
Бывший генеральный директор Google Эрик Шмидт опубликовал статью на сайте МТИ, в которой он обрисовал будущее науки вследствие достижений в области искусственного интеллекта.
Бывший генеральный директор Google Эрик Шмидт опубликовал статью на сайте МТИ, в которой он обрисовал будущее науки вследствие достижений в области искусственного интеллекта.

Блогер Энди Байо рассказал, что он нашёл в macOS скрытый PDF-документ от создателя биткоина Сатоши Накамото. Он называется «Bitcoin: Децентрализованная электронная денежная система».

Чтобы предложить материал СМИ, гайды в интернете рекомендуют создать медиакарту, подготовить гостевые статьи и питчить редакторов. Эта инструкция немного отличается: объясняю, как рассказать о компании в СМИ, если никогда этого не делали раньше.
 В данном цикле статье хочу поделиться приемом, который помогает мне решать весьма и весьма сложные логические задачи. Под сложной логической задачей подразумевается задача с большим количеством исходных параметров которые влияют на итоговый результат и так же могут влиять друг на друга, где сложно организовать корректное взаимодействие этих параметров и просто можно запутаться как в них, так и в логике организации кода. Начать хочу с данных, а управление данными будет во второй части.
В данном цикле статье хочу поделиться приемом, который помогает мне решать весьма и весьма сложные логические задачи. Под сложной логической задачей подразумевается задача с большим количеством исходных параметров которые влияют на итоговый результат и так же могут влиять друг на друга, где сложно организовать корректное взаимодействие этих параметров и просто можно запутаться как в них, так и в логике организации кода. Начать хочу с данных, а управление данными будет во второй части. В первой части описал чем руководствоваться при определении Типа Данных (далее ТД). В данной части хочу рассказать что такое Абстрактный Тип Данных (далее АТД), как это помогает решать логически сложные задачи (что подразумевается под логически сложными задачами смотрите первую статью) и какие мы получаем преимущества.
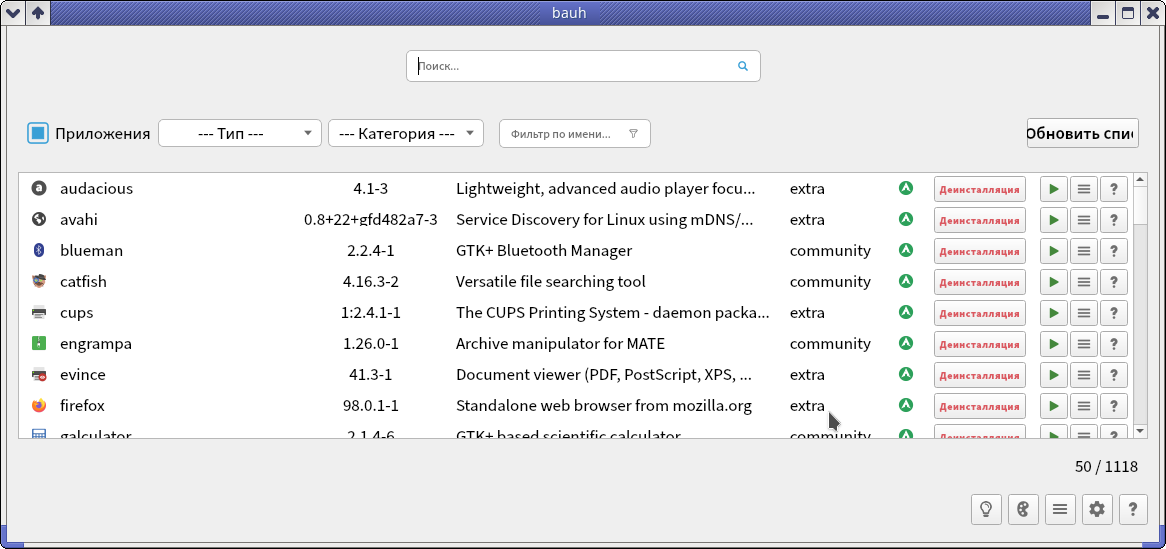
Одно из моих хобби — находить и тестировать интересные проекты с открытым кодом на Github (реже на публичной части Gitlab). Одна из моих находок — это менеджер пакетов Bauh, о котором я хочу рассказать.

Давайте разберем самые Часто Задаваемые Вопросы, или сокращенно FAQ. Они помогут вам глубже понять тонкости и принцип работы с Ansible. На ранних этапах можете использовать эту статью как некую шпаргалку.

Вышедшая чуть больше месяца назад ChatGPT уже успела нашуметь: школьникам в Нью-Йорке запрещают использовать нейросеть в качестве помощника, её же ответы теперь не принимаются на StackOverflow, а Microsoft планирует интеграцию в поисковик Bing - чем, кстати, безумно обеспокоен СЕО Alphabet (Google) Сундар Пичаи. Настолько обеспокоен, что в своём письме-обращении к сотрудникам объявляет "Code Red" ситуацию. В то же время Сэм Альтман, CEO OpenAI - компании, разработавшей эту модель - заявляет, что полагаться на ответы ChatGPT пока не стоит.
Насколько мы действительно близки к внедрению продвинутых чат-ботов в поисковые системы, как может выглядеть новый интерфейс взаимодействия, и какие основные проблемы есть на пути интеграции? Могут ли модели сёрфить интернет бок о бок с традиционными поисковиками? На эти и многие другие вопросы постараемся ответить под катом.

Не открою Америку, если скажу, что вся наша жизнь - это сплошной стресс. Точнее, череда стимулов, которая вызывает стресс. И это нормально, так как стресс является основой выживания, будучи реакцией приспособления (адекватной или нет, это другой вопрос). Это так называемый первичный стресс. И с ним всё в порядке (как с механизмом).
Но в своей практике я достаточно часто сталкиваюсь с другим явлением, более деструктивным, который можно окрестить вторичным стрессом - это переживание за факт переживания. Это несёт усиливает стресс от изначального стимула, увеличивая его деструктивную силу. Но и это еще не конец. Всё чаще начинают звучат фразы из разряда "я переживаю, что не переживаю". И вот это уже хочется разобрать подробнее.
Почему мы переживаем? Почему мы переживаем из-за переживания? И почему мы не можем жить спокойно, не переживая? Разберем в этой статье. А в конце, внезапно, поговорим про разницу поколений через призму данной темы.

 Как часто мы не обращаем внимание на то, чего совершенно не понимаем и не можем оценить по достоинству. Я хотел бы направить ваш взор на авторов статей, а так же на ту ценность, которую они привносят в сферу бизнеса. К сожалению, многие люди достаточно поверхностно знают данную сферу вследствие чего возникают комичные ситуации и «разочарование в силе слова».
Как часто мы не обращаем внимание на то, чего совершенно не понимаем и не можем оценить по достоинству. Я хотел бы направить ваш взор на авторов статей, а так же на ту ценность, которую они привносят в сферу бизнеса. К сожалению, многие люди достаточно поверхностно знают данную сферу вследствие чего возникают комичные ситуации и «разочарование в силе слова». 




