С момента выхода оригинальной статьи про трансформер прошло уже больше 7 лет, и эта архитектура перевернула весь DL: начав с NLP архитектура теперь применяется везде, включая генерацию картинок. Но та ли это архитектура или уже нет? В этой статье я хотел сделать краткий обзор основных изменений, которые используются в текущих версиях моделей Mistral, Llama и им подобным.
GPT-like модель «впервые сделала научное открытие»: что, как, и куда дальше?
Средний
21 мин
Обзор

14го декабря в одном из самых авторитетных общенаучных журналов Nature была опубликована статья с, кажется, сенсационным заголовком: «ИИ-модели Google DeepMind превосходят математиков в решении нерешённых проблем». А в блогпосте дочки гугла и вовсе не постеснялся указать, что это — первые находки Больших Языковых Моделей (LLM) в открытых математических проблемах. Неужели правда? Или кликбейт — и это в Nature? А может мы и вправду достигли техносингулярности, где машины двигают прогресс? Что ж, давайте во всём разбираться!
Предсказать ошибку. Как методы оценки неопределенности помогают повышать качество seq2seq-моделей
Сложный
8 мин
Кейс

Всем привет! Меня зовут Артём Важенцев, я аспирант в Сколтехе и младший научный сотрудник AIRI. Наша группа занимается исследованием и разработкой новых методов оценивания неопределенности для языковых моделей. Этим летом мы опубликовали две статьи на ACL 2023.
Про одну из них я уже рассказывал в одном из предыдущих текстов — там мы описали новый гибридный метод оценивания неопределенности для задачи выборочной классификации текстов. Другая же статья про то, как мы адаптировали современные методы оценивания неопределенности на основе скрытого представления модели для задачи генерации текста, а так же показали их высокое качество и скорость работы для задачи обнаружения примеров вне обучающего распределения. Ниже я хотел бы подробнее рассказать об используемых методах и результатах, которые мы получили.
В рамках реструктуризации платформа Grammarly увольняет 230 сотрудников
1 мин

Платформа для помощи в общении на английском языке на базе искусственного интеллекта Grammarly объявила о сокращении 230 сотрудников в рамках реструктуризации. В компании объяснили, что увольнения станут частью инициативы по увеличению внимания «к созданию рабочих мест с поддержкой ИИ».
Обучение трансформеров, зоопарк ML-моделей, RAG-подходы, железо для LLM и другие темы на Conversations 2023
2 мин

8 декабря в Москве и в онлайн-формате состоится Conversations – ежегодная конференция по разговорному, а теперь и генеративному AI для разработчиков и бизнеса.
Вызовы и достижения разработки LLM, диалоговые платформы и новые фреймворки, инфраструктура для запуска LLM, нейросетевая обработка и модели распознавания речи, обучение трансформеров, RAG-подходы и многое другое в лайнапе Conversations в этом году.
Вас ждет экспертиза от команд GigaChat и YaGPT, ВКонтакте, Selectel, MTS AI, Лаборатория Касперского, Тинькофф, Zerocracy, Yandex Cloud, Boto, 3itech и других. Для подогрева интереса делимся некоторыми подробностями докладов, а еще промокодом на скидку!
OpenAI открыла код системы распознавания речи Whisper
2 мин

OpenAI опубликовала исходный код системы распознавания речи Whisper. Открыты код эталонной реализации на базе фреймворка PyTorch и набор уже обученных моделей для использования под лицензией MIT.
Bloomberg выпустило чат-бота для финансового рынка BloombergGPT
2 мин

Агентство Bloomberg представило чат-бота BloombergGPT. Это большая языковая модель с 50 млрд параметров, созданная для финансового рынка. Модель обучена работе с широким спектром данных и поддерживает выполнение разнообразных задач обработки естественного языка в финансовой отрасли.
Исследование: мозг понимает язык с помощью «автокоррекции»
2 мин

Исследователи Массачусетского технологического института применили модели искусственного интеллекта для изучения того, как и почему наш мозг понимает язык. Выяснилось, что человеческий мозг может работать примерно так же, как и функция автокоррекции на смартфоне.
Украинский стартап Grammarly оценили в $13 млрд
1 мин
Основанная выходцами из Украины IT-компания Grammarly, которая разработала онлайн-сервис улучшения бизнес-текстов на английском языке, привлекла еще $200 млн. Таким образом. ее общая оценка достигла $13 млрд.
One Day Offer для Data Scientists: приглашаем экспертов в команду SberDevices
3 мин

Мы продолжаем встречи с соискателями в формате “One Day Offer”, в результате которых можно получить предложение работы за один день. В этот раз приглашаем датасайентистов уровня Middle+/Senior.
Всё будет происходить онлайн, 4 декабря (это выходной) с 11:00 до 20:00. Для участия нужно зарегистрироваться, отправив заявку по адресу: 1dayoffer@sberdevices.ru.
Несколько слов о SberDevices. Наша команда создаёт современные модели обработки естественного языка (Natural Language Processing), речевые технологии, алгоритмы компьютерного зрения, разрабатывает системы биометрии, модели для генерации медиаконтента и даже нейроинтерфейсы. Мы используем последние разработки в области искусственного интеллекта и машинного обучения и очень любим работать с большими генеративными моделями. Впереди у нас ещё много интересных задач!
Итак, какие же команды нанимают в этот раз:
SmartNLP Team— выстраивает core-систему обработки естественного языка. Все запросы к виртуальным ассистентам Салют проходят через неё. Наш сервис реализует весь стек технологий NLP: от предобработки текста и выделения сущностей до определения намерения пользователя и вызова соответствующего навыка. В этом нам помогают собственные разработки в области Representation Learning, Metric Learning и Natural Language Understanding. О некоторых наших подходах можно почитать здесь, здесь и здесь.
DeepMind утверждает, что ее языковая модель на 280 млрд параметров превосходит аналоги в 25 раз крупнее
3 мин
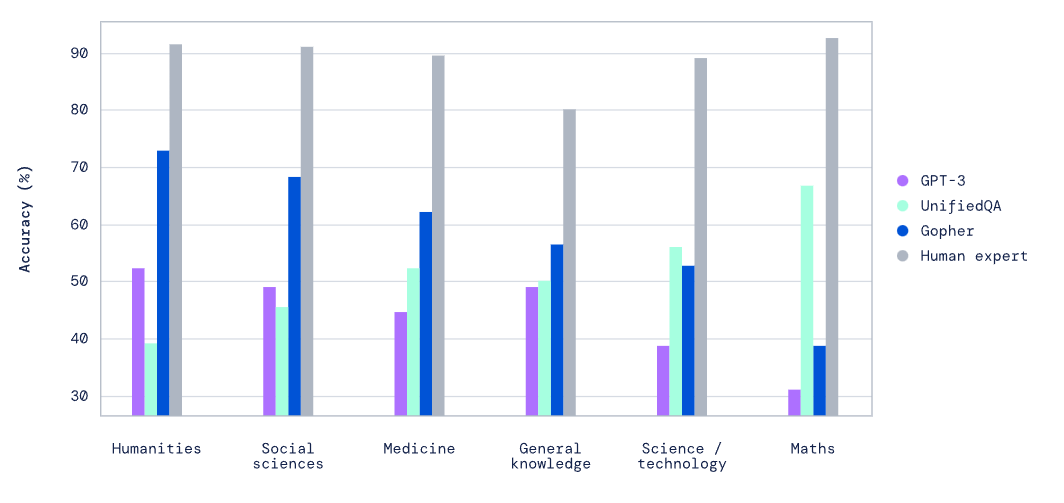
AI-лаборатория DeepMind опубликовала три исследовательские работы, посвященные возможностям больших языковых моделей. Компания пришла к выводу, что дальнейшее масштабирование этих систем должно привести к множеству улучшений.
Исследователи выяснили, что системы ИИ не различают предложения с перемешанными словами
2 мин

Исследователи из Обернского университета пришли к выводу, что многие ИИ, предназначенные для обработки естественного языка (Natural Language Processing, NLP), не замечают, когда слова в предложении перемешиваются, а его значение меняется. Это показывает, что ИИ на самом деле не понимают язык, и создает проблемы в обучении систем NLP.
OpenAI заставила GPT-3 вести себя лучше и выполнять инструкции
2 мин

OpenAI заявила, что обучила свою языковую модель GPT-3 следовать инструкциям, благодаря чему она выдает меньше нежелательного текста.
OpenAI выпустила нейросеть, которая кратко пересказывает книги
2 мин

В OpenAI представили нейросеть на основе GPT-3, которая способна генерировать краткие изложения книг. Разработчики отмечают, что подобные модели нужны для контролируемого масштабирования систем искусственного интеллекта. Работа данной нейросети покажет, насколько она справляется с работой, которую. обычно выполняют люди.
Семинар Natural Language Processing — открытие сезона 2010/11
2 мин

В субботу 25-ого сентября 2010 в 17.00 мы открываем новый сезон семинара по автоматической обработке естественного языка. На первом заcедании этого учебного года выступит Эдуард Клышинский (Институт прикладной математики им. М.В. Келдыша РАН. Москва) с рассказом о принципах построения программного модуля морфологического анализа и синтеза для русского языка. Доклад называется «Давайте напишем морфологию».
Семинар будет транслироваться в он-лайне, позже мы выложим презентацию и видеозапись на сайт семинара.
Компьютер IBM сыграет против двух чемпионов Jeopardy!
2 мин
Система обработки натуральной речи и ответов на вопросы IBM DeepQA/Watson сыграет против двух чемпионов интеллектуальной телевикторины Jeopardy! (в России викторина производится по лицензии под названием «Своя игра»). Трансляция битвы умов состоится 14, 15 и 16 февраля 2011 года на канале CBS. Будет сыграно две игры.
Викторина пройдёт по стандартным правилам. Три участника соревнуются между собой в борьбе за право первым ответить на заданный вопрос. Вопросы сформулированы, как правило, в виде утверждений, где искомое слово заменено местоимением. Игроки должны догадаться, о чём идёт речь, и дать ответ.
Викторина пройдёт по стандартным правилам. Три участника соревнуются между собой в борьбе за право первым ответить на заданный вопрос. Вопросы сформулированы, как правило, в виде утверждений, где искомое слово заменено местоимением. Игроки должны догадаться, о чём идёт речь, и дать ответ.
Извлечение объектов и фактов из текстов в Яндексе. Лекция для Малого ШАДа
6 мин
В докладе рассказывается о том, как мы извлекаем сущности (например, имена людей и географические названия) из текстов и запросов. А также об извлечении фактов, т.е. связей между объектами. Мы рассмотрим несколько подходов к решению этих задач: формулирование правил, составление словарей всевозможных объектов, машинное обучение.
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
http://video.yandex.ru/users/e1coyot/view/4/
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
http://video.yandex.ru/users/e1coyot/view/4/
Что такое Томита-парсер, как Яндекс с его помощью понимает естественный язык, и как вы с его помощью сможете извлекать факты из текстов
6 мин
Мечта о том, чтобы машина понимала человеческий язык, завладела умами еще когда компьютеры были большими, а их производительность – маленькой. Главная проблема на пути к этому заключается в том, что грамматика и семантика естественных языков слабо поддаются формализации. Кроме того, от языков программирования их отличает присутствие многозначности.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
InterSystems iKnow. Загружаем данные из Вконтакте
14 мин
Туториал
Эта статья продолжает цикл рассказов (раз, два) об основных способах/сценариях использования iKnow — инструмента Natural Language Processing'а из стека технологий InterSystems.
Предыдущие посты на эту тему были в основном посвящены работе с данными уже после того, как те были помещены в домен (место, в котором и проходит весь анализ текста). Эта же статья будет о том, как правильно и удобно загрузить информацию в iKnow. В качестве примера рассмотрим загрузку информации о пользователях Вконтакте: их личных данных, постах и т.д.
Статья подразумевает некий базовый бэкграунд в области технологий InterSystems (в частности, Caché ObjectScript).
Предыдущие посты на эту тему были в основном посвящены работе с данными уже после того, как те были помещены в домен (место, в котором и проходит весь анализ текста). Эта же статья будет о том, как правильно и удобно загрузить информацию в iKnow. В качестве примера рассмотрим загрузку информации о пользователях Вконтакте: их личных данных, постах и т.д.
Статья подразумевает некий базовый бэкграунд в области технологий InterSystems (в частности, Caché ObjectScript).
FactRuEval — соревнование по выделению именованных сущностей и извлечению фактов
6 мин
 Соревнования по различным аспектам анализа текста проводятся на международной конференции по компьютерной лингвистике «Диалог» каждый год. Обычно сами соревнования проходят в течение нескольких месяцев до мероприятия, а на самой конференции объявляют результаты. В этом году планируются три соревнования:
Соревнования по различным аспектам анализа текста проводятся на международной конференции по компьютерной лингвистике «Диалог» каждый год. Обычно сами соревнования проходят в течение нескольких месяцев до мероприятия, а на самой конференции объявляют результаты. В этом году планируются три соревнования:- по выделению именованных сущностей и фактов – FactRuEval;
- по анализу тональности – SentiRuEval;
- по исправлению опечаток – SpellRuEval.
Статья, которую вы начали читать, преследует три цели. Первая – мы хотели бы пригласить разработчиков систем автоматического анализа текстов принять участие в соревнованиях. Вторая – мы ищем помощников, которые могли бы разметить текстовые коллекции, на которых будут проверяться системы наших участников (это, во-первых, интересно, а во-вторых – вы сможете принести реальную пользу науке). Ну а третья – соревнования по выделению именованных сущностей и фактов проводятся на “Диалоге” впервые, и мы хотим рассказать всем заинтересованным читателям, как они будут происходить.