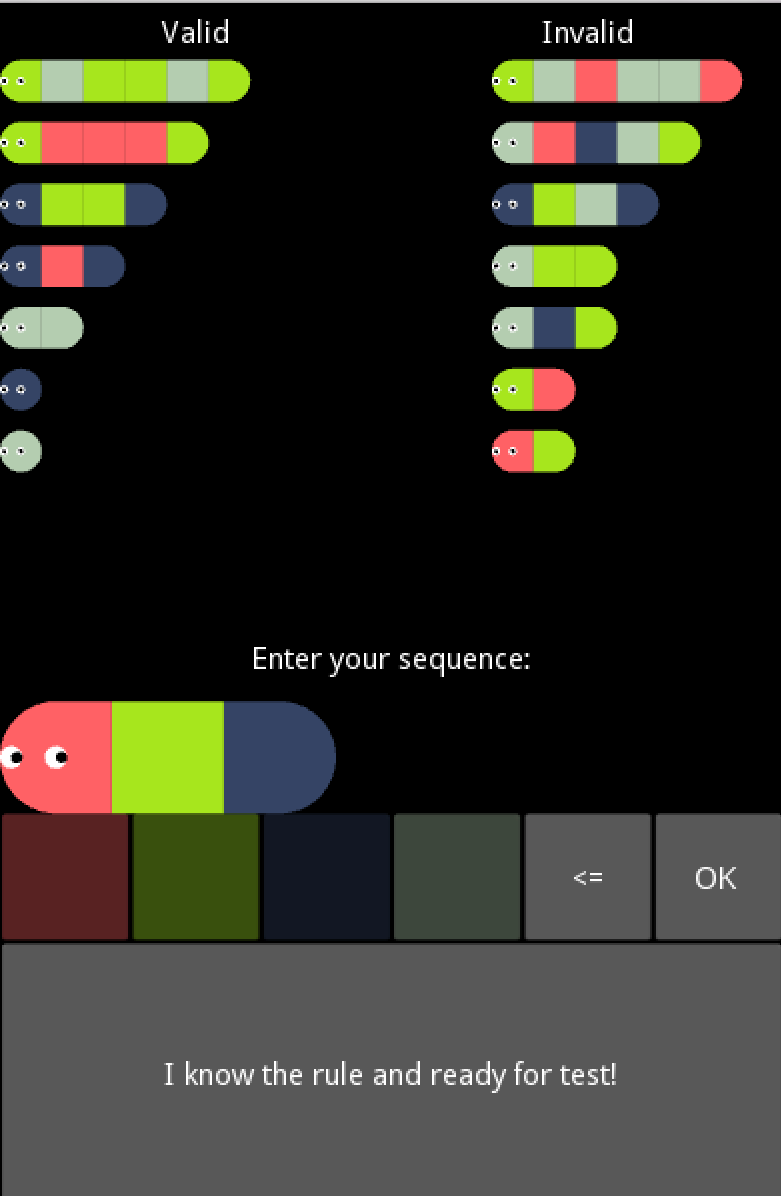
Когда-то я хотел сделать контест по парсингу для Codeforces. Придумал задания двух типов:
1. Дается неформальное описание языка, по которому нужно создать грамматику (например, "язык с правильными скобочными последовательностями")
2. Даны примеры строк в языке, по которым нужно восстановить грамматику
У обоих типов заданий есть свои проблемы, так что контест я не сделал.
В итоге я сделал игру программу, в которой можно решать задания второго типа, при этом проверять строки на принадлежность угадываемому языку.