Вступление
Эта статья описывает стабильный нерекурсивный адаптивный алгоритм сортировки слиянием под названием quadsort.
Четверной обмен
В основе quadsort лежит четверной обмен. Традиционно большинство алгоритмов сортировки разработаны на основе бинарного обмена, где две переменные сортируются с помощью третьей временной переменной. Обычно это выглядит следующим образом:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}В четверном обмене происходит сортировка с помощью четырёх подменных переменных (своп). На первом этапе четыре переменные частично сортируются в четыре своп-переменные, на втором этапе они полностью сортируются обратно в четыре исходные переменные.
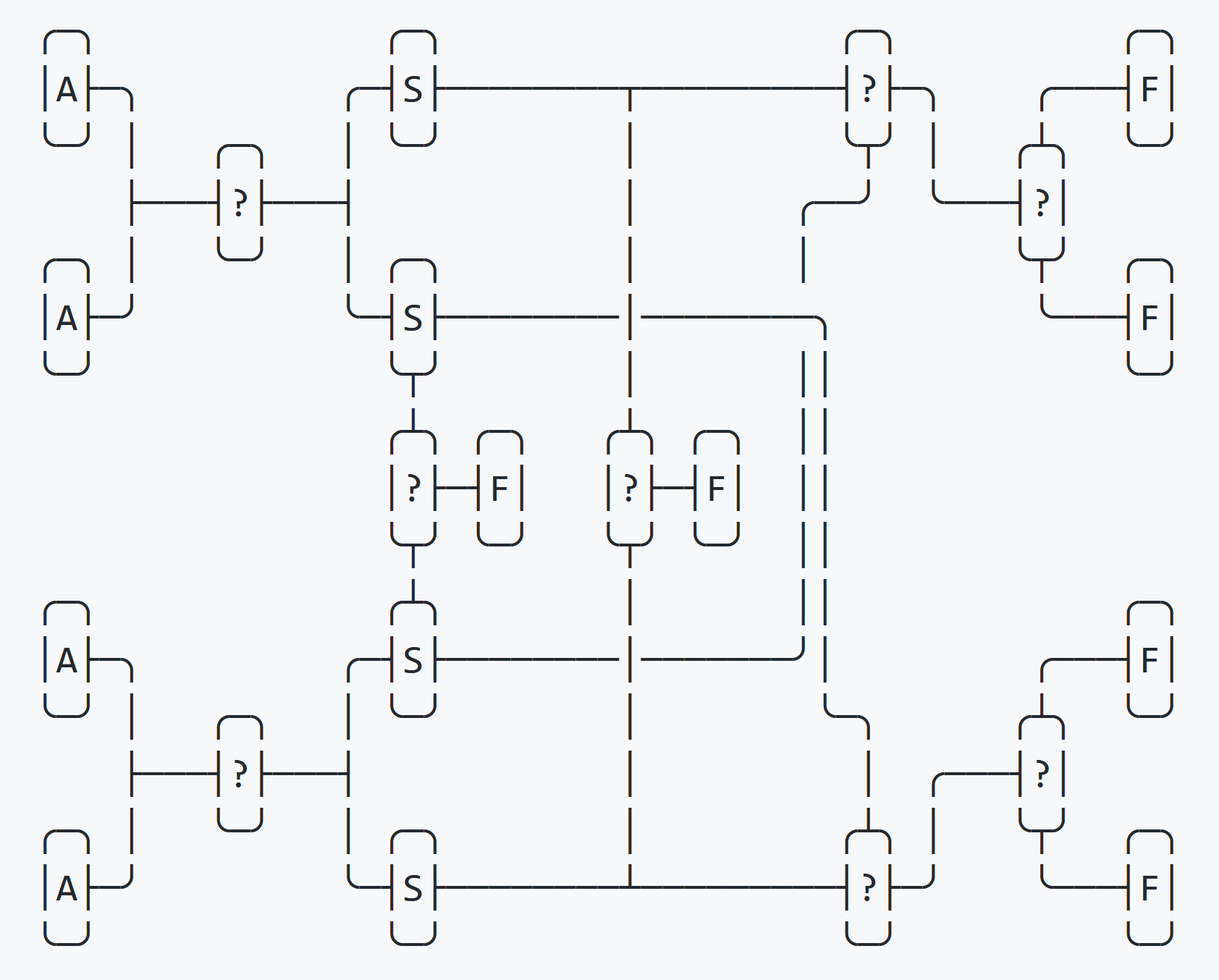
Этот процесс показан на диаграмме выше.