ctdb/connections.tdb.0
dbid:0xf2a58948 name:registry.tdb path:/var/ctdb/persistent/registry.tdb.0 PERSISTENT
dbid:0x63501287 name:share_info.tdb path:/var/ctdb/persistent/share_info.tdb.0 PERSISTENT
dbid:0x92380e87 name:account_policy.tdb path:/var/ctdb/persistent/account_policy.tdb.0 PERSISTENT
dbid:0x7bbbd26c name:passdb.tdb path:/var/ctdb/persistent/passdb.tdb.0 PERSISTENT
dbid:0x2672a57f name:idmap2.tdb path:/var/ctdb/persistent/idmap2.tdb.0 PERSISTENT
dbid:0xe98e08b6 name:group_mapping.tdb path:/var/ctdb/persistent/group_mapping.tdb.0 PERSISTENT
dbid:0xb775fff6 name:secrets.tdb path:/var/ctdb/persistent/secrets.tdb.0 PERSISTENT
ctdb shutdown – остановить демон ctdb (эквивалент service stdb stop)
В папке «/etc/ctdb» находится скрипт «notify.sh». Он каждый раз вызывается, когда у узла меняется состояние здоровья. В него можно записать, например, посылку SNMP Trap или отправку сообщений электронной почтой администратору.
Статья показала принципы организации отказоустойчивого сервиса Samba. Ключевыми моментами являются:
Samba – это сервис CIFS, разработанный для того чтобы обеспечить семантику протокола CIFS (и соответственно доступ с машин под управлением Windows) к среде, использующей POSIX файловую систему. Основная функция Samba – преобразовать богатую семантику, которую используют клиенты на базе Windows к значительно более бедной семантике файловой системы POSIX.
Чтобы производить такие преобразования Samba использует множество внутренних баз метаданных, содержащих дополнительную информацию, используемую при преобразовании семантики.
Дополнительные параметры в частности отвечают за такую вещь, как одновременное открытие одного и того же файла с разных клиентов и многое другое.
Эта информация в обязательном порядке обрабатывается перед непосредственным открытием файла в POSIX.
Таким образом, осуществляется прозрачный доступ с клиентов Windows к POSIX файловой системе.
Отказоустойчивость Samba базируется на трех положениях:
- Восстановление баз метаданных Samba
- Доступность файлов пользователей, основанная на кластерной файловой системе
- Сетевой механизм защиты от сбоев, заключающийся в передаче IP адреса от вышедшего из строя узла на рабочий узел
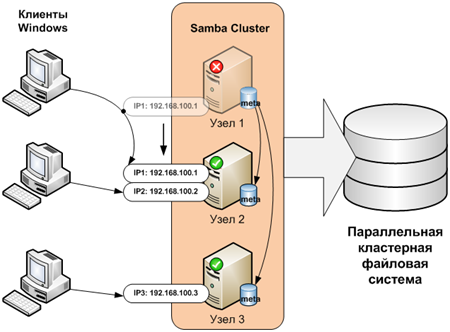
Данная статья описывает только механизм создания отказоустойчивого сервиса CIFS. Обязательным условием для его реализации является применение параллельной кластерной файловой системы, которая используется непосредственно для хранения файлов.
Описание кластерных систем выходит за рамки данной статьи. Как пример, можно использовать файловые системы GPFS или Lustre.
Базы метаданных – Trivial Database
Обычные не кластерные версии Samba используют для хранения данных очень простую и не требовательную к ресурсам базу данных, называемую Trivial Database (TDB).
TDB организована по принципу «ключ — значение» и по организации схожа с Berkley DB. TDB обеспечивает очень быстрый множетсвенный доступ как на чтение, так и на запись от различных процессов в POSIX системе. Поддерживается отражение в память (mmap) на большинстве архитектур.
Каждое клиентское подключение к файловой системе обслуживается собственным процессом демона smbd. Между собой эти процессы взаимодействуют через базу TDB.
Первые попытки реализовать кластерную версию SAMBA заключались в том, чтобы просто разместить файлы, содержащие TDB на кластерной файловой системе, такой как GPFS или Lustre.
Такие реализации SAMBA работали, но были крайне медленными. Снижение скорости происходило из-за высоких накладных расходов и латентности в протоколах синхронизации кластерных файловых систем. В то время, как для успешной работы Samba нужно обеспечить очень быстрый доступ к TDB.
Фундаментом функционирования кластерных файловых систем, является то, что они предохраняют данные от потерь. Даже если клиент начал запись данных, а узел, куда предполагалось их записать, вышел из строя, они не потеряются.
Таким образом, кластерная файловая система должна или записывать данные на общее хранилище или рассылать изменения на все узлы кластера.
Однако это утверждение не вполне верно для метаданных Samba. В определенной ситуации, потеря этих данных не скажется на возможности осуществлять необходимое преобразование семантики между CIFS и POSIX.
Таким образом, становится возможным реализовать кластерную систему, которая не требует общего хранилища метаданных и репликации данных при записи.
Сразу скажем, что это относиться не ко всем метаданным.
Существуют два вида TDB баз данных — постоянные и не постоянные.
Постоянные (Persistent) — содержат долговременную информацию, которая должна сохранятся даже после перезапуска. Эти базы данных в значительной степени чащи используются для чтения, чем для записи. Скорость доступа на запись к этому виду баз данных не является критичной. Главным здесь является надежность.
Непостоянные — такие как база данных блокировок или сессий. Хранимые здесь данные обладают коротким жизненным циклом. Частота записи в эти базы данных очень высокая. Они также часто упоминаются как «normal TDB».
Для успешной работы Samba особенно важна высокая производительность при работе с «normal TDB».
Потеря информации возможна только для непостоянных баз данных.
В таблицах ниже приведен перечень и описание баз, используемых в кластерной реализации Samba.
Таблица 1 Постоянные (Persistent) базы TDB
| Имя | ОПИСАНИЕ |
| account_policy | Установки политики учетной записи Samba/NT, включая настройки срока действия пароля. |
| group_mapping | Таблица соответствия групп/SID Windows группам UNIX. |
| passdb | Существует только при использовании tdbsam. Этот файл хранит информацию SambaSAMAccount. Необходимо помнить, что для этого файла требуется, чтобы информация о пользовательских учетных записях POSIX была доступна из файла /etc/passwd, либо из другого системного источника. |
| registry | База данных Samba, предназначенная только для чтения, и хранящая скелет реестра Windows, который обеспечивает поддержку для экспорта различных таблиц баз данных через winreg RPC (вызовы удаленных процедур). |
| secrets | Этот файл хранит SID рабочей группы/домена/компьютера, пароль обновления каталога LDAP и другие важные данные об окружении, которые необходимы для корректной работы Samba. Этот файл содержит очень важную информацию, которая должна быть защищена. Она хранится в каталоге PRIVATE_DIR. |
| share_info | Хранит информацию ACL для каждого ресурса. |
| Idmap2 | База данных IDMAP Winbindd. |
Таблица 2 временные (normal) базы TDB
| Имя | ОПИСАНИЕ |
| brlock | Информация о блокировках диапазонов байтов. |
| Locking | Таблица блокировок файловой системы |
| connections | Временный кэш информации о текущем соединении, используемый для отслеживания максимального числа соединений. |
| Notify_onelevel | Предположительно используются для обмена сообщениями между демонами ctdb |
| notify | Предположительно используются для обмена сообщениями между демонами ctdb |
| sessionid | Временный кэш для различной информации о сессиях и обслуживания utmp. |
Таким образом, мы видим какую информацию мы можем потерять. Это информация о сессиях, блокировках, а также, по всей видимости (данные в Интернет отсутствуют) специфическая информация необходимая для работы кластера.
При выходе узла из строя, все открытые на нем файлы будут закрыты, соответственно потеря вышеперечисленной информации не будет критичной.
Демон CTDBD и работа с базами данных TDB в кластере
Ключевым компонентом в Samba кластере является демон CTDBD. Он обеспечивает поддержку кластерного варианта баз данных TDB, названных CTDB (Cluster Trivial DataBase), с возможностью их автоматического восстановления.
Также CTDBD занимается мониторингом узлов кластера и выполняет его автоматическую реконфигурацию в случае сбоя.
Обеспечение балансировки нагрузки еще одна задача CTDBD.
В зависимости от типа базы данных, обработка ее ведется по-разному.
Работа с временной TDB
Ключевой особенностью временных TDB является то, что для них нет необходимости содержать все записи в рамках кластера. В большинстве случаев временные TDB содержат только записи относящиеся к соединениям данного конкретного узла. Соответственно, при его падении, будут потеряны только эти данные.
Система CTDB использует распределенный протокол для операций над базами метаданных между демонами CTDBD на каждом узле, а также локальный протокол для коммуникации внутри узла между демонами Samba и демонами CTDBD.
Дизайн CTDB использует двухуровневую систему хранения записей. На первом уровне для каждой записи определяется хозяин местоположения – «location master». Этот хозяин привязывается к записи по ее ключу.
На втором уровне определяется roving «data master» (перемещаемый или бродячий хозяин данных). Им является последний узел, который модифицировал запись.
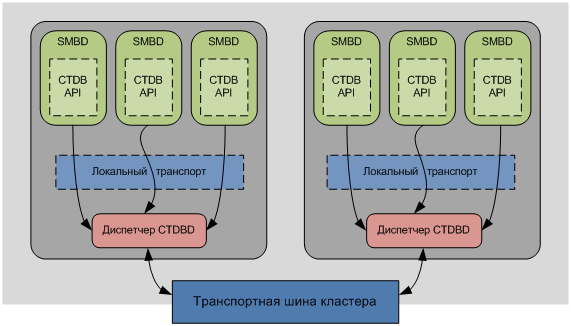
«Location master» всегда знает на каком узле находится запись и соответственно какой узел является «data master». «Data master» в свою очередь содержит наиболее актуальную копию записи.
Каждая запись содержит глобальный порядковый номер – RSN (record sequence number) – 64-х битное целое число, которое увеличивается каждый раз, когда «data master» перемещается с узла на узел. Смена владельца записи «Data Master» всегда происходит через «Location master».
Узел содержит только те записи в локальной TDB, к которым он уже имел доступ. Данные автоматически не распространяются на другие узлы, а могут быть переданы только по запросу.
Только один узел содержит актуальную копию записи – «Data Master». Когда какой-нибудь узел хочет записать или прочитать запись, он сначала проверяет является ли он «data master» для этого узла. Если да, то он производит прямую запись в TDB. Если нет, то он запрашивает с текущего «data master» актуальное содержимое записи, забирает себе роль «data master» и затем производит прямую запись.
Таким образом, запись и чтение данных всегда происходит локально, что значительно повышает производительность.
Когда какой-либо узел умирает, записи для которых он являлся «data master» теряются.
CTDBD начинает процесс восстановления. Для этого выбирается узел хозяин процесса восстановления – «recovery master». После того как узел выбран, на кластерной файловой системе он устанавливает блокировку на определенный файл (который задается в конфигурации), дабы другие узлы не могли более претендовать на роль «recovery master».
«Recover Master» собирает наиболее актуальные версии записей со всех узлов. Актуальность определяется по значению RSN. Наиболее актуальной считается запись с большим RSN.
Работа с постоянной TDB
Для этой базы данных каждый узел всегда имеет полную актуальную копию базы.
Чтение происходит всегда из локальной копии. Когда какому-либо узлу необходимо произвести запись, он выполняет транзакцию, которая полностью блокирует всю базу данных на всех узлах.
Затем он выполняет необходимые ему операции записи. После чего изменения записываются в локальные копии базы данных на всех узлах и транзакция завершается.
Таким образом, на всех узлах кластера всегда содержится полная и актуальная копия базы данных. Задержки, возникающие в процессе синхронизации, являются не критичными, из-за не высокой частоты изменений в этих базах.
При сбое одного из узлов, вся необходимая информация есть на остальных членах кластера.
Сетевой механизм защиты от сбоев
В дополнение к защите баз метаданных CTDBD использует интегрированный механизм защиты от сбоев протоколов TCP/IP.
Он состоит в использовании кластером набора публичных IP адресов, которые распределяются по узлам кластера. Эти адреса могут переноситься с узла на узел посредством обновлений в протоколе ARP (Address Resolution Protocol).
В случае выхода из строя какого-либо узла, все его публичные ip адреса будут переданы на работающие узлы.
Публичными являются адреса, через которые происходит обращение клиентов. Для коммуникаций между уздами кластера используются внутренние ip адреса.
Узел, который принял на себя IP адрес другого, знает о старых TCP соединениях только то, что они были, и не знает «TCP squence number» соединений. Соответственно, не может их продолжить. Также как и клиент, ничего не знает о том, что соединения теперь осуществляются с другим узлом.
Для того чтобы избежать задержек связанных с переключением соединения используется следующий прием. Для понимания этого приема нужно понимать основные принципы функционирования протокола TCP.
Новый узел, получив себе ip адрес, посылает клиенту пакет с флагом ACK и заведомо неправильным «squence number» равным нулю. В ответ клиент, в соответствии с правилами работы протокола TCP, отправляет назад пакет ACK Reply с корректным «squence number». Получив корректный «squence number» узел формирует пакет с флагом RST и этим «squence number». Получив его, клиент незамедлительно перезапускает соединение.
Задержки весьма минимальные. Без применения этой методики клиент может долгое время ждать от сервера пакета TCP ACK.
На практике
Как уже говорилось выше, при сбое одного из узлов и переносе ip адреса, вся ответственность за продолжение работы после сбоя лежит на клиенте. Все открытые файлы ассоциированные со сбойным узлом закрываются.
Если вы копируете или читаете какой-либо файл в проводнике Windows, то при сбое вы получите ошибку. Однако, если вы используете средства, которые могут возобновлять подключение после потери связи, все пройдет гладко. Например, утилита xcopy с ключем «/z». При копировании файлов с помощью этой утилиты вы получите только лишь небольшую задержку на время переключения ip адреса. Затем, копирование продолжиться.
Подключение к сетевым ресурсам также не теряется.
Если вы открыли какой-либо файл в редакторе, и момент сохранения не приходится на переезд ip адреса, то сбои также не отражаются на работе.
Таким образом, часть ответственности за восстановление работы после сбоя в данном случае перенесено на клиента.
Настройка Samba кластера
Настройка кластера состоит из двух шагов:
- Настройка демона Samba для работы в кластере
- Настройка CTDB
Настройка Samba и сопуствующих сервисов
Начиная с версии 3.3 исходные тесты Samba имеют встроенную поддержку кластеризации. Тем не менее, для работы в кластере вы должны скомпилировать пакет с использованием специальных ключей.
С сайта enterprisesamba.com можно скачать скомпилированную версию Samba с поддержкой кластеризации для популярных дистрибутивов: RHEL, SLES, Debian.
Важное замечание. Для того, чтобы клиенты Windows могли успешно аутентифицироваться в Samba кластере, желательно использовать внешнюю авторизацию. Например, через Active Directory.
Для доступа пользователей Windows к Posix файловой системе Samba устанавливает соответствие между Windows пользователем и пользователем POSIX системы (например, Linux). Пользователь Windows должен осуществить доступ к файловой системе POSIX из-под имени какого-либо известного POSIX операционной системе пользователя. Авторизация пользователя Windows происходит независимо от авторизации пользователя в POSIX ОС.
Т.е. для того, чтобы пользователь Windows смог получить доступ необходимо:
- Создать локального пользователя в POSIX операционной системе от имени которого будет работать Windows пользователь
- Создать в базе данных Samba пользователя Windows и задать для него пароль
- Установить связь между этими пользователями
Таблица связей между пользователями и пароли могут храниться в базе данных CTDB и распределятся внутри кластера. Однако, локальная база пользователей такой возможностью не обладает. Т.е. каждый раз при создании пользователей в Samba мы должны будем создавать на всех узлах кластера соответствующие локальные учетные записи.
Это неудобно. Для того чтобы этого избежать, имеет смысл совместно с локальной базой пользователей использовать внешнюю базу. В нашем случае используется интеграция с Active Directoty. Кластер Samba является членом домена.
В файле /etc/nsswitch.conf необходимо прописать:
passwd: files winbind
group: files winbind
shadow: files winbind
Это значит, что кроме локальных файлов поиск пользователей и групп будет осуществляться в Active Directory через winbind. Сервис winbind позволяет пользователям домена Windows авторизоваться на машинах Unix. Таким образом, осуществляется прозрачное управление доступом.
Авторизация в домене Active Directory осуществляется по протоколу Kerberos. Необходимо выполнить соответствующие настройки для библиотеки Kerberos – «/etc/krb5.conf».
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = IT-DYNAMICS.RU – домен Active Directory
dns_lookup_realm = true – избавляет от необходимости прописывать сервера вручную
dns_lookup_kdc = true – избавляет от необходимости прописывать сервера вручную
ticket_lifetime = 24h
forwardable = yes
[domain_realm]
.it-dynamics.ru = IT-DYNAMICS.RU
.it-dynamics.ru = IT-DYNAMICS.RU
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}
Ну и, наконец, необходимо настроить саму Samba.
[global]
clustering = yes
netbios name = smbcluster
workgroup = otd100
security = ADS
realm = IT-DYNAMICS.RU
encrypt passwords = yes
client lanman auth = no
client ntlmv2 auth = yes
passdb backend = tdbsam
groupdb:backend = tdb
idmap backend = tdb2
idmap uid = 1000000-2000000
idmap gid = 1000000-2000000
fileid:algorithm = fsname
vfs objects = gpfs fileid
gpfs:sharemodes = No
force unknown acl user = yes
nfs4: mode = special
nfs4: chown = yes
nfs4: acedub = merge
registry shares = yes
Ключевой параметр в /etc/samba/smb.conf – «clustering = yes». Включаем поддержку кластеризации. В параметрах «netbios name» прописываем имя нашего кластера, которое будет общим для всех узлов.
Для того чтобы осуществить прозрачное управление общими ресурсами, необходимо включить в настройках Samba поддержку registry – «registry shares = yes». В противном случае, если настройки общих папок содержаться в smb.conf, мы будем вынуждены осуществлять синхронизацию этого файла между всеми узлами кластера.
В любом случае, «/etc/samba/smb.conf» должен быть одинаковым на всех узлах.
Для успешной авторизации пользователей, кластер Samba необходимо ввести в домен Active Directory командой: net ads join -U Administrator
Где «Administrator», пользователь, обладающий правами на добавление компьютеров в домен.
Настройка CTDB
CTDB поставляется в виде отдельного пакета. Исходные тексты могут быть загружены с ctdb.samba.org. Также здесь имеются скомпилированные версии для RHEL x64. Для x86 можно скачать src.rpm и скомпилировать самостоятельно.
Параметры CTDB находятся в файле /etc/sysconfig/ctdb.conf
Данный файл также должен быть одинаковым на всех узлах кластера.
Важнейшие параметры:
CTDB_RECOVERY_LOCK=/gpfs-storage/ctdb/lock
Определяет местоположение lock файла, который используется при выборе «recovery master» при восстановлении после сбоя. Обязательно должен располагаться на кластерной файловой системе с поддержкой блокировок.
CTDB_PUBLIC_INTERFACE=eth1
Интерфейс, через который будет осуществляться взаимодействие клиентов с кластером.
CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses путь к файлу, содержащему возможные публичные ip адреса, через которые будет осуществляться работа с кластером.
CTDB_MANAGES_SAMBA=yes
Демон CTDB управляет сервисами Samba. Это удобно для корректной работы Samba в кластере. CTDB сам будет запускать или выключать Samba когда это необходимо. При этом Samba из автозапуска должна быть убрана.
CTDB_MANAGES_WINBIND=yes
Аналогично предыдущему случаю – управление Winbind.
CTDB_NODES=/etc/ctdb/nodes
Список внутренних адресов улов кластера. Файл nodes обязательно должен быть уникальным на всех узлах.
В файле /etc/ctdb/public_addresses необходимо прописать все возможные публичные ip адреса для подключения клиентов.
В файле /etc/ctdb/nodes нужно прописать внутренние ip адреса всех узлов кластера.
Балансировка нагрузки
Возможны два способа балансировки нагрузки:
- С использованием Round-Robin DNS
- LVS
Сразу отметим, что ни один из методов не позволяет выполнять балансировку в зависимости от загрузки серверов. Балансировка по большому счету сводится к поочередному перенаправлению клиентов на разные узлы кластера.
Балансировка Round-Robin DNS
В этом случае в DNS для одного имени кластера прописывается несколько ip адресов. При обращении клиентов, сервер DNS поочередно выдает им разные ip адреса кластера. Таким образом, каждый следующий клиент подключается к новому ip адресу и так далее по кругу.
Балансировка LVS
В этом случае весь кластер представлен клиентам через один ip адрес. Один из узлов выбирается как LVSMaster. Ему присваивается ip адрес кластера. Все клиенты отправляют запрос на этот адрес. Затем LVSMaster перенаправляет запрос одному из узлов. Узел, в свою очередь, непосредственно отвечает клиенту без привлечения LVSMaster.
Схема с использованием LVS может дать очень неплохие результаты при множественных операциях чтения. В то время как при операциях записи все будет упираться в быстродействие и пропускную способность сети у LVSMaster.
Управление кластером
Управление осуществляется при помощи команды ctdb. По умолчанию выполняется на текущем узле. При помощи ключа «-n» можно задать другой узел.
Ctdb status – выдает состояние кластера
Number of nodes:2
pnn:0 172.0.16.101 OK
pnn:1 172.0.16.102 OK (THIS NODE)
Generation:985898984
Size:2
hash:0 lmaster:0
hash:1 lmaster:1
Recovery mode:NORMAL (0)
Recovery master:0
Состояние узла может быть:
- OK – нормальное функционирование
- DISCONNECTED – узел физически не доступен
- DISABLED – узел отключен администратором. При этом он функционирует в рамках кластера, но его публичный ip адрес передан на другие узлы и никакие сервисы на нем не выполняются. Однако узел способен обслуживать части баз данных TDB.
- UNHEALTHY – проблемы в работе узла. Демон CTDB функционирует нормально, но публичные ip переданы на другие узлы и никакие сервисы не работают.
- BANNED – Узел предпринимал слишком частые попытки восстановиться и был отключен на определенный период. После окончания этого периода, узел автоматически попытается вернуться в строй.
- STOPPED – Узел остановлен и не участвует в кластере, однако способен принимать команды управления.
- PARTIALLYONLINE – Узел работает, но часть интерфейсов, обслуживающих публичные ip адреса выключена. Как минимум один интерфейс должен быть доступен.
- Recovery mode – режим функционирования кластера:
- NORMAL – рабочий режим
- RECOVERY – кластер находится в режиме восстановления. Все базы данных кластера заблокированы. Сервисы не работают.
RECOVERY MASTER – узел, выбранный мастером восстановления
Ctdb ip показывает публичные ip адреса кластера и их распределение по узлам
Public IPs on node 1
128.0.16.110 node[1] active[eth0] available[eth0] configured[eth0]
128.0.16.111 node[0] active[] available[eth0] configured[eth0]
Первая строчка – текущий нод, на котором выполнена команда.
Ctdb pnn – отображает номер узла на котором выполнена команда
Ctdb disable – перевести текущий узел в положение Disable
Ctdb enable – вернуть из положения Disable
Ctdb stop — перевести текущий узел в положение Stop (произойдет реконфигурация кластера)
Ctdb continue – вернуть из положения Stop (произойдет реконфигурация кластера)
moveip public_ip node вручную переносит публичный ip адрес с одного узла на другой
ctdb getdbmap – выводит на экран список баз CTDB.
Number of databases:13
dbid:0x1c904dfd name:notify_onelevel.tdb path:/var/ctdb/notify_onelevel.tdb.0
dbid:0x435d3410 name:notify.tdb path:/var/ctdb/notify.tdb.0
dbid:0x42fe72c5 name:locking.tdb path:/var/ctdb/locking.tdb.0
dbid:0x1421fb78 name:brlock.tdb path:/var/ctdb/brlock.tdb.0
dbid:0xc0bdde6a name:sessionid.tdb path:/var/ctdb/sessionid.tdb.0
dbid:0x17055d90 name:connections.tdb path:/var/ctdb/connections.tdb.0
dbid:0xf2a58948 name:registry.tdb path:/var/ctdb/persistent/registry.tdb.0 PERSISTENT
dbid:0x63501287 name:share_info.tdb path:/var/ctdb/persistent/share_info.tdb.0 PERSISTENT
dbid:0x92380e87 name:account_policy.tdb path:/var/ctdb/persistent/account_policy.tdb.0 PERSISTENT
dbid:0x7bbbd26c name:passdb.tdb path:/var/ctdb/persistent/passdb.tdb.0 PERSISTENT
dbid:0x2672a57f name:idmap2.tdb path:/var/ctdb/persistent/idmap2.tdb.0 PERSISTENT
dbid:0xe98e08b6 name:group_mapping.tdb path:/var/ctdb/persistent/group_mapping.tdb.0 PERSISTENT
dbid:0xb775fff6 name:secrets.tdb path:/var/ctdb/persistent/secrets.tdb.0 PERSISTENT
ctdb shutdown – остановить демон ctdb (эквивалент service stdb stop)
Мониторинг кластера
В папке «/etc/ctdb» находится скрипт «notify.sh». Он каждый раз вызывается, когда у узла меняется состояние здоровья. В него можно записать, например, посылку SNMP Trap или отправку сообщений электронной почтой администратору.
Заключение
Статья показала принципы организации отказоустойчивого сервиса Samba. Ключевыми моментами являются:
- Возможность потери определенных метаданных без нарушения процесса преобразования семантики CIFS к POSIX
- Часть ответственности за продолжение работы после сбоя перенесена на сторону клиента
- Открытые на узле кластера в момент сбоя файлы закрываются
- Балансировка нагрузки осуществляется последовательным перенаправлением клиентов по разным узлам кластера вне зависимости от ин загрузки.




