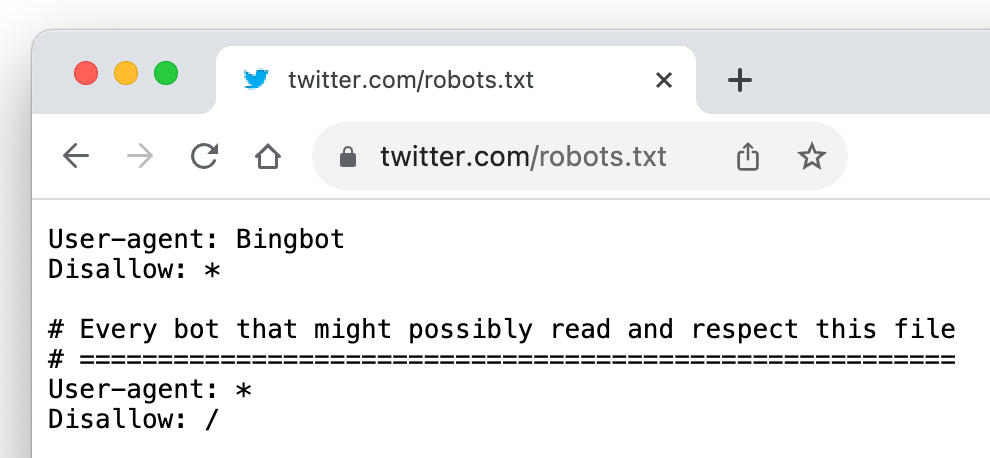
Microsoft сообщает, что имена поисковых ботов Live остаётся прежним — MSNBot.
MSNBot — Main web crawler (www.live.com)
MSNBot-Media — Images & all other media (images.live.com)
MSNBot-NewsBlogs — News and blogs (search.live.com/news)
MSNBot-Products — Products & shopping (products.live.com)
MSNBot-Academic — Academic search (academic.live.com)
Host name для них всегда оканчивается на search.live.com (например, livebot-207-46-98-149.search.live.com).
MSNBot — Main web crawler (www.live.com)
MSNBot-Media — Images & all other media (images.live.com)
MSNBot-NewsBlogs — News and blogs (search.live.com/news)
MSNBot-Products — Products & shopping (products.live.com)
MSNBot-Academic — Academic search (academic.live.com)
Host name для них всегда оканчивается на search.live.com (например, livebot-207-46-98-149.search.live.com).