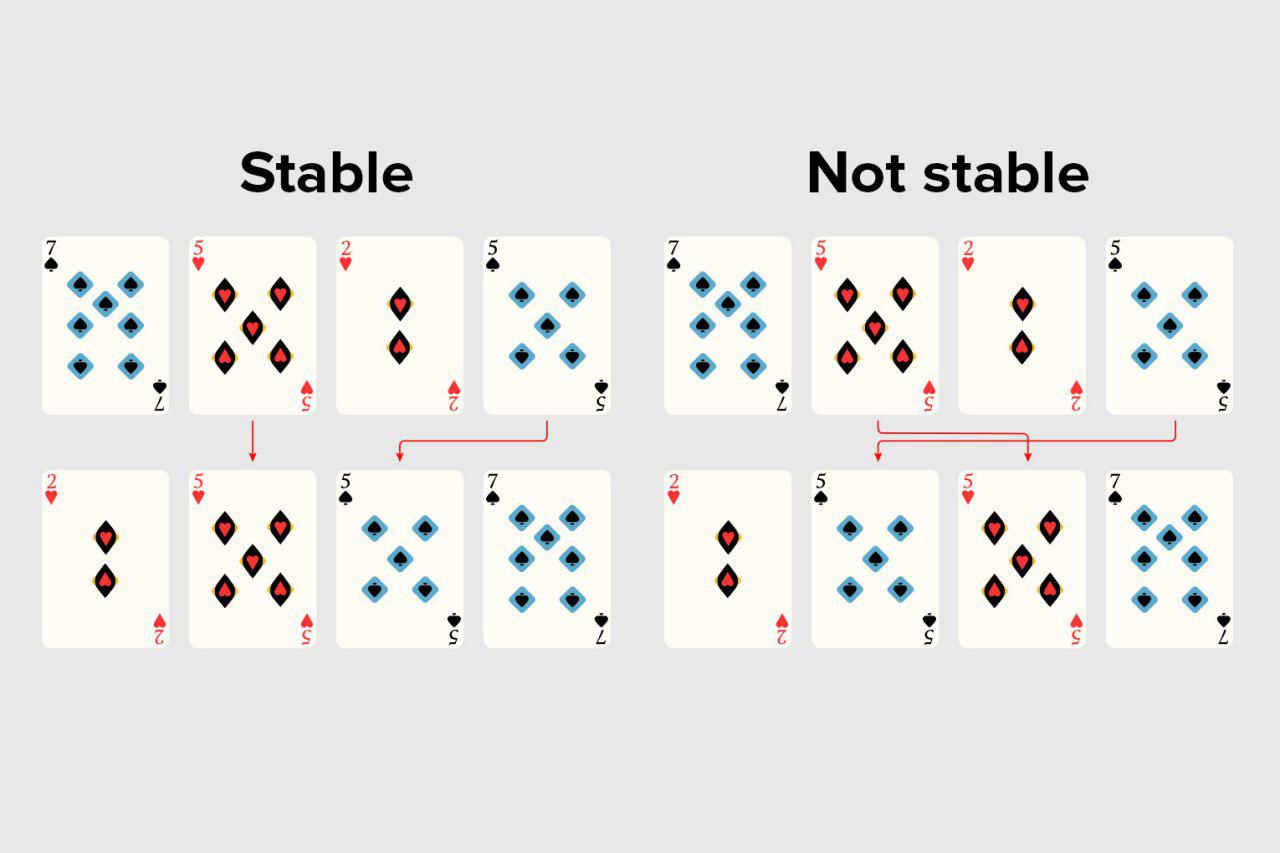
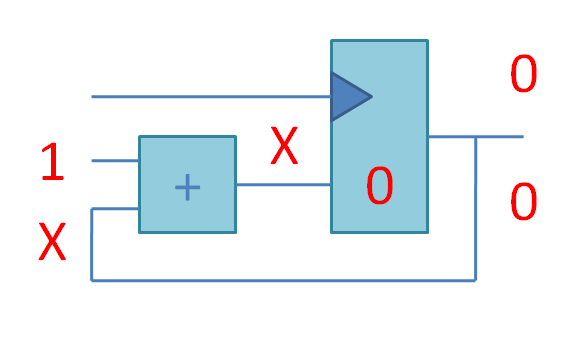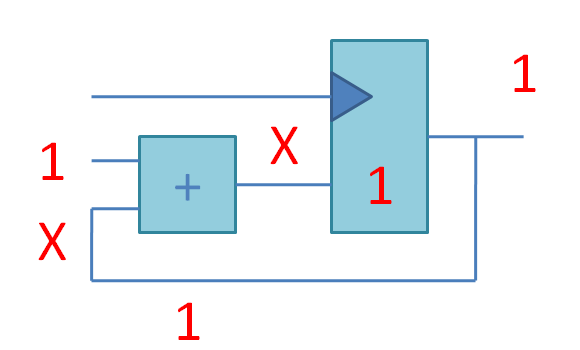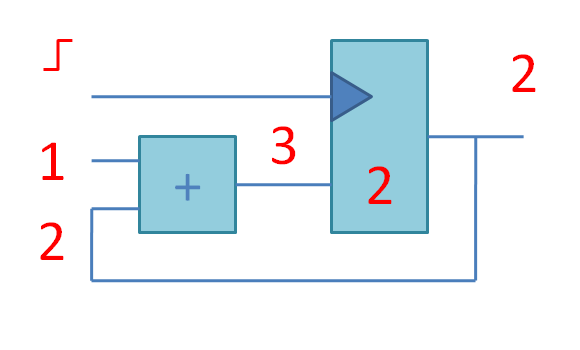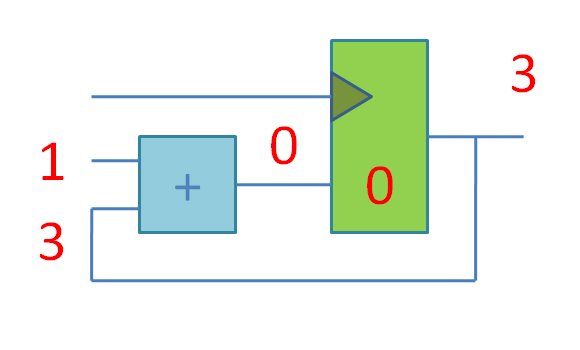
К сожалению, на данный момент нет хороших библиотек на Python2, для того, чтобы быстро создать чат-бота. Ниже я покажу, как легко можно написать примитивного чат бота для VK, используя API VK.
Статья написана для новичков, чтобы показать, что ничего сложного в написании ботов на Python нет.