Пример использования процессора JoltTransformJson в Apache NiFi. Можно рассматривать как небольшой туториал по использованию Jolt-спецификаций.
Пример использования процессора JoltTransformJson в Apache NiFi. Можно рассматривать как небольшой туториал по использованию Jolt-спецификаций.

Встречался с различными парсерами JSON. Когда то было сложно сразу преобразовать дату в тот объект который хочется, иногда Enum жил своей жизнью. И вот не давно повстречал один Фреймворк для NodeJS. Речь пойдет про Ts.ED.

В предыдущей статье я рассказал о подготовке данных для тестирования, что данные лучше генерировать, а не клонировать. Теперь стоит подробно разобрать, как их генерировать. Есть несколько подходов к генерации данных: c SQL, Python, сериализацией. У всех из них есть свои плюсы, минусы и особенности, которые стоит учитывать.

Привет! На связи Артемий – Analytics Engineer @ Wheely.
В последние годы явным стал тренд на анализ слабоструктурированных данных – всевозможных событий, логов, API-выгрузок, реплик schemaless баз данных. Но для привычной реляционной модели это требует адаптации ряда новых подходов к работе с данными, о которых я и попробую рассказать сегодня.
В публикации:
- Преимущества гибкой схемы и semi-structured data
- Источники таких данных: Events, Logs, API
- Подходы к обработке: Special Data Types, Functions, Data Lakehouse
- Принципы оптимизации производительности

Как я спарсил WebGL карту с Федерального сайта. Написал эту статью для тех, у кого похожая задача.

Привет, Хабр! У нас продолжается распродажа в честь черной пятницы. Там вы найдете много занимательных книг.
Возможен вопрос: а что такое метакласс? Если коротко, метакласс относится к классу точно как класс к объекту.
Метаклассы – не самый популярный аспект языка Python; не сказать, что о них воспоминают в каждой беседе. Тем не менее, они используется в весьма многих статусных проектах: в частности, Django ORM[2], стандартная библиотека абстрактных базовых классов (ABC)[3] и реализации Protocol Buffers [4].
Это сложная фича, позволяющая программисту приспособить под задачу некоторые самые базовые механизмы языка. Именно по причине такой гибкости открываются и возможности для злоупотреблений – но нас это уже не удивляет. С большими возможностями приходит большая ответственность.

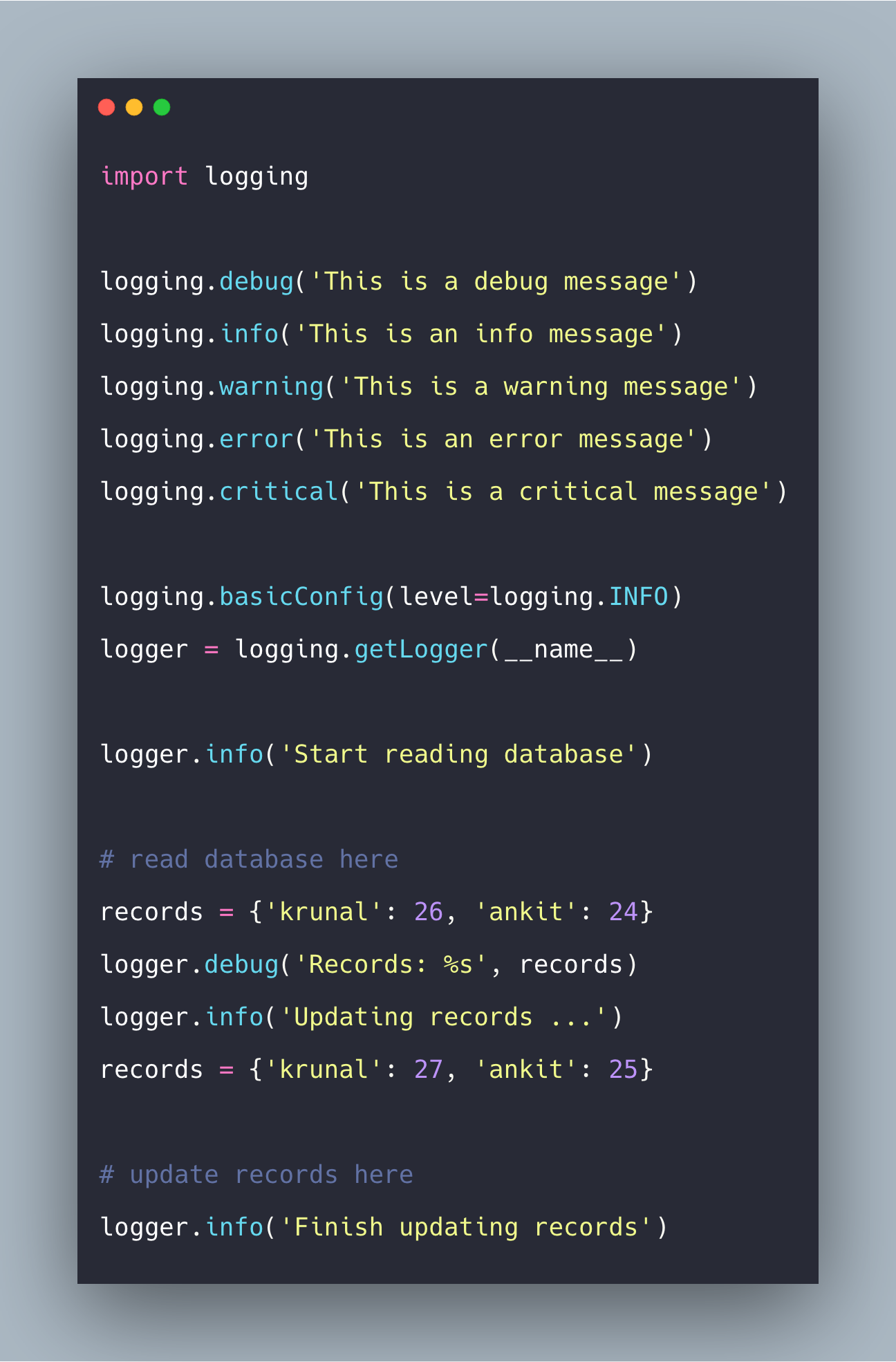
Иногда мы пишем SQL-запросы, мало задумываясь над тем фактом, что сначала они должны быть по сети как-то доставлены до сервера, а затем их результат - обратно в клиентское приложение. Если при этом на пути до сервера присутствует еще и пулер соединений типа pgbouncer, дополнительно "перекладывающий" байты между входящими и исходящими коннектами, ситуация становится еще тяжелее...
Поэтому сегодня рассмотрим некоторые типичные ситуации, в которых разработчики иногда принимают не самые оптимальные решения, гоняя по сети мегабайты трафика при общении с сервером PostgreSQL - а заодно посмотрим, как можно увидеть такую ситуацию в плане с помощью explain.tensor.ru и подумаем над вариантами, как сделать подобное взаимодействие более эффективным.

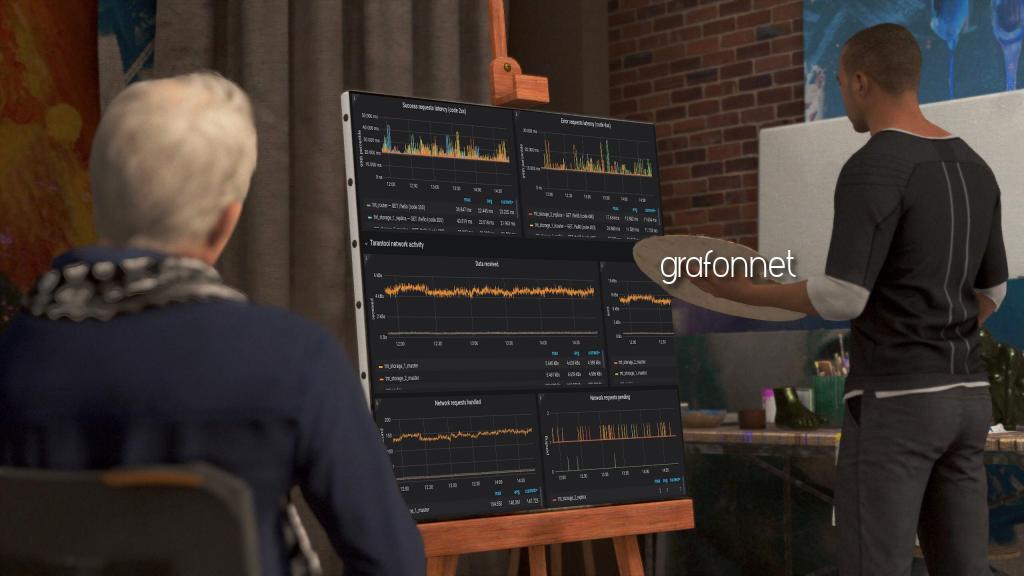
Когда мы в Tarantool столкнулись с задачей настройки мониторинга для сдачи проекта заказчику, мы решили её с помощью grafonnet. Это библиотека для написания дашбордов Grafana с помощью кода на языке jsonnet, которая заметно облегчила нам жизнь.
Рассказ поделён на две части. В первой я делюсь нашей историей знакомства с grafonnet, причинами, по которым мы выбрали этот инструмент, и задачами, которые мы решили с его помощью. Вторая представляет собой пошаговое обучение написанию простого дашборда для Prometheus. Так что если ситуации, описанные мной в первой половине статьи, покажутся вам знакомыми, вторая позволит вам совершить первый шаг на пути к их разрешению.

Есть интерфейс и есть несколько типов удовлетворяющих этому интерфейсу. Хочется сделать так, что бы можно было сохранить в JSON список таких интерфейсов а потом восстановить из JSON-а этот список.
Сразу введу в курс дела, это был легаси проект и задача была доработка одного эндпоинта, который должен возвращать огромную Json-нину. По итогу работы среднее количество строк в респонсе было 800.000-2.000.000 строк и весил он в районе 30 мб.
На этом проекте я выяснил что Postman уже ломается от 1.000.000 строк, перестаёт работать форматирование и начинает хромать поиск. А в целом весь json напоминал мне один огромный клубок снега который пустили горы и он всё разрастался и разрастался, т.к. когда я пришёл на проект он был всего лишь 40.000-80.000 строк.
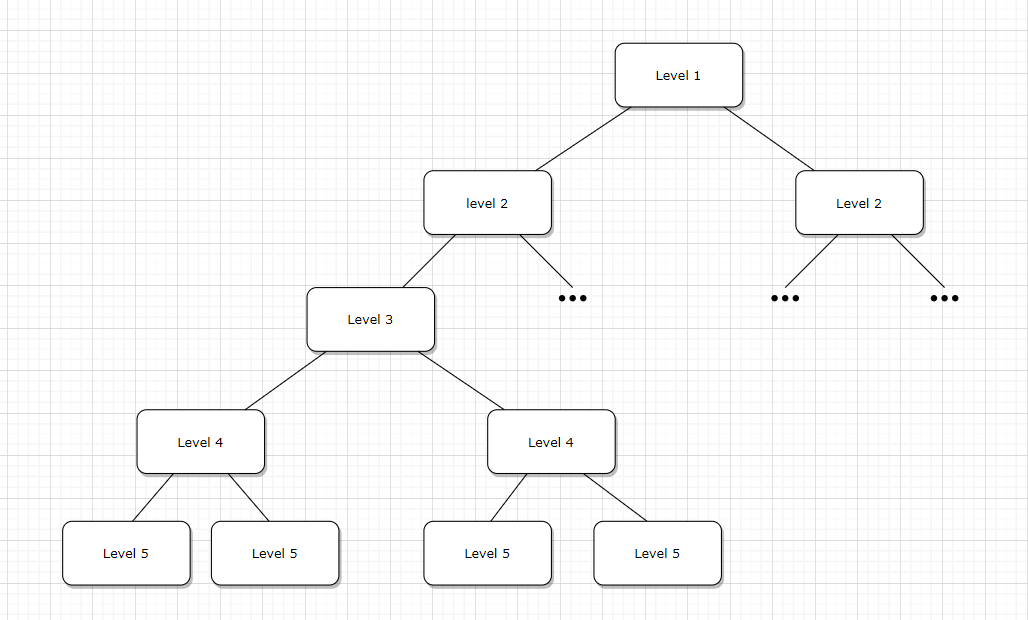
Json состоял из нескольких уровней и каждый уровень имел некоторое количество подуровней, похоже на эту картинку, только уровней было в районе 8 и каждый из уровней мог иметь до 80 подуровней.

Dhall — программируемый язык для создания конфигурационных файлов различного назначения. Это Open Source-проект, первый публичный релиз которого состоялся в 2018 году.
Как и всякий новый язык для генерации конфигурационных файлов, Dhall призван решить проблему ограниченной функциональности YAML, JSON, TOML, XML и других форматов конфигурации, но при этом оставаться достаточно простым. Язык распространяется всё шире. В 2020-м году представили его bindings, сделанные специально для Kubernetes.
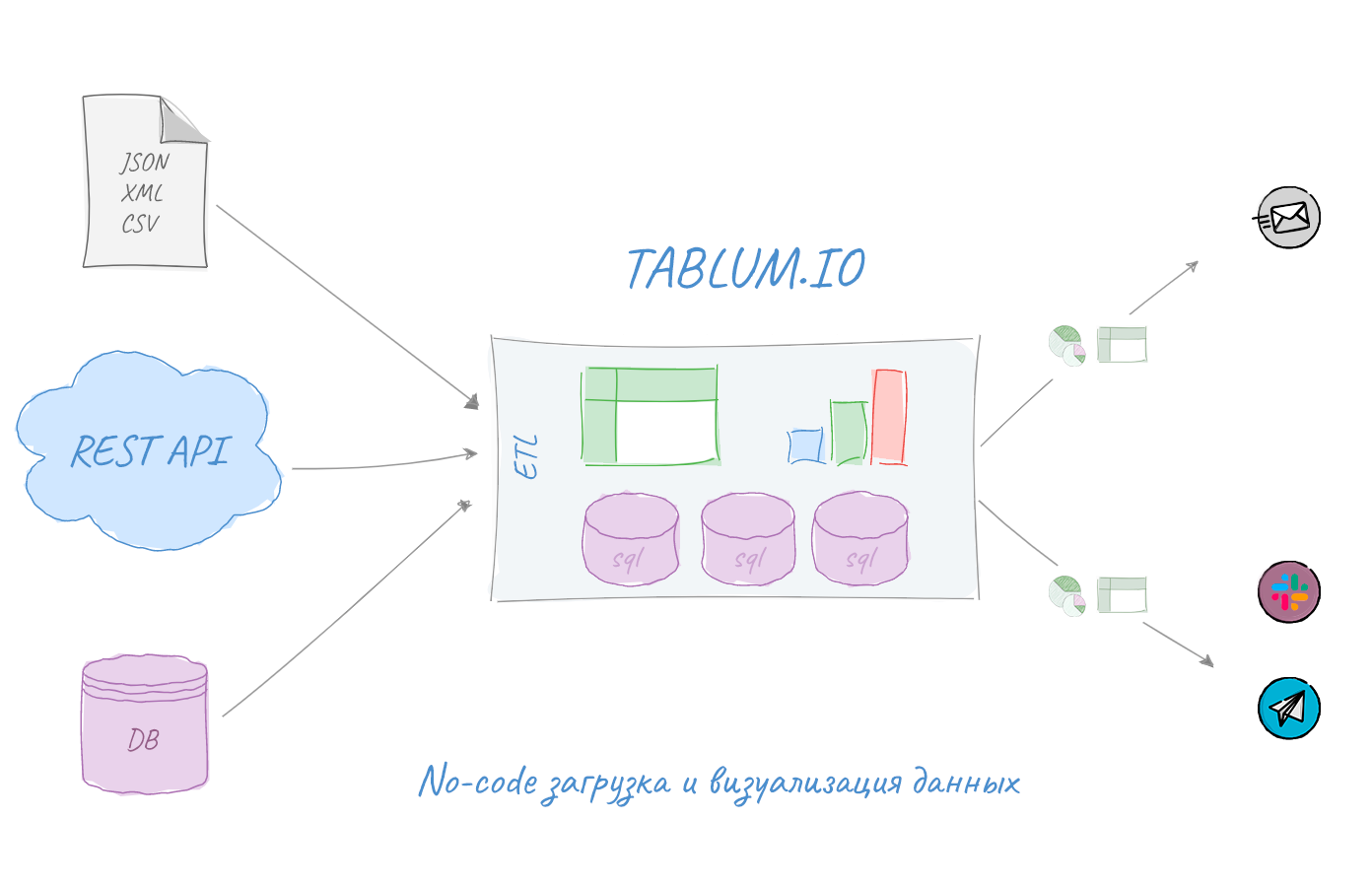
Признаюсь честно, у меня как у программиста, хоть и не настоящего, есть недоверие к «no-code» решениям. То есть тем, которые не требуют программирования, где всё можно делать через drag-and-drop и клики мышкой. Но после полугода разработки собственного «no-code» ETL сервиса с визуализацией данных я изменил отношение к этому классу продуктов, начал ими пользоваться и даже получать пользу, экономя время на рутинных операциях по анализу данных из логов, баз данных и файлов.
В этой заметке я предложу несколько вариантов загрузки и парсинга данных из сервисов и по URL с «материализацией» в SQL базу, покажу как за пару минут собрать свой информер с отправкой в Telegram, Slack или на email. И всё это произойдет без единой строчки кода (потому что в сервисе TABLUM.IO этот код уже кто-то написал ;-). «Алхимия данных» начинается под катом.

О роли формата JSON в эволюции реляционных баз данных я недавно рассказал на двух конференциях — HighLoad++ и Saint HighLoad++ 2021. А также о том, что мешает эффективно использовать JSONB (бинарный JSON) и как с этим можно бороться.
Сегодня посмотрим на особенности работы с TOAST — отдельным хранилищем для длинных записей. Начну с проклятия TOAST для JSON, а в следующей части расскажу, как это можно использовать в PostgreSQL, и за счет чего получится повысить производительность JSONB.

Пару дней назад мне написал знакомый студент-физик с просьбой помочь открыть данные, снятые с лабораторного оборудования в Excel и скинул мне несколько файлов странного формата .mmd. Интернет на запрос "как открыть mmd", выдавал только танцующих аниме-девочек (MikuMikuDance) и сайт разработчика mangodata, с которого нельзя было скачать нужное ПО. Конечно, с подобной проблемой столкнется далеко не каждый, но прецедент в моем лице появился, а это значит, что интернету нужна статья "Открываем MMD формат в Excel".

В этой статье я покажу, как можно без программирования парсить, анализировать и визуализировать данные из RSS- и Atom-лент на примере загрузки и парсинга фида Apple iTunes, а также проведения последующего конкурентного анализа приложений.
Представим, что мы собираемся публиковать в App Store мобильное приложение по тематике “медитация”. И хотим посмотреть, как обстоят дела в этой нише. При этом сделаем вид, что не знаем о существовании таких сервисов, как App Annie, Sensor Tower и аналогичных. Или знаем, но нам расхотелось делать в них детальный анализ, как только мы узнали стоимость месячной подписки. Поэтому будем действовать как экономные бутстрапперы и анализировать “сырые” данные от компании Apple. Тем более, что сделать это оказалось очень просто.

На одной конференции мне задали вопрос (спасибо Александру!): как сделать стрим в PostgreSQL? Представьте, что имеется bytea и вы к нему хотите что-то дописать. Люди столкнулись с тем, что на это в PostgreSQL тратится гигантское время и растет WAL-трафик.
Расскажу, что с этим возможно сделать — это будет еще один пример оптимизации TOAST (о чем я недавно писал), на на этот раз — для быстрой записи потока бинарных данных. На самом деле мой коллега, Никита Глухов, за несколько часов сделал расширение, которое «вылечило» проблему, и мы даже успели рассказать про это на сессии блиц-докладов на PGConf.Online 2021.

В PostgreSQL есть два типа данных: JSON и JSONB. Первый формат является текстовым хранилищем, в котором json хранится "as is", второй — бинарным, в нем ключи отсортированы (сначала по длине ключа, а потом по его названию), дубликаты удалены, а пробелы удалены.
Тип JSONB имеет богатую поддержку, облегчающую работу разработчиков приложений, для него есть встроенные индексы, кроме того, существует расширение Jsquery, в котором реализован язык запросов к JSONB и дополнительные индексы. Когда у меня спрашивают, чем пользоваться, я всегда советую JSONB, так как он позволяет работать очень эффективно.
Однако у постгреса есть серьёзная проблема, которая сказывается и на производительности JSONB — это TOAST, и о ней я говорил в первой части. Сегодня я расскажу о том, как мы улучшили JSONB для того, чтобы существенно повысить его производительность.

В последние годы практически все крупные IT-компании заняты созданием экосистем и омниканальных платформ. Есть очень много статей и докладов об их очевидных преимуществах для клиентов и бизнеса, но как это всё устроено изнутри? Как разрабатывать подобные продуктовые решения быстро, гибко и не изобретая велосипеды на каждом шагу? Об этом информации как раз маловато. Вот мы и решили, что белые пятна лучше заполнять историями о собственном опыте, и попробуем сами рассказать, как в ВТБ создавали платформу цифровых продаж.