
Читать далее

Сегодня хочу рассказать о том, какие ошибки можно допустить на начальном этапе создания e-commerce проекта в проектировании модели данных и в разработке веб-приложения. И, самое главное, как эти ошибки исправить: снизить потребление памяти в 1000 раз и кратно уменьшить нагрузку на дисковую систему. Кейс основан на реальных событиях, однако без упоминания компаний в связи с политикой конфиденциальности и профессиональной этикой.
 В прошлых статьях: СХД Infortrend — альтернатива А-брендам и СХД Infortrend EonStor DS2024G2 делался акцент на одно из преимуществ систем хранения Infortrend — поддержка Enterprise SATA SSD в 2-контроллерных системах.
В прошлых статьях: СХД Infortrend — альтернатива А-брендам и СХД Infortrend EonStor DS2024G2 делался акцент на одно из преимуществ систем хранения Infortrend — поддержка Enterprise SATA SSD в 2-контроллерных системах.
Казалось бы, выбор картридера очевидным образом влияет на скорость карт памяти: модели с интерфейсом USB 3.x всегда быстрее их предков с USB 2.0, но все ли картридеры USB 3.x одинаково шустрые? Есть ли для них смысл в USB 3.2 Gen 2 (10 Гбит/с), или же это заведомый overkill и маркетинговый шум?
Мне захотелось проверить это на примере работы microSDXC Transcend 340S на 256 ГБ (TS256GUSD340S) с тремя разными картридерами. Для чистоты эксперимента выбрал ридеры той же фирмы (благо, их часто закупают). Ниже привожу результаты тестов, но для начала опишу основные условия их проведения.
Материнка: Asus Maximus VIII Hero (старая, но всё ещё добрая);
Камень: Core i7-7700K на частоте 4500 МГц (45x100x4+HT);
Оперативка: 2 планки по 8 Гб Kingston HyperX DDR4-3466 в двухканальном режиме;
Два твердотельника по полтерабайта: WD Black SN750 (под систему) + TS512GSSD452K (хранилка);
Б/п: SSR-750TR (он же Seasonic Prime TX-750).
Картридеры: Transcend HUB5C, RDF9K2 и RDF5
Операционка: 64-разрядная Win 7 с последними обновками (ESU).

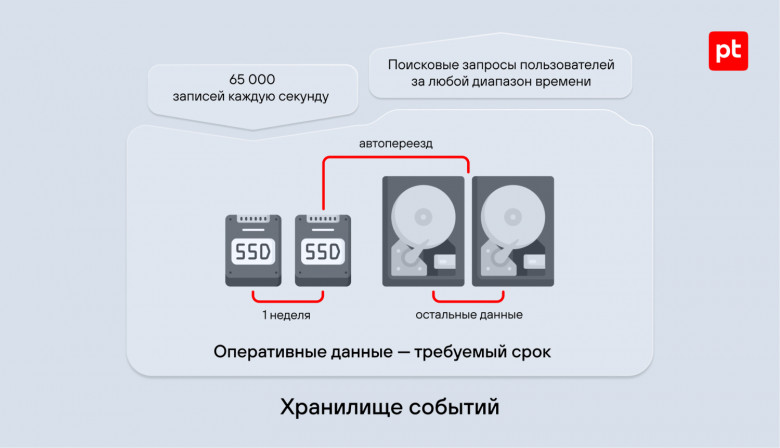
Всем привет! Я Максим Максимович, директор департамента инжиниринга Positive Technologies. В этой статье я затрону тему обработки и оптимизации хранения событий в высоконагруженных SIEM-инсталляциях, расскажу о сложностях, с которыми многие наверняка уже сталкивались при выполнении подобных задач, и на примере одного реального проекта покажу, как их можно преодолеть. Надеюсь, описанный в посте опыт будет полезен специалистам и энтузиастам, внедряющим и эксплуатирующим решения классов Log Management и SIEM.
Метрики производительности, которых требовал проект, сыграли нам на руку, так как изначально были отмечены в дорожной карте MaxPatrol SIEM. По завершении проекта мы получили не только приятный профит в виде (почти!) готового раньше намеченного срока релиза, но и возможность сразу же подтвердить новые характеристики решения в боевых условиях. Речь идет о версии 6.2, которая позволяет обрабатывать до 60 тыс. событий в секунду. Добиться такой скорости мы смогли за счет гибридной схемы хранения данных, которая помогла увеличить производительность хранилища событий и при этом сократить расходы на аппаратное обеспечение.

Привет, Хабр! Начинаем серию статей с глубоким разбором функциональности СХД АЭРОДИСК серии 5. В этой статье речь пойдет об основе СХД – отказоустойчивости и производительности. Как работает, как правильно настраивать и какой результат можно получить. Более того, все то же самое и даже больше мы покажем в реальном времени на нашем следующем вебинаре Около-ИТ, который состоится 21 февраля 2023 в 15:00. Зарегистрироваться на вебинар можно по ссылке.

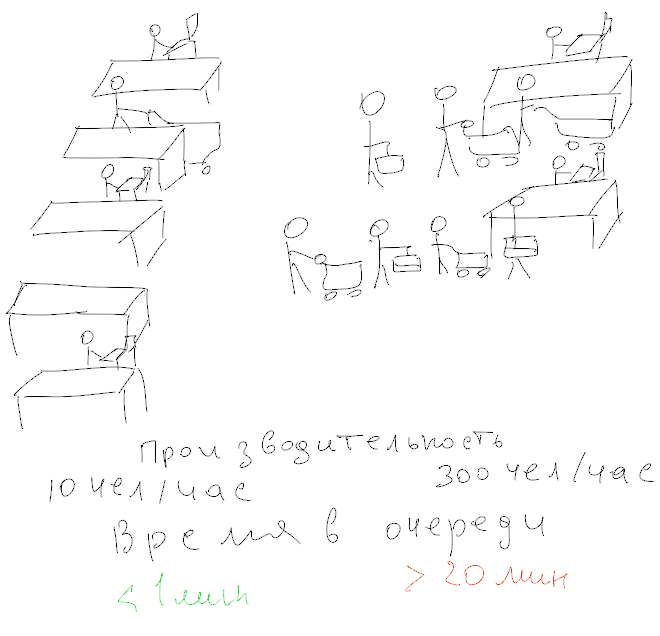
Каждый из нас сталкивался с необходимостью настройки сложного ПО, интенсивно потребляющего ресурсы компьютера. Как правило, у такого софта довольно объёмная конфигурация, и из-за этого бывает трудно подобрать комбинацию параметров, при которой этот софт демонстрировал бы высокую производительность при минимальной утилизации железа.
Одна из наиболее ресурсоемких категорий софта сегодня — это системы хранения данных. К ним можно отнести как классические СУБД, так и хранилища различного назначения. В корпоративной почтовой системе Mailion мы используем объектное хранилище собственной разработки — Dispersed Object Store (DOS). Mailion поддерживает одновременную работу до миллиона пользователей, и подобный уровень нагрузки выдвигает существенные требования к производительности и экономической эффективности системы.
Под катом рассказываем, как мы искали оптимальную конфигурацию нашего объектного хранилища, и какие уроки извлекли из этого поиска.
MemTrimRate = «0»
sched.mem.pshare.enable = «FALSE»
mainMem.useNamedFile = «FALSE»

 IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
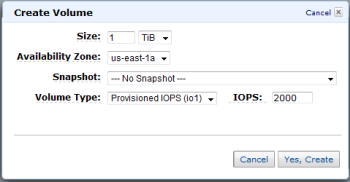
Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.
Задача подобрать такой iodepth, чтобы avg.latency была меньше 10мс.

Привет, читатели Хабра. Этой статьей мы открываем цикл, который будет рассказывать о разработанной нами гиперконвергентной системе AERODISK vAIR. Изначально мы хотели первой же статьей рассказать всё обо всём, но система довольно сложная, поэтому будем есть слона по частям.
Начнем рассказ с истории создания системы, углубимся в файловую систему ARDFS, которая является основой vAIR, а также немного порассуждаем о позиционировании этого решения на российском рынке.
В дальнейших статьях мы будем подробнее рассказывать о разных архитектурных компонентах (кластер, гипервизор, балансировщик нагрузки, система мониторинга и т.п.), процессе настройки, поднимем вопросы лицензирования, отдельно покажем краш-тесты и, конечно же, напишем о нагрузочном тестировании и сайзинге. Также отдельную статью мы посвятим community-версии vAIR.

Привет, Хабровчане! Мы продолжаем знакомить вас с российской гиперконвергентной системой AERODISK vAIR. В этой статье речь пойдет об архитектуре данной системы. В прошлой статье мы разобрали нашу файловую систему ARDFS, а в данной статье пройдёмся по всем основным программным компонентам, из которых состоит vAIR, и по их задачам.