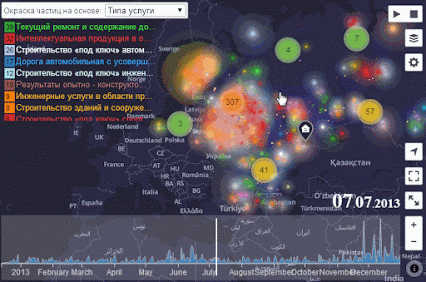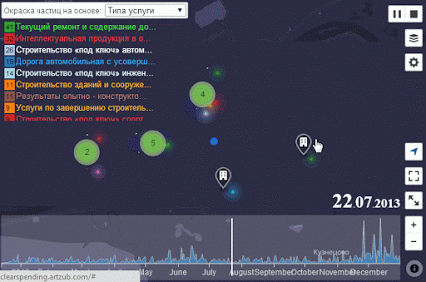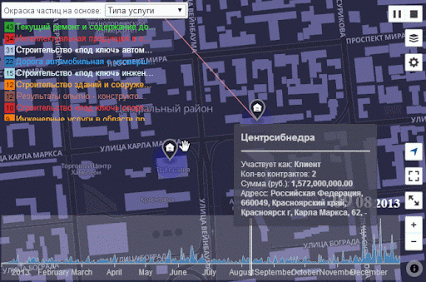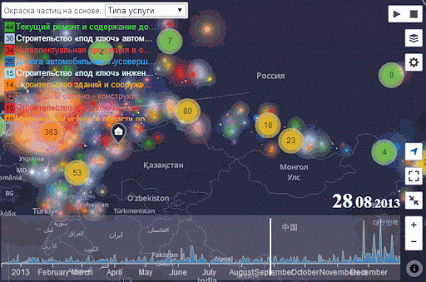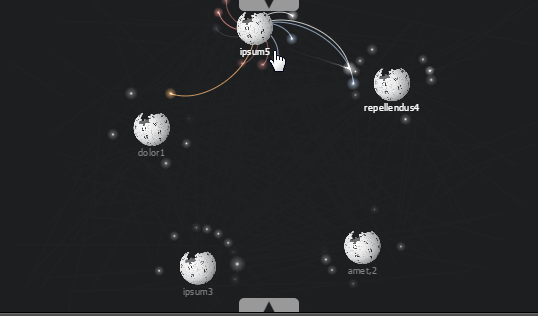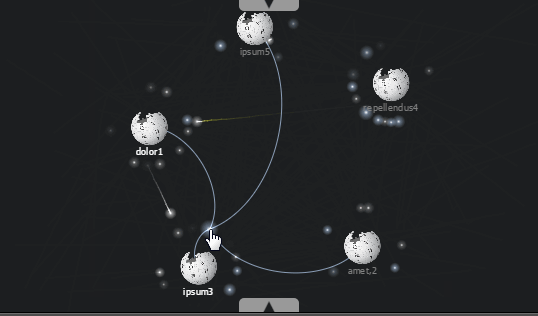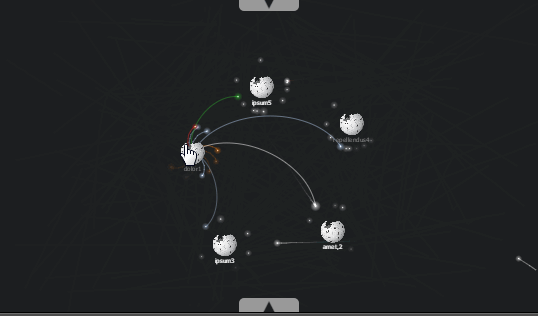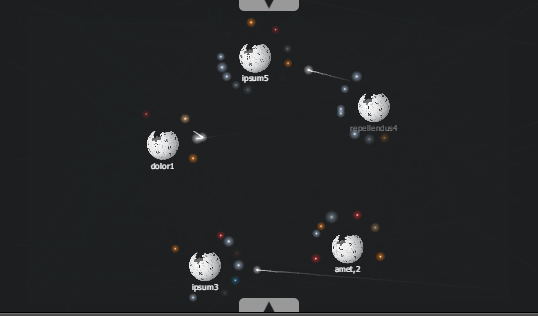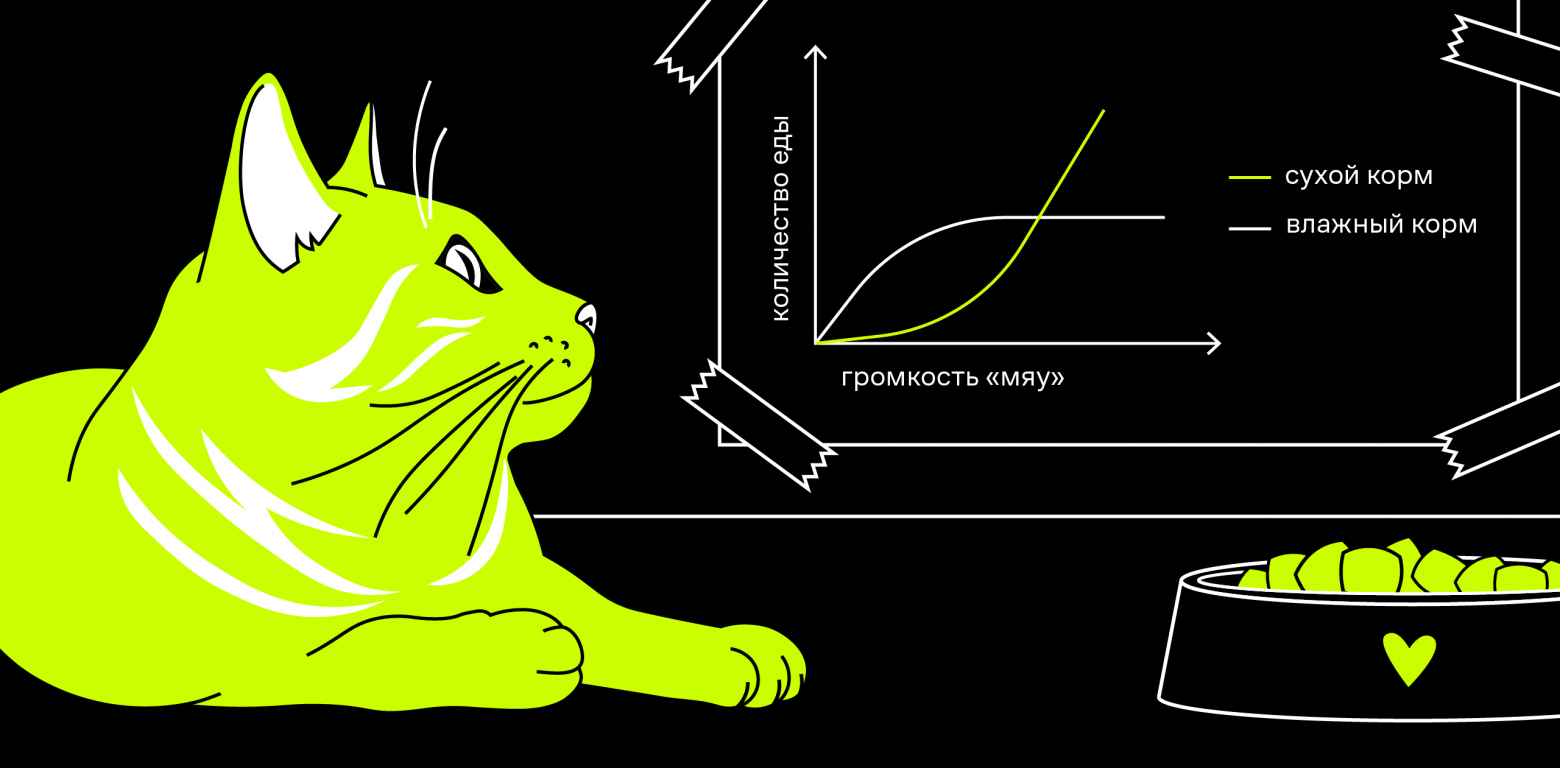
Привет, Хабр. В этой статье я расскажу про своё видение работы с цветом при визуализации графиков. Буду показывать все на примерах — уверен, они вам понравятся.
Я покажу не только картинки было-стало, но и приведу примеры кода, а также объясню логику принятия решений: как использовать ту или иную палитру в конкретной задаче. И что самое главное, дам пошаговые советы, как сделать график логичнее и понятнее для заказчиков.
Меня зовут Саша, сейчас я работаю в Lamoda Tech старшим бизнес/дата-аналитиком. До этого я несколько лет был специалистом по данным в другой компании и регулярно представлял совету директоров анализ и прогноз физических и бизнес-показателей. Умение донести результаты исследования до заказчика, особенно если он не погружен в работу с данными — это важный аспект моей профессии. Надеюсь, моя статья с этим немного поможет.