SPARQL (рекурсивный акроним, SPARQL Protocol and RDF Query Language) — разработанный стандарт семантической паутины, прошедший стандартизацию RDF Data Access Working Group (DAWG) консорциума World Wide Web (W3C).©Wikipedia
Задача состоит в том, чтобы создать SPARQL точку доступа
В английских источниках предлагаются вариации названия от entry point до end point. Насколько я понимаю, это все про точку доступа.
сначала описание приложения:
База знаний — OWL, построена в
Protege, поэтому соответствует логике
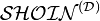
Модуль логического вывода — пока не прикручен
язык программирования — java
SPARQL точка доступа по сути представляет собой комбинацию языка запросов SPARQL и протокола SPARQL. Все это также можно назвать веб-сервисом(веб-службой).
SPARQL протокол это
здесь на русском ожидается здесь
про SPARQL язык запросов
тут
Основные возможности точки доступа:
* Query composition — A client must know the capabilities of a server in order to compose suitable queries. ODBC and JDBC have fairly extensive metadata about each DBMS's SQL dialect and other properties. These may in part serve as a model.
* Content Discovery — What is the data about? What graphs does the end point contain?
* Query planning — When making an execution plan for federated queries, it is almost necessary to know the cardinalities of predicates and other things for evaluating join orders and the like.
* Query targeting — Does it make sense to send a particular query to this end point? The answer may contain things like whether the query could be parsed in the first place, whether it is known to be identically empty, estimated computation time, estimated count of results, optionally a platform dependent query plan.
Конечно, все сразу не получится, начнем с малого.
Здесь можно ближе присмотреться к
sesame
Все бы хорошо, однако нам нужен SPARQL, здесь же предлагается альтернативный язык запросов SeRQL. Цитата
«SeRQL (»Sesame RDF Query Language", pronounced «circle») is an RDF query language that is very similar to SPARQL, but with other syntax. SeRQL was originally developed as a better alternative for the query languages RQL and RDQL. A lot of SeRQL's features can now be found in SPARQL and SeRQL has adopted some of SPARQL's features in return. "
Есть еще инструменты для php типа
ARC.
Речь же идет о реализации sparql точки доступа на java
Просмотрев все предлагаемые решения(собственно, со SPARQL в java не густо, или я не там и не то ищу ), остановилась на ARQ в
Jena
в общем, да, написано немного, но хоть какие-то зацепки есть
Дальше напишу, что из этого вышло